详解Elastic Search高速搜索背后的秘密:倒排索引

引入
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选,相信大家多多少少的都听说过它。它可以快速地储存、搜索和分析海量数据。就连维基百科、Stack Overflow、Github 都采用它选择作为自己的搜索引擎今天就让我们来了解了解 Elasticsearch 为什么这么快它的架构介绍及原理解析。
文章目录
- 引入
- 一 、Elastic Search的简介
- 二、什么是倒排索引
- 2.1 倒排索引讲解
- 三、倒排索引的工作原理
- 3.1 分词与索引构建
- 3.2 索引存储与优化
- 3.3 查询处理
- 四、构建倒排索引的源码解析
- 五、实战教学
- 5.1 创建索引和映射
- 5.2 添加文档
- 5.3 搜索文档
- 总结
一 、Elastic Search的简介
Elastic Search(简称ES)是一个基于Apache Lucene构建的开源、分布式、RESTful搜索和分析引擎。它允许你快速地存储、搜索和分析大量数据。ES通常用于日志分析、全文搜索等复杂的数据分析场景。
二、什么是倒排索引
倒排索引是一种用于快速检索的数据结构,常用于搜索引擎和数据库中。与传统的正排索引不同,倒排索引是根据关键词来建立索引,而不是根据文档ID。
2.1 倒排索引讲解
下面我们用一个简单的例子描述一下倒排索引的作用过程:
假如现在有三份数据文档,内容分别是:
代码语言:javascript
Doc 1:Java is the best programming languageDoc 2:PHP is the best programming languageDoc 3:Javascript is the best programming language
为了创建索引,ES引擎通过分词器将每个文档的内容拆成单独的词(称之为词条,或term),再将这些词条创建成不含重复词条的排序列表,然后列出每个词条出现在哪个文档,结果如下:
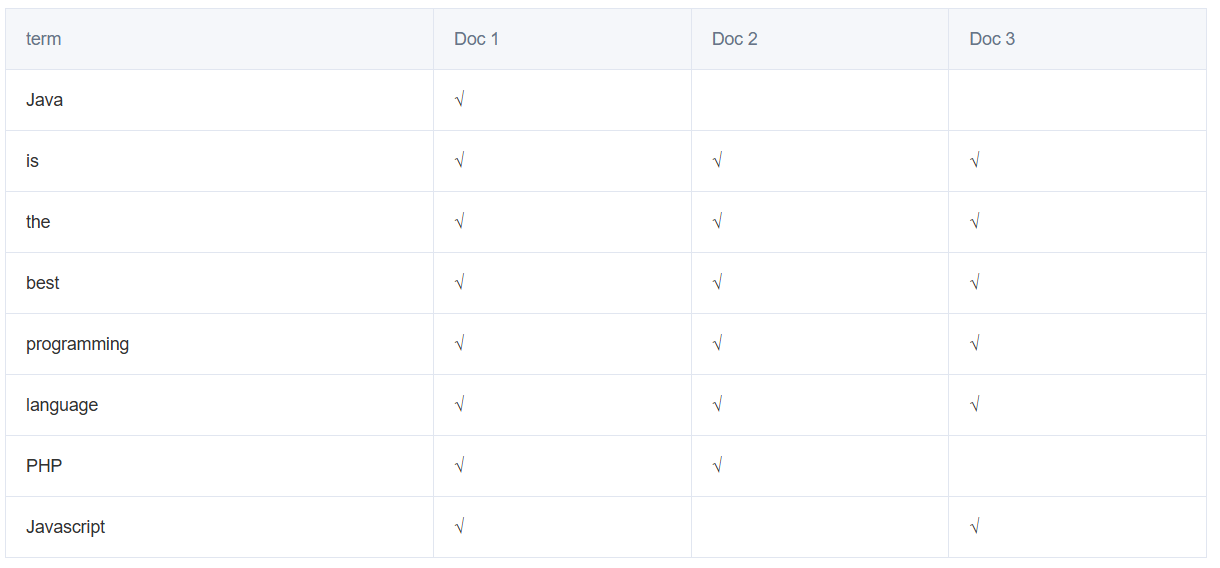
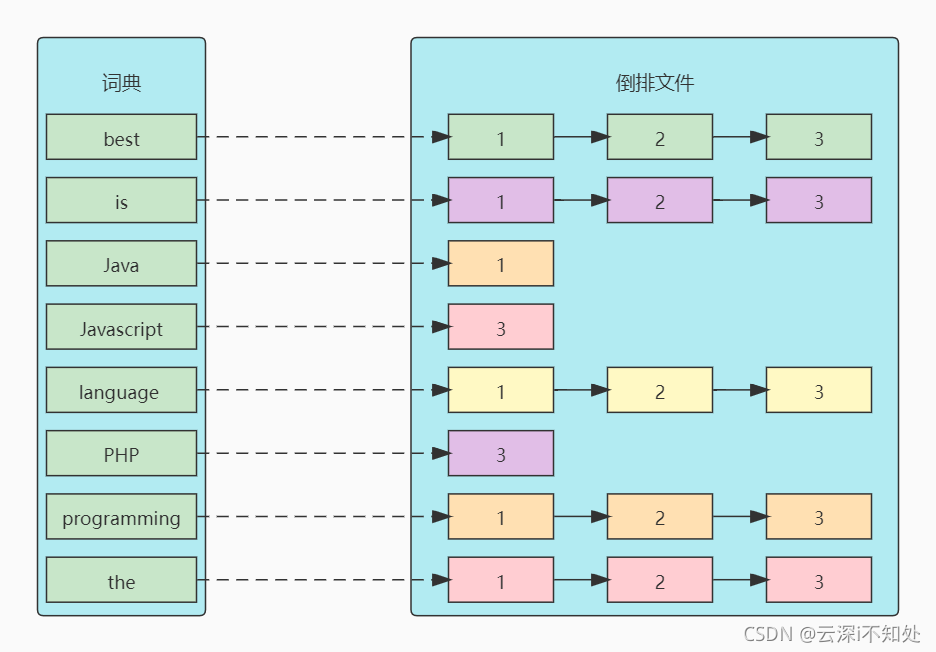
这种结构由文档中所有不重复的词的列表构成,对于其中每个词都有至少一个文档与与之关联。这种由属性值来确定记录的位置的结构就是倒排索引,带有倒排索引的文件被称为倒排文件。
将上表转为更直观的图片来展示倒排索引:
三、倒排索引的工作原理
3.1 分词与索引构建
首先,搜索引擎会对文档内容进行分词处理,将文本拆分成独立的单词或词组。然后,为每个单词或词组创建一个倒排列表,该列表记录了包含该单词或词组的所有文档的ID和该单词在文档中的位置信息(如偏移量、词频等)。
3.2 索引存储与优化
接下来,搜索引擎会将这些倒排列表存储在磁盘上,并进行一系列的优化操作,如压缩、合并等,以减少存储空间和提高查询效率。这些优化操作使得倒排索引在保持高效查询性能的同时,也具有良好的可扩展性和稳定性。
3.3 查询处理
当用户发起搜索请求时,搜索引擎会对查询语句进行分词处理,并生成一个查询词列表。然后,根据这个查询词列表在倒排索引中查找对应的倒排列表,并将这些倒排列表进行交集运算,以找到同时包含所有查询词的文档。最后,根据一定的排序算法对结果进行排序,并返回给用户。
四、构建倒排索引的源码解析
public class IndexWriter {// ... 其他属性和方法public void addDocument(Document doc) throws IOException {// Document 是一个容器,存储了待索引的字段和值// ... 初始化和准备阶段的代码// 遍历文档的每个字段for (IndexableField field : doc) {// 获取字段的名称和值String name = field.name();String value = field.stringValue();// 使用分析器对文本进行分词Analyzer analyzer = getAnalyzer();TokenStream tokenStream = analyzer.tokenStream(name, value);tokenStream.reset();// 遍历分词结果,构建倒排索引while (tokenStream.incrementToken()) {CharTermAttribute termAtt = tokenStream.getAttribute(CharTermAttribute.class);String termText = termAtt.toString();// 此处的 termText 即为分词后的词项// 将词项加入到倒排索引中,此处为简化示例,具体实现会涉及到词项的存储、文档的标识、词项在文档中的位置等信息addTermToInvertedIndex(name, termText, docId);}tokenStream.end();tokenStream.close();}// ... 后续的索引更新和维护代码}private void addTermToInvertedIndex(String fieldName, String termText, int docId) {// 此方法用于将词项加入到倒排索引中// 在实际的 Lucene 源码中,这里会涉及到更复杂的数据结构和算法来存储和管理倒排索引// ... 具体的实现代码}// ... 其他属性和方法
}五、实战教学
5.1 创建索引和映射
首先,我们需要创建一个索引,并为该索引定义一个映射(mapping),以确定文档的结构。
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;public class CreateIndexExample {public static void createBlogIndex(RestHighLevelClient client) {CreateIndexRequest request = new CreateIndexRequest("blog");request.source("{\"properties\": {\"title\": {\"type\": \"text\"},\"content\": {\"type\": \"text\"}}");try {CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);System.out.println(createIndexResponse.isAcknowledged());} catch (IOException e) {e.printStackTrace();}}
}5.2 添加文档
接下来,我们可以向我们的索引中添加一些文档。
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;public class AddDocumentExample {public static void addBlogPost(RestHighLevelClient client, String id, String title, String content) {IndexRequest request = new IndexRequest("blog").id(id);request.source("{\"title\": \"" + title + "\", \"content\": \"" + content + "\"}");try {IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);System.out.println(indexResponse.getId());} catch (IOException e) {e.printStackTrace();}}
}5.3 搜索文档
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;public class SearchDocumentExample {public static void searchPost(RestHighLevelClient client, String query) {SearchRequest searchRequest = new SearchRequest("blog");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchQuery("title", query));searchRequest.source(searchSourceBuilder);try {SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);for (SearchHit hit : searchResponse.getHits().getHits()) {System.out.println(hit.getSourceAsString());}} catch (IOException e) {e.printStackTrace();}}
}总结
过这个简单的实战示例,我们可以看到Elasticsearch的倒排索引如何使得文本搜索变得高效。倒排索引的核心思想是将单词或词组映射到包含它们的文档上,这样我们就可以直接查询倒排索引来找到包含特定单词的文档,而不需要逐个检查每个文档的内容。这使得Elasticsearch成为一个非常强大的搜索引擎,适用于各种需要高效文本搜索的场景。
相关文章:
详解Elastic Search高速搜索背后的秘密:倒排索引
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 引入 全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引…...

数据库操控指南:玩转数据
对于表中数据的基本操作 数据的操作——DML语句(增删改)1.插入数据2.修改数据3.数据删除 数据的查询——DQL语句1.原理:2.查看表结构3.条件查询4.基础的SELECT语法 阅读指南: 本文章讲述了对于数据库中的数据的基本操作࿰…...

前端 CSS 经典:图层放大的 hover 效果
效果 思路 设置 3 层元素,最上层元素使用 clip-path 裁剪成圆,hover 改变圆大小,添加过渡效果。 实现代码 <!DOCTYPE html> <html lang"en"><head><meta charset"utf-8" /><meta http-eq…...

Flutter实现页面间传参
带参跳转 步骤 在router中配置这个路由需要携带的参数,这里的参数是 arguments,注意要用花括号包裹参数名称 在相应组件中实现带参构造函数 在state类中可以直接使用${widget.arguments}来访问到传递的参数 在其他页面中使用Navigator.pushNamed()带参跳转...

如何在Java中实现安全编码
如何在Java中实现安全编码 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在当今数字化和网络化的时代,安全编码成为软件开发中至关重要的一环。特…...
C#开发-集合使用和技巧(八)集合中的排序Sort、OrderBy、OrderByDescending
C#开发-集合使用和技巧(八)集合中的排序Sort、OrderBy、OrderByDescending List<T>.Sort()方法签名使用场景示例升序实现效果 降序实现效果 IEnumerable<T>.OrderBy()方法签名使用场景示例实现效果 Enumerable<T>.OrderByDescending()…...
仓库管理系统
摘 要 随着电子商务的快速发展和物流行业的蓬勃发展,仓库管理成为了企业重要的一环。仓库管理涉及到商品的入库、出库、库存管理等一系列操作,对于企业的运营效率和成本控制具有重要影响。传统的仓库管理方式往往依赖于人工操作和纸质记录,存…...

AI绘画Stable Diffusion:超级质感真人大模型,逼真青纯!
大家好,我是设计师阿威 今天和大家分享一个具有超级质感的基于SD1.5的真人大模型:极致质感-DgirlV5,该模型追求质感的不断优化,细到发丝,当前最新版本是V5.1,修正了V5版本整体色彩发红的问题。 作者对该模…...

CMake笔记之CMAKE_INSTALL_PREFIX详解以及ROS中可执行文件为什么会在devel_lib中
CMake笔记之CMAKE_INSTALL_PREFIX详解以及ROS中可执行文件为什么会在devel_lib中 code review! 文章目录 CMake笔记之CMAKE_INSTALL_PREFIX详解以及ROS中可执行文件为什么会在devel_lib中1.CMAKE_INSTALL_PREFIX详解变量作用设置 CMAKE_INSTALL_PREFIX示例影响范围常见用法特别…...
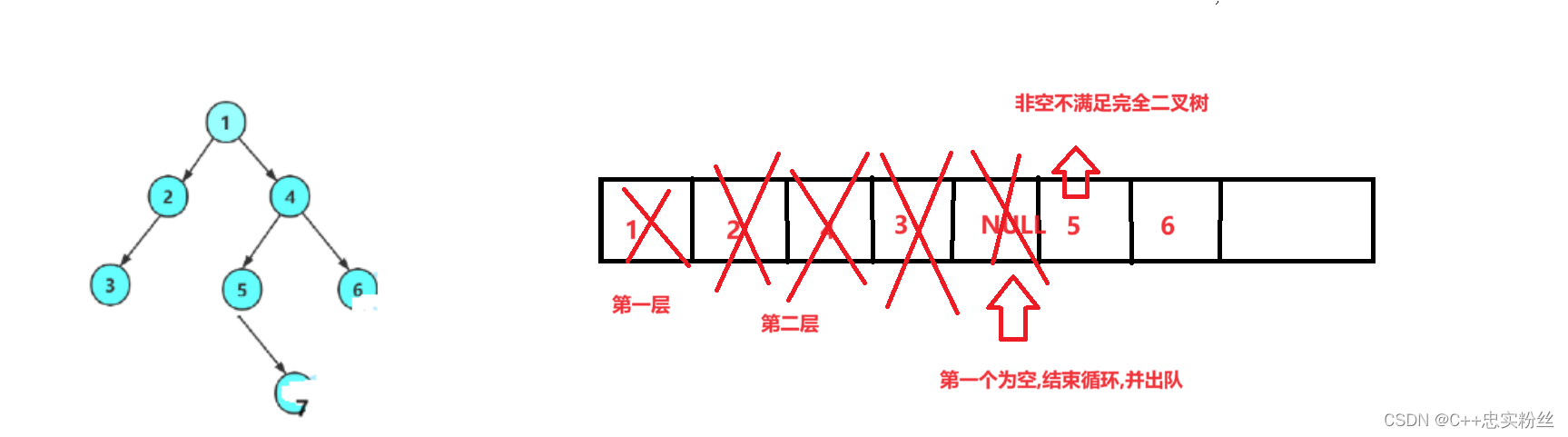
数据结构之二叉树的超详细讲解(3)--(二叉树的遍历和操作)
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 数据结构之二叉树的超详细讲解(3)--(二叉树的遍历和操作) 收录于专栏【数据结构初阶】 本专栏旨在分享学习数据结构学习的一点学习笔记,欢迎大家在评…...
Arduino - 旋转编码器 - 伺服电机
Arduino - 旋转编码器 - 伺服电机 Arduino - Rotary Encoder In this tutorial, We are going to learn how to program Arduino to rotate a servo motor according to the rotary encoder’s output value. 在本教程中,我们将学习如何对Arduino进行编程ÿ…...

儿童电动音乐牙刷OTP芯片方案:NV040C,耐温耐压,抗干扰能力强
一:方案背景概述 随着科技的飞速发展,源于对儿童口腔健康深入细致的关怀,以及对现代科技在日常生活用品中应用的不断追求,儿童电动音乐牙刷OTP芯片方案的诞生。 二:芯片简介 NV040C语音芯片是一款性能稳定、适合工厂量…...
Sentinel链路流控模式失效的解决方法
解决方法 1、在pom.xml中增加sentinel-web-servlet的依赖,我使用的版本是1.7.1 <dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-web-servlet</artifactId> </dependency>2、在项目中添加一个FilterCon…...
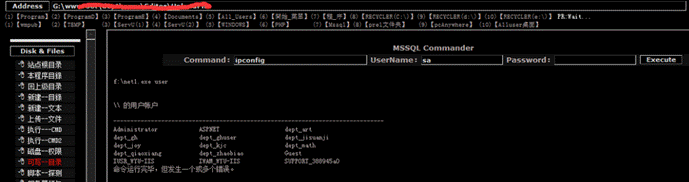
Web应用安全测试-专项漏洞(一)
Web应用安全测试-专项漏洞(一) 专项漏洞部分注重测试方法论,每个专项仅列举一个例子。实际测试过程中,需视情况而定。 文章目录 Web应用安全测试-专项漏洞(一)Web组件(SSL/WebDAV)漏…...
VMware ESXi 8.0U2c macOS Unlocker OEM BIOS Huawei (华为) FusionServer 定制版
VMware ESXi 8.0U2c macOS Unlocker & OEM BIOS Huawei (华为) FusionServer 定制版 ESXi 8.0U2 标准版,Dell (戴尔)、HPE (慧与)、Lenovo (联想)、Inspur (浪潮)、Cisco (思科)、Hitachi (日立)、Fujitsu (富士通)、NEC (日电)、Huawei (华为)、xFusion (超聚…...

python中的高阶函数介绍
在Python中,高阶函数是指那些可以接受函数作为参数或者返回函数作为结果的函数。这种特性使得函数式编程成为可能,并且可以编写出更加简洁和灵活的代码。以下是Python中一些常用的高阶函数: map() map() 函数接受一个函数和一个可迭代对象作为…...

华为OD机试 - 石头剪刀布游戏(Java 2024 D卷 200分)
华为OD机试 2024D卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(D卷C卷A卷B卷)》。 刷的越多,抽中的概率越大,每一题都有详细的答题思路、详细的代码注释、样例测…...

[开发|java] LocalDate转化为LocalDateTime
要将 java.time.LocalDate 转换为 java.time.LocalDateTime,你需要指定一天中的时间。因为 LocalDate 只包含日期部分(年、月、日),而 LocalDateTime 包含日期和时间(时、分、秒、纳秒),所以在转…...

介绍几种 MySQL 官方高可用方案
前言: MySQL 官方提供了多种高可用部署方案,从最基础的主从复制到组复制再到 InnoDB Cluster 等等。本篇文章以 MySQL 8.0 版本为准,介绍下不同高可用方案架构原理及使用场景。 1.MySQL Replication MySQL Replication 是官方提供的主从同…...
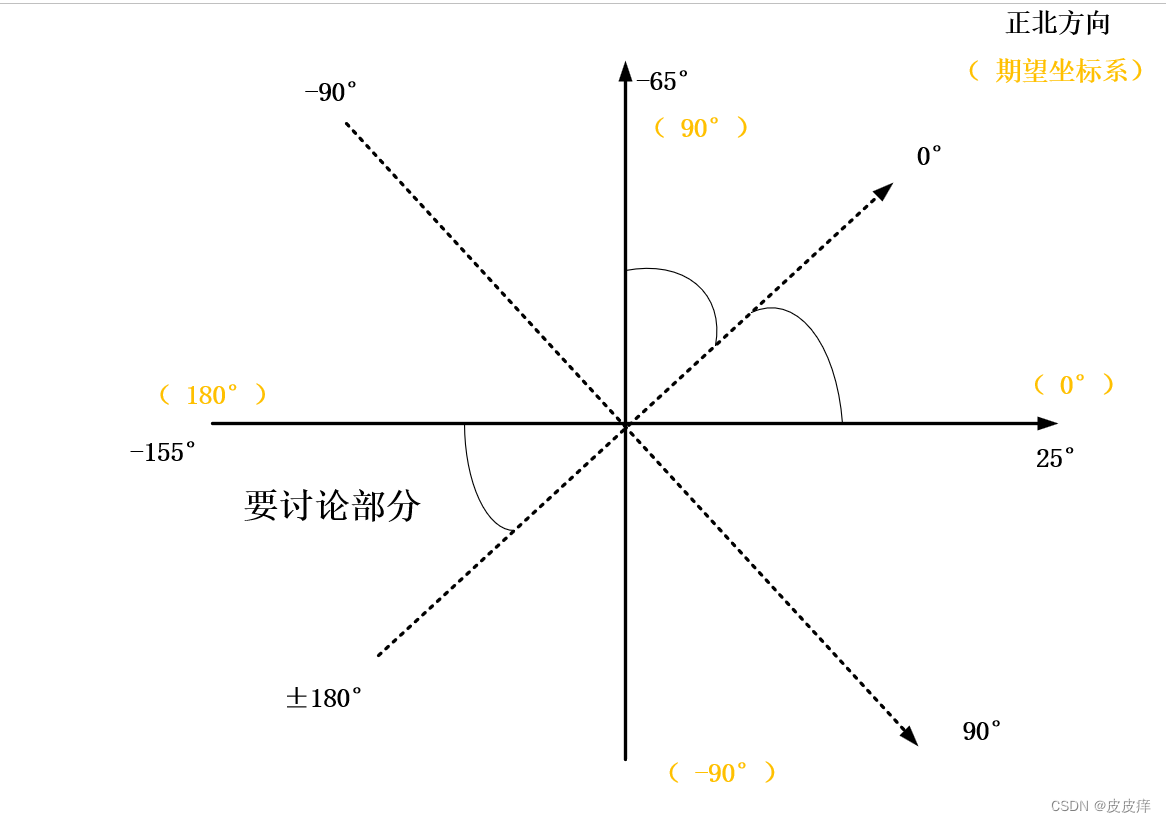
IMU坐标系与自定义坐标系转化
1.首先示例图为例: 虚线黑色角度为IMU的坐标系;实线为自定义坐标系; 矫正:(默认angleyaw为IMU采的数据角度) angleyaw_pt angleyaw-25;if(-180<angleyaw&&angleyaw<-155) // 角度跳变问…...

3个关键策略:qmcdump如何高效解密QQ音乐加密音频文件
3个关键策略:qmcdump如何高效解密QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...

一文搞懂JTT1078:车载视频监控协议科普+开发入门
之前聊过JTT808,很多朋友私信问我,车载监控里的视频画面、语音对讲靠什么实现的?答案很简单——JTT1078协议。如果说JTT808是车载监控的“骨架”,负责定位和基础状态传输,那JTT1078就是“神经”,专门管音视…...

稳压二极管数据手册参数深度解析:从符号到实战选型
1. 稳压二极管核心参数全解析 第一次拿到稳压二极管的数据手册时,我完全被那些密密麻麻的符号搞懵了。VZ、IZK、ZZT这些字母组合到底代表什么?后来在项目中踩过几次坑才明白,这些参数直接关系到电路的稳定性。就拿去年做的一个电源模块来说&a…...

从零到一:UNet环境搭建与自定义数据集实战指南
1. 环境准备:从Anaconda到PyTorch的完整配置 第一次接触UNet时,我最头疼的就是环境配置。记得当时为了跑通一个细胞分割的demo,整整折腾了两天。现在回头看,其实只要掌握几个关键步骤,整个过程可以非常顺畅。 首先需要…...

Amphenol ICC RJE1Y33A53162401网线组件解析与替代思路
在工业通信、服务器互联以及智能设备网络连接场景中,RJ45类线束组件一直是不可忽视的重要组成部分。近期不少工程师在项目选型时关注到 Amphenol ICC 推出的 RJE1Y33A53162401 线束组件。本文就围绕这款型号,从产品特点、应用方向、选型思路以及兼容替代…...

管 Vibe Coding 项目,就像管公共厕所
本文整理自"AI炼金术"播客对徐文浩的访谈,探讨 AI 辅助编程(Vibe Coding)在组织落地后面临的治理挑战和应对策略。从"屎山三年一遇"到"屎山月月有"传统软件开发中,一个系统的"屎山化"通常…...

ARM GIC中断控制器架构与关键寄存器详解
1. ARM GIC中断控制器架构概述ARM通用中断控制器(GIC)是现代ARM处理器中负责中断管理的核心组件,它实现了复杂的中断分发和处理机制。GIC架构从v2版本发展到现在的v4版本,功能不断增强,支持多核处理、虚拟化扩展和安全隔离等高级特性。GIC主要…...

DOM NodeList 深入解析
DOM NodeList 深入解析 概述 DOM NodeList 是 Web 开发中常用的一种数据结构,它代表了文档中一系列元素的集合。在本文中,我们将对 DOM NodeList 进行深入解析,包括其定义、特点、使用方法以及在实际开发中的应用。 定义 DOM NodeList 是一个类似数组的对象,它包含了文…...

终极指南:如何让淘宝淘金币任务全自动完成,每天节省20分钟
终极指南:如何让淘宝淘金币任务全自动完成,每天节省20分钟 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/tao…...

为什么92%的DeepSeek私有化部署在K8s上遭遇OOMKilled?——GPU内存隔离、vLLM适配与cgroups v2调优三重解法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek私有化部署的Kubernetes现状与OOMKilled困局 当前,DeepSeek系列大模型在企业私有化场景中广泛采用Kubernetes进行容器化编排部署。然而,实际落地过程中,内存…...