解决Transformer根本缺陷,所有大模型都能获得巨大改进
即使最强大的 LLM 也难以通过 token 索引来关注句子等概念,现在有办法了。
最近两天,马斯克和 LeCun 的口水战妥妥成为大家的看点。这两位 AI 圈的名人你来我往,在推特(现为 X)上相互拆对方台。

LeCun 在宣传自家最新论文时,也不忘手动 @ 一把马斯克,并意味深长地嘱咐道:「马斯克,我们这项研究用来改善你家的 Grok 也没问题。」

LeCun 宣传的这篇论文题目为《 Contextual Position Encoding: Learning to Count What’s Important 》,来自 Meta 的 FAIR。
骂战归骂战,这篇论文的重要性不言而喻。短短 24 小时之内就成为了 AI 领域最热门的论文之一。它有望解决如今大模型(LLM)最让人头疼的问题。

论文地址:[arxiv.org/pdf/2405.18…]
总的来说,该研究提出了一种新的用于 transformer 的位置编码方法 CoPE(全称 Contextual Position Encoding),解决了标准 transformer 无法解决的计数和复制任务。传统的位置编码方法通常基于 token 位置,而 CoPE 允许模型根据内容和上下文来选择性地编码位置。CoPE 使得模型能更好地处理需要对输入数据结构和语义内容进行精细理解的任务。文章通过多个实验展示了 CoPE 在处理选择性复制、计数任务以及语言和编码任务中相对于传统方法的优越性,尤其是在处理分布外数据和需要高泛化能力的任务上表现出更强的性能。
CoPE 为大型语言模型提供了一种更为高效和灵活的位置编码方式,拓宽了模型在自然语言处理领域的应用范围。
有网友表示,CoPE 的出现改变了在 LLM 中进行位置编码的游戏规则,此后,研究者能够在一个句子中精确定位特定的单词、名词或句子,这一研究非常令人兴奋。

这篇论文主要讲了什么,我们接着看。
许多常见的数据源(例如文本、音频、代码)都是顺序序列(ordered sequences)。在处理此类序列时,顺序(ordering)信息至关重要。对于文本,位置信息不仅对于解码单词之间的含义至关重要,而且在其他尺度(例如句子和段落级别)上都是必需的。
作为当前大型语言模型 (LLM) 的主要支柱 Transformer 架构,依赖于注意力机制,而这种机制本身就缺乏顺序信息,因此,需要一种额外的机制来编码数据的位置信息。
先前有研究者提出了位置编码(PE,Position encoding),该方法通过为每个位置分配一个嵌入向量,并将其添加到相应的 token 表示中来实现这一点。然而,当前的位置编码方法使用 token 计数来确定位置,因此无法推广到更高层次如句子。
为了将位置与更具有语义的单元(如单词或句子)联系起来,需要考虑上下文。然而,使用当前的位置编码方法无法实现这一点,因为位置寻址是独立于上下文计算的,然后再与上下文寻址合并。
Meta 认为,位置与上下文寻址的这种分离是问题的根本所在,因此他们提出了一种新的 PE 方法,即上下文位置编码( CoPE ),将上下文和位置寻址结合在一起。
方法介绍
CoPE 首先使用上下文向量确定要计数的 token。具体来说,给定当前 token 作为查询向量,接着使用先前 token 的键向量计算一个门值(gate value)。然后汇总这些门值,以确定每个 token 相对于当前 token 的相对位置,如图 1 所示。
与 token 位置不同,上下文位置可以取分数值,因而不能具有指定的嵌入。相反,该研究插入赋值为整数值的嵌入来计算位置嵌入。与其他 PE 方法一样,这些位置嵌入随后被添加到键向量中,因此查询向量可以在注意力操作中使用它们。由于上下文位置可能因查询和层而异,因此该模型可以同时测量多个单元的距离。

在 CoPE 中,位置是通过上下文相关的方式来测量的,而不是简单的 token 计数。该方法的工作原理是首先决定在使用上下文向量测量距离时应包含哪些 token。因此,对每个查询 q_i 和键 k_j 对计算门值

其中 j < i 且 σ 是 sigmoid 函数。门值为 1 表示该键将被计入位置测量中,而 0 表示将被忽略。例如,要计算 token i 和 j 之间的句子,仅对于诸如 “.” 之类的句子分隔 token,门值应为 1。门以查询为条件,如果需要,每个查询可以有不同的位置测量。软门控函数(soft gating function)允许微分,以便可以通过反向传播来训练系统。
然后,该研究通过添加当前 token 和目标 token 之间的门值来计算位置值。
值得注意的是,如果门值始终为 1,则 p_ij = i − j + 1 ,并且恢复基于 token 的相对位置。因此,CoPE 可以被视为相对 PE 的泛化。然而,一般来说,p_ij 可以是特定单词或单词类型(如名词或数字)的计数、句子的数量或 Transformer 认为在训练期间有用的其他概念。
与 token 位置不同,位置值 p_ij 不限于整数,并且因为 sigmoid 函数的原因可以采用小数值。这意味着不能像相对 PE 中那样使用嵌入层将位置值转换为向量。
首先,该研究为每个整数位置 p ∈ [0, T] 分配一个可学习的嵌入向量 e [p],那么位置 p_ij 的嵌入将是两个最接近的整数嵌入的简单插值。
最后,计算类似于如下等式的注意力权重。

然而,在实践中,计算和存储向量 e [p_ij ] 需要使用额外的计算和内存。该研究通过首先计算所有整数位置 p 的 乘法,再对结果值进行插值来提高效率:
乘法,再对结果值进行插值来提高效率:

如下方程 (4) 所示,p_ij 的最大值是上下文大小 T,这意味着需要 T + 1 个位置嵌入(包括位置 0)。然而,如果门被稀疏激活(例如计算句子),则可以用更少的位置覆盖整个上下文 T。因此,该研究通过设置 ,使得最大可能位置 p_max < T。
,使得最大可能位置 p_max < T。

CoPE 的多头扩展非常简单,因为每个头都会独立执行自己的 CoPE。头之间的键和查询向量是不同的,这意味着它们可以实现不同的位置测量。
实验结果
Flip-Flop 任务
Liu 等人 [2024] 提出了 Flip-Flop 语言建模任务,以揭示 Transformer 模型无法在长距离输入序列上进行稳健推理。
结果如表 2(左)所示。结果表明,CoPE 优于现有方法,使模型不仅可以学习分布内任务,还可以推广到 OOD 序列 —— 这是现有 PE 方法无法提供的属性。

选择性复制任务
Gu 和 Dao [2023] 提出的选择性复制任务需要上下文感知推理才能进行选择性记忆。
表 2(右)中给出的结果显示,在分布内测试集上,新方法 CoPE 可以解决该任务,而其他方法则无法解决。同样的,CoPE 在密集和稀疏 OOD 测试集上都具有更好的泛化能力。空白 token 的存在使得找到下一个要复制的 token 变得更加困难,但 CoPE 只能计算非空白 token,因此更加稳定。在每个步骤中,它可以简单地复制距离为 256(非空白)的非空白 token。重复此操作 256 次将复制整个非空白序列。
计数任务
计数比简单地回忆上一个实例更具挑战性,因为它需要在一定范围内更均匀的注意力。
结果见表 3 和图 2。具有相对 PE 的基线模型很难学习此任务,尤其是当有多个变量需要跟踪时。绝对 PE 的表现更差。最佳表现来自 CoPE,在 1 个变量的情况下获得满分。对于 OOD 泛化,相对 PE 表现出较差的泛化能力,而 CoPE 的泛化能力非常好,如表 4 所示。有关这些实验的标准差,请参见附录表 9。

语言建模
为了在语言建模任务上测试新方法,研究人员使用了 Wikitext-103 数据集,该数据集包含从 Wikipedia 中提取的 1 亿个 token。
表 5(左)中比较了不同的 PE 方法:绝对 PE 表现最差,CoPE 优于相对 PE,与相对 PE 结合使用时效果更佳。这表明,即使在一般语言建模中,CoPE 也能带来改进。

接下来,作者测试了 CoPE 推广到比训练上下文更长的上下文的效果。
结果如图 3 所示。相对 PE 推广到更长的上下文效果不佳。相比之下,相对上限版本的表现要好得多。然而 CoPE 的表现仍然优于它,当测试上下文比训练上下文长得多时,差距会扩大(见图 3 右)。

如图 4 所示,作者展示了使用 sep-keys 训练的模型的注意力图示例(gate 是用分离的键计算的)。注意力图仅根据位置构建(它们必须与上下文注意力相乘才能得到最终的注意力),这能让我们更好地了解 CoPE 正在做什么。作者还进行了归一化,以便每个查询的最大注意力权重始终为 1。首先,我们可以看到位置明显具有上下文相关性,因为无论它们的相对位置如何,注意力都倾向于落在特定的 token 上。
仔细观察这些 token 会发现,注意力主要集中在最后一段(左)或部分(右)上。为清楚起见,实际的段落和部分边界用黑色加号标记。在 CoPE 中,这是可能的,因为一个注意力头可以计数段落,而另一个注意力头计数部分,然后它可以只关注位置 0。

代码建模
作者通过对代码数据进行评估来进一步测试 CoPE 的能力。与自然语言相比,代码数据具有更多的结构,并且可能对上下文学习更敏感。
结果总结在表 5(右)中。CoPE 嵌入的困惑度比绝对 PE 和 RoPE 分别提高了 17% 和 5%。将 RoPE 和 CoPE 嵌入结合在一起可以改善 RoPE,但不会比所提出的嵌入方法带来任何改进。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
解决Transformer根本缺陷,所有大模型都能获得巨大改进
即使最强大的 LLM 也难以通过 token 索引来关注句子等概念,现在有办法了。 最近两天,马斯克和 LeCun 的口水战妥妥成为大家的看点。这两位 AI 圈的名人你来我往,在推特(现为 X)上相互拆对方台。 LeCun 在宣传自家最新论…...

如何排查Java应用的死锁
排查Java应用中的死锁问题是一个复杂但重要的任务,因为死锁会导致应用程序停止响应,影响用户体验和系统稳定性。以下是一些方法和步骤,帮助你排查Java应用中的死锁。 1. 理解死锁的概念 在计算机科学中,死锁是指两个或多个线程相…...

JS面试题1
1. 延迟加载JS有哪些方式? defer: 等html全部解析完成,才会执行js代码,顺次执行js脚本 async:是和html解析同步的,不是顺次执行js脚本(当有很多个js时),是谁先加载完谁先执行。 <…...
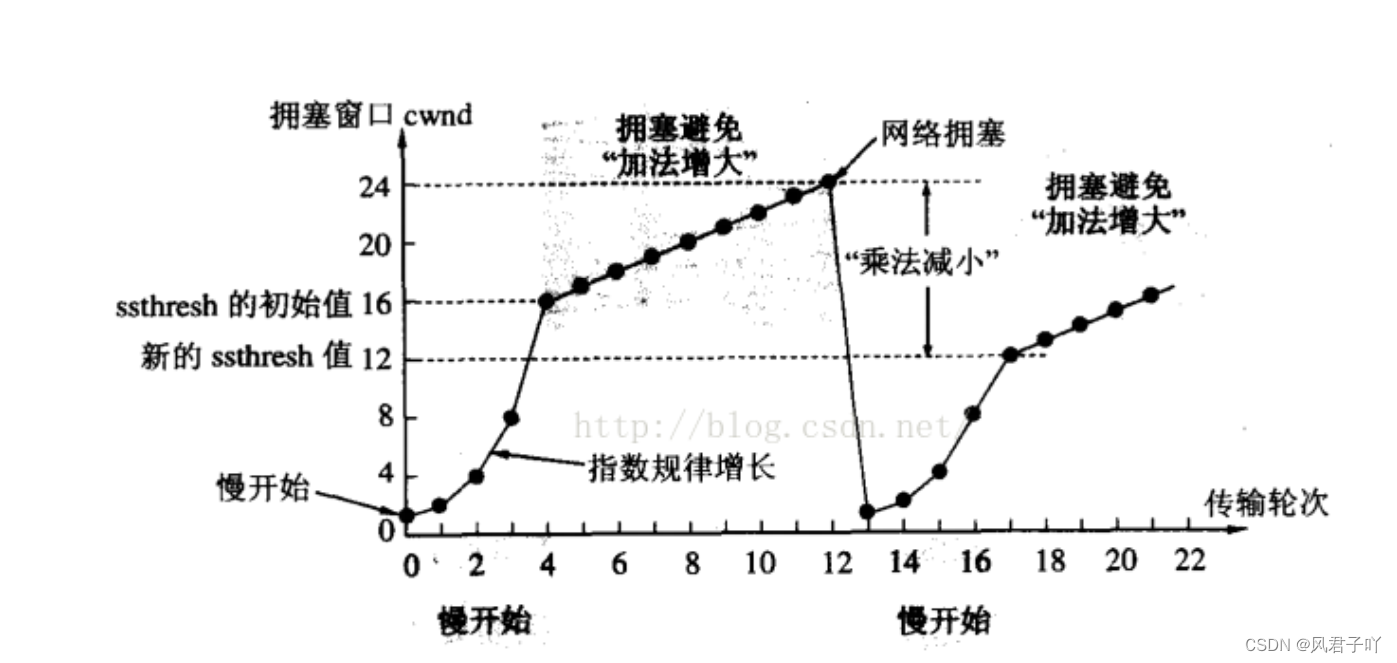
Linux网络 - 再谈、详谈UDP和TCP协议
文章目录 前言预备netstatpidofcat /etc/services 一、UDP协议UDP协议端格式UDP的缓冲区基于UDP的应用层协议 二、TCP协议1.TCP协议段格式确认应答(ACK)机制三次握手疑问1 最后一次客户端发给服务端的ACK请求怎么保证服务端能够收到? 四次挥手疑问2 为什么挥手是四次…...

el-form重置后input无法输入问题
新增用户遇到的问题: 如果你没有为 formData 设置默认值,而只是将其初始化为空对象 {},则在打开dialog时,正常输入, formdata会变成如下 但是,打开后,直接使用 resetFields 或直接清空表单&…...
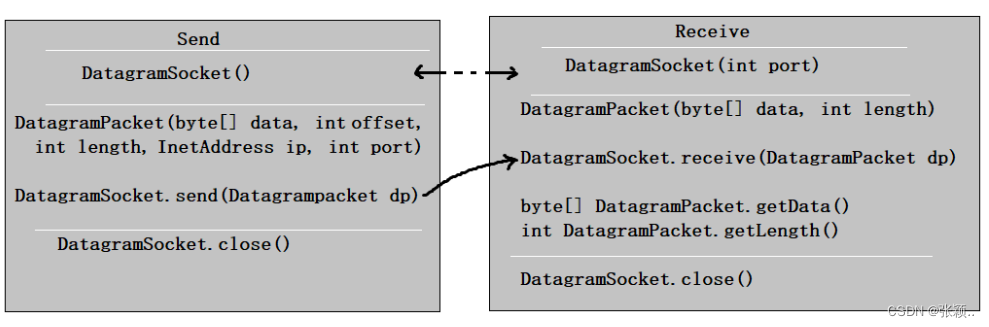
Java网络编程(JavaWeb的基础)
Java网络编程(JavaWeb的基础) 文章目录 Java网络编程(JavaWeb的基础)前言一、网络编程概述1.1 软件架构&网络基础1.2 网络通信要素:IP/端口/通信协议1.3 传输层协议:tcp/udp 二、网络编程API2.1 InetAddress类2.2 Socket类&am…...

鸿蒙Harmony开发实战案例:使用OpenGL绘制3D图形
XComponent控件常用于相机预览流的显示和游戏画面的绘制,在OpenHarmony上,可以配合Native Window创建OpenGL开发环境,并最终将OpenGL绘制的图形显示到XComponent控件。本文将采用"Native C"模板,调用OpenGL ES图形库绘制3D图形&…...

DM达梦数据库存储过程
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 💝Ὁ…...

【python】OpenCV—Color Correction
文章目录 cv2.aruco 介绍imutils.perspective.four_point_transform 介绍skimage.exposure.match_histograms 介绍牛刀小试遇到的问题 参考学习来自 OpenCV基础(18)使用 OpenCV 和 Python 进行自动色彩校正 cv2.aruco 介绍 一、cv2.aruco模块概述 cv2.…...
Java基础知识整理笔记
目录 1.关于Java概念 1.1 谈谈对Java的理解? 1.2 Java的基础数据类型? 1.3 关于面向对象的设计理解 1.3.1 面向对象的特性有哪些? 1.3.2 重写和重载的区别? 1.3.3 面向对象的设计原则是什么? 1.4 关于变量与方…...
知识图谱——Neo4j数据库实战
数据与代码链接见文末 1.Neo4j数据库安装 JDK 安装:https://www.oracle.com/java/technologies/javase-downloads.html Neo4j 安装:https://neo4j.com/download-center/ 配置好 JDK 和 Neo4j 的环境变量...

第十一次Javaweb作业
4.登录校验 4.1会话 --用户打开浏览器,访问web服务器的资源,会话建立,直到有一方断开连接,会话结束。在一次会话中可以包含多次请求和响应。 会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求…...

人工智能AI风口已开:如何赋予UI设计与视频剪辑新生命
随着科技的浪潮不断向前推进,人工智能(AI)正以惊人的速度重塑着我们的世界,特别是在创意产业的核心领域——UI设计与视频剪辑中,AI正逐步成为驱动行业创新与变革的关键力量。在这个AI技术全面开花的新时代,…...

计算机专业课面试常见问题-编程语言篇
目录 1. 程序的编译执行流程? 2. C浅拷贝和深拷贝的区别? 3. C虚函数? …...
CSS|05 继承性与优先级
继承性 一、继承性的特点: 1.外层元素身上的样式会被内层元素所继承 2.如果内层元素与外层元素身上的演示相同时,外层元素的样式会被内层元素所覆盖 二、关于继承性的问题 是不是所有样式都能被继承? 答:并不是所有样式能被继承…...

KVM性能优化之内存优化(宿主机)
linux系统自带了一技术叫透明巨型页(transparent huge page),它允许所有的空余内存被用作缓存以提高性能,而且这个设置是默认开启的,我们不需要手动去操作。 Centos下,我们用cat /sys/kernel/mm/transpare…...
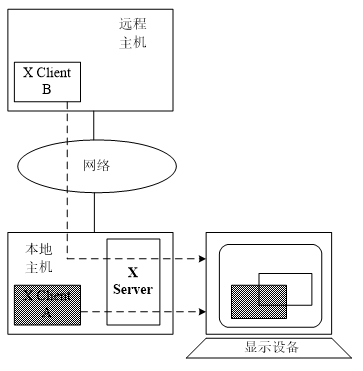
【Linux杂货铺】Linux学习之路:期末总结篇1
第一章 什么是Linux? Linux 是 UNIX 操作系统的一个克隆;它由林纳斯 本纳第克特 托瓦兹从零开始编写,并在网络上众多松散的黑客团队的帮助下得以发展和完善;它遵从可移植操作系统接口(POSIX)标准和单一 UNIX 规范…...

GPT-5的到来:智能飞跃与未来畅想
IT之家6月22日消息,在美国达特茅斯工程学院的采访中,OpenAI首席技术官米拉穆拉蒂确认了GPT-5的发布计划,预计将在一年半后推出。穆拉蒂形象地将GPT-4到GPT-5的飞跃比作高中生到博士生的成长。这一飞跃将给我们带来哪些变化?GPT-5的…...
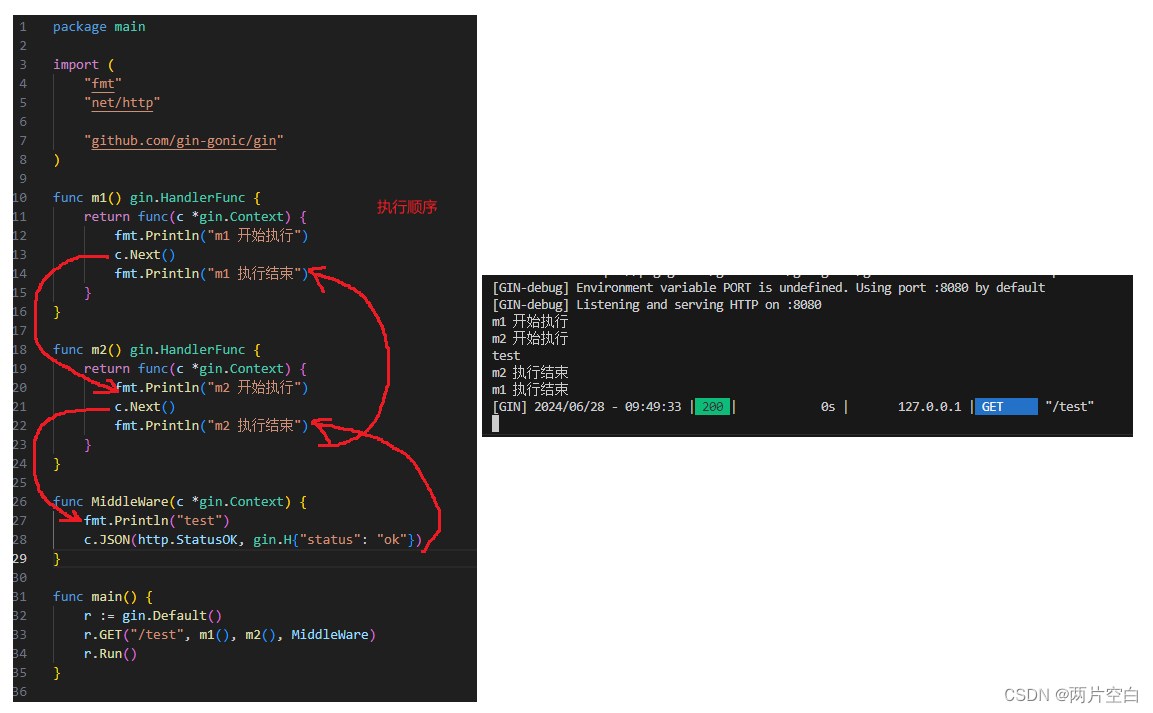
gin中间件
在web应用服务中,完整的业务处理在技术上包含客户端操作,服务端处理,返回处理结果给客户端三个步骤。但是在在更负责的业务和需求场景。一个完整的系统可能要包含鉴权认证,权限管理,安全检查,日志记录等多维…...

swagger常用注解
最近查看接口文档的时候发现,POST方法中的query没法在swagger中显示,查了才发现这是因为Swagger或OpenAPI规范默认将HTTP POST请求的参数识别为请求体(body)参数,而不是查询字符串(query)参数。…...

从分钟到秒级:我们用 Fluss + Paimon 替换掉 Kafka + Iceberg,实时宽表终于不用 Flink 死扛了
从分钟到秒级:我们用 Fluss Paimon 替换掉 Kafka Iceberg,实时宽表终于不用 Flink 死扛了 📅 更新于 2026-05-21 | 🏷️ Fluss Paimon 湖流一体 实时数仓 架构升级 摘要:上一代湖仓一体架构中,Kafka …...

PDF补丁丁终极指南:5分钟学会PDF元数据精准修改技巧
PDF补丁丁终极指南:5分钟学会PDF元数据精准修改技巧 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https://gitc…...

【QiLink 创始人手记:为什么我回绝了第一家专利代理所?】
QiLink 创始人手记:为什么我回绝了第一家专利代理所?今天,我做了一个可能会让很多传统创业者感到“冒险”的决定——我正式回绝了一家安徽本地律师事务所的专利代理合作。写下这段文字,并不是为了炫耀我“砍价”成功,而…...

从测试分类到缺陷管理
目录 1.多维测试分类:覆盖测试全场景 1.1 按测试目标分类 1.2 按执行方式分类 1.3 按测试方法分类 1.4 按测试阶段分类 1.5 按实施组织分类 2. 测试用例设计 2.1 用例设计万能公式 2.2 六大核心设计方法 3. 测试核心流程与 bug 管理 3.1 软件测试生命…...

华硕笔记本性能控制终极指南:用GHelper轻松管理硬件性能
华硕笔记本性能控制终极指南:用GHelper轻松管理硬件性能 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, …...

从零到精通:3分钟掌握gdown,让Google Drive下载不再是噩梦
从零到精通:3分钟掌握gdown,让Google Drive下载不再是噩梦 【免费下载链接】gdown Google Drive public file downloader when curl/wget fails. 项目地址: https://gitcode.com/gh_mirrors/gd/gdown 还在为Google Drive大文件下载失败而烦恼吗&a…...
)
FANUC机器人摆焊+电弧跟踪实战:从参数详解到避坑指南(ROBOGUIDE仿真)
FANUC机器人摆焊与电弧跟踪协同优化实战解析 在厚板焊接与复杂轨迹加工领域,正弦摆焊与电弧跟踪技术的协同应用已成为提升焊接质量的关键手段。资深工程师们常常面临这样的挑战:如何在坡口焊接中精准配置那二十余项电弧传感器参数,使机器人既…...

企业内训系统集成Taotoken实现多模型AI助教与可控的交互成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内训系统集成Taotoken实现多模型AI助教与可控的交互成本 对于现代企业而言,构建一个高效、智能的内训系统是提升员…...

基于YOLOv10的低延迟AI瞄准系统:多平台硬件加速与实时检测架构设计
基于YOLOv10的低延迟AI瞄准系统:多平台硬件加速与实时检测架构设计 【免费下载链接】yolov8_aimbot Aim-bot based on AI for all FPS games 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_aimbot Sunone Aimbot是一个基于YOLOv10深度学习模型的FPS游…...

终极Zotero插件市场:一站式插件发现与管理完全指南
终极Zotero插件市场:一站式插件发现与管理完全指南 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing and installing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons Zotero插件市场&a…...