一文入门机器学习参数调整实操
作者前言:
通过向身边的同事大佬请教之后,大佬指点我把本文的宗旨从“参数调优”改成了“参数调整”。实在惭愧,暂时还没到能“调优”的水平,本文只能通过实操演示“哪些操作会对数据训练产生影响”,后续加深学习之后,再争取入门“参数调优”。
一、为什么要参数调优?
答:提升数据模型性能。
通常来说,我们选择使用的数据模型并不是万能的,它们面对不同的使用场景时,均存在一定的局限性,因此我们渴望提升模型性能,理论上无限追求“万能”模型。
数据模型的常用性能指标大致如下:
| 性能指标 | 定义 | 衡量指标 | 影响因素 |
|---|---|---|---|
| 准确性 ⭐⭐⭐ | 模型在预测或分类任务中的准确性,即模型对数据的预测或分类是否准确。 | - 准确率(Accuracy) - 精确率(Precision) - 召回率(Recall) - F1分数(F1 Score) - AUC-ROC | - 数据集的质量和数量 - 特征工程的效果 - 模型的选择和参数调优 |
| 泛化能力 ⭐⭐⭐ | 模型对未见过的新数据、噪声和异常值的适应能力,即模型在新数据上的表现是否良好。 | - 交叉验证(Cross-Validation) - 验证集和测试集性能 - 学习曲线(Learning Curve) - 异常值检测能力 - 鲁棒性测试 | - 数据集的多样性和代表性 - 模型的复杂度(过拟合和欠拟合) - 正则化技术(如L1、L2正则化) - 数据增强和数据预处理方法 |
| 训练速度 | 模型在训练过程中的速度,即模型在给定数据集上的训练时间。 | - 训练时间 - 迭代次数 | - 数据集的大小和复杂度 - 模型的复杂度和参数数量 - 硬件配置(如CPU、GPU、TPU) - 优化算法(如SGD、Adam)的选择 |
| 预测速度 | 模型在预测或推断阶段的速度,即模型在给定数据上的预测时间。 | - 预测时间 - 吞吐量 | - 模型的复杂度和参数数量 - 硬件配置(如CPU、GPU、TPU) - 预测时的批处理大小(Batch Size) |
| 模型复杂度 | 模型的复杂度和简洁性,即模型的结构和参数数量,以及模型是否过于简单或过于复杂。 | - 参数数量 - 模型结构 - 计算复杂度 | - 任务的复杂性和数据的特征 - 模型选择(如线性模型、决策树、神经网络) - 正则化和剪枝技术 |
二、参数调优调整
切记!切记!下面所有的例子,都是仅针对单一衡量指标演示不同的case对该指标的影响,具体的衡量指标数据并非越大/小越好,评判性能好坏需要根据实际情况结合多个衡量指标共同判断!!!
通过阅读一文入门机器学习,我们知道数据模型训练的流程大致如下:
因此参数调优基本可以分为两个方向:
- 数据集
- 数据量
- 数据特征
- 数据模型
- 模型类型
- 模型超参数
所以下面内容均按照这两个方向来演示。
Tips:
- 在开始之前请先准备好环境
# 安装python3 # 自行搜索安装教程,我这里使用的是python3# 安装pip3 python3 -m ensurepip --upgrade# 安装机器学习常用库 pip3 install scikit-learn pip3 install numpy
0.准确性
以经典的鸢尾花数据集为例,演示“数据集、数据模型的调整”对准确性的影响。
这里仅演示准确率这一个衡量指标,需要注意,并非准确率越高,准确性就越强(如过拟合)。
a.影响因素:数据集
在例子中,我们分3种case测试:
- case1:相同数据模型,相同数据集,使用所有特征,使用100%数据量
- case2:相同数据模型,相同数据集,使用所有特征,仅使用5%数据量
- case3:相同数据模型,相同数据集,仅使用前2个特征,使用100%数据量
示例代码如下:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# case1:相同数据模型,相同数据集,使用所有特征,使用100%数据量
# 逻辑回归模型
model1 = LogisticRegression()
model1.fit(X_train, y_train)
y_pred1 = model1.predict(X_test)
# 计算分类模型准确率
accuracy1 = accuracy_score(y_test, y_pred1)# case2:相同数据模型,相同数据集,使用所有特征,仅使用5%数据量
# 逻辑回归模型
model2 = LogisticRegression()
X_train_5 = X_train[:int(0.05 * len(X_train))]
y_train_5 = y_train[:int(0.05 * len(y_train))]
model2.fit(X_train_5, y_train_5)
y_pred2 = model2.predict(X_test)
# 计算分类模型准确率
accuracy2 = accuracy_score(y_test, y_pred2)# case3:相同数据模型,相同数据集,仅使用前2个特征,使用100%数据量
# 逻辑回归模型
model3 = LogisticRegression()
X_train_subset = X_train[:, :2]
X_test_subset = X_test[:, :2]
model3.fit(X_train_subset, y_train)
y_pred3 = model3.predict(X_test_subset)
# 计算分类模型准确率
accuracy3 = accuracy_score(y_test, y_pred3)print(f"使用100%训练数据的准确率: {accuracy1:.2f}")
print(f"使用5%训练数据的准确率: {accuracy2:.2f}")
print(f"仅使用前2个特征的准确率: {accuracy3:.2f}")
执行结果:
| case | 准确率 |
|---|---|
| case1:相同数据模型,相同数据集,使用所有特征,使用100%数据量 | 1.00 |
| case2:相同数据模型,相同数据集,使用所有特征,仅使用5%数据量 | 0.44 |
| case3:相同数据模型,相同数据集,仅使用前2个特征,使用100%数据量 | 0.82 |
很明显可以看出,相同数据集,不同的数据量、数据特征,均会影响准确率。
b.影响因素:数据模型
在例子中,我们分3种case测试:
- case1:使用逻辑回归模型,相同数据集,仅使用前2个特征,使用100%数据量
- case2:使用随机森林模型,相同数据集,仅使用前2个特征,使用100%数据量
- case3:使用随机森林模型,相同数据集,仅使用前2个特征,使用100%数据量,进行超参数调优
Tips:
- 这里“仅使用前2个特征”是因为鸢尾花数据集这个经典的机器学习案例相对较简单(数据量小、特征少、标签有限),如果使用全部特征来训练的话,准确率直接100%了,不便于演示调整效果,因此这里限制一下特征。
示例代码如下:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 仅使用前2个特征
X_train_subset = X_train[:, :2]
X_test_subset = X_test[:, :2]# case1:逻辑回归
clf_lr = LogisticRegression(random_state=42, max_iter=200)
clf_lr.fit(X_train_subset, y_train)
y_pred_lr = clf_lr.predict(X_test_subset)
# 计算分类模型准确率
accuracy_lr = accuracy_score(y_test, y_pred_lr)# case2:随机森林
clf_rf = RandomForestClassifier(random_state=42)
clf_rf.fit(X_train_subset, y_train)
y_pred_rf = clf_rf.predict(X_test_subset)
# 计算分类模型准确率
accuracy_rf = accuracy_score(y_test, y_pred_rf)# case3:随机森林超参数调优
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 10, 20, 30],'min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42), param_grid=param_grid, cv=5, n_jobs=-1)
grid_search.fit(X_train_subset, y_train)
best_rf = grid_search.best_estimator_
y_pred_best_rf = best_rf.predict(X_test_subset)
# 计算分类模型准确率
accuracy_best_rf = accuracy_score(y_test, y_pred_best_rf)print(f"逻辑回归的准确率: {accuracy_lr:.2f}")
print(f"随机森林的准确率: {accuracy_rf:.2f}")
print(f"调优后的随机森林的准确率: {accuracy_best_rf:.2f}")
执行结果:
| case | 准确率 |
|---|---|
| case1:使用逻辑回归模型,相同数据集,仅使用前2个特征,使用100%数据量 | 0.82 |
| case2:使用随机森林模型,相同数据集,仅使用前2个特征,使用100%数据量 | 0.73 |
| case3:使用随机森林模型,相同数据集,仅使用前2个特征,使用100%数据量,进行超参数调优 | 0.78 |
同样可以看出,数据模型的类型、数据模型的超参数均会影响准确率。
1.泛化能力
以经典的加利福尼亚房价数据集为例,演示“数据集、数据模型的调整”对泛化能力的影响,该数据集包含20640个样本,每个样本有8个特征(如房间数、人口、经纬度等)。
Tips:
- 这里仅演示“方差”这一个衡量指标,需要注意,并非方差越低,泛化能力就越强。评判一个数据模型的泛化能力通常需要综合考虑多个衡量指标。
- 对于回归问题,常用的指标包括MSE、RMSE、MAE和R²;
- 对于分类问题,常用的指标包括准确率、精确率、召回率、F1分数、AUC-ROC曲线和混淆矩阵。
- 此外,交叉验证和学习曲线也是评估模型泛化能力的重要方法。通过综合这些指标,可以更全面地评估模型在未见过的数据上的表现。
a.影响因素:数据集
在例子中,我们分7种case测试:
- case1:使用线性回归模型,相同数据集,使用所有特征,使用1000数据量
- case2:使用线性回归模型,相同数据集,使用所有特征,使用5000数据量
- case3:使用线性回归模型,相同数据集,使用所有特征,使用10000数据量
- case4:使用线性回归模型,相同数据集,使用所有特征,使用20000数据量
- case5:使用线性回归模型,相同数据集,仅使用前1个特征,使用20640数据量
- case6:使用线性回归模型,相同数据集,仅使用前3个特征,使用20640数据量
- case7:使用线性回归模型,相同数据集,仅使用前5个特征,使用20640数据量
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.datasets import fetch_california_housing# 加载加利福尼亚房价数据集
california = fetch_california_housing()
X = california.data
y = california.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)def train_and_evaluate(num_samples):# 线性回归模型model = LinearRegression()model.fit(X_train[:num_samples], y_train[:num_samples])y_pred = model.predict(X_test)# 计算均方误差mse = mean_squared_error(y_test, y_pred)return mse# case1、2、3、4:不同数据量的测试结果
for num_samples in [1000, 5000, 10000, 20000]:mse = train_and_evaluate(num_samples)print(f"使用 {num_samples} 条数据训练,测试集均方误差: {mse:.2f}")def train_with_features(features):# 线性回归模型model = LinearRegression()model.fit(X_train[:, :features], y_train)y_pred = model.predict(X_test[:, :features])# 计算均方误差mse = mean_squared_error(y_test, y_pred)return mse# case5、6、7:使用不同特征组合
# 不同特征组合的测试结果
for features in [1, 3, 5]:mse = train_with_features(features)print(f"使用前 {features} 个特征训练,测试集均方误差: {mse:.2f}")
执行结果:
| case | 方差 |
|---|---|
| case1:使用线性回归模型,相同数据集,使用所有特征,使用1000数据量 | 0.60 |
| case2:使用线性回归模型,相同数据集,使用所有特征,使用5000数据量 | 0.55 |
| case3:使用线性回归模型,相同数据集,使用所有特征,使用10000数据量 | 0.55 |
| case4:使用线性回归模型,相同数据集,使用所有特征,使用20000数据量 | 0.56 |
| case5:使用线性回归模型,相同数据集,仅使用前1个特征,使用20640数据量 | 0.71 |
| case6:使用线性回归模型,相同数据集,仅使用前3个特征,使用20640数据量 | 0.66 |
| case7:使用线性回归模型,相同数据集,仅使用前5个特征,使用20640数据量 | 0.64 |
从数据可以看出,数据模型的数据量不同、特征不同,均会影响方差。
b.影响因素:数据模型
在例子中,我们分4种case测试:
- case1:使用线性回归模型,相同数据集,使用所有特征,使用20640数据量
- case2:使用决策树回归模型,相同数据集,使用所有特征,使用20640数据量
- case3:使用随机森林回归模型,相同数据集,使用所有特征,使用20640数据量
- case4:使用随机森林回归模型,相同数据集,使用所有特征,使用20640数据量,进行超参数调优
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor# 加载加利福尼亚房价数据集
california = fetch_california_housing()
X = california.data
y = california.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# case1、2、3:线性回归、决策树回归和随机森林回归模型
models = {'Linear Regression': LinearRegression(),'Decision Tree Regressor': DecisionTreeRegressor(),'Random Forest Regressor': RandomForestRegressor()
}# 训练和评估模型
for name, model in models.items():model.fit(X_train, y_train)y_pred = model.predict(X_test)mse = mean_squared_error(y_test, y_pred)print(f"{name} 均方误差: {mse:.2f}")# case4:超参数调优
# 定义超参数网格
param_grid = {'n_estimators': [10, 50, 100],'max_depth': [None, 10, 20, 30],'min_samples_split': [2, 5, 10]
}# 随机森林回归模型
rf = RandomForestRegressor()# 网格搜索,使用单CPU,执行很慢,建议使用下面优化的网格搜索
# grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, scoring='neg_mean_squared_error')# 网格搜索,使用所有可用的CPU
# 参数解释:
# n_jobs=-1:使用所有可用的 CPU 核心进行并行计算。
# cv=5:使用5折交叉验证来评估每个超参数组合的性能。
# scoring='neg_mean_squared_error':使用负均方误差作为评估指标,因为 GridSearchCV 期望一个越大越好的评分指标。
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, scoring='neg_mean_squared_error', n_jobs=-1)
grid_search.fit(X_train, y_train)# 最佳超参数
best_params = grid_search.best_params_
print(f"最佳超参数: {best_params}")# 使用最佳超参数训练模型
best_rf = grid_search.best_estimator_
y_pred = best_rf.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"调优后的随机森林均方误差: {mse:.2f}")
执行结果:
| case | 方差 |
|---|---|
| case1:使用线性回归模型,相同数据集,使用所有特征,使用20640数据量 | 0.56 |
| case2:使用决策树回归模型,相同数据集,使用所有特征,使用20640数据量 | 0.50 |
| case3:使用随机森林回归模型,相同数据集,使用所有特征,使用20640数据量 | 0.26 |
| case4:使用随机森林回归模型,相同数据集,使用所有特征,使用20640数据量,进行超参数调优 | 0.25 |
同样可以看出,数据模型的类型、数据模型的超参数均会影响方差。
2.其他性能指标
除“准确性”和“泛化能力”之外,其他性能指标并非核心指标,这里仅选取“训练速度”演示一下。
a.影响因素:数据集
数据量和数据特征对训练速度的影响比较简单易懂,通常情况下,越多越慢,所以就不在这里做演示了。
b.影响因素:数据模型
以经典的鸢尾花数据集为例,演示“数据模型类型、数据模型参数”对准确性的影响。
在例子中,我们分2种case测试:
- case1:使用逻辑回归模型,相同数据集,使用所有特征,使用所有数据量
- case2:使用向量机(SVM)模型,相同数据集,使用所有特征,使用所有数据量
执行以下代码:
# 导入必要的库
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.metrics import accuracy_score
import time# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)start_time_lr = time.time()
# 逻辑回归模型
model_lr = LogisticRegression()
model_lr.fit(X_train, y_train)
predictions_lr = model_lr.predict(X_test)
# 计算分类模型准确率
accuracy_lr = accuracy_score(y_test, predictions_lr)
end_time_lr = time.time()
print("逻辑回归模型准确率:", accuracy_lr)
print("逻辑回归模型训练耗时:", end_time_lr - start_time_lr, "秒")start_time_svm = time.time()
# 支持向量机(SVM)模型
model_svm = SVC(kernel='linear')
model_svm.fit(X_train, y_train)
predictions_svm = model_svm.predict(X_test)
# 计算分类模型准确率
accuracy_svm = accuracy_score(y_test, predictions_svm)
end_time_svm = time.time()
print("SVM模型准确率:", accuracy_svm)
print("SVM模型训练耗时:", end_time_svm - start_time_svm, "秒")
执行结果:
| case | 训练耗时 (秒) |
|---|---|
| case1:使用逻辑回归模型,相同数据集,使用所有特征,使用所有数据量 | 0.016212940216064453 |
| case2:使用向量机(SVM)模型,相同数据集,使用所有特征,使用所有数据量 | 0.002279996871948242 |
明显可以看到向量机(SVM)模型比逻辑回归模型的训练速度更快。
三、归纳
Tips:
- 准确性的实操演示,只以“准确率”这一个衡量指标做了演示;
- 泛化能力的实操演示,只以“方差”这一个衡量指标做了演示;
- 其他同样重要的衡量指标不在这里做演示,毕竟本文仅仅是入门文章,当读者有一定基础之后,可以自行研究其他衡量指标的实操。
| 调优方向 | 调优内容 | 调优方式 | 补充 |
| 数据集 | 数据量 | 增加数据量:更多的数据通常可以帮助模型更好地学习数据的模式和规律,提高模型的准确性。 | 当然,数据量越多准确性越高,但是训练速度也会越低,实际应用中需要酌情选择适量数据集。 |
| 特征 ⭐⭐⭐ | 特征选择:选择最相关的特征,减少噪声和冗余特征,提高模型的准确性; 特征提取:从原始数据中提取新的特征,帮助模型更好地捕捉数据的模式; 特征转换:对特征进行变换,如标准化、归一化等,使特征更适合模型的使用。 | 特征选取的足够好,既能提高模型的准确性,也能提升模型的训练速度。 | |
| 数据模型 | 模型类型 ⭐⭐ | 选择合适的模型:根据问题的性质选择合适的模型类型,如分类、回归、聚类等,以提高模型的准确性。 | 同样,模型选取的足够好,既能提高模型的准确性,也能提升模型的训练速度。 |
| 模型参数 ⭐⭐⭐ | 调优模型参数:通过网格搜索、随机搜索等方法调优模型的超参数,以找到最佳的参数组合,提高模型准确性; 正则化:使用正则化方法,如L1正则化、L2正则化,控制模型的复杂度,避免过拟合,提高模型的泛化能力。 | 本文缺少对超参数的介绍,后续会在“参数调优”的文章中补充,帮助读者入门“超参数”,感谢理解。🙏 |
四、寄语
在撰写本文的过程中,我深刻体会到参数调整的重要性和复杂性。虽然目前我还未达到“调优”的水平,但希望通过本文的实操演示,能帮助大家了解哪些操作会对数据训练产生影响。
机器学习的世界广阔而深邃,参数调整只是其中的一部分。希望大家在学习的过程中,不断探索和实践,逐步提升自己的技能。未来,我也会继续学习和分享更多关于“参数调优”的内容,期待与大家共同进步。
五、材料
- 机器学习数据集库:目前维护着665个开源数据集,读者可以查看、下载、上传数据集。
- 机器学习python库:scikit-learn:基于python的机器学习接口库,提供功能丰富的机器学习接口,如:下载数据集、训练、调参等。
- 机器学习python库:tensorflow:基于python的机器学习接口库,通过交互式代码示例,了解如何使用直观的API。
相关文章:

一文入门机器学习参数调整实操
作者前言: 通过向身边的同事大佬请教之后,大佬指点我把本文的宗旨从“参数调优”改成了“参数调整”。实在惭愧,暂时还没到能“调优”的水平,本文只能通过实操演示“哪些操作会对数据训练产生影响”,后续加深学习之后,…...

基于51单片机的银行排队呼叫系统设计
一.硬件方案 本系统是以排队抽号顺序为核心,客户利用客户端抽号,工作人员利用叫号端叫号;通过显示器及时显示当前所叫号数,客户及时了解排队信息,通过合理的程序结构来执行排队抽号。电路主要由51单片机最小系统LCD12…...

JXCategoryView的使用总结
一、初始化 -(JXCategoryTitleView *)categoryView{if (!_categoryView) {_categoryView [[JXCategoryTitleView alloc] init];_categoryView.delegate self;_categoryView.titleDataSource self;_categoryView.averageCellSpacingEnabled NO; //是否平均分配项目之间的间…...

Centos9 安装VBox增强功能问题
安装步骤 更新gcc 首先手动更新gcc,防止无法兼容最新版本的内核,我这里将gcc 11更新到gcc 13 1.首先更新当前gcc和支持 yum install -y gcc gcc-c 2.下载新版本gcc压缩包 wget http://ftp.gnu.org/gnu/gcc/gcc-13.1.0/gcc-13.1.0.tar.gz 解压到usr ta…...

【JVM】Java虚拟机运行时数据分区介绍
JVM 分区(运行时数据区域) 文章目录 JVM 分区(运行时数据区域)前言1. 程序计数器2. Java 虚拟机栈3. 本地方法栈4. Java 堆5. 方法区6. 运行时常量池7. 直接内存 前言 之前在说多线程的时候,提到了JVM虚拟机的分区内存…...
)
大数据面试题之Kafka(2)
目录 Kafka的工作原理? Kafka怎么保证数据不丢失,不重复? Kafka分区策略 Kafka如何尽可能保证数据可靠性? Kafka数据丢失怎么处理? Kafka如何保证全局有序? 生产者消费者模式与发布订阅模式有何异同? Kafka的消费者组是如何消费数据的 Kafka的…...
)
前端面试题(基础篇十一)
一、DOCTYPE 的作用是什么? <!DOCTYPE> 声明一般位于文档的第一行,它的作用主要是告诉浏览器以什么样的模式来解析文档。一般指定了之后会以标准模式来进行文档解析,否则就以兼容模式进行解析。在标准模式下,浏览器的解析规…...
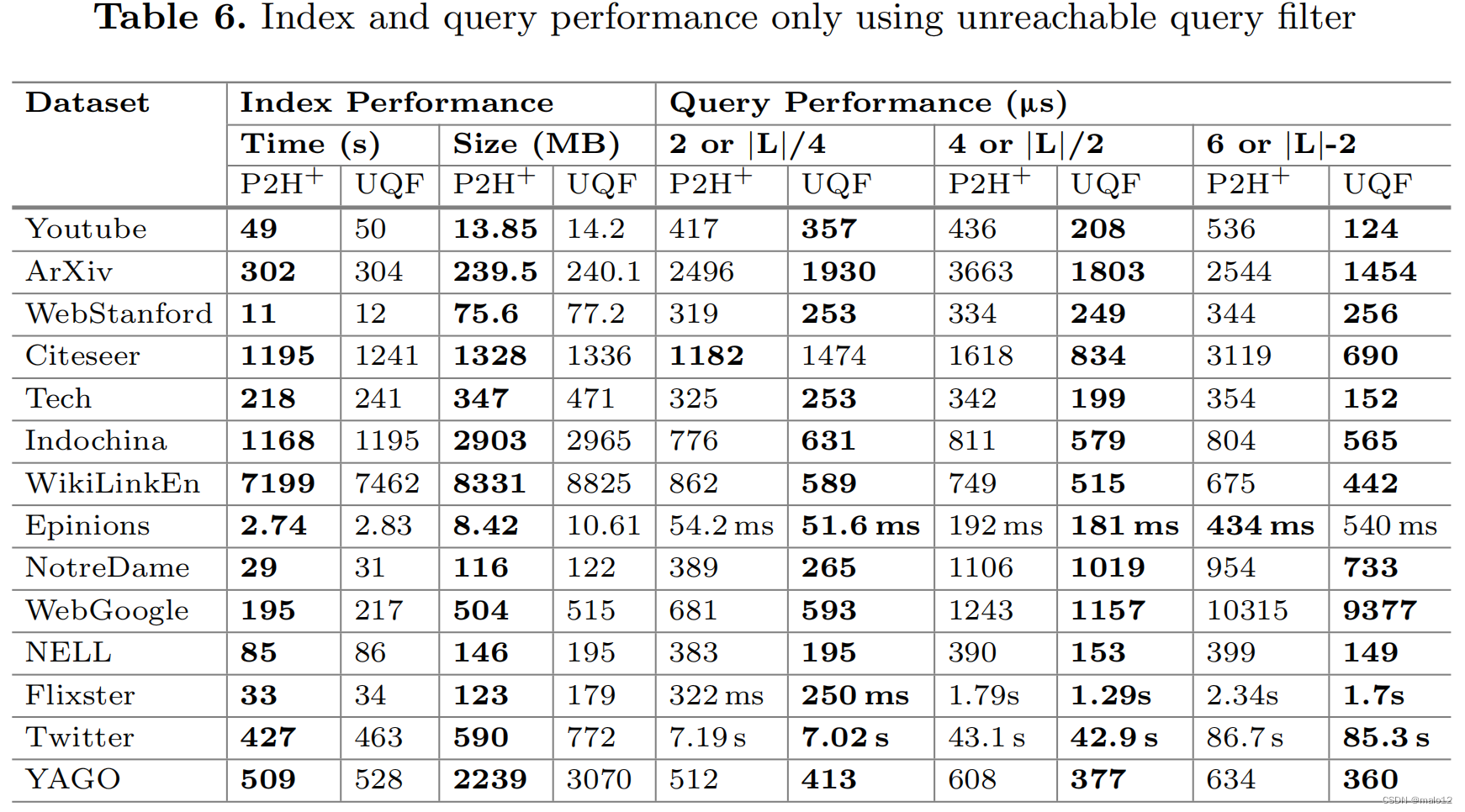
【论文阅读】Answering Label-Constrained Reachability Queries via Reduction Techniques
Cai Y, Zheng W. Answering Label-Constrained Reachability Queries via Reduction Techniques[C]//International Conference on Database Systems for Advanced Applications. Cham: Springer Nature Switzerland, 2023: 114-131. Abstract 许多真实世界的图都包含边缘标签…...

Git Flow 工作流学习要点
Git Flow 工作流学习要点 Git Flow — 流程图Git Flow — 操作指令优点:缺点:Git Flow 分支类型Git Flow 工作流程简述关于 feature 分支关于 Release 分支关于 hotfix 分支 总结 Git Flow — 流程图 图片来源:https://nvie.com/posts/a-succ…...

blender 快捷键 常见问题
一、快捷键 平移视图:Shift 鼠标中键旋转视图:鼠标中键缩放视图:鼠标滚动框选放大模型:Shift B线框预览和材质预览切换:Shift Z 二、常见问题 问题:导入模型成功,但是场景中看不到。 解…...

HTTP详解:TCP三次握手和四次挥手
一、TCP协议概述 TCP协议是互联网协议栈中传输层的核心协议之一,它提供了一种可靠的数据传输方式,确保数据包按顺序到达,并且没有丢失或重复。TCP的主要特点包括: 面向连接:TCP在传输数据之前需要建立连接。可靠传输&…...

详解HTTP:有了HTTP,为何需要WebSocket?
在日常生活中,HTTP 常用于请求数据。例如,当你打开一个天气预报网站时,浏览器会发送一个 HTTP 请求到服务器,请求当前的天气数据,服务器返回响应,浏览器解析并显示这些数据。 但是,当涉及到需要…...

Spring Boot 启动流程是怎么样的
引言 SpringBoot是一个广泛使用的Java框架,旨在简化基于Spring框架的应用程序的开发过程。在这篇文章中,我们将深入探讨SpringBoot应用程序的启动流程,了解其背后的机制。 Spring Boot 启动概览 SpringBoot应用程序的启动通常从一个包含 m…...
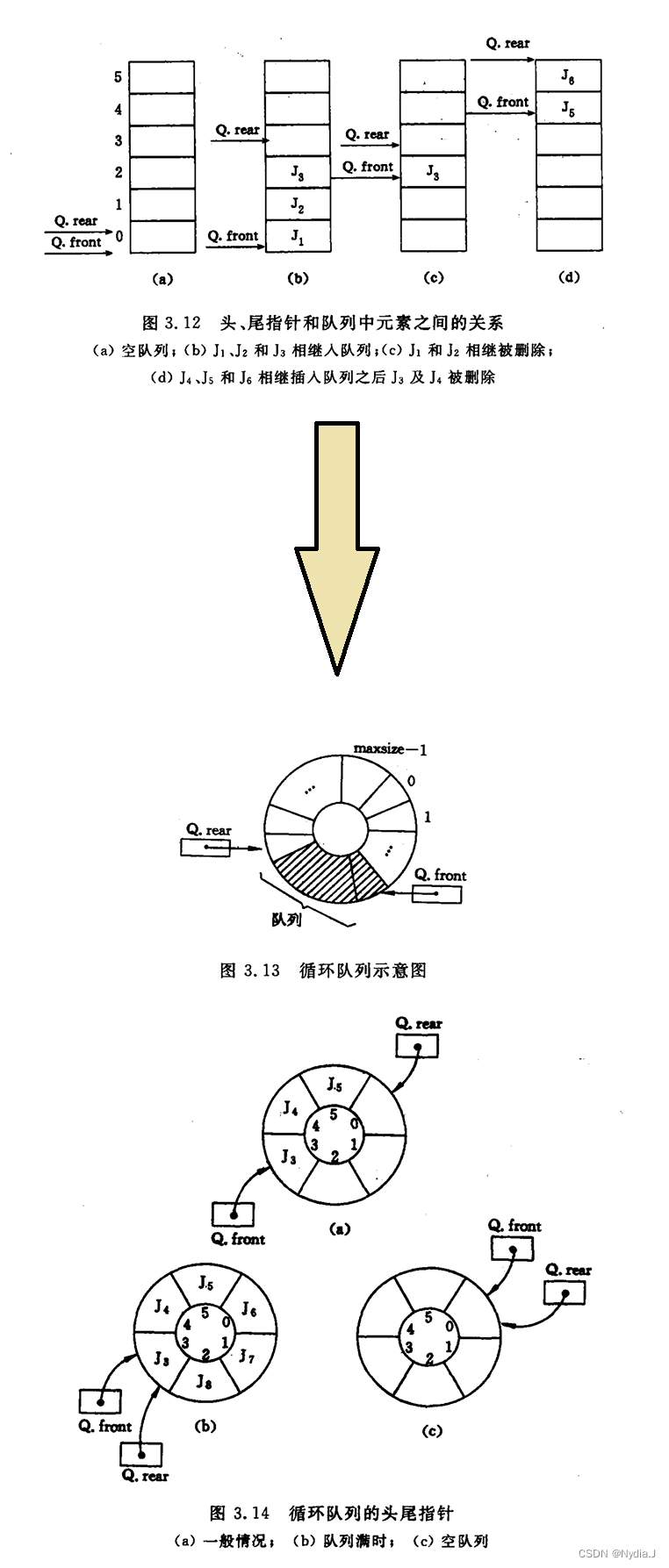
【学习笔记】数据结构(三)
栈和队列 文章目录 栈和队列3.1 栈 - Stack3.1.1 抽象数据类型栈的定义3.1.2 栈的表示和实现 3.2 栈的应用举例3.2.1 数制转换3.2.2 括号匹配的检验3.2.3 迷宫求解3.2.4 表达式求值 - 波兰、逆波兰3.2.5 反转一个字符串或者反转一个链表 3.3 栈与递归的实现3.4 队列 - Queue3.4…...

学习python笔记:10,requests,enumerate,numpy.array
requests库,用于发送 HTTP 请求的 Python 库。 requests 是一个用于发送 HTTP 请求的 Python 库。它使得发送 HTTP 请求变得简单且人性化。以下是一些基本的 requests 函数及其用途: requests.get(url, **kwargs) 发送一个 GET 请求到指定的 URL。 i…...

经典神经网络(13)GPT-1、GPT-2原理及nanoGPT源码分析(GPT-2)
经典神经网络(13)GPT-1、GPT-2原理及nanoGPT源码分析(GPT-2) 2022 年 11 月,ChatGPT 成功面世,成为历史上用户增长最快的消费者应用。与 Google、FaceBook等公司不同,OpenAI 从初代模型 GPT-1 开始,始终贯彻只有解码器࿰…...

MySQL库与表的操作
目录 一、登录并进入数据库 1、登录 2、USE 命令 检查当前数据库 二、库的操作 1、创建数据库语法 2、举例演示 3、退出 三、字符集和校对规则 1、字符集(Character Set) 2、校对集(Collation) 总结 3、操作命令 …...

TTS 语音合成技术学习
TTS 语音合成技术 TTS(Text-to-Speech,文字转语音)技术是一种能够将文字内容转换为自然语音的技术。通过 TTS,机器可以“说话”,这大大增强了人与机器之间的互动能力。无论是在语音助手、导航系统还是电子书朗读器中&…...

小公司做自动化的困境
1. 人员数量不够 非常常见的场景, 开发没几个, 凭什么测试要那么多, 假设这里面有3个测试, 是不是得有1个人会搞框架? 是不是得有2人搞功能测试, 一个人又搞框架, 有些脚本, 真来得及吗? 2. 人员基础不够 现在有的大公司, 是这样子协作的, 也就是某模块需求谁谁测试的, 那么…...

基于pytorch框架的手写数字识别(保姆级教学)
1、前言 本文基于PyTorch框架,采用CNN卷积神经网络实现MNIST手写数字识别,不仅可以在GPU上,同时也可以在CPU上运行。方便即使只有CPU的小伙伴也可以运行该模型。本博客手把手教学,如何手写网络层(3层),以及模型训练,详细介绍各参数含义与用途。 2、模型源码解读 该模型…...

开源提示词库:提升AI协作效率的实战指南与核心设计解析
1. 项目概述:一个开源提示词库的价值与定位如果你也经常使用大型语言模型,无论是用于编程辅助、内容创作还是日常问答,那么你一定遇到过这样的困境:面对一个空白的输入框,明明心里有明确的需求,却不知道如何…...
)
别再傻傻传文件了!用Java Base64把图片和PDF直接“塞”进HTML页面(附完整代码)
告别文件传输:Java Base64技术实现图片与PDF的HTML直嵌方案 在Web开发中,我们经常遇到需要将图片或PDF文档直接嵌入HTML页面的场景。传统做法通常需要先将文件上传到服务器,然后通过URL引用,这不仅增加了网络请求,还引…...

AI编码助手重复犯错?4大策略构建可控的智能编程伙伴
1. 项目概述:当AI编码助手陷入“重复犯错”的怪圈最近和几个团队的技术负责人聊天,发现大家都有个共同的烦恼:项目里引入的AI编码助手(或者叫AI编程副驾),用着用着就发现它好像“不长记性”。同一个项目里&…...

RAG开发实战:Langchain-RAG-DevelopmentKit核心架构与工程化指南
1. 项目概述:一个面向RAG应用开发的“瑞士军刀”如果你正在或打算基于LangChain构建检索增强生成(RAG)应用,那么你大概率会遇到一个经典困境:从零开始搭建一个健壮、可扩展的RAG系统,需要整合的组件和技术栈…...

AI辅助开发工作流:用免费代理优化付费工具,提升代码生成效率
1. 项目概述:用免费AI代理优化付费AI工具的开发工作流如果你和我一样,订阅了Claude Pro或者GitHub Copilot,但每个月看着额度条飞速见底,心里总有点发慌,那这篇文章就是为你准备的。我们不是在讨论哪个AI写代码更强&am…...

AI产品经理转型指南——传统PM如何不被淘汰
文章针对想转型AI产品经理但缺乏经验的人提供了实用的转型路径。首先,文章指出传统产品经理的焦虑源于视角受限,而非技术能力不足,并提出AI无法替代产品经理对用户、业务和组织的深度理解。接着,文章建议转型者从“用AI重做一遍”…...

基于FastAPI与Cytoscape.js构建个人技能图谱可视化平台
1. 项目概述:一个技能图谱的聚合与沉淀平台最近在整理自己的技术栈和项目经验时,我常常感到一种“知识碎片化”的困扰。学过的框架、用过的工具、解决过的特定问题,都散落在不同的笔记、代码仓库和记忆角落里。当需要快速构建一个原型&#x…...

CodeSandbox终极指南:10个让你开发效率倍增的隐藏功能
CodeSandbox终极指南:10个让你开发效率倍增的隐藏功能 【免费下载链接】codesandbox-client An online IDE for rapid web development 项目地址: https://gitcode.com/gh_mirrors/co/codesandbox-client CodeSandbox是一款强大的在线IDE,专为快速…...

OpenClaw本地控制台:一站式图形化管理AI助手工作流
1. 项目概述:一个为本地OpenClaw工作流量身打造的控制台如果你和我一样,在Windows上折腾过OpenClaw,那你肯定经历过这种“精神分裂”式的管理体验:想启动服务,得切到终端敲命令;要改个模型配置,…...

为什么93%的DeepSeek PR被拒?揭秘CI流水线自动拦截的4类“伪Clean”代码陷阱
更多请点击: https://intelliparadigm.com 第一章:为什么93%的DeepSeek PR被拒?揭秘CI流水线自动拦截的4类“伪Clean”代码陷阱 DeepSeek 开源仓库的 CI 流水线以严苛著称——最新统计显示,93% 的 PR 在 pre-commit 阶段即被自动…...