【Apache Doris】如何实现高并发点查?(原理+实践全析)
【Apache Doris】如何实现高并发点查?(原理+实践全析)
- 一、背景说明
- 二、原理介绍
- 三、环境信息
- 四、Jmeter初始化
- 五、参数预调
- 六、用例准备
- 七、高并发实测
- 八、影响因素
- 九、总结
本文主要分享 Apache Doris 是如何实现高并发点查的,以及如何实测单节点上万QPS。
一、背景说明
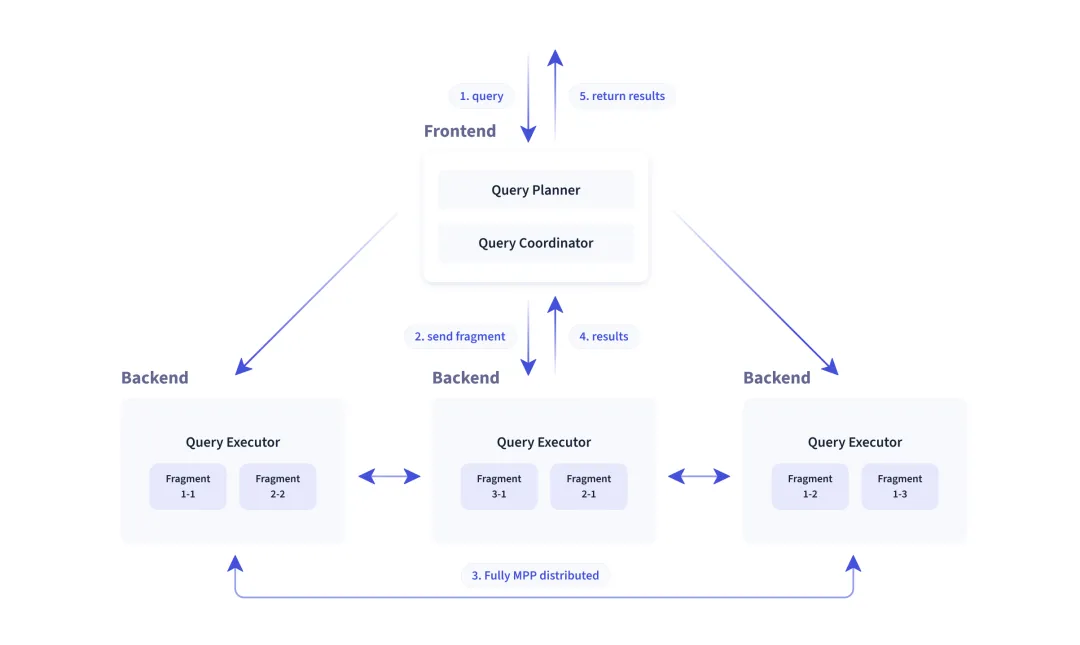
Apache Doris 是一款基于 MPP 架构的高性能、实时的分析型数据库。它可以在多个节点上并行处理查询,显著提高查询效率,且默认以列存格式引擎构建。这种格式非常适合进行数据分析,因为它可以有效地压缩数据,并且在执行查询时只需要读取相关的列。但有些高并发服务场景中,用户需要频繁获取整行数据,如果表较宽时,列存的IO也随之被放大。
Apache Doris 中 FE 是 SQL 查询的访问层服务,使用 Java 编写,分析和解析 SQL 也会导致高并发查询的高 CPU 开销,且其查询引擎和计划对于某些简单的查询(例如点查询)而言太重了。
那么,Apache Doris 是如何实现高并发查询以及如何实现高并发点查的呢?
二、原理介绍
Apache Doris 能够实现高并发查询的能力主要是通过以下几个方面:
- MPP架构
基于大规模并行处理(Massively Parallel Processing, MPP)架构设计,它可以将查询分解为多个任务,在多个节点上并行执行这些任务,使得系统可以通过增加更多的计算资源来线性扩展其查询处理能力。
- 列式存储
使用列式存储格式,这意味着对于任何给定的查询,它只需要读取涉及到的列,而不是整行数据。这减少了磁盘I/O压力,因为只有必需的数据被加载到内存中。
- 数据分片
分区和分桶裁剪在 Apache Doris 中也是实现高并发查询的重要机制。这两种技术可以帮助更有效地组织数据,提高查询效率,尤其是在面对大规模数据集时。
- 向量化查询执行
Apache Doris 实现了向量化查询处理,这意味着在执行操作时,它可以一次处理数据列的一整块,而不是逐行处理。这样可以大大提高CPU的利用率,降低每个数据点的处理开销。
- 索引和物化视图
Apache Doris 支持创建索引和物化视图来加速查询,减少扫描行数和避免了大量的现场计算,例如倒排、ZoneMap、Bloom Filter和Bitmap 等索引和预计算物化。
- 统计信息和成本基准优化
Apache Doris 会收集表和列的统计信息,并使用这些信息来优化查询计划,选择最佳的执行路径。
… 此处省略上万字
基于【背景说明】和上述内容,Apache Doris 可实现单节点上千 QPS 的并发支持。但在一些超高并发要求(例如上万 QPS)的 Data Serving 场景中,仍然存在瓶颈。
因此,Apache Doris 引入了如下几个2.0新特性 从降低 SQL 内存 IO 开销、提升点查执行效率以及降低 SQL 解析开销这三个设计点出发,进行一系列优化:
- 行式存储格式(Row Store Format)
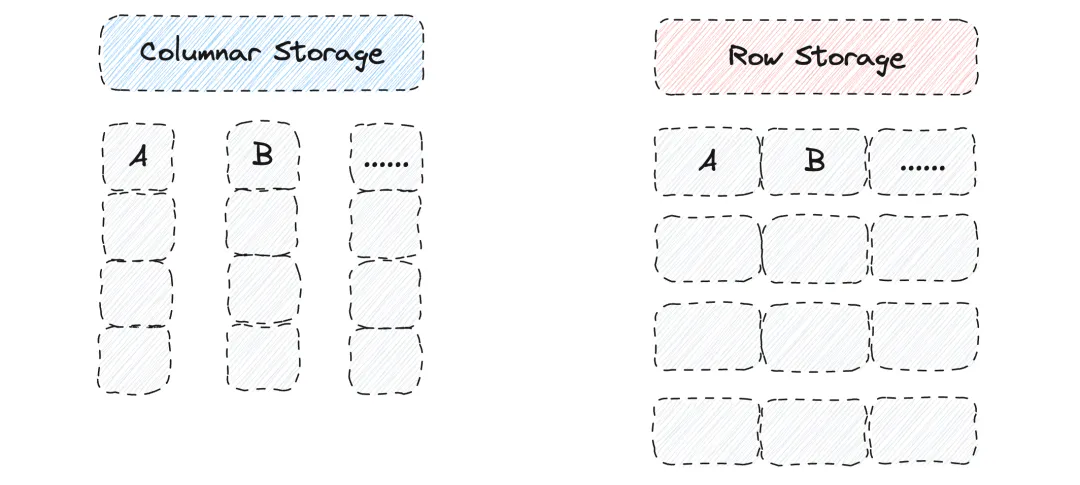
Apache Doris 支持用户在建表时,通过 store_row_column 表属性另存一份行数据(列存+行存)。在单次检索整行数据时效率更高,减少磁盘访问次数 。
- 行存缓存(Row Cache)
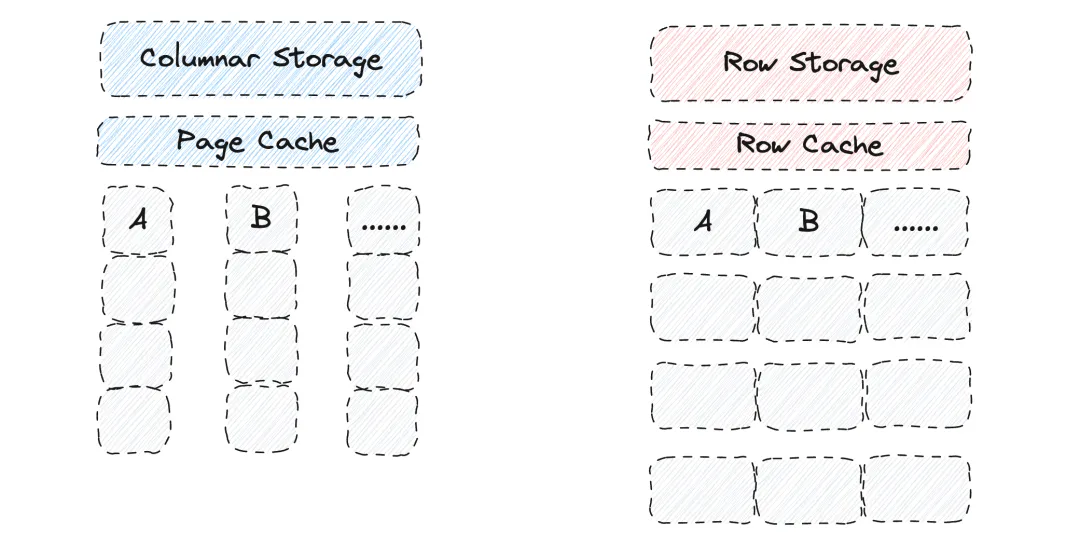
Apache Doris 有针对列数据的Page Cache。但如果一行包括多列数据,这类缓存可能会被大查询给刷掉,为了增加缓存命中率、提升点查询的性能,Apache Doris 引入了行存缓存(Row Cache)。
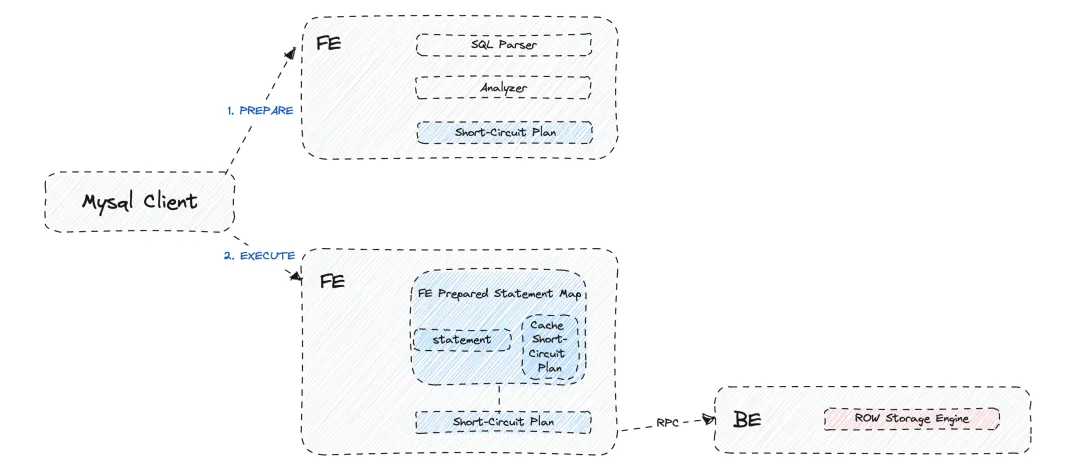
- 点查询短路径优化(Short-Circuit)
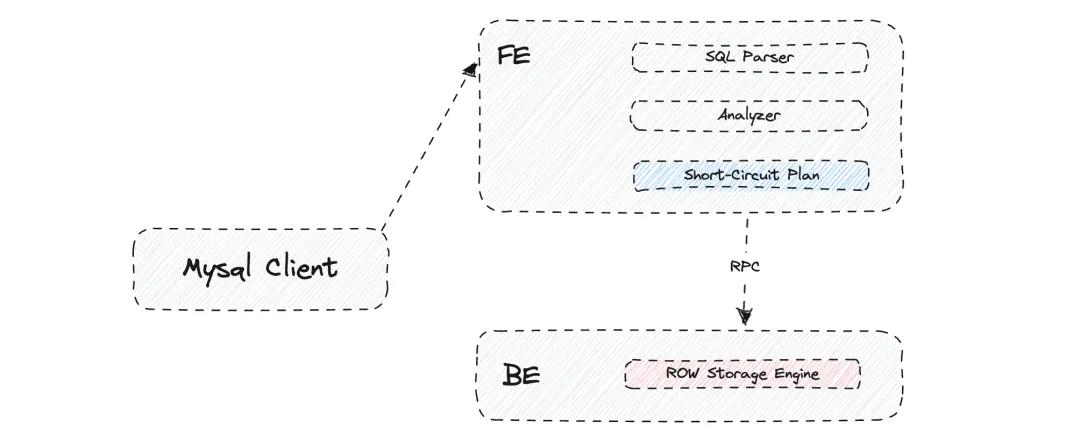
通常而言,一个查询会在 FE 端进行SQL语句解析、生成执行计划后下发到 BE 进行计算获取结果。但对于高并发点查场景,则不适合这个长流程。
因此,Apache Doris 实现了点查询的短路径优化。当FE接收到此类查询时,会在规划器中生成轻量级的 Short-Circuit Plan,避免生成复杂的 Fragment Plan 并消除了在 MPP 查询框架下执行调度的性能开销。
- 预处理语句优化(Prepared Statement)
高并发查询中的 CPU 开销可以部分归因于 FE 层分析和解析 SQL 的 CPU 计算,为了解决这个问题,Apache Doris 在 FE 端提供了与 MySQL 协议完全兼容的预处理语句(Prepared Statement)。
通过在 Session 内存 HashMap 中缓存预先计算好的 SQL 和表达式,在后续查询时直接复用缓存对象,避免这些结构在序列化和反序列化时造成CPU热点。
基于以上一系列优化,帮助 Apache Doris 在 Data Serving 场景的性能得到进一步提升。下面就来实测一把吧。
三、环境信息
- 硬件信息
- 内存:32G
- CPU:16C
- CPU架构:X86_64
- 硬盘:SSD单盘
- 节点数:1
- 软件信息
- Doris版本:2.0.3
- Manager版本:23.10.3
- Jmeter版本:5.6
- JDK版本:1.8
- Mysql Driver版本:8.0
- 系统:CentOS
四、Jmeter初始化
本文基于Jmeter进行高并发实测。
- 安装部署
非GUI使用模式。
# 官方下载包
wget https://dlcdn.apache.org/jmeter/binaries/apache-jmeter-5.6.tgz # 解压包 tar -zvf apache-jmeter-5.6.tgz
# 解压后目录结构和本地UI模式一

上传mysql-connector包到lib目录下。
- 参数说明
命令模版和参数说明,详情可阅:
https://jmeter.apache.org/usermanual/get-started.html#non_gui
jmeter -n -t <脚本文件名>.jmx -l <本不存在的结果文件名>.jtl -e -o <存放html报告的空目录> -h 帮助
-n 非GUI模式
-t 测试脚本.jmx的路径和文件名称
-l 测试结果存放的路径和文件名称 (要确保之前没有运行过,即xxx.jtl不存在,不然报错),会自动创建
-r 启动jmeter.properties文件中指定的所有远程服务器
-e 在脚本运行结束后生成html报告
-o 用于存放html报告的目录(目录要为空,不然报错),会自动创建
五、参数预调
- fe.conf
-- 每个 FE 的最大连接数,默认值:1024
qe_max_connection=10240
- be.conf
为了增加行缓存命中率,Doris单独引入了行存缓存;行缓存复用了 Doris 中的 LRU Cache 机制来保障内存的使用。
-- 是否开启行缓存, 默认不开启
disable_storage_row_cache=false
-- 指定 Row cache 占用内存的百分比, 默认 20% 内存
row_cache_mem_limit=40%
- 表属性
建表时调整即可。
-- 必须为Unique Key表
-- 开启行存
"store_row_column" = "true"
-- 开启mow模式
"enable_unique_key_merge_on_write" = "true"
-- 开启light
schema change: "light_schema_change" = "true"
- 会话参数
-- 查看新优化器是否开启
show variables like '%enable_nereids_planner%'; -- 非必选,jdbc链接配置 useServerPrepStmts=true时,会自动走短路径优化、即不走旧优化器
-- 如:jdbc:mysql://127.0.0.1:9030/ycsb?useServerPrepStmts=true
set global experimental_enable_nereids_planner=false;
- 用户参数
-- 查看用户连接数
SHOW PROPERTY FOR 'root' LIKE '%max_user_connections%';
-- 设置连接数
SET PROPERTY FOR 'root' 'max_user_connections' = '10000';
六、用例准备
- 测试表创建
基于Star Schema Benchmark的part零件信息表调整创建,共9个字段、2个联合Key。
CREATE TABLE `row_part` (
`p_partkey` int(11) NULL,
`p_name` varchar(69) NULL,
`p_mfgr` varchar(21) NULL,
`p_category` varchar(24) NULL,
`p_brand` varchar(30) NULL,
`p_color` varchar(36) NULL,
`p_type` varchar(78) NULL,
`p_size` int(11) NULL,
`p_container` varchar(33) NULL
) ENGINE=OLAP
Unique KEY(`p_partkey`, `p_name`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`p_partkey`, `p_name`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"light_schema_change" = "true",
"store_row_column" = "true" ,
"enable_unique_key_merge_on_write" = "true"
);
- 测试表数据生成
测试表最终为3200万数据。
-- 源表为明细模型,目标表为开启了行存、mow和light_schema_change的unique模式表
-- 通过对字段+数字等方式去重快速造数
insert into row_part -- 目标测试表
select
`p_partkey`+1,
concat(`p_name`, '1'),
`p_mfgr` ,
`p_category`,
`p_brand`,
`p_color`,
`p_type`L,
`p_size`,
`p_container`
from part; -- 源表
- 测试SQL
测试SQL如下。
select * from ssb_test.row_part
where p_partkey = ? and p_name = ?
确认是否符合高并发点查条件,即该SQL是否走短路径(当前版本需要where带上所有key才可触发)。
-- 本地client查验需要先关闭新优化器
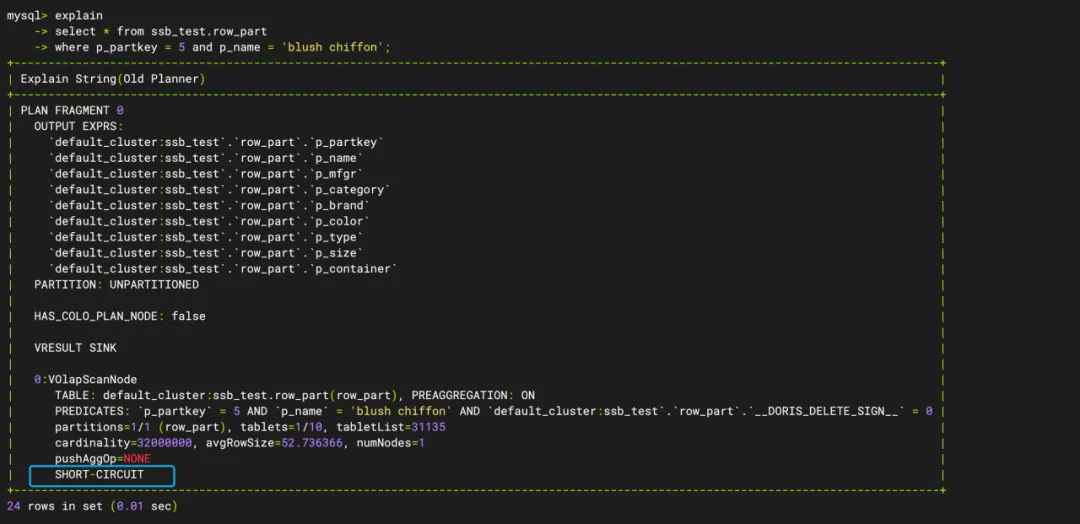
set experimental_enable_nereids_planner=false;-- ScanNode中是否有SHORT-CIRCUIT标识
explain
select * from ssb_test.row_part
where p_partkey = 5 and p_name = 'blush chiffon';
如下图所示,ScanNode中有SHORT-CIRCUIT标识,符合高并发点查条件。
- prepare参数生成
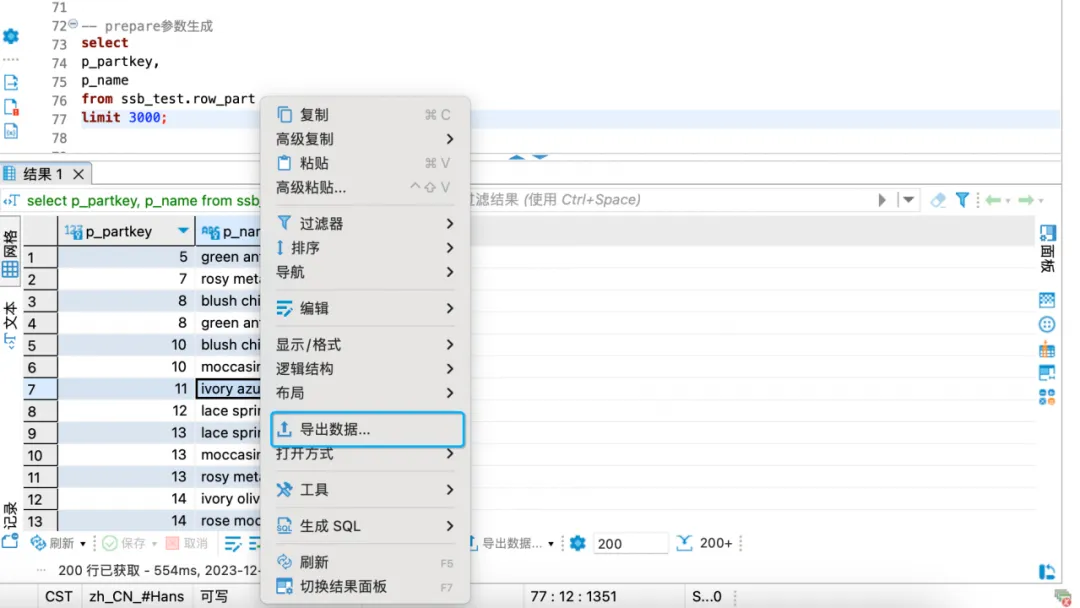
获取prepare的csv参数数据。
--
select
p_partkey,
p_name
from ssb_test.row_part
limit 3000;
导出查询结果集(通过dbeaver自身的功能导出csv数据作为prepare参数)。
导出后会在相应目录生成对应文件(需要手动去除第一行的字段名)。
上传至jmeter的home目录下。
- JMX脚本准备
可以在本地jmeter客户端配置后保存生成.jmx再上传至jmeter的home目录下。
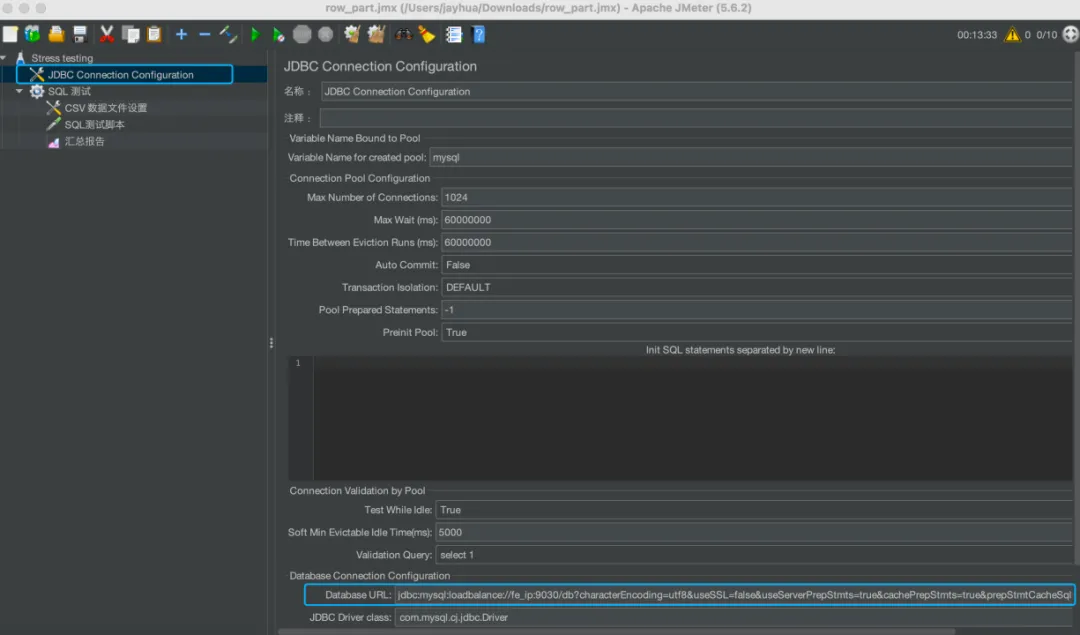
① JDBC连接管理器
jdbc:mysql:loadbalance://fe_ip:9030/db?characterEncoding=utf8&useSSL=false&useServerPrepStmts=true;cachePrepStmts=true&prepStmtCacheSqlLimit=1024
直接影响效率的参数:
- useServerPrepStmts = true
- cachePrepStmts = true
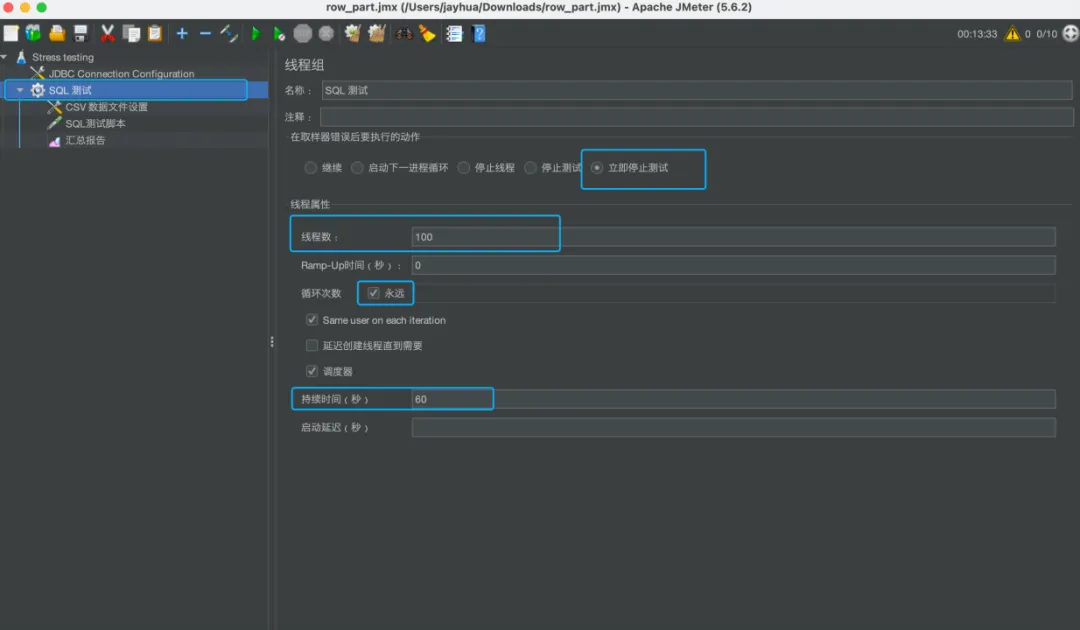
② 线程组
主要用于控制压测的循环测试、线程数和压测时间等;本文默认设置的是100线程数压60秒。
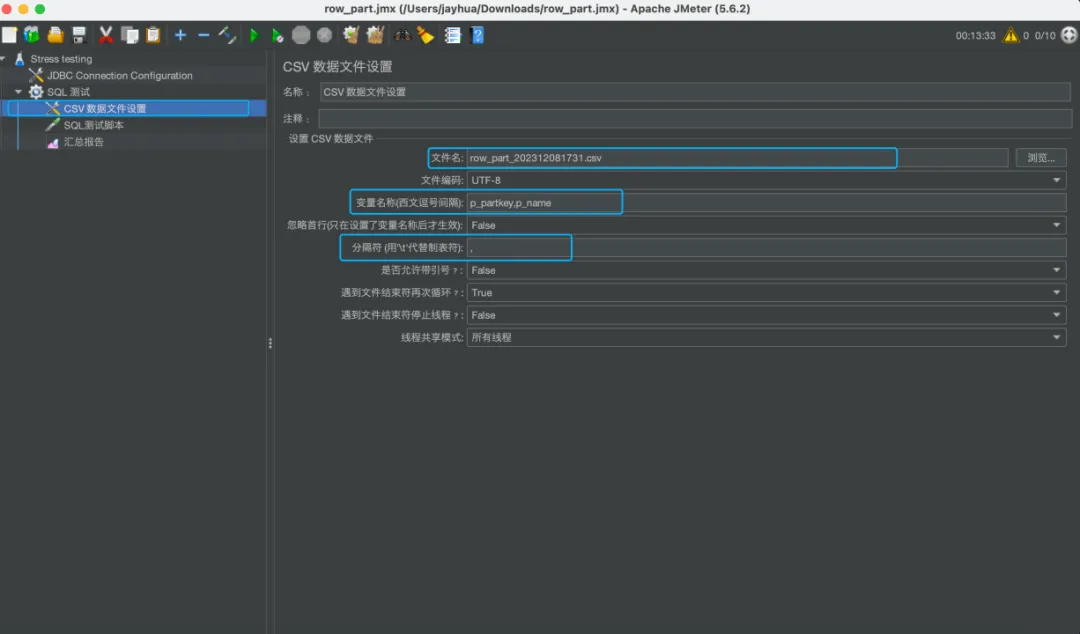
③ CSV数据文件设置
需要注意文件名、即对应 [prepare参数生成] 的csv文件存放路径, 以及csv列对应的字段名称和分隔符的填写。
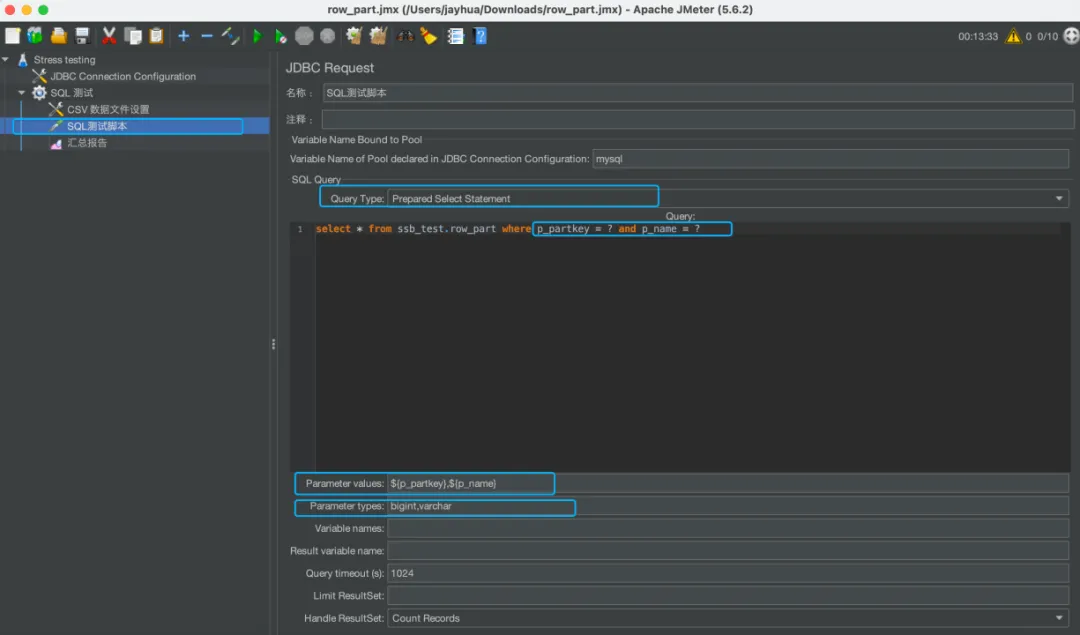
④ SQL测试脚本
选择Prepare模式随机传参,其中[Parameter values]和[Parameter types]需要和SQL中的[?]缺省值完全对齐。
七、高并发实测
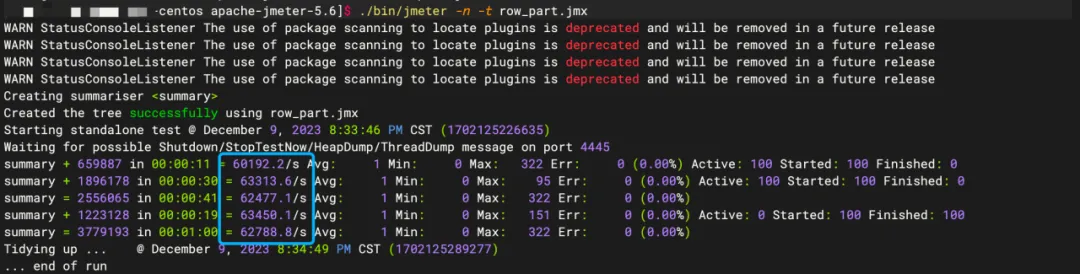
Jmeter执行脚本(简易模式)。
./bin/jmeter -n -t row_part.jmx
最终随机压测结果的平均QPS为6W+/S。
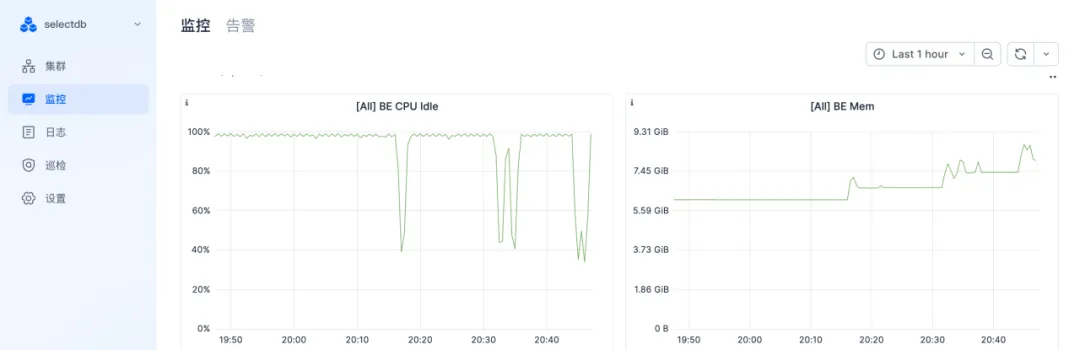
压测过程中,BE的CPU大致使用50%(其中包括Jmeter进程的),内存使用率较低。
八、影响因素
- 常规配置
- 未按【参数预调】进行调整
- 未按【JMX脚本准备】进行合理设置
- 数据分区分桶太大(并行度过高)或太小(并发过小)都会影响效率
- jdbc参数
仅去除 jdbc url 中的useServerPrepStmts=true; 参数时降为3W+/S。
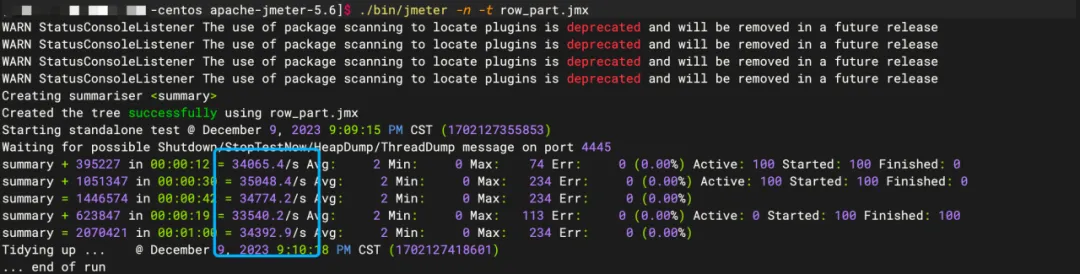
仅去除 jdbc url 中的cachePrepStmts=true; 参数时降为2W/S。
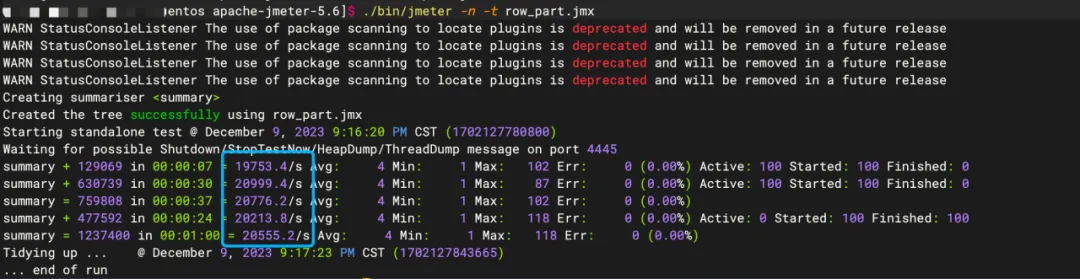
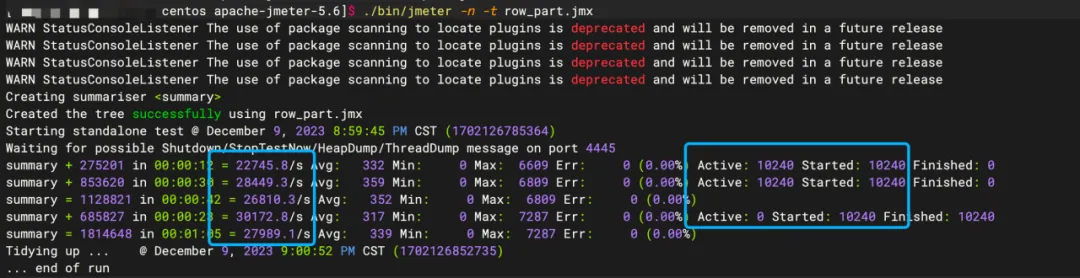
- 线程数
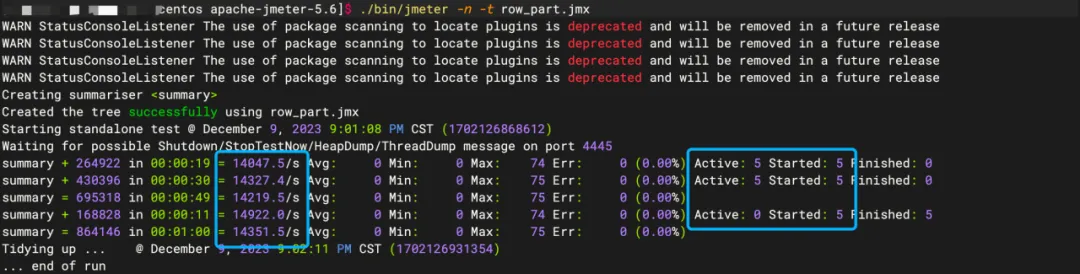
不宜过高,例如> 1W线程数时,降为2W+/S。
不宜过少,例如5个线程数时,降为1W+/S。
具体线程数设置需要根据【环境信息】进行对比调整。
- fe个数
合理范围内,1个fe可提高一定的并发量。如果多加fe、QPS都没有增长,需要定位是否存在其它影响因素。
- prepare参数分布
【prepare参数生成】过于集中、可能导致集中查某几台be影响效率,需要足够分散。
- 资源瓶颈
如果上述原因都符合预期,且CPU还相对空闲的情况下,QPS依旧无法提升,需要排查网络或IO等资源是否遇到了瓶颈。
- 其它
欢迎各位看官补充。
九、总结
Apache Doris 基于MPP架构、列存、分区分桶、向量化引擎、索引视图和基准优化等方面实现了高性能并发查询。在此基础上引入了行存、短查询路径和Prepared Statement特性实现了高并发点查询,效果俱佳。如果有相关场景的同学,欢迎实测交流。
至此,【Apache Doris】如何实现高并发点查 分享结束,查阅过程中若遇到问题欢迎留言交流。
相关文章:
【Apache Doris】如何实现高并发点查?(原理+实践全析)
【Apache Doris】如何实现高并发点查?(原理实践全析) 一、背景说明二、原理介绍三、环境信息四、Jmeter初始化五、参数预调六、用例准备七、高并发实测八、影响因素九、总结 本文主要分享 Apache Doris 是如何实现高并发点查的,以…...

解决SpringMVC使用MyBatis-Plus自定义MyBaits拦截器不生效的问题
自定义MyBatis拦截器 如果是SpringBoot项目引入Component注解就生效了,但是SpringMVC不行 import lombok.extern.slf4j.Slf4j; import org.apache.ibatis.executor.parameter.ParameterHandler; import org.apache.ibatis.executor.statement.StatementHandler; i…...
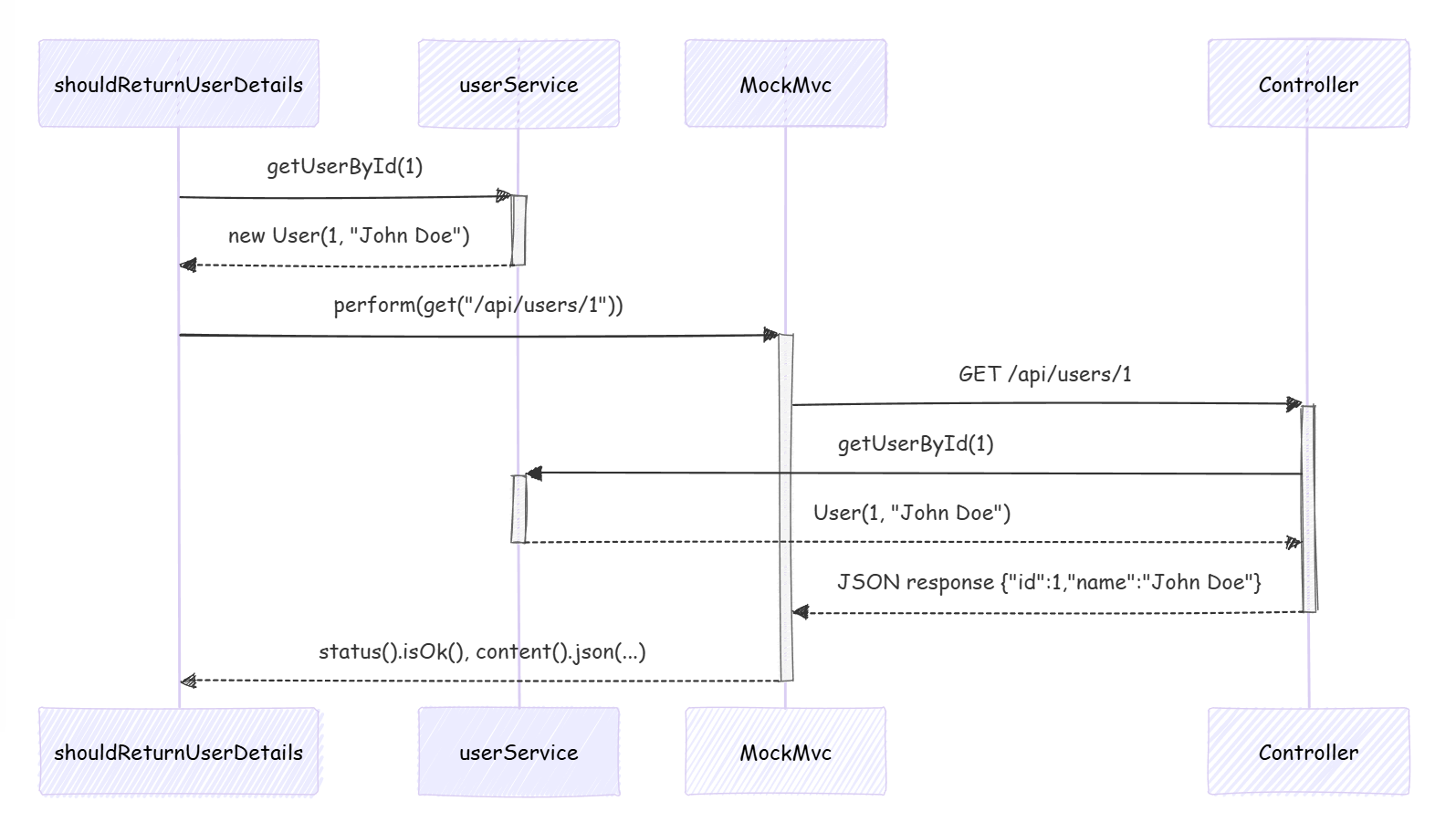
Swagger与RESTful API
1. Swagger简介 在现代软件开发中,RESTful API已成为应用程序间通信的一个标准。这种架构风格通过使用标准的HTTP方法来执行网络上的操作,简化了不同系统之间的交互。API(应用程序编程接口)允许不同的软件系统以一种预定义的方式…...
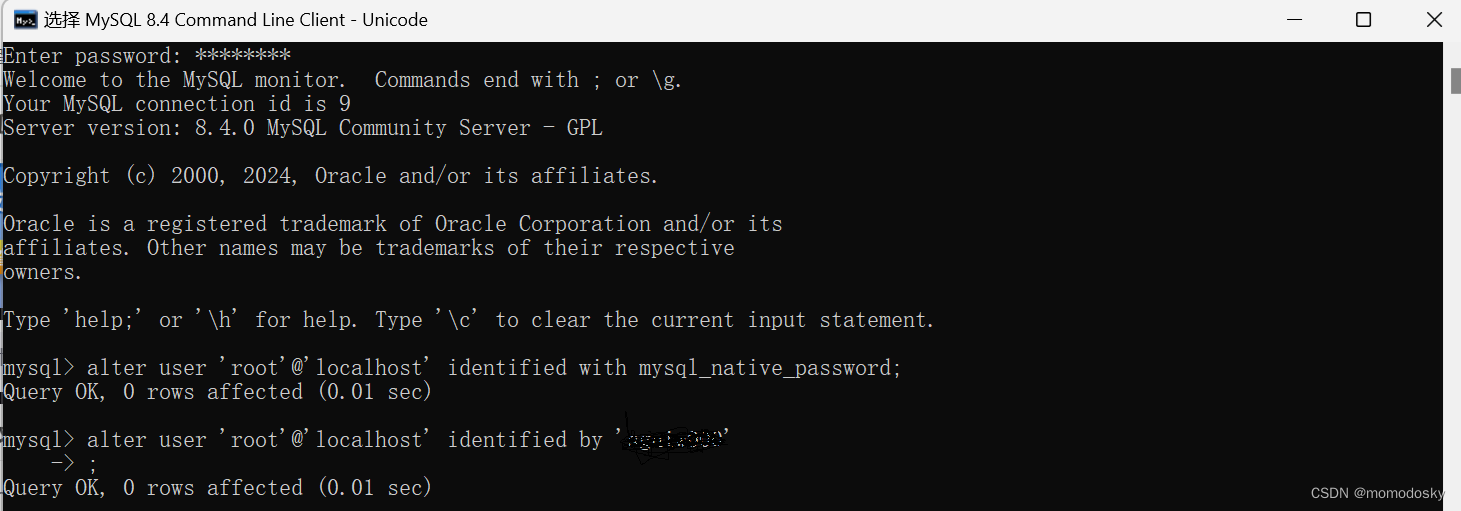
MySQL84 -- ERROR 1524 (HY000): Plugin ‘msql_native_password‘ is not loaded.
【问题描述】 MySQL 8.4版本,配置用户使用mysql_native_password认证插件验证用户身份,报错: 【解决方法】(Windows, MySQL 8.4) 1、修改MySQL配置文件my.ini,在[mysqld]段添加mysql_native_passwordON。 2、管理员…...

将Excel中的错误值#N/A替换成心仪的字符串,瞬间爱了……
常用表格的人都晓得,看到满屏悦动的#N/A,心情都会不好。把它替换成自己心仪的字符,瞬间就爱了。 (笔记模板由python脚本于2024年06月13日 19:32:37创建,本篇笔记适合常用Excel,喜欢数据的coder翻阅) 【学习的细节是欢悦…...

AI大模型日报#0628:谷歌开源9B 27B版Gemma2、AI首次实时生成视频、讯飞星火4.0发布
导读:AI大模型日报,爬虫LLM自动生成,一文览尽每日AI大模型要点资讯!目前采用“文心一言”(ERNIE-4.0-8K-latest)生成了今日要点以及每条资讯的摘要。欢迎阅读!《AI大模型日报》今日要点…...
)
【随笔】提高代码学习水平(以更高的视角看事物)
最近,我感觉到自己的代码水平似乎卡在了一个瓶颈。似乎只想着数仓,Hive,Spark技术优化,但只要稍微离开这几个点,我就感到无所适从。我开始反思,或许,我应该总结一下自己的学习方法。 1.站的高&…...
游戏AI的创造思路-技术基础-深度学习(5)
继续深度学习技术的探讨,填坑不断,头秃不断~~~~~ 目录 3.5. 自编码器(AE) 3.5.1. 定义 3.5.2. 形成过程 3.5.3. 运行原理 3.5.3.1.运行原理及基本框架 3.5.3.2. 示例代码 3.5.4. 优缺点 3.5.5. 存在的问题和解决方法 3.5…...
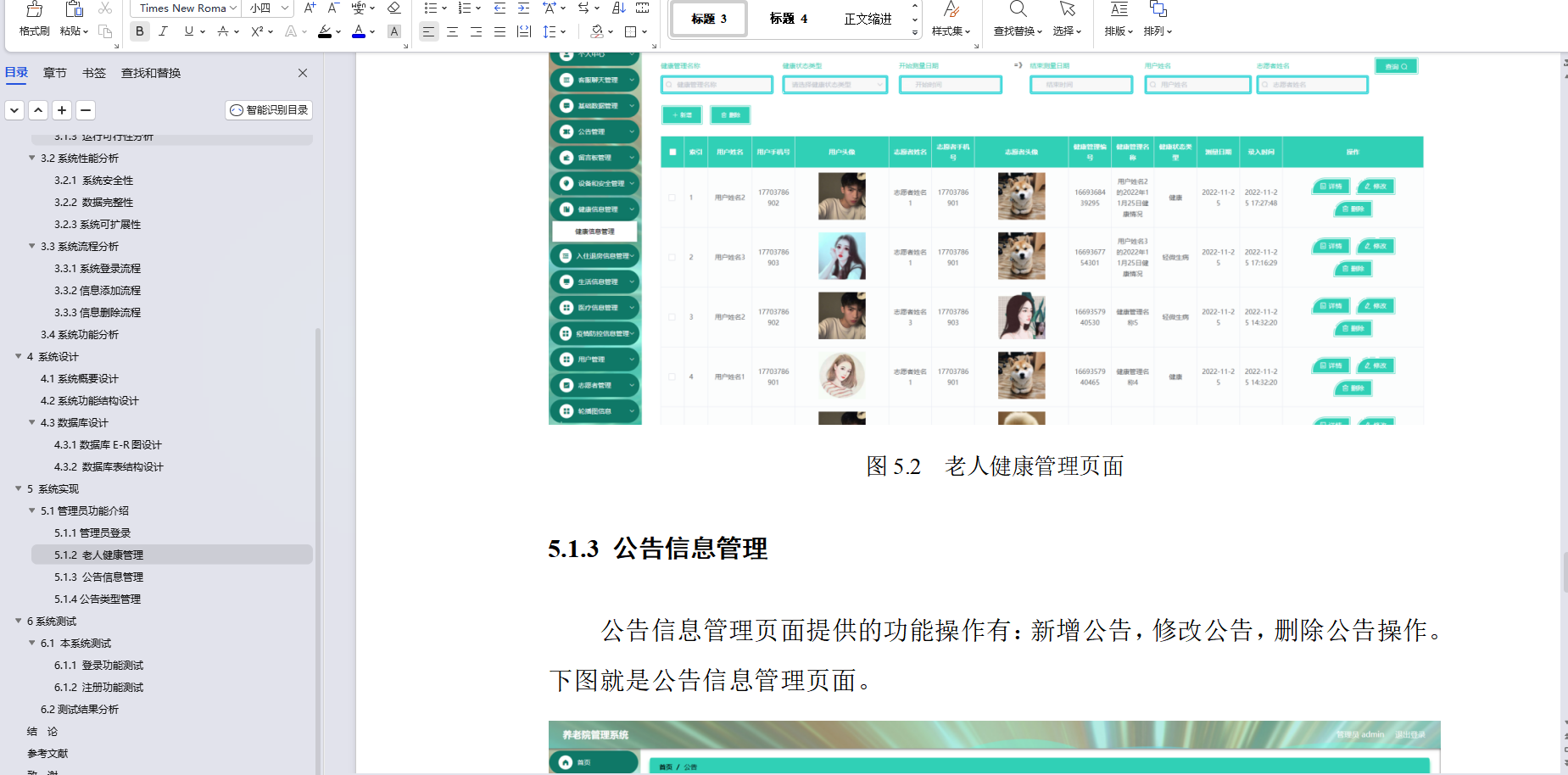
基于SpringBoot养老院管理系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟感兴趣的可以先收藏起来,还…...

餐饮点餐的简单MySQL集合
ER图 模型图(没有进行排序,混乱) DDL和DML /* Navicat MySQL Data TransferSource Server : Mylink Source Server Version : 50726 Source Host : localhost:3306 Source Database : schooldbTarget Server Type …...

STM32驱动-ads1112
汇总一系列AD/DA的驱动程序 ads1112.c #include "ads1112.h" #include "common.h"void AD5726_Init(void) {GPIO_InitTypeDef GPIO_InitStructure;RCC_APB2PeriphClockCmd( RCC_APB2Periph_GPIOA | RCC_APB2Periph_GPIOC, ENABLE );//PORTA、D时钟使能 G…...

数据结构与算法高频面试题
初级面试题及详细解答 当涉及到数据结构与算法的初级面试题时,通常涉及基本的数据结构操作、算法复杂度分析和基本算法的应用。 1. 什么是数组?数组和链表有什么区别? 解答: 数组:是一种线性数据结构,用…...

uni-app的showModal提示框,进行删除的二次确认,可自定义确定或取消操作
实现效果: 此处为删除的二次确认示例,点击删除按钮时出现该提示,该提示写在js script中。 实现方式: 通过uni.showModal进行提示,success为确认状态下的操作自定义,此处调用后端接口进行了删除操作&#…...
5款提高工作效率的免费工具推荐
SimpleTex SimpleTex是一款用于创建和编辑LaTeX公式的简单工具。它能够识别图片中的复杂公式并将其转换为可编辑的数据格式。该软件提供了一个直观的界面,用户可以在编辑LaTeX代码的同时实时预览公式的效果,无需额外的编译步骤。此外,SimpleT…...

区块链的技术架构:节点、网络和数据结构
区块链技术听起来很高大上,但其实它的核心架构并不难理解。今天我们就用一些简单的例子和有趣的比喻,来聊聊区块链的技术架构:节点、网络和数据结构。 节点:区块链的“细胞” 想象一下,区块链就像是一个大型的组织&a…...

pdfmake不能设置表格边框颜色?
找到pdfmake>build>pdfmake.js中: 找到定义的“TableProcessor.prototype.drawVerticalLine”和“TableProcessor.prototype.drawHorizontalLine”两个方法: 重新定义borderColor: var borderColor this.tableNode.table.borderColor||"#…...

laravel 使用RabbitMQ作为消息中间件
先搞定环境,安装amqp扩展 确保已安装rabbitmq-c-dev。 比如 可以使用apk add rabbmit-c-dev安装 cd ~ wget http://pecl.php.net/get/amqp-1.10.2.tgz tar -zxf amqp-1.10.2.tgz cd amqp-1.10.2 phpize ./configure make && make install cd ~ rm -rf am…...
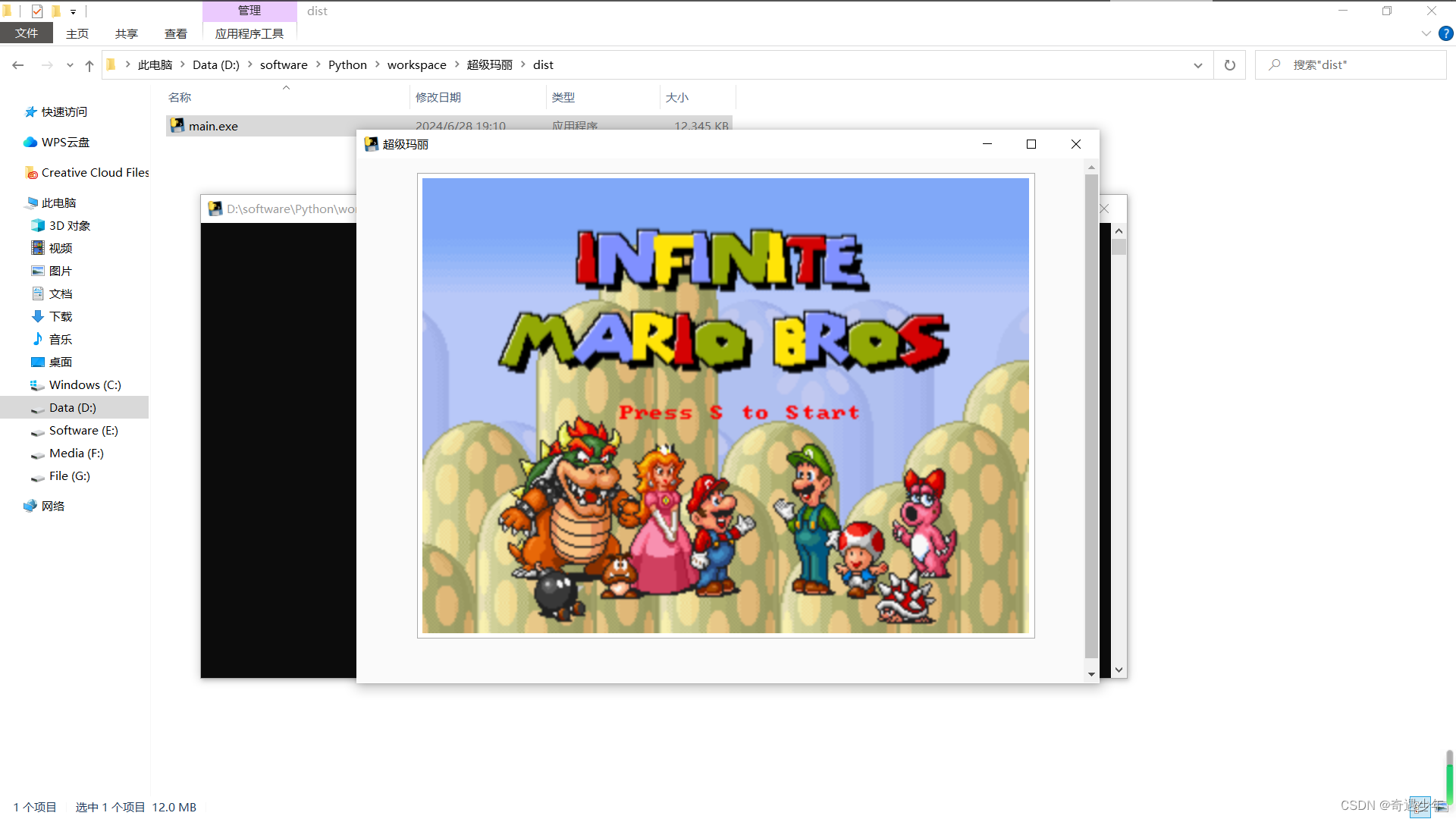
web项目打包成可以离线跑的exe软件
目录 引言打开PyCharm安装依赖创建 Web 应用运行应用程序打包成可执行文件结语注意事项 引言 在开发桌面应用程序时,我们经常需要将网页集成到应用程序中。Python 提供了多种方法来实现这一目标,其中 pywebview 是一个轻量级的库,它允许我们…...
BFS:队列+树的宽搜
一、二叉树的层序遍历 . - 力扣(LeetCode) 该题的层序遍历和以往不同的是需要一层一层去遍历,每一次while循环都要知道在队列中节点的个数,然后用一个for循环将该层节点走完了再走下一层 class Solution { public:vector<vec…...
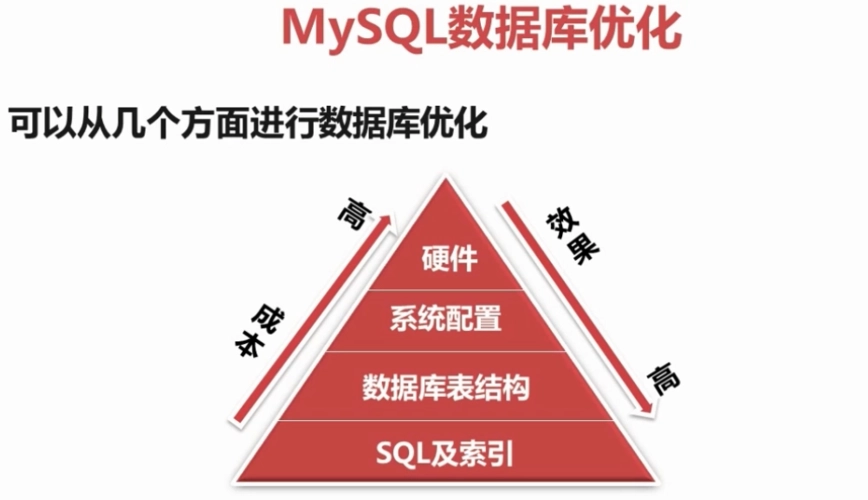
MySQL高级-SQL优化- count 优化 - 尽量使用count(*)
文章目录 1、count 优化2、count的几种用法3、count(*)4、count(id)5、count(profession)6、count(null)7、 count(1) 1、count 优化 MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高&a…...

Andorid下给PDF盖骑缝章的方法—安卓手机批量盖骑缝章的方法
Andorid下给PDF盖骑缝章的方法,安卓手机批量盖骑缝章的方法。一、准备印章图片1。不需要制作为透明的印章,用白底Png格式图片即可,白底图片盖章时软件会自动透明并融合。2。印章边线与图片四边不要有空隙,如下:错误的&…...

Swarmocracy:基于蜂群智能的分布式组织决策模拟实践
1. 项目概述:当开源项目遇上“蜂群民主”最近在开源社区里闲逛,发现一个挺有意思的项目,叫“Swarmocracy”。光看名字,就能嗅到一股混合了技术极客与组织社会学的味道——“Swarm”(蜂群)加上“-cracy”&am…...
搜索插入位置、搜索二维矩阵、查找数组相同的所有位置、搜索旋转排序数组、旋转升序数组的最小值)
【LeetCode 手撕算法】(二分查找)搜索插入位置、搜索二维矩阵、查找数组相同的所有位置、搜索旋转排序数组、旋转升序数组的最小值
复杂度为O(log n)且有序用二分查找35-搜索插入位置思路:二分查找,左右指针 求中间值注意:while的查询条件是>class Solution {public int searchInsert(int[] nums, int target) {int left0;int rightnums.length-1;while(left<right){…...
)
Unity游戏逆向第一步:手把手教你从APK里提取Assembly-CSharp.dll(附ILSpy使用指南)
Unity游戏逆向实战:从APK提取C#脚本的完整指南 在移动游戏开发领域,Unity引擎凭借其跨平台特性占据了重要地位。对于开发者而言,了解Unity打包后的文件结构不仅是调试的必要技能,也是学习优秀游戏设计的重要途径。本文将详细介绍如…...

如何5分钟搞定GitHub界面中文化:新手必看的浏览器插件终极指南
如何5分钟搞定GitHub界面中文化:新手必看的浏览器插件终极指南 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 还在为GitH…...

FPGA仿真避坑指南:从HDLbits的5道Verification题里,我总结出了3个新手最易踩的时序错误
FPGA仿真避坑指南:从HDLbits实战中提炼的3个关键时序陷阱 第一次在Modelsim里看到仿真波形完全不符合预期时,我盯着屏幕发了半小时呆。时钟边沿对不齐、信号延迟莫名其妙、仿真突然卡住不动——这些场景对FPGA新手来说就像走进雷区。HDLbits的Verificati…...
)
别再死记硬背了!用这三个等效模型,轻松搞定二极管电路分析(附典型例题)
二极管电路分析的三大等效模型实战指南 在电子工程和嵌入式开发领域,二极管作为基础元件却常常成为初学者的"拦路虎"。面对复杂的二极管电路,很多人陷入死记硬背的困境——记住各种电路的输出结果,却无法理解背后的分析逻辑。这种学…...

ReAct不是格式游戏!揭秘让LLM从“文本生成器”变身“决策引擎”的底层逻辑
文章指出,ReAct常被误解为高级Prompt工程,但核心是闭环执行架构。真正的ReAct强调“决策-执行-反馈”循环,而非固定的Thought/Action/Observation格式。工程代码定义流程,模型生成内容,实现真实工具调用与反馈闭环。文…...

一键解决!VisualCppRedist AIO彻底告别Windows DLL错误困扰
一键解决!VisualCppRedist AIO彻底告别Windows DLL错误困扰 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还记得那个令人抓狂的时刻吗?…...

WindowResizer:突破Windows窗口限制的精准尺寸控制工具
WindowResizer:突破Windows窗口限制的精准尺寸控制工具 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 在Windows桌面环境中,应用程序窗口尺寸管理是影响工…...