如何不改变 PostgreSQL 列类型#PG培训
开发应用程序并在其背后操作数据库集群时,会遇到一个意想不到的问题是实践与理论、开发环境与生产之间的差异。这种不匹配的一个完美例子就是更改列类型。
#PG考试#postgresql培训#postgresql考试#postgresql认证
关于如何在 PostgreSQL(以及其他符合 SQL 标准的系统)中更改列类型的常规知识是:
ALTER TABLE table_name
ALTER COLUMN column_name
[SET DATA] TYPE new_data_type
这显然是语义上正确的方式,但是在适当的情况下,您可能会遇到相当不愉快的意外。

问题
让我们创建一个示例表并演示您可能观察到的孤立行为。让我们从 1000 万行开始(这实际上只是整个数据世界中的一小部分)。
-- create very simple table
CREATE TABLE sample_table (id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,label TEXT,created_at TIMESTAMP WITHOUT TIME ZONE DEFAULT NOW(),updated_at TIMESTAMP WITHOUT TIME ZONE DEFAULT NOW()
);-- populate with 10m records
INSERT INTO sample_table (label)
SELECT 'hash: ' || md5(random()::text)
FROM generate_series(1, 7000000);
我们将 id 类型从 INT 改为 BIGINT。
alter_type_demo=# ALTER TABLE sample_table ALTER COLUMN id TYPE bigint;
ALTER TABLE
Time: 21592.190 ms (00:21.592)
然后… 21 秒后,您就得到了更改。请注意,这是一个小表,其中大约有 600 MB 的数据。如果您要面对 100 倍于这个数量的情况怎么办?让我们看看幕后发生了什么。
PostgreSQL 必须做的事情
更改数据类型(以及您可能会遇到的许多其他操作)并非易事,PostgreSQL 引擎必须执行多项任务:
- 重写表是最明显的罪魁祸首。将列从 INT 更改为 BIGINT 需要为每个元组(嗯,想想行)分配 4个额外的字节。由于原始表模式需要固定数量的字节,因此集群以最有效的方式存储它们。也就是说,必须使用正确的元组大小读取和重写每一行(在我们的示例中为1000 万行)。
- 在我们的综合示例中,锁可能不是问题,但如果您在生产中使用数百或数千个并发查询执行 ALTER 命令,则您必须等待所有查询释放锁。
- 索引和约束- 如果要更改的列已编入索引或有约束,则需要重建/重新验证它们。这是额外的开销。
- 事务和预写日志是问题的另一个重要部分。为了保证持久性(ACID 中的“D”),PostgreSQL 必须在 WAL
文件中记录每个更改。这样,如果数据库崩溃,系统可以重放 WAL 文件以重建自上次检查点以来丢失的修改。
如您所见,执行一些可能被理解为常规表维护的操作涉及很多内容。修改的数据的大小、磁盘 I/O 和容量以及一般系统拥塞都会发挥作用。
但真正的问题并没有就此结束。如果我们谈论的是任何类型的严肃生产部署,你必须考虑更多的事情:
- 实时复制(包括物理和逻辑复制):这增加了额外的复杂性。对于只读副本,默认行为可确保维护同步提交以实现整个数据库集群的一致性。此设置可保证只有在所有备用副本都确认收到更改后,事务才会完成。然而,这带来了新的挑战,因为性能现在还取决于网络吞吐量(包括潜在的拥塞)以及备用节点的延迟和
I/O 性能。 - 恢复和备份是另一个需要考虑的重要领域。虽然常规备份的大小可能不会受到太大影响,但您必须考虑更改前的最后一次备份与下一次备份之间发生的所有事情,并确保时间点一致性。
- 不太常见但并非闻所未闻的可能是异步副本或逻辑复制的保留槽。生成大量更改(以及 WAL文件)可能会使性能较差(或不频繁)的复制系统落后相当长的时间。虽然这可能是可以接受的,但您需要确保源系统有足够的磁盘空间来保存 WAL文件足够长的时间
如您所见,更改列数据类型并不像看起来那么简单。当前的 CI/CD 实践通常使软件开发人员能够非常轻松地提交数据库迁移并将其推广到生产环境,但几分钟后他们就会发现自己处于生产事件之中。虽然暂存部署可能会有所帮助,但它不能保证与生产具有相同的特征(无论是由于负载水平还是资金限制)。
因此,问题在于(我会重复一遍),修改的数据量的规模、系统的整体拥塞程度、 I/O 容量以及目标表在应用程序设计中的重要性。
归根结底,这转化为完成迁移所需的总时间,以及您的企业可以或可能无法承受的独特限制。解决该问题最简单的方法是将计划维护安排在流量较低的时段并完成它。
如何安全地更改 PostgreSQL 列类型
如果您需要重写数百 GB 甚至 TB 的数据,并且无法承受超过最低限度的停机时间,该怎么办?让我们探索如何正确更改列类型。
让我们先从坏消息开始——你无法避免重写整个表,这将在此过程中生成大量 WAL 文件。这是必然的,你必须计划如何管理它。
好消息:您可以将潜在的停机时间分散到比处理数据所需的更长的时间段。具体要求和限制将根据各个业务需求而有所不同,因此仔细规划至关重要。
完整的迁移可以概括为以下一系列步骤:
- 向目标表添加具有正确类型的新列。确保该列可以为 NULL 且没有默认值,以避免强制重写整个表1。例如,如果您需要增加ID,则order_id最终会得到新列new_order_id。
- 设置一个触发器,在有新数据进入时更新新列。这可确保迁移期间的所有新数据都将填充新列。
- 实现一个函数或逻辑,以便随着时间的推移批量将值从旧列迁移到新列。批次的大小和时间应与您的业务/环境的运营约束相一致。
- 迁移旧值:根据您的约束、数据大小和 I/O 功能,此过程可能需要数小时到数周甚至更长时间。虽然在终端会话中运行的 SQL 或PL/pgSQL 函数(考虑使用tmux)可能足以完成较短的迁移,但更长的迁移可能需要更复杂的方法。仅此主题就可以成为单独的博客文章或指南的好主题。
- 迁移完成后,创建反映新列的约束和索引。注意潜在的锁定问题,尤其是当该字段是任何外键的一部分时。
此时,您已准备好执行切换本身。如果您可以验证所有行都已正确填充新列,那么是时候接受最困难的部分了。如果可能的话,在一个事务中或更短的计划停机时间内完成
- 删除旧列。此操作通常只会短暂锁定表。
- 删除旧列后,重命名新列。此步骤完成了大部分迁移过程。
考虑重新启动所有依赖于更改的表的应用程序是一种很好的做法,因为某些工具(ORM…我正在看你)可能会缓存 OID 并且不能很好地处理更改。
就是这样 - 但事实并非如此。删除列只会删除引用,数据本身将物理保留在磁盘上。这是您可能需要执行的场景VACUUM FULL- 这可能会锁定表并完全重写它 - 可能会破坏并发迁移的目的。这让我们回到了促使我撰写本指南的原始文章 - [[The Bloat Busters:pg_repack vs pg_squeeze]] 是必经之路。强烈建议提前准备并熟悉这些工具。
结论
虽然更改 PostgreSQL 中的列类型可能像发出 ALTER TABLE 命令一样简单,但对于所有参与其中的人来说,了解与之相关的复杂性非常重要。无论您是请求更改的软件开发人员、审核人员,还是在没有仔细规划的情况下将此类更改部署到生产环境时负责解决事件的个人,深入了解此过程都至关重要。此外,掌握这一特定变化使您能够轻松地将洞察力投射到其他可能代价高昂的操作上。
相关文章:
如何不改变 PostgreSQL 列类型#PG培训
开发应用程序并在其背后操作数据库集群时,会遇到一个意想不到的问题是实践与理论、开发环境与生产之间的差异。这种不匹配的一个完美例子就是更改列类型。 #PG考试#postgresql培训#postgresql考试#postgresql认证 关于如何在 PostgreSQL(以及其他符合 SQ…...

RocketMQ快速入门:事务消息原理及实现(十)
目录 0. 引言1. 原理2. 事务消息的实现2.1 java client实现(适用于spring框架)2.2 springboot实现 3. 总结 0. 引言 rocketmq 的一大特性就是支持事务性消息,这在诸多场景中有所应用。在之前的文章中我们已经讲解过事务消息的使用࿰…...
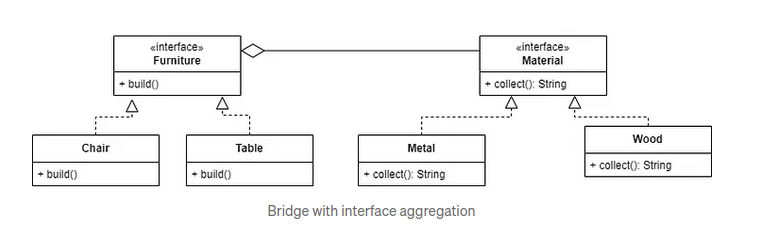
Kotlin设计模式:深入理解桥接模式
Kotlin设计模式:深入理解桥接模式 在软件开发中,随着系统需求的不断增长和变化,类的职责可能会变得越来越复杂,导致代码难以维护和扩展。桥接模式(Bridge Pattern)是一种结构型设计模式,它通过…...
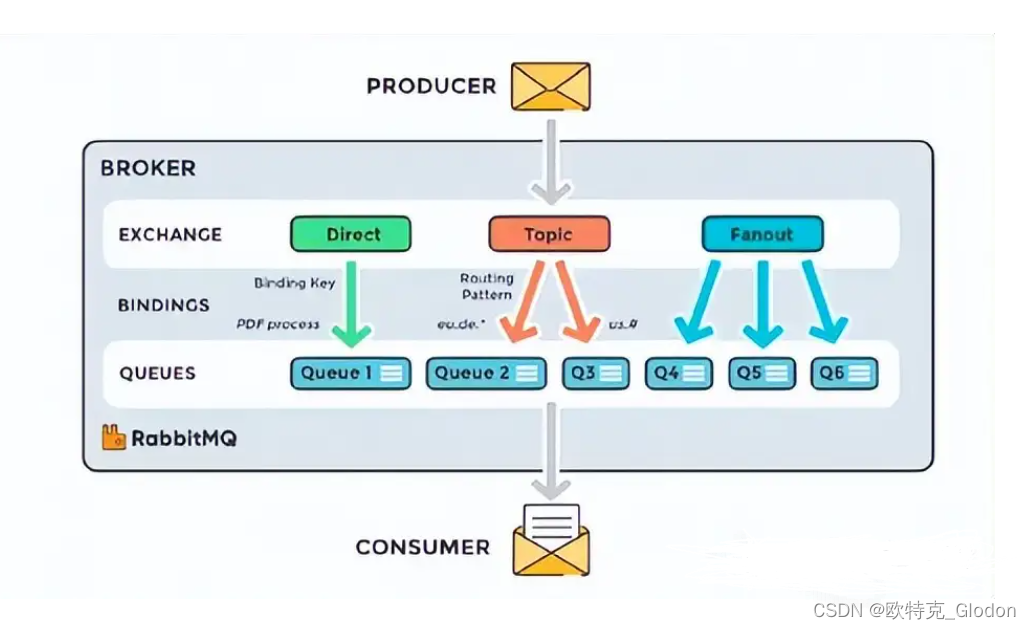
常用MQ消息中间件Kafka、ZeroMQ和RabbitMQ对比及RabbitMQ详解
1、概述 在现代的分布式系统和实时数据处理领域,消息中间件扮演着关键的角色,用于解决应用程序之间的通信和数据传递的挑战。在众多的消息中间件解决方案中,Kafka、ZeroMQ和RabbitMQ 是备受关注和广泛应用的代表性系统。它们各自具有独特的特…...
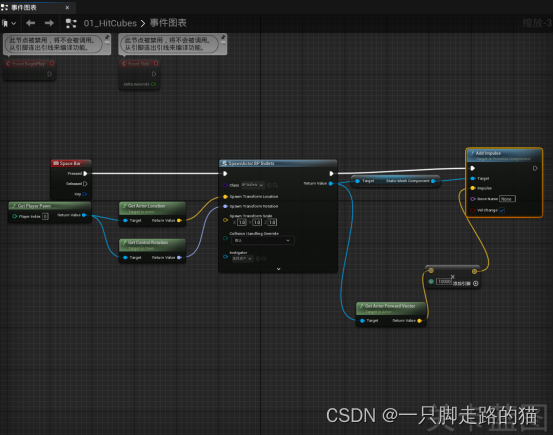
【UE5.3】笔记6-第一个简单小游戏
打砖块小游戏: 1、制造一面砖块组成的墙 在关卡中放置一个cube,放这地面上,将其转换成蓝图类,改名BP_Cube,更换砖块的贴图,按住alt键进行拷贝,堆出一面墙,复制出来的会很多,全选移动…...

LeetCode---402周赛
题目列表 3184. 构成整天的下标对数目 I 3185. 构成整天的下标对数目 II 3186. 施咒的最大总伤害 3187. 数组中的峰值 一、构成整天的下标对数目 I & II 可以直接二重for循环暴力遍历出所有的下标对,然后统计符合条件的下标对数目返回。代码如下 class So…...

循环冗余校验
循环冗余校验(Cyclic Redundancy Check,简称CRC)是一种广泛使用的错误检测编码技术,用于检测数据在传输或存储过程中是否发生错误。CRC通过在数据后面添加一个校验值(通常称为CRC码或CRC校验和)来实现错误检…...

resample sensor
resample sensor 的一个问题。 背景: 项目要求,发送多个数据到 sensor-hal 上去,发现无论怎样,在 sensor-hal 上都 只有一个数据。 resample sensor 是重新采样,这个怎么理解的,我的理解是: 假设 sensor 采…...
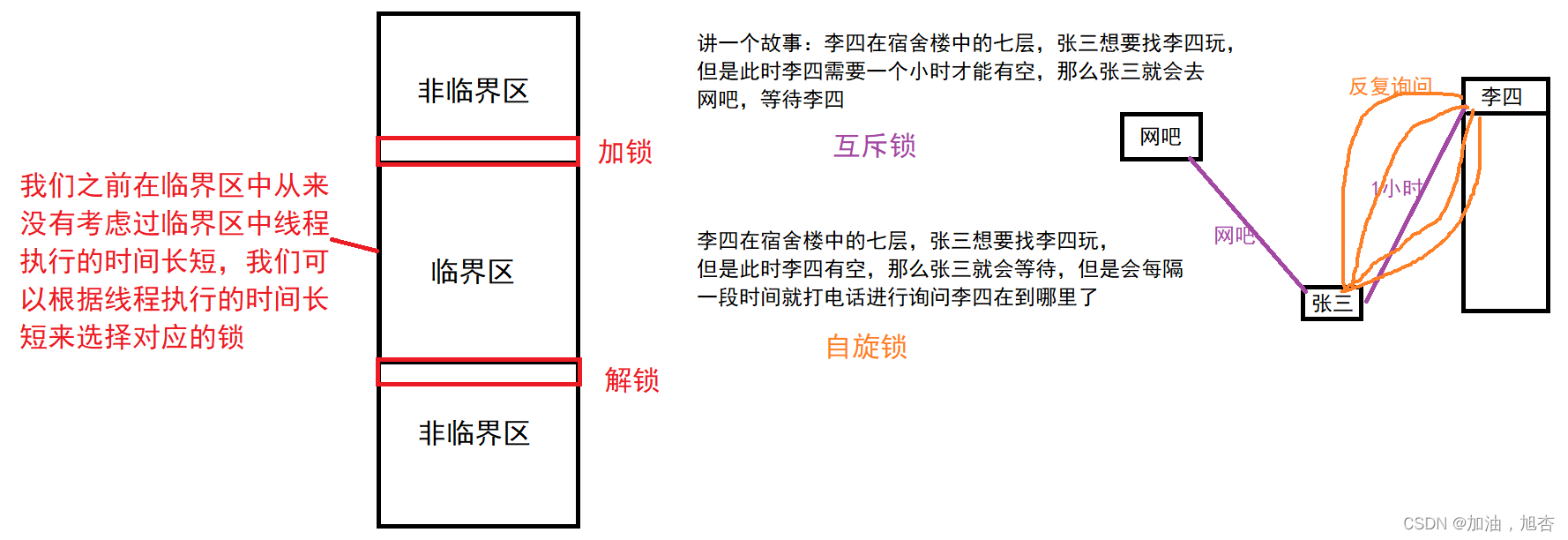
【Linux】多线程的相关知识点
一、线程安全 1.1 可重入 VS 线程安全 1.1.1 概念 线程安全:多个线程并发执行同一段代码时,不会出现不同的结果。常见对全局变量或者静态变量进行操作,并且没有锁的保护的情况下,会出现问题。重入:同一个函数被不同…...

Java反射详解
Java反射 一.什么是反射 我们使用的一些像框架,tomcat,或者一些其他的组件(jackson 对象–>json)。他们可以做到给他什么类名,就可以创建给定类的对象,并调用该对象的方法和属性。这是如何做到的? 当他们加载我们…...

Spring Boot与Apache Kafka集成的深度指南
Spring Boot与Apache Kafka集成的深度指南 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在现代分布式系统中,消息队列的作用愈发重要࿰…...

甄选版“论软件系统架构评估”,软考高级论文,系统架构设计师论文
论文真题 对于软件系统,尤其是大规模的复杂软件系统来说,软件的系统架构对于确保最终系统的质量具有十分重要的意义,不恰当的系统架构将给项目开发带来高昂的代价和难以避免的灾难。对一个系统架构进行评估,是为了:分析现有架构存在的潜在风险,检验设计中提出的质量需求,…...
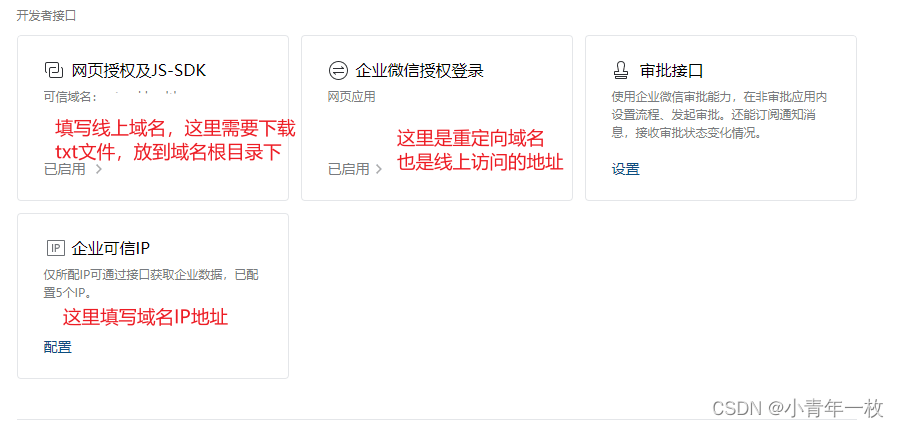
uniapp开发企业微信内部应用
最近一直忙着开发项目,终于1.0版本开发完成,抽时间自己总结下在项目开发中遇到的技术点。此次项目属于自研产品,公司扩展业务,需要在企业微信中开发内部应用。因为工作中使用的是钉钉,很少使用企业微信,对于…...

0122__linux之eventfd理解
linux之eventfd理解-CSDN博客 Linux fd 系列 — eventfd 是什么?-CSDN博客...

数学建模 —— 查找数据
目录 百度搜索技巧 完全匹配搜索:查询词的外边加上双引号“ ” 标题必含关键词:查询词前加上intitle: 搜索文档:空格再输入filetype:文件格式 去掉不想要的:查询词后面加空格后加减号与关键字 知网查文献 先看知网的硕博士…...
合并有序链表
合并有序链表 图解代码如下 图解 虽然很复杂,但能够很好的理解怎么使用链表,以及对链表的指针类理解 代码如下 Node* merge_list_two_pointer(List& list1, List& list2) {Node* new_head1 list1.head;Node* new_head2 list2.head;Node* s…...

【SpringBoot Web框架实战教程】05 Spring Boot 使用 JdbcTemplate 操作数据库
不积跬步,无以至千里;不积小流,无以成江海。大家好,我是闲鹤,微信:xxh_1459,十多年开发、架构经验,先后在华为、迅雷服役过,也在高校从事教学3年;目前已创业了…...
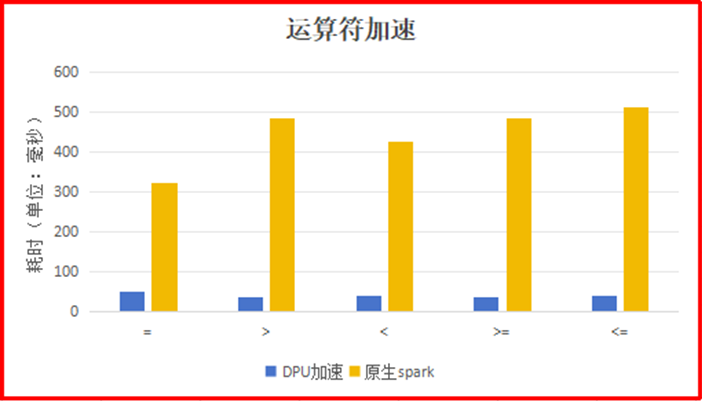
Spark基于DPU的Native引擎算子卸载方案
1.背景介绍 Apache Spark(以下简称Spark)是一个开源的分布式计算框架,由UC Berkeley AMP Lab开发,可用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习&a…...
)
Mini2440 start.s 修改支持串口输出,方便调试 (四)
经常会遇到点板子的时候,板子没有任何反应!怎么知道板子有没有在正常启动,在uboot阶段 start.s 中加入串口打印信息是很有必要的! 输出串口信息 ***UART:mini-2440-uBoot*** ***UART:mini-2440-uBoot*** ***UART:mini-2440-uBoo…...

【教程】几种不同的RBF神经网络
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com 目录 一、经典RBF神经网络1.1.经典径向基神经网络是什么1.2.经典径向基神经网络-代码与示例 二、广义回归神经网络GRNN2.1.广义回归神经网络是什么2.2.广义回归神经网络是什么-代码与示例 三、概率…...

ClawGuard:为Clawdbot AI智能体打造的安全监控与熔断防护系统
1. 项目概述:ClawGuard 是什么,以及为什么你需要它如果你正在使用或开发基于 Clawdbot 框架的 AI 智能体,那么“安全”和“可控”这两个词,大概率已经在你脑海里盘旋过无数次了。我接触过不少团队,从最初的兴奋于 AI 智…...

技术指标库 Pandas TA 详细使用手册
Pandas TA 详细使用手册:从入门到精通 一、简介与安装 Pandas TA 是一个专为金融时间序列分析打造的技术分析库,它扩展了 Pandas DataFrame,提供 130 种技术指标、60 种K线形态识别功能。它的核心优势在于与 Pandas 深度集成,让你…...

技术突破开源方案:img2latex-mathpix实现公式图像转LaTeX代码的本地化部署
技术突破开源方案:img2latex-mathpix实现公式图像转LaTeX代码的本地化部署 【免费下载链接】img2latex-mathpix Mathpix has changed their billing policy and no longer has free monthly API requests. This repo is now archived and will not receive any upda…...
)
Acrylic Paint风格在Midjourney中失效的5大隐性陷阱(附官方未公开的--s 700+--style raw协同调参公式)
更多请点击: https://intelliparadigm.com 第一章:Acrylic Paint风格在Midjourney中的本质定义与失效现象全景图 Acrylic Paint(丙烯画)风格在Midjourney中并非原生语义标签,而是一种通过视觉特征逆向建模的提示工程产…...

工程师视角:最低成本脱碳路径与气候解决方案的工程化思维
1. 项目概述:一封关于气候与经济的公开信最近在EE Times上读到一封写给埃隆马斯克的公开信,作者格伦温瑞布提出了一些关于气候变化和联邦预算赤字的想法,挺有意思的。这封信的核心不是空谈环保理念,而是从一个工程师和务实主义者的…...

数据分析实习面试准备全攻略:专业知识+项目深挖+行为面试,职卓科技的面试辅导体系
摘要数据分析实习面试通常包含三大模块:专业知识考察(SQL、Python、统计学基础)、项目深挖(业务理解、技术选择、问题解决)、行为面试(团队协作、学习能力、职业规划)。很多学员在面试中表现不佳…...

BetaClaw:开源AI代理运行时,统一多模型调用与智能成本控制
1. 项目概述:一个为开发者打造的“瑞士军刀”级AI代理运行时如果你和我一样,每天都在和不同的AI模型打交道,那你一定也经历过这种痛苦:想用Claude写点创意文案,得去Anthropic的API;想用GPT-4o分析代码&…...

国家级数据仓库构建:从爬取到应用的全流程实践指南
1. 项目概述与核心价值最近在整理一个数据项目时,我偶然发现了一个名为“national_data”的仓库,作者是Ddhjx。这个项目名听起来平平无奇,但点进去之后,我发现它远不止是一个简单的数据集合。它本质上是一个结构化的、持续更新的国…...

ROS2导航SLAM建图实战:从Gazebo仿真到真实地图构建
1. 环境准备与基础配置 第一次接触ROS2导航和SLAM建图的朋友可能会觉得配置环境很复杂,其实只要跟着步骤一步步来,半小时就能搞定。我用的是一台装了Ubuntu 20.04的笔记本,ROS2版本选择Foxy,这个组合最稳定。记得先更新系统&#…...

如何绕过Cursor Pro试用限制:技术原理与实战指南
如何绕过Cursor Pro试用限制:技术原理与实战指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial re…...