Why is Kafka fast?(Kafka性能基石)
Kafka概述
Why is kafka fast?
思考一下,当我们在讨论Kafka快的时候我们是在谈论什么呢?What does it even mean that Kafka is fast?
我们是在谈论kafka的低延迟(low latency)还是在讨论吞吐量(throughput)呢?
It is fast compared to what?
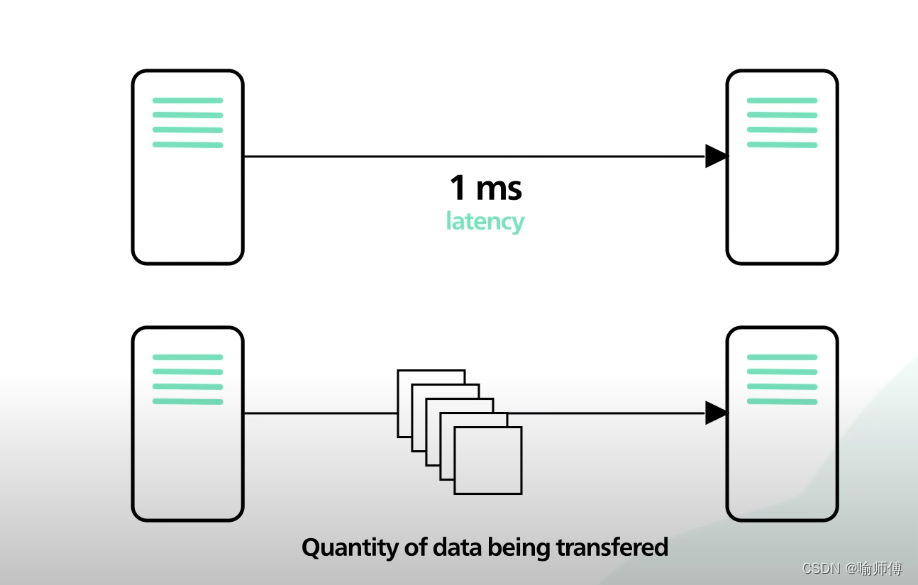
kafka is optimized for high throughput. lt is designed to move a large number of records in a short amount of time.
Kafka针对高吞吐量进行了优化。它的设计目的是在短时间内移动大量的记录。
Think of it as a very large pipe moving liquid.把Kafka想象成一个非常大的管道移动液体。

The bigger the diameter of the pipe, the largerthe volume of liquid that can move through it.
管道的直径越大,流经管道的液体体积就越大。
So when someone says Kafka is fast, they usually refer to Kafka’s ability to move a lot of data.
所以人们谈论Kafka很快的时候,他们通常指的是Kafka移动大量数据的能力。

What are some of the design decisions that help Kafka move a lot of data quickly?
那么Kafka哪些设计决策与设计细节可以实现快速移动大量数据呢?
There are many design decisions that contributed to Kafka’s performance.这里我们只关注两种最重要的设计。
1.Sequential I/O
The first one is Kafka’s reliance on sequential l/0.首先是Kafka对顺序l/0的依赖。

什么是sequential I/O呢?
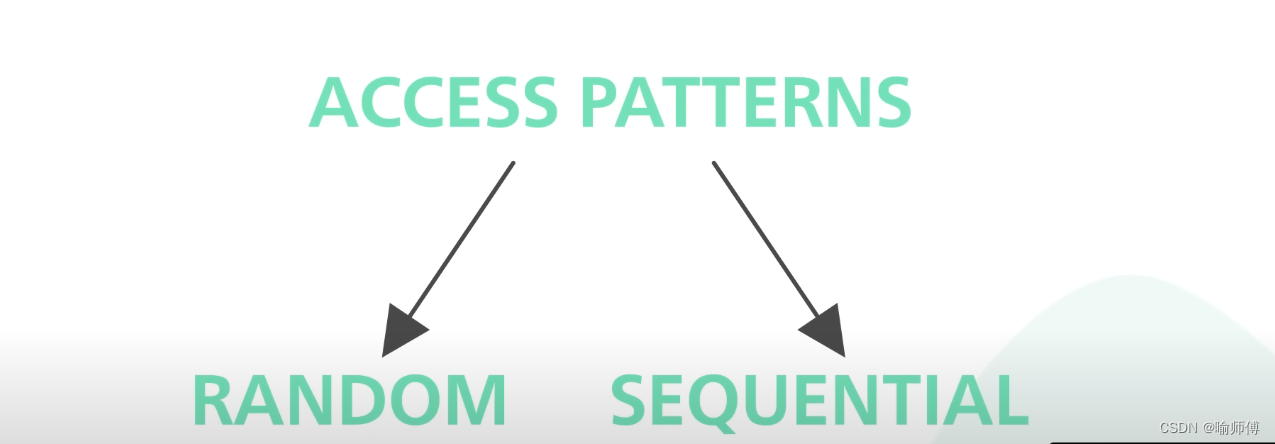
这里我们有一个常见的误区,我们常常认为磁盘访问比内存访问慢,但是其实这在很大程度上取决于数据访问模式(access pattern)。
There are two types of disk access patterns —random and sequential.
For hard drives it takes time to physically move the arm to different locations on the magnetic disks.This is what makes random access slow.
对于硬盘驱动器,它需要时间来物理移动磁头臂到磁盘上的不同位置。这就是随机访问缓慢的原因。
For sequential access, though, since your arm doesn’t need to jump around, it is much faster to read and write blocks of data oneafter the other.
对于顺序访问,由于磁头臂不需要跳转,因此依次读取和写入数据块的速度要快得多。
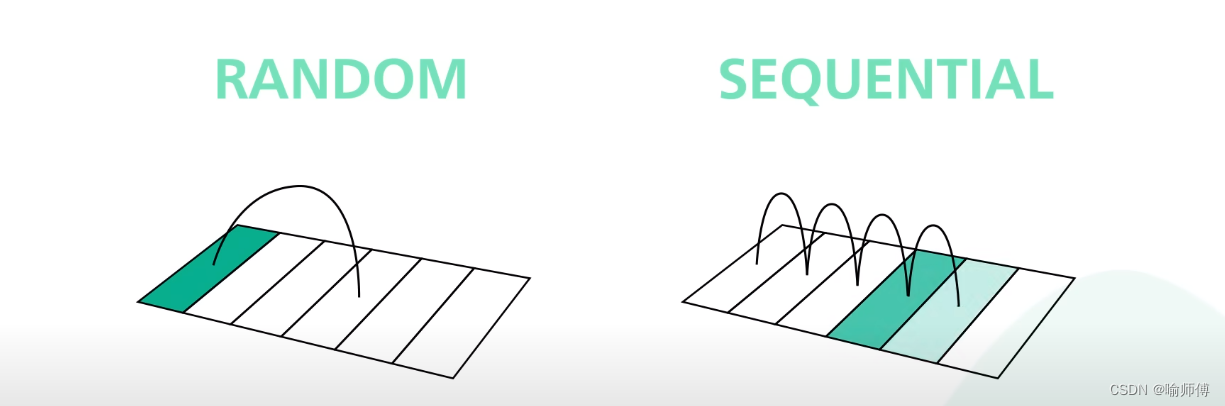
Kafka takes advantage of this by using an append-only log as its primary data structure.
Kafka使用仅追加日志作为其主要数据结构,即实现了顺序I/O模式。
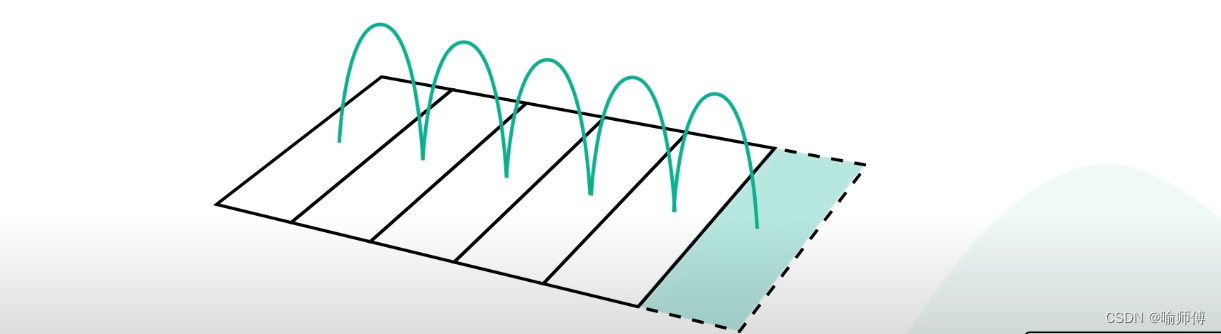
An append-only log adds new data to the end of the file.This access pattern is sequential.
仅追加日志将新数据添加到文件的末尾,这种访问模式是顺序的。
On modern hardware with an array of these hard disks, sequential writes reach hundreds of megabytes per second, while random writes aremeasured in hundreds of kilobyte per second.
在拥有这些硬盘阵列的现代硬件上,顺序写入达到每秒数百Mb字节,而随机写入只能达到每秒数百Kb字节。
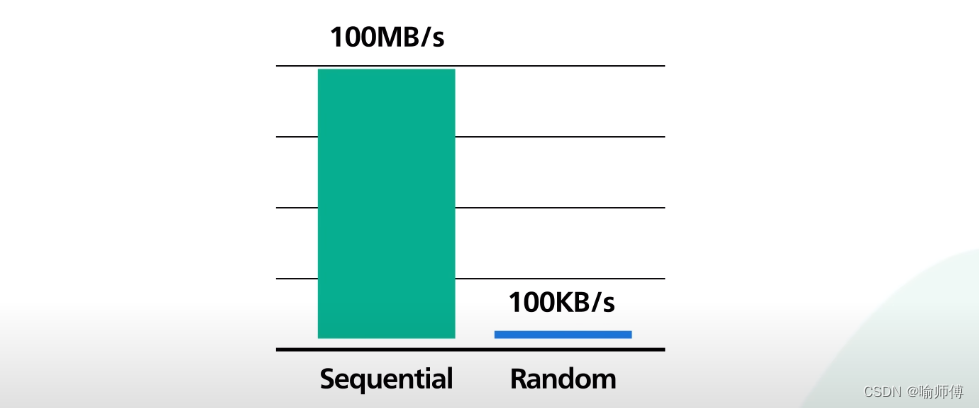
Sequential access is several order of magnitude faster. 顺序访问速度快几个数量级。
Using hard disks has its cost advantage, too. 使用硬盘也有其成本优势。

与SSD相比,硬盘的价格只有它的三分之一,但容量却是它的三倍。
Giving Kafka a large pool of cheap disk space without any performance penalty means that Kafka can cost effectively retain messages for a long period of time,a feature that was uncommon to messaging systems before Kafka.
为Kafka提供大量廉价的磁盘空间而没有任何性能损失,这意味着Kafka可以有效地长时间保留消息。
而这一点在Kafka之前的消息系统中,并不常见。

2.Zero copy principle
The second design choice that gives Kafka its performance advantage is its focus on efficiency.
Kafka moves a lot of data from network to disk, and from disk to network.
Kafka将大量数据从网络移动到磁盘,再从磁盘移动到网络。
It is critically important to eliminate excess copy when moving pages and pages of data between the disk and the network.
在磁盘和网络之间移动一页又一页的数据时,消除多余的拷贝是非常重要的。

这就是零复制原理发挥作用的地方。This is where zero copy principle comes into the picture.
现代unix操作系统经过高度优化,可以将数据从磁盘传输到网络,而不会过度复制数据。
Modern unix operating systems are highly optimized to transfer data from disk to network without copying data excessively.
首先,我们看一下Kafka是如何在零拷贝根本不使用的情况下将磁盘上的一页数据发送给消费者的。

-
1.数据从磁盘加载到操作系统缓存。
First the data is loaded from disk to the OS cache. -
2.数据从操作系统缓存复制到Kafka应用程序。
Second the data is copied from the OS cache into the Kafka application.
-
3.数据从Kafka复制到套接字缓冲区。Third the data is copied from Kafka to the socket buffer.
-
4 将数据从套接字缓冲区复制到网络接口卡缓冲区。
And fourth the data is copied from the socket buffer to the network interface card buffer. -
5.最后数据通过网络发送给消费者。And finally, the data is sent over the network to the consumer.
Now this is clearly inefficient. There are four copies and two system calls. 这显然是低效的。有四个副本和两个系统调用。
现在我们再来看一下使用零拷贝的Kafka。

第一步是一样的。数据页面从磁盘加载到操作系统缓存。
零拷贝时,Kafka应用程序使用一个名为sendfile()的系统调用来告诉操作系统直接将数据从操作系统缓存复制到网络接口卡缓冲区。
With zero copy, the Kafka application uses a system call called sendfile() to tell the operating system to directly copy the data from the OS cache to the network interface card buffer.
在这个优化的路径中,唯一的拷贝是从操作系统缓存到网卡缓冲区的。
With a modern network card, this copying is done with DMA.对于现代网卡,这种复制是通过DMA完成的。

DMA stands for direct memory access. When DMA is used the cpu is not involved, making it even more efficient.
DMA表示直接内存访问。当使用DMA时,不涉及cpu,使其更加高效。
To recap, sequential I/O and zero copy principle are the cornerstone to Kafka’s high performance.
顺序I/O和零拷贝原则是Kafka高性能的基石。
Kafka uses other techniques to squeeze every ounce of performance out of modern hardware, but
these two are the most important in our view.
Kafka使用其他技术从现代硬件中挤出每一丝性能,而在我们看来,顺序I/O、零拷贝原则这两个是最重要的。
Learned it from youtuber:ByteByteGo.
相关文章:
Why is Kafka fast?(Kafka性能基石)
Kafka概述 Why is kafka fast? 思考一下,当我们在讨论Kafka快的时候我们是在谈论什么呢?What does it even mean that Kafka is fast? 我们是在谈论kafka的低延迟(low latency)还是在讨论吞吐量(through…...

Linux下的SSH详解及Ubuntu教程
前言 SSH(Secure Shell)是一种用于计算机之间安全通信的协议,广泛应用于远程登录、系统管理和文件传输等场景。本文将详细介绍SSH在Linux系统(特别是Ubuntu)下的使用,包括安装、配置、密钥管理和常见应用&…...
MobPush HarmonyOS NEXT 版本集成指南
开发工具:DevEco Studio 集成方式:在线集成 HarmonyOS API支持:> 11 集成前准备 注册账号 使用MobSDK之前,需要先在MobTech官网注册开发者账号,并获取MobTech提供的AppKey和AppSecret,详情可以点击查…...

什么是封装?为什么要封装?
什么是封装? 封装是计算机科学中的一个重要概念,尤其在面向对象编程(OOP)中占据核心地位。封装主要指的是将数据(属性)和对这些数据的操作(方法)组合在一个单元中(我们称…...
远程桌面无法复制粘贴文件到本地怎么办?
远程桌面不能复制粘贴问题 Windows远程桌面为我们提供了随时随地访问文件和数据的便捷途径,大大提升了工作和生活的效率。然而,在使用过程中,我们也可能遇到一些问题。例如,在通过远程桌面传输文件时,常常会出现无法复…...
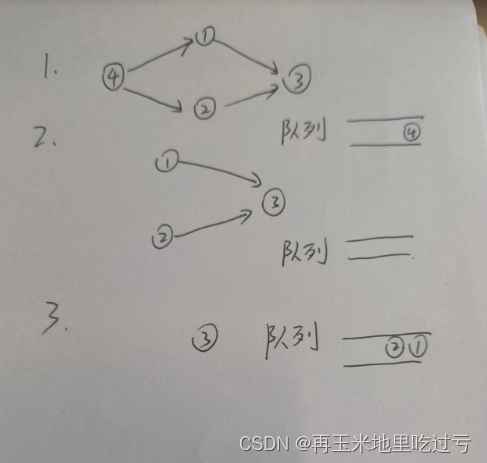
LeetCode 207. 课程表
思路:这是一道拓扑排序问题,拓扑排序听起来可能有点复杂,但实际上它是个相当直观的概念。想象一下,你有很多事情要做,但有些事情必须在另一些事情完成之后才能开始,就像你得先穿上袜子再穿鞋子 拓扑排序就…...
数据结构历年考研真题对应知识点(树的基本概念)
目录 5.1树的基本概念 5.1.2基本术语 【森林中树的数量、边数和结点数的关系(2016)】 5.1.3树的性质 【树中结点数和度数的关系的应用(2010、2016)】 【指定结点数的三叉树的最小高度分析(2022)】 5.1…...

Pytorch和Tensorflow安装【Win和Linux】
Ubuntu/win安装Pytorch和Tensorflow 说明: 这两种框架的搭建,均基于Anaconda进行搭建。先在系统中安装Anaconda软件。 一、Pytorch的搭建 windows安装 (1)搭建参考官网给的命令,pytorch官网 (2)下载地址:https://download.pytorch.org/whl/torch_stable.html 从上述…...

筑算网基石 创数智未来|锐捷网络闪耀2024 MWC上海
2024年6月26日至28日,全球科技界瞩目的GSMA世界移动大会(MWC 上海)在上海新国际博览中心(SNIEC)盛大召开。作为行业领先的网络解决方案提供商,锐捷网络以“筑算网基石 创数智未来”为主题,带来了…...

T4打卡 学习笔记
所用环境 ● 语言环境:Python3.11 ● 编译器:jupyter notebook ● 深度学习框架:TensorFlow2.16.1 ● 显卡(GPU):NVIDIA GeForce RTX 2070 设置GPU from tensorflow import keras from tensorflow.keras…...
抖音矩阵云混剪系统源码 短视频矩阵营销系统V2(全开源版)
>>>系统简述: 抖音阵营销系统多平台多账号一站式管理,一键发布作品。智能标题,关键词优化,排名查询,混剪生成原创视频,账号分组,意向客户自动采集,智能回复,多…...
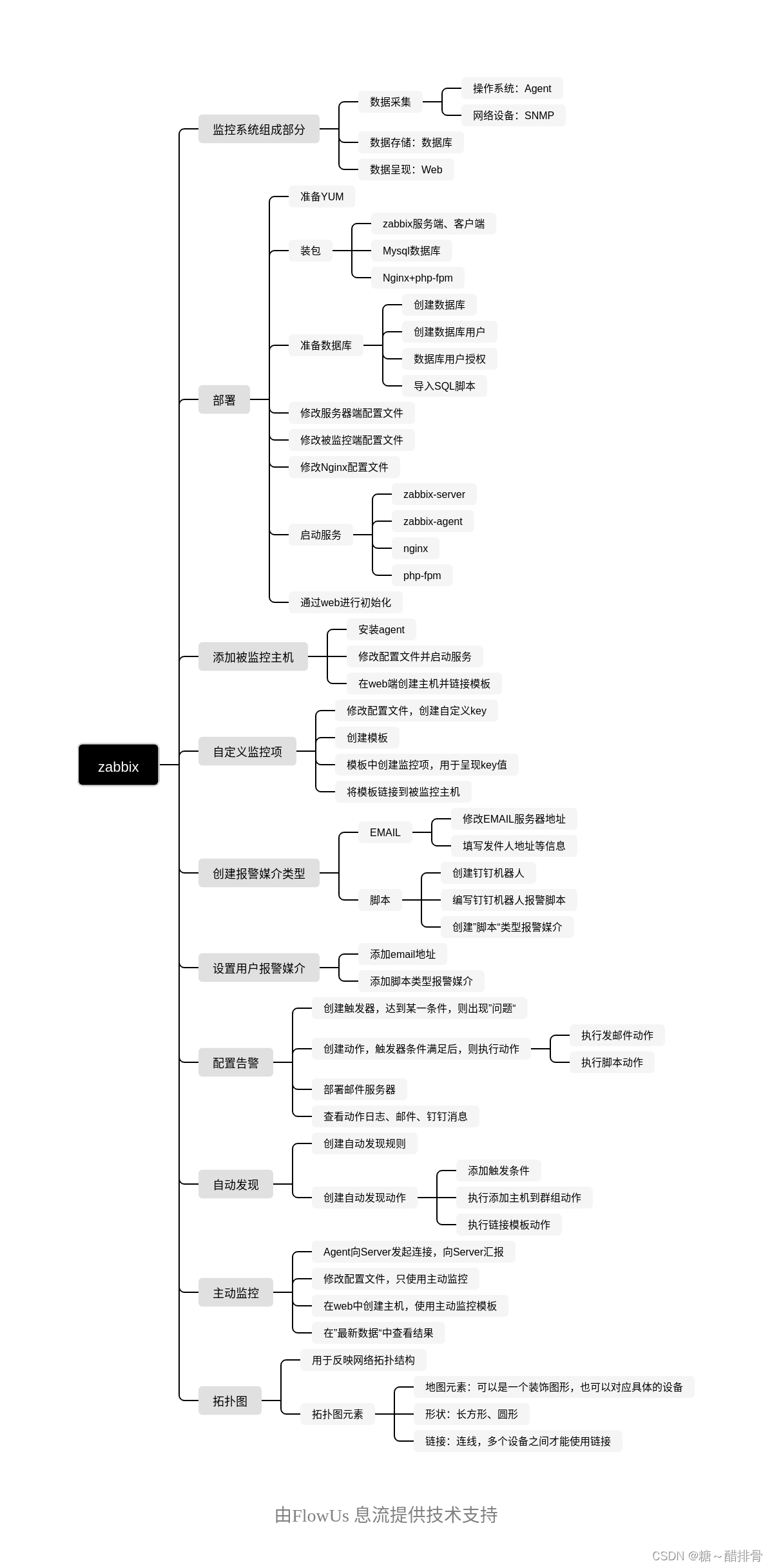
zabbix报警机制
zabbix思路流程...

【Matlab】-- 飞蛾扑火优化算法
文章目录 文章目录 01 飞蛾扑火算法介绍02 飞蛾扑火算法伪代码03 基于Matlab的部分飞蛾扑火MFO算法04 参考文献 01 飞蛾扑火算法介绍 飞蛾扑火算法(Moth-Flame Optimization,MFO)是一种基于自然界飞蛾行为的群体智能优化算法。该算法由 Sey…...

全面体验ONLYOFFICE 8.1版本桌面编辑器
ONLYOFFICE官网 在当今的数字化办公环境中,选择合适的文档处理工具对于提升工作效率和团队协作至关重要。ONLYOFFICE 8.1版本桌面编辑器,作为一款集成了多项先进功能的办公软件,为用户提供了全新的办公体验。今天,我们将深入探索…...

建议csdn赶紧将未经作者同意擅自锁住收费的文章全部解锁,别逼我用极端手段让你们就范
前两天我偶然发现csdn竟然将我以前发表的很多文章锁住向读者收费才让看。 csdn这种无耻行径往小了说是侵犯了作者的版权著作权,往大了说这是在打击我国IT领域未来的发展,因为每一个做过编程工作的人都知道,任何一个程序员的学习成长过程都少不…...

Pycharm一些问题解决办法
研究生期间遇到关于Pycharm一些问题报错以及解决办法的汇总 ModuleNotFoundError: No module named sklearn’ 安装机器学习库,需要注意报错的sklearn是scikit-learn缩写。 pip install scikit-learnPyCharm 导包提示 unresolved reference 描述:模块…...
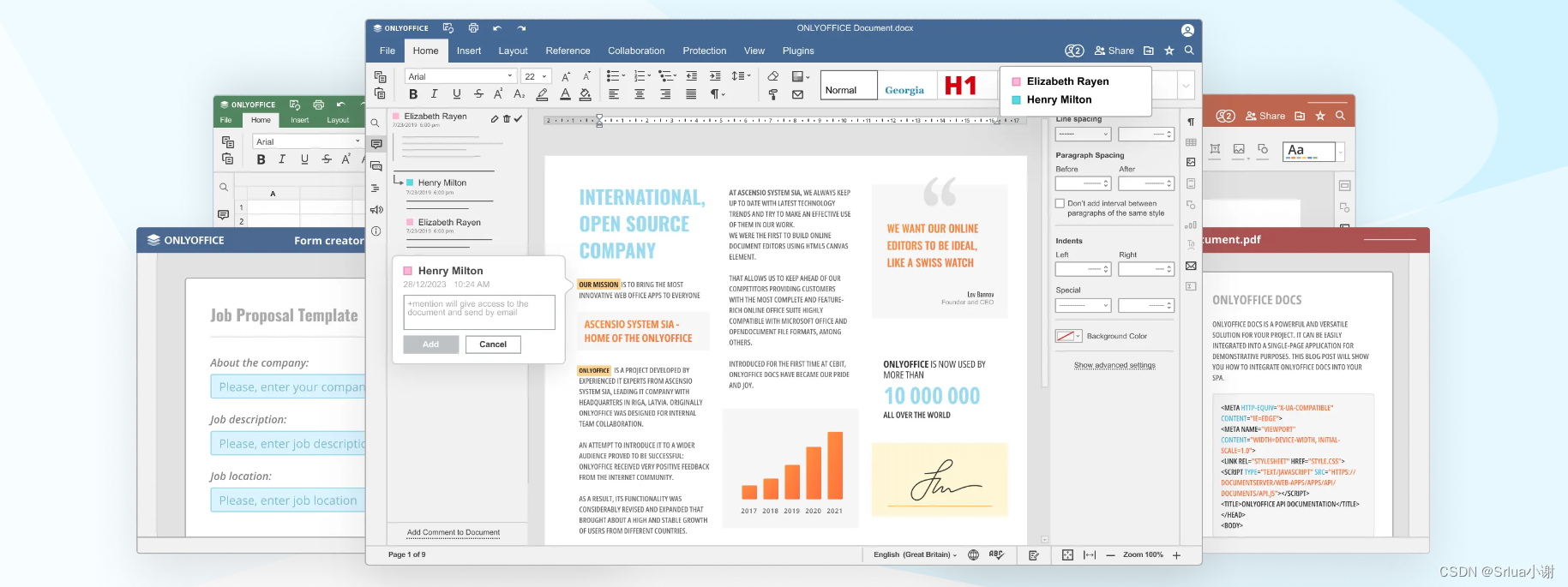
ONLYOFFICE 桌面编辑器 8.1 发布:全新 PDF 编辑器、幻灯片版式、增强 RTL 支持及更多本地化选项
目录 什么是ONLYOFFICE? ONLYOFFICE 主要特点包括: 官网信息: 1. 功能齐全的 PDF 编辑器 1.1 编辑 PDF 文本 1.2 插入和修改对象 1.3 创建和填写表单 2. 幻灯片版式功能 2.1 快速应用幻灯片版式 2.2 动画窗格的改进 3. 文档编辑、…...
Linux高并发服务器开发(六)线程
文章目录 1. 前言2 线程相关操作3 线程的创建4 进程数据段共享和回收5 线程分离6 线程退出和取消7 线程属性(了解)8 资源竞争9 互斥锁9.1 同步与互斥9.2 互斥锁 10 死锁11 读写锁12 条件变量13 生产者消费者模型14 信号量15 哲学家就餐 1. 前言 进程是C…...
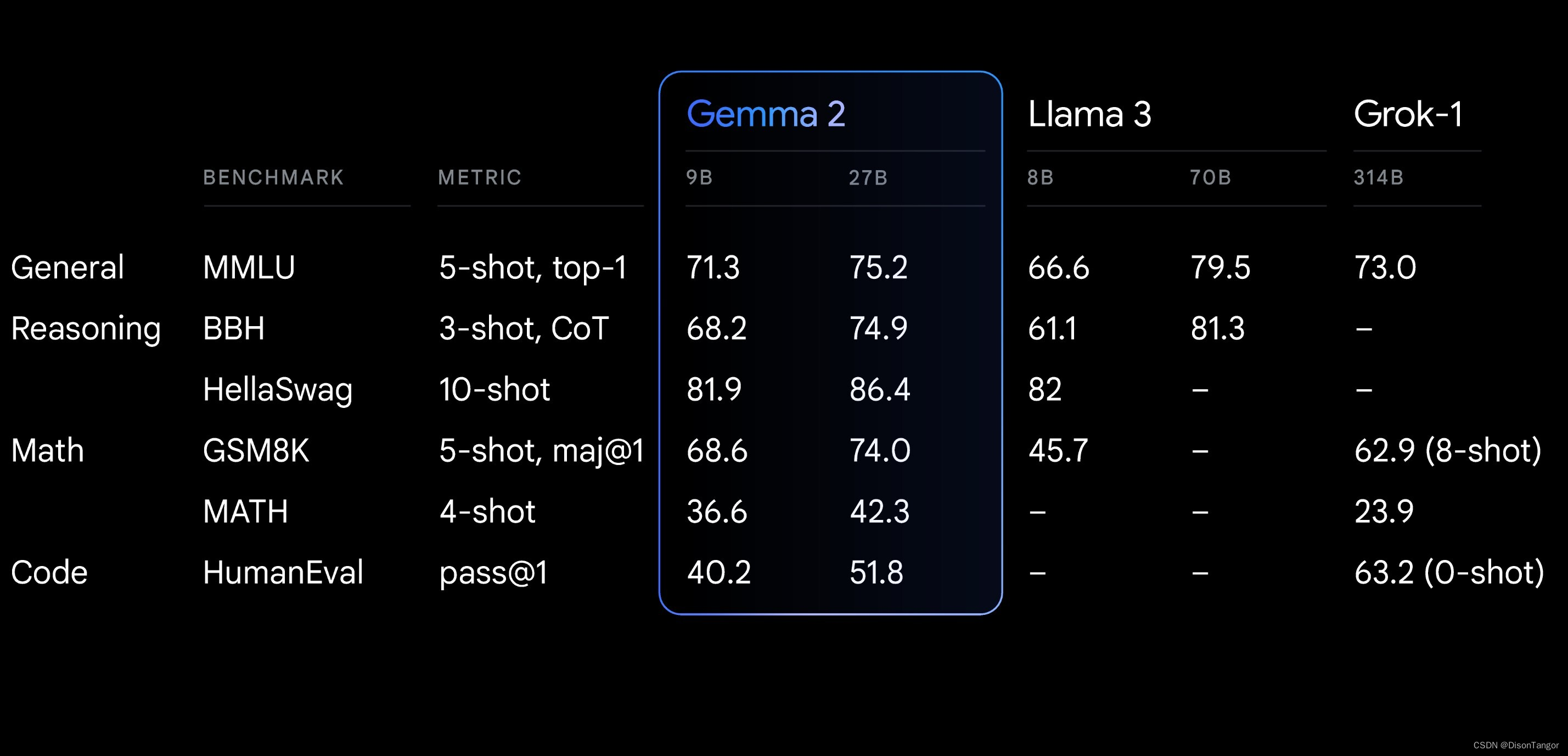
Google发布Gemma 2轻量级开放模型 以极小的成本提供强大的性能
除了 Gemini 系列人工智能模型外,Google还提供 Gemma 系列轻量级开放模型。今天,他们发布了 Gemma 2,这是基于全新架构设计的下一代产品,具有突破性的性能和效率。 Gemma 2 有两种规格:90 亿 (9B) 和 270 亿 (27B) 个参…...
精品UI知识付费系统源码网站EyouCMS模版源码
这是一款知识付费平台模板,后台可上传本地视频,批量上传视频连接, 视频后台可设计权限观看,免费试看时间时长,会员等级观看,付费观看等功能, 也带软件app权限下载,帮助知识教育和软件…...

AMD Carrizo架构解析:SoC集成与HSA异构计算如何重塑移动处理器
1. 从“胶水粘合”到“原生融合”:Carrizo与Carrizo-L的架构革命2014年底,当AMD在新加坡的“计算的未来”活动上拿出Carrizo和Carrizo-L这两颗芯片时,现场的反应可能比预想的要平静一些。毕竟,对于习惯了每年“挤牙膏”式升级的行…...

增材制造如何破解光电子小批量定制化制造难题
1. 项目概述:一份被“雪藏”的产业复兴蓝图最近在整理行业资料时,我翻到了一篇2012年《EE Times》的老文章,标题叫《Seeing the light on optoelectronics manufacturing》。文章的核心观点很有意思,它批评了当时美国国家研究委员…...

Skeleton骨架系统:基于Tailwind CSS的现代前端UI架构实践
1. 项目概述:骨架系统在现代前端开发中的价值回归如果你在前端领域摸爬滚打了一段时间,尤其是深度使用过 Tailwind CSS,那么你很可能已经对“组件库”这三个字又爱又恨。爱的是它们能极大提升开发效率,恨的是它们往往伴随着沉重的…...

Dev Containers实战:容器化开发环境配置与团队协作指南
1. 项目概述:一个容器化的开发环境定义仓库如果你和我一样,经常需要在不同的机器上切换工作,或者团队里有新成员加入,那么“环境配置”这件事,绝对能排进程序员最头疼问题的前三名。我经历过无数次这样的场景ÿ…...

S32K3 FlexCAN实战:从MCAL配置到DMA接收,手把手教你避开那些手册里没写的坑
S32K3 FlexCAN深度实战:从寄存器配置到DMA优化全链路解析 在车载电子架构快速迭代的今天,S32K3系列MCU凭借其强大的FlexCAN模块成为汽车电子开发者的首选。但官方文档往往只勾勒出理想状态下的功能框架,当工程师真正着手实现CAN FD通信时&…...

基于MCP协议与Docker为Claude Code构建Brave搜索服务器Argus
1. 项目概述:为Claude Code打造一个“全视之眼” 如果你和我一样,日常重度依赖Claude Code来辅助编程、查资料、写文档,那你一定遇到过这样的痛点:当Claude需要联网搜索时,要么得手动复制粘贴,要么得依赖一…...

AI舞蹈生成实战:从扩散模型原理到seedance-2.0部署与调优
1. 项目概述:从种子到舞蹈的AI生成革命最近在AI生成领域,一个名为“seedance-2.0”的项目引起了我的注意。这个项目名本身就很有意思,“seedance”可以拆解为“seed”(种子)和“dance”(舞蹈)&a…...

抽水蓄能电站岔管结构智能优化【附模型】
✨ 长期致力于抽水蓄能、球形钢岔管、智能优化、鲸鱼算法、静力分析研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)球形钢岔管参数化有限元建模&…...
)
Lindy AI Agent工作流编排进阶:从单Step到多Agent协同的6种拓扑模式(附拓扑决策树)
更多请点击: https://intelliparadigm.com 第一章:Lindy AI Agent工作流编排进阶:从单Step到多Agent协同的6种拓扑模式(附拓扑决策树) 在 Lindy 框架中,AI Agent 的工作流编排已超越传统线性 Step 链式调用…...
linux删除无用依赖 —东方仙盟)
服务器运维(四十八)linux删除无用依赖 —东方仙盟
一、逐条安全性分析1. sudo dnf autoremove -y作用:删掉安装软件后遗留的无用依赖包风险:极低禁忌:你现在只跑 nginxmysqllua,没有冷门依赖,随便跑效果:清大量残留库、编译依赖2. sudo dnf clean all作用&a…...