[深度学习] 卷积神经网络CNN
卷积神经网络(Convolutional Neural Network, CNN)是一种专门用于处理数据具有类似网格结构的神经网络,最常用于图像数据处理。
一、CNN的详细过程:
1. 输入层
输入层接收原始数据,例如一张图像,它可以被表示为一个三维矩阵(高度、宽度和颜色通道)。
2. 卷积层(Convolutional Layer)
卷积层是CNN的核心组件之一,通过卷积操作提取输入数据中的特征。卷积层的步骤如下:
- 卷积操作:使用若干个滤波器(也称为卷积核)在输入数据上进行滑动窗口操作。每个滤波器是一个较小的矩阵,它在输入数据的各个位置上进行矩阵乘法和加和运算,生成一个特征图。
- 激活函数:通常在卷积操作后应用激活函数(如ReLU)引入非线性,使模型能够学习更复杂的特征。
3. 池化层(Pooling Layer)
池化层用于减少特征图的尺寸,从而减少参数和计算量,同时控制过拟合。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。
- 最大池化:取池化窗口中的最大值。
- 平均池化:取池化窗口中的平均值。
4. 归一化层(Normalization Layer)
有时在卷积层和池化层之间会插入归一化层(如批量归一化),以加速训练过程并稳定模型性能。
5. 全连接层(Fully Connected Layer)
在经过若干个卷积和池化层后,通常会将特征图展平(flatten)为一个向量,然后输入全连接层。这类似于传统的神经网络,每个节点与前一层的所有节点相连。
6. 输出层
输出层通常是一个全连接层,用于生成最终的分类结果或其他任务的结果。
7. 损失函数(Loss Function)和优化(Optimization)
- 损失函数:用于评估模型预测与实际标签的差距,如交叉熵损失(Cross-Entropy Loss)用于分类问题。
- 优化算法:常用的优化算法有随机梯度下降(SGD)及其变种(如Adam),用于调整模型参数以最小化损失函数。
8. 训练过程
- 前向传播(Forward Propagation):将输入数据依次通过各层,计算输出。
- 反向传播(Backward Propagation):通过链式法则计算损失函数相对于每个参数的梯度,并更新参数。
9. 迭代训练
模型通过多次迭代训练,不断调整参数,使损失函数值逐渐减小,模型性能逐渐提升。
10. 评估和测试
使用独立的验证集和测试集评估模型性能,确保模型对新数据有良好的泛化能力。
卷积神经网络通过卷积层提取特征,池化层降维,全连接层进行分类,损失函数和优化算法进行参数调整,逐步提升模型性能,最终实现对图像等数据的有效处理和分析。
二、cnn模型构建过程举例
假设输入形状为 (5, 5, 1),并使用一个3x3的卷积核,stride为1,padding为same。
Stride是卷积核在输入图像上移动的步长。Stride定义了卷积核每次移动的像素数。常见的stride值有:
stride=1:卷积核每次移动一个像素。产生的特征图尺寸较大。
stride=2:卷积核每次移动两个像素。产生的特征图尺寸较小,计算量也较少。
Padding是在输入图像的边缘添加额外的像素,以保持输出特征图的尺寸。常见的padding类型有:
valid(无填充):不进行填充,卷积核只在输入图像内部滑动。特征图尺寸会缩小。
same(相同填充):进行填充,使得卷积后输出特征图的尺寸与输入图像相同。通常在每一边添加适当数量的零填充。
1. 输入层
假设输入图像为5x5的灰度图,像素值如下:
[[0, 1, 2, 1, 0],[1, 2, 3, 2, 1],[2, 3, 4, 3, 2],[1, 2, 3, 2, 1],[0, 1, 2, 1, 0]
]
2. 第一个卷积层
使用一个3x3卷积核,stride为1,padding为same。假设卷积核如下:
[[1, 0, -1],[1, 0, -1],[1, 0, -1]
]
先进行填充操作:
填充后的输入图像(周围填充一圈0):
[[0, 0, 0, 0, 0, 0, 0],[0, 0, 1, 2, 1, 0, 0],[0, 1, 2, 3, 2, 1, 0],[0, 2, 3, 4, 3, 2, 0],[0, 1, 2, 3, 2, 1, 0],[0, 0, 1, 2, 1, 0, 0],[0, 0, 0, 0, 0, 0, 0]
]
卷积操作步骤如下:
你是对的,如果使用 padding='same',在进行卷积操作之前,我们应该先对输入图像进行填充。下面我将详细说明每一步的计算过程,包括填充步骤。
1. 输入层
假设输入图像为5x5的灰度图,像素值如下:
[[0, 1, 2, 1, 0],[1, 2, 3, 2, 1],[2, 3, 4, 3, 2],[1, 2, 3, 2, 1],[0, 1, 2, 1, 0]
]
2. 填充
在进行卷积操作之前,使用 padding='same',我们需要在图像周围填充0,以保持输出图像尺寸与输入图像相同。填充后的图像为7x7:
[[0, 0, 0, 0, 0, 0, 0],[0, 0, 1, 2, 1, 0, 0],[0, 1, 2, 3, 2, 1, 0],[0, 2, 3, 4, 3, 2, 0],[0, 1, 2, 3, 2, 1, 0],[0, 0, 1, 2, 1, 0, 0],[0, 0, 0, 0, 0, 0, 0]
]
3. 第一个卷积层
使用一个3x3卷积核,stride为1,padding为same。假设垂直边缘检测卷积核如下:
[[1, 0, -1],[1, 0, -1],[1, 0, -1]
]
卷积操作计算
-
对位置(0, 0)的3x3区域进行卷积(左上角):
(0*1 + 0*0 + 0*(-1)) + (0*1 + 0*0 + 1*(-1)) + (0*1 + 1*0 + 2*(-1)) = 0 + 0 + 0 + 0 + 0 - 1 + 0 + 0 - 2 = -3 -
对位置(0, 1)的3x3区域进行卷积:
(0*1 + 0*0 + 0*(-1)) + (0*1 + 1*0 + 2*(-1)) + (0*1 + 2*0 + 3*(-1)) = 0 + 0 + 0 + 0 + 0 - 2 + 0 + 0 - 3 = -5 -
对位置(0, 2)的3x3区域进行卷积:
(0*1 + 0*0 + 0*(-1)) + (1*1 + 2*0 + 1*(-1)) + (2*1 + 3*0 + 2*(-1)) = 0 + 0 + 0 + 1 + 0 - 1 + 2 + 0 - 2 = 0 -
对位置(0, 3)的3x3区域进行卷积:
(0*1 + 0*0 + 0*(-1)) + (2*1 + 1*0 + 0*(-1)) + (3*1 + 2*0 + 1*(-1)) = 0 + 0 + 0 + 2 + 0 + 0 + 3 + 0 - 1 = 4 -
对位置(0, 4)的3x3区域进行卷积:
(0*1 + 0*0 + 0*(-1)) + (1*1 + 0*0 + 0*(-1)) + (2*1 + 1*0 + 0*(-1)) = 0 + 0 + 0 + 1 + 0 + 0 + 2 + 0 + 0 = 3 -
对位置(1, 0)的3x3区域进行卷积:
(0*1 + 0*0 + 1*(-1)) + (0*1 + 1*0 + 2*(-1)) + (0*1 + 2*0 + 3*(-1)) = 0 + 0 - 1 + 0 + 0 - 2 + 0 + 0 - 3 = -6 -
对位置(1, 1)的3x3区域进行卷积:
(0*1 + 1*0 + 2*(-1)) + (1*1 + 2*0 + 3*(-1)) + (2*1 + 3*0 + 4*(-1)) = 0 + 0 - 2 + 1 + 0 - 3 + 2 + 0 - 4 = -6 -
对位置(1, 2)的3x3区域进行卷积:
(1*1 + 2*0 + 1*(-1)) + (2*1 + 3*0 + 2*(-1)) + (3*1 + 4*0 + 3*(-1)) = 1 + 0 - 1 + 2 + 0 - 2 + 3 + 0 - 3 = 0 -
对位置(1, 3)的3x3区域进行卷积:
(2*1 + 1*0 + 0*(-1)) + (3*1 + 2*0 + 1*(-1)) + (4*1 + 3*0 + 2*(-1)) = 2 + 0 + 0 + 3 + 0 - 1 + 4 + 0 - 2 = 6 -
对位置(1, 4)的3x3区域进行卷积:
(1*1 + 0*0 + 0*(-1)) + (2*1 + 1*0 + 0*(-1)) + (3*1 + 2*0 + 1*(-1)) = 1 + 0 + 0 + 2 + 0 + 0 + 3 + 0 - 1 = 5 -
对位置(2, 0)的3x3区域进行卷积:
(0*1 + 1*0 + 2*(-1)) + (0*1 + 2*0 + 3*(-1)) + (0*1 + 3*0 + 4*(-1)) = 0 + 0 - 2 + 0 + 0 - 3 + 0 + 0 - 4 = -9 -
对位置(2, 1)的3x3区域进行卷积:
(1*1 + 2*0 + 3*(-1)) + (2*1 + 3*0 + 4*(-1)) + (3*1 + 4*0 + 3*(-1)) = 1 + 0 - 3 + 2 + 0 - 4 + 3 + 0 - 3 = -4 -
对位置(2, 2)的3x3区域进行卷积:
(2*1 + 3*0 + 2*(-1)) + (3*1 + 4*0 + 3*(-1)) + (4*1 + 3*0 + 2*(-1)) = 2 + 0 - 2 + 3 + 0 - 3 + 4 + 0 - 2 = 2 -
对位置(2, 3)的3x3区域进行卷积:
(3*1 + 2*0 + 1*(-1)) + (4*1 + 3*0 + 2*(-1)) + (3*1 + 2*0 + 1*(-1)) = 3 + 0 - 1 + 4 + 0 - 2 + 3 + 0 - 1 = 6 -
对位置(2, 4)的3x3区域进行卷积:
(2*1 + 1*0 + 0*(-1)) + (3*1 + 2*0 + 1*(-1)) + (4*1 + 3*0 + 2*(-1)) = 2 + 0 + 0 + 3 + 0 - 1 + 4 + 0 - 2 = 6 -
对位置(3, 0)的3x3区域进行卷积
-
对位置 (0,0) 的3x3区域进行卷积(左上角):
(0*1 + 0*0 + 0*(-1)) + (0*1 + 0*0 + 1*(-1)) + (0*1 + 1*0 + 2*(-1)) = -3 -
对位置 (0,1) 的3x3区域进行卷积:
(0*1 + 0*0 + 0*(-1)) + (0*1 + 1*0 + 2*(-1)) + (1*1 + 2*0 + 3*(-1)) = -4 -
对位置 (0,2) 的3x3区域进行卷积:
(0*1 + 0*0 + 0*(-1)) + (1*1 + 2*0 + 1*(-1)) + (2*1 + 3*0 + 2*(-1)) = 0 -
对位置 (0,3) 的3x3区域进行卷积:
(0*1 + 0*0 + 0*(-1)) + (2*1 + 1*0 + 0*(-1)) + (3*1 + 2*0 + 1*(-1)) = 4 -
对位置 (0,4) 的3x3区域进行卷积:
(0*1 + 0*0 + 0*(-1)) + (1*1 + 0*0 + 0*(-1)) + (2*1 + 1*0 + 0*(-1)) = 3 -
对位置 (1,0) 的3x3区域进行卷积:
(0*1 + 0*0 + 1*(-1)) + (0*1 + 1*0 + 2*(-1)) + (0*1 + 2*0 + 3*(-1)) = -6 -
对位置 (1,1) 的3x3区域进行卷积:
(0*1 + 1*0 + 2*(-1)) + (1*1 + 2*0 + 3*(-1)) + (2*1 + 3*0 + 4*(-1)) = -6 -
对位置 (1,2) 的3x3区域进行卷积:
(1*1 + 2*0 + 1*(-1)) + (2*1 + 3*0 + 2*(-1)) + (3*1 + 4*0 + 3*(-1)) = 0
以此类推,生成的特征图为:
[[-3, -4, 0, 4, 3],[-6, -6, 0, 6, 6],[-7, -6, 0, 6, 7],[-6, -6, 0, 6, 6],[-3, -4, 0, 4, 3]
]激活函数ReLU
应用ReLU激活函数,将负值置为0:
[[0, 0, 0, 4, 3],[0, 0, 0, 6, 6],[0, 0, 0, 6, 7],[0, 0, 0, 6, 6],[0, 0, 0, 4, 3]
]
3. 第一个池化层
使用2x2最大池化,stride为2,padding为valid
池化操作计算
- 窗口覆盖区域 (0,0)到 (1,1):
[
[0, 0],
[0, 0]
]
最大值为0
- 窗口覆盖区域 (0,2)到 (1,3):
[
[0,4],
[0,6]
]
最大值为6
- 窗口覆盖区域 (2,0)到 (3,1)
[
[0,0],
[0,0]
]
最大值为0
- 窗口覆盖区域 (2,2)到 (3,3)
[
[0,6],
[0,6]
]
最大值为6
最大池化结果:
[[0, 6],[0, 6]
]
4. 第二个卷积层
使用另一个3x3卷积核,stride为1,padding为same。假设水平边缘检测卷积核如下:
[[1, 1, 1],[0, 0, 0],[-1, -1, -1]
]
填充上述池化层输出:
[
[0,0,0,0]
[0,0,6,0]
[0,0,6,0]
[0,0,0,0]
]
卷积操作计算同前,生成新的特征图为:
[[-6, -6],[6, 6]
]
激活函数ReLU
应用ReLU激活函数,将负值置为0:
[[0, 0],[6, 6]
]
5. 第二个池化层
使用2x2最大池化,stride为2,padding为valid,输出为:
[[6]
]
6. 扁平层
将最后一个池化层的输出展平成一维向量:
[6]
7. 全连接层
假设全连接层有3个神经元,随机初始化权重和偏置,进行计算:
[1.176856*6 + b1, -0.25833628*6 + b2, 1.3403485*6 + b3] # 假设b1, b2, b3均为0
= [7.0611362, -1.5500176, 8.042091]
8. 输出层
使用softmax函数将全连接层输出转换为概率分布:
softmax([7.0611362, -1.5500176, 8.042091])
= [exp(7.0611362)/sum, exp(-1.5500176)/sum, exp(8.042091)/sum]
= [0.5209936545215091, -0.11436535298620337, 0.5933716984646943]
预测类别为概率最大的类别,即数字2。
具体代码实现
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np# 创建一个示例输入
x_train = np.array([[[0, 1, 2, 1, 0],[1, 2, 3, 2, 1],[2, 3, 4, 3, 2],[1, 2, 3, 2, 1],[0, 1, 2, 1, 0]
]], dtype=np.float32)
x_train = x_train[..., np.newaxis] # 添加通道维度# 定义垂直边缘检测卷积核
vertical_kernel = np.array([[1, 0, -1],[1, 0, -1],[1, 0, -1]
], dtype=np.float32)# 定义水平边缘检测卷积核
horizontal_kernel = np.array([[1, 1, 1],[0, 0, 0],[-1, -1, -1]
], dtype=np.float32)# 将卷积核转换为4D张量
vertical_kernel = vertical_kernel.reshape((3, 3, 1, 1))
horizontal_kernel = horizontal_kernel.reshape((3, 3, 1, 1))# 构建CNN模型
model = models.Sequential([layers.Conv2D(1, (3, 3), activation='relu', input_shape=(5, 5, 1), padding='same'), # 没有激活函数layers.MaxPooling2D((2, 2)),layers.Conv2D(1, (3, 3), activation='relu', padding='same'), # 没有激活函数layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(3) # 假设输出层有3个神经元
])# 设置第一个卷积层的权重为垂直边缘检测卷积核
model.layers[0].set_weights([vertical_kernel, np.zeros(1)]) # np.zeros(1) 是偏置# 设置第二个卷积层的权重为水平边缘检测卷积核
model.layers[2].set_weights([horizontal_kernel, np.zeros(1)]) # np.zeros(1) 是偏置# 设置全连接层的权重和偏置
# 获取全连接层的输入大小(展平后的特征图大小)
model_temp = models.Sequential(model.layers[:-1]) # 去掉最后的 Dense 层
flatten_output = model_temp.predict(x_train)
flattened_size = flatten_output.shape[1]print("Flatten层输出大小:", flattened_size)# 定义全连接层的权重和偏置
dense_weights = np.random.normal(size=(flattened_size, 3)).astype(np.float32) # 权重初始化
dense_biases = np.zeros(3, dtype=np.float32) # 偏置初始化# 设置全连接层的权重和偏置
model.layers[-1].set_weights([dense_weights, dense_biases])# 前向传播
outputs = model(x_train)
print("输出层结果:", outputs.numpy())# 使用softmax转换为概率分布
probabilities = tf.nn.softmax(outputs).numpy()
print("概率分布:", probabilities)三、CNN模型训练代码实现
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt# 加载数据集(以CIFAR-10为例)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 # 数据归一化# 构建模型
model = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(10)
])# 编译模型
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])# 训练模型
history = model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))# 可视化训练结果
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
plt.show()# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f'Test accuracy: {test_acc}')
四、构建CNN模型时,各层的作用和意义
输入层(Input Layer)
- 意义:定义输入数据的形状。对于图像数据,通常包括高度、宽度和通道数。
- 示例:
layers.Input(shape=(28, 28, 1))表示输入为 28x28 像素的灰度图像。
卷积层(Convolutional Layer)
- 意义:应用卷积操作,通过局部连接和共享权重的方式提取局部特征。卷积层通过不同的滤波器(卷积核)对输入数据进行卷积操作,提取不同特征。
- 示例:
layers.Conv2D(32, (3, 3), activation='relu', padding='same')表示使用32个3x3的卷积核进行卷积操作,ReLU作为激活函数,padding='same'表示输出的大小与输入相同(填充边界以保持大小)。
激活函数层(Activation Layer)
- 意义:引入非线性,使模型能够学习和表示更复杂的函数。常用的激活函数包括ReLU、Sigmoid、Tanh等。
- 示例:
layers.Activation('relu')表示使用ReLU激活函数。
池化层(Pooling Layer)
- 意义:通过下采样操作减少数据维度,保留重要特征,同时减少计算量和过拟合。常见的池化操作有最大池化(MaxPooling)和平均池化(AveragePooling)。
- 示例:
layers.MaxPooling2D((2, 2), strides=2, padding='valid')表示使用2x2的池化窗口,步幅为2,padding='valid'表示不填充边界。
扁平层(Flatten Layer)
- 意义:将多维特征图展平成一维向量,以便全连接层处理。扁平层通常连接卷积层和全连接层。
- 示例:
layers.Flatten()将多维输入展平成一维。
全连接层(Dense Layer)
- 意义:连接所有输入和输出神经元,执行线性变换和激活函数。在模型的最后几层,通常使用全连接层来综合卷积层提取的特征。
- 示例:
layers.Dense(128, activation='relu')表示一个有128个神经元的全连接层,使用ReLU激活函数。
Dropout 层(Dropout Layer)
- 意义:在训练过程中随机丢弃一定比例的神经元,防止过拟合,提高模型的泛化能力。
- 示例:
layers.Dropout(0.5)表示每个神经元有50%的概率被丢弃。
输出层(Output Layer)
- 意义:提供最终的预测结果。对于分类任务,输出层通常使用Softmax激活函数来输出概率分布。
- 示例:
layers.Dense(10, activation='softmax')表示一个有10个神经元的全连接层,使用Softmax激活函数,用于10分类任务。
五、优化器
卷积神经网络(CNN)的优化器是用于调整网络权重以最小化损失函数的算法。不同的优化器在处理学习率调整和梯度更新方面有所不同。
梯度
在深度学习中,梯度是损失函数相对于模型参数(权重和偏置)的导数。通过计算梯度,优化器可以调整模型的参数,使得损失函数逐步减小,从而提高模型的性能。
具体来说,梯度下降算法(Gradient Descent)是一种迭代优化算法,用于寻找损失函数的最小值。该算法通过以下步骤进行:
1. 计算损失函数的梯度:计算损失函数相对于每个模型参数的导数。
2. 更新模型参数:按照梯度的反方向更新模型参数,更新步长由学习率决定。
3. 迭代上述步骤:不断重复上述步骤,直到损失函数收敛或达到预设的迭代次数。
在深度学习中,梯度通常通过反向传播算法(Backpropagation)进行计算。反向传播算法利用链式法则(Chain Rule),从输出层开始,逐层计算每个参数的梯度。
以下是一些常用的优化器及其作用:
1. 随机梯度下降(SGD)
作用:SGD通过逐步调整网络权重,使得损失函数逐步减少。它在每次迭代中使用一个小批量(mini-batch)数据来计算梯度并更新权重。
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
优点:
- 简单易理解。
- 对大规模数据集有效。
缺点:
- 容易陷入局部最小值。
- 收敛速度较慢。
2. 动量梯度下降(SGD with Momentum)
作用:在SGD的基础上增加了动量的概念,通过引入一个动量项,来加速收敛,并减少震荡。
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.9)
优点:
- 加快收敛速度。
- 减少损失函数在局部最小值处的震荡。
缺点:
- 需要调节动量参数。
3. Nesterov 动量(Nesterov Momentum)
作用:在动量梯度下降的基础上,进行提前梯度计算,进一步提高优化效率。
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.9, nesterov=True)
优点:
- 提前梯度计算,提高优化效率。
- 更稳定的收敛。
缺点:
- 需要调节动量参数。
4. 自适应梯度算法(Adagrad)
作用:自适应学习率优化器,根据参数的历史梯度自适应地调整学习率,对稀疏数据表现良好。
optimizer = tf.keras.optimizers.Adagrad(learning_rate=0.01)
优点:
- 自适应调整学习率。
- 对稀疏数据表现良好。
缺点:
- 学习率可能会变得过小,导致模型停止训练。
5. RMSProp
作用:对Adagrad进行改进,防止学习率过小,通过指数加权移动平均来调整学习率。
optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.001)
优点:
- 保持学习率的稳定性。
- 对处理非平稳目标(如RNN)有效。
缺点:
- 需要调节衰减参数。
6. 自适应矩估计(Adam)
作用:结合了动量梯度下降和RMSProp的优点,自适应调整学习率,同时考虑了一阶矩和二阶矩估计。
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
优点:
- 收敛速度快。
- 自适应调整学习率。
- 默认参数效果良好。
缺点:
- 对某些问题的泛化性能不如SGD。
7. Adam变体(如Adamax、Nadam)
作用:Adam的变体,针对特定问题做出改进。
optimizer = tf.keras.optimizers.Adamax(learning_rate=0.002)
optimizer = tf.keras.optimizers.Nadam(learning_rate=0.001)
优点:
- 适用于不同的优化需求。
- 结合了不同优化器的优点。
缺点:
- 需要根据具体任务选择合适的变体。
选择优化器的建议
- Adam 是最常用的优化器之一,适合大多数深度学习任务,尤其是初学者。
- SGD with Momentum 适合需要控制训练过程、对大规模数据集进行训练的情况。
- RMSProp 和 Adagrad 适合处理稀疏数据或梯度较稀疏的任务。
- 在特定任务中,可以尝试不同的优化器,结合验证集结果选择最合适的优化器。
六、损失函数
在卷积神经网络(CNN)中,损失函数用于衡量模型预测值与真实值之间的差异。选择适当的损失函数对模型的训练和性能有重要影响。以下是常用的损失函数及其作用:
1. 均方误差(Mean Squared Error, MSE)
作用:主要用于回归任务,衡量预测值与真实值之间的平方差。
公式:
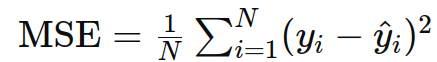
示例:
loss = tf.keras.losses.MeanSquaredError()
应用:回归任务,如房价预测、温度预测等。
2. 平均绝对误差(Mean Absolute Error, MAE)
作用:用于回归任务,衡量预测值与真实值之间的绝对差异。
公式:
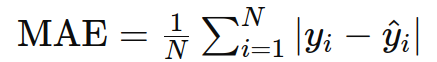
示例:
loss = tf.keras.losses.MeanAbsoluteError()
应用:回归任务,特别是对异常值不敏感的情况。
3. 二分类交叉熵(Binary Cross-Entropy)
作用:用于二分类任务,衡量预测概率分布与真实分布之间的差异。
公式:
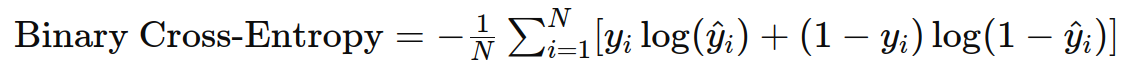
示例:
loss = tf.keras.losses.BinaryCrossentropy()
应用:二分类任务,如垃圾邮件分类、图像中的物体检测(是/否)。
4. 类别交叉熵(Categorical Cross-Entropy)
作用:用于多分类任务,衡量预测概率分布与真实分布之间的差异。
公式:
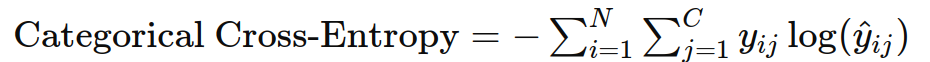
示例:
loss = tf.keras.losses.CategoricalCrossentropy()
应用:多分类任务,如手写数字识别(MNIST)、图像分类(CIFAR-10)。
5. 稀疏类别交叉熵(Sparse Categorical Cross-Entropy)
作用:类似于类别交叉熵,但标签是整数编码而不是one-hot编码。
公式:同类别交叉熵,但输入为整数标签。
示例:
loss = tf.keras.losses.SparseCategoricalCrossentropy()
应用:多分类任务,但标签为整数编码的情况。
6. Hinge 损失
作用:用于支持向量机(SVM)和最大边缘分类问题。
公式:
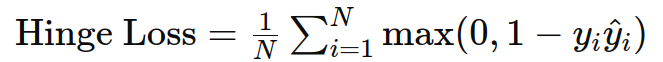
示例:
loss = tf.keras.losses.Hinge()
应用:二分类任务,通常用于支持向量机。
7. Kullback-Leibler 散度(Kullback-Leibler Divergence, KL Divergence)
作用:衡量两个概率分布之间的差异,常用于变分自编码器(VAE)等生成模型。
公式:
 \max(0, m - d)^2) ]
g.cn/direct/a8763aca2a7949e8b96773fd84b53ed4.png)
示例:
loss = tf.keras.losses.KLDivergence()
应用:概率分布比较,如生成模型中的分布匹配。
8. 对比损失(Contrastive Loss)
作用:用于度量学习,衡量成对样本之间的相似性。
公式:
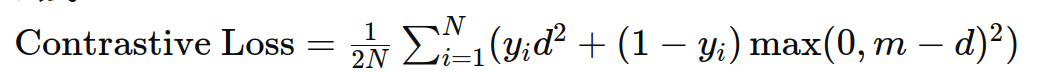
示例:
def contrastive_loss(y_true, y_pred):margin = 1return tf.reduce_mean(y_true * tf.square(y_pred) + (1 - y_true) * tf.square(tf.maximum(margin - y_pred, 0)))
应用:度量学习任务,如人脸识别中的 Siamese 网络。
实际应用中的损失函数选择
在实际应用中,选择损失函数应根据任务类型和数据特点来确定。以下是一些常见场景及其对应的损失函数:
- 图像分类:使用类别交叉熵(Categorical Cross-Entropy)或稀疏类别交叉熵(Sparse Categorical Cross-Entropy)。
- 图像分割:使用类别交叉熵或 Dice 损失(Dice Loss)。
- 物体检测:使用类别交叉熵和边界框回归损失(如 Smooth L1 Loss)的组合。
- 生成模型:使用 Kullback-Leibler 散度(KL Divergence)和对抗性损失(如 GAN 的生成器和判别器损失)。
- 回归任务:使用均方误差(MSE)或平均绝对误差(MAE)。
步骤5:实验与调优
- 调整超参数:改变卷积核大小、池化方式、层数等。
- 数据增强:使用图像翻转、旋转、缩放等方法增加训练数据。
- 正则化:使用Dropout层防止过拟合。
七、应用场景
卷积神经网络(CNN)在许多计算机视觉和其他领域有广泛的应用。以下是一些主要的应用场景:
1. 图像分类
- 应用:识别图像中的对象类别。
- 示例:手写数字识别(如MNIST)、猫狗分类、ImageNet大规模图像分类。
- 方法:使用带有Softmax输出层的CNN来预测图像所属的类别。
2. 物体检测
- 应用:在图像中检测并定位多个对象。
- 示例:自动驾驶中的行人和车辆检测、安防监控中的异常检测。
- 方法:使用区域卷积神经网络(R-CNN)、YOLO(You Only Look Once)、SSD(Single Shot Multibox Detector)等模型。
3. 图像分割
- 应用:将图像划分为不同的区域,每个区域对应不同的类别。
- 示例:医学图像分析中的器官分割、自动驾驶中的道路和车道分割。
- 方法:使用全卷积网络(FCN)、U-Net、SegNet等模型。
4. 图像生成和图像修复
- 应用:生成逼真的图像、修复损坏或缺失的图像部分。
- 示例:生成对抗网络(GANs)用于生成艺术作品、修复老照片。
- 方法:使用生成对抗网络(GANs)、变分自编码器(VAEs)等模型。
5. 图像风格迁移
- 应用:将一种图像的风格应用到另一种图像上。
- 示例:将梵高的画作风格应用到普通照片上。
- 方法:使用卷积神经网络进行风格迁移,例如使用卷积神经网络进行风格迁移(Neural Style Transfer)。
6. 面部识别
- 应用:识别和验证人脸。
- 示例:安全系统中的人脸验证、社交媒体中的人脸标签、智能手机解锁。
- 方法:使用深度学习模型,如VGG-Face、FaceNet等。
7. 视频分析
- 应用:分析视频帧序列以识别活动或事件。
- 示例:监控视频中的行为识别、体育赛事中的动作识别。
- 方法:结合CNN和循环神经网络(RNN)或长短期记忆网络(LSTM),如使用3D-CNN、C3D等模型。
8. 自然语言处理
- 应用:文本分类、情感分析、机器翻译。
- 示例:情感分析中的正负情绪分类、垃圾邮件检测。
- 方法:使用文本卷积神经网络(Text-CNN)、卷积神经网络与RNN结合的方法。
9. 医疗诊断
- 应用:分析医学图像以辅助诊断。
- 示例:X光片中的肺结核检测、MRI中的肿瘤识别。
- 方法:使用训练有素的CNN模型进行图像分类、分割和检测。
10. 自动驾驶
- 应用:环境感知,检测和识别道路上的物体。
- 示例:自动驾驶汽车中的行人、交通标志、车道检测。
- 方法:使用YOLO、R-CNN、FCN等模型进行实时对象检测和分割。
11. 遥感图像分析
- 应用:从卫星图像中提取有用的信息。
- 示例:土地覆盖分类、城市增长监测、灾害评估。
- 方法:使用CNN进行图像分类和分割。
12. 体育运动分析
- 应用:分析运动员的动作和比赛情况。
- 示例:足球比赛中的球员追踪、动作分析。
- 方法:结合CNN和LSTM进行视频分析和动作识别。
这些应用场景展示了CNN的广泛应用,尤其是在处理图像和视频数据方面。通过不断的发展和优化,CNN在各种实际问题中表现出色,并在许多领域取得了显著的进展。
相关文章:
[深度学习] 卷积神经网络CNN
卷积神经网络(Convolutional Neural Network, CNN)是一种专门用于处理数据具有类似网格结构的神经网络,最常用于图像数据处理。 一、CNN的详细过程: 1. 输入层 输入层接收原始数据,例如一张图像,它可以被…...

区别QPushButton和QToolButton
在刚开始学习Qt时,可能很难理解QPushButton和QToolButton之间的区别。 QToolButton通常用于QToolBar中,常常只显示图标,而不显示文本。那么,它们的主要区别是什么?什么时候应该使用QPushButton,什么时候应该使用QToolButton? 了解这一点很重要,这样我们才能选择最合适…...

【Python】已解决:TypeError: Object of type JpegImageFile is not JSON serializable
文章目录 一、分析问题背景二、可能出错的原因三、错误代码示例四、正确代码示例五、注意事项 已解决:TypeError: Object of type JpegImageFile is not JSON serializable 一、分析问题背景 在进行Python编程时,特别是处理图像数据和JSON序列化时&…...
超简单的nodejs使用log4js保存日志到本地(可直接复制使用)
引入依赖 npm install log4js 新建配置文件logUtil.js const log4js require(log4js);// 日志配置 log4js.configure({appenders: {// 控制台输出consoleAppender: { type: console },// 文件输出fileAppender: {type: dateFile,filename: ./logs/default, //日志文件的存…...
Python面试宝典第1题:两数之和
题目 给定一个整数数组 nums 和一个目标值 target,找出数组中和为目标值的两个数的索引。可以假设每个输入只对应唯一的答案,且同样的元素不能被重复利用。比如:给定 nums [2, 7, 11, 15] 和 target 9,返回 [0, 1],因…...

fastapi集成jwt
fastapi集成jwt fastapipython-jose实现jwt登录 1、安装相关包 python-jose pip install python-jose2、创建token及token校验 from copy import deepcopy from datetime import timedelta, datetimefrom jose import jwt, ExpiredSignatureErrorSECRET_KEY "xxx&quo…...
自定义一个背景图片的高度,随着容器高度的变化而变化,小于图片的高度时裁剪,大于时拉伸100%展示
1、通过js创建<image?>标签来获取背景图片的宽高比; 2、当元素的高度大于原有比例计算出来的高度时,背景图片的高度拉伸自适应100%,否则高度为auto,会自动被裁减 3、背景图片容器高度变化时,自动计算背景图片的…...
iPhone怎么恢复删除的数据?几款顶级iPhone数据恢复软件
从iOS设备恢复数据。 对于任何数据恢复软件来说,从iOS设备恢复数据都是一项复杂的任务,因为Apple已将众多数据保护技术集成到现代iPhone和iPad中。其中包括硬件加密和文件级加密。iOS 上已删除的数据只能通过取证文件工件搜索来找到,例如分析…...

macOS 上或linux安装 Jenkins
在 macOS 上使用 Docker 安装 Jenkins 的步骤如下: 安装 Docker: 如果尚未安装 Docker,请先从 Docker 官网下载并安装 Docker Desktop for Mac。 打开终端: 打开 macOS 上的终端应用程序。 拉取 Jenkins 镜像: 使用以下命令从 Docker Hub 拉取 Jenkins…...

axios发送数据的几种方式
axios 发送数据的几种方式 1、最简单的方式是将参数直接拼接在 URL 上,这通常用于传递少量的数据,例如资源的 ID。 const id 12; axios.delete(https://api.example.com/${id}).then(response > {console.log(Resource deleted successfully:, res…...

示例:WPF中推荐一个Diagram开源流程图控件
一、目的:分享一个自研的开源流程图控件 二、使用方法 1、引用Nuget包: 2、添加节点列表和绘图控件 <DockPanel><ItemsControl DockPanel.Dock"Left"><h:GeometryNodeData Text"节点"/></ItemsControl><…...

离线安装kubesphere-详细操作,以及报错
离线安装kubesphere 官网地址 https://kubesphere.io/zh/docs/v3.4/installing-on-linux/introduction/air-gapped-installation/ 1.先准备docker环境 [rootnode1 ~]# tar -xf docker-24.0.6.tgz [rootnode1 ~]# ls anaconda-ks.cfg calico-v3.26.1.tar docker …...
Python Coala库:代码质量检查与自动化修复的利器
更多Python学习内容:ipengtao.com 在软件开发过程中,代码质量至关重要。高质量的代码不仅易于维护和扩展,还能减少错误和提升效率。为了确保代码质量,我们常常需要依赖代码分析工具。Python的Coala库就是这样一个强大的工具&#…...
MyBatis 映射文件中的 resultMap)
MyBatis(12)MyBatis 映射文件中的 resultMap
MyBatis 的 resultMap 是一种高级映射策略,用于处理复杂的SQL查询结果和Java对象之间的映射关系。resultMap 提供了比 auto-mapping 更为灵活的映射方式,它允许开发者显式指定数据库列和Java对象属性之间的映射关系,甚至可以处理复杂的数据结…...

C语言从入门到进阶(15万字总结)
前言: 《C语言从入门到进阶》这本书可是作者呕心沥血之作,建议零售价1元,当然这里开个玩笑。 本篇博客可是作者之前写的所有C语言笔记博客的集结,本篇博客不止有知识点,还有一部分代码练习。 有人可能会问ÿ…...

Java---Maven详解
一段新的启程, 披荆斩棘而前, 心中的梦想, 照亮每个黑暗的瞬间。 无论风雨多大, 我们都将坚强, 因为希望的火焰, 在胸中永不熄灭。 成功不是终点, 而是每一步的脚印, 用汗水浇灌&…...

服务器日志事件ID4107:从自动更新 cab 中提取第三方的根目录列表失败,错误为: 已处理证书链,但是在不受信任提供程序信任的根证书中终止。
在查看Windows系统日志时,你是否有遇到过事件ID4107错误,来源CAPI2,详细信息在 http://www.download.windowsupdate.com/msdownload/update/v3/static/trustedr/en/authrootstl.cab 从自动更新 cab 中提取第三方的根目录列表失败,…...
)
【高级篇】MySQL集群与分布式:构建弹性和高效的数据服务(十四)
引言 在探讨了《分区与分片》策略后,我们已经学会了如何在单一数据库层面有效管理大量数据和提升查询效率。本章,我们将踏上更高层次的探索之旅,深入MySQL集群与分布式技术的广阔领域。这些技术不仅能够横向扩展系统的处理能力和存储容量,还能显著增强数据服务的可靠性和响…...

vue3 学习记录
文章目录 props组合式组件 使用<script setup \>组合式组件 没有使用 <script setup\>选项式组件 this emits组合式组件 使用<script setup \>组合式组件 没有使用 <script setup\>选项式组件 this v-model 组件数据绑定单个model多个model实现 model …...

spring boot jar 启动报错 Zip64 archives are not supported
spring boot jar 启动报错 Zip64 archives are not supported 原因、解决方案问题为什么 spring boot 不支持 zip64zip、zip64 功能上的区别zip 的文件格式spring-boot-loader 是如何判断是否是 zip64 的? 参考 spring boot 版本是 2.1.8.RELEASE,引入以…...

简单介绍C语言中的字符串函数
1.首先给出字符分类函数这几个就简单过一下,不做重点说明。这两个为字符转换函数,顾名思义,没什么好介绍的;接下来简单介绍几个字符串函数:strlen.strcpy.strcat.strstr.strncpy.strncat.memcpy.memmove;strlen:求字符…...
)
Cocos Creator实战:5步搞定棋牌游戏大厅场景开发(附完整代码)
Cocos Creator实战:5步构建高交互棋牌游戏大厅(附模块化代码) 棋牌游戏大厅作为玩家进入游戏的第一印象,其体验直接决定了用户留存率。根据行业数据,精心设计的大厅界面能提升30%以上的玩家次日留存。不同于传统游戏开…...

从语义熵到可信AI:构建大语言模型幻觉检测的通用框架
1. 当AI开始"胡说八道":什么是大语言模型幻觉? 想象一下,你正在咨询一位AI客服关于某款手机的参数。它信誓旦旦地告诉你"这款手机搭载了最新款骁龙8Gen3芯片,电池容量5000mAh",而实际上这款手机用…...
)
保姆级避坑指南:在CentOS 7上手动部署MySQL 8.0二进制包(附systemd服务配置)
CentOS 7手动部署MySQL 8.0二进制包的深度避坑指南 在Linux服务器上手动部署MySQL数据库是每个运维工程师的必修课。不同于常见的yum或apt安装方式,二进制包部署能让你更深入地理解MySQL的运行机制,同时获得更灵活的控制权。但这条路并不平坦,…...

黑客为什么不攻击微信钱包?
黑客为什么不攻击微信钱包? 现在人人手机里都装着微信和支付宝,里面都或多或少存了些钱。怎么从来没听说谁的钱被技术牛逼黑客惦记走? 是黑客没攻击过?还是黑客不敢攻击?其实都不是。阿里巴巴首席风险官郑俊芳就说过&…...
-- 从高斯消元到对称正定:LU、LDLT与Cholesky分解的算法演进与应用场景)
矩阵分解(1)-- 从高斯消元到对称正定:LU、LDLT与Cholesky分解的算法演进与应用场景
1. 矩阵分解:为什么我们需要它? 想象一下你面前有一堆积木,乱七八糟地堆在一起。如果你想快速找到其中某一块积木,可能需要翻找很久。但如果有人帮你把这些积木按照颜色、形状分类摆放整齐,找起来就会容易得多。矩阵分…...

数谷智能和爱莫科技,非标准数据 AI 定制处理谁更强?
在数字化转型步入“深水区”的今天,企业面临的最大挑战不再是标准化的数据库信息,而是占据企业数据总量 80% 以上的“非标准数据”。这些数据散落在手写单据、非结构化合同、复杂的网页信息、甚至是不规则的工业图像中。如何高效、精准地处理这些非标数据…...

终极指南:如何彻底解决Colab运行text-generation-webui的Matplotlib后端错误
终极指南:如何彻底解决Colab运行text-generation-webui的Matplotlib后端错误 【免费下载链接】text-generation-webui The original local LLM interface. Text, vision, tool-calling, training, and more. 100% offline. 项目地址: https://gitcode.com/GitHub_…...

解锁Switch无限可能:TegraRcmGUI图形化注入工具实战指南
解锁Switch无限可能:TegraRcmGUI图形化注入工具实战指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI 当你想为Nintendo Switch安装自定义系统…...

SDMatte与LSTM结合研究:时序视频抠图的初步探索
SDMatte与LSTM结合研究:时序视频抠图的初步探索 1. 引言:视频抠图的新挑战 视频抠图技术一直是影视后期和内容创作领域的重要工具。传统的静态图像抠图方法在处理视频时常常面临一个棘手问题:帧与帧之间的结果不一致,导致最终视…...