Tensorflow入门实战 T06-Vgg16 明星识别
目录
1、前言
2、 完整代码
3、运行过程+结果
4、遇到的问题
5、小结
- 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
1、前言
这周主要是使用VGG16模型,完成明星照片识别。
2、 完整代码
from keras.utils import losses_utils
from tensorflow import keras
from keras import layers, models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from keras.callbacks import ModelCheckpoint, EarlyStoppinggpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0], "GPU")# 导入数据
data_dir = "/Users/MsLiang/Documents/mySelf_project/pythonProject_pytorch/learn_demo/P_model/p06_vgg16/data"
data_dir = pathlib.Path(data_dir)# 查看数据
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:",image_count) # 1800roses = list(data_dir.glob('Jennifer Lawrence/*.jpg'))
img = PIL.Image.open(str(roses[0]))
# img.show() # 查看图片# 数据预处理
# 1、加载数据
batch_size = 32
img_height = 224
img_width = 224print('data_dir======>',data_dir)
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.1,subset="training",label_mode="categorical",seed=123,image_size=(img_height, img_width),batch_size=batch_size)"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.1,subset="validation",label_mode="categorical",seed=123,image_size=(img_height, img_width),batch_size=batch_size)class_names = train_ds.class_names
print(class_names)# 可视化数据
plt.figure(figsize=(20, 10))for images, labels in train_ds.take(1):for i in range(20):ax = plt.subplot(5, 10, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[np.argmax(labels[i])])plt.axis("off")
plt.show()# 再次检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape) # (32, 224, 224, 3)print(labels_batch.shape) # (32, 17)break# 配置数据集
AUTOTUNE = tf.data.AUTOTUNEtrain_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)# 构建CNN网络
"""
关于卷积核的计算不懂的可以参考文章:https://blog.csdn.net/qq_38251616/article/details/114278995layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力。
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/115826689
"""model = models.Sequential([keras.layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=(img_height, img_width, 3)),layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样layers.Dropout(0.5),layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3layers.AveragePooling2D((2, 2)),layers.Dropout(0.5),layers.Conv2D(128, (3, 3), activation='relu'), # 卷积层3,卷积核3*3layers.Dropout(0.5),layers.Flatten(), # Flatten层,连接卷积层与全连接层layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取layers.Dense(len(class_names)) # 输出层,输出预期结果
])# model.summary() # 打印网络结构# 训练模型
# 1、设置动态学习率
# 设置初始学习率
initial_learning_rate = 1e-4lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate,decay_steps=60, # 敲黑板!!!这里是指 steps,不是指epochsdecay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lrstaircase=True)# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)model.compile(optimizer=optimizer,loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),metrics=['accuracy'])# 损失函数
# 调用方式1:
model.compile(optimizer="adam",loss='categorical_crossentropy',metrics=['accuracy'])# 调用方式2:
# model.compile(optimizer="adam",
# loss=tf.keras.losses.CategoricalCrossentropy(),
# metrics=['accuracy'])# sparse_categorical_crossentropy(稀疏性多分类的对数损失函数)
# 调用方式1:
model.compile(optimizer="adam",loss='categorical_crossentropy',metrics=['accuracy'])
# ↑↑↑↑这里出现报错,需要将 sparse_categorical_crossentropy 改成→ categorical_crossentropy↑↑
# 调用方式2:
# model.compile(optimizer="adam",
# loss=tf.keras.losses.SparseCategoricalCrossentropy(),
# metrics=['accuracy'])# 函数原型
tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False,reduction=losses_utils.ReductionV2.AUTO,name='sparse_categorical_crossentropy'
)epochs = 100# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',monitor='val_accuracy',verbose=1,save_best_only=True,save_weights_only=True)# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy',min_delta=0.001,patience=20,verbose=1)# 网络模型训练
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs,callbacks=[checkpointer, earlystopper])# 模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(len(loss))plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()# 指定图片进行预测
# 加载效果最好的模型权重
model.load_weights('best_model.h5')from PIL import Image
import numpy as npimg = Image.open("/Users/MsLiang/Documents/mySelf_project/pythonProject_pytorch/learn_demo/P_model/p06_vgg16/data/Jennifer Lawrence/003_963a3627.jpg") #这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])img_array = tf.expand_dims(image, 0)predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])3、运行过程+结果
【查看图片】

【模型运行过程---第21epoch就早停了】
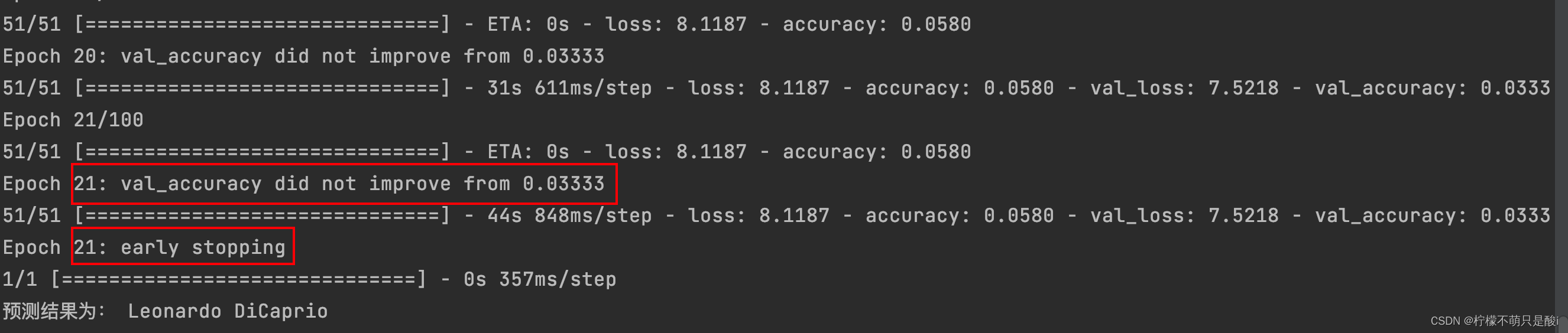
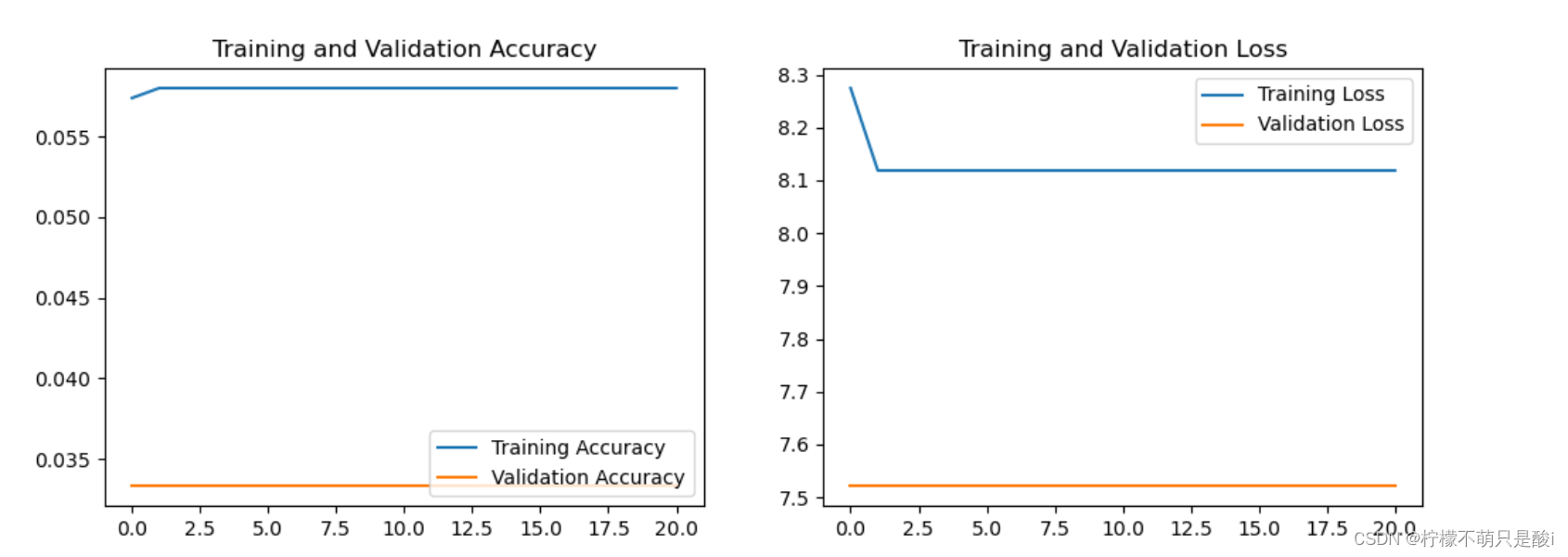
【训练精度、损失-----显然结果很很差】
4、遇到的问题
① 在运行代码的时候遇到报错:
错误:Graph execution error: Detected at node 'sparse_categorical_crossentropy/SparseSoftmaxCrossEntropyWithLogits/SparseSoftmaxCrossEntropyWithLogits' defined at (most recent call last):
出现这个问题来自我们使用的损失函数。
model.compile(optimizer="adam",loss='sparse_categorical_crossentropy',metrics=['accuracy'])解决办法:
将损失函数里面的loss='sparse_categorical_crossentropy' 改成 'categorical_crossentropy',即可解决报错问题。
关于sparse_categorical_crossentropy和categorical_crossentropy的更多细节,详细参考这篇博文:交叉熵损失_多分类交叉熵损失函数-CSDN博客
5、小结
原始模型,跑出来效果很差很差!!!
(1)将原来的Adam优化器换成SGD优化器,效果如下:
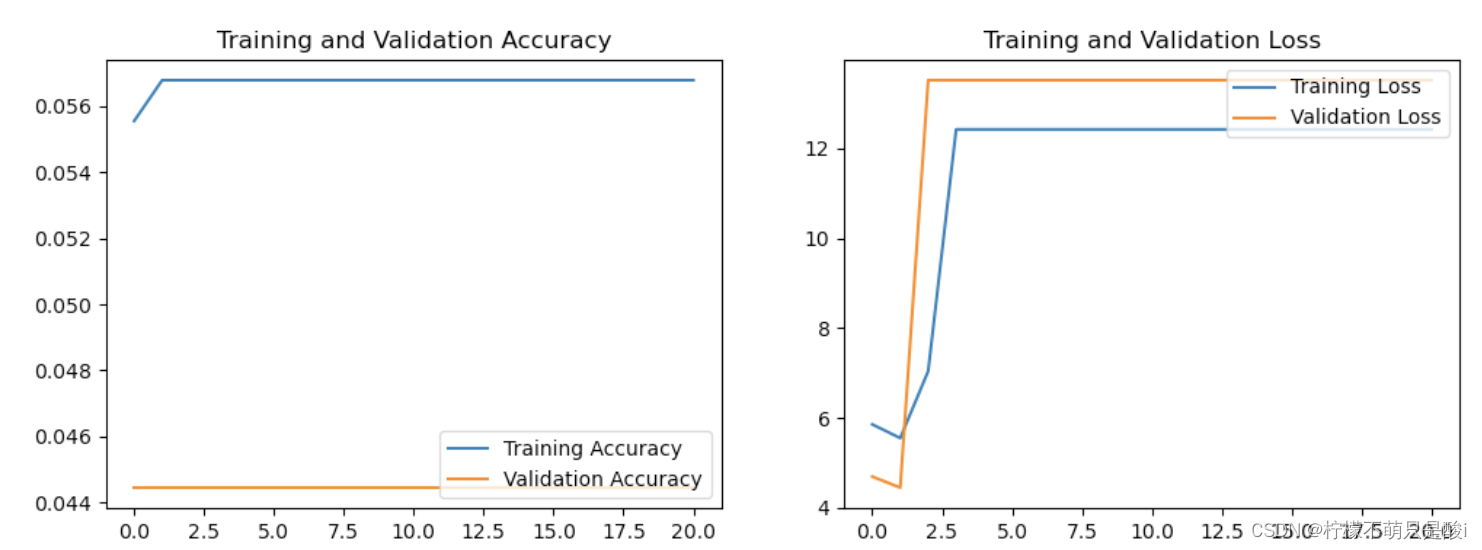
(2)后续再补充,最近在写结课论文,有些忙。
相关文章:
Tensorflow入门实战 T06-Vgg16 明星识别
目录 1、前言 2、 完整代码 3、运行过程结果 4、遇到的问题 5、小结 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 1、前言 这周主要是使用VGG16模型,完成明星照片识别。 2、 完整代…...

SpringBoot 3.3.1 + Minio 实现极速上传和预览模式
统一版本管理 <properties><minio.version>8.5.10</minio.version><aws.version>1.12.737</aws.version><hutool.version>5.8.28</hutool.version> </properties><!--minio --> <dependency><groupId>io.m…...

Linux: network: 丢包分析的另一个途径 tracing
丢包的另一个思路,内核里有些counter的计数,记录的不准确。这个时候怎么办?就需要使用另外一个方式:/sys/kernel/debug/tracing/event/skb/kfree_skb 的跟踪功能。这个算是对counter的一个补充,可以拿来做统计分析使用…...

【保姆级教程+配置源码】在VScode配置C/C++环境
目录 一、下载VScode 1. 在官网直接下载安装即可 2. 安装中文插件 二、下载C语言编译器MinGW-W64 三、配置编译器环境变量 1. 解压下载的压缩包,复制该文件夹下bin目录所在地址 2. 在电脑搜索环境变量并打开 3. 点击环境变量→选择系统变量里的Path→点击编…...
Qt creator实现一个简单计算器
目录 1 界面设计 2 思路简介 3 代码 目录 1 界面设计 2 思路简介 3 代码 3.1 widget.h 3.2 widget.c 4 完整代码 在这里主要记载了如何使用Qt creator完成一个计算器的功能。该计算器可以实现正常的加减乘除以及括号操作,能实现简单的计算器功能。 1 界…...

Java代码基础算法练习-计算被 3 或 5 整除数之和-2024.06.29
任务描述: 计算 1 到 n 之间能够被 3 或者 5 整除的数之和。 解决思路: 输入的数字为 for 循环总次数,每次循环就以当前的 i 进行 3、5 的取余操作,都成立计入总数sum中,循环结束,输出 sum 的值 代码示例&…...
核心代码讲解)
Socket编程详解(二)核心代码讲解
本文对代码的讲解基于上一篇博客 快速链接 Socket编程详解(一)服务端与客户端的双向对话 小试牛刀1:委托声明的关键字和委托方法使用的方法名是不一样的名称 可读性:有时,委托的名称可能描述了它的用途或它在哪里被…...

(项目实战)聚合支付系统开发环境搭建-基于VMware17安装Centos7.9
1 开发环境介绍 dtpay聚合支付系统和ecard预付卡系统,服务端部署在Linux环境。后续的开发环境,生产环境都是基于Linux进行搭建,系统使用到的相关中间件(RocketMQ,Redis,Nginx等),配置中心Nacos,数据库MySQ…...

Python现在可以在线编程了!
你好,我是郭震 1 在线编程 在线编程好处: 1 无需安装和配置环境: 在线编程平台不需要用户在本地安装任何软件或配置开发环境。这对初学者和那些希望快速上手进行编程的人非常有利。 2 跨平台兼容性: 这些平台可以在任何具有互联网连接的设备上使用&#…...

ThreadPoolExecutor线程池创建线程
线程池介绍 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源&#…...

畅谈GPT-5
前言 ChatGBT(Chat Generative Bidirectional Transformer)是一种基于自然语言处理技术的对话系统,它的出现是人工智能和自然语言处理技术发展的必然趋势。随着技术的更新和进步,GPT也迎来了一代代的更新迭代。 1.GPT的回顾 1.1 GPT-3的介绍 GPT-3(Gen…...

石家庄高校大学智能制造实验室数字孪生可视化系统平台项目验收
智能制造作为未来制造业的发展方向,已成为各国竞相发展的重点领域。石家庄高校大学智能制造实验室积极响应国家发展战略,结合自身优势,决定引进数字孪生技术,构建一个集教学、科研、生产于一体的可视化系统平台。 数字孪生可视化…...

WLAN 4-Way Handshake如何生成GTK?
关于Wi-Fi的加密认证过程,可以参考如下链接,今天我们来理解如何生成GTK。 WLAN数据加密机制_tls加密wifi-CSDN博客 1 GTK GTK(Group Temporal Key)是由AP通过GMK生成,长度为128位,并在四次握手的第三步中…...

Qt/C++模拟鼠标键盘输入
1、控制鼠标移动 (1)Qt方案 QScreen* sc QGuiApplication::primaryScreen(); QCursor* c new QCursor(); int deltaX 10; int deltaY 10; c->setPos(sc, c->pos().x() deltaX, c->pos().y() deltaY);(2)Windows原…...
OpenGL3.3_C++_Windows(22)
材质: 决定物体在渲染过程中最终视觉呈现的关键因素之一,它通过一系列光学(投光物)和物理参数(反光度,反照率、金属度,折射率……)准确模拟现实世界中的材料特性,从而增…...
electron-builder 打包过慢解决
报错内容如下 > 6-241.0.0 build > electron-builder • electron-builder version24.13.3 os10.0.22631 • loaded configuration filepackage.json ("build" field) • writing effective config filedist\builder-effective-config.yaml • pack…...

leetcode226反转二叉树
本文主要讲解反转二叉树的要点与细节,按照步骤思考更方便理解 c和java代码如下,末尾 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 具体要点: 1. 首先我们要理解题意, 反转二叉树具体…...
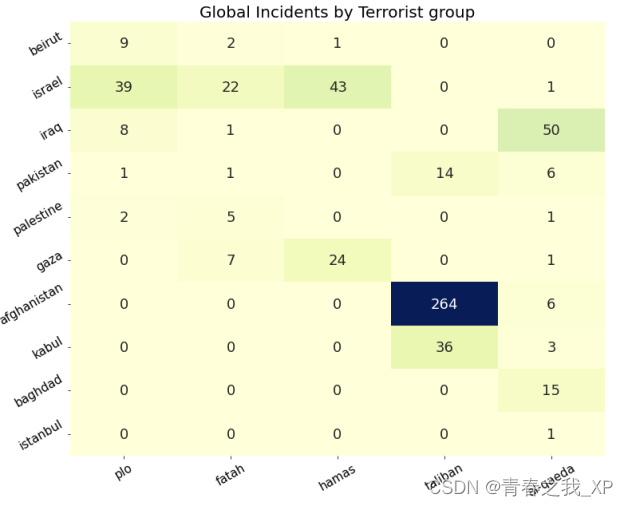
【自然语言处理系列】探索NLP:使用Spacy进行分词、分句、词性标注和命名实体识别,并以《傲慢与偏见》与全球恐怖活动两个实例文本进行分析
本文深入探讨了scaPy库在文本分析和数据可视化方面的应用。首先,我们通过简单的文本处理任务,如分词和分句,来展示scaPy的基本功能。接着,我们利用scaPy的命名实体识别和词性标注功能,分析了Jane Austen的经典小说《傲…...

【Rust】function和methed的区别
文章目录 functionmethedAssociated Functions 参考资料 一句话总结: function和methed很多都是相同的。 不同点在于: methed定义在结构体里面,并且它的第一个参数肯定是self,代表结构体实例。方法需要用实例名.方法名调用当然结…...

python基础语法 003-4 数据类型集合
1 集合 1.1 什么是集合 什么是集合?ANS:集合set是一个无序的不重复元素序列集合怎么表示?ANS: {} , 用逗号隔开打印元组类型,type()一个元素的集合怎么表示?:ANS:存储多种类型{"a", 1} """…...

重新定义下载体验:ctfileGet城通网盘高速下载完整指南
重新定义下载体验:ctfileGet城通网盘高速下载完整指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾经面对城通网盘几十KB/s的下载速度感到绝望?当急需一个大文件时&a…...
)
从选型到调参:伺服电机刚性、惯量比实战避坑指南(以台达/三菱为例)
伺服电机系统实战:从刚性调节到三环控制的深度优化 在工业自动化领域,伺服系统的性能直接决定了设备的精度与效率。去年参与的一个CNC机床改造项目中,我们遇到了一个典型问题:在加工复杂曲面时,机械臂末端总是出现微米…...

基于MCP协议与Playwright的AI智能体网页抓取工具部署与实战
1. 项目概述:一个为AI智能体打造的“网页抓取工具箱” 如果你正在开发或使用基于MCP(Model Context Protocol)的AI智能体,并且经常需要让它们从网页上获取结构化数据,那么你很可能已经遇到了一个核心痛点: …...

CSS Flexbox 布局高级技巧完全指南
CSS Flexbox 布局高级技巧完全指南 引言 Flexbox 是现代 CSS 布局的核心技术之一,它提供了一种一维布局方式,让开发者能够轻松实现灵活的响应式布局。本文将深入探讨 Flexbox 的高级特性和实用技巧。 Flexbox 基础回顾 在深入高级技巧之前,让…...

把轻量接口做成真正可用的业务入口,聊透 ABAP HTTP Service Editor 的开发节奏
做 ABAP 集成时,经常会碰到这样一类需求,外部系统只想调用一个很轻的 URL,拿一段文本、一个健康检查结果、一个简单的回调响应,或者把某个小型业务动作推到 ABAP 后端里。这个时候,很多人脑子里冒出来的还是 RAP、Service Binding、Gateway,甚至直接跳到 SICF 手工找节点…...

鸣潮自动化终极指南:5分钟解放双手,告别重复刷图
鸣潮自动化终极指南:5分钟解放双手,告别重复刷图 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves ok-ww 是一…...

OpenClaw + Claude Code 插件:多 Agent 协作开发,到底解决了什么,没解决什么?
先说结论多 Agent Council 适合复杂项目,但简单任务直接用 CLI 更高效。混合引擎能发挥不同模型优势,但协调成本和 API 费用不容忽视。持久会话和工具 API 提升了开发体验,但需注意 API Key 计费而非订阅额度。从实际选型角度,拆解…...

嵌入式GUI设计:硬件选型与OpenGL优化实战
1. 嵌入式GUI设计的核心价值与市场驱动力在智能设备爆发的时代,嵌入式图形用户界面(GUI)已经从"锦上添花"变成了"不可或缺"的核心竞争力。我亲历过多个项目,那些仅关注硬件性能而忽视交互体验的产品ÿ…...

Cursor AI编辑器离线资源库:解决网络依赖,实现内网与定制化开发
1. 项目概述:一个AI代码编辑器的离线资源库最近在折腾Cursor这个AI代码编辑器,发现它确实能极大提升开发效率。但有个问题一直困扰着不少开发者:它的AI功能高度依赖网络,一旦网络环境不佳,或者你想在特定场景下&#x…...

第十一节:私有知识大脑——为本地 Agent 构建企业级 RAG 检索增强链路
引言 承接上一章我们对 embedding 和向量检索的实战部署,本章将聚焦打造私有知识大脑,通过构建完整的 RAG(Retrieval-Augmented Generation)检索增强链路,极大拓展本地 Agent 在企业场景的应用边界。 核心理论 RAG 是实现大模型实时访问和利用外部知识的关键技术,其数…...