Hadoop 安装与伪分布的搭建
目录
1 SSH免密登录
1.1 修改主机名称
1.2 修改hosts文件
1.3 创建hadoop用户
1.4 生成密钥对免密登录
2 搭建hadoop环境与jdk环境
2.1 将下载好的压缩包进行解压
2.2 编写hadoop环境变量脚本文件
2.3 修改hadoop配置文件,指定jdk路径
2.4 查看环境是否搭建完成
3 hadoop的启动
3.1 Hadoop 启动需要修改的配置文件
3.2 配置文件的修改
1、core-site.xml
2、hdfs-site.xml
3、mapred-site.xml
4、yarn-site.xml
3.3 启动hadoop与权限修改
3.4 再次启动hadoop
Rocky Linux 9.4 (CentOS同样适用)
hadoop版本 3.3.6
java : jdk1.8
1 SSH免密登录
1.1 修改主机名称
[root@localhost ~]# hostnamectl set-hostname hadoop
退出重新登录
[root@localhost ~]# exit
1.2 修改hosts文件

[root@hadoop ~]# vim /etc/hosts

1.3 创建hadoop用户
[root@hadoop ~] useradd -m hadoop -s /bin/bash
[root@hadoop ~] ls /home/
hadoop rocky
# 设置用户密码
[root@hadoop ~] passwd hadoop
更改用户 hadoop 的密码 。
新的密码:
重新输入新的密码:
passwd:所有的身份验证令牌已经成功更新。
[root@hadoop ~] ssh hadoop@hadoop
hadoop@hadoop's password:
Last failed login: Sat Jun 29 15:08:33 CST 2024 from 192.168.239.131 on ssh:notty
There were 2 failed login attempts since the last successful login.
[hadoop@hadoop ~]$ exit
注销
1.4 生成密钥对免密登录
使用su - hadoop 登录hadoop 账户
[root@hadoop /]# su - hadoop# 创建秘钥对,为免密登录做准备
[hadoop@hadoop ~]$ ssh-keygen -t rsa -b 4096
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:NVZ+2Ur09zHUadG9KMNkwOnh1wodT3SUpR9ae6xM+wo hadoop@hadoop1
The key's randomart image is:
+---[RSA 4096]----+
| ..o o.o=X|
| + * ooO+|
| o X * B==|
| * B *o=B|
| S o +.o.=|
| . o o.|
| E + |
| . . |
| ...|
+----[SHA256]-----+[hadoop@hadoop ~]$ ssh-copy-id root@hadoop
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop1's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'root@hadoop1'"
and check to make sure that only the key(s) you wanted were added.# 给本机免密登录
[hadoop@hadoop1 ~]$ ssh-copy-id hadoop
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@hadoop1's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop1'"
and check to make sure that only the key(s) you wanted were added.# 测试免密登录是否成功
[hadoop@hadoop1 ~]$ ssh hadoop1
Last login: Sat Jun 29 15:32:19 2024 from fe80::20c:29ff:fe33:d160%ens160
[hadoop@hadoop1 ~]$ exit
注销
命令行输入 ssh hadoop 不需要密码即成功

2 搭建hadoop环境与jdk环境
2.1 将下载好的压缩包进行解压
解压路径为
hadoop : /opt/hadoop
jdk : /opt/jdk
[root@hadoop ~] ls
hadoop-3.3.6.tar.gz jdk-8u162-linux-x64.tar.gz 公共 模板 视频 图片 文档 下载 音乐 桌面 anaconda-ks.cfg test[root@hadoop ~] mkdir -p /opt/jdk
[root@hadoop ~] mkdir -p /opt/hadoop
[root@hadoop ~] tar -xzf jdk-8u162-linux-x64.tar.gz -C /opt/jdk
[root@hadoop ~] tar -xzf hadoop-3.3.6.tar.gz -C /opt/hadoop
[root@hadoop ~] cd /opt
[root@hadoop opt] ls
hadoop jdk rh soft
2.2 编写hadoop环境变量脚本文件
添加路径到path环境变量中
[hadoop@hadoop ~]$ exit
[root@hadoop ~] # vim /etc/profile.d/hadoop-eco.sh
创建脚本文件,加入以下环境变量路径
JAVA_HOME=/opt/jdk
PATH=$JAVA_HOME/bin:$PATHHADOOP_HOME=/opt/hadoop
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH# HADOOP_USER
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
export HDFS_JOURNALNODE_USER=hadoop
export HDFS_ZKFC_USER=hadoop
HDFS_NAMENODE_USER=hadoop:指定HDFS NameNode服务的运行用户。NameNode负责管理文件系统的命名空间,包括文件和目录的元数据。
HDFS_DATANODE_USER=hadoop:指定HDFS DataNode服务的运行用户。DataNodes存储实际的数据块,是HDFS数据存储的主要组成部分。
HDFS_SECONDARYNAMENODE_USER=hadoop:指定HDFS Secondary NameNode服务的运行用户。Secondary NameNode并不存储集群的实时状态,但它定期合并NameNode的fsimage和editlogs文件,减少NameNode的启动时间。
YARN_RESOURCEMANAGER_USER=hadoop:指定YARN ResourceManager服务的运行用户。ResourceManager是YARN中的主控服务,负责集群资源的分配和管理工作。
YARN_NODEMANAGER_USER=hadoop:指定YARN NodeManager服务的运行用户。NodeManagers运行在每个集群节点上,负责容器的生命周期管理。
HDFS_JOURNALNODE_USER=hadoop:指定HDFS JournalNode服务的运行用户。JournalNodes用于在HA(High Availability)配置中存储NameNode状态的编辑日志,以保证数据的一致性。
HDFS_ZKFC_USER=hadoop:指定ZooKeeper Failover Controller(ZKFC)的运行用户。ZKFC用于监控NameNode的状态,并在检测到故障时触发failover,切换到备用NameNode。通过设置这些环境变量,你确保了Hadoop的各个服务将以
hadoop用户的身份运行,而不是以root或其他用户运行。这不仅增强了系统的安全性,还便于管理和审计。在Hadoop的启动脚本中,这些变量会被读取并应用到相应的服务启动过程中
2.3 修改hadoop配置文件,指定jdk路径
[root@hadoop ~]# vim /opt/hadoop/etc/hadoop/hadoop-env.sh
这个变量指定了 Java 的安装位置。Hadoop 依赖于 Java 运行,因此必须正确设置此变量,指向你的 Java 安装目录。
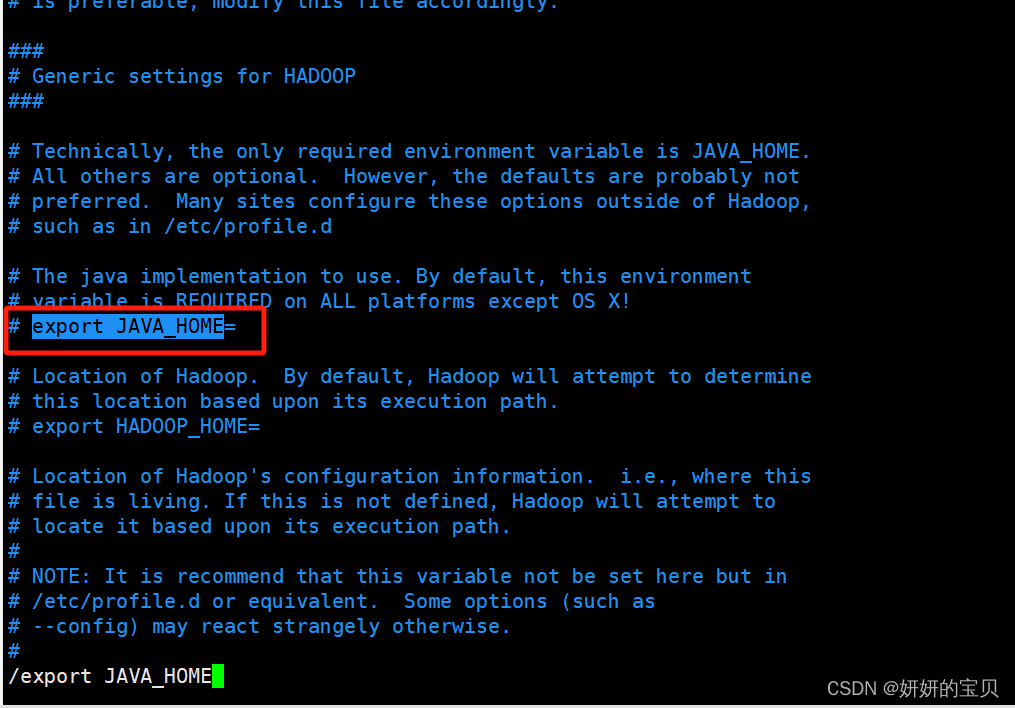
增加以下行,注意此路径为java环境变量的路径
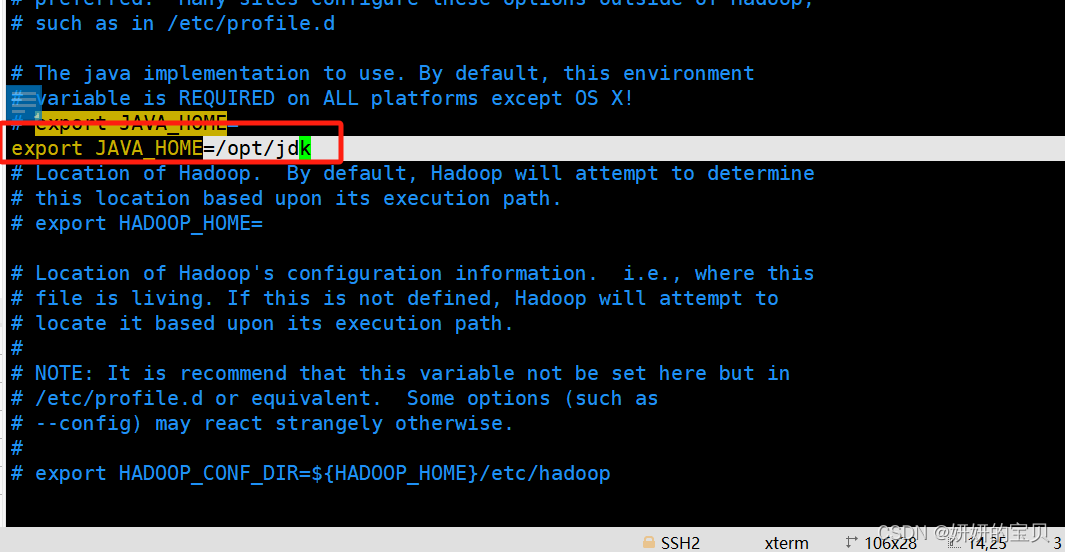
运行修改后的脚本
[root@hadoop ~] source /opt/hadoop/etc/hadoop/hadoop-env.sh2.4 查看环境是否搭建完成
输入hadoop version 和 java -version 查询版本号,检查环境是否配好
[root@hadoop ~] hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /opt/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
[root@hadoop ~] java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
3 hadoop的启动
3.1 Hadoop 启动需要修改的配置文件
1、core-site.xml
fs.defaultFS
hadoop.tmp.dir
2、hdfs-site.xml
dfs.replication => 1
dfs.namenode.name.dir
dfs.datanode.data.dir
3、mapred-site.xml
mapreduce.framework.name =>yarn
4、yarn-site.xml
yarn.resourcemanager.hostname => localhost
yarn.nodemanager.aux-services => mapreduce_shuffle
3.2 配置文件的修改
1、core-site.xml
[root@hadoop hadoop] vim /opt/hadoop/etc/hadoop/core-site.xml在configuration块中添加以下信息
<property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value>
</property>
<property><name>hadoop.tmp.dir</name><value>file:///opt/hadoop-record/tep</value>
</property>
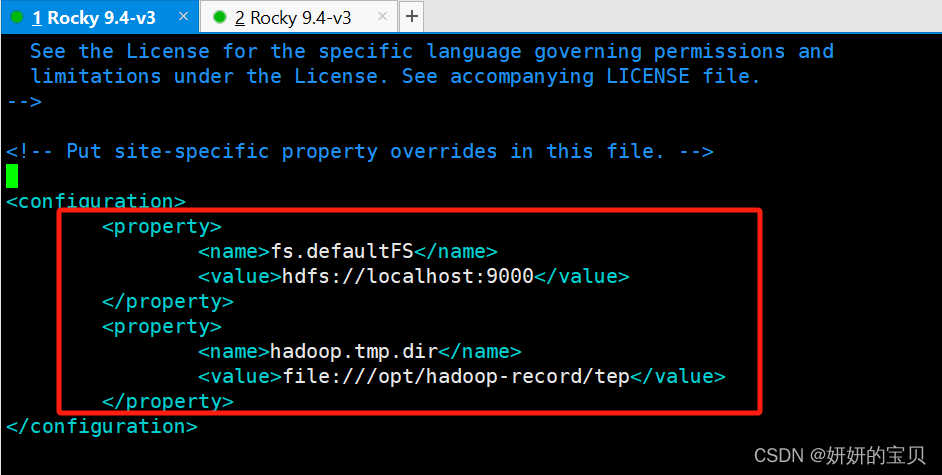
<configuration>这是Hadoop配置文件的根标签,用于包含所有的配置属性。
<property>这个标签用于定义一个具体的配置项,包括名称(
<name>)和值(<value>)两部分。
<name>fs.defaultFS</name>这个配置项指定了Hadoop的默认文件系统。在你的例子中,
hdfs://localhost:9000表示Hadoop将使用运行在本地主机上的Hadoop分布式文件系统(HDFS),端口号为9000。
<name>hadoop.tmp.dir</name>这个配置项定义了Hadoop存放临时文件的目录。这里设置为
file:///opt/hadoop-record/tep,意味着所有Hadoop产生的临时文件将存储在本地文件系统的/opt/hadoop-record/tep目录下。这些配置通常被写入到Hadoop的核心配置文件
core-site.xml中,该文件位于Hadoop的配置目录$HADOOP_HOME/etc/hadoop/内。通过修改这些配置,可以指定Hadoop如何存储数据以及临时文件的存放位置,这对于优化性能和管理数据至关重要。
2、hdfs-site.xml
[root@hadoop hadoop] vim /opt/hadoop/etc/hadoop/hdfs-site.xml在configuration块中添加以下配置
<property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:///opt/hadoop-record/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:///opt/hadoop-record/data</value></property>

<property>每一个
<property>标签都定义了一个具体的配置项,包括配置项的名称和对应的值。
<name>dfs.replication</name>
功能描述:此配置项决定了HDFS中数据块的默认复制因子。复制因子是指一个数据块在HDFS集群中存储的副本数量。
你的设置:你将其设置为
1,这意味着数据块只在一个节点上保存一份副本,不进行冗余备份。在生产环境中,这通常是不推荐的做法,因为如果存储数据的节点出现故障,数据可能会丢失。但在测试或开发环境中,为了节省资源,有时会采用这种方式。
<name>dfs.namenode.name.dir</name>
功能描述:此配置项指定了NameNode存储元数据信息的本地文件系统目录。
你的设置:将其设置为
file:///opt/hadoop-record/name,这意味着NameNode的元数据将存储在本地文件系统的/opt/hadoop-record/name目录下。
<name>dfs.datanode.data.dir</name>
功能描述:此配置项指定了DataNode存储实际数据块的本地文件系统目录。
你的设置:你将其设置为
file:///opt/hadoop-record/data,这意味着DataNode的数据块将存储在本地文件系统的/opt/hadoop-record/data目录下。
3、mapred-site.xml
[root@hadoop hadoop] vim /opt/hadoop/etc/hadoop/mapred-site.xml在configuration块中添加以下配置
<property><name>mapreduce.framework.name</name><value>yarn</value></property>

<configuration>这是Hadoop配置文件中的根元素,用于封装所有的配置项。
<property>此标签定义了一个具体的配置属性,包含了属性的名称和值。
<name>mapreduce.framework.name</name>
功能描述:此配置项指定了MapReduce作业执行时所依赖的资源管理和调度框架。在Hadoop生态系统中,YARN(Yet Another Resource Negotiator)是一个通用的资源管理系统,它不仅可以管理MapReduce作业,还可以支持其他类型的计算框架。
设置:将其设置为
yarn,这意味着MapReduce作业将通过YARN来进行资源管理和调度。这是Hadoop 2.x版本及以后版本的默认设置,YARN提供了一个更加灵活和强大的平台,允许多种计算框架共存于同一集群中。
4、yarn-site.xml
[root@hadoop hadoop] vim /opt/hadoop/etc/hadoop/yarn-site.xml 在configuration块中添加以下配置
<property><name>yarn.resourcemanager.hostname</name><value>localhost</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
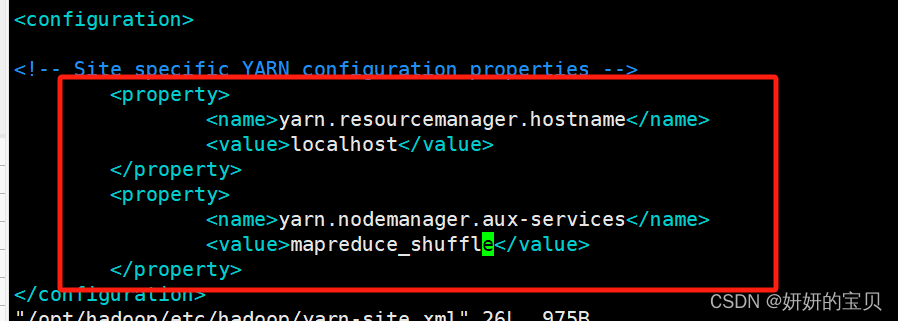
3.3 启动hadoop与权限修改
格式化namenode
[root@hadoop ~]# hdfs namenode -format
[root@hadoop ~]# start-all.sh
接下来启动hadoop会有可能发现以下问题,这是由于hadoop用户权限不足
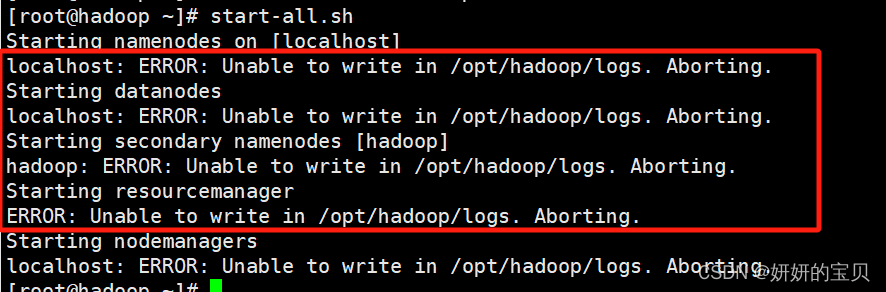
修改权限
[root@hadoop ~]# chown -R hadoop:hadoop /opt/hadoop
3.4 再次启动hadoop
[root@hadoop opt]# start-all.sh

jsp 命令输出显示了当前运行在你的 hadoop 节点上的 Java 进程及其进程ID(PID)
[root@hadoop opt]# jps
9824 NameNode
10738 NodeManager
13539 Jps
10020 DataNode
10582 ResourceManager
10329 SecondaryNameNode

关闭防火墙
[root@hadoop opt]# systemctl stop firewalld
浏览器打开虚拟机的ip+端口号
http://192.168.239.132:9870/

相关文章:
Hadoop 安装与伪分布的搭建
目录 1 SSH免密登录 1.1 修改主机名称 1.2 修改hosts文件 1.3 创建hadoop用户 1.4 生成密钥对免密登录 2 搭建hadoop环境与jdk环境 2.1 将下载好的压缩包进行解压 2.2 编写hadoop环境变量脚本文件 2.3 修改hadoop配置文件,指定jdk路径 2.4 查看环境是否搭建完成 3 …...
)
网络安全:渗透测试思路.(面试)
网络安全:渗透测试思路.(面试) 渗透测试,也称为 "pen testing",是一种模拟黑客攻击的网络安全实践,目的是评估计算机系统、网络或Web应用程序的安全性. 目录: 网络安全:…...

优化堆排序
优化堆排序 堆排序是一种基于比较的排序算法,它利用堆这种数据结构来进行排序。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。堆排序算法分为两个大的步骤:首先将待排序的序列构造成一个最大堆,此时,整个序…...

vue3使用一些组件的方法
iconpark...

OceanBase 4.2.1 离线安装
OceanBase 4.2.1 离线安装 4.2 版本的OceanBase支持一键安装,所以在线版本的安装简单了很多,但在无法连接网络的情况下安装就只能手动离线安装。 注:如下安装过程都是在同一台机器上面进行,也就是只有一个节点,多个节…...

ForkJoin
线程数超过CPU核心数是没有任何意义的【因为要使用CPU密集型运算】 Fork/Join:线程池的实现,体现是分治思想,适用于能够进行任务拆分的 CPU 密集型运算,用于并行计算 任务拆分:将一个大任务拆分为算法上相同的小任务…...
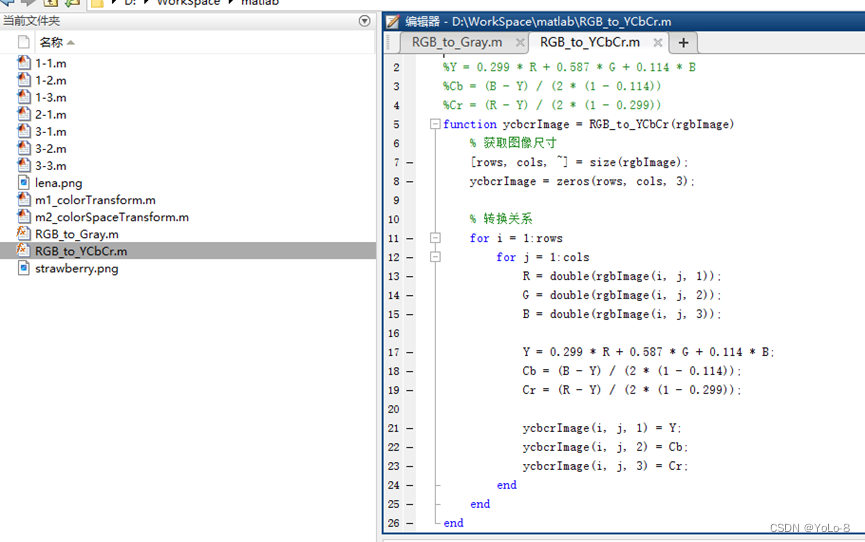
实验2 色彩模式转换
1. 实验目的 ①了解常用的色彩模式,理解色彩模式转换原理; ②掌握Photoshop中常用的颜色管理工具和色彩模式转换方法; ③掌握使用Matlab/PythonOpenCV编程实现色彩模式转换的方法。 2. 实验内容 ①使用Photoshop中的颜色管理工具ÿ…...
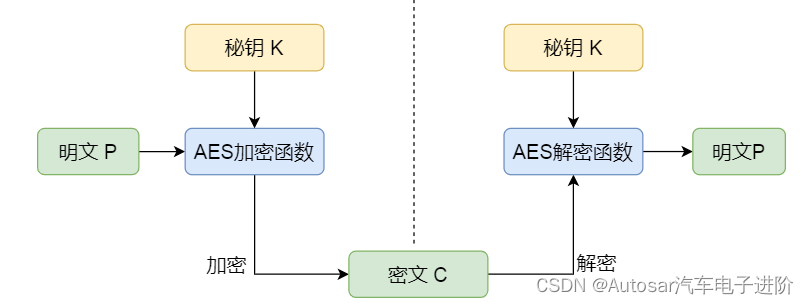
AES加密算法及AES-CMAC原理白话版系统解析
本文框架 前言1. AES加密理论1.1 不同AES算法区别1.2 加密过程介绍1.2.1 加密模式和填充方案选择1.2.2 密钥扩展1.2.3分组处理1.2.4多轮加密1.2.4.1字节替换1.2.4.2行移位1.2.4.3列混淆1.2.4.4轮密钥加1.3 加密模式1.3.1ECB模式1.3.2CBC模式1.3.3CTR模式1.3.4CFB模式1.3.5 OFB模…...

24年hvv前夕,微步也要收费了,情报共享会在今年结束么?
一个人走的很快,但一群人才能走的更远。吉祥同学学安全https://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247483727&idx1&sndb05d8c1115a4539716eddd9fde4e5c9&scene21#wechat_redirect这个星球🔗里面已经沉淀了: 《Ja…...

【地理库 Turf.js】
非常全面的地理库 , 这里枚举一些比较常用,重点的功能, 重点功能 提供地理相关的类:包括点,线,面等类。 测量功能:点到线段的距离,点和线的关系等。 判断功能: 点是否在…...
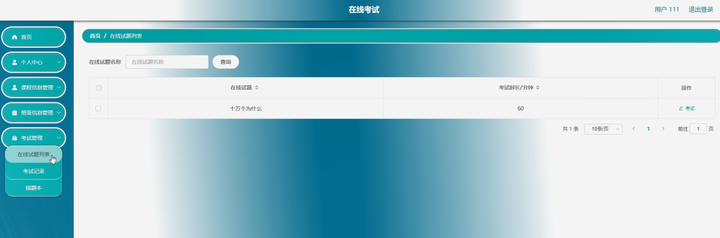
springboot在线考试 LW +PPT+源码+讲解
第三章 系统分析 3.1 可行性分析 一个完整的系统,可行性分析是必须要有的,因为他关系到系统生存问题,对开发的意义进行分析,能否通过本系统来补充线下在线考试管理模式中的缺限,去解决其中的不足等,通过对…...

JDBC中的事务及其ACID特性
在JDBC(Java Database Connectivity)中,事务(Transaction)是指作为单个逻辑工作单元执行的一系列操作。这些操作要么全部执行,要么全部不执行,从而确保数据库的完整性和一致性。事务是现代数据库…...

Python | Leetcode Python题解之第204题计数质数
题目: 题解: MX5000000 is_prime [1] * MX is_prime[0]is_prime[1]0 for i in range(2, MX):if is_prime[i]:for j in range(i * i, MX, i):#循环每次增加iis_prime[j] 0 class Solution:def countPrimes(self, n: int) -> int:return sum(is_prim…...
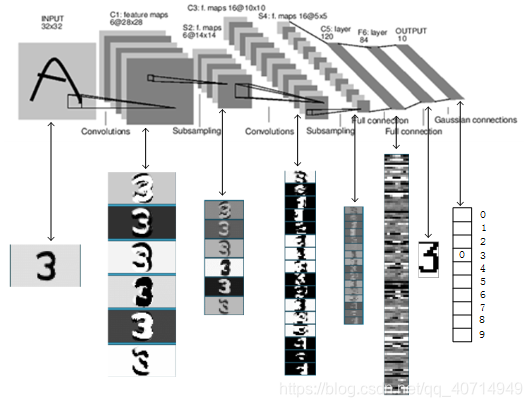
【课程总结】Day10:卷积网络的基本组件
前言 由于接下来的课程内容将围绕计算机视觉展开,其中接触最多的内容是卷积、卷积神经网络等…因此,本篇内容将从卷积入手,梳理理解:卷积的意义、卷积在图像处理中的作用以及卷积神经网络的概念,最后利用pytorch搭建一…...

ModuleNotFoundError: No module named ‘_sysconfigdata_x86_64_conda_linux_gnu‘
ModuleNotFoundError: No module named _sysconfigdata_x86_64_conda_linux_gnu 1.软件环境⚙️2.问题描述🔍3.解决方法🐡4.结果预览🤔 1.软件环境⚙️ Ubuntu 20.04 Python 3.7.0 2.问题描述🔍 今天发现更新conda之后࿰…...
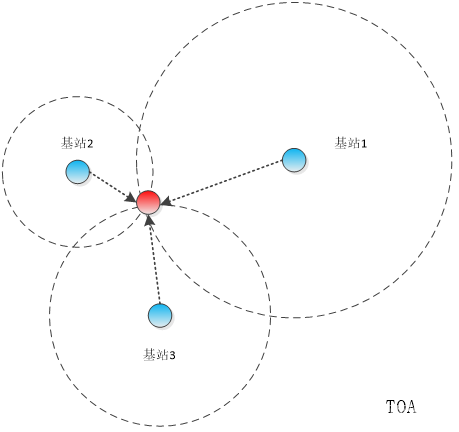
【物联网】室内定位技术及定位方式简介
目录 一、概述 二、常用的室内定位技术 2.1 WIFI技术 2.2 UWB超宽带 2.3 蓝牙BLE 2.4 ZigBee技术 2.5 RFID技术 三、常用的室内定位方式 3.1 信号到达时间 3.2 信号到达时间差 3.3 信号到达角 3.4 接收信号强度 一、概述 GPS是目前应用最广泛的定位技术࿰…...
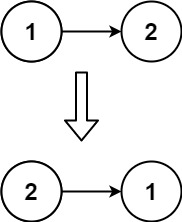
Leetcode[反转链表]
LCR 024. 反转链表 给定单链表的头节点 head ,请反转链表,并返回反转后的链表的头节点。 示例 1: 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1]示例 2: 输入:head [1,2] 输出:[2,1]示…...

【差分数组】个人练习-Leetcode-2249. Count Lattice Points Inside a Circle
题目链接:https://leetcode.cn/problems/count-lattice-points-inside-a-circle/description/ 题目大意:给出一系列圆的圆心坐标和半径,求在这些圆内部(边缘也算)的格点的数量。 思路:简单的思路就是暴力…...

【JavaEE】Cookie和Session详解
一.Cookie 首先我们知道HTTP协议本身是’‘无状态’‘的, 这里的’‘无状态’指的是:默认情况下HTTP协议的客户端和服务器之间的这次通信,和下次通信之间没有直接的联系. 但是在实际的开发过程之中, 我们很多时候是需要知道请求之间的关联关系的. 例如登陆网站成功后,第二次访…...

uniapp canvas vue3 ts实例
<template><view><canvas canvas-idcanvas-test class"canvas-test"></canvas></view> </template><script setup lang"ts">//封装的jsimport libs from /libs;//重点引入的import type { ComponentInternalIns…...

一键获取Steam游戏清单:Onekey工具让游戏管理变得如此简单
一键获取Steam游戏清单:Onekey工具让游戏管理变得如此简单 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 你是否曾为管理Steam游戏文件而烦恼?想备份心爱的游戏却不知从…...

Linuxbonding链路稳定性治理方法
Linuxbonding链路稳定性治理方法这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限…...

All in Token,三个运营商建Token工厂,中国移动跟进Token经营 三大运营商争夺AI阵地
随着Token(词元)经营战略的密集落地,三大运营商在AI领域的竞争愈发激烈。在日前举行的2026移动云大会上,中国移动正式发布了Token运营生态体系与移动模型服务平台MoMA,宣布接入超300款模型,并通过Token集约…...

合宙Air153C看门狗芯片:嵌入式系统可靠性的硬件守护方案
1. 项目概述:一颗“小而美”的国产看门狗芯片最近在做一个低功耗的户外监测设备项目,主控用的就是合宙的Air系列MCU。在调试过程中,最让我头疼的就是系统偶尔的“死机”问题。设备部署在野外,不可能每次都跑过去手动重启。正当我琢…...

基于AutoHotkey的Windows桌面自动化工具开发实战
1. 项目概述与核心价值最近在整理个人项目库时,翻到了一个挺有意思的“老伙计”——cua_desktop_operator_skill。这个项目名听起来有点拗口,直译过来是“CUA桌面操作员技能”。乍一看,可能会让人联想到某种工业控制台的专用软件。但实际上&a…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

基于Panel与LLM构建智能数据可视化应用的架构与实践
1. 项目概述与核心价值最近在数据可视化与交互应用开发领域,一个名为holoviz-topics/panel-chat-examples的项目仓库引起了我的注意。乍一看,这似乎只是将聊天界面(Chat Interface)与 Panel 这个强大的 Python 交互式仪表盘库结合…...

SVG与CSS变量驱动的自动化品牌视觉生成技术实践
1. 项目概述:一分钟品牌塑造的实践宝库在品牌营销和创意设计领域,一个常见的痛点是如何快速、高效地生成高质量的视觉品牌资产。无论是初创公司需要一个临时的Logo,还是内容创作者想为新的系列视频设计一个统一的片头,传统的品牌设…...

揭秘GPT超级提示工程:从原理到实战,打造高效AI协作指南
1. 项目概述:当“Awesome”遇见“Super Prompting”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫“CyberAlbSecOP/Awesome_GPT_Super_Prompting”。光看这名字,就透着一股“硬核”和“集大成”的味道。作为一个长期和各类大语…...

提示工程实战:从核心模式到高级技巧的AI交互优化指南
1. 项目概述:从代码仓库到提示工程实战指南最近在GitHub上看到一个名为“SKY-lv/prompt-engineer”的仓库,点进去一看,发现这不仅仅是一个简单的代码集合,更像是一位资深从业者(SKY-lv)精心整理的提示工程实…...