install nebula with source
linux 环境:ubuntu 2004
默认gcc 7.5
nebula requerment: g++ 8.5 above
下载source
git clone --branch release-3.8 https://github.com/vesoft-inc/nebula.git
install gcc g++ 11
apt install gcc-11 g++-11
此时 linux环境存在多个版本gcc:7,9.11
查看 gcc --version,显示仍然是7.5.这种情况需要如下配置:
1.
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-11 110 --slave /usr/bin/g++ g++ /usr/bin/g++-11 --slave /usr/bin/gcov gcov /usr/bin/gcov-11
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 70 --slave /usr/bin/g++ g++ /usr/bin/g++-7 --slave /usr/bin/gcov gcov /usr/bin/gcov-7
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 90 --slave /usr/bin/g++ g++ /usr/bin/g++-9 --slave /usr/bin/gcov gcov /usr/bin/gcov-9
2.
sudo update-alternatives --config gcc
选择:0
(base) root@ubuntu:/usr/bin# sudo update-alternatives --config gcc
There are 3 choices for the alternative gcc (providing /usr/bin/gcc).Selection Path Priority Status
------------------------------------------------------------
* 0 /usr/bin/gcc-11 110 auto mode
1 /usr/bin/gcc-11 110 manual mode
2 /usr/bin/gcc-7 70 manual mode
3 /usr/bin/gcc-9 90 manual modePress <enter> to keep the current choice[*], or type selection number:
install three part
$ cd nebula/third-party $ ./install-third-party.sh
服务器下载文件失败,从本地下载:
curl https://oss-cdn.nebula-graph.com.cn/third-party/3.3/vesoft-third-party-3.3-x86_64-libc-2.31-gcc-11.2.0-abi-11.sh --output D:\vesoft-third-party-3.3-x86_64-libc-2.31-gcc-11.2.0-abi-11.sh
将文件上传到nebula/thirdpart/
bash vesoft-third-party-3.3-x86_64-libc-2.31-gcc-11.2.0-abi-11.sh
输出:
Nebula Third Party has been installed to /opt/vesoft/third-party/3.3
make
cd ..
mkdir build && cd buildcmake -DCMAKE_INSTALL_PREFIX=/usr/local/nebula -DENABLE_TESTING=OFF -DCMAKE_BUILD_TYPE=Release ..
加快mk速度:

查看CPU核数:
(base) root@ubuntu:/data/nebula3.8/nebula/build# cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
32
(base) root@ubuntu:/data/nebula3.8/nebula/build# cat /proc/cpuinfo| grep "cpu cores"| uniq
cpu cores : 1
(base) root@ubuntu:/data/nebula3.8/nebula/build# cat /proc/cpuinfo| grep "processor"| wc -l
32
(base) root@ubuntu:/data/nebula3.8/nebula/build# free
total used free shared buff/cache available
Mem: 65845892 1874080 12186732 6240 51785080 63268188
衡量内存和CPU数据,确认N为32
N = 32
参考:make -j{N} # E.g., make -j2
执行下面命令:make -j32
创建配置文件三个:
cd /usr/local/nebula/etc
cp nebula-graphd.conf.default nebula-graphd.conf
cp nebula-metad.conf.default nebula-metad.conf
cp nebula-storaged.conf.default nebula-storaged.conf
启动服务:
sudo /usr/local/nebula/scripts/nebula.service start all
netstat -nplt
(base) root@ubuntu:/usr/local/nebula/etc# netstat -nplt
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:19559 0.0.0.0:* LISTEN 1909079/nebula-meta
tcp 0 0 127.0.0.1:44041 0.0.0.0:* LISTEN 1658097/python
tcp 0 0 127.0.0.1:40495 0.0.0.0:* LISTEN 1658097/python
tcp 0 0 127.0.0.1:60975 0.0.0.0:* LISTEN 1658097/python
tcp 0 0 127.0.0.1:50707 0.0.0.0:* LISTEN 1658097/python
tcp 0 0 10.255.132.22:60020 0.0.0.0:* LISTEN 1740/./gse_agent
tcp 0 0 0.0.0.0:19669 0.0.0.0:* LISTEN 1909140/nebula-grap
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 938/systemd-resolve
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1119/sshd: /usr/sbi
tcp 0 0 127.0.0.1:43799 0.0.0.0:* LISTEN 1658097/python
tcp 0 0 0.0.0.0:8701 0.0.0.0:* LISTEN 1657354/python
tcp 0 0 127.0.0.1:46655 0.0.0.0:* LISTEN 1658097/python
tcp6 0 0 :::9669 :::* LISTEN 1909140/nebula-grap
tcp6 0 0 :::9835 :::* LISTEN 1037/nvidia_gpu_exp
tcp6 0 0 :::9100 :::* LISTEN 1044/node_exporter
tcp6 0 0 :::22 :::* LISTEN 1119/sshd: /usr/sbi
tcp6 0 0 :::9559 :::* LISTEN 1909079/nebula-meta
tcp6 0 0 :::9560 :::* LISTEN 1909079/nebula-meta
tcp6 0 0 :::3000 :::* LISTEN 2130337/grafana
tcp6 0 0 :::8701 :::* LISTEN 1657354/python
服务管理:参考
$ sudo /usr/local/nebula/scripts/nebula.service
[-v] [-c <config_file_path>]
<start | stop | restart | kill | status>
<metad | graphd | storaged | all>
检查状态:
(base) root@ubuntu:/usr/local/nebula/etc# sudo /usr/local/nebula/scripts/nebula.service status all
[WARN] The maximum files allowed to open might be too few: 1024
[INFO] nebula-metad(fa928930a): Running as 1909079, Listening on 9559
[INFO] nebula-graphd(fa928930a): Running as 1909140, Listening on 9669
[WARN] nebula-storaged after v3.0.0 will not start service until it is added to cluster.
[WARN] See Manage Storage hosts:ADD HOSTS in https://docs.nebula-graph.io/
[INFO] nebula-storaged(fa928930a): Running as 1909205, Listening on 9779
下载 nebula-console 二进制文件:
https://github.com/vesoft-inc/nebula-console/releases/download/v3.8.0/nebula-console-linux-amd64-v3.8.0
起名为:nebula-console-shell
chmod 777 nebula-console-shell
链接数据库:
sudo ./nebula-console-shell -addr 127.0.0.1 -port 9669 -u root -p nebula
退出 “:quit”
相关文章:

install nebula with source
linux 环境:ubuntu 2004 默认gcc 7.5 nebula requerment: g 8.5 above 下载source git clone --branch release-3.8 https://github.com/vesoft-inc/nebula.git install gcc g 11 apt install gcc-11 g-11 此时 linux环境存在多个版本gcc:…...

拆分盘投资策略解析:机制、案例与风险考量
一、引言 随着互联网技术的迅猛发展和金融市场的不断创新,拆分盘这一投资模式逐渐崭露头角,成为投资者关注的焦点。它基于特定的拆分策略,通过调整投资者持有的份额和单价,实现了看似稳健的资产增长。本文旨在深入探讨拆分盘的运…...

Redis主从复制、哨兵模式以及Cluster集群
一.主从复制 1.主从复制的概念 主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master),后者称为从节点(Slave);数据的复制是单向的,只能由主节点到从节点。默认情况下,…...

【chatgpt】npy文件和npz文件区别
npy文件和npz文件都是用于存储NumPy数组的文件格式。它们的主要区别如下: npy文件:这种文件格式用于存储单个NumPy数组。它是一种简单的二进制文件格式,可以快速地读写NumPy数组。 npz文件:这种文件格式是一个压缩包,…...

为什么IP地址会被列入黑名单?
您是否曾经历过网站访客数量骤减或电子邮件投递失败的困扰?这背后或许隐藏着一个常被忽略的原因:您的IP地址可能已经被列入了黑名单内。尽管您并没有进行任何违法的网络操作,但这个问题依然可能出现。那么,究竟黑名单是什么&#…...

【OceanBase诊断调优】—— 如何查找表被哪些其它表引用外键
本文详述如何查找指定表是否被其他表引用做外键。 适用版本 OceanBase 数据库所有版本。 MySQL 租户 obclient> select * from INFORMATION_SCHEMA.KEY_COLUMN_USAGE where REFERENCED_TABLE_NAME表名;Oracle 租户 obclient> SELECT TABLE_NAME FROM dba_constraint…...
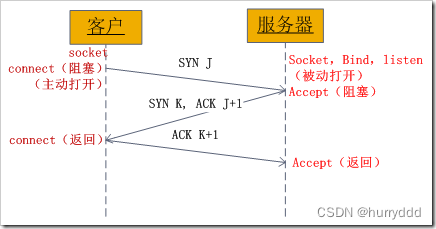
网络编程常见问题
1、TCP状态迁移图 2、TCP三次握手过程 2.1、握手流程 1、TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态; 2、TCP客户进程也是先创建传输控制块TCBÿ…...

回调函数的使用详解
实际工作中,经常使用回调函数。用来实现触发等机制,也是基于一些已开发好的底层平台,开发上层应用的常用方法。下面对回调函数做一个详细的解释。 目录 1. 简单的回调函数实例 2. C11,使用function<>的写法 3. 注册函数 …...
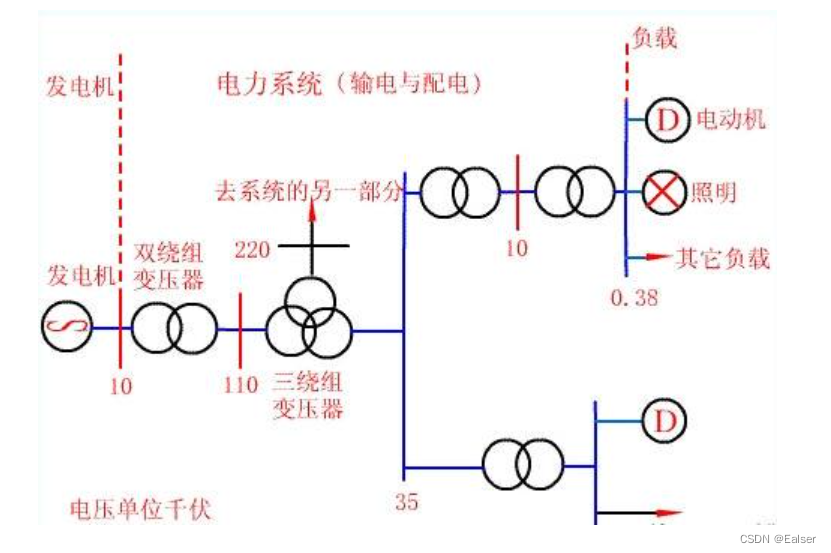
<电力行业> - 《第8课:输电(一)》
1 输电环节的意义 电能的传输,是电力系统整体功能的重要组成环节。发电厂与电力负荷中心通常都位于不同地区。在水力、煤炭等一次能源资源条件适宜的地点建立发电厂,通过输电可以将电能输送到远离发电厂的负荷中心,使电能的开发和利用超越地…...

【python学习】 __pycache__ 文件是什么
__pycache__文件是Python中的一个特殊目录,主要用于存储已编译的字节码文件(.pyc文件)。以下是关于__pycache__文件的详细解释: 作用:当Python解释器执行一个模块时,它会首先检查是否存在对应的.pyc文件。…...
论文阅读_基本于文本嵌入的信息提取
英文名:Embedding-based Retrieval with LLM for Effective Agriculture Information Extracting from Unstructured Data 中文名:基于嵌入的检索,LLM 从非结构化数据中提取有效的农业信息 地址: https://arxiv.org/abs/2308.03107 时间&…...

kafka学习笔记08
Springboot项目整合spring-kafka依赖包配置 有这种方式,就是可以是把之前test里的配置在这写上,用Bean注解上。 现在来介绍第二种方式: 1.添加kafka依赖: 2.添加kafka配置方式: 编写代码发送消息: 测试: …...

Flask的 preprocess_request
理解 Flask 类似框架中的 preprocess_request 方法 在 Flask 类似的 web 框架中,preprocess_request 方法是一个关键组件。它在请求被分派之前调用,用于执行一些预处理操作。让我们一步一步来理解这个方法的工作原理。 1. 方法概述 首先,我…...
)
重温react-05(类组件生命周期和性能优化)
类组件的生命周期 import React, { Component } from reactexport default class learnReact05 extends Component {state {number: 1}render() {return (<div>{this.state.number}</div>)}// 一般将请求的方法,放在这个生命周期componentDidMount() {setInterva…...
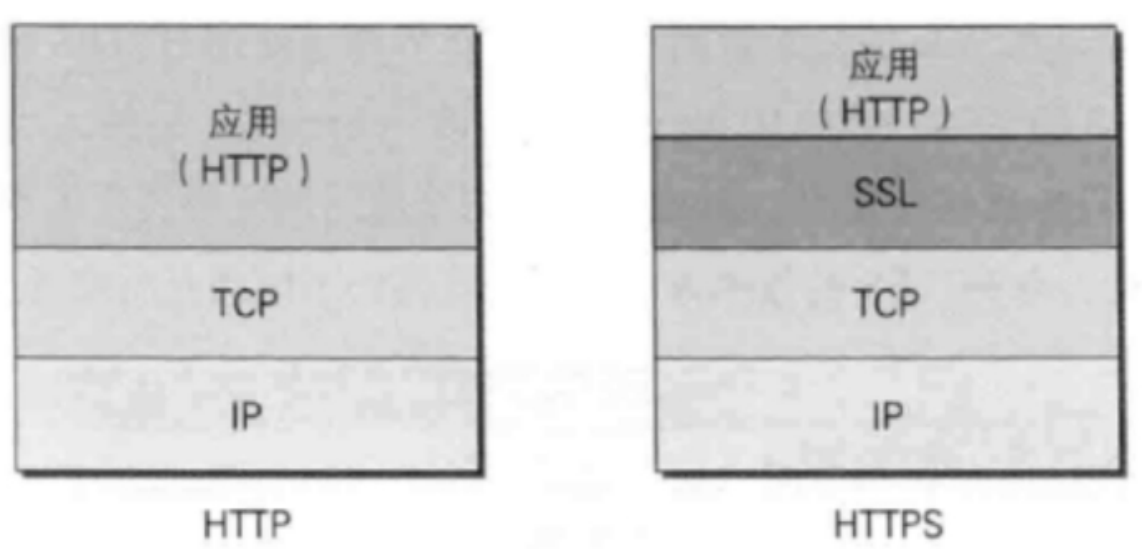
RHCE四---web服务器的高级优化方案
一、Web服务器(2) 基于https协议的静态网站 概念解释 HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer 或 Hypertext TransferProtocol Secure,超文本传输安全协议),是以…...
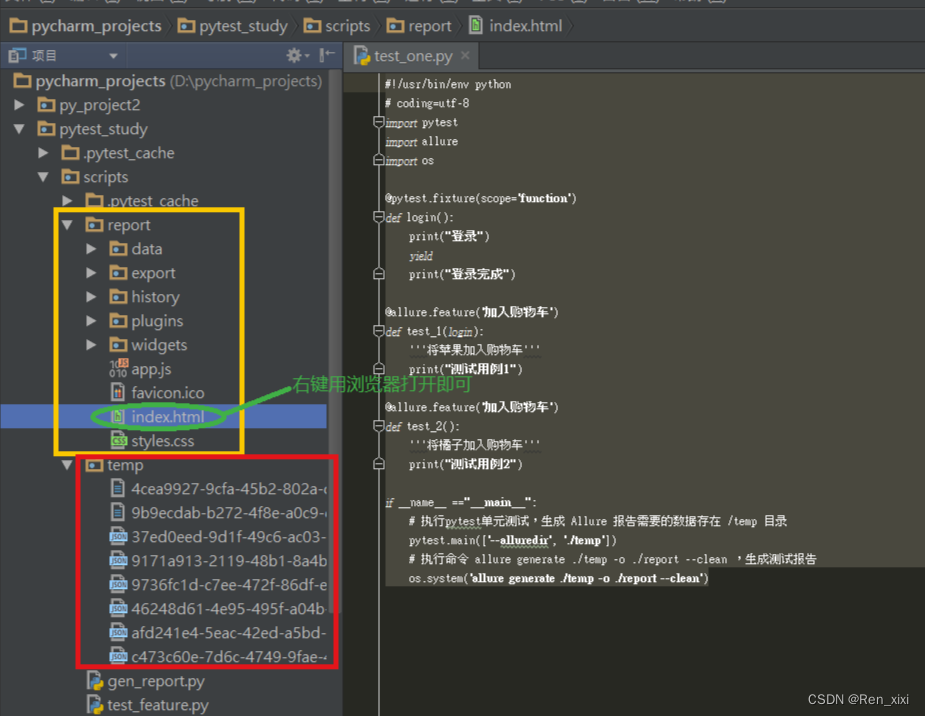
Pytest集成Allure生成测试报告
# 运行并输出报告在Report文件夹下 查看生成的allure报告 1. 生成allure报告:pycharm terminal中输入命令:产生报告文件夹 pytest -s --alluredir../report 2. pycharm terminal中输入命令:查看生成的allure报告 allure serve ../report …...

SpringBoot 参数校验
参数校验 引入springvalidation依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-validation</artifactId> </dependency>参数前添加Pattern public Result registry(Pattern(regexp &qu…...

【Arduino】实验使用ESP32控制可编程继电器制作跑马灯(图文)
今天小飞鱼实验使用ESP控制继电器,为了更好的掌握继电器的使用方法这里实验做了一个跑马灯的效果。 这里用到的可编程继电器,起始原理并不复杂,同样需要ESP32控制针脚输出高电平或低电平给到继电器,继电器使用这个信号控制一个电…...

islower()方法——判断字符串是否全由小写字母组成
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 语法参考 islower()方法用于判断字符串是否由小写字母组成。islower()方法的语法格式如下: str.islower() 如果字符串中包含至少一个区…...

发布/订阅模式
实现发布/订阅模式的基本思路是通过一个中介者(发布者)来管理订阅者(监听器),并在特定事件发生时通知所有订阅者执行相应的操作。下面是实现发布/订阅模式的基本思路: 创建发布者对象:首先&…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

终极免费城通网盘直连解析工具:告别下载限速的完整指南
终极免费城通网盘直连解析工具:告别下载限速的完整指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载速度慢、等待时间长而烦恼吗?ctfileGet是一款专为城通…...

ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析
ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款运行在Windows内核模式的驱…...

数据分析师能力展示:从项目构建到报告呈现的完整指南
1. 项目概述:一个数据分析师的能力展示平台最近在GitHub上看到一个挺有意思的项目,叫“dataanalyst-showcase”。光看名字,你可能会觉得这又是一个数据科学项目合集,但点进去仔细研究后,我发现它的定位非常精准——它不…...
)
Tea印相失效诊断清单:从--v 6.2到--v 6.6,6个版本兼容性断点及降级回滚方案(含JSON config快照备份包)
更多请点击: https://intelliparadigm.com 第一章:Tea印相失效诊断清单:从--v 6.2到--v 6.6,6个版本兼容性断点及降级回滚方案(含JSON config快照备份包) Tea印相(TeaYinXiang)在 v…...

Argo Workflows:Kubernetes原生工作流引擎从入门到生产实践
1. 项目概述:一个开源的容器化工作流引擎如果你在云原生、数据科学或者自动化运维领域摸爬滚打过一阵子,大概率听说过 Argo。它不是某个游戏里的角色,而是一个在 Kubernetes 生态中,用来编排和运行复杂工作流的强大引擎。简单来说…...

构建个人技能图谱:从结构化设计到自动化可视化的实践指南
1. 项目概述:一个技能图谱的诞生最近在GitHub上看到一个挺有意思的项目,叫dortort/skills。初看这个仓库名,你可能会有点懵,dortort是作者,那skills是什么?点进去一看,发现它不是一个具体的工具…...

017、Docker在TinyML开发中的应用
017 Docker在TinyML开发中的应用 从一次“环境地狱”说起 上个月帮团队调一个STM32上的TinyML推理延迟问题,模型是MobileNetV2量化版,在开发板上跑得好好的,换到同事的Ubuntu 20.04机器上编译,死活链接不上CMSIS-NN库。折腾半天发现他系统里默认的arm-none-eabi-gcc版本是…...

记一次在双 RTX 3090 工作站上部署 vLLM 与 Qwen3.6-35B-AWQ 的实战记录
记一次在双 RTX 3090 工作站上部署 vLLM 与 Qwen3.6-35B-AWQ 的实战记录 1. 升级目的 最近需要本地部署大模型推理服务,目标是运行 Qwen3.6-35B 的 INT4 量化版本(AWQ 格式),并使用高性能推理引擎 vLLM 提供服务。由于模型采用 …...

出门在外也能用!OpenAI 将 Codex 接入 ChatGPT 移动端
曾经在企业办公室工作过的人,可能都见过这样的场景:同事们把笔记本电脑托在手臂上,从一个会议室走到另一个会议室。倒也不是非要在走廊、电梯或楼道里处理邮件,只是不想合上盖子然后再等电脑重启。看似有些滑稽,但又不…...