CNN神经网络——手写体识别
目录
Load The Datesets
Defining,Training,Measuring CNN Algorithm
Datasets
GRAET HONOR TO SHARE MY KNOWLEDGE WITH YOU
This paper is going to show how to use keras to relize a CNN model for digits classfication
Load The Datesets
The datasets files are shown in the follwing chart:
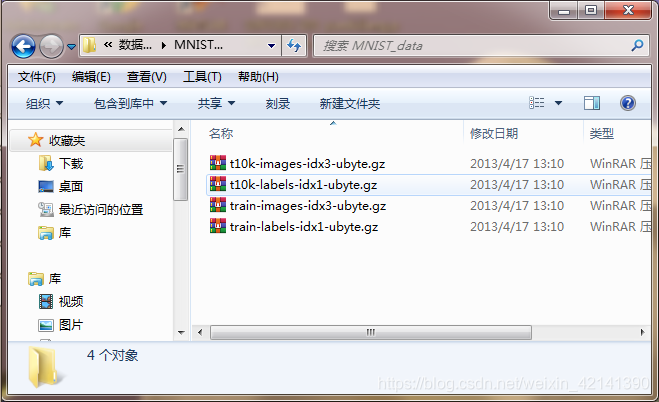
we see, there are all .gz file, which is a common zipped file format. And differ from some datasets needed to be splitted as training sest and testting set, this datasets shown above is already be splitted as traning and testing set, where file t10k-images-idx3-ubyte.gz and t10k-labels-idx1-ubyte.gz is the features and labels of testing sets respectively, while the other two is features and labels of traning sets. When upzipping those files, one could find there is a binary file:
![]()
As we see, this file is not CSV , XLSX, DATA or other image file like PNG, JPG or JPEG. So How to read it to Python is another problem we have to deal with. Since is not our focus, there I just show the code:
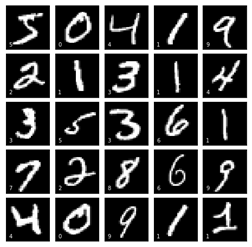
def data_generate():import gzipdatadir = r'..\数据集\MNIST_data' #datadir为解压路径sources = ['t10k-images-idx3-ubyte.gz','t10k-labels-idx1-ubyte.gz','train-images-idx3-ubyte.gz','train-labels-idx1-ubyte.gz']"""函数说明:def extract_tar函数用于解压某个tar.gz的压缩文件。"""def extract_tar(datafile,extractdir): #定义一个解压缩函数file = datafile.replace(".gz","")g_file = gzip.GzipFile(datafile)#读取解压后的文件,并写入去掉后缀名的同名文件(即得到解压后的文件)open(file, "wb+").write(g_file.read()) #将文件加压缩到压缩文件所在的文件夹中g_file.close()print("%s 解压完成."%datafile)return file #返回解压缩后文件的名称字符串data_file = [] for source in sources: #通过遍历解压文件夹datasets_q8中所有文件datafile = r'%s\%s' %(datadir,source) #指定待解压缩文件file = extract_tar(datafile,datadir) #将文件压缩到路径datadirdata_file.append(file)"""很多类型的文件,其起始的几个字节的内容是固定的(或是有意填充,或是本就如此)。根据这几个字节的内容就可以确定文件类型,因此这几个字节的内容被称为魔数 (magic number)。"""import structimport numpy as npdef decode_idx1_ubyte(idx1_ubyte_file):"""解析idx1文件的通用函数:param idx1_ubyte_file: idx1文件路径:return: 数据集"""# 读取二进制数据bin_data = open(idx1_ubyte_file, 'rb').read()# 解析文件头信息,依次为魔数和标签数offset = 0fmt_header = '>ii'magic_number, num_images = struct.unpack_from(fmt_header, bin_data, offset)print('魔数:%d, 图片数量: %d张' % (magic_number, num_images))# 解析数据集offset += struct.calcsize(fmt_header)fmt_image = '>B'labels = np.empty(num_images)for i in range(num_images):if (i + 1) % 10000 == 0:print ('已解析 %d' % (i + 1) + '张')labels[i] = struct.unpack_from(fmt_image, bin_data, offset)[0]offset += struct.calcsize(fmt_image)return labelsy_train = decode_idx1_ubyte(data_file[3])y_test = decode_idx1_ubyte(data_file[1])y_train = y_train.astype(np.int)y_test = y_test.astype(np.int)def decode_idx3_ubyte(idx3_ubyte_file):"""解析idx3文件的通用函数:param idx3_ubyte_file: idx3文件路径:return: 数据集"""# 读取二进制数据bin_data = open(idx3_ubyte_file, 'rb').read()# 解析文件头信息,依次为魔数、图片数量、每张图片高、每张图片宽offset = 0fmt_header = '>iiii' #因为数据结构中前4行的数据类型都是32位整型,所以采用i格式,但我们需要读取前4行数据,所以需要4个i。我们后面会看到标签集中,只使用2个ii。magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_header, bin_data, offset)print('魔数:%d, 图片数量: %d张, 图片大小: %d*%d' % (magic_number, num_images, num_rows, num_cols))# 解析数据集image_size = num_rows * num_colsoffset += struct.calcsize(fmt_header) #获得数据在缓存中的指针位置,从前面介绍的数据结构可以看出,读取了前4行之后,指针位置(即偏移位置offset)指向0016。print(offset)fmt_image = '>' + str(image_size) + 'B' #图像数据像素值的类型为unsigned char型,对应的format格式为B。这里还有加上图像大小784,是为了读取784个B格式数据,如果没有则只会读取一个值(即一副图像中的一个像素值)print(fmt_image,offset,struct.calcsize(fmt_image))images = np.empty((num_images, num_rows, num_cols))#plt.figure()for i in range(num_images):if (i + 1) % 10000 == 0:print('已解析 %d' % (i + 1) + '张')print(offset)images[i] = np.array(struct.unpack_from(fmt_image, bin_data, offset)).reshape((num_rows, num_cols))offset += struct.calcsize(fmt_image)return imagesX_train = decode_idx3_ubyte(data_file[2])X_test = decode_idx3_ubyte(data_file[0])"""画图代码:读者可以运行该代码直观地查看数据集"""import matplotlib.pyplot as pltfig, axes = plt.subplots(5,5, figsize=(8, 8),subplot_kw={'xticks':[], 'yticks':[]},gridspec_kw=dict(hspace=0.1, wspace=0.1))for i, ax in enumerate(axes.flat):ax.imshow(X_train[i], cmap='gray', interpolation='nearest')ax.text(0.07, 0.07, str(y_train[i]),transform=ax.transAxes, color='white')return X_train,y_train,X_test,y_testThe above code define a function that generates the features of Trainingset denoted as X_train, labels of Trainingset denoted as y_train, and X_test, y_test of Testingset. Meanwhile, the above code plotting some of the datasets, shown below:
Defining,Training,Measuring CNN Algorithm
This section we will construct, traning a CNN model ,and measuring it in the testing sets using accuracy score
We run the function to gain dataset:
X_train,y_train,X_test,y_test = data_generate()Then we import some useful package:
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Conv2D,AveragePooling2D,Flatten
Then we define the CNN model :
model = Sequential() #创建神经网络类
model.add(Conv2D(16,kernel_size=(3,3),input_shape=(width,height,1),activation='relu')) #创建一个卷积层,核为3X3
model.add(Dropout(0.2)) #Dropout正则化
model.add(Conv2D(32,kernel_size=(3,3),activation='relu'))
model.add(Dropout(0.2))
model.add(AveragePooling2D(pool_size=(2,2))) #添加池化层,并根据平均值将矩阵缩放成2X2
model.add(Dropout(0.2))
model.add(Conv2D(64,kernel_size=(3,3),activation='relu'))
model.add(AveragePooling2D(pool_size=(2,2))) #添加池化层,缩放成2X2
model.add(Flatten()) #添加Flatten层
model.add(Dense(units=512,activation='relu')) #BP神经网络的隐藏层,512个节点
model.add(Dense(units=10,activation='sigmoid')) #输出层For the principle of Convolution layer or Pooling layer, please refer to
https://blog.csdn.net/weixin_42141390/article/details/105004900
Then we select Adam as the algorithm to finding the parameters of the CNN model with cross-entropy as cost function,then we set the max iteration is 100, the code is shown as below:
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy']) #使用Adam算法训练模型
history = model.fit(X_train,y_train,epochs=100,batch_size=256,validation_data=(X_test,y_test)) #定义随机搜索算法的mini-batch=256
Running the code, the output windows will show the following information:
Epoch 1/100
60000/60000 [==============================] - 219s 4ms/step - loss: 0.0869 - acc: 0.9712 - val_loss: 0.0199 - val_acc: 0.9934
..........
Epoch 99/100
60000/60000 [==============================] - 186s 3ms/step - loss: 2.6969e-05 - acc: 1.0000 - val_loss: 0.0109 - val_acc: 0.9986
Epoch 100/100
60000/60000 [==============================] - 186s 3ms/step - loss: 2.6969e-05 - acc: 1.0000 - val_loss: 0.0110 - val_acc: 0.9986
Then we plot the training curve by varible "history",using the following code:
import matplotlib.pyplot as plt
font1 = {'family' : 'Times New Roman',
'weight' : 'normal',
'size' : 20,
}
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.plot(history.history['acc'],linewidth=3,label='Train')
plt.plot(history.history['val_acc'],linewidth=3,linestyle='dashed',label='Test')
plt.xlabel('Epoch',fontsize=20)
plt.ylabel('精确度',fontsize=20)
plt.legend(prop=font1)

Datasets
to gain the datasets, you can refer to :https://github.com/1259975740/Machine_Learning/tree/master/chapter12/%E6%95%B0%E6%8D%AE%E9%9B%86/MNIST_data
相关文章:
CNN神经网络——手写体识别
目录 Load The Datesets Defining,Training,Measuring CNN Algorithm Datasets GRAET HONOR TO SHARE MY KNOWLEDGE WITH YOU This paper is going to show how to use keras to relize a CNN model for digits classfication Load The Datesets The datasets files are …...
python调试模块ipdb
1. 调试python ipdb是用来python中用以交互式debug的模块,可以直接利用pip安装; 其功能类似于pycharm中 python控制台, 而使用ipdb 的优点,便是直接在代码中调试, 避免了在python控制台,或者重新设置一些简单变量。…...

【数据库】聊聊MySQL的日志,binlog、undo log、redo log
日志 在数据库中,如何保证数据的回滚,以及数据同步,系统宕机后可以恢复到原来的状态,其实就是依靠日志。 其中bin log是Server层特有的,redo log是Innodb存储引擎特有的。 bin log 是逻辑日志,主要记录这条…...
aws dynamodb java低等级api和高级客户端api的使用
参考资料 https://docs.amazonaws.cn/zh_cn/sdk-for-java/latest/developer-guide/setup-project-maven.html 初始化环境 创建maven项目 mvn org.apache.maven.plugins:maven-archetype-plugin:3.1.2:generate \-DarchetypeArtifactId"maven-archetype-quickstart&quo…...

Kafka中那些巧妙的设计
一、kafka的架构 Kafka是一个分布式、多分区、基于发布/订阅模式的消息队列(Message Queue),具有可扩展和高吞吐率的特点。 kafka中大致包含以下部分: Producer: 消息生产者,向 Kafka Broker 发消息的客户…...
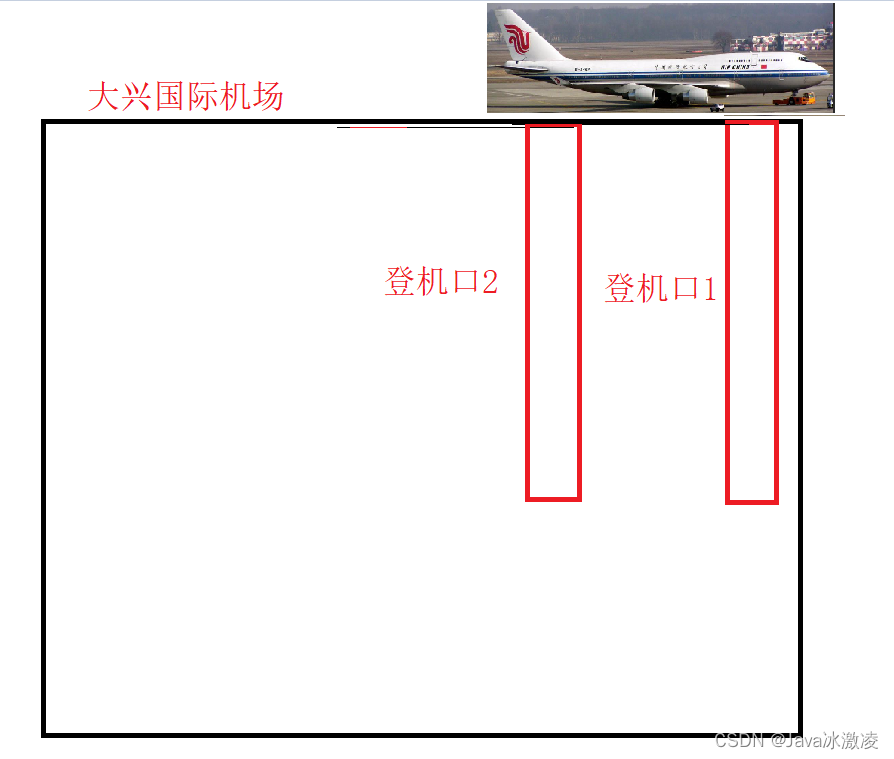
《JavaEE》进程和线程的区别和联系
👑作者主页:Java冰激凌 📖专栏链接:JavaEE 目录 进程是什么? 线程是什么? 进程和线程之间的联系~ ps1:假设我们当前的大兴国际机场有一条登机口可以登入飞机 ps2:我们为…...
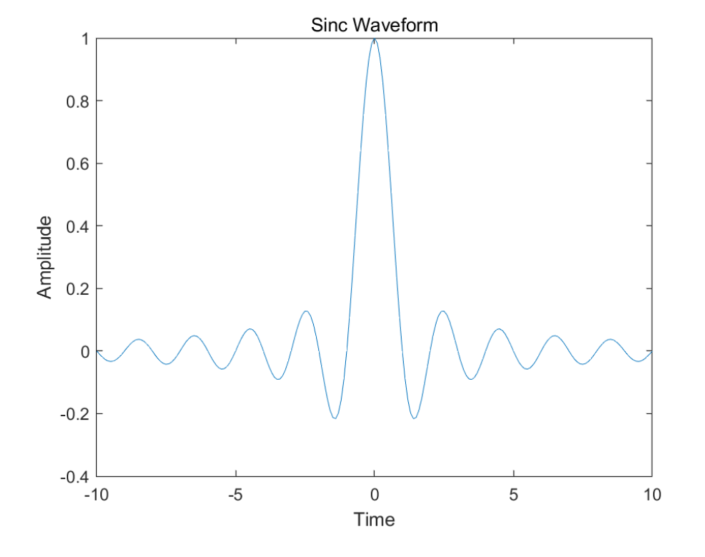
Matlab生成sinc信号
Matlab生成sinc信号 在Matlab中生成sinc信号非常容易。首先,我们需要了解什么是sinc波形。 sinc波形是一种理想的信号,它在时域上是一个宽度为无穷的矩形函数,而在频域上则是一个平的频谱。它的公式为: sinc(x)sin(πx)πx\…...

进程与线程区别与联系
进程与线程的区别与联系线程线程介绍为什么要有线程呢?线程与进程的区别于联系(重点)线程 线程介绍 我们知道进程就是运行起来的程序, 那线程又是什么呢? 一个线程就是一个 “执行流”. 每个线程之间都可以按照顺序执行自己的代码. 多个线程之间 “同时” 执行着多份代码. …...

使用vbscript.regexp实现VBA代码格式化
Office自带的VBE在编辑代码时,没有自动完成代码缩进的功能,而我们在网上找到的VBA代码,经常没有实现良好的自动缩进,复制到VBE后,可读性较差。本文介绍的宏,通过使用vbscript.regexp对象,利用正…...

选择结构习题:百分值转换成其相应的等级
Description 编一程序,输入一个百分制的成绩(整数类型),按要求输出相应的字符串信息,对应关系为: excellent 90-100 good 80-89 middle 70-79 pass 60-69 fail 60以下或100以上 Input 输入仅一行&…...
c# 源生成器
本文概述了 .NET Compiler Platform(“Roslyn”)SDK 附带的源生成器。 通过源生成器,C# 开发人员可以在编译用户代码时检查用户代码。 生成器可以动态创建新的 C# 源文件,这些文件将添加到用户的编译中。 这样,代码可以…...
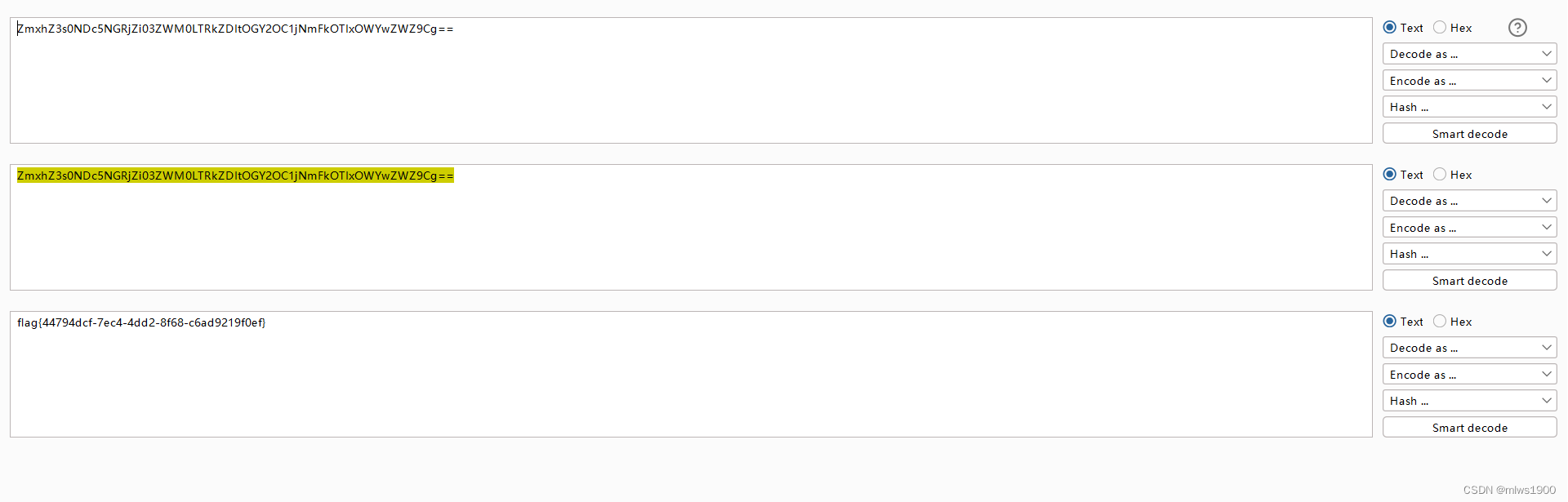
[N1CTF 2018]eating_cms1
一个cms,先打开环境试了一下弱口令,无效,再试一下万能密码,告诉我有waf,先不想怎么绕过,直接开扫(信息收集)访问register.php注册一个账号进行登录上面的链接尝试用php读文件http://…...
数据结构与算法基础(王卓)(15):KMP算法详解(含速成套路和详细思路剖析)
如果时间不够,急(忙)着应付考试没心思看,直接参考(照抄)如下套路: PART 1:关于next [ j ] PPT:P30 根据书上以及视频上给出的思路(提醒)&#x…...

【互联网架构】聊一聊所谓的“跨语言、跨平台“
文章目录序跨语言跨平台【饭后杂谈】为什么有人说Java的跨平台很鸡肋?序 很多技术都具有跨语言、跨平台的特点 比如JSON是跨语言的、Java是跨平台的、UniAPP、Electron是跨平台的 跨语言和跨平台,是比较重要的一个特性。这些特性经常能够决定开发者是否…...
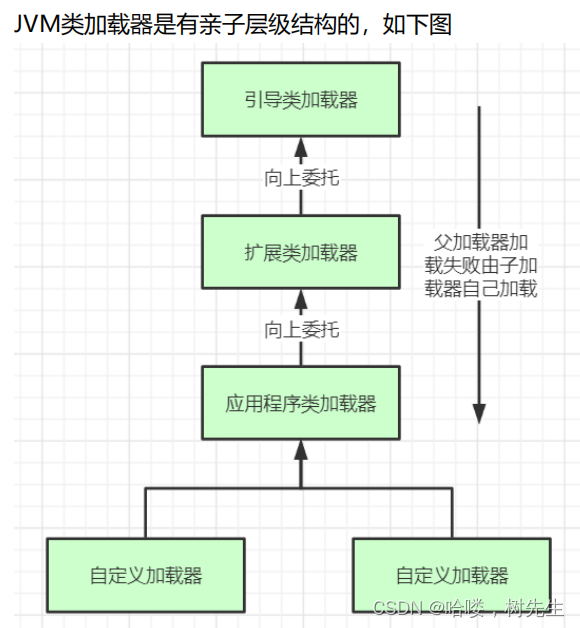
1.JVM常识之 类加载器
1.jvm组成 JVM组成: 1.类加载器 2.运行时数据区 3.执行引擎 4.本地库接口 各组件的作用: 首先通过类加载器(ClassLoader)会把 Java 代码转换成字节码,运行时数据区(Runtime Data Area)再把字节码…...
一天搞定《AI工程师的PySide2 PyQt5实战开发手册》
PySide2/PySide6、PyQt5/PyQt6:都是基于Qt 的Python库,可以形象地这样说,PySide2 是Qt的 亲儿子(Qt官方开发的) , PyQt5 是Qt还没有亲儿子之前的收的 义子 (Riverbank Computing这个公司开发的,有商业版权限…...

身份推理桌游
目录 杀人游戏(天黑请闭眼) (1)入门版 (2)标准版 (3)延伸版——百度百科 (3.1)引入医生和秘密警察 (3.2)引入狙击手、森林老人和…...
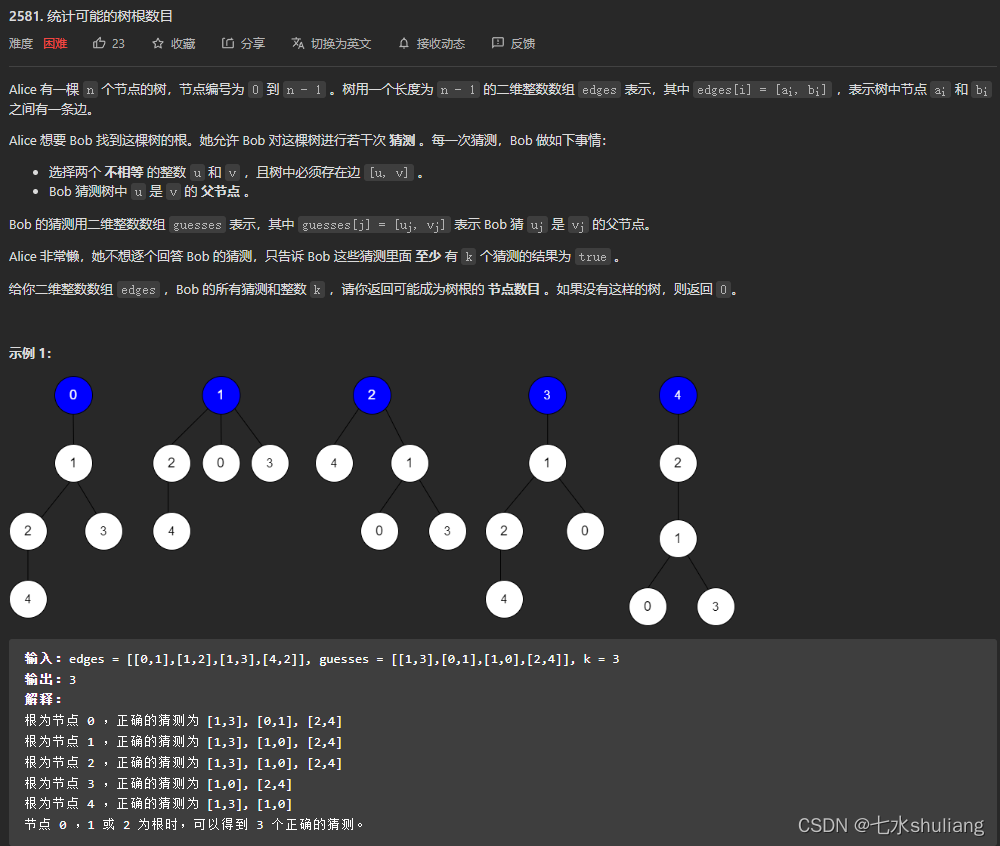
[LeetCode周赛复盘] 第 99 场双周赛20230304
[LeetCode周赛复盘] 第 99 场双周赛20230304 一、本周周赛总结二、 [Easy] 2578. 最小和分割1. 题目描述2. 思路分析3. 代码实现三、[Medium] 2579. 统计染色格子数1. 题目描述2. 思路分析3. 代码实现四、[Medium] 2580. 统计将重叠区间合并成组的方案数1. 题目描述2. 思路分析…...

Parcel Bundle漏洞学习
Bundle的序列化细节看上去还是有些复杂的,在之前已经讨论过,一般我们使用Parcel的时候,都是严格的write和read相对应。一些疏漏,不对应,竟然就可以成为漏洞,https://xz.aliyun.com/t/2364 里介绍了Bundle漏…...

RTP载荷H264(实战细节)
RTP包由两部分组成,RTP头和RTP载荷: RTP头 RTP头的 结构如下: 代码结构: typedef struct RtpHdr {uint8_t cc : 4, // CSRC countx : 1, // header extendp : 1, // padding flagversion : 2; // versionuint8_t …...

MMD创作者必看:除了跳舞,你还能用MikuMikuDance玩出哪些花样?
MMD创作者进阶指南:解锁MikuMikuDance的隐藏玩法 当你已经能熟练制作MMD舞蹈视频时,是否想过这款免费3D动画软件还能玩出更多花样?MikuMikuDance远不止是一个"虚拟歌姬跳舞模拟器",它其实是一个被严重低估的轻量级3D动画…...

LOSEHU固件深度解析:泉盛UV-K5/K6全功能固件架构与实战部署指南
LOSEHU固件深度解析:泉盛UV-K5/K6全功能固件架构与实战部署指南 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom LOSEHU固件是一款专为…...

数据中心网络跃迁:25GbE以太网如何以创造性破坏重塑技术路径
1. 从技术演进到范式跃迁:我眼中的“创造性破坏”风暴我是在上世纪90年代末来到这里的,那是一个技术浪潮奔涌的年代。我亲眼见证了录像带从VHS到DVD,再到如今的云DVR和视频流媒体的完整迭代;也目睹了通信设备从固定电话到功能手机…...
【含Matlab源码 15428期】)
【冷链配送】遗传算法求解低碳冷链物流车辆路径问题(目标函数固定成本 运输成本 制冷成本 惩罚成本 总碳排放成本)【含Matlab源码 15428期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab领域博客之家💞&…...

支付钱包启动器:架构设计与工程实践全解析
1. 项目概述:一个面向开发者的支付钱包启动器 最近在和一些做独立开发的朋友聊天,发现大家在做项目时,但凡涉及到支付、钱包这类功能,都挺头疼的。不是对接流程繁琐,就是安全风险高,要么就是代码耦合度太强…...

5分钟告别百度网盘提取码烦恼:智能获取工具全解析
5分钟告别百度网盘提取码烦恼:智能获取工具全解析 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾经因为一个简单的提取码,在浏览器标签页间反复切换,浪费了宝贵的十几分钟…...

智慧树刷课插件:3个核心功能帮你告别重复点击,学习效率提升300%
智慧树刷课插件:3个核心功能帮你告别重复点击,学习效率提升300% 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台繁琐的手动操作…...
| 系统提权)
渗透测试技巧(七)| 系统提权
系统提权基础 实战过程中,你通过漏洞(上传漏洞、弱口令、Web 漏洞)打进服务器,一般只能对应应用服务的账户权限。这个权限常常属于低权限账户,无法查看账号密码、配置系统文件、获取敏感数据等,这时就需要提权!提权就是把低权限账号升级为系统最高权限,从而完全控制服…...

OTFS系统中结构化稀疏表示与GPU优化实践
1. OTFS系统与结构化稀疏表示概述 在无线通信领域,正交时频空间(OTFS)调制技术因其在高移动性场景下的卓越性能而备受关注。与传统OFDM系统不同,OTFS将信息符号调制在时延-多普勒(DD)域,能够更好地抵抗多普勒扩展和时延扩展的影响。然而&…...

从零部署私有AI助手:igogpt项目实战与优化指南
1. 项目概述与核心价值最近在折腾AI应用部署的时候,发现了一个挺有意思的项目,叫igolaizola/igogpt。乍一看这个名字,可能会有点摸不着头脑,但如果你对开源AI模型部署和WebUI界面搭建感兴趣,那这个项目绝对值得你花时间…...