如何使用PHP和Selenium快速构建自己的网络爬虫系统
近年来,随着互联网的普及,网络爬虫逐渐成为了信息采集的主要手段之一,然而,常规的爬虫技术不稳定、难以维护,市面上的纯web网页爬虫也只能在静态页面上进行操作。而php结合selenium可达到动态爬虫的效果,具有稳定性高、数据采集全面等优点,被广泛应用于爬虫开发中。本文将介绍如何使用php和selenium快速构建自己的网络爬虫系统。
一、Selenium和ChromeDriver的安装
Selenium是一个自动化测试工具,可以对Web应用程序进行自动化测试,其中将浏览器与操作系统分离式地处理,无强制插入代码实现页面渲染。ChromeDriver则是Selenium中调用Chrome浏览器的驱动程序,可以使Selenium直接操作Chrome,从而实现动态页面的爬取。
首先需要在本地安装Chrome浏览器和PHP环境。接着,我们需要安装相应版本的Selenium和ChromeDriver,在命令行中输入以下代码即可安装:
| 1 |
|
然后将ChromeDriver二进制文件(根据自己的本地Chrome版本下载相应版本的ChromeDrive)置于系统Path变量环境中,代码如下:
| 1 2 3 |
|
二、构建Selenium和ChromeDriver的封装类
Selenium封装类主要用来维护Selenium和ChromeDriver,避免重复创建、销毁,代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
注意,参数中的ChromeOptions主要是为了在无GUI(图形化界面)下仍能稳定运行,--no-sandbox参数是为了防止在linux系统下运行时报错。
三、创建网页源码解析类
爬虫系统的核心在于解析非静态页面,这里需要创建源码解析类,使用正则表达式或XPath表达式来定位和获取目标节点信息。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
这里主要用到了DOMXPath类和DOMDocument类来解析页面中的HTML节点,分别通过parseList和parseSingle方法来定位和获取多个和一个目标节点的内容。
四、创建爬虫类
最后,我们需要构建一个专门爬取页面内容的爬虫类,代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
该类的getContent方法接收两个参数,一个是目标节点的XPath表达式,另一个是是否获取多个内容。 getModelContent函数请求URL并解析节点来获取所需内容,该函数获取结束后关闭浏览器进程。
五、使用示例
最后,我们使用实际例子来说明如何使用这个爬虫类。假设我们需要从一个拥有多个a标签的网页上,爬取a标签中的href属性和文本信息。我们可以通过以下代码来实现:
| 1 2 3 4 5 6 7 8 |
|
在以上代码中,首先使用Spider类获取页面源码,然后通过XPath表达式获取多个a标签的节点信息,最后通过getAttribute和nodeValue方法获取每个a标签的href属性和文本。
六、总结
综上所述,本文通过介绍如何使用PHP和Selenium构建网页爬虫系统,并通过实际示例说明如何获取页面中的节点信息,该爬虫具有稳定性高、数据采集全面等优点,具有一定的应用价值。但同时需要注意的是,爬取数据时需要注意合法性和道德性,并遵守相关法律法规。
相关文章:

如何使用PHP和Selenium快速构建自己的网络爬虫系统
近年来,随着互联网的普及,网络爬虫逐渐成为了信息采集的主要手段之一,然而,常规的爬虫技术不稳定、难以维护,市面上的纯web网页爬虫也只能在静态页面上进行操作。而php结合selenium可达到动态爬虫的效果,具…...
intellij idea安装R包ggplot2报错问题求解
1、intellij idea安装R包ggplot2问题 在我上次解决图形显示问题后,发现安装ggplot2包时出现了问题,这在之前高版本中并没有出现问题, install.packages(ggplot2) ERROR: lazy loading failed for package lifecycle * removing C:/Users/V…...

【C++】初识C++(一)
一.什么是C C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度 的抽象和建模时,C语言则不合适。为了解决软件危机, 20世纪80年代, 计算机界提出了OOP(object o…...
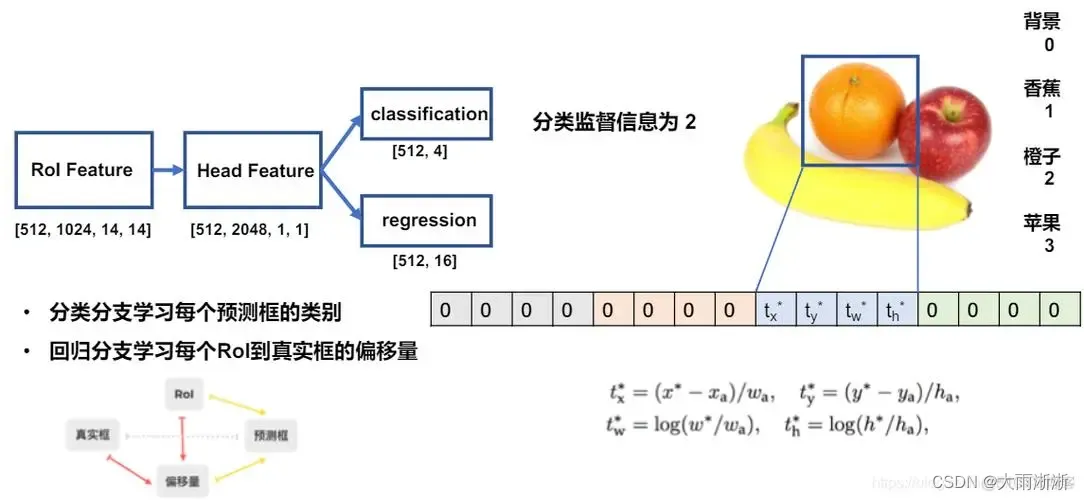
【智能算法】目标检测算法
目录 一、目标检测算法分类 二、 常见目标检测算法及matlab代码实现 2.1 R-CNN 2.1.1 定义 2.1.2 matlab代码实现 2.2 Fast R-CNN 2.2.1 定义 2.2.2 matlab代码实现 2.3 Faster R-CNN 2.3.1 定义 2.3.2 matlab代码实现 2.4 YOLO 2.4.1 定义 2.4.2 matlab代码实现…...

python 中 json.load json.loadd json.dump json.dumps 详解
在Python中,json 模块提供了用于处理JSON数据的函数。json.load(), json.loads(), json.dump(), 和 json.dumps() 是这个模块中用于序列化和反序列化JSON数据的主要函数。下面是它们之间的区别详解: json.load() 作用:从一个文件对象&#x…...

【UE 网络】专用服务器和多个客户端加入游戏会话的过程,以及GameMode、PlayerController、Pawn的创建流程
目录 0 引言1 多人游戏会话1.1 Why?为什么要有这个1.2 How?怎么使用? 2 加入游戏会话的流程总结 🙋♂️ 作者:海码007📜 专栏:UE虚幻引擎专栏💥 标题:【UE 网络】在网络…...
区别及操作笔记)
磁盘分区工具(fdisk 和 parted)区别及操作笔记
fdisk 和 parted 都是 Linux 系统中用于磁盘分区的工具。 两者主要区别: 支持的分区表类型: fdisk 主要支持 MBR分区表,MBR分区表支持的硬盘单个分区最大容量为2TB,最多可以有4个主分区。parted 支持 MBR分区表 和 GPT分区表&…...
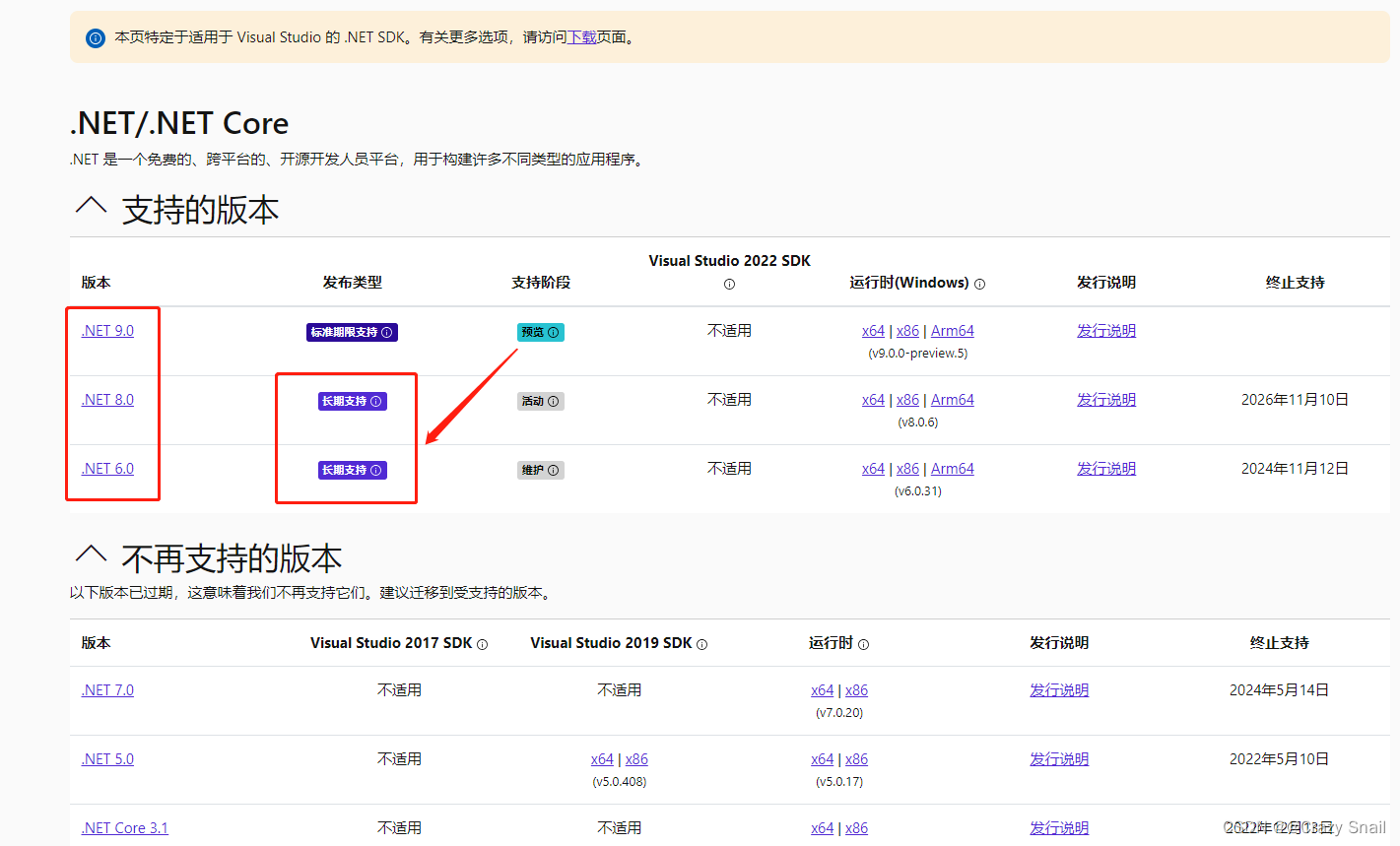
VisualStudio2019受支持的.NET Core
1.VS Studio2019受支持的.NET Core? 适用于 Visual Studio 的 .NET SDK 下载 (microsoft.com) Visual Studio 2019 默认并不直接支持 .NET 6 及以上版本。要使用 .NET 6 或更高版本,你需要在 Visual Studio 2019 中采取额外步骤,比如安装相应…...

Java——IO流(二)-(1/7):字符流-FileReader、FileWriter、字符输出流的注意事项(构造器及常用方法、小结)
目录 文件字符输入流-读字符数据进来 介绍 构造器及常用方法 实例演示 文件字符输出流-写字符数据出去 介绍、构造器及常用方法 实例演示 字符输出流使用时的注意事项 小结 文件字符输入流-读字符数据进来 介绍 FileReader(文件字符输入流) 作…...

Spring循环依赖问题——从源码画流程图
文章目录 关键代码相关知识为什么要使用二级缓存为什么要使用三级缓存只使用两个缓存的问题不能解决构造器循环依赖为什么多例bean不能解决循环依赖问题初始化后代理对象赋值给原始对象解决循环依赖SpringBoot开启循环依赖 循环依赖 在线流程图 关键代码 从缓存中查询getSingl…...
)
Android SurfaceFlinger——动画播放准备(十五)
BootAnimation 本质上是一个线程,执行 run 之后,会先执行 readyToRun,接着执行 treadLoop 方法。 一、线程启动 1、BootAnimation 源码位置:/frameworks/base/cmds/bootanimation/BootAnimation.cpp readyToRun status_t BootAnimation::readyToRun() {// 添加默认资源…...

Zynq7000系列FPGA中的DMA控制器简介(二)
AXI互连上的DMA传输 所有DMA事务都使用AXI接口在PL中的片上存储器、DDR存储器和从外设之间传递数据。PL中的从设备通过DMAC的外部请求接口与DMAC通信,以控制数据流。这意味着从设备可以请求DMA交易,以便将数据从源地址传输到目标地址。 虽然DMAC在技术…...
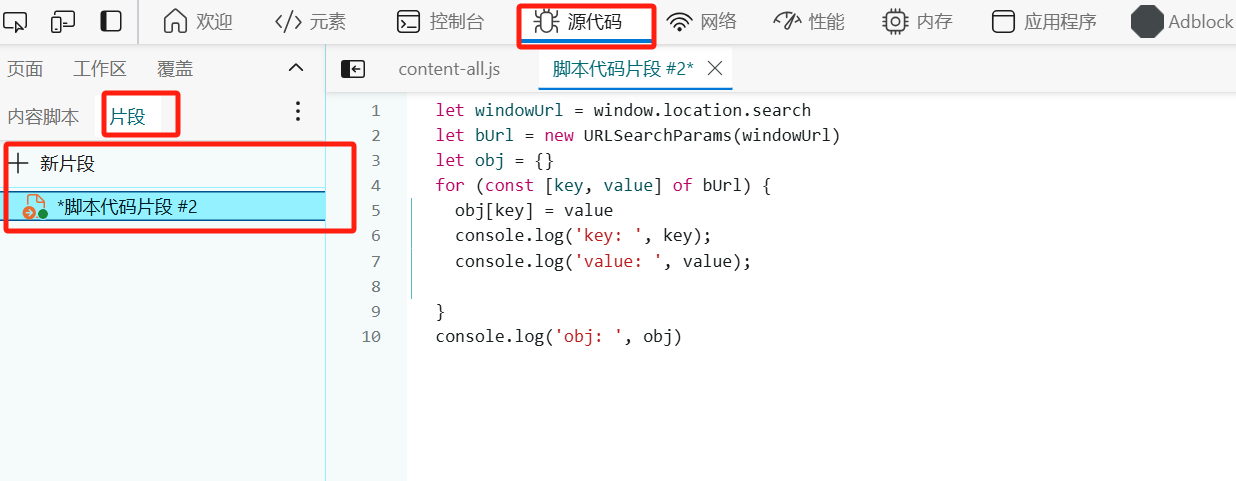
获取 url 地址栏 ? 后面的查询字符串,并以键值对形式放到对象里面
写在前面 在前端面试当中,关于 url 相关的问题很常见,而对于 url 请求参数的问题也很常见,大部分以笔试题常见,今天就根据这道面试题一起来看一下。 问题 获取 url 地址栏?后面的查询字符串,并以键值对形式放到对象…...
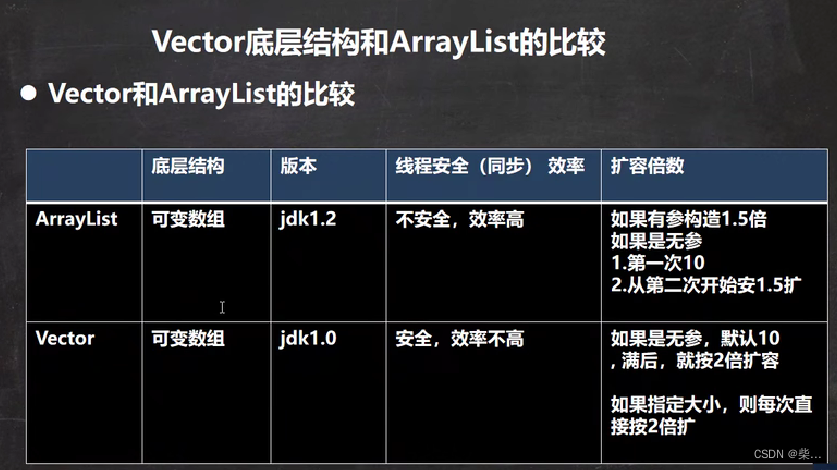
List接口, ArrayList Vector LinkedList
Collection接口的子接口 子类Vector,ArrayList,LinkedList 1.元素的添加顺序和取出顺序一致,且可重复 2.每个元素都有其对应的顺序索引 方法 在index 1 的位置插入一个对象,list.add(1,list2)获取指定index位置的元素&#…...

探讨数字化背景下VSM(价值流程图)的挑战和机遇
在信息化、数字化飞速发展的今天,各行各业都面临着前所未有的挑战与机遇。作为源自丰田生产模式的VSM(价值流程图),这一曾经引领制造业革命的工具,在数字化背景下又将如何乘风破浪,应对新的市场格局和技术变…...

Conda跨平台环境迁移
问题描述: 在一台Ubuntu电脑上完全复刻在Windows中通过conda创建的环境。 导出环境 在Windows机器上,需要导出当前conda环境的配置。这将生成一个environment.yml文件,其中包含所有已安装的包和版本信息。 打开Anaconda Prompt(…...

全面掌握 Jackson 序列化工具:原理、使用与高级配置详解
全面掌握 Jackson 序列化工具:原理、使用与高级配置详解 Jackson 是一个功能强大的 JSON 处理库,广泛应用于 Java 项目中。它提供了丰富的功能和灵活的配置选项,可以轻松地在 Java 对象和 JSON 数据之间进行转换。本文将详细介绍 Jackson 的…...

mathtype7.4永久激活码密钥及2024最新破解版注册码附安装教程
MathType 7版本号还提升了对教育行业的支持,如增加了大量预定义的教学公式和符号,使老师和学生在教学过程中能够更加便捷的应用。同时,它还加强了云备份功能,用户可将自己的公式存储在云端,随时随地访问和编辑…...

【SQL】优化慢 SQL的简单思路
优化慢 SQL 需要综合考虑多个方面,包括查询的结构、索引的使用、表结构设计等。以下是一些常见的 SQL 优化技巧和步骤: 1. 检查查询计划 使用数据库提供的工具查看查询计划(例如 MySQL 的 EXPLAIN 命令)可以帮助了解查询的执行路…...
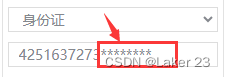
禁止浏览器对input的自动填充和填充提示(适用于谷歌、火狐、Edge(原IE浏览器)等常见浏览器)
目录 1.要解决的问题2.一技能:原生属性,小试牛刀3.二技能:傀儡input,瞒天过海4.三技能:JavaScript出击,直接开大5.九九八十一难,永远还有最后一难 写在前面: 如有转载,务…...

CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战
CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战 车牌识别系统中,数据预处理的质量直接影响模型性能。CCPD作为目前最全面的中文车牌数据集,其四点标注特性为透视变换提供了基础,但也暗藏诸多陷阱。本文将手把手带您穿…...
实战:从零部署企业级WEB前后端项目)
TongWEB(东方通)实战:从零部署企业级WEB前后端项目
1. 环境准备:银河麒麟系统下的基础搭建 在银河麒麟桌面系统V10(SP1)兆芯版上部署企业级WEB项目,环境准备是第一步。我遇到过不少开发者直接跳过环境检查就急着部署,结果浪费大量时间排查兼容性问题。这里分享几个关键点: 首先是系…...

智能路由器项目解析:基于策略路由实现多线路流量智能调度
1. 项目概述:一个“聪明”的路由器能做什么?最近在GitHub上看到一个挺有意思的项目,叫smart-router,作者是c0nSpIc0uS7uRk3r。光看名字,你可能会觉得这又是一个关于家庭网络优化的工具,但点进去仔细研究后&…...

LVGUI字体瘦身实战:如何为你的IoT设备定制一个超小的中文字体库
LGVUI字体瘦身实战:为IoT设备定制超小中文字体库的工程化解决方案 在嵌入式物联网设备开发中,每一KB的Flash和RAM都弥足珍贵。当你的智能温控器需要显示"当前温度:25℃"或者电子秤要呈现"净重:0.5kg"时&#…...

抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播
抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

通达信数据解析终极指南:mootdx让金融数据获取变得如此简单
通达信数据解析终极指南:mootdx让金融数据获取变得如此简单 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易的世界里,获取准确、完整的市场数据是…...

Go语言静态站点生成器Zeuxis:极简架构与高性能构建实践
1. 项目概述:一个轻量级、高性能的静态站点生成器最近在折腾个人博客和文档站点,发现市面上的静态站点生成器虽然多,但要么配置复杂、学习曲线陡峭,要么过于臃肿,启动和构建速度慢得让人抓狂。直到我遇到了bnomei/zeux…...

技术解构:逆向工程视角下的百度网盘下载链接解析机制
技术解构:逆向工程视角下的百度网盘下载链接解析机制 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 想象一下,当你收到朋友分享的百度网盘链接时&…...
、连读规则注入与敬语语调开关(内测白名单已开放))
仅限菲律宾本地团队使用的ElevenLabs隐藏功能:Tagalog重音标记语法(`[ˈba.ka]`)、连读规则注入与敬语语调开关(内测白名单已开放)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs菲律宾文语音能力的本地化演进背景 菲律宾语(Filipino)作为以他加禄语(Tagalog)为基础的国家官方语言,拥有约1.05亿母语及第二语言…...
:提取未文档化emotion_intensity参数,实现新闻播报级庄严语调控制)
【独家首发】ElevenLabs乌尔都语语音SDK逆向分析(v2.4.1):提取未文档化emotion_intensity参数,实现新闻播报级庄严语调控制
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs乌尔都语语音SDK逆向分析全景概览 ElevenLabs 官方未公开乌尔都语(ur-PK)的独立语音 SDK,但其 Web API 实际支持该语言的 TTS 合成。通过对官方 JS SDK&am…...