【入门】5分钟了解卷积神经网络CNN是什么
本文来自《老饼讲解-BP神经网络》https://www.bbbdata.com/
目录
- 一、卷积神经网络的结构
- 1.1.卷积与池化的作用
- 2.2.全连接层的作用
- 二、卷积神经网络的运算
- 2.1.卷积层的运算
- 2.2.池化的运算
- 2.3.全连接层运算
- 三、pytorch实现一个CNN例子
- 3.1.模型的搭建
- 3.2.CNN完整训练代码
CNN神经网络常用于图片识别,是深度学习中常用的模型。
本文简单快速了解卷积神经网络是什么东西,并展示一个简单的示例。
一、卷积神经网络的结构
一个经典的卷积神经网络的结构如下:
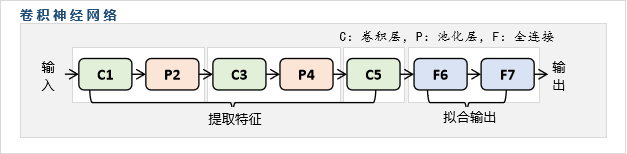
C代表卷积层,P代表池化层,F代表全连接层。
卷积神经网络主要的、朴素的用途是图片识别。即输入图片,然后识别图片的类别,例如输入一张图片,识别该图片是猫还是狗。
1.1.卷积与池化的作用
卷积层与池化层共同是卷积神经网络的核心,它用于将输入图片进行压缩,例如一张224x224的图片,经过卷积+池化后,可能得到的就是55x55的图片,也就是说,卷积与池化的目的就是使得输入图片变小,同时尽量不要损失太多与类别相关的信息。例如一张猫的图片经过卷积与池化之后,尽量减少图片的大小,但要尽可能地保留"猫"的信息。
2.2.全连接层的作用
全连接层主要用于预测图片的类别。全连接层实际可以看作一个BP神经网络模型, 使用"卷积+池化"之后得到的特征来拟合图片的类别。
二、卷积神经网络的运算
2.1.卷积层的运算
卷积层的运算如下:

卷积层中的卷积核就是一个矩阵,直观来看它就是一个窗口,卷积窗口一般为正方形,即长宽一致,
卷积运算通过从左到右,从上往下移动卷积核窗口,将窗口覆盖的每一小块输入进行加权,作为输出
2.2.池化的运算
池化层是通过一个池化窗口,对输入进行逐块扫描,每次将窗口的元素合并为一个元素,
池化层的运算如下:
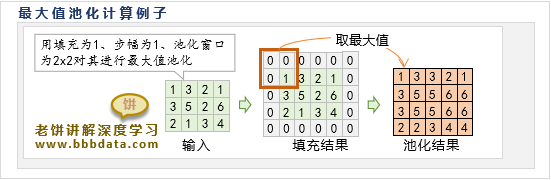
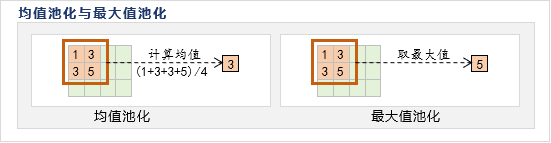
池化层一般分为均值池化与最大值池化,顾名思义,就是计算时使用均值还是最大值:
2.3.全连接层运算
全连接层就相当于一个BP神经网络模型,即每一层与下一层都是全连接形式。
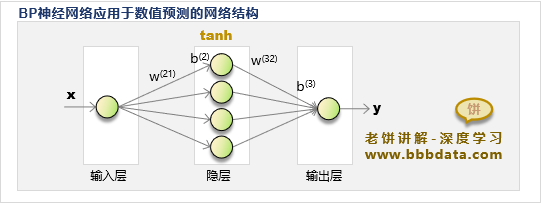
假设前一层传过来的输入的是X,则当前层的输出是tanh(WX+b)
三、pytorch实现一个CNN例子
下面以手写数字识别为例,展示如何使用pytorch实现一个CNN

3.1.模型的搭建
如下所示,就搭建了一个CNN模型
# 卷积神经网络的结构
class ConvNet(nn.Module):def __init__(self,in_channel,num_classes):super(ConvNet, self).__init__()self.nn_stack=nn.Sequential(#--------------C1层-------------------nn.Conv2d(in_channel,6, kernel_size=5,stride=1,padding=2),nn.ReLU(inplace=True), nn.AvgPool2d(kernel_size=2,stride=2),# 输出14*14#--------------C2层-------------------nn.Conv2d(6,16, kernel_size=5,stride=1,padding=2),nn.ReLU(inplace=True),nn.AvgPool2d(kernel_size=2,stride=2),# 输出7*7#--------------C3层-------------------nn.Conv2d(16,80,kernel_size=7,stride=1,padding=0),# 输出1*1*80#--------------全连接层F4----------nn.Flatten(), # 对C3的结果进行展平nn.Linear(80, 120), nn.ReLU(inplace=True), #--------------全连接层F5---------- nn.Linear(120, num_classes) )def forward(self, x):p = self.nn_stack(x)return p
从代码里可以看到,只需按自己所设定的结构进行随意搭建就可以了。
搭建了之后再使用数据进行训练可以了,然后就可以使用模型对样本进行预测。
3.2.CNN完整训练代码
完整的CNN训练代码示例如下:
import torch
from torch import nn
from torch.utils.data import DataLoader
import torchvision
import numpy as np#--------------------模型结构--------------------------------------------
# 卷积神经网络的结构
class ConvNet(nn.Module):def __init__(self,in_channel,num_classes):super(ConvNet, self).__init__()self.nn_stack=nn.Sequential(#--------------C1层-------------------nn.Conv2d(in_channel,6, kernel_size=5,stride=1,padding=2),nn.ReLU(inplace=True), nn.AvgPool2d(kernel_size=2,stride=2),# 输出14*14#--------------C2层-------------------nn.Conv2d(6,16, kernel_size=5,stride=1,padding=2),nn.ReLU(inplace=True),nn.AvgPool2d(kernel_size=2,stride=2),# 输出7*7#--------------C3层-------------------nn.Conv2d(16,80,kernel_size=7,stride=1,padding=0),# 输出1*1*80#--------------全连接层F4----------nn.Flatten(), # 对C3的结果进行展平nn.Linear(80, 120), nn.ReLU(inplace=True), #--------------全连接层F5---------- nn.Linear(120, num_classes) )def forward(self, x):p = self.nn_stack(x)return p#-----------------------模型训练---------------------------------------
# 参数初始化函数
def init_param(model):# 初始化权重阈值 param_list = list(model.named_parameters()) # 将模型的参数提取为列表 for i in range(len(param_list)): # 逐个初始化权重、阈值is_weight = i%2==0 # 如果i是偶数,就是权重参数,i是奇数就是阈值参数if is_weight: torch.nn.init.normal_(param_list[i][1],mean=0,std=0.01) # 对于权重,以N(0,0.01)进行随机初始化else: torch.nn.init.constant_(param_list[i][1],val=0) # 阈值初始化为0# 训练函数
def train(dataloader,valLoader,model,epochs,goal,device): for epoch in range(epochs): err_num = 0 # 本次epoch评估错误的样本eval_num = 0 # 本次epoch已评估的样本print('-----------当前epoch:',str(epoch),'----------------') for batch, (imgs, labels) in enumerate(dataloader): # -----训练模型----- x, y = imgs.to(device), labels.to(device) # 将数据发送到设备optimizer.zero_grad() # 将优化器里的参数梯度清空py = model(x) # 计算模型的预测值 loss = lossFun(py, y) # 计算损失函数值loss.backward() # 更新参数的梯度optimizer.step() # 更新参数# ----计算错误率---- idx = torch.argmax(py,axis=1) # 模型的预测类别eval_num = eval_num + len(idx) # 更新本次epoch已评估的样本err_num = err_num +sum(y != idx) # 更新本次epoch评估错误的样本if(batch%10==0): # 每10批打印一次结果print('err_rate:',err_num/eval_num) # 打印错误率# -----------验证数据误差--------------------------- model.eval() # 将模型调整为评估状态val_acc_rate = calAcc(model,valLoader,device) # 计算验证数据集的准确率model.train() # 将模型调整回训练状态print("验证数据的准确率:",val_acc_rate) # 打印准确率 if((err_num/eval_num)<=goal): # 检查退出条件break print('训练步数',str(epoch),',最终训练误差',str(err_num/eval_num)) # 计算数据集的准确率
def calAcc(model,dataLoader,device): py = np.empty(0) # 初始化预测结果y = np.empty(0) # 初始化真实结果for batch, (imgs, labels) in enumerate(dataLoader): # 逐批预测cur_py = model(imgs.to(device)) # 计算网络的输出cur_py = torch.argmax(cur_py,axis=1) # 将最大者作为预测结果py = np.hstack((py,cur_py.detach().cpu().numpy())) # 记录本批预测的yy = np.hstack((y,labels)) # 记录本批真实的yacc_rate = sum(y==py)/len(y) # 计算测试样本的准确率return acc_rate #--------------------------主流程脚本----------------------------------------------
#-------------------加载数据--------------------------------
train_data = torchvision.datasets.MNIST(root = 'D:\pytorch\data' # 路径,如果路径有,就直接从路径中加载,如果没有,就联网获取,train = True # 获取训练数据,transform = torchvision.transforms.ToTensor() # 转换为tensor数据,download = True # 是否下载,选为True,就下载到root下面,target_transform= None)
val_data = torchvision.datasets.MNIST(root = 'D:\pytorch\data' # 路径,如果路径有,就直接从路径中加载,如果没有,就联网获取,train = False # 获取测试数据,transform = torchvision.transforms.ToTensor() # 转换为tensor数据,download = True # 是否下载,选为True,就下载到root下面,target_transform= None) #-------------------模型训练--------------------------------
trainLoader = DataLoader(train_data, batch_size=1000, shuffle=True) # 将数据装载到DataLoader
valLoader = DataLoader(val_data , batch_size=100) # 将验证数据装载到DataLoader
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设置训练设备
model = ConvNet(in_channel =1,num_classes=10).to(device) # 初始化模型,并发送到设备
lossFun = torch.nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01,momentum =0.9,dampening=0.0005) # 初始化优化器
train(trainLoader,valLoader,model,1000,0.01,device) # 训练模型,训练100步,错误低于1%时停止训练# -----------模型效果评估---------------------------
model.eval() # 将模型切换到评估状态(屏蔽Dropout)
train_acc_rate = calAcc(model,trainLoader,device) # 计算训练数据集的准确率
print("训练数据的准确率:",train_acc_rate) # 打印准确率
val_acc_rate = calAcc(model,valLoader,device) # 计算验证数据集的准确率
print("验证数据的准确率:",val_acc_rate) # 打印准确率运行结果如下:
-----------当前epoch: 0 ----------------
err_rate: tensor(0.7000)
验证数据的准确率: 0.3350877192982456
-----------当前epoch: 1 ----------------
err_rate: tensor(0.6400)
验证数据的准确率: 0.3350877192982456
-----------当前epoch: 2 ----------------
.......
.......
-----------当前epoch: 77 ----------------
err_rate: tensor(0.0100)
验证数据的准确率: 1.0
-----------当前epoch: 78 ----------------
err_rate: tensor(0.)
验证数据的准确率: 1.0
-----------当前epoch: 79 ----------------
err_rate: tensor(0.0200)
验证数据的准确率: 1.0
-----------当前epoch: 80 ----------------
err_rate: tensor(0.0100)
验证数据的准确率: 0.9982456140350877
-----------------------------------------
训练步数 80 ,最终训练误差 tensor(0.0088)
训练数据的准确率: 0.9982456140350877
验证数据的准确率: 0.9982456140350877
可以看到,识别效果达到了99.8%。CNN模型对图片的识别是非常有效的。
相关链接:
《老饼讲解-机器学习》:老饼讲解-机器学习教程-通俗易懂
《老饼讲解-神经网络》:老饼讲解-matlab神经网络-通俗易懂
《老饼讲解-神经网络》:老饼讲解-深度学习-通俗易懂
相关文章:
【入门】5分钟了解卷积神经网络CNN是什么
本文来自《老饼讲解-BP神经网络》https://www.bbbdata.com/ 目录 一、卷积神经网络的结构1.1.卷积与池化的作用2.2.全连接层的作用 二、卷积神经网络的运算2.1.卷积层的运算2.2.池化的运算2.3.全连接层运算 三、pytorch实现一个CNN例子3.1.模型的搭建3.2.CNN完整训练代码 CNN神…...

dB分贝入门
主要参考资料: dB(分贝)定义及其应用: https://blog.csdn.net/u014162133/article/details/110388145 目录 dB的应用一、声音的大小二、信号强度三、增益 dB的应用 一、声音的大小 在日常生活中,住宅小区告知牌上面标示噪音要低…...

力扣1744.你能在你最喜欢的那天吃到你最喜欢的糖果吗?
力扣1744.你能在你最喜欢的那天吃到你最喜欢的糖果吗? 对于第i类糖果求出吃到它的最大时间和最小时间 判断给定时间是否在范围内 注意: 同一天可以吃多种糖果 不是只能吃一种 class Solution {public:vector<bool> canEat(vector<int>&am…...
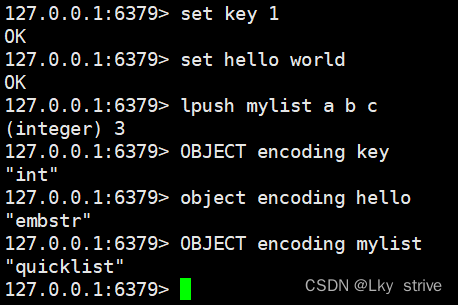
Redis的使用和原理
目录 1.初识Redis 1.1 Redis是什么? 1.2 Redis的特性 1.2.1 速度快 1.2.2 基于键值对的数据结构服务器 1.2.3 丰富的功能 1.2.4 简单稳定 1.2.5 持久化 1.2.6 主从复制 1.2.7 高可用和分布式 1.3 Redis的使用场景 1.3.1 缓存 1.3.2 排行榜系统 1.3.3 计数器应用 1.3…...

扫描全能王的AI驱动创新与智能高清滤镜技术解析
目录 引言1、扫描全能王2、智能高清滤镜黑科技2.1、图像视觉矫正2.2、去干扰技术 3、实际应用案例3.1、打印文稿褶皱检测3.2、试卷擦除手写3.3、老旧文件处理3.4、收银小票3.5、从不同角度扫描文档 4、用户体验结论与未来展望 引言 在数字化时代背景下,文档扫描功能…...
【Linux】Linux系统配置,linux的交互方式
1.Linux系统环境安装 有三种方式 裸机安装或者双系统 -- 不推荐虚拟机安装 --- 不推荐云服务器/安装简单, 维护成本低——推荐, 未来学习效果好 我们借助云服务器 云服务器(Elastic Compute Service,ECS)的标准定义…...

Linux中--prefix命令使用及源码安装
1.prefix - 指定文件安装路径通常与configure搭配使用: 在安装源码时可使用下述命令指定源码安装路径: bogon:httpd-2.4.59 wancanchishenma$./configure --prefix/usr/local/apache 2.源码的安装一般由3个步骤组成:配置(configur…...

加速科技Flash存储测试解决方案 全面保障数据存储可靠性
Flash存储芯片 现代电子设备的核心数据存储守护者 Flash存储芯片是一种关键的非易失性存储器,作为现代电子设备中不可或缺的核心组件,承载着数据的存取重任。这种小巧而强大的芯片,以其低功耗、可靠性、高速的读写能力和巨大的存储容量&…...

数字化那点事:一文读懂数字乡村
一、数字乡村的定义 数字乡村是指利用信息技术和数字化手段,推动乡村社会经济发展和治理模式变革,提升乡村治理能力和公共服务水平,实现乡村全面振兴的一种新型发展模式。它包括农业生产的数字化、乡村治理的智能化、乡村生活的现代化等方面…...

彻底解决 macos中chrome应用程序 的 无法更新 Chrome 弹窗提示 mac自定义参数启动 chrome.app
mac系统中的chrome app应用在每次打开是都会提示一个 “无法更新 Chrome Chrome 无法更新至最新版本,因此您未能获得最新的功能和安全修复程序。” , 然而最新的chrome 程序似乎在某些情况下居然会出现 输入和显示不一致的情况,暂时不想升…...

等级保护 | 如何完成等保的建设整改
等级保护整改是等保基本建设的一个阶段。为了能成功通过等级测评,企业要根据等级保护建设要求,对信息和信息系统进行网络安全升级,对定级对象当前不满足要求的进行建设整改,包括技术层面的整改,也包括管理方面的整改。…...

开发微信小程序从开始到部署上线,哪些个流程需要付费
1. 微信公众平台账号注册 费用:300元人民币(这是企业账号的认证费用,个人账号不需要付费)。说明:如果你是企业或组织,需要进行微信公众平台的认证,这会产生费用。个人开发者可以免费注册账号&a…...

python r, b, u, f 前缀详解
1、r前缀 一般来说,\n’是一个换行符,是一个字符串;而加上r为前缀后,不会以任何特殊方式处理反斜杠。因此,r"\n" 是包含 ‘\’ 和 ‘n’ 的双字符字符串;示例如下: >>> pr…...
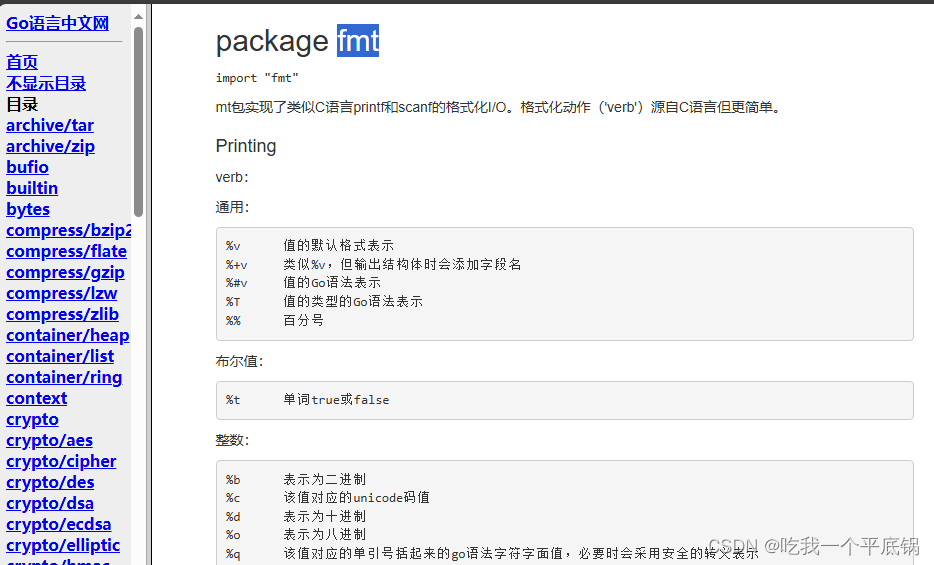
Go语言简介
Go语言 Go语言是由 Google 的 Robert Griesemer,Rob Pike 及 Ken Thompson 开发的一种静态强类型、编译型语言。 Go 语言(或称 Golang)是云计算时代的C语言。Go语言的诞生是为了让程序员有更高的生产效率,Go语言专门针对多处理器系统应用程序的编程进行了优化&…...
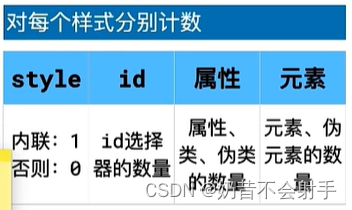
css持续学习
一、样式层叠 当一个css样式发生冲突时,比如多处给一个字体设置了不同的颜色,这个时候就需要样式层叠了,它会进行三种比较 比较重要性 重要性从高到低: 1.带有 important 的作者样式(作者样式就是开发者写的样式&…...

FFmpeg 关于AV1编码指导文档介绍
介绍 本篇博客主要介绍FFMpeg中关于AV1编码支持说明,主要根据官方wiki说明进行总结。官方wiki地址:AV1AV1是一种由Alliance for Open Media (AOMedia)开发的开源且免版税的视频编解码器,它在压缩效率上比VP9高出约30%,比H.264高出约50%。目前,FFmpeg支持三种AV1编码器:li…...
鸿蒙系统——强大的分布式系统
鸿蒙相比较于传统安卓最最最主要的优势是微内核分布式操作系统,具有面向未来,跨设备无缝协作,数据共享的全场景体验。下面简单来感受一下鸿蒙系统的多端自由流转。 自由流转概述 场景介绍 随着全场景多设备的生活方式不断深入,…...
centos7 安装单机MongoDB
centos7安装单机 yum 安装 1、配置yum源 vim /etc/yum.repos.d/mongodb.repo [mongodb-org-7.0] nameMongoDB Repository baseurlhttps://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/7.0/x86_64/ gpgcheck1 enabled1 gpgkeyhttps://www.mongodb.org/static/pgp…...

数据库回表介绍
索引覆盖 索引覆盖或称为覆盖索引,是数据库中的一种优化手段当我们在执行一个sql查询时,如果只需要查询某几个字段的值,并且这几个字段的数据都已经被包含在某一个索引中(而不是全表扫描),那么数据库引擎就会直接通过这个索引来取…...
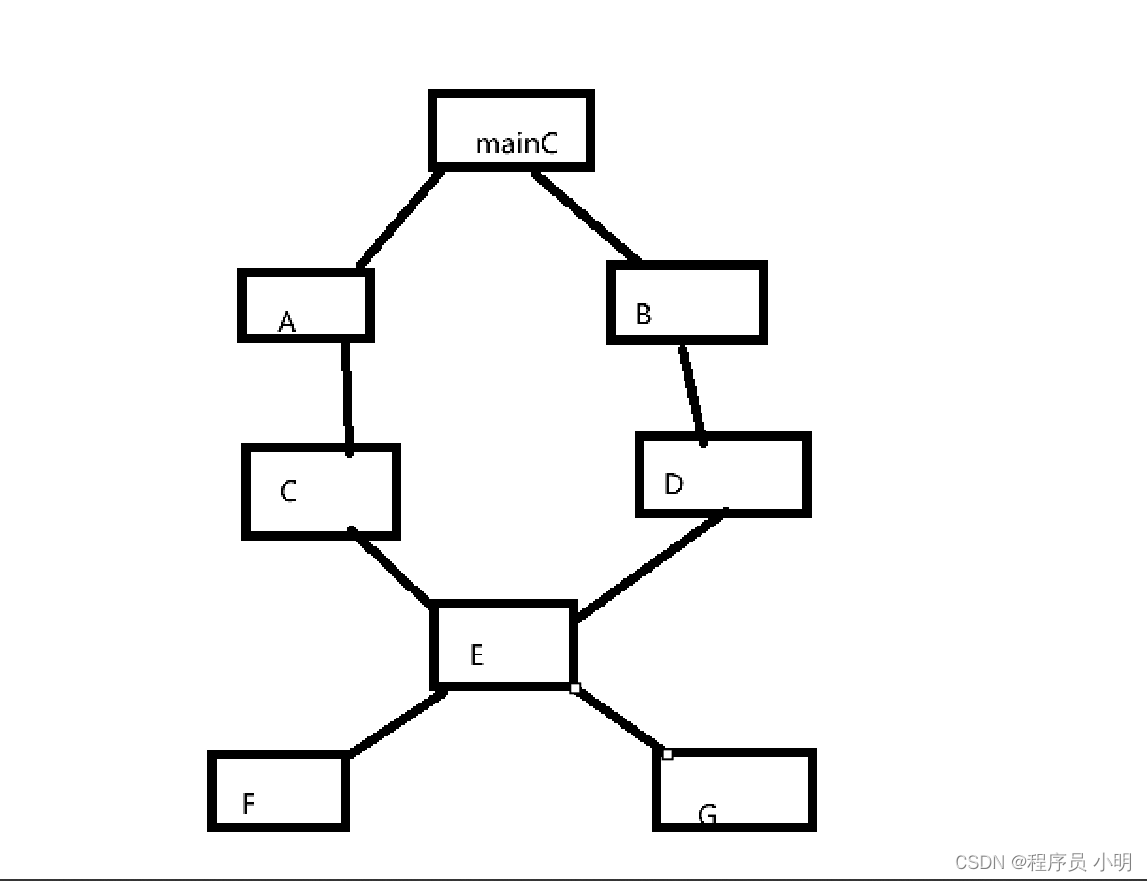
python多继承的3C算法
python多继承的3C算法 有很多地方都说python多继承的继承顺序,是按照深度遍历的方式,其实python多继承顺序的算法,不是严格意义上的深度遍历,而是基于深度遍历基础上优化出一种叫3C算法 python多继承的深度遍历 class C:def ru…...

Sophia优化器:二阶曲率感知如何加速大模型训练与调参
1. 项目概述:当优化器遇上“二阶”智慧最近在复现一些前沿的论文实验时,我又一次被优化器的选择给卡住了。AdamW虽然稳,但在某些超大规模模型或特定任务上,总觉得收敛速度不够快,调参又是个玄学。就在我对着损失曲线发…...

基于xclaude-plugin框架的Claude自定义插件开发实战指南
1. 项目概述:Claude插件生态的“瑞士军刀”如果你最近在深度使用Claude,尤其是Claude Desktop应用,那你大概率已经感受到了插件生态的潜力与混乱。官方插件商店虽然方便,但总有些特定需求找不到现成的解决方案,或者找到…...

开源流程编排引擎FlowCue:基于DAG与事件驱动的自动化工作流实践
1. 项目概述:FlowCue是什么,以及它为何值得关注如果你是一名开发者,尤其是经常和API、数据流、自动化任务打交道的后端或全栈工程师,那么你肯定对“流程编排”这个概念不陌生。简单来说,就是把一系列独立的操作&#x…...
)
别再手动折腾了!用Docker Compose 5分钟搞定ChirpStack LoRaWAN服务器部署(附配置文件详解)
5分钟极速部署ChirpStack LoRaWAN服务器的Docker Compose实战指南 1. 为什么选择Docker Compose部署ChirpStack? 对于物联网开发者而言,时间就是最宝贵的资源。传统的手动部署方式需要逐个安装和配置PostgreSQL、Redis、MQTT broker以及ChirpStack各个组…...

K210实战:三种高效部署kmodel模型至TF卡的进阶方案
1. K210模型部署的痛点与进阶方案概览 第一次用K210做图像识别项目时,最让我头疼的就是模型部署问题。每次修改模型都要反复插拔TF卡,调试过程像在玩打地鼠游戏。后来才发现,基础的拷贝粘贴只是入门操作,真正高效的部署方式能节省…...

顶伯 + 微软 TTS,3 分钟生成专业级解说配音
🎯 顶伯 微软 TTS,3 分钟生成专业级解说配音告别繁琐录音,用顶伯文字转语音工具快速打造高品质配音。✨ 一、为什么选择顶伯与微软 TTS 的组合?在视频制作、课程讲解或产品演示中,配音质量直接影响观众体验。 顶伯文字…...

3步掌握ADB驱动安装:Windows平台最简Android连接方案
3步掌握ADB驱动安装:Windows平台最简Android连接方案 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/la/Lat…...

ROFL-Player:英雄联盟回放时光机,一键穿越所有版本
ROFL-Player:英雄联盟回放时光机,一键穿越所有版本 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联…...

借助 Taotoken 多模型聚合能力为开源项目构建智能问答机器人
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 借助 Taotoken 多模型聚合能力为开源项目构建智能问答机器人 为开源项目添加一个智能问答助手,能显著提升社区体验&…...
)
独家解密:ElevenLabs匈牙利语模型训练数据源(含布达佩斯大学语料库授权细节与音系学标注规范)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs匈牙利语语音模型的技术定位与战略意义 ElevenLabs 匈牙利语语音模型并非简单的地方语言适配,而是其多语言零样本语音合成(Zero-Shot Voice Cloning)架构在…...