Transformer详解encoder
目录
1. Input Embedding
2. Positional Encoding
3. Multi-Head Attention
4. Add & Norm
5. Feedforward + Add & Norm
6.代码展示
(1)layer_norm
(2)encoder_layer=1
最近刚好梳理了下transformer,今天就来讲讲它~
Transformer是谷歌大脑2017年在论文attention is all you need中提出来的seq2seq模型,它的本质就是由编码器和解码器组成,今天的主角则是其中的编码器(在BERT预训练模型中也只用到了编码器部分)如下图所示,这个模块的输入为 𝑋 (每一行代表一个句子,batchsize有多大就有多少行),我们将从输入到隐藏层按照从1到4的顺序逐层来看一下各个维度的变化。

1. Input Embedding
所谓的Embedding其实就是查字典或者叫查表,也就是将一个句子里的每一个字转化为一个维度为embedding dimension的向量来表示,因此 𝑋 经过嵌入后变成 𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 ,三个维度分别表示一个批次的句子数,每个句子的字数,每个字的嵌入维度。
2. Positional Encoding
位置编码,按照字面意思理解就是给输入的位置做个标记,简单理解比如你就给一个字在句子中的位置编码1,2,3,4这样下去,高级点的比如作者用的正余弦函数
𝑃𝐸(𝑝𝑜𝑠,2𝑖)=𝑠𝑖𝑛(𝑝𝑜𝑠/100002𝑖/𝑑𝑚𝑜𝑑𝑒𝑙)
𝑃𝐸(𝑝𝑜𝑠,2𝑖+1)=𝑐𝑜𝑠(𝑝𝑜𝑠/100002𝑖/𝑑𝑚𝑜𝑑𝑒𝑙)
其中pos表示字在句子中的位置,i指的词向量的维度。经过位置编码,相当于能够得到一个和输入维度完全一致的编码数组 𝑋𝑝𝑜𝑠 ,当它叠加到原来的词嵌入上得到新的词嵌入
𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔=𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔+𝑋𝑝𝑜𝑠
此时的维度为:一个批次的句子数 × 一个句子的词数 × 一个词的嵌入维度
3. Multi-Head Attention
注意力机制,其实可以理解为就是在计算相关性,很自然的想法就是去更多地关注那些相关更大的东西。这里首先要引入Query,Key和Value的概念,Query就是查询的意思,Key就是键用来和你要查询的Query做比较,比较得到一个分数(相关性或者相似度)再乘以Value这个值得到最终的结果。
那么这个Q,K,V从哪里来呢,这里采用的是self-attention的方式,也就是从输入自己 𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 来产生,即做线性映射产生Q,K,V:
𝑄=𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔∗𝑊𝑄𝐾=𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔∗𝑊𝐾𝑉=𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔∗𝑊𝑉
这里三个权重矩阵均为维度为Embedding的方阵,也就是说Q,K,V的维度和 𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 是一致的。
接下来考虑什么叫做multi-head(多头)呢,本质上就是从embedding的维度上将矩阵切分为多份,每一份就是一个头,比如之前的Q,K,V切完后的维度就是一个批次的句子数 × 一个句子的词数 × 头数 × (词嵌入维度/头数)这个多头的切分体现在最后两个维度:词嵌入维度=数 × (词嵌入维度/头数)为了便于计算,通常会将第二第三维度进行转置,即最终的维度为一个批次的句子数 × 头数 × 一个句子的词数 × (词嵌入维度/头数)
接下来说说注意力机制的计算,假设Q,K,V为切分完后的矩阵(其中一个头),根据两个向量的点积越大越相似,我们通过 𝑄𝐾𝑇 求出注意力矩阵,再根据注意力矩阵来给Value进行加权,即
𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄,𝐾,𝑉)=𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝑄𝐾𝑇𝑑𝑘)𝑉
其中 𝑑𝑘 是为了把注意力矩阵变成标准正态分布,softmax进行归一化,使每个字与其他字的注意力权重之和为1。这一操作使得每一个字的嵌入都包含当前句子内所有字的信息,注意Attention(Q,K,V)的维度和 𝑉 的维度保持一致。
4. Add & Norm
这里主要做了两个操作
- 一个是残差连接(或者叫做短路连接),说得直白点就是把上一层的输入 𝑋 和上一层的输出加起来 𝑆𝑢𝑏𝐿𝑎𝑦𝑒𝑟(𝑋) ,即 𝑋+𝑆𝑢𝑏𝐿𝑎𝑦𝑒𝑟(𝑋) ,举例说明,比如在注意力机制前后的残差连接:
𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔+𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄,𝐾,𝑉)
- 一个是LayerNormalization(作用是把神经网络中隐藏层归一为标准正态分布,加速收敛),具体操作是将每一行的每一个元素减去这行的均值, 再除以这行的标准差, 从而得到归一化后的数值。
5. Feedforward + Add & Norm
前馈网络也就是简单的两层线性映射再经过激活函数一下,比如
𝑋ℎ𝑖𝑑𝑑𝑒𝑛=𝑅𝑒𝑙𝑢(𝑋ℎ𝑖𝑑𝑑𝑒𝑛∗𝑊1∗𝑊2)
残差操作和层归一化同步骤3.
上述的1,2,3,4就构成Transformer中的一个encoder模块,经过1,2,3,4后得到的就是encode后的隐藏层表示,可以发现它的维度其实和输入是一致的!即:一个批次中句子数 × 一个句子的字数 × 字嵌入的维度
6.代码展示
(1)layer_norm
bs=2,seq=3,dim=5
import torchbatch_size = 2
seq = 3
fea_dim = 5
X = torch.rand(batch_size,seq,fea_dim)
layer_norm = torch.nn.LayerNorm(fea_dim)
out = layer_norm(X)
print(out)
print('-'*30)mean = torch.mean(X,dim=-1,keepdim=True)
std = torch.sqrt(torch.var(X,unbiased=False,dim=-1,keepdim=True) + 1e-5)
weight = layer_norm.state_dict()['weight']
bias = layer_norm.state_dict()['bias']
my_norm = ((X - mean)/std) * weight + bias
print(my_norm)(2)encoder_layer=1
bs=1,seq=1,dim=6,head=1
import torchseq = 1
dim = 6
heads = 1
batch_size = 1
value = torch.rand(batch_size,seq,dim)encoder_layer = torch.nn.TransformerEncoderLayer(dim,heads,dropout=0.0,batch_first=True)
out = encoder_layer(value)
print(out)# 多头自注意力
def my_scaled_dot_product(query,key,value):qk_T = torch.mm(query,key.T)qk_T_scale = qk_T / torch.sqrt(torch.tensor(value.shape[1]))qk_exp = torch.exp(qk_T_scale)qk_exp_sum = torch.sum(qk_exp,dim=1,keepdim=True)qk_softmax = qk_exp / qk_exp_sumv_attn = torch.mm(qk_softmax,value)return v_attn,qk_softmaxin_proj_weight = encoder_layer.state_dict()['self_attn.in_proj_weight']
in_proj_bias = encoder_layer.state_dict()['self_attn.in_proj_bias']out_proj_weight = encoder_layer.state_dict()['self_attn.out_proj.weight']
out_proj_bias = encoder_layer.state_dict()['self_attn.out_proj.bias']batch_V_output = torch.empty(batch_size,seq,dim)
for i in range(batch_size):in_proj = torch.mm(value[i],in_proj_weight.T) + in_proj_biasQs,Ks,Vs = torch.split(in_proj,dim,dim=-1)head_Vs = []attn_weight = torch.zeros(seq,seq)for Q,K,V in zip(torch.split(Qs,dim//heads,dim=-1),torch.split(Ks,dim//heads,dim=-1),torch.split(Vs,dim//heads,dim=-1)):head_v,_ = my_scaled_dot_product(Q,K,V)head_Vs.append(head_v)V_cat = torch.cat(head_Vs,dim=-1)V_ouput = torch.mm(V_cat,out_proj_weight.T) + out_proj_biasbatch_V_output[i] = V_ouput# 第一次加
first_Add = value + batch_V_output# 第一次layer_norm
norm1_mean = torch.mean(first_Add,dim=-1,keepdim=True)
norm1_std = torch.sqrt(torch.var(first_Add,unbiased=False,dim=-1,keepdim=True) + 1e-5)
norm1_weight = encoder_layer.state_dict()['norm1.weight']
norm1_bias = encoder_layer.state_dict()['norm1.bias']
norm1 = ((first_Add - norm1_mean)/norm1_std) * norm1_weight + norm1_bias# feed forward
linear1_weight = encoder_layer.state_dict()['linear1.weight']
linear1_bias = encoder_layer.state_dict()['linear1.bias']
linear2_weight = encoder_layer.state_dict()['linear2.weight']
linear2_bias = encoder_layer.state_dict()['linear2.bias']
linear1 = torch.matmul(norm1,linear1_weight.T) + linear1_bias
linear1_relu = torch.nn.functional.relu(linear1)
linear2 = torch.matmul(linear1_relu,linear2_weight.T) + linear2_bias# 第二次加
second_Add = norm1 + linear2# 第二次layer_norm
norm2_mean = torch.mean(second_Add,dim=-1,keepdim=True)
norm2_std = torch.sqrt(torch.var(second_Add,unbiased=False,dim=-1,keepdim=True) + 1e-5)
norm2_weight = encoder_layer.state_dict()['norm2.weight']
norm2_bias = encoder_layer.state_dict()['norm2.bias']
norm2 = ((second_Add - norm2_mean)/norm2_std) * norm2_weight + norm2_bias
print(norm2)相关文章:
Transformer详解encoder
目录 1. Input Embedding 2. Positional Encoding 3. Multi-Head Attention 4. Add & Norm 5. Feedforward Add & Norm 6.代码展示 (1)layer_norm (2)encoder_layer1 最近刚好梳理了下transformer,今…...

ISO 19110操作要求类/req/operation/signature的详细解释
/req/operation/signature 要求: 每个要素操作实体必须有且仅有一个在要素目录范围内唯一的“signature”属性。 附注: 签名(signature)指定了操作的名称和调用该操作所需的参数名称。 具体解释 定义 要素操作实体(feature operation …...

理解GPT2:无监督学习的多任务语言模型
目录 一、背景与动机 二、卖点与创新 三、几个问题 四、具体是如何做的 1、更多、优质的数据,更大的模型 2、大数据量,大模型使得zero-shot成为可能 3、使用prompt做下游任务 五、一些资料 一、背景与动机 基于 Transformer 解码器的 GPT-1 证明…...

深度学习11-20
1.神经元的个数对结果的影响: (http://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html) (1)神经元3个的时候 (2)神经元是10个的时候 神经元个数越多,可能会产生…...

耐磨材料元宇宙:探索未来科技的无限可能
随着科技的不断发展,我们正逐渐进入一个全新的时代——元宇宙。在这个虚拟世界中,人们可以自由地创造、探索和交流。而在元宇宙中,耐磨材料作为一种重要的基础资源,将为我们的虚拟世界带来更多的可能性。 一、耐磨材料在元宇宙中…...

力扣2874.有序三元组中的最大值 II
力扣2874.有序三元组中的最大值 II 遍历j –> 找j左边最大数 和右边最大数 class Solution {public:long long maximumTripletValue(vector<int>& nums) {int n nums.size();vector<int> suf_max(n1,0);//右边最大数for(int in-1;i>1;i--){suf_max[i…...

Linux-笔记 嵌入式gdb远程调试
目录 前言 实现 1、内核配置 2、GDB移植 3、准备调试程序 4、开始调试 前言 gdb调试器是基于命令行的GNU项目调试器,通过gdb工具我们可以实现许多调试手段,同时gdb支持多种语言,兼容性很强。 在桌面 Linux 系统(如 Ubuntu、Cent…...

观测云产品更新 | Pipelines、智能监控、日志数据访问等
观测云更新 Pipelines 1、Pipelines:支持选择中心 Pipeline 执行脚本。 2、付费计划与账单:新增中心 Pipeline 计费项,统计所有命中中心 Pipeline 处理的原始日志的数据大小。 监控 1、通知对象管理:新增权限控制。配置操作权…...

docker 拉取不到镜像的问题:拉取超时
如果每次拉取的时候遇到超时 error pulling image configuration: download failed after attempts6: dial tcp 31.13.94.10:443: i/o timeout 解决方法如下: 设置国内镜像源: sudo mkdir -p /etc/docker 然后 sudo gedit /etc/docker/daemon.json 或…...
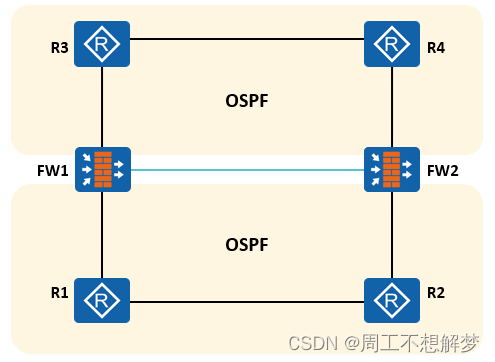
防火墙双机热备
防火墙双机热备 随着移动办公、网上购物、即时通讯、互联网金融、互联网教育等业务蓬勃发展,网络承载的业务越来越多,越来越重要。所以如何保证网络的不间断传输成为网络发展过程中急需解决的一个问题。 防火墙部署在企业网络出口处,内外网之…...

30分钟学习如何搭建扩散模型的运行环境【pytorch版】【B站视频教程】【解决环境搭建问题】
30分钟学习如何搭建扩散模型的运行环境【B站视频教程】【解决环境搭建问题】 动手学习扩散模型 点击以下链接即可进入学习: B站视频教程附赠:环境配置安装(配套讲解文档) 视频 讲解主要内容 一、环境设置 1.本地安装…...
)
使用Java连接数据库并且执行数据库操作和创建用户登录图形化界面(1)
创建一个Java程序,建立与本机mysql服务器上student数据库的连接,实现在tb_student学生表上插入一条学生信息:学号21540118,姓名王五,性别男,出生日期2003-12-10,所在学院5。 使用JDBC连接数据库…...

HarmonyOS Next开发学习手册——弹性布局 (Flex)
概述 弹性布局( Flex )提供更加有效的方式对容器中的子元素进行排列、对齐和分配剩余空间。常用于页面头部导航栏的均匀分布、页面框架的搭建、多行数据的排列等。 容器默认存在主轴与交叉轴,子元素默认沿主轴排列,子元素在主轴…...
centOS7网络配置_NAT模式设置
第一步:查看电脑网卡 nat模式对应本地网卡的VMnet 8 ,查看对应的IP地址。 第二步:虚拟网络编辑器 打开VMWare,编辑--虚拟网络编辑器,整个都默认设置好了,只需要查看对应的DHCP设置中对应的IP的起始&#…...

喜报 | 极限科技获得北京市“创新型”中小企业资格认证
2024年6月20日,北京市经济和信息化局正式发布《关于对2024年度4月份北京市创新型中小企业名单进行公告的通知》,极限数据(北京)科技有限公司凭借其出色的创新能力和卓越的企业实力,成功获得“北京市创新型中小企业”的…...

整合Spring Boot和Pulsar实现可扩展的消息处理
整合Spring Boot和Pulsar实现可扩展的消息处理 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在现代分布式系统中,消息队列是实现异步通信和解耦…...
如何给WPS、Word、PPT等办公三件套添加收费字体---方正仿宋GBK
1.先下载需要的字体。 下载字体的网站比较多,基本上都是免费的。随便在网上搜索一个就可以了,下面是下载的链接。 方正仿宋GBK字体免费下载和在线预览-字体天下 www.fonts.net.cn/font-31602268591.html 注意:切记不要商用,以免…...
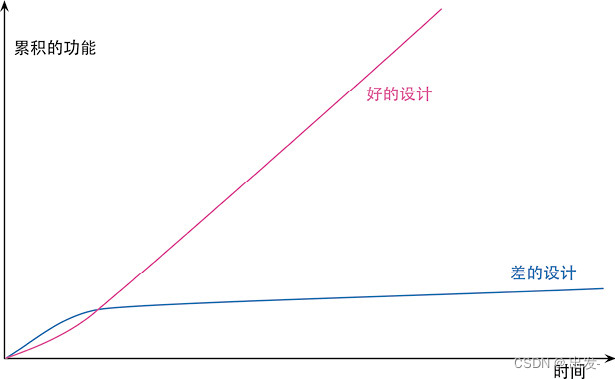
《重构》读书笔记【第1章 重构,第一个示例,第2章 重构原则】
文章目录 第1章 重构,第一个示例1.1 重构前1.2 重构后 第2章 重构原则2.1 何谓重构2.2 两顶帽子2.3 为何重构2.4 何时重构2.5 重构和开发过程 第1章 重构,第一个示例 我这里使用的IDE是IntelliJ IDEA 1.1 重构前 plays.js export const plays {&quo…...
学会整理电脑,基于小白用户(无关硬件升级)
如果你不想进行硬件升级,就要学会进行整理维护电脑 基于小白用户,每一个操作点我都会在后续整理出流程,软件推荐会选择占用小且实用的软件 主要从三个角度去讨论【如果有新的内容我会随时修改,也希望有补充告诉我,我…...
使用ioDraw,AI绘图只需几秒钟!
只需几秒钟,就能将文字或图片转化为精准的思维导图、流程图、折线图、柱状图、饼图等各种图表! 思维导图 思维导图工具使用入口 文字转思维导图 将文本大纲或想法转换成可视化的思维导图,以组织和结构化您的想法。 图片转思维导图 从现有…...
)
ElevenLabs成年男性语音定制全流程(含Stability Score阈值表+Voice Embedding相似度热力图)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs成年男性语音定制的核心价值与适用边界 ElevenLabs 的成年男性语音定制能力,本质上是通过深度神经声码器与说话人嵌入(speaker embedding)联合建模实现的高…...
)
新手也能玩转CTF内存取证:从Win7镜像到Volatility插件实战(附Gimp调图技巧)
新手也能玩转CTF内存取证:从Win7镜像到Volatility插件实战(附Gimp调图技巧) 当你第一次接触CTF比赛中的内存取证题目时,面对一个陌生的内存镜像文件和一堆专业工具,可能会感到无从下手。本文将带你从零开始,…...

在macOS上运行Windows应用:为什么传统方案失败而Whisky成功
在macOS上运行Windows应用:为什么传统方案失败而Whisky成功 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 你是否曾经面临这样的困境:手头有一款必须使用的W…...

Cursor Free VIP:一键解决Cursor AI试用限制的智能工具
Cursor Free VIP:一键解决Cursor AI试用限制的智能工具 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...

百度网盘秒传链接终极指南:免费在线转存、生成与转换全攻略
百度网盘秒传链接终极指南:免费在线转存、生成与转换全攻略 【免费下载链接】baidupan-rapidupload 百度网盘秒传链接转存/生成/转换 网页工具 (全平台可用) 项目地址: https://gitcode.com/gh_mirrors/bai/baidupan-rapidupload 还在为百度网盘文件分享的繁…...

AI专著撰写秘籍!AI专著生成工具助力,3天完成20万字专著写作!
撰写学术专著时,研究者必须在“内容的深度”和“覆盖的广度”之间找到一个合适的平衡点,这往往是很多学者面临的挑战。从深度来看,AI专著写作要确保核心观点具备充足的学术基础,不仅要清楚地回答“是什么”,还要深入探…...

使用 Taotoken CLI 工具一键配置多开发环境与团队协作密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken CLI 工具一键配置多开发环境与团队协作密钥 在团队协作开发中,统一大模型 API 的接入配置是一项基础但繁…...

VSCode经典体验配置指南:从界面净化到键盘流工作流打造
1. 项目概述:为什么我们需要一个“经典体验”的VSCode?如果你和我一样,是个在代码编辑器里泡了十多年的老程序员,那你一定经历过从记事本、Notepad、Sublime Text到Visual Studio Code(VSCode)的漫长迁徙。…...
)
【从零学Vibe Coding】第二章:大模型到底是怎么工作的(小白版)
第二章:大模型到底是怎么工作的(小白版) 为什么要了解原理? 很多人一边用 AI 写代码,一边又觉得它像魔法。魔法感越强,失望也越大。 因为一旦它出错,你就不知道问题出在哪,只能骂一…...

在ARM架构Windows上,用Hyper-V快速部署Ubuntu Server 22.04 LTS
1. 为什么选择ARM架构WindowsHyper-V跑Ubuntu? 最近两年ARM架构的Windows设备越来越多了,像Surface Pro X这样的设备用起来确实轻便省电。但很多开发者发现,想在ARM电脑上跑个Linux环境测试代码,总会遇到各种兼容性问题。我自己用…...