吴恩达机器学习 第三课 week2 推荐算法(上)
目录
01 学习目标
02 推荐算法
2.1 定义
2.2 应用
2.3 算法
03 协同过滤推荐算法
04 电影推荐系统
4.1 问题描述
4.2 算法实现
05 总结
01 学习目标
(1)了解推荐算法
(2)掌握协同过滤推荐算法(Collaborative Filtering Recommender Algorithm)原理
(3)利用协同过滤算法实现“电影推荐系统”
02 推荐算法
2.1 定义
推荐算法是信息过滤系统中的一种技术,旨在预测用户对未接触过的物品的喜好程度,并据此向用户推荐相应的物品。
2.2 应用
推荐系统广泛应用于电商、社交媒体、音视频平台、新闻资讯等领域,可以提升用户体验、增加用户黏性和促进内容发现。
2.3 算法
推荐算法大致可以分为以下几类:

03 协同过滤推荐算法
下面基于一个生活场景来理解协同过滤算法的推荐逻辑。
假设小强在上午11:30打开饱了么外卖APP搜索附近的菜馆,小强只在APP上进行一次评分,且APP有家最近上架的新菜馆“老狼大盘鸡”。小强进入APP最先看到的会是哪家菜馆呢?我们来算一下!
假设下表中为该APP的全部数据(表中?表示未评过分或系统无法归类的菜馆):
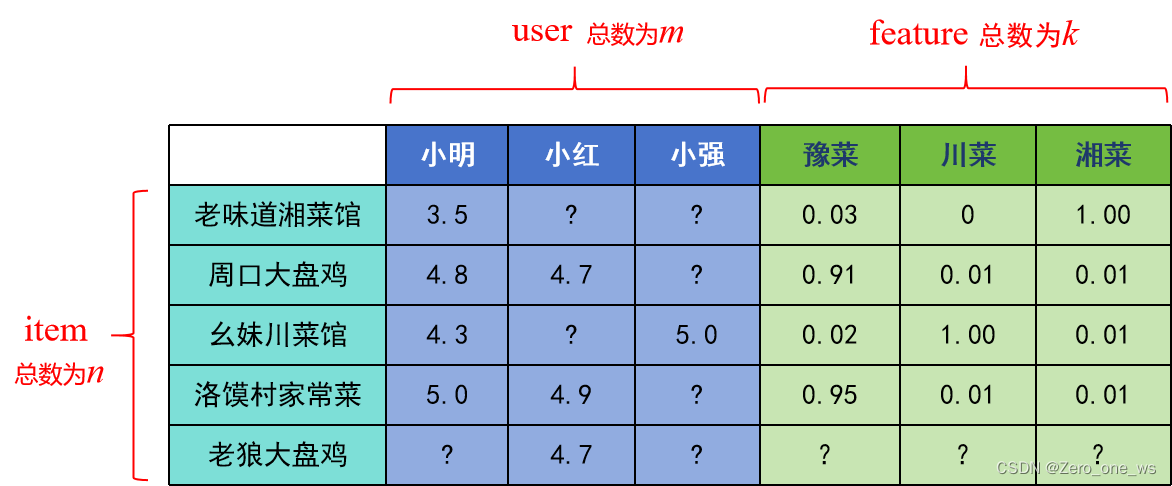
基于表中数据,可以提取以下数组(“0”替换“?”):
菜品特征矩阵(值:0~1):
用户评分矩阵:
评分判断矩阵(已评为1、未评为0):
此外,再构造一个用户参数矩阵W和用户参数向量b:
由以上5个矩阵,可以构造出预测用户评分的一般式如下:
式中,参数阵W和b采用梯度下降法计算得到,同时为防止参数过拟合,成本函数增加正则项,如下所示:
由于部分菜馆(老狼大盘鸡)的特征未知,因此增加了X的正则项。饱了么APP会根据成本最小原则预测出参数W和b及特征X,进而得到每位用户对不同菜馆的预测分数。最后预测出的小强的评分高低排序后,依次进行推荐,如下:

计算结果表明,口碑最好且“小强”没评过分(可能没吃过)的“洛馍村家常菜”排在最前面;而“老狼大盘鸡”是新上的菜馆,其排名竟然是第二,这可能是饱了么的常客“小红”的评论发挥了作用;第三名是“小强”曾经给过高分的“幺妹川菜馆”。完整代码如下:
# 导包
import numpy as np
import tensorflow as tf
from tensorflow import keras# 数据准备
X = np.array([[0.03, 0, 1], [0.91, 0.01, 0.01], [0.02, 1, 0.01], [0.95, 0.01, 0.01], [0, 0, 0]])
Y = np.array([[3.5, 0, 0], [4.8, 4.7, 0], [4.3, 0, 5], [5, 4.9, 0], [0, 4.7, 0]])
R = np.array([[1, 0, 0], [1, 1, 0], [1, 0, 1], [1, 1, 0], [0, 1, 0]])
label_ = ['老味道湘菜馆','周口大盘鸡','幺妹川菜馆','洛馍村家常菜','老狼大盘鸡']# 定义归一化函数、成本函数
def normalizeRatings(Y, R):Ymean = (np.sum(Y*R,axis=1)/(np.sum(R, axis=1)+1e-12)).reshape(-1,1)Ynorm = Y - np.multiply(Ymean, R) return(Ynorm, Ymean)def cofi_cost_func(X, W, b, Y, R, lambda_):"""Returns the cost for the content-based filteringArgs:X (ndarray (num_movies,num_features)): matrix of item featuresW (ndarray (num_users,num_features)) : matrix of user parametersb (ndarray (1, num_users) : vector of user parametersY (ndarray (num_movies,num_users) : matrix of user ratings of moviesR (ndarray (num_movies,num_users) : matrix, where R(i, j) = 1 if the i-th movies was rated by the j-th userlambda_ (float): regularization parameterReturns:J (float) : Cost"""error = tf.linalg.matmul(X, tf.transpose(W)) + b - Yj = tf.boolean_mask(error, tf.cast(R, tf.bool)) ** 2J = 0.5 * tf.reduce_sum(j) + (lambda_ / 2) * (tf.reduce_sum(X **2) + tf.reduce_sum(W **2))return J# 归一化处理
Ynorm, Ymean = normalizeRatings(Y, R)# 定义模型
n, m = Y.shape
k =3tf.random.set_seed(1234)
W = tf.Variable(tf.random.normal((m, k), dtype=tf.float64), name='W')
X = tf.Variable(tf.random.normal((n, k), dtype=tf.float64), name='X')
b = tf.Variable(tf.random.normal((1, m), dtype=tf.float64), name='b')optimizer = keras.optimizers.Adam(learning_rate=0.005)# 训练模型
iterations = 200
lambda_ = 1
for iter in range(iterations):with tf.GradientTape() as tape:cost = cofi_cost_func(X, W, b, Ynorm, R, lambda_)grads = tape.gradient(cost, [X, W, b])optimizer.apply_gradients(zip(grads, [X, W, b]))if iter %20 == 0:print(f'第{iter}次迭代的成本为:{cost.numpy()}')# 预测分数
y = np.matmul(X, np.transpose(W)) + b
y_m = y + Ymean # 恢复数值
pred = y_m[:,1] # 选择小强的结果
ix = tf.argsort(pred, direction='DESCENDING') # 降序排列# 推荐
for i in range(len(ix)):print(f'top{i +1}:{label_[ix[i]]},预测评分:{pred[ix[i]]:0.2f}')协同过滤(Collaborative Filtering, CF)中的“协同”二字,其核心意义在于“合作”或“协同工作”,“协同”本质是通过分析用户群或物品群之间的共同行为模式,来推断和预测单个用户的潜在喜好,从而实现个性化推荐。在推荐系统领域,这种“协同”体现在算法利用大量用户的行为数据(如评分、购买历史、浏览记录等),通过分析用户之间的共同偏好或者物品之间的相似性,来实现对用户可能感兴趣但尚未直接接触的物品的推荐。
具体来说,协同过滤算法分为两大类:
-
用户协同过滤(User-based Collaborative Filtering):在这种方法中,“协同”意味着算法寻找与目标用户兴趣相似的其他用户群体。算法分析这些相似用户喜欢的物品,并基于这些相似用户的偏好来推荐物品给目标用户。这里,用户之间的“协同”体现在他们的共同兴趣和行为模式上。
-
物品协同过滤(Item-based Collaborative Filtering):在物品协同过滤中,“协同”的概念体现为算法识别出经常被相同用户喜欢的物品集合,即使这些用户之间可能没有直接的相似性。换句话说,如果用户A喜欢物品X和Y,用户B也喜欢物品X,那么就可以推断用户B可能也会喜欢物品Y。这里,物品之间的“协同”是基于它们被共同评价或消费的模式。
04 电影推荐系统
4.1 问题描述
GroupLens 是明尼苏达大学双城分校计算机科学与工程系的一个研究实验室,专注于推荐系统、在线社区、移动和无处不在技术、数字图书馆和本地地理信息系统等领域。
我们从GroupLens网站的 MovieLens 栏目下载电影数据集,用于构建“电影推荐系统”。

4.2 算法实现
(1)导入所需模块
import numpy as np
import tensorflow as tf
from tensorflow import keras
from recsys_utils import *(recsys_utils模块内有数据读取函数load_precalc_params_small、load_ratings_small、load_Movie_List_pd以及归一化函数normalizeRatings)
(2)数据读取
# 读取数据
X, W, b, num_movies, num_features, num_users = load_precalc_params_small()
Y, R = load_ratings_small()
# 读取电影信息并提取名称列
movieList, movieList_df = load_Movie_List_pd()print("Y", Y.shape, "R", R.shape)
print("X", X.shape)
print("W", W.shape)
print("b", b.shape)
print("num_features", num_features)
print("num_movies", num_movies)
print("num_users", num_users)
print("movieList:\n",movieList[:5])
print("movieList_df:\n",movieList_df[:5])运行以上代码,结果如下:

(原始数据集包含由600名用户对9000部电影进行的评价。为了专注于2000年以后的电影,我们将数据集的规模缩小至包含443名用户和4778部电影。该数据集在0.5到5的范围内对电影进行评分,以0.5的步长递增)
(3)定义成本函数
def cofi_cost_func_v(X, W, b, Y, R, lambda_):"""Returns the cost for the content-based filteringVectorized for speed. Uses tensorflow operations to be compatible with custom training loop.Args:X (ndarray (num_movies,num_features)): matrix of item featuresW (ndarray (num_users,num_features)) : matrix of user parametersb (ndarray (1, num_users) : vector of user parametersY (ndarray (num_movies,num_users) : matrix of user ratings of moviesR (ndarray (num_movies,num_users) : matrix, where R(i, j) = 1 if the i-th movies was rated by the j-th userlambda_ (float): regularization parameterReturns:J (float) : Cost"""j = (tf.linalg.matmul(X, tf.transpose(W)) + b - Y)*RJ = 0.5 * tf.reduce_sum(j**2) + (lambda_/2) * (tf.reduce_sum(X**2) + tf.reduce_sum(W**2))return J(tf.linalg.matmul(X, tf.transpose(W)) 是一个使用 TensorFlow 库的矩阵乘法函数,其中 X 和 W 是两个张量(tensor),tf.transpose(W) 表示对张量 W 进行转置)
(4)目标用户数据提取
假设推荐目标用户是Tony,Tony的历史评分如下(我们手动添加):
my_ratings = np.zeros(num_movies) # Initialize my ratings# 手动添加Tony的评分
my_ratings[2700] = 5 # Toy Story 3 (2010)
my_ratings[2609] = 2 # Persuasion (2007)
my_ratings[929] = 5 # Lord of the Rings: The Return of the King, The
my_ratings[246] = 5 # Shrek (2001)
my_ratings[2716] = 3 # Inception
my_ratings[1150] = 5 # Incredibles, The (2004)
my_ratings[382] = 2 # Amelie (Fabuleux destin d'Amélie Poulain, Le)
my_ratings[366] = 5 # Harry Potter and the Sorcerer's Stone (a.k.a. Harry Potter and the Philosopher's Stone) (2001)
my_ratings[622] = 5 # Harry Potter and the Chamber of Secrets (2002)
my_ratings[988] = 3 # Eternal Sunshine of the Spotless Mind (2004)
my_ratings[2925] = 1 # Louis Theroux: Law & Disorder (2008)
my_ratings[2937] = 1 # Nothing to Declare (Rien à déclarer)
my_ratings[793] = 5 # Pirates of the Caribbean: The Curse of the Black Pearl (2003)
# 已评分电影的索引
my_rated = [i for i in range(len(my_ratings)) if my_ratings[i] > 0]# 将Tony的评分及相应的布尔数组添加至原数据中
Y = np.c_[my_ratings, Y]
R = np.c_[(my_ratings != 0).astype(int), R]print("\n(New user)Tony's ratings:\n")
for i in range(len(my_ratings)):if my_ratings[i] > 0 :print(f'Rated {my_ratings[i]} for {movieList_df.loc[i,"title"]}')("my_rated = [i for i in range(len(my_ratings)) if my_ratings[i] > 0]": range(len(my_ratings)) 会生成一个从0到 len(my_ratings)-1 的整数序列,如果 my_ratings[i]大于0,那么i 就会被添加到 my_rated 列表中)
(my_ratings != 0将my_ratings 中不等于0的数转为true,等于0的数转为false(布尔数组),astype(int) 将该布尔数组转换为整数数组(0和1)然后用np.c_[] 将两个布尔数组按列合并)
运行以上代码,结果如下:

(5)数据归一化
Ynorm, Ymean = normalizeRatings(Y, R)(6)定义模型
num_movies, num_users = Y.shape
num_features = 100# 采用tf.Variable 初始化参数
tf.random.set_seed(1234) # for consistent results
W = tf.Variable(tf.random.normal((num_users, num_features),dtype=tf.float64), name='W')
X = tf.Variable(tf.random.normal((num_movies, num_features),dtype=tf.float64), name='X')
b = tf.Variable(tf.random.normal((1, num_users), dtype=tf.float64), name='b')# 设置优化器、学习率
optimizer = keras.optimizers.Adam(learning_rate=1e-1)(7)训练模型
iterations = 200
lambda_ = 1
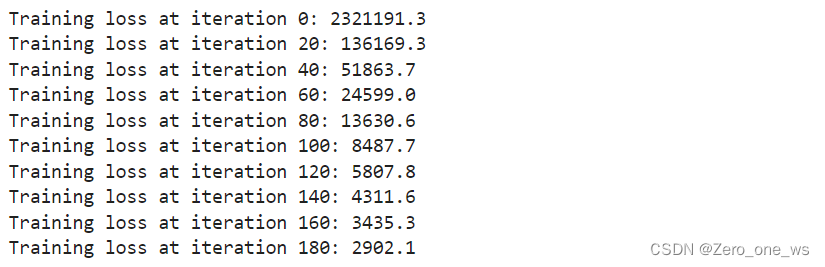
for iter in range(iterations): # 使用TensorFlow的GradientTape记录用于计算成本的操作with tf.GradientTape() as tape:# Compute the costcost_value = cofi_cost_func_v(X, W, b, Ynorm, R, lambda_)# 使用梯度记录器自动获取可训练变量相对于损失的梯度。grads = tape.gradient( cost_value, [X,W,b] )# 通过更新变量的值来进行一次梯度下降,以使损失函数达到最小值。optimizer.apply_gradients( zip(grads, [X,W,b]) )# 打印进度if iter % 20 == 0:print(f"Training loss at iteration {iter}: {cost_value:0.1f}")运行以上代码,结果如下:
(8)电影推荐
# 计算概率
p = np.matmul(X.numpy(), np.transpose(W.numpy())) + b.numpy()
# 归一化恢复
pm = p + Ymean
# 提取Tony的数据
my_predictions = pm[:,0]
# sort predictions返回降序索引
ix = tf.argsort(my_predictions, direction='DESCENDING')# 推荐Tony未评价过的电影(从预测评分top17的电影中挑选)
for i in range(17):j = ix[i]if j not in my_rated:print(f'Predicting rating {my_predictions[j]:0.2f} for movie {movieList[j]}')# 测试比对user评分的真实值与预测值
print('\n\nOriginal vs Predicted ratings:\n')
for i in range(len(my_ratings)):if my_ratings[i] > 0:print(f'Original {my_ratings[i]}, Predicted {my_predictions[i]:0.2f} for {movieList[i]}')运行以上代码,结果如下:

上面的代码实现了两个功能:一是向Tony推荐了他从未评分的电影,二是将Tony评过分的13部电影分数与预测分数进行了对比,可以发现,如果考虑四舍五入的话,预测分数与Tony的评分完全一致。
05 总结
(1)协同过滤算法的原理类似于多元线性回归,包括数据处理、定义模型、拟合参数及预测这4个关键步骤,相较于人工神经网络的“黑箱子”计算,协同过滤算法的计算过程更易理解。
(2) 在协同过滤算法处理大批量数据时,采用tensorflow的张量计算和GradientTape可以迅速实现梯度下降,可以大幅提升计算效率。
(3)不同的工程师设计的同类算法,可能推荐结果并不一致,这可能引出道德或伦理问题,比如某些平台可能会优先推荐利润率大而不是最适合用户的商品。
相关文章:
吴恩达机器学习 第三课 week2 推荐算法(上)
目录 01 学习目标 02 推荐算法 2.1 定义 2.2 应用 2.3 算法 03 协同过滤推荐算法 04 电影推荐系统 4.1 问题描述 4.2 算法实现 05 总结 01 学习目标 (1)了解推荐算法 (2)掌握协同过滤推荐算法(Collabo…...

MySQL CASE 表达式
MySQL CASE表达式 一、CASE表达式的语法二、 常用场景1,按属性分组统计2,多条件统计3,按条件UPDATE4, 在CASE表达式中使用聚合函数 三、CASE表达式出现的位置 一、CASE表达式的语法 -- 简单CASE表达式 CASE sexWHEN 1 THEN 男WHEN 2 THEN 女…...

Unity3D 游戏数据本地化存储与管理详解
在Unity3D游戏开发中,数据的本地化存储与管理是一个重要的环节。这不仅涉及到游戏状态、玩家信息、游戏设置等关键数据的保存,还关系到游戏的稳定性和用户体验。本文将详细介绍Unity3D中游戏数据的本地化存储与管理的技术方法,并给出相应的代…...

昇思25天学习打卡营第1天|初学教程
文章目录 背景创建环境熟悉环境打卡记录学习总结展望未来 背景 参加了昇思的25天学习记录,这里给自己记录一下所学内容笔记。 创建环境 首先在平台注册账号,然后登录,按下图操作,创建环境即可 创建好环境后进入即可࿰…...
ctfshow-web入门-命令执行(web59-web65)
目录 1、web59 2、web60 3、web61 4、web62 5、web63 6、web64 7、web65 都是使用 highlight_file 或者 show_source 1、web59 直接用上一题的 payload: cshow_source(flag.php); 拿到 flag:ctfshow{9e058a62-f37d-425e-9696-43387b0b3629} 2、w…...
Websocket在Java中的实践——最小可行案例
大纲 最小可行案例依赖开启Websocket,绑定路由逻辑类 测试参考资料 WebSocket是一种先进的网络通信协议,它允许在单个TCP连接上进行全双工通信,即数据可以在同一时间双向流动。WebSocket由IETF标准化为RFC 6455,并且已被W3C定义为…...

python请求报错::requests.exceptions.ProxyError: HTTPSConnectionPool
在发送网页请求时,发现很久未响应,最后报错: requests.exceptions.ProxyError: HTTPSConnectionPool(hostsvr-6-9009.share.51env.net, port443): Max retries exceeded with url: /prod-api/getInfo (Caused by ProxyError(Unable to conne…...
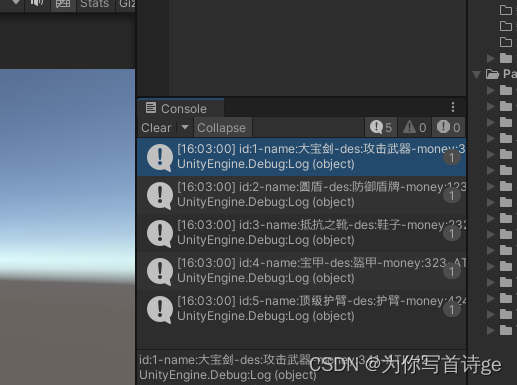
【Unity】Excel配置工具
1、功能介绍 通过Excel表配置表数据,一键生成对应Excel配置表的数据结构类、数据容器类、已经二进制数据文件,加载二进制数据文件获取所有表数据 需要使用Excel读取的dll包 2、关键代码 2.1 ExcelTool类 实现一键生成Excel配置表的数据结构类、数据…...
)
001 线性查找(lua)
文章目录 迭代器主程序 迭代器 -- 定义一个名为 linearSearch 的函数,它接受两个参数:data(一个数组)和 target(一个目标值) function linearSearch(data, target) -- 使用 for 循环遍历数组 data&…...

数据结构之链表
储备知识: 线性表 :一对一的数据所组成的关系称为线性表。 线性表是一种数据内部的逻辑关系,与存储形式无关线性表既可以采用连续的顺序存储(数组),也可以采用离散的链式存储(链表)顺序表和链表都称为线性表 顺序存储就是将数据存…...

【小工具】 Unity相机宽度适配
相机默认是根据高度适配的,但是在部分游戏中需要根据宽度进行适配 实现步骤 定义标准屏幕宽、高判断标准屏幕宽高比与当前的是否相等通过**(标准宽度/当前宽度) (标准高度 / 当前高度)**计算缩放调整相机fieldOfView即…...

centos误删yum和python
在下载pkdg时,因为yum报错坏的解释器,然后误删了yum和python。 在下载各种版本,创建各种软连接,修改yum文件都不好使后,发现了这样一个方法:Centos: 完美解决python升级导致的yum报错问题(相信…...

WP黑格导航主题BlackCandy
BlackCandy-V2.0全新升级!首推专题区(推荐分类)更多自定义颜色!选择自己喜欢的色系,焕然一新的UI设计,更加扁平和现代化! WP黑格导航主题BlackCandy...

elasticsearch底层核心组件
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎,它基于Apache Lucene构建,并添加了分布式特性。以下是Elasticsearch的一些底层核心组件: 1. **Lucene**: - Elasticsearch基于Apache Lucene,一个高性能的…...
EasyExcel数据导入
前言: 我先讲一种网上信息的获取方式把,虽然我感觉和后面的EasyExcel没有什么关系,可能是因为这个项目这个操作很难实现,不过也可以在此记录一下,如果需要再拆出来也行。 看上了网页信息,怎么抓到&#x…...

20240630 每日AI必读资讯
📚全美TOP 5机器学习博士发帖吐槽:实验室H100数量为0! - 普林斯顿、哈佛「GPU豪门」,手上的H100至少三四百块,然而绝大多数ML博士一块H100都用不上 - 年轻的研究者们纷纷自曝自己所在学校或公司的GPU情况:…...
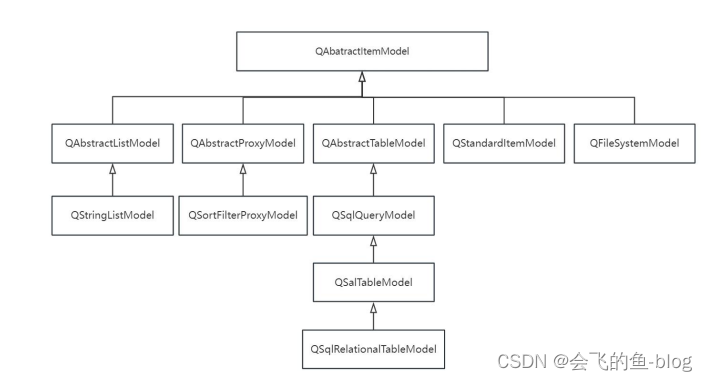
第十一章 Qt的模型视图
目录 一、模型/视图的原理 1、原理分析 2、模型(数据模型) 3、视图 4、代理 二、文件系统模型 1、项目练习 2、UI 设计 3、代码实现 三、字符串链表模型 QStringListModel 1、项目效果 2、项目实现 四、标准项模型(QStandardItemModel) 1、模型分析 2、项目效…...

力扣 单词规律
所用数据结构 哈希表 核心方法 判断字符串pattern 和字符串s 是否存在一对一的映射关系,按照题意,双向连接的对应规律。 思路以及实现步骤 1.字符串s带有空格,因此需要转换成字符数组进行更方便的操作,将字符串s拆分成单词列表…...
10款好用不火的PC软件,真的超好用!
AI视频生成:小说文案智能分镜智能识别角色和场景批量Ai绘图自动配音添加音乐一键合成视频https://aitools.jurilu.com/市场上有很多软件,除了那些常见的大众化软件,还有很多不为人知的小众软件,它们的作用非常强大,简洁…...

Windows怎么实现虚拟IP
在做高可用架构时,往往需要用到虚拟IP,在linux上面有keepalived来实现虚拟ip的设置。在windows上面该怎么弄,keepalived好像也没有windows版本,我推荐一款浮动IP软件PanguVip,它可以实现windows上面虚拟ip的漂移。设置…...

Smithbox终极指南:如何轻松定制你的魂类游戏世界
Smithbox终极指南:如何轻松定制你的魂类游戏世界 【免费下载链接】Smithbox Smithbox is a modding tool for Elden Ring, Armored Core VI, Sekiro, Dark Souls 3, Dark Souls 2, Dark Souls, Bloodborne and Demons Souls. 项目地址: https://gitcode.com/gh_mi…...

OpenClaw 落地企业微信:AI 驱动办公,效率提升看得见
前言 在企业数字化办公场景下,将智能对话功能与企业微信集成可有效提升内部沟通效率和业务响应速度。本文系统阐述了OpenClaw与企业微信的对接方案,该方案采用可视化操作界面实现智能机器人的快速部署,助力企业便捷构建专属AI助手࿰…...

HBuilderX网站打包APP
下载HBuilderX安装包官网地址:https://www.dcloud.io/ 选择HBuilderX极客开发工具 点击DOWNLOAD 点击历史版本,这里为什么不下载最新的版本,是因为我一开始下载的最新版本,打包一直提示cannot find module babel-core 将HBuilder…...

知识竞赛代表队分组方法详解
🎲 知识竞赛代表队分组方法详解公平 均衡 策略 让每一支队伍都在合适的起点🎯 引言知识竞赛中,代表队的合理分组是赛事公平与精彩的基础。无论是学校比赛、企业活动还是大型公开赛,组织者都需要根据队伍数量和赛制选择合适的分…...

ARM Cortex-A72 GICv3中断处理机制与优化实践
1. ARM Cortex-A72 GIC CPU接口架构概述在ARMv8-A架构中,通用中断控制器(GIC)作为中断管理的核心组件,其CPU接口承担着处理器核心与中断源之间的桥梁作用。Cortex-A72处理器实现了GICv3架构规范,相较于前代GICv2,主要引入了以下关…...

终极指南:使用Tinke轻松探索和修改NDS游戏资源
终极指南:使用Tinke轻松探索和修改NDS游戏资源 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾经好奇任天堂DS游戏内部是如何组织的?想要提取游戏中的精美图片、动…...

2026年腾讯云部署OpenClaw/Hermes Agent 配置Token Plan怎么快速上手?看这篇
2026年腾讯云部署OpenClaw/Hermes Agent 配置Token Plan怎么快速上手?看这篇。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Toke…...

3步解决Beyond Compare 5评估模式错误:密钥生成与完全激活指南
3步解决Beyond Compare 5评估模式错误:密钥生成与完全激活指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 当Beyond Compare 5的30天评估期结束后,软件会显示"评…...

告别‘不是内部或外部命令’:手把手配置MsBuild.exe环境变量与命令行编译实战
1. 为什么命令行找不到MsBuild.exe? 刚装完系统或者新配置开发环境时,很多朋友都会遇到这个经典错误:在命令行输入msbuild后,系统提示"不是内部或外部命令"。这就像你拿着钥匙却找不到锁孔一样让人抓狂。其实这个问题90…...
,命令行实操完整版)
Linux 系统安装 MySQL(CentOS8/Ubuntu),命令行实操完整版
前言开发和服务器部署基本都是 Linux 环境,本篇手把手教你 CentOS8 和 Ubuntu 两大主流系统命令行安装 MySQL,全程命令复制即用,无多余操作。一、通用前置准备关闭防火墙、关闭 SELinux(服务器环境可选)bash运行# Cent…...