基于协同过滤的电影推荐与大数据分析的可视化系统
基于协同过滤的电影推荐与大数据分析的可视化系统
在大数据时代,数据分析和可视化是从大量数据中提取有价值信息的关键步骤。本文将介绍如何使用Python进行数据爬取,Hive进行数据分析,ECharts进行数据可视化,以及基于协同过滤算法进行电影推荐。
目录
1、豆瓣电影数据爬取
2、hive数据分析
3、echarts数据可视化
4、基于系统过滤进行电影推荐
1. 豆瓣电影数据爬取
首先,我们使用Python爬取豆瓣电影的相关数据。爬取的数据包括电影名称、评分、评价人数、电影详情链接、图片链接、摘要和相关信息,然后将mysql数据存到mysql中。
import pymysql
from bs4 import BeautifulSoup
import re # 正则表达式,进行文字匹配
import urllib.request, urllib.error # 指定URL,获取网页数据
import xlwt # 进行excel操作from data.mapper import savedata2mysqldef main():baseurl = "https://movie.douban.com/top250?start="datalist = getdata(baseurl)savedata2mysql(datalist)findLink = re.compile(r'<a href="(.*?)">') # 正则表达式模式的匹配,影片详情
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S让换行符包含在字符中,图片信息
findTitle = re.compile(r'<span class="title">(.*)</span>') # 影片片名
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') # 找到评分
findJudge = re.compile(r'<span>(\d*)人评价</span>') # 找到评价人数 #\d表示数字
findInq = re.compile(r'<span class="inq">(.*)</span>') # 找到概况
findBd = re.compile(r'<p class="">(.*?)</p>', re.S) # 找到影片的相关内容,如导演,演员等##获取网页数据
def getdata(baseurl):datalist = []for i in range(0, 10):url = baseurl + str(i * 25) ##豆瓣页面上一共有十页信息,一页爬取完成后继续下一页html = geturl(url)soup = BeautifulSoup(html, "html.parser") # 构建了一个BeautifulSoup类型的对象soup,是解析html的for item in soup.find_all("div", class_='item'): ##find_all返回的是一个列表data = [] # 保存HTML中一部电影的所有信息item = str(item) ##需要先转换为字符串findall才能进行搜索link = re.findall(findLink, item)[0] ##findall返回的是列表,索引只将值赋值data.append(link)imgSrc = re.findall(findImgSrc, item)[0]data.append(imgSrc)titles = re.findall(findTitle, item) ##有的影片只有一个中文名,有的有中文和英文if (len(titles) == 2):onetitle = titles[0]data.append(onetitle)twotitle = titles[1].replace("/", "") # 去掉无关的符号data.append(twotitle)else:data.append(titles)data.append(" ") ##将下一个值空出来rating = re.findall(findRating, item)[0] # 添加评分data.append(rating)judgeNum = re.findall(findJudge, item)[0] # 添加评价人数data.append(judgeNum)inq = re.findall(findInq, item) # 添加概述if len(inq) != 0:inq = inq[0].replace("。", "")data.append(inq)else:data.append(" ")bd = re.findall(findBd, item)[0]bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd)bd = re.sub('/', " ", bd)data.append(bd.strip()) # 去掉前后的空格datalist.append(data)return datalistdef geturl(url):head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"}req = urllib.request.Request(url, headers=head)try: ##异常检测response = urllib.request.urlopen(req)html = response.read().decode("utf-8")except urllib.error.URLError as e:if hasattr(e, "code"): ##如果错误中有这个属性的话print(e.code)if hasattr(e, "reason"):print(e.reason)return html
2. 数据分析
接下来,我们将爬取的数据导入Hive进行分析。Hive是一个基于Hadoop的数据仓库工具,提供了类SQL的查询功能。
导入数据到Hive
首先,将数据上传到HDFS(Hadoop分布式文件系统):
hdfs dfs -put douban_movies.csv /user/hive/warehouse/douban_movies.csv
在Hive中创建一个表并导入数据:
CREATE TABLE douban_movies (title STRING,rating FLOAT,review_count INT,link STRING,image STRING,summary STRING,info STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
LOAD DATA INPATH '/user/hive/warehouse/douban_movies.csv' INTO TABLE douban_movies;
数据分析
SELECT rating, COUNT(*) AS movie_count
FROM douban_movies
GROUP BY rating
ORDER BY rating DESC;
select chinese_name,rating
from douban_movies order
by rating desc limit 20
select chinese_name,review_count
from douban_movies
order by review_count desc limit 20
SELECT type,COUNT(*) AS movie_countFROM (SELECT CASEWHEN related_info LIKE '%犯罪%' THEN '犯罪'WHEN related_info LIKE '%剧情%' THEN '剧情'WHEN related_info LIKE '%爱情%' THEN '爱情'WHEN related_info LIKE '%同性%' THEN '同性'WHEN related_info LIKE '%喜剧%' THEN '喜剧'WHEN related_info LIKE '%动画%' THEN '动画'WHEN related_info LIKE '%奇幻%' THEN '奇幻'WHEN related_info LIKE '%冒险%' THEN '冒险'ELSE '其他'END AS typeFROM douban_movies) AS subqueryGROUP BY typeORDER BY movie_count DESC;
SELECT year,COUNT(*) AS movie_countFROM (SELECT REGEXP_SUBSTR(related_info, '[[:digit:]]{4}') AS yearFROM douban_movies) AS subqueryWHERE year IS NOT NULL GROUP BY yearORDER BY year desc limit 20;
SELECT CASE WHEN related_info LIKE '%美国%' THEN '美国'WHEN related_info LIKE '%中国%' THEN '中国'WHEN related_info LIKE '%中国大陆%' THEN '中国'WHEN related_info LIKE '%中国香港%' THEN '中国香港'WHEN related_info LIKE '%法国%' THEN '法国'WHEN related_info LIKE '%日本%' THEN '日本'WHEN related_info LIKE '%英国%' THEN '英国'WHEN related_info LIKE '%德国%' THEN '德国'ELSE '其他'END AS country,COUNT(*) AS movie_countFROM douban_moviesGROUP BY country;
3. 数据可视化
为了更直观地展示数据分析结果,我们使用ECharts进行数据可视化。ECharts是一个基于JavaScript的数据可视化库,同时使用django框架查询mysql数据返回给前端。
前端代码
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Data Analysis</title><!-- 引入 Pyecharts 的依赖库 -->{{ chart_html | safe }}<style>body {display: flex;justify-content: center;align-items: center;height: 100vh;margin: 0;}.container {text-align: center;}</style>
</head>
<body><div class="container"><h2>{{ button_name }}</h2><!-- 其他页面内容... -->
</div></body>
</html>
后端代码
def data_analysis(request, button_id):if button_id == 1:x,y = top20_movie_rating()line_chart = (Line().add_xaxis(xaxis_data=x).add_yaxis(series_name="电影评分", y_axis=y).set_global_opts(title_opts=opts.TitleOpts(title="电影评分top20")))chart_html = line_chart.render_embed()button_name = "折线图"elif button_id == 2:x,y = movie_review_count()bar_chart = (Bar().add_xaxis(xaxis_data=x).add_yaxis(series_name="电影评论数",y_axis=y).set_global_opts(title_opts=opts.TitleOpts(title="电影评论数top20")))chart_html = bar_chart.render_embed()button_name = "条形图"elif button_id == 3:chart_html = wordcloud_to_html()button_name = "词云图"elif button_id == 4:x, y = movie_type_count()pie = Pie()pie.add("", list(zip(x, y)))pie.set_global_opts(title_opts={"text": "电影类型统计分析", "subtext": "年份"},legend_opts=opts.LegendOpts(orient="vertical", pos_right="right", pos_top="center"))chart_html = pie.render_embed()button_name = "饼图"elif button_id == 5:x,y=movie_year_count()# 创建饼图pie = (Pie(init_opts=opts.InitOpts(width="800px", height="600px")).add(series_name="不同年份的电影数量分析",data_pair=list(zip(x, y)),radius=["40%", "75%"], # 设置内外半径,实现空心效果label_opts=opts.LabelOpts(is_show=True, position="inside"),).set_global_opts(title_opts=opts.TitleOpts(title="不同年份的电影数量分析"),legend_opts=opts.LegendOpts(orient="vertical", pos_right="right", pos_top="center"),).set_series_opts( # 设置系列选项,调整 is_show 阈值label_opts=opts.LabelOpts(is_show=True)))chart_html = pie.render_embed()button_name = "饼图"elif button_id == 6:x, y = movie_count_count()bar_chart = (Bar().add_xaxis(xaxis_data=x).add_yaxis(series_name="电影数量", y_axis=y).set_global_opts(title_opts=opts.TitleOpts(title="不同国家的电影数量分析")))chart_html = bar_chart.render_embed()button_name = "条形图"elif button_id == 0:return redirect('movie_recommendation')return render(request, 'data_analysis.html', {'chart_html': chart_html, 'button_name': button_name})






4. 电影推荐
最后,我们基于协同过滤算法进行电影推荐。协同过滤是推荐系统中常用的一种算法,通过用户的行为数据(如评分、点击等)来预测用户可能感兴趣的项目。
这里我们使用 sklearn 库来实现协同过滤推荐系统。
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import mysql.connector# 数据库连接参数
db_config = {'user': 'root','password': '12345678','host': '127.0.0.1','database': 'mydb'
}# 连接到数据库
conn = mysql.connector.connect(**db_config)
cursor = conn.cursor()# 读取电影数据
query = "SELECT id, foreign_name, chinese_name, rating, review_count, summary, related_info FROM douban_movies"
movies_df = pd.read_sql(query, conn)# 处理文本特征:电影外文名、简介、相关信息
tfidf_vectorizer = TfidfVectorizer(stop_words='english')# 外文名的TF-IDF向量
foreign_name_tfidf = tfidf_vectorizer.fit_transform(movies_df['foreign_name'].fillna(''))# 简介的TF-IDF向量
summary_tfidf = tfidf_vectorizer.fit_transform(movies_df['summary'].fillna(''))# 相关信息的TF-IDF向量
related_info_tfidf = tfidf_vectorizer.fit_transform(movies_df['related_info'].fillna(''))# 数值特征:评分和评论数
scaler = StandardScaler()rating_scaled = scaler.fit_transform(movies_df[['rating']].fillna(0))
review_count_scaled = scaler.fit_transform(movies_df[['review_count']].fillna(0))# 合并所有特征
features = np.hstack([foreign_name_tfidf.toarray(),summary_tfidf.toarray(),related_info_tfidf.toarray(),rating_scaled,review_count_scaled
])# 计算电影之间的余弦相似度
cosine_sim = cosine_similarity(features)# 将相似度矩阵转换为DataFrame
cosine_sim_df = pd.DataFrame(cosine_sim, index=movies_df['id'], columns=movies_df['id'])# 将相似度结果存储到数据库
similarities = []
for movie_id in cosine_sim_df.index:similar_movies = cosine_sim_df.loc[movie_id].sort_values(ascending=False).index[1:6] # 取前5个相似的电影for similar_movie_id in similar_movies:similarity = cosine_sim_df.loc[movie_id, similar_movie_id]similarities.append((int(movie_id), int(similar_movie_id), float(similarity)))print(similarities)
# 插入相似度数据到数据库
insert_query = """
INSERT INTO movie_similarities (movie_id, similar_movie_id, similarity)
VALUES (%s, %s, %s)
"""
cursor.executemany(insert_query, similarities)
conn.commit()# 关闭连接
cursor.close()
conn.close()
总结
通过本文,我们展示了如何使用Python进行数据爬取,如何将数据导入Hive进行分析,如何使用ECharts进行数据可视化,以及如何使用协同过滤算法进行电影推荐。这个流程展示了从数据采集、数据分析到数据可视化和推荐系统的完整数据处理流程。
如有遇到问题可以找小编沟通交流哦。另外小编帮忙辅导大课作业,学生毕设等。不限于MapReduce, MySQL, python,java,大数据,模型训练等。 hadoop hdfs yarn spark Django flask flink kafka flume datax sqoop seatunnel echart可视化 机器学习等

相关文章:
基于协同过滤的电影推荐与大数据分析的可视化系统
基于协同过滤的电影推荐与大数据分析的可视化系统 在大数据时代,数据分析和可视化是从大量数据中提取有价值信息的关键步骤。本文将介绍如何使用Python进行数据爬取,Hive进行数据分析,ECharts进行数据可视化,以及基于协同过滤算法…...
修复vcruntime140.dll方法分享
修复vcruntime140.dll方法分享 最近在破解typora的时候出现了缺失vcruntime140.dll文件的报错导致软件启动失败。所以找了一番资料发现都不是很方便的处理,甚至有的dll处理工具还需要花钱????,我本来就是为…...

PostgreSQL的系统视图pg_stat_wal_receiver
PostgreSQL的系统视图pg_stat_wal_receiver 在 PostgreSQL 中,pg_stat_wal_receiver 视图提供了关于 WAL(Write-Ahead Logging)接收进程的统计信息。WAL 接收器是 PostgreSQL 集群中流复制的一部分,它在从节点中工作,…...
Qt之Pdb生成及Dump崩溃文件生成与调试(含注释和源码)
文章目录 一、Pdb生成及Dump文件使用示例图1.Pdb文件生成2.Dump文件调试3.参数不全Pdb生成的Dump文件调试 二、个人理解1.生成Pdb文件的方式2.Dump文件不生产的情况 三、源码Pro文件mian.cppMainWindowUi文件 总结 一、Pdb生成及Dump文件使用示例图 1.Pdb文件生成 下图先通过…...

视频号视频怎么保存到手机,视频号视频怎么保存到手机相册里,苹果手机电脑都可以用
随着数字媒体的蓬勃发展,视频已成为我们日常生活中不可或缺的一部分。视频号作为众多视频分享平台中的一员,吸引了大量用户上传和分享各类精彩视频。然而,有时我们可能希望将视频号上的视频下载下来,以下将详细介绍如何将视频号的视频。 方法…...
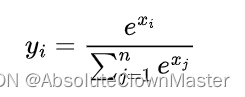
Softmax函数的作用
Softmax 函数主要用于多类别分类问题,它将输入的数值转换为概率分布。 具体来说,对于给定的输入向量 x [x_1, x_2,..., x_n] ,Softmax 函数的输出为 y [y_1, y_2,..., y_n] ,其中: 这样,Softmax 函数的输…...

cesium 添加 Echarts 图层(空气质量点图)
cesium 添加 Echarts 图层(下面附有源码) 1、实现思路 1、在scene上面新增一个canvas画布 2、通坐标转换,将经纬度坐标转为屏幕坐标来实现 3、将ecarts 中每个series数组中元素都加 coordinateSystem: ‘cesiumEcharts’ 2、示例代码 <!DOCTYPE html> <html lan…...

Python技术笔记汇总(含语法、工具库、数科、爬虫等)
对Python学习方法及入门、语法、数据处理、数据可视化、空间地理信息、爬虫、自动化办公和数据科学的相关内容可以归纳如下: 一、Python学习方法 分解自己的学习目标:可以将学习目标分基础知识,进阶知识,高级应用,实…...

Nacos-注册中心
一、注册中心的交互流程 注册中心通常有两个角色: 服务提供者(生产者):对外提供服务的微服务应用。它会把自身的服务地址注册到注册中心,以供消费者发现和调用。服务调用者(消费者):调用其他微服务的应用程序。它会向注册中心订阅自己需要的服…...
Unity制作一个简单抽卡系统(简单好抄)
业务流程:点击抽卡——>播放动画——>显示抽卡面板——>将随机结果添加到面板中——>关闭面板 1.准备素材并导入Unity中(包含2个抽卡动画,抽卡结果的图片,一个背景图片,一个你的展示图片) 2.给…...
简单多状态DP问题
这里写目录标题 什么是多状态DP解决多状态DP问题应该怎么做?关于多状态DP问题的几道题1.按摩师2.打家劫舍Ⅱ3.删除并获得点数4.粉刷房子5.买卖股票的最佳时期含手冷冻期 总结 什么是多状态DP 多状态动态规划(Multi-State Dynamic Programming, Multi-St…...
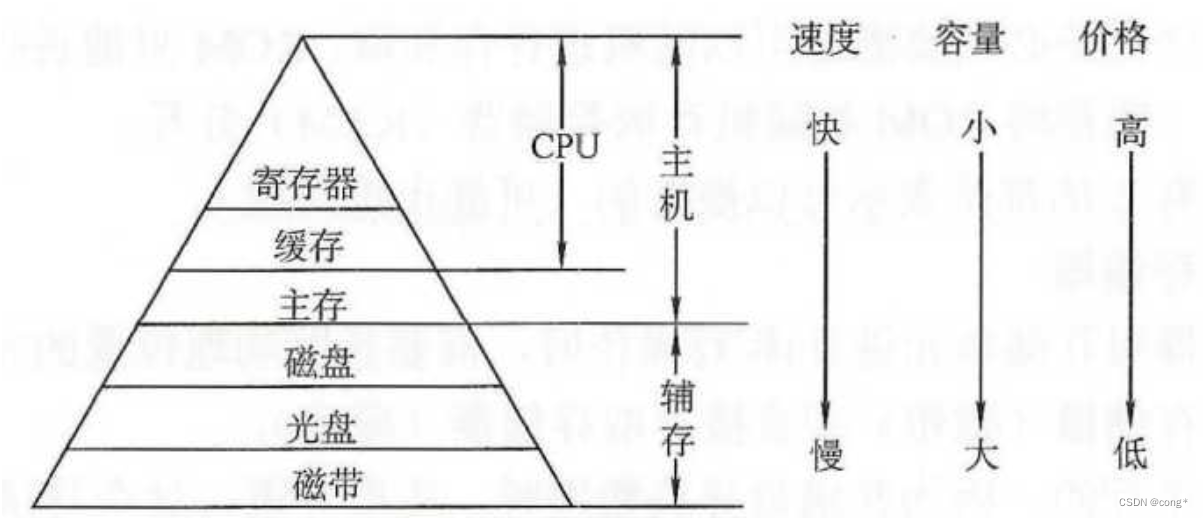
cpu,缓存,辅存,主存之间的关系及特点
关系图 示意图: ------------------- | CPU | | ------------- | | | 寄存器 | | | ------------- | | | L1缓存 | | | ------------- | | | L2缓存 | | | ------------- | | | L3缓存 | | | ------------- | ----…...

【每日刷题】Day77
【每日刷题】Day77 🥕个人主页:开敲🍉 🔥所属专栏:每日刷题🍍 🌼文章目录🌼 1. LCR 159. 库存管理 III - 力扣(LeetCode) 2. LCR 075. 数组的相对排序 - 力…...
macros模块)
chrome-base源码分析(1)macros模块
Chrome-base源码分析(2)之Macros模块 Author:Once Day Date:2024年6月29日 漫漫长路,才刚刚开始… 全系列文章请查看专栏: 源码分析_Once-Day的博客-CSDN博客 参考文档: macros - Chromium Code SearchChrome base 库详解:工…...

玩转springboot之springboot定制嵌入式的servlet
springboot定制嵌入式的servlet容器 修改容器配置 有两种方式可以修改容器的配置 可以直接在配置文件中修改和server有关的配置 server.port8081 server.tomcat.uri-encodingUTF-8//通用的Servlet容器设置 server.xxx //指定Tomcat的设置 server.tomcat.xxx编写一个EmbeddedSer…...
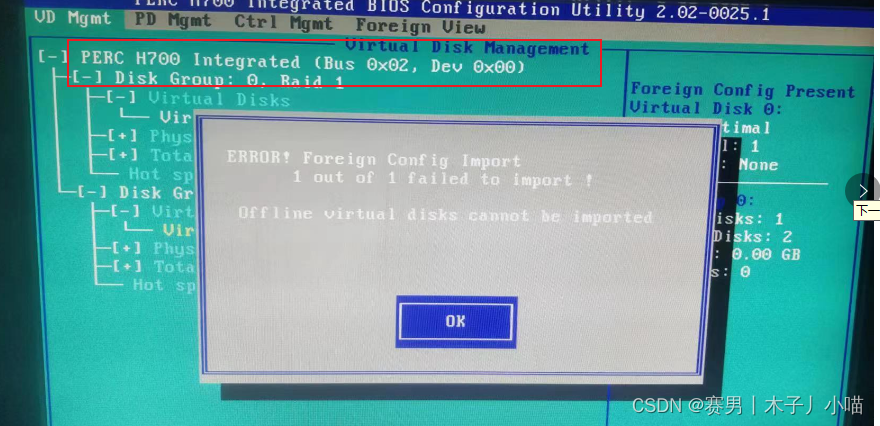
dell服务器RAID5磁盘阵列出现故障的解决过程二——热备盘制作与坏盘替换过程
目录 背景方案概念全局热备(Global Hot Spare):独立热备(Dedicated Hot Spare): 过程8号制作成热备清除配置制作独立热备热备顶替坏盘直接rebuild 更换2号盘2号热备 注意注意事项foreign状态要先清除配置 背…...
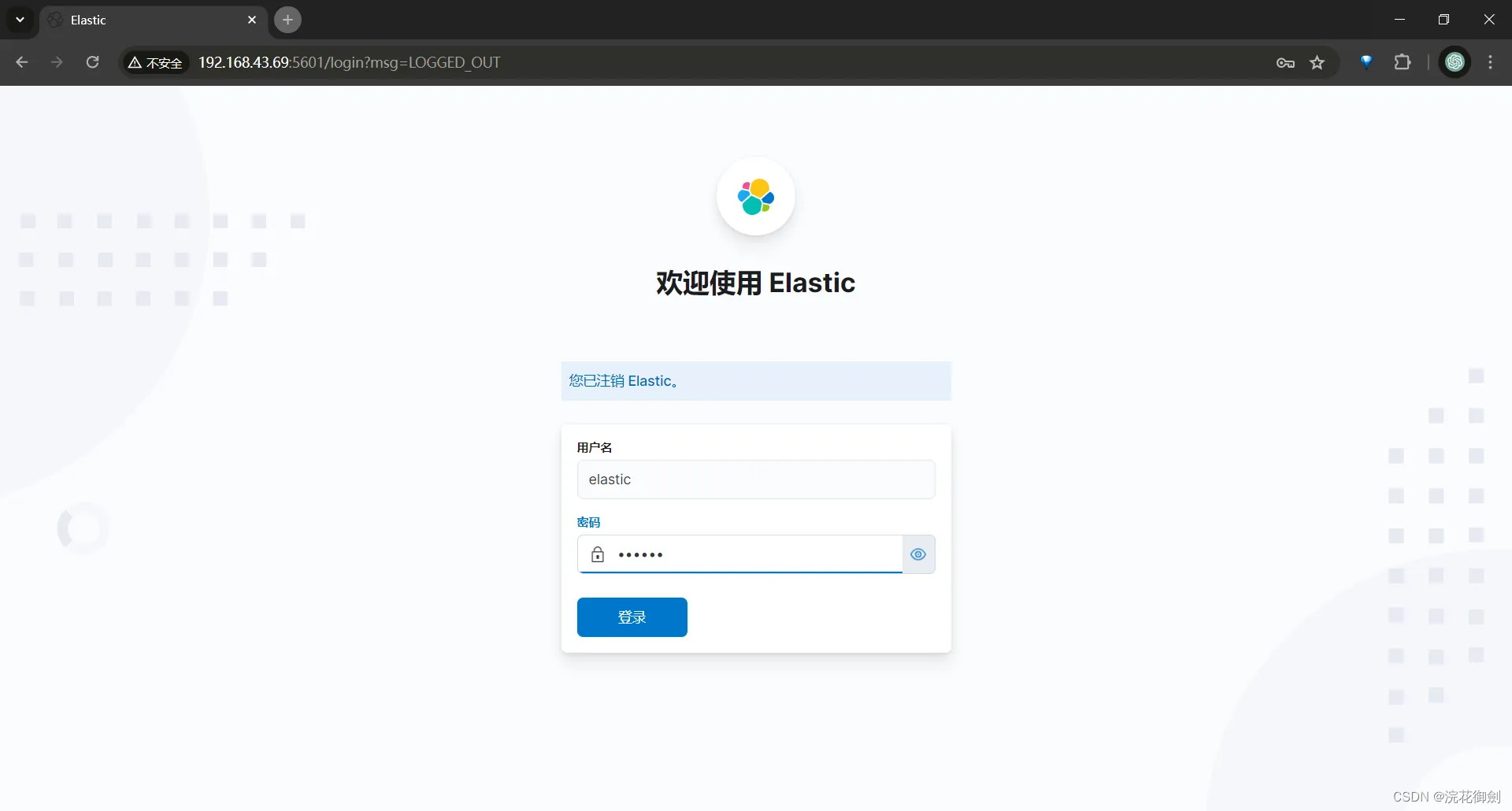
Elasticsearch开启认证|为ES设置账号密码|ES账号密码设置|ES单机开启认证|ES集群开启认证
文章目录 前言单节点模式开启认证生成节点证书修改ES配置文件为内置账号添加密码Kibana修改配置验证 ES集群开启认证验证 前言 ES安装完成并运行,默认情况下是允许任何用户访问的,这样并不安全,可以为ES开启认证,设置账号密码。 …...

Excel 数据筛选难题解决
人不走空 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌赋:斯是陋室,惟吾德馨 目录 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌…...

Web实时通信的学习之旅:WebSocket入门指南及示例演示
文章目录 WebSocket的特点1、工作原理2、特点3、WebSocket 协议介绍4、安全性 WebSocket的使用一、服务端1、创建实例:创建一个webScoket实例对象1.1、WebSocket.Server(options[,callback])方法中options对象所支持的参数1.2、同样也有一个加密的 wss:/…...

分治精炼宝库-----快速排序运用(⌯꒪꒫꒪)੭
目录 一.基本概念: 一.颜色分类: 二.排序数组: 三.数组中的第k个最大元素: 解法一:快速选择算法 解法二:简单粗暴优先级队列 四.库存管理Ⅲ: 解法一:快速选择 解法二:简单粗…...

Windows平台终极ADB驱动环境一键配置指南:告别繁琐,专注开发
Windows平台终极ADB驱动环境一键配置指南:告别繁琐,专注开发 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com…...

MacType终极指南:彻底解决Windows字体模糊问题的免费神器
MacType终极指南:彻底解决Windows字体模糊问题的免费神器 【免费下载链接】mactype Better font rendering for Windows. 项目地址: https://gitcode.com/gh_mirrors/ma/mactype 你是否厌倦了Windows系统上模糊不清的字体显示?长期面对锯齿边缘的…...

基于Telegram的AI智能体框架:从原理到实践部署指南
1. 项目概述:一个基于Telegram的AI智能体框架最近在GitHub上看到一个挺有意思的项目,叫openclaw-telegram-ai-agent。光看名字,你大概能猜到它是个什么东西:一个运行在Telegram平台上的AI智能体(Agent)。但…...

星露谷物语SMAPI模组加载器:从零开始打造你的专属农场世界
星露谷物语SMAPI模组加载器:从零开始打造你的专属农场世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 还在为星露谷物语的模组安装而烦恼吗?每次看到心仪的模组却因为复杂…...

Windows热键冲突终极排查指南:5分钟快速定位占用进程
Windows热键冲突终极排查指南:5分钟快速定位占用进程 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经…...
)
RK3588 Android12在线视频播放拷机重启?手把手教你定位DMABUF内存泄漏(附/proc节点排查法)
RK3588 Android12视频播放内存泄漏实战:从崩溃日志到精准定位DMABUF泄漏进程 当RK3588平台在Android12系统上长时间播放在线视频时突然重启,这种看似随机的系统崩溃往往让开发者头疼不已。本文将带您深入内核层,通过一套可复用的方法论&#…...
)
内网开发环境救星:保姆级教程搞定Docker与Docker Compose离线安装(附避坑清单)
内网开发环境救星:保姆级教程搞定Docker与Docker Compose离线安装(附避坑清单) 在企业级开发环境中,内网隔离是常见的安全策略,但这也给技术栈的部署带来了挑战。想象一下,当你需要在完全离线的环境中搭建一…...
)
PSIM 9.0 手把手教学:从零搭建直流电机双闭环调速模型(附完整代码与波形分析)
PSIM 9.0 手把手教学:从零搭建直流电机双闭环调速模型(附完整代码与波形分析) 在电力电子与电机控制领域,仿真技术已成为工程师和研究人员不可或缺的工具。PSIM作为一款专业的电力电子仿真软件,以其高效的仿真速度和直…...

MoviePilot连接TMDB异常的终极诊断指南:5步快速排查与完整解决方案
MoviePilot连接TMDB异常的终极诊断指南:5步快速排查与完整解决方案 【免费下载链接】MoviePilot NAS媒体库自动化管理工具 项目地址: https://gitcode.com/gh_mirrors/mo/MoviePilot MoviePilot作为NAS媒体库自动化管理工具,其核心功能依赖TheMov…...

Git合并翻车现场实录:从命令行到IDEA,详解Merge冲突前后的撤销操作差异
Git合并操作全流程避险指南:冲突诊断与精准撤销策略 当两个开发分支在版本控制系统中交汇时,合并操作就像一场精心编排的代码芭蕾。但现实往往比理想骨感——据统计,约35%的Git用户在合并过程中至少遭遇过一次需要撤销操作的场景。本文将带您…...