运维锅总详解Prometheus
本文尝试从Prometheus简介、架构、各重要组件详解、relable_configs最佳实践、性能能优化及常见高可用解决方案等方面对Prometheus进行详细阐述。希望对您有所帮助!
一、Prometheus简介
Prometheus 是一个开源的系统监控和报警工具,最初由 SoundCloud 开发,现在是 Cloud Native Computing Foundation (CNCF) 的一个项目。它特别适合用于动态和分布式环境,尤其是在云原生应用中。以下是 Prometheus 的一些关键特性和组件:
1. 多维数据模型
Prometheus 使用多维数据模型,通过指标名称和键值对(标签)来标识数据。这种模型使得用户可以灵活地对数据进行聚合和过滤,从而进行详细的分析。
2. PromQL 查询语言
Prometheus 提供了一种名为 PromQL(Prometheus Query Language)的强大查询语言,用户可以用它来进行实时的数据查询和分析。这种查询语言设计直观,功能强大,适合复杂的数据操作和聚合。
3. 时间序列数据库
Prometheus 内置了一个高效的时间序列数据库,用于存储和检索监控数据。数据以时间序列的形式存储,每个时间序列由唯一的指标名和一组标签确定。
4. 数据抓取模型
Prometheus 采用 pull 模型,通过 HTTP 协议定期从被监控的服务抓取数据。这种方式使得 Prometheus 可以很好地适应动态和分布式的环境,特别适用于微服务架构。
5. 丰富的生态系统
Prometheus 有丰富的生态系统,支持多种导出器(Exporter),可以与许多不同的服务和应用集成。例如:
- Node Exporter:用于监控 Linux 系统的基本资源指标。
- Blackbox Exporter:用于探测网络服务的可用性。
- Custom Exporter:用户可以编写自定义导出器来监控特定的应用和服务。
6. 报警功能
Prometheus 内置了报警功能,用户可以根据设定的规则生成报警。报警规则使用 PromQL 定义,并可以通过 Alertmanager 发送通知,支持多种通知方式(如电子邮件、Slack、PagerDuty 等)。
7. 服务发现
Prometheus 支持多种服务发现机制,可以自动发现和监控动态变化的服务。这对于 Kubernetes 等容器编排系统特别有用。
8. 可视化工具
Prometheus 通常与 Grafana 一起使用。Grafana 是一个开源的可视化工具,提供了强大的数据展示和仪表盘功能,用户可以创建和分享丰富的监控仪表盘。
主要应用场景
- 云原生应用:适用于 Kubernetes 等容器化环境的监控。
- 微服务架构:监控复杂的微服务应用。
- 基础设施监控:监控服务器、网络设备和其他基础设施组件。
生态系统组件
- Prometheus Server:负责抓取和存储时间序列数据。
- Alertmanager:处理报警通知。
- Pushgateway:用于短期作业的指标推送。
- Prometheus Exporters:用于导出指标数据的工具。
Prometheus 以其灵活性、高性能和广泛的社区支持,成为现代监控系统的首选之一。
二、Prometheus架构

这张图展示了 Prometheus 的整体架构及其工作流程。以下是各个组件的详细说明及其在整个工作流程中的作用:
1. Prometheus Server
- Retrieval: Prometheus 服务器从各个目标(targets)抓取监控数据。目标可以是各种服务、应用和设备,通常通过 HTTP 协议抓取指标数据。
- TSDB (Time Series Database): 抓取到的数据存储在时间序列数据库中,用于后续的查询和分析。
- HTTP Server: 提供一个 HTTP 端点,用户可以通过它查询监控数据、查看仪表盘和管理配置。
2. Service Discovery
- Prometheus 支持多种服务发现机制,如 Kubernetes、Consul、DNS 等,用于自动发现和监控动态变化的目标。
kubernetes和file_sd是两种常见的服务发现方式,分别用于从 Kubernetes 集群和文件中发现监控目标。
3. Jobs/Exporters
- Jobs: 定义了要监控的一组服务或应用,每个 job 包含多个目标(targets)。
- Exporters: 特殊的服务,用于从各种系统和服务中导出监控指标。例如,Node Exporter 用于导出主机的系统级指标。
4. Pushgateway
- 用于处理短期任务(short-lived jobs)的指标。这些任务可能在 Prometheus 抓取周期内结束,因此无法直接被 Prometheus 抓取。Pushgateway 允许这些任务在退出时将指标推送到网关,Prometheus 再从 Pushgateway 中抓取这些数据。
5. Alertmanager
- 处理由 Prometheus 服务器生成的报警(alerts),根据配置的规则将报警通知发送到不同的接收渠道,如电子邮件、Slack、PagerDuty 等。
6. Visualization and API Clients
- Prometheus Web UI: 提供了一个简单的界面,可以直接查询和查看监控数据。
- Grafana: 一个强大的开源数据可视化和监控工具,通常与 Prometheus 一起使用。Grafana 可以创建复杂的仪表盘来展示监控数据。
- API Clients: 提供各种 API,用于与其他系统和应用集成。
工作流程总结
- 数据抓取: Prometheus 服务器通过服务发现或静态配置,定期从各个目标(targets)抓取监控数据。
- 数据存储: 抓取的数据存储在时间序列数据库(TSDB)中。
- 报警生成: 根据配置的规则,Prometheus 服务器会生成报警,并将这些报警推送到 Alertmanager。
- 报警通知: Alertmanager 根据配置的通知渠道,将报警通知发送给相关人员。
- 数据查询和可视化: 用户可以通过 Prometheus Web UI 或 Grafana 查询和可视化监控数据。
通过这种架构设计,Prometheus 提供了一个灵活、高效且可扩展的监控和报警解决方案,适用于现代云原生和分布式系统的监控需求。
三、Prometheus Job
在 Prometheus 中,job 是一个逻辑组,用于定义一组目标(targets)以及如何抓取(scrape)这些目标的数据。每个 job 可以包含多个目标,这些目标通常代表一组提供相同服务的实例。配置 jobs 是 Prometheus 配置文件(通常是 prometheus.yml)的一个重要部分。下面是关于 Prometheus jobs 的详细解释和一个示例配置。
配置文件结构
Prometheus 的配置文件通常是 prometheus.yml。以下是一个基本的配置文件结构示例:
global:scrape_interval: 15s # 默认的抓取间隔时间scrape_configs:- job_name: 'example-job' # Job 名称scrape_interval: 5s # 可选,覆盖全局的抓取间隔时间static_configs:- targets: ['localhost:9090', 'localhost:8080'] # 静态目标列表- job_name: 'another-job'static_configs:- targets: ['localhost:9091']
关键配置项
-
global
scrape_interval: 设置全局的抓取间隔时间,默认为 1 分钟。
-
scrape_configs
job_name: 定义 job 的名称,每个 job 需要一个唯一的名称。scrape_interval: 可选参数,用于覆盖全局的抓取间隔时间。static_configs: 定义一组静态目标,可以直接指定要监控的目标地址。targets: 定义具体的目标列表,以主机名或 IP 地址和端口号的形式表示。
动态服务发现
除了静态配置,Prometheus 还支持多种服务发现机制,如 Kubernetes、Consul、EC2、DNS 等。以下是一个使用 Kubernetes 服务发现的示例:
scrape_configs:- job_name: 'kubernetes-apiservers'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https
Job 示例
以下是一个更复杂的示例,展示了如何配置多个 job,并使用不同的服务发现机制:
global:scrape_interval: 15sscrape_configs:- job_name: 'prometheus'scrape_interval: 10sstatic_configs:- targets: ['localhost:9090']- job_name: 'node_exporter'static_configs:- targets: ['localhost:9100']- job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_label_app]action: keepregex: myapp- job_name: 'consul'consul_sd_configs:- server: 'localhost:8500'relabel_configs:- source_labels: [__meta_consul_service]action: keepregex: my-consul-service
总结
在 Prometheus 中,job 是用于定义如何抓取监控数据的基本单位。通过配置不同的 job,可以监控不同的服务和系统,支持静态配置和动态服务发现机制,以适应不同的监控需求。
四、Prometheus exporter
在 Prometheus 中,Exporter 是一个独立的进程,用于从各种系统、服务和设备中导出监控指标。Exporter 提供一个 HTTP 端点,Prometheus 服务器通过该端点抓取(scrape)监控数据。以下是关于 Prometheus Exporter 的详细说明及一些常见的 Exporter 示例。
Exporter 的工作原理
- 数据收集: Exporter 从特定的系统或服务中收集监控数据。
- 数据暴露: Exporter 在一个 HTTP 端点上暴露收集到的数据,通常在
/metrics路径下。 - 数据抓取: Prometheus 服务器定期从 Exporter 暴露的 HTTP 端点抓取数据,并将数据存储在时间序列数据库中。
常见的 Exporter
-
Node Exporter
- 用途: 用于收集和导出 Linux 系统的硬件和操作系统级别的指标,如 CPU 使用率、内存使用率、磁盘 I/O 等。
- 端点示例:
http://<node-exporter-host>:9100/metrics
-
Blackbox Exporter
- 用途: 用于探测网络服务的可用性和性能,支持 HTTP、HTTPS、DNS、TCP 等多种协议。
- 端点示例:
http://<blackbox-exporter-host>:9115/probe?target=<target-url>
-
MySQL Exporter
- 用途: 用于收集和导出 MySQL 数据库的性能指标,如查询速率、连接数、缓存命中率等。
- 端点示例:
http://<mysql-exporter-host>:9104/metrics
-
Kafka Exporter
- 用途: 用于收集和导出 Kafka 集群的指标,如消费者延迟、分区偏移量、主题消息速率等。
- 端点示例:
http://<kafka-exporter-host>:9308/metrics
-
Cadvisor
- 用途: 用于收集和导出容器的资源使用情况指标,如 CPU、内存、网络和文件系统的使用情况。通常用于监控 Docker 容器。
- 端点示例:
http://<cadvisor-host>:8080/metrics
如何配置 Exporter
以下是一个配置 Node Exporter 的示例 prometheus.yml 配置文件:
global:scrape_interval: 15sscrape_configs:- job_name: 'node_exporter'static_configs:- targets: ['localhost:9100']
编写自定义 Exporter
如果现有的 Exporter 无法满足需求,用户可以编写自定义 Exporter。以下是一个使用 Python 编写简单 HTTP 服务的示例,暴露自定义指标:
from prometheus_client import start_http_server, Gauge
import random
import time# 创建一个指标
g = Gauge('random_number', 'A random number')if __name__ == '__main__':# 启动 HTTP 服务器,暴露指标start_http_server(8000)while True:# 设置指标值g.set(random.random())time.sleep(5)
启动这个 Python 脚本后,可以在 http://localhost:8000/metrics 端点查看暴露的随机数指标。
总结
Prometheus Exporter 是 Prometheus 生态系统的重要组成部分,用于从各种系统和服务中导出监控指标。通过使用现有的 Exporter 或编写自定义 Exporter,用户可以灵活地监控广泛的系统和应用。
自定义Prometheus exporter最佳实践
自定义 Prometheus exporter 是用于将自定义应用程序的监控数据导出到 Prometheus 监控系统的工具。要确保你的自定义 exporter 高效且易于维护,以下是一些最佳实践:
1. 设计清晰的指标
- 选择正确的指标类型:了解 Prometheus 的四种基本指标类型(Counter, Gauge, Histogram, Summary),并根据你的需求选择合适的类型。例如,计数器用于递增的值,仪表用于瞬时的值。
- 命名规范:使用有意义的命名,以便在查询时可以清楚地知道每个指标的含义。通常使用
snake_case格式,例如http_requests_total。
2. 高效的数据采集
- 避免过度采集:确保你只收集必要的数据。过多的指标会导致存储和查询负担。
- 定期更新:确保你的 exporter 定期从数据源获取最新的数据。如果数据更新频繁,考虑优化采集方式或增加缓存机制。
3. 优化性能
- 批量采集:尽量减少对数据源的访问次数。可以使用批量操作或缓存机制来减少负担。
- 异步处理:如果你的数据采集过程较慢,考虑使用异步处理来提高 exporter 的响应速度。
4. 考虑容错和稳定性
- 错误处理:添加适当的错误处理机制,以应对数据源不可用或数据不一致的情况。
- 恢复策略:确保 exporter 在出现故障后可以自动恢复并继续正常工作。
5. 提供详细的文档
- 指标说明:在 exporter 文档中提供每个指标的详细说明,包括单位、采集频率、计算方法等。
- 使用示例:提供 PromQL 查询示例,帮助用户理解如何利用你的指标进行查询和分析。
6. 遵循 Prometheus 开发指南
- 符合 Prometheus 标准:遵循 Prometheus 的 开发指南 来确保你的 exporter 与 Prometheus 兼容。
- HTTP 接口:使用 HTTP/1.1 协议和
text/plain格式进行数据暴露,符合 Prometheus 的数据采集标准。
7. 安全性
- 访问控制:如果你的 exporter 暴露在公共网络上,考虑实现访问控制措施,如基本身份验证或 IP 白名单。
- 加密传输:使用 HTTPS 保护数据传输,尤其是在生产环境中。
8. 测试和监控
- 单元测试和集成测试:编写测试用例来验证你的 exporter 的功能和稳定性。
- 运行时监控:在生产环境中监控 exporter 的健康状态,包括资源使用情况和响应时间。
9. 版本管理
- 版本控制:使用版本号来标识不同版本的 exporter。记录变更日志以便追踪更新。
- 兼容性:确保新版本与旧版本的兼容性,特别是在进行重大更改时。
通过遵循这些最佳实践,你可以创建一个高效、稳定且易于维护的自定义 Prometheus exporter。
伪代码实现一个自定义exporter
以下是一个用 Go 语言编写的 Prometheus exporter 的伪代码示例,展示如何遵循上述最佳实践。这个示例 exporter 用于监控一个假设的系统的 HTTP 请求总数和处理时间。
package mainimport ("net/http""time""github.com/prometheus/client_golang/prometheus""github.com/prometheus/client_golang/prometheus/promhttp"
)// 定义自定义指标
var (httpRequestsTotal = prometheus.NewCounterVec(prometheus.CounterOpts{Name: "http_requests_total",Help: "Total number of HTTP requests.",},[]string{"method", "status_code"},)httpRequestDuration = prometheus.NewHistogramVec(prometheus.HistogramOpts{Name: "http_request_duration_seconds",Help: "Histogram of HTTP request durations.",Buckets: prometheus.DefBuckets,},[]string{"method"},)
)func init() {// 注册指标prometheus.MustRegister(httpRequestsTotal)prometheus.MustRegister(httpRequestDuration)
}func main() {// 设置 HTTP 处理程序http.HandleFunc("/metrics", prometheusHandler)http.HandleFunc("/health", healthHandler)// 启动 HTTP 服务器http.ListenAndServe(":2112", nil)
}// prometheusHandler 处理 /metrics 请求并返回 Prometheus 指标
func prometheusHandler(w http.ResponseWriter, r *http.Request) {// 提供指标数据promhttp.Handler().ServeHTTP(w, r)
}// healthHandler 处理 /health 请求以检查 exporter 状态
func healthHandler(w http.ResponseWriter, r *http.Request) {// 返回 200 OK 状态w.WriteHeader(http.StatusOK)
}// 更新指标的模拟函数
func updateMetrics() {for {// 模拟采集数据httpRequestsTotal.WithLabelValues("GET", "200").Inc()httpRequestDuration.WithLabelValues("GET").Observe(0.2)// 模拟等待time.Sleep(10 * time.Second)}
}// 启动数据采集
func init() {go updateMetrics()
}
关键部分说明
-
定义自定义指标
httpRequestsTotal:一个计数器,用于跟踪 HTTP 请求的总数。通过标签(method,status_code)来区分不同的请求。httpRequestDuration:一个直方图,用于测量 HTTP 请求的处理时间。
-
注册指标
- 使用
prometheus.MustRegister注册自定义指标,这样 Prometheus 才能发现并抓取这些指标。
- 使用
-
设置 HTTP 处理程序
/metrics路由提供 Prometheus 指标数据。/health路由用于检查 exporter 的健康状态。
-
更新指标
- 在
updateMetrics函数中模拟数据采集。这里使用Inc和Observe更新指标的值。 - 使用
time.Sleep模拟定期更新数据的间隔。
- 在
-
启动数据采集
updateMetrics函数在一个 goroutine 中运行,以便持续更新指标。
注意事项
- 性能:实际应用中,你可能需要从真实的数据源动态获取指标,而不是使用模拟数据。
- 错误处理:在实际生产环境中,应该添加更多的错误处理机制。
- 安全性:此示例没有实现访问控制和加密传输,生产环境中应考虑这些安全性措施。
这个伪代码示例提供了一个简单的框架,你可以根据实际需求扩展和修改。
五、Prometheus Alertmanager
Prometheus Alertmanager 是 Prometheus 生态系统中的一个重要组件,用于处理和管理来自 Prometheus 的警报。它提供了警报的去重、分组、抑制以及通知等功能。下面是有关 Prometheus Alertmanager 的一些关键概念和最佳实践。
主要功能
-
去重(Deduplication):
- 目的:防止同一警报多次发送。
- 实现:Alertmanager 根据警报的标签和其他元数据去重。
-
分组(Grouping):
- 目的:将相关的警报聚合在一起,以便以批量方式发送通知。
- 实现:根据警报标签和配置的分组规则将警报分组。
-
抑制(Silencing):
- 目的:在特定条件下临时禁用某些警报。
- 实现:可以根据警报标签设置抑制规则,防止通知在特定的时间段内触发。
-
通知(Notification):
- 目的:将警报发送到不同的通知渠道(如邮件、Slack、PagerDuty等)。
- 实现:配置通知接收器并设置发送规则。
基本配置
1. Alertmanager 配置文件
Alertmanager 的配置文件通常是 alertmanager.yml,包含了警报接收和通知的规则。
global:# 全局配置,例如 SMTP 服务器地址smtp_smarthost: 'smtp.example.com:25'smtp_from: 'alertmanager@example.com'smtp_auth_username: 'alertmanager'smtp_auth_password: 'password'route:# 默认路由,指定警报的处理方式receiver: 'email'group_by: ['alertname']group_wait: 30sgroup_interval: 5mrepeat_interval: 12hroutes:- match:severity: 'critical'receiver: 'pagerduty'group_by: ['alertname', 'severity']receivers:- name: 'email'email_configs:- to: 'alerts@example.com'send_resolved: true- name: 'pagerduty'pagerduty_configs:- service_key: 'your-pagerduty-service-key'
2. 配置说明
- global:定义全局配置项,如 SMTP 设置用于发送电子邮件通知。
- route:定义警报路由规则,包括默认的接收器和分组配置。
- receivers:定义通知接收器及其配置,例如邮件、Slack、PagerDuty 等。
安装与启动
1. 下载和安装
可以从 Prometheus 的 GitHub 发行页面 下载 Alertmanager。
2. 启动
假设你已经下载并解压了 Alertmanager,可以使用以下命令启动 Alertmanager:
./alertmanager --config.file=alertmanager.yml
实践建议
-
定义明确的警报规则
- 在 Prometheus 中配置明确的警报规则,以确保你只收到重要的警报。
-
设置合理的分组和抑制
- 配置合理的分组规则和抑制策略,以减少噪声和避免不必要的通知。
-
定期检查和调整配置
- 定期查看警报和通知的效果,根据实际情况调整配置,确保系统能够有效响应警报。
-
测试通知通道
- 确保所有通知通道(如电子邮件、Slack、PagerDuty)都已正确配置,并能够接收到测试通知。
-
监控 Alertmanager 本身
- 监控 Alertmanager 的健康状况和性能,以确保它能够正常处理和发送警报。
故障排除
- 检查日志:查看 Alertmanager 的日志文件,以获取有关错误和警报处理的详细信息。
- 验证配置:使用
alertmanager --config.file=alertmanager.yml --dry-run验证配置文件是否有错误。 - 检查网络:确保 Alertmanager 可以访问配置中指定的通知服务(如 SMTP 服务器、PagerDuty)。
通过合理配置和管理 Prometheus Alertmanager,你可以有效地处理和响应警报,确保系统的健康和可靠性。
六、Prometheus Service Discovery
Prometheus 的服务发现(Service Discovery)是一个关键功能,它使 Prometheus 能够动态发现和监控不断变化的服务和实例。服务发现的目的是自动化地检测和配置监控目标,而不需要手动干预。
主要概念
-
服务发现(Service Discovery):
- 定义:服务发现是指 Prometheus 自动发现和更新其监控目标的过程。
- 目的:使 Prometheus 能够监控那些 IP 地址或端口可能随时变化的动态服务,如 Kubernetes Pods、云服务等。
-
目标(Targets):
- 定义:被 Prometheus 监控的实体。每个目标由其地址、端口和一些标签(如服务名、环境等)标识。
- 获取方式:目标可以通过静态配置、服务发现机制或其它方式获取。
服务发现机制
Prometheus 支持多种服务发现机制,包括:
-
静态配置:
-
定义:在 Prometheus 配置文件中手动指定监控目标。
-
配置示例:
scrape_configs:- job_name: 'static_targets'static_configs:- targets: ['localhost:9090', 'localhost:9091']
-
-
Kubernetes:
-
定义:通过 Kubernetes API 发现集群中的 Pods 和 Services。
-
配置示例:
scrape_configs:- job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_label_app]target_label: app
-
-
Consul:
-
定义:通过 Consul 服务注册表发现服务。
-
配置示例:
scrape_configs:- job_name: 'consul'consul_sd_configs:- server: 'localhost:8500'services: ['my_service']
-
-
DNS:
-
定义:通过 DNS 查询发现目标。
-
配置示例:
scrape_configs:- job_name: 'dns'dns_sd_configs:- names:- 'my-service.example.com'type: 'A'rtype: 'A'
-
-
EC2:
-
定义:通过 AWS EC2 实例元数据发现目标。
-
配置示例:
scrape_configs:- job_name: 'ec2'ec2_sd_configs:- region: 'us-east-1'access_key: 'YOUR_ACCESS_KEY'secret_key: 'YOUR_SECRET_KEY'
-
-
Azure:
-
定义:通过 Azure 发现目标。
-
配置示例:
scrape_configs:- job_name: 'azure'azure_sd_configs:- subscription_id: 'your-subscription-id'tenant_id: 'your-tenant-id'client_id: 'your-client-id'client_secret: 'your-client-secret'
-
配置示例
以下是一个包含多种服务发现机制的 Prometheus 配置文件示例:
global:scrape_interval: 15sscrape_configs:- job_name: 'static_targets'static_configs:- targets: ['localhost:9090', 'localhost:9091']- job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_label_app]target_label: app- job_name: 'consul'consul_sd_configs:- server: 'localhost:8500'services: ['my_service']- job_name: 'dns'dns_sd_configs:- names:- 'my-service.example.com'type: 'A'rtype: 'A'- job_name: 'ec2'ec2_sd_configs:- region: 'us-east-1'- job_name: 'azure'azure_sd_configs:- subscription_id: 'your-subscription-id'tenant_id: 'your-tenant-id'client_id: 'your-client-id'client_secret: 'your-client-secret'
最佳实践
-
优化标签:
- 使用标签来区分不同的目标或服务。例如,使用
job标签来标识不同的服务类型或环境。
- 使用标签来区分不同的目标或服务。例如,使用
-
使用 relabel_configs:
- 使用
relabel_configs来处理服务发现返回的数据,将其转换为 Prometheus 需要的格式。
- 使用
-
动态更新:
- 确保 Prometheus 配置文件支持动态更新,以便自动发现和监控新添加的目标。
-
安全性:
- 对服务发现配置进行适当的安全设置,特别是在涉及云服务或内部服务时。
-
性能:
- 定期检查服务发现的性能和稳定性,确保不会导致 Prometheus 服务器的性能问题。
通过合理配置服务发现,Prometheus 可以自动化地监控动态环境中的目标,从而提高系统的可靠性和灵活性。
七、Prometheus relabel_configs 最佳实践
在 Prometheus 中,relabel_configs 是一个强大的工具,用于对监控目标的标签进行处理和修改。有效地使用 relabel_configs 可以帮助你优化监控数据,增强查询能力,并确保监控系统的高效运作。以下是一些 relabel_configs 的最佳实践和配置示例。
1. 优化标签
- 去除不必要的标签:移除那些不需要的标签,避免标签的数量过多。过多的标签会影响 Prometheus 的性能,并使数据的查询和存储变得复杂。
示例:
relabel_configs:- source_labels: [__meta_kubernetes_pod_label_unwanted_label]action: drop
- 统一标签格式:将标签格式统一化,确保标签一致性,以便于查询和聚合。
示例:
relabel_configs:- source_labels: [__meta_kubernetes_pod_label_app]target_label: app
2. 增强查询能力
- 添加有用的标签:添加能够增强查询能力的标签,例如服务环境、地区等。
示例:
relabel_configs:- source_labels: [__meta_kubernetes_namespace]target_label: namespace
- 使用标签重命名:重命名标签以便于理解和使用。
示例:
relabel_configs:- source_labels: [__meta_kubernetes_pod_label_app]target_label: application
3. 处理标签的值
- 修改标签值:使用
replacement替换标签的值。
示例:
relabel_configs:- source_labels: [__meta_kubernetes_pod_label_version]target_label: versionreplacement: 'v1.0'
- 使用正则表达式:利用正则表达式处理标签值的提取和替换。
示例:
relabel_configs:- source_labels: [__meta_kubernetes_pod_label_version]target_label: versionregex: 'v(.*)'replacement: '${1}'
4. 过滤和选择目标
- 过滤目标:只选择符合特定条件的目标,避免监控不相关的目标。
示例:
relabel_configs:- source_labels: [__meta_kubernetes_pod_label_environment]action: keepregex: 'production'
- 删除无效目标:删除那些不符合条件的目标,减少不必要的监控数据。
示例:
relabel_configs:- source_labels: [__meta_kubernetes_pod_label_status]action: dropregex: 'inactive'
5. 确保性能
- 避免复杂的
relabel_configs:尽量避免复杂的relabel_configs,以防止性能问题。
示例:
relabel_configs:- source_labels: [__meta_kubernetes_pod_label_role]target_label: roleaction: replace
- 使用合适的
action:选择最适合的action类型以高效处理标签。
常见 action 类型:
replace:替换标签值。drop:删除目标。keep:只保留匹配的目标。hashmod:进行 hashmod 运算,用于分片等。
6. 使用多阶段 relabeling
- 分阶段处理:分阶段处理标签,以便于复杂的标签管理需求。
示例:
relabel_configs:# 第一阶段:添加标签- source_labels: [__meta_kubernetes_pod_label_app]target_label: app# 第二阶段:修改标签值- source_labels: [__meta_kubernetes_pod_label_version]target_label: versionregex: 'v(.*)'replacement: '${1}'# 第三阶段:过滤目标- source_labels: [__meta_kubernetes_pod_label_environment]action: keepregex: 'production'
7. 测试和验证配置
-
测试配置:在应用到生产环境之前,在测试环境中验证
relabel_configs配置。 -
使用
prometheus --config.file=prometheus.yml --dry-run:检查配置文件的语法和逻辑错误。
配置示例
以下是一个综合示例,展示了如何使用 relabel_configs 来优化监控目标标签:
scrape_configs:- job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_namespace]target_label: namespace- source_labels: [__meta_kubernetes_pod_label_app]target_label: application- source_labels: [__meta_kubernetes_pod_label_version]target_label: versionregex: 'v(.*)'replacement: '${1}'- source_labels: [__meta_kubernetes_pod_label_environment]action: keepregex: 'production'- source_labels: [__address__]target_label: instance
总结
- 简化和优化:保持
relabel_configs的简洁,避免复杂的配置。 - 增强标签管理:合理使用标签,增强监控数据的查询和管理。
- 性能和测试:关注性能,定期测试和验证配置。
通过遵循这些最佳实践,你可以有效地利用 relabel_configs 优化 Prometheus 的监控数据,使查询和管理更加高效。
八、Prometheus性能优化
为了具体说明如何优化 Prometheus 的性能,我们可以通过几个实际的示例来展示不同的优化策略,包括配置优化、查询优化、存储优化、硬件优化等方面。
示例 1: 配置优化
背景
假设你有一个 Prometheus 实例,当前的抓取间隔设置为 15 秒。你注意到 Prometheus 的存储和处理负载很高,查询性能也受到影响。
优化策略
- 调整抓取间隔:将抓取间隔从 15 秒增加到 30 秒,以减少每秒抓取的样本数量。
配置更改:
global:scrape_interval: 30s # 从 15s 增加到 30sscrape_timeout: 10s
- 增加存储保留时间:如果数据存储需求较低,可以减少存储保留时间,减少存储负担。
配置更改:
storage.tsdb.retention.time: 7d # 从默认的 15d 减少到 7d
示例 2: 查询优化
背景
你有一个复杂的 PromQL 查询,例如查询过去 1 小时的所有 HTTP 请求总量。查询执行时间较长,影响了 Prometheus 的性能。
优化策略
- 优化查询语法:将
rate()函数的时间窗口缩短,减少计算量。
原始查询:
sum(rate(http_requests_total[1h])) by (job)
优化后的查询:
sum(rate(http_requests_total[5m])) by (job) # 缩短时间窗口到 5 分钟
- 使用
subquery:使用子查询来减少计算量,尤其是在图形和数据点数量较多时。
优化后的查询:
sum(rate(http_requests_total[5m:1m])) by (job) # 使用子查询来计算每分钟的平均值
示例 3: 存储优化
背景
你的 Prometheus 存储设备是机械硬盘(HDD),并且你注意到存储性能成为瓶颈。
优化策略
- 使用 SSD:将存储设备更换为固态硬盘(SSD),以提高读写性能。
实施方案:
-
将现有的 HDD 磁盘替换为 SSD。
-
确保 Prometheus 的数据目录位于 SSD 上。
- 调整存储块的大小:调整存储块的最大和最小持续时间,以优化数据块的存储和访问。
配置更改:
storage.tsdb.max-block-duration: 2h # 将最大块持续时间设置为 2 小时
storage.tsdb.min-block-duration: 2h # 将最小块持续时间设置为 2 小时
示例 4: 硬件优化
背景
你的 Prometheus 实例运行在一台具有 4 核 CPU 和 16GB 内存的服务器上,但在高负载下经常出现性能瓶颈。
优化策略
- 增加内存:将内存从 16GB 增加到 32GB,以提高数据缓存和处理能力。
实施方案:
-
购买和安装更多的内存条。
-
确保 Prometheus 能够使用增加的内存。
- 使用多核 CPU:升级服务器,使用具有更多 CPU 核心的实例,以提高处理能力。
实施方案:
- 升级到具有更多核心的 CPU。
- 确保 Prometheus 配置能够利用多核 CPU 的优势。
示例 5: 监控和维护
背景
你发现 Prometheus 的性能逐渐下降,怀疑是由于长期运行和数据积累导致的。
优化策略
- 监控 Prometheus 自身:使用 Prometheus 自带的
/metrics端点监控自身性能指标。
配置:
scrape_configs:- job_name: 'prometheus-self-monitoring'static_configs:- targets: ['localhost:9090']
- 设置警报:配置警报规则,以便在性能问题出现时能够及时响应。
配置:
groups:- name: prometheusrules:- alert: HighQueryDurationexpr: rate(prometheus_engine_query_duration_seconds_sum[5m]) > 0.5for: 5mlabels:severity: criticalannotations:summary: "Prometheus query duration is high"
总结
- 配置优化:调整抓取间隔和存储保留时间,以减少负载和存储压力。
- 查询优化:简化和优化 PromQL 查询,减少计算量。
- 存储优化:使用 SSD 替代 HDD,调整数据块大小。
- 硬件优化:增加内存和 CPU 资源以提升性能。
- 监控和维护:监控 Prometheus 的自身性能并设置警报以快速响应问题。
通过这些具体的优化措施,你可以显著提升 Prometheus 的性能和稳定性,更好地满足监控需求。
九、Prometheus常见高可用解决方案
在 Prometheus 中实现高可用性(HA)对于确保监控系统的可靠性和稳定性至关重要。以下是几种常见的高可用解决方案和实现方法:
1. Prometheus 集群
Prometheus 本身不支持内建的集群模式,但可以通过多实例部署和其他工具实现高可用性。
1.1. 多 Prometheus 实例
- 方案:部署多个 Prometheus 实例来增加系统的冗余。
- 实现:
- 配置:每个 Prometheus 实例独立抓取目标,相同的抓取配置和存储配置。
- 优点:提高系统的容错能力。
- 缺点:数据需要去重处理;不同实例的查询可能会略有不同。
配置示例:
scrape_configs:- job_name: 'example'static_configs:- targets: ['localhost:9090']
1.2. 使用 Thanos
- 方案:使用 Thanos 作为 Prometheus 的查询层和长时间存储层,提供高可用性和水平扩展。
- 优点:支持查询层的高可用和跨 Prometheus 实例的统一查询。
- 实现:
- 部署 Thanos Sidecar、Thanos Store、Thanos Query 等组件。
- Thanos Sidecar:与每个 Prometheus 实例配合,负责数据的上传和查询请求的转发。
- Thanos Store:提供长时间存储和全局查询功能。
- Thanos Query:支持从多个 Prometheus 实例和 Thanos Store 中进行联合查询。
配置示例:
# Thanos Sidecar 配置
--tsdb.path=/prometheus
--http-address=0.0.0.0:10902
--grpc-address=0.0.0.0:10901
--objstore.config-file=/etc/thanos/bucket.yml# Thanos Query 配置
--http-address=0.0.0.0:9090
--grpc-address=0.0.0.0:9091
--query.lookback-delta=2m
--store=thanos-store1:10901
--store=thanos-store2:10901
2. Prometheus 数据冗余和备份
2.1. 使用 Prometheus Federation
- 方案:配置一个 Prometheus 实例作为“主”实例,其他实例作为“从”实例,通过联邦配置进行数据汇总。
- 优点:支持将数据从多个 Prometheus 实例集中到一个主实例中,以便于全局查询和数据备份。
- 实现:
- 主实例:配置抓取其他 Prometheus 实例的数据。
- 从实例:配置正常的抓取目标。
配置示例:
scrape_configs:- job_name: 'federation'scrape_interval: 5mstatic_configs:- targets: ['prometheus1:9090', 'prometheus2:9090']
2.2. 数据备份
- 方案:定期备份 Prometheus 数据存储,确保在数据丢失的情况下能够恢复。
- 工具:
- 使用
prometheus tsdb工具或其他备份工具定期备份 TSDB 数据。
- 使用
- 实施:
- 定期创建备份快照。
- 确保备份存储的安全性和可靠性。
备份命令示例:
prometheus tsdb snapshot /path/to/backup
3. 负载均衡和高可用性
3.1. 使用负载均衡器
- 方案:在前端使用负载均衡器分发查询请求到多个 Prometheus 实例。
- 优点:提升查询请求的负载均衡,确保高可用性。
- 实现:
- 配置负载均衡器(如 NGINX、HAProxy)来分发请求。
- 确保负载均衡器能够处理健康检查和故障转移。
负载均衡配置示例(NGINX):
upstream prometheus {server prometheus1:9090;server prometheus2:9090;
}server {listen 80;location / {proxy_pass http://prometheus;proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header X-Forwarded-Proto $scheme;}
}
3.2. DNS 轮询
- 方案:通过 DNS 轮询实现 Prometheus 实例的负载均衡。
- 优点:简单易用,但缺乏健康检查机制。
- 实现:
- 配置 DNS 记录,轮询不同的 Prometheus 实例。
- 确保 DNS TTL 值设置得当,以减少故障切换的延迟。
DNS 配置示例:
prometheus.example.com. IN A 192.168.1.1
prometheus.example.com. IN A 192.168.1.2
4. 高可用 Alertmanager
4.1. 使用 Alertmanager 集群
- 方案:部署多个 Alertmanager 实例,通过配置文件实现集群模式,确保告警的高可用性。
- 优点:提高告警处理的可靠性和冗余。
- 实现:
- 配置 Alertmanager 集群并在每个实例中配置集群通信。
- 确保告警配置和通知通道的一致性。
Alertmanager 集群配置示例:
# alertmanager.yml
alertmanager:- static_configs:- targets: ['alertmanager1:9093', 'alertmanager2:9093']
总结
- Prometheus 实例:通过部署多个 Prometheus 实例或使用 Thanos 提供的查询层和长时间存储层来实现高可用性。
- 数据冗余和备份:使用 Prometheus Federation 实现数据冗余,通过定期备份保证数据的安全性。
- 负载均衡:使用负载均衡器或 DNS 轮询来分发查询请求,提升系统的高可用性。
- Alertmanager 集群:通过配置 Alertmanager 集群来确保告警系统的可靠性和冗余。
通过以上这些高可用解决方案,你可以有效地提升 Prometheus 的可靠性,确保监控系统在故障或负载高峰时的稳定性。
完。
十、一个秘密
希望对您有所帮助!关注锅总,及时获得更多花里胡哨的运维实用操作!

锅总个人博客
https://gentlewok.blog.csdn.net/
锅总微信公众号

相关文章:
运维锅总详解Prometheus
本文尝试从Prometheus简介、架构、各重要组件详解、relable_configs最佳实践、性能能优化及常见高可用解决方案等方面对Prometheus进行详细阐述。希望对您有所帮助! 一、Prometheus简介 Prometheus 是一个开源的系统监控和报警工具,最初由 SoundCloud …...
)
深入解析Tomcat:Java Web服务器(上)
深入解析Tomcat:Java Web服务器(上) Apache Tomcat是一个开源的Java Web服务器和Servlet容器,用于运行Java Servlets和JavaServer Pages (JSP)。Tomcat在Java Web应用开发中扮演着重要角色。本文将详细介绍Tomcat的基本概念、安装…...

【第9章】MyBatis-Plus持久层接口之SimpleQuery
文章目录 前言一、使用步骤1.引入 SimpleQuery 工具类2.使用 SimpleQuery 进行查询 二、使用提示三、功能详解1. keyMap1.1 方法签名1.2 参数说明1.3 使用示例1.4 使用提示 2. map2.1 方法签名2.2 参数说明2.3 使用示例2.4 使用提示 3. group3.1 方法签名3.2 参数说明3.3 使用示…...
一文带你了解乐观锁和悲观锁的本质区别!
文章目录 悲观锁是什么?乐观锁是什么?如何实现乐观锁?什么是CAS应用局限性ABA问题是什么? 悲观锁是什么? 悲观锁它总是假设最坏的情况,它会认为共享资源在每次被访问的时候就会出现线程安全问题࿰…...
Android Studio环境搭建(4.03)和报错解决记录
1.本地SDK包导入 安装好IDE以及下好SDK包后,先不要管IDE的引导配置,直接新建一个新工程,进到开发界面。 SDK路径配置:File---->>Other Settings---->>Default Project Structure 拷贝你SDK解压的路径来这,…...

基于协同过滤的电影推荐与大数据分析的可视化系统
基于协同过滤的电影推荐与大数据分析的可视化系统 在大数据时代,数据分析和可视化是从大量数据中提取有价值信息的关键步骤。本文将介绍如何使用Python进行数据爬取,Hive进行数据分析,ECharts进行数据可视化,以及基于协同过滤算法…...
修复vcruntime140.dll方法分享
修复vcruntime140.dll方法分享 最近在破解typora的时候出现了缺失vcruntime140.dll文件的报错导致软件启动失败。所以找了一番资料发现都不是很方便的处理,甚至有的dll处理工具还需要花钱????,我本来就是为…...

PostgreSQL的系统视图pg_stat_wal_receiver
PostgreSQL的系统视图pg_stat_wal_receiver 在 PostgreSQL 中,pg_stat_wal_receiver 视图提供了关于 WAL(Write-Ahead Logging)接收进程的统计信息。WAL 接收器是 PostgreSQL 集群中流复制的一部分,它在从节点中工作,…...
Qt之Pdb生成及Dump崩溃文件生成与调试(含注释和源码)
文章目录 一、Pdb生成及Dump文件使用示例图1.Pdb文件生成2.Dump文件调试3.参数不全Pdb生成的Dump文件调试 二、个人理解1.生成Pdb文件的方式2.Dump文件不生产的情况 三、源码Pro文件mian.cppMainWindowUi文件 总结 一、Pdb生成及Dump文件使用示例图 1.Pdb文件生成 下图先通过…...

视频号视频怎么保存到手机,视频号视频怎么保存到手机相册里,苹果手机电脑都可以用
随着数字媒体的蓬勃发展,视频已成为我们日常生活中不可或缺的一部分。视频号作为众多视频分享平台中的一员,吸引了大量用户上传和分享各类精彩视频。然而,有时我们可能希望将视频号上的视频下载下来,以下将详细介绍如何将视频号的视频。 方法…...
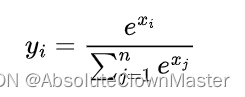
Softmax函数的作用
Softmax 函数主要用于多类别分类问题,它将输入的数值转换为概率分布。 具体来说,对于给定的输入向量 x [x_1, x_2,..., x_n] ,Softmax 函数的输出为 y [y_1, y_2,..., y_n] ,其中: 这样,Softmax 函数的输…...

cesium 添加 Echarts 图层(空气质量点图)
cesium 添加 Echarts 图层(下面附有源码) 1、实现思路 1、在scene上面新增一个canvas画布 2、通坐标转换,将经纬度坐标转为屏幕坐标来实现 3、将ecarts 中每个series数组中元素都加 coordinateSystem: ‘cesiumEcharts’ 2、示例代码 <!DOCTYPE html> <html lan…...

Python技术笔记汇总(含语法、工具库、数科、爬虫等)
对Python学习方法及入门、语法、数据处理、数据可视化、空间地理信息、爬虫、自动化办公和数据科学的相关内容可以归纳如下: 一、Python学习方法 分解自己的学习目标:可以将学习目标分基础知识,进阶知识,高级应用,实…...

Nacos-注册中心
一、注册中心的交互流程 注册中心通常有两个角色: 服务提供者(生产者):对外提供服务的微服务应用。它会把自身的服务地址注册到注册中心,以供消费者发现和调用。服务调用者(消费者):调用其他微服务的应用程序。它会向注册中心订阅自己需要的服…...
Unity制作一个简单抽卡系统(简单好抄)
业务流程:点击抽卡——>播放动画——>显示抽卡面板——>将随机结果添加到面板中——>关闭面板 1.准备素材并导入Unity中(包含2个抽卡动画,抽卡结果的图片,一个背景图片,一个你的展示图片) 2.给…...
简单多状态DP问题
这里写目录标题 什么是多状态DP解决多状态DP问题应该怎么做?关于多状态DP问题的几道题1.按摩师2.打家劫舍Ⅱ3.删除并获得点数4.粉刷房子5.买卖股票的最佳时期含手冷冻期 总结 什么是多状态DP 多状态动态规划(Multi-State Dynamic Programming, Multi-St…...
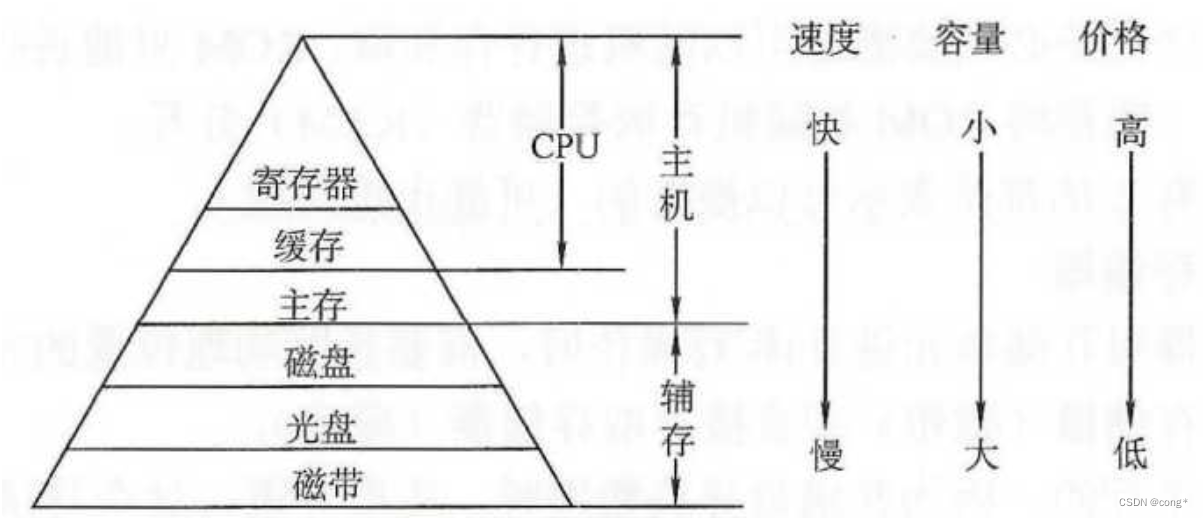
cpu,缓存,辅存,主存之间的关系及特点
关系图 示意图: ------------------- | CPU | | ------------- | | | 寄存器 | | | ------------- | | | L1缓存 | | | ------------- | | | L2缓存 | | | ------------- | | | L3缓存 | | | ------------- | ----…...

【每日刷题】Day77
【每日刷题】Day77 🥕个人主页:开敲🍉 🔥所属专栏:每日刷题🍍 🌼文章目录🌼 1. LCR 159. 库存管理 III - 力扣(LeetCode) 2. LCR 075. 数组的相对排序 - 力…...
macros模块)
chrome-base源码分析(1)macros模块
Chrome-base源码分析(2)之Macros模块 Author:Once Day Date:2024年6月29日 漫漫长路,才刚刚开始… 全系列文章请查看专栏: 源码分析_Once-Day的博客-CSDN博客 参考文档: macros - Chromium Code SearchChrome base 库详解:工…...

玩转springboot之springboot定制嵌入式的servlet
springboot定制嵌入式的servlet容器 修改容器配置 有两种方式可以修改容器的配置 可以直接在配置文件中修改和server有关的配置 server.port8081 server.tomcat.uri-encodingUTF-8//通用的Servlet容器设置 server.xxx //指定Tomcat的设置 server.tomcat.xxx编写一个EmbeddedSer…...

别再死记硬背了!用‘配对’思想图解二次剩余,5分钟理解勒让德符号
用配对游戏破解二次剩余:勒让德符号的视觉化理解指南 数论中那些看似晦涩的概念,往往只需要换个角度就能豁然开朗。想象你手里有一副特殊的扑克牌,每张牌代表一个数字,而你要玩的游戏是找到那些能完美配对的数字——这就是理解二次…...

TikTokDownload完整指南:轻松下载无水印抖音内容
TikTokDownload完整指南:轻松下载无水印抖音内容 【免费下载链接】TikTokDownload 抖音去水印批量下载用户主页作品、喜欢、收藏、图文、音频 项目地址: https://gitcode.com/gh_mirrors/ti/TikTokDownload 抖音内容创作者和爱好者们,你们是否曾经…...
)
别再踩坑了!emWin6.x窗口管理器定时器WM_CreateTimer的正确打开方式(附RTOS/裸机源码)
深度解析emWin6.x窗口管理器定时器的实战避坑指南 在嵌入式GUI开发中,emWin的窗口管理器定时器功能是构建动态交互界面的核心工具之一。许多开发者在初次接触WM_CreateTimer时,往往会被看似简单的API背后隐藏的细节所困扰——为什么定时器没有触发&#…...

双源判别器提升城市场景语义分割精度
篇名问题,背景方法其他基于双源判别器的域自适应城市场景语义分割(2023)1.跨域数据集外观分布不同导致域差异,导致对抗训练不稳定,分割精度不够理想。2.网络对小目标分割精度不理想双源判别器(判别器输入包含 2 个不同域 的特征信…...

终极魔兽争霸3兼容性修复指南:WarcraftHelper让你的经典游戏重获新生
终极魔兽争霸3兼容性修复指南:WarcraftHelper让你的经典游戏重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸III…...

突破海外镜像访问瓶颈:public-image-mirror 容器镜像加速实战指南
突破海外镜像访问瓶颈:public-image-mirror 容器镜像加速实战指南 【免费下载链接】public-image-mirror 很多镜像都在国外。比如 gcr 。国内下载很慢,需要加速。致力于提供连接全世界的稳定可靠安全的容器镜像服务。 项目地址: https://gitcode.com/G…...

赣州 GEO 科普|AI 时代品牌信息基建,七文 GEO 助力品牌长效可见
赣州GEO科普|AI时代品牌信息基建,读懂生成式引擎优化逻辑人工智能全面普及的当下,生成式AI正在重塑大众的信息获取方式。如今多数用户习惯借助文心一言等AI工具检索品牌、查询行业服务,人工智能会整合全网信息进行智能作答。在此行…...
)
485温湿度传感器Modbus通信避坑指南:从波特率匹配到报文解析(以4800波特率为例)
485温湿度传感器Modbus通信实战:从硬件对接到数据解析全流程 工业现场的数据采集往往从一串看似简单的十六进制代码开始。当您第一次将485温湿度传感器接入系统时,可能会遇到这样的场景:硬件连接无误,指示灯正常闪烁,但…...

数据与大语言模型融合:从NL2SQL到RAG架构的实践指南
1. 项目概述:当数据遇见大语言模型如果你是一名数据工程师、数据分析师,或者任何需要和数据打交道的开发者,最近肯定被“大语言模型”和“数据智能”这两个词轮番轰炸。我们手里有海量的数据,从结构化的业务表到非结构化的日志、文…...

英雄联盟智能BP与战绩查询:你的排位赛终极助手
英雄联盟智能BP与战绩查询:你的排位赛终极助手 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否曾经在排位赛BP阶段手忙脚乱,不知道该禁用哪个英雄?或者想了解队友和对…...