Kafka~高吞吐量设计
Kafka 之所以能够实现高性能和高速度,主要归因于以下几个关键因素:
- 分布式架构:Kafka 采用分布式架构,可以水平扩展,通过增加服务器节点来处理更多的流量和数据存储。
- 顺序写入磁盘:Kafka 将消息顺序地写入磁盘,这种顺序写入相比随机写入磁盘的性能要高得多。磁盘顺序读写的速度接近于内存的读写速度。
- 分区机制(稀疏索引):数据被分割到多个分区,不同分区可以并行处理,从而提高了并发处理能力,并按照数据量级间隔建立索引。
- 批量处理:Kafka 会对消息进行批量处理,而不是逐个处理消息,减少了网络开销和磁盘 I/O 次数。
- 零拷贝技术:在数据传输过程中,使用零拷贝技术避免了不必要的数据复制,提高了数据传输效率。
- 内存映射:通过内存映射文件(Memory Mapped Files),将磁盘文件映射到内存,加快了数据的访问速度。
- 高效的存储格式:Kafka 采用紧凑的二进制存储格式,减少了存储空间的占用,并且有利于数据的快速读取和处理。
- 预读和后写优化:利用磁盘的预读和后写特性,提前读取后续可能需要的数据,以及延迟写入以合并更多的操作。
我挑几个比较重要的讲一讲。
发送批量处理
- 批量发送:Kafka通过将多个消息打包成一个批次,减少了网络传输和磁盘写入的次数,从而提高了消息的吞吐量和传输效率。详细可以看我之前的文档-消息写入过程
- 异步发送:生产者可以异步发送消息,不必等待每个消息的确认,这大大提高了消息发送的效率。
- 消息压缩:支持对消息进行压缩,减少网络传输的数据量。
- 并行发送:通过将数据分布在不同的分区(Partitions)中,生产者可以并行发送消息,从而提高了吞吐量。
数据高效存储
- 零拷贝技术:Kafka使用零拷贝技术来避免了数据的拷贝操作,降低了内存和CPU的使用率,提高了系统的性能。
如果不考虑用户态的内存拷贝和物理设备到驱动的数据拷贝,一次数据读取IO会涉及4次数据拷贝。同时也会涉及到4次进程上下文的切换。所谓的零拷贝,作用就是通过各种方式,在特殊情况下,减少数据拷贝的次数/减少CPU参与数据拷贝的次数。
常见的零拷贝方式有mmap、sendfile、dma、directl/O等。
- 磁盘顺序写入:Kafka把消息存储在磁盘上,且以顺序的方式写入数据。顺序写入比随机写入速度快很多,因为它减少了磁头寻道时间。避免了随机读写带来的性能损耗,提高了了磁盘的使用效率。
- 页缓存:Kafka将其数据存储在磁盘中,但在访问数据时,它会先将数据加载到操作系统的页缓存中,并在页缓存中保留一份副本,因为MQ大多是顺序读操作,从而实现快速的数据访问。
- 稀疏索引:Kafka存储消息是通过分段的日志文件,每个个分段都有自己的索引文件。这些索引文件中的条目不是对分段中的每条消息都建立索引,而是每隔一定数量的消息建立一个索引点,这就构成了稀疏索引。稀疏索引减少了索引大小,使得加载到内存中的索引更小,提高了查找特定消息的效率。
- 分区和副本:Kafka采用分区和副本的机制,可以将数据分散到1多个节点上进行处理,从而实现了分布式的高可用性和负载均衡。
并行消费
- 并行消费:不同的消费者可以独立地消费不同的分区,实现消费的并行处理。
- 批量拉取:Kafka支持批量拉取消息,可以一次性拉取多个消息进行消费。减少网络消耗,提升性能。
相关文章:

Kafka~高吞吐量设计
Kafka 之所以能够实现高性能和高速度,主要归因于以下几个关键因素: 分布式架构:Kafka 采用分布式架构,可以水平扩展,通过增加服务器节点来处理更多的流量和数据存储。顺序写入磁盘:Kafka 将消息顺序地写入…...

STM32小项目———感应垃圾桶
文章目录 前言一、超声波测距1.超声波简介2.超声波测距原理2.超声波测距步骤 二、舵机的控制三、硬件搭建及功能展示总结 前言 一个学习STM32的小白~ 有问题请评论区或私信指出 提示:以下是本篇文章正文内容,下面案例可供参考 一、超声波测距 1.超声波…...

嵌入式MCU平台汇总
文章目录 1. 单片机(MCU) 2. 数字信号处理器(DSP) 3. ARM Cortex 系列 4. 超低功耗MCU 5. 物联网MCU(IoT MCU) 6. 开源架构MCU(RISC-V) 7. 可编程逻辑器件(FPGA&a…...
C#udpClient组播
一、0udpClient 控件: button(打开,关闭,发送),textbox,richTextBox 打开UDP: UdpClient udp: namespace _01udpClient {public partial class Form1 : Form{public Form1(){Initi…...
《昇思25天学习打卡营第14天 | 昇思MindSpore基于MindNLP+MusicGen生成自己的个性化音乐》
14天 本节学了基于MindNLPMusicGen生成自己的个性化音乐。 MusicGen是来自Meta AI的Jade Copet等人提出的基于单个语言模型的音乐生成模型,能够根据文本描述或音频提示生成高质量的音乐样本。 MusicGen模型基于Transformer结构,可以分解为三个不同的阶段…...

新奥集团校招面试经验分享、测评笔试题型分析
一、走进新奥集团 新奥集团成立于1989年,总部位于河北廊坊,是中国领先的清洁能源企业集团。业务涵盖城市燃气、能源化工、环保科技等多个领域,致力于构建现代能源体系,提升生活品质。 二、新奥集团校招面试经验分享 新奥集团的…...

【推荐】Prometheus+Grafana企业级监控预警实战
新鲜出炉!!!PrometheusGrafanaAlertmanager springboot 企业级监控预警实战课程,从0到1快速搭建企业监控预警平台,实现接口调用量统计,接口请求耗时统计…… 详情请戳 https://edu.csdn.net/course/detai…...

深度剖析:前端如何驾驭海量数据,实现流畅渲染的多种途径
文章目录 一、分批渲染1、setTimeout定时器分批渲染2、使用requestAnimationFrame()改进渲染2.1、什么是requestAnimationFrame2.2、为什么使用requestAnimationFrame而不是setTimeout或setInterval2.3、requestAnimationFrame的优势和适用场景 二、滚动触底加载数据三、Elemen…...

AI时代,你的工作会被AI替代吗?
AI在不同领域的应用和发展速度是不同的。在智商方面,尤其是在逻辑推理、数据分析和模式识别等领域,AI已经取得了显著的进展。例如,在国际象棋、围棋等策略游戏中,AI已经能够击败顶尖的人类选手。在科学研究、医学诊断、股市分析等…...

Java_日志
日志技术 可以将系统执行的信息,方便的记录到指定的位置(控制台、文件中、数据库中) 可以随时以开关的形式控制日志启停,无需侵入到源代码中去进行修改。 日志技术的体系结构 日志框架:JUL、Log4j、Logback、其他实现。 日志接口…...
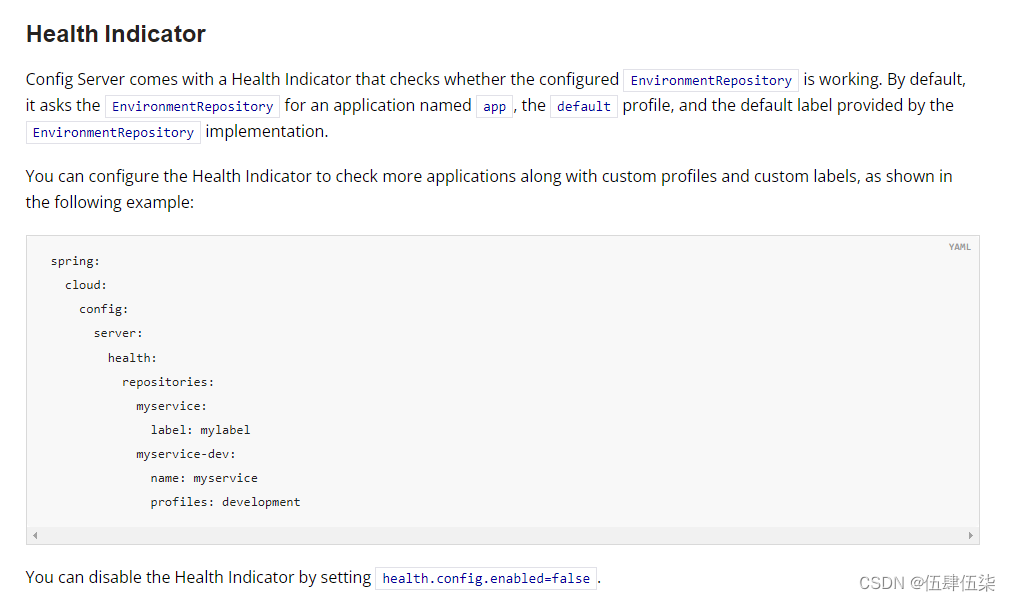
springcould-config git源情况下报错app仓库找不到
在使用spring config server服务的时候发现在启动之后的一段时间内控制台会抛出异常,spring admin监控爆红,控制台信息如下 --2024-06-26 20:38:59.615 - WARN 2944 --- [oundedElastic-7] o.s.c.c.s.e.JGitEnvironmentRepository : Error occured …...

MySQL serverTimezone=UTC
在数据库连接字符串中使用 serverTimezoneUTC 是一个常见的配置选项,特别是当数据库服务器和应用程序服务器位于不同的时区时。这个选项指定了数据库服务器应当使用的时区,以确保日期和时间数据在客户端和服务器之间正确传输和处理。 UTC(协…...
基于YOLOv9的PCB板缺陷检测
数据集 PCB缺陷检测,我们直接采用北京大学智能机器人开放实验室数据提供的数据集, 共六类缺陷 漏孔、鼠咬、开路、短路、杂散、杂铜 已经对数据进行了数据增强处理,同时按照YOLO格式配置好,数据内容如下 模型训练 采用YOLO…...

高考结束,踏上西北的美食之旅
高考的帷幕落下,暑期的阳光洒来,是时候放下书本,背上行囊,踏上一场充满期待的西北之旅。而在甘肃这片广袤的土地上,除了壮丽的自然风光,还有众多令人垂涎欲滴的美食等待着您的品尝。当您踏入甘肃࿰…...

人工智能 (AI) 在能源系统中应用的机会和风险
现代文明极度依赖于电力的获取。电力系统支撑着我们视为理所当然的几乎所有基本生活功能。没有电力的获取,大多数经济活动将是不可能的。然而,现有的电网系统并未设计来应对当前——更不用说未来的——电力需求。与此同时,气候变化迫切要求我…...

[AIGC] 定时删除日志文件
文章目录 需求实现脚本解释 需求 实现一个定时任务,定时删除两天前的日志文件,如果某个目录使用量超过80%,则删除文件 实现 要实现这样的要求,我们可以创建一个shell脚本,在该脚本中使用find命令查找两天前的日志文…...

C++:typeid4种cast转换
typeid typeid typeid是C标准库中提供的一种运算符,它用于获取类型的信息。它主要用于类型检查和动态类型识别。当你对一个变量或对象使用typeid运算符时,它会返回一个指向std::type_info类型的指针,这个信息包含了关于该类型名称、大小、基…...

vue3的配置和使用
vue的使用需要配置node且node版本需要在15以上。管理员方式打开cmd,输入node -v,可以查看node版本。 创建vue有以下两种方式 npm init vuelatestnpm create vuelatest创建后输入项目名,其它的输入否即可,新手可以先不用 按照要求…...
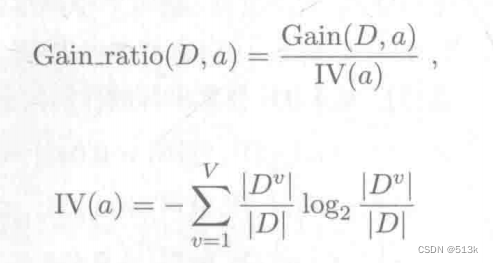
决策树划分属性依据
划分依据 基尼系数基尼系数的应用信息熵信息增益信息增益的使用信息增益准则的局限性 最近在学习项目的时候经常用到随机森林,所以对决策树进行探索学习。 基尼系数 基尼系数用来判断不确定性或不纯度,数值范围在0~0.5之间,数值越低&#x…...
短视频利器 ffmpeg (2)
ffmpeg 官网这样写到 Converting video and audio has never been so easy. 如何轻松简单的使用: 1、下载 官网:http://www.ffmpeg.org 安装参考文档: https://blog.csdn.net/qq_36765018/article/details/139067654 2、安装 # 启用RPM …...

【实战避坑】从清华源手动下载到权限修复:一站式解决d2l安装疑难杂症
1. 为什么你的d2l安装总是失败?从下载到权限的全流程避坑指南 每次看到"动手学深度学习"课程里那些酷炫的案例,你是不是也迫不及待想动手试试?但现实往往很骨感——光是安装d2l这个入门包就能卡住80%的新手。我见过太多人在第一步就…...

小白程序员看过来!TS同学半年逆袭AI大模型产品经理,收藏这份转行避坑指南!
TS同学从景观设计转行AI大模型产品经理的经历分享。他经历了离职、脱产学习、国企子公司项目被裁等波折,最终以20%薪资涨幅加入AI公司。文章重点介绍了他的心态调整、求职策略变化以及对“稳定”的新理解,同时探讨了AI时代教育孩子的思考。 本期嘉宾TS同…...

金蝶云星空日常使用功能
1、必录和锁定和隐藏 2、取多少位字符 FMaterialId <> null AND ( FMaterialId.FNumber[0:3] in (321) or FMaterialId.FNumber[0:1] in (P)) 3、设定指定值...

多智能体协作框架Agentset:从原理到实战构建AI团队
1. 项目概述:当AI智能体开始“组队打怪”最近在AI应用开发圈里,一个词的热度持续攀升:智能体(Agent)。如果说大语言模型(LLM)是学会了“思考”的大脑,那么智能体就是具备了“感知-决…...

AI 的能源账单:训练一次模型够一个城市用一年、$440 亿投资涌入、核能成为新基建 — 算力背后的环境代价
Stanford HAI 2026 年 AI Index 报告用一组数字泼了盆冷水:AI 模型正在取得突破性的科学和推理成果,但环境代价高到令人不安。报告披露:一个前沿大模型的单次训练,能耗相当于一个小型城市一天的全部用电量。而 2024-2026 年间&…...

法律科技实践:基于Python与NLP的法律文书自动化处理工具集
1. 项目概述:一个法律从业者的效率工具箱如果你是一名律师、法务或者法律专业的学生,每天面对海量的法律文书、案例检索和合同审查,你一定会对“效率”这个词有切肤之痛。我从事法律相关工作超过十年,从最初的实习律师到后来独立处…...

ARM ETMv4跟踪寄存器架构与调试实践
1. ARM ETMv4 跟踪寄存器架构概述ARM嵌入式跟踪宏单元(ETM)是处理器调试架构中的关键组件,ETMv4作为其第四代架构,提供了更强大的指令和数据跟踪能力。与传统的断点调试不同,ETM采用实时跟踪技术,能够在不中断处理器运行的情况下&…...

Godot集成CEF:用Web技术构建高性能跨平台桌面应用
1. 项目概述:一个被低估的桌面应用开发利器 如果你正在寻找一个能让你用熟悉的Web技术(HTML、CSS、JavaScript)来构建高性能、跨平台桌面应用的工具,并且对Electron的臃肿和资源占用感到头疼,那么你很可能已经听说过C…...

Wonder3D完整教程:如何用单张图片快速生成3D模型
Wonder3D完整教程:如何用单张图片快速生成3D模型 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 想要将一张普通的图片变成立体的3D模型吗࿱…...

LIKWID标记API深度解析:精确测量代码性能
LIKWID标记API深度解析:精确测量代码性能 【免费下载链接】likwid Performance monitoring and benchmarking suite 项目地址: https://gitcode.com/gh_mirrors/li/likwid LIKWID是一款功能强大的性能监控和基准测试套件,其标记API(Ma…...