MySQL 索引之外的相关查询优化总结
在这之前先说明几个概念:
1、驱动表和被驱动表:驱动表是主表,被驱动表是从表、非驱动表。驱动表和被驱动表并非根据 from 后面表名的先后顺序而确定,而是根据 explain 语句查询得到的顺序确定;展示在前面的是驱动表,后面的是非驱动表。
2、关联查询的类型非为:内连接(inner join)、左外连接(left join)、右外连接(right join)、全外连接(full join);
一、关联查询优化
1、整体效率比较:INLJ>BNLJ>SNLJ(这些值在EXPLAIN语句中Extra字段展示)
2、永远用小结果集驱动大结果集(其本质就是减少外层循环的数据数量)(小的度量单位指的是 表行数"每行大小
#推荐
select t1.b,t2.* from t1 Istraight_join t2 on(t1.b=t2.b)where t2.id<=188;
#不推荐
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=108;
3、为被驱动表匹配的条件增加索引(减少内层表的循环匹配次数)
4、增大join buffer size的大小(一次缓存的数据越多,那么内层包的扫表次数就越少).
5、减少驱动表不必要的字段査询(字段越少,join buffer 所缓存的数据就越多);
实践得到以下结论:
结论1:对于内连接来说,查询优化器可以决定谁来作为驱动表,谁作为被驱动表出现
结论2:对于内连接来讲,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表
结论3:对于内连接来说,在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表。小表驱动大表
关联查询优化细节可参考视频教程上部和下部
二、子查询优化和排序优化(相关视频教程)
1、子查询是 MySQL 的一项重要的功能,可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作 ,能够帮助我们通过一个 SQL 语句实现比较复杂的查询。但是子查询的执行效率不高。原因如下:
(1) 执行子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。这样会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
(2) 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。
(3) 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
在MySQL中,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表,其速度比子查询要快,如果查询中使用索引的话,性能就会更好。
2、在查询时不仅要在 WHERE 条件字段上加索引,还要在在 ORDER BY 字段上添加索引,因为在 MySQL 中,支持两种排序方式,分别是 FileSort 和 Index 排序。
◆ Index 排序中,索引可以保证数据的有序性,不需要再进行排序,效率更高。
◆ Filesort 排序则一般在内存中进行排序,占用 CPU 较多。如果待排结果较大,会产生临时文件 IO 到磁盘进行排序的情况,效率较低。
优化建议如下(这块的内容很详细,具体实践一定要看教程):
(1) SQL 中,可以在 WHERE 子句和 ORDER BY 子句中使用索引,目的是在 WHERE 子句中 避免全表扫描,在 ORDER BY 子句避免使用 FileSort 排序。当然,某些情况下全表扫描,或者 FileSort 排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。
(2) 尽量使用 Index 完成 ORDER BY 排序。如果 WHERE 和 ORDER BY 后面是相同的列就使用单索引列;如果不同就使用联合索引。
(3) 无法使用 Index 时,需要对 FileSort 方式进行调优。
三、GROUP BY优化和分页查询优化(相关视频教程)
1、group by 的优化策略主要包含以下六点
(1) group by 使用索引的原则几乎跟order by一致 ,group by 即使没有过滤条件用到索引,也可以直接使用索引。
(2) group by 先排序再分组,遵照索引建的最佳左前缀法则
(3) 当无法使用索引列,可以增大max_length_for_sort_data和sort_buffer_size参数的设置
(4) where效率高于having,能写在where限定的条件就不要写在having中了
(5) 减少使用 order by,和业务沟通能不排序就不排序,或将排序放到程序端去做。Order by、group by、distinct 这些语句较为耗费 CPU,数据库的CPU资源是极其宝贵的。
(6) 包含了order by、group by、distinct 这些查询的语句,where 条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。
2、一般分页查询时,通过创建覆盖索引能够比较好地提高性能。一个常见又非常头疼的问题就是 limit 2000000,10此时需要MySQL排序前2000010 记录,仅仅返回2000000-2000010 的记录,其他记录丢弃,查询排序的代价非常大。
EXPLAIN SELECT *FROM student LIMIT 2000000,10;
优化思路一
在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容。
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10) a WHERE t.id = a.id;
优化思路二
该方案适用于主键自增的表,可以把 Limit 查询转换成某个位置的查询。
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;
四、覆盖索引的使用(相关视频教程)
1、什么是覆盖索引?
理解方式一:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了满足查询结果的数据就叫做覆盖索引。
理解方式二:非聚簇复合索引的一种形式,它包括在查询里的SELECT、JOIN和WHERE子句用到的所有列(即建索引的字段正好是覆盖查询条件中所涉及的字段)。
简单说就是,索引列+主键包含SELECT 到 FROM之间查询的列。
2、索引覆盖的好处
(1) 避免Innodb表进行索引的二次查询(回表)
Innodb是以聚集索引的顺序来存储的,对于Innodb来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据,在查找到相应的键值后,还需通过主键进行二次查询才能获取我们真实所需要的数据。在覆盖索引中,二级索引的键值中可以获取所要的数据,避免了对主键的二次査询 ,减少了IO操作,提升了查询效率。
(2) 可以把随机 IO 变成顺序 IO 加快查询效率
由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围査找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序IO 。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
3、索引覆盖的缺点
索引字段的维护总是有代价的。因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑了。这是业务 DBA,或者称为业务数据架构师的工作。
五、索引条件下推(ICP)(相关视频教程)
select * from a where key > 'z' and key like '%a'
以上查询语句在使用和不适用 ICP 两种场景如下
1、在不使用 ICP 索引扫描的过程:
storage层:只将满足index key条件的索引(key>‘z’)记录对应的整行记录取出,返回给server层,回表
server 层:对返回的数据,使用后面的where条件(key like ‘%a’)过滤,直至返回最后一行。
2、使用 ICP 扫描的过程:
storage层:首先将index key条件满足的索引(key>‘z’)记录区间确定,然后在索引上使用index filter进行(key like ‘%a’)过滤。将满足的index filter条件的索引记录才去回表取出整行记录返回server层。不满足index filter条件的索引记录丢弃,不回表、也不会返回server层。
server 层:对返回的数据,使用table filter条件做最后的过滤。
3、ICP 的开启/关闭
·默认情况下启用索引条件下推。可以通过设置系统变量 optimizer_switch 控制:index_condition_pushdown
#打开索引下推
SET optimizer switch='index condition pushdown=off':
#关闭索引下推
SET optimizer_switch='index_condition_pushdown=on';
4、ICP的使用条件
(1) 如果表访问的类型为 range、ref、eq_ref和ref_or_null 可以使用ICP
(2) ICP可以用于 InnoDB 和MyISAM 表,包括分区表 InnoDB和 MyISAM 表
(3) 对于 InnoDB 表,ICP 仅用于`二级索引’。ICP 的目标是减少全行读取次数,从而减少 /0 操作。
(4) 当SQL使用覆盖索引时,不支持ICP。为这种情况下使用ICP 不会减少 IO。
(5) 相关子查询的条件不能使用ICP
六、其他查询优化策略(相关视频教程)
1、EXISTS 和 IN 的区分
索引是个前提,其实选择与否还会要看表的大小。你可以将选择的标准理解为小表驱动大表。在这种方式下效率是最高的。
2、COUNT(*)、COUNT(1)与COUNT(具体字段)效率
前提:如果你要统计的是某个字段的非空数据行数,则另当别论,毕竟比较执行效率的前提是结果一样才可以。
环节1:COUNT(星)和COUNT(1)都是对所有结果进行COUNT,COUNT(星)和COUNT(1)本质上并没有区别(二者执行时间可能略有差别,不过你还是可以把它俩的执行效率看成是相等的)。如果有WHERE子句,则是对所有符合筛选条件的数据行进行统计;如果没有WHERE子句,则是对数据表的数据行数进行统计。
环节2:如果是MyISAM存储引擎,统计数据表的行数只需要O(1)的复杂度,这是因为每张MyISAM的数据表都有一个meta信息存储了row_count值,而一致性则是由表级锁来保证的。
如果是InnoDB存储引擎,因为InnoDB支持事务,采用行级锁和MVCC机制,所以无法像MyISAM一样,维护一个row_count变量,因此需要采用扫描全表,是O(n)的复杂度,进行循环+计数的方式来完成统计。
环节3:在InnoDB引擎中,如果采用COUNT(具体字段)来统计数据行数,要尽量采用二级索引。因为主键采用的索引是聚簇索引,聚簇索引包含的信息多,明显会大于二级索引(非聚簇索引)。对于COUNT(*)和COUNT(1)来说,它们不需要查找具体的行,只是统计行数,系统会自动采用占用空间更小的二级索引来进行统计。
如果有多个二级索引,会使用key_len小的二级索引进行扫描。当没有二级索引的时候,才会采用主键索引来进行统计。
3、关于SELECT(星)
在表查询中,建议明确字段,不要使用 * 作为查询的字段列表,推荐使用SELECT <字段列表> 查询。原因:
(1) MySQL 在解析的过程中,会通过查询数据字典将"*"按序转换成所有列名,这会大大的耗费资源和时间。
(2) 无法使用覆盖索引
4、LIMIT 1 对优化的影响
针对的是会扫描全表的 SQL 语句,如果你可以确定结果集只有一条,那么加上LIMIT 1的时候,当找到一条结果的时候就不会继续扫描了,这样会加快查询速度。
如果数据表已经对字段建立了唯一索引,那么可以通过索引进行查询,不会全表扫描的话,就不需要加上LIMIT 1了。
5、多使用 COMMIT
只要有可能,在程序中尽量多使用 COMMIT,这样程序的性能得到提高,需求也会因为 COMMIT 所释放的资源而减少。
COMMIT 所释放的资源:
(1) 回滚段上用于恢复数据的信息
(2) 被程序语句获得的锁
(3) redo / undo log buffer 中的空间
(4) 管理上述 3 种资源中的内部花费
相关文章:

MySQL 索引之外的相关查询优化总结
在这之前先说明几个概念: 1、驱动表和被驱动表:驱动表是主表,被驱动表是从表、非驱动表。驱动表和被驱动表并非根据 from 后面表名的先后顺序而确定,而是根据 explain 语句查询得到的顺序确定;展示在前面的是驱动表&am…...

EE trade:贵金属投资的优点及缺点
贵金属(如黄金、白银、铂金和钯金)一直以来都是重要的投资和避险工具。它们具有独特的物理和化学特性,广泛应用于各种行业,同时也被视为财富储备。在进行贵金属投资时,了解其优点和缺点对于做出明智的投资决策至关重要。 一、贵金属投资的优…...

python工作目录与文件目录
工作目录 文件目录:文件所在的目录 工作目录:执行python命令所在的目录 D:. | main.py | ---data | data.txt | ---model | | model.py | | train.py | | __init__.py | | | ---nlp | | | bert.py | …...

可信和可解释的大语言模型推理-RoG
大型语言模型(LLM)在复杂任务中表现出令人印象深刻的推理能力。然而,LLM在推理过程中缺乏最新的知识和经验,这可能导致不正确的推理过程,降低他们的表现和可信度。知识图谱(Knowledge graphs, KGs)以结构化的形式存储了…...

秋招季的策略与行动指南:提前布局,高效备战,精准出击
6月即将进入尾声,一年一度的秋季招聘季正在热火进行中。对于即将毕业的学生和寻求职业发展的职场人士来说,秋招是一个不容错过的黄金时期。 秋招的序幕通常在6月至9月间拉开,名企们纷纷开启网申的大门。在此期间,求职备战是一个系…...

Java并发编程-wait与notify详解及案例实战
文章目录 概述wait()notify()作用注意事项用wait与notify手写一个内存队列wait与notify的底层原理:monitor以及wait_setMonitor(监视器)Wait Set(等待集合)Wait() 原理Notify() / NotifyAll() 原理注意事项wait与notify在代码中使用时的注意事项总结案例实战:基于wait与not…...
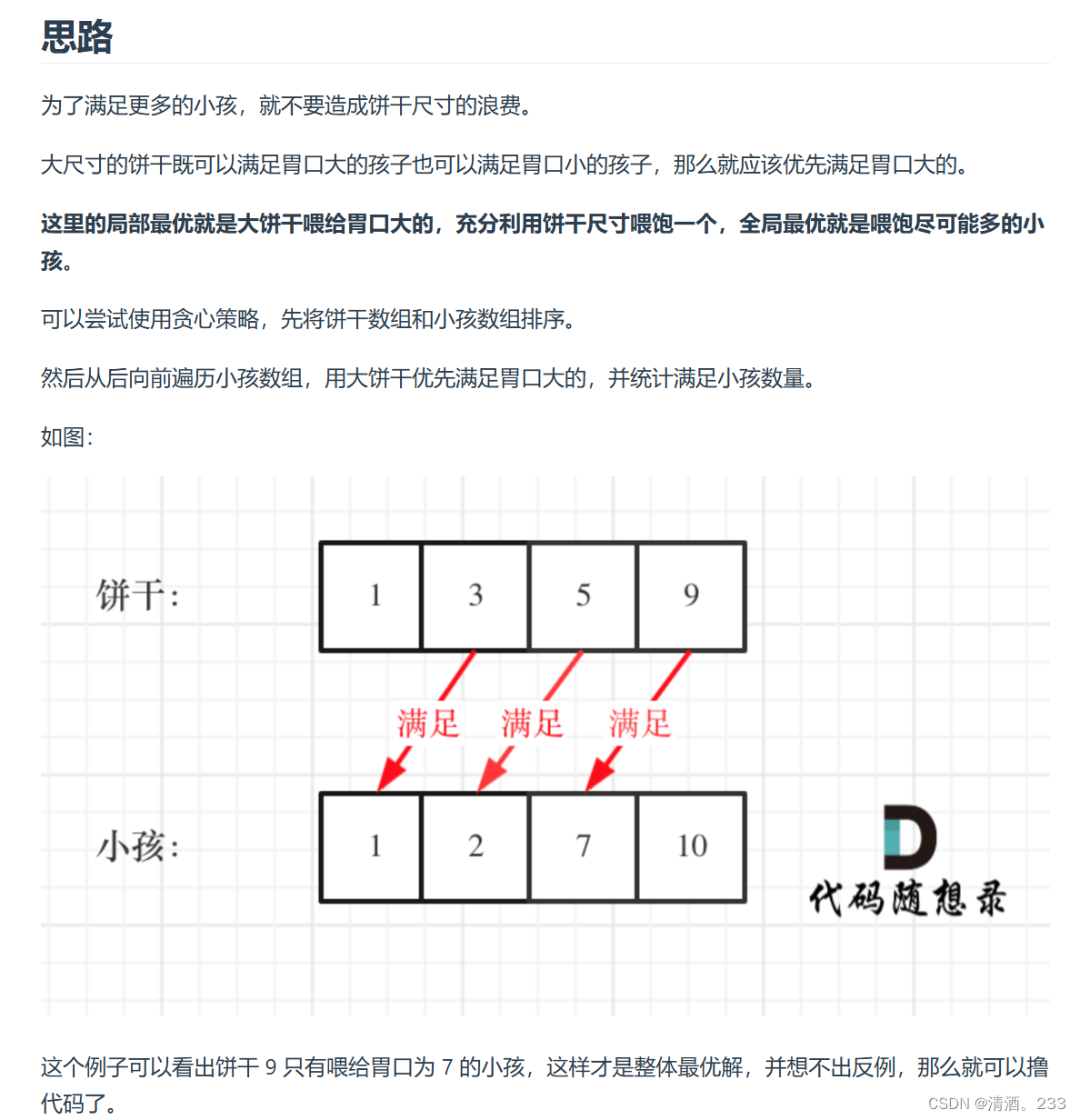
204.贪心算法:分发饼干(力扣)
以下来源于代码随想录 class Solution { public:int findContentChildren(vector<int>& g, vector<int>& s) {// 对孩子的胃口进行排序sort(g.begin(), g.end());// 对饼干的尺寸进行排序sort(s.begin(), s.end());int index s.size() - 1; // 从最大的饼…...
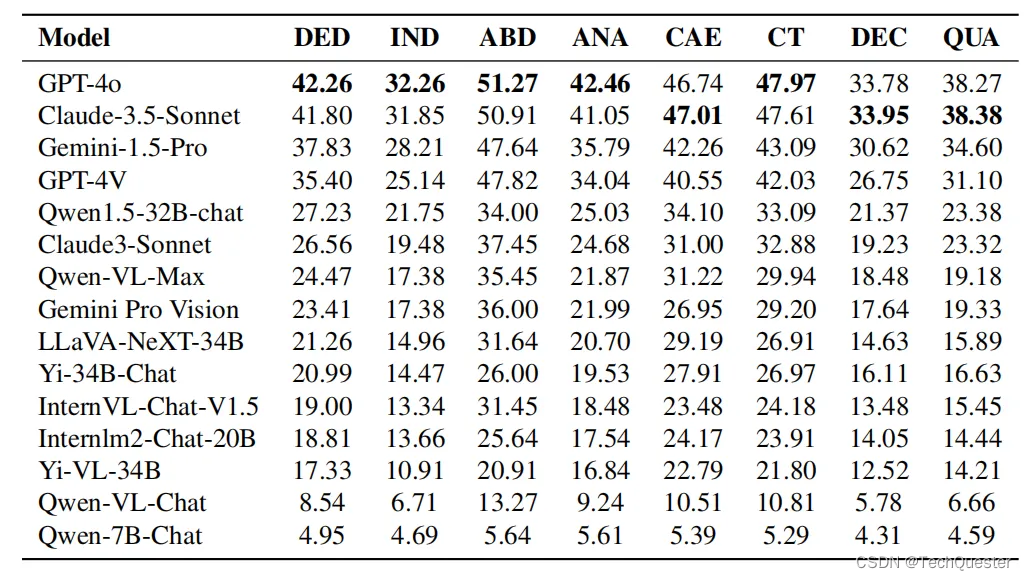
AI奥林匹克竞赛:Claude-3.5-Sonnet对决GPT-4o,谁是最聪明的AI?
目录 实验设置 评估对象 评估方法 结果与分析 针对学科的细粒度分析 GPT-4o vs. Claude-3.5-Sonnet GPT-4V vs. Gemini-1.5-Pro 结论 AI技术日新月异,Anthropic公司最新发布的Claude-3.5-Sonnet因在知识型推理、数学推理、编程任务及视觉推理等任务上设立新…...

【C++】const修饰成员函数
const修饰成员函数 常函数: 成员函数后加const后我们称为这个函数为常函数 常函数内不可以修改成员属性 成员属性声明时加关键字mutable后,在常函数中依然可以修改 class Animal { public:void fun1(){//这是一个普通的成员函数 }void fun2…...
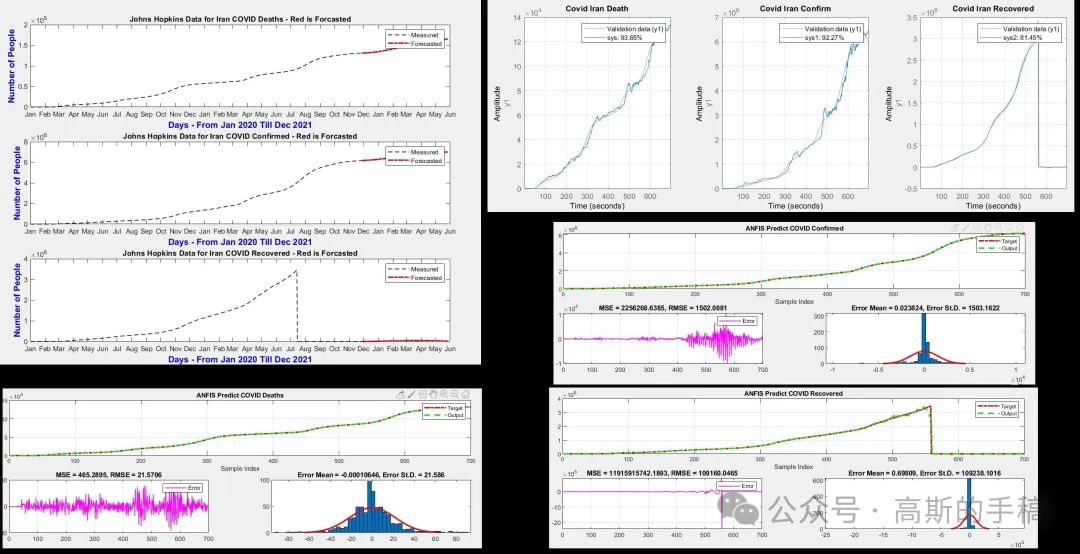
基于模糊神经网络的时间序列预测(以hopkinsirandeath数据集为例,MATLAB)
模糊神经网络从提出发展到今天,主要有三种形式:算术神经网络、逻辑模糊神经网络和混合模糊神经网络。算术神经网络是最基本的,它主要是对输入量进行模糊化,且网络结构中的权重也是模糊权重;逻辑模糊神经网络的主要特点是模糊权值可…...
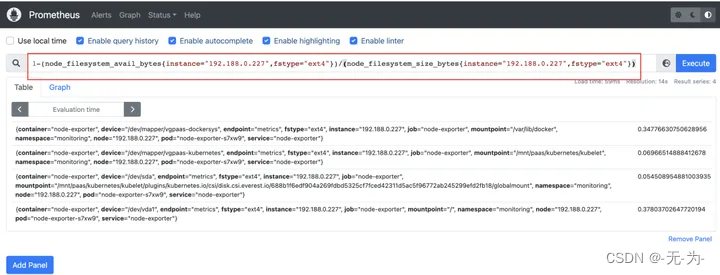
Java web应用性能分析之【prometheus监控K8s指标说明】
常规k8s的监控指标 单独 1、集群维度 集群状态集群节点数节点状态(正常、不可达、未知)节点的资源使用率(CPU、内存、IO等) 2、应用维度 应用响应时间 应用的错误率 应用的请求量 3、系统和集群组件维度 API服务器状态控…...

Spring Boot中的应用配置文件管理
Spring Boot中的应用配置文件管理 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨Spring Boot中的应用配置文件管理。在现代的软件开发中&am…...
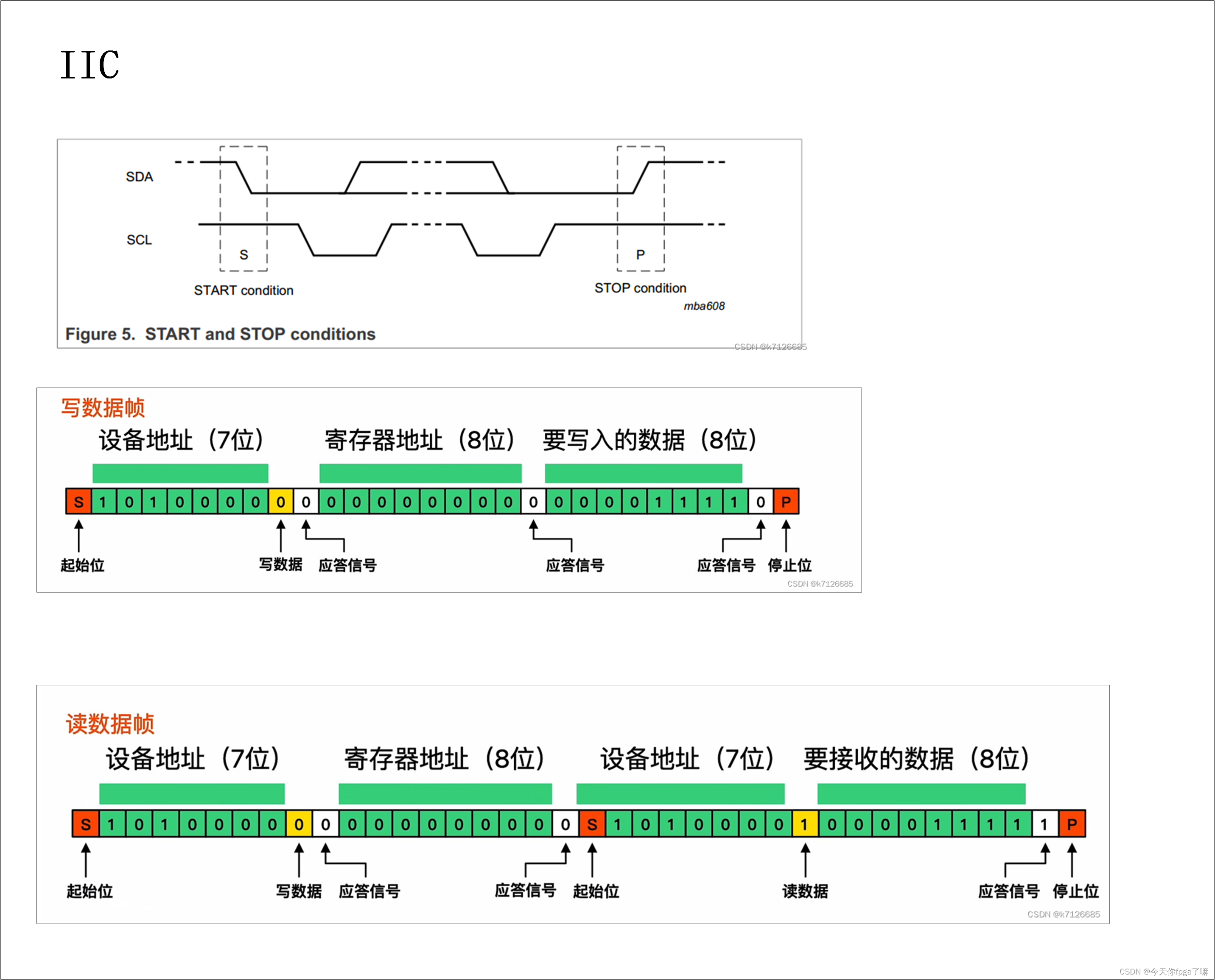
SCCB协议介绍,以及与IIC协议对比
在之前的文章里已经介绍了IIC协议:iic通信协议 这篇内容主要介绍一下SCCB协议。 文章目录 SCCB协议:SCCB时序图iic时序图SCCB时序 VS IIC时序 总:SCCB协议常用在摄像头配置上面,例如OV5640摄像头,和IIC协议很相似&…...
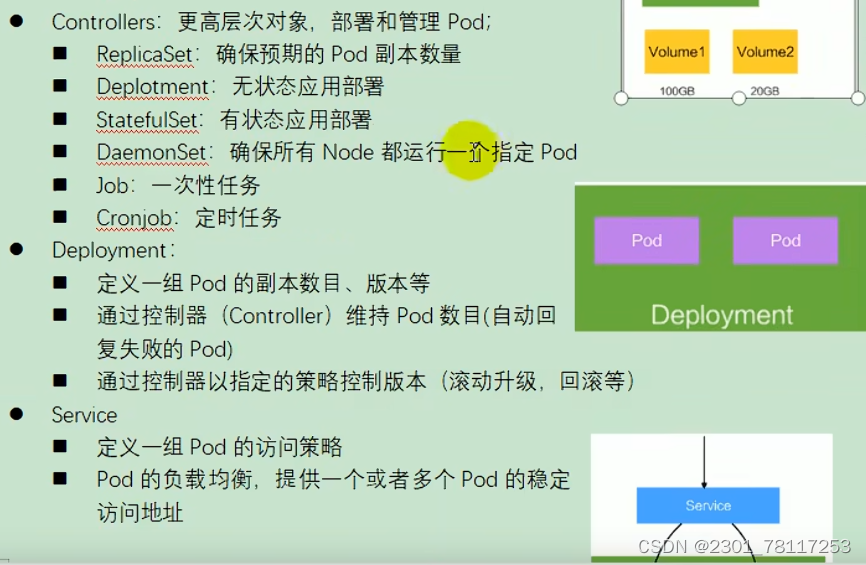
K8S基础简介
用于自动部署,扩展和管理容器化应用程序的开源系统。 功能: 服务发现和负载均衡; 存储编排; 自动部署和回滚; 自动二进制打包; 自我修复; 密钥与配置管理; 1. K8S组件 主从方式架…...

Studying-代码随想录训练营day24| 93.复原IP地址、78.子集、90.子集II
第24天,回溯算法part03,牢记回溯三部曲,掌握树形结构结题方法💪 目录 93.复原IP地址 78.子集 90.子集II 总结 93.复原IP地址 文档讲解:代码随想录复原IP地址 视频讲解:手撕复原IP地址 题目࿱…...

2024《汽车出海全产业数据安全合规发展白皮书》下载
随着中国制造向中国智造目标的迈进,中国汽车正以前所未有的速度和质量,在全球市场上开疆拓土。不过,在中国汽车加快出海步伐的过程中,数据安全合规风险管理成为车企不容忽视的课题。 6月25日,在中国(上海&…...
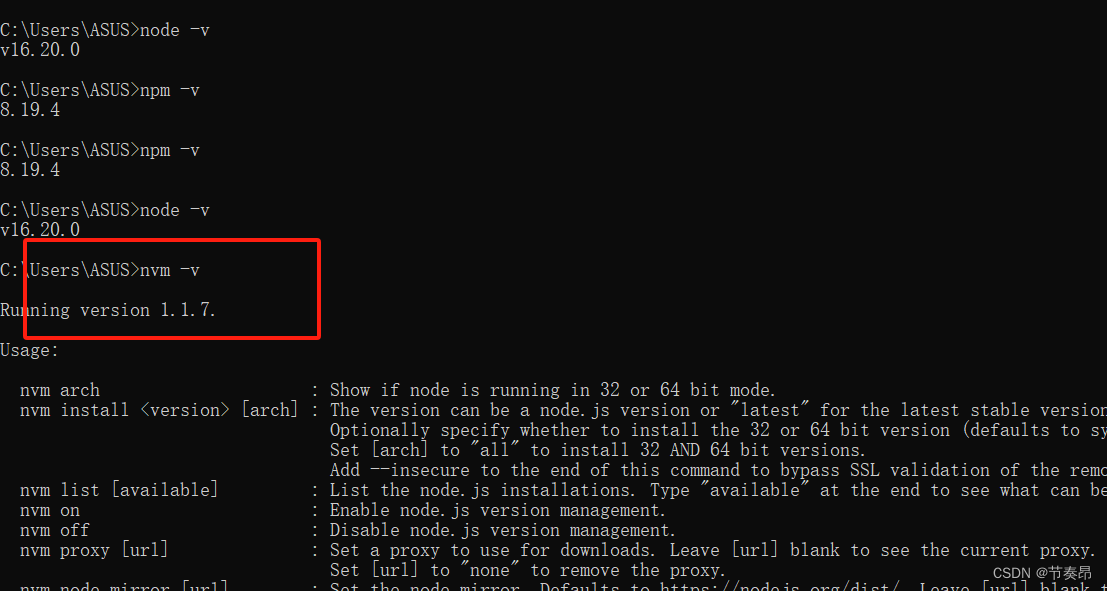
nvm安装以及idea下vue启动项目过程和注意事项
注意1:nvm版本不要太低,1.1.7会出现下面这个问题,建议1.1.10及其以上版本 然后安装这个教程安装nvm和node.js 链接: nvm安装教程(一篇文章所有问题全搞定,非常详细) 注意2:上面的教程有一步骤…...

Java SPI服务发现与扩展的利器
Java中,为了实现模块之间的解耦和可扩展性,我们常常需要一种机制来动态加载和替换实现。Java SPI就是这样一种机制,它允许我们在不修改原有代码的情况下,为接口添加新的实现,并在运行时动态加载它们。 SPI,…...

Ansible的Playbook
Playbook 特点 playbook 剧本是由一个或多个"play"组成的列表play的主要功能在于将预定义的一组主机,装扮成事先通过ansible中的task定义好的任务角色。Task实际是调用ansible的一个module,将多个play组织在一个playbook中,即可以让…...

多平台自动养号【开心版】偷偷使用就行了!
大家好,今天我无意间发现了一款【多平台自动养号工具】,看了一下里面的功能还是挺全面的,包含了【抖音,快手,小红薯】还有一些截流功能 虽然这款工具功能强大,但美中不足的是需要付费的。但别担心…...

ARM SCTLR2_EL2寄存器解析与虚拟化安全控制
1. ARM SCTLR2_EL2寄存器架构解析SCTLR2_EL2是ARMv8/v9架构中EL2(Hypervisor)级别的扩展系统控制寄存器,作为标准SCTLR_EL2的补充,它通过掩码位机制实现了对关键系统功能的细粒度控制。这个64位寄存器主要包含两类功能字段&#x…...

Augustus核心功能深度解析:路障、劳动力池与仓库管理
Augustus核心功能深度解析:路障、劳动力池与仓库管理 【免费下载链接】augustus An open source re-implementation of Caesar III 项目地址: https://gitcode.com/gh_mirrors/au/augustus Augustus是一款开源的Caesar III重制版游戏,它通过精准的…...

基于ESP32-S3与CircuitPython的NASA小行星追踪器项目实践
1. 项目概述:一个会“说话”的太空瞭望台如果你对头顶那片星空既充满好奇又带有一丝敬畏,想知道是否有“天外来客”正悄无声息地接近我们,那么这个项目就是为你准备的。这不是一个简单的数据看板,而是一个亲手搭建的、能实时“对话…...

如何用Python快速接入Taotoken平台调用多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用Python快速接入Taotoken平台调用多模型API 对于希望快速体验不同大模型能力的开发者而言,逐一对接各家厂商的API…...
之Java自动化不同类型环境的配置浅析)
自动化(二)之Java自动化不同类型环境的配置浅析
小编本文主要是关于Java自动化环境的配置搭建与大家进行分享。 本篇内容包含(基于上篇的基础上根据不同端汇总环境配置):单元测试(JUnit5) 接口自动化(RestAssured) UI自动化(Selenium) 测试报告(Allure)。 前置必备软件&#x…...

Perplexity搜索响应延迟超800ms?紧急修复手册:从LLM路由策略到本地缓存穿透的5层优化路径
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索响应延迟超800ms?紧急修复手册:从LLM路由策略到本地缓存穿透的5层优化路径 当Perplexity风格的语义搜索接口P95延迟持续突破800ms,用户会感知明显卡顿…...

开源机械爪资源库指南:从入门到ROS集成与自主抓取
1. 项目概述:一个开源“机械爪”的宝藏资源库如果你对机器人、自动化或者DIY硬件感兴趣,最近又在琢磨着给自己的项目加一个“手”,那么你很可能已经听说过“机械爪”这个概念。无论是想做一个自动抓取小物件的桌面机器人,还是为你…...

BQ34Z100-G1电量计配置不求人:用咸鱼EV2400+BqStudio完成电池组参数学习的保姆级教程
BQ34Z100-G1电量计配置实战:从零搭建高精度电池管理系统 在新能源和储能系统蓬勃发展的今天,精确的电池电量计量已成为电池管理系统(BMS)的核心竞争力。德州仪器(TI)的BQ34Z100-G1阻抗跟踪电量计凭借其出色的精度和稳定性,在工业储能、电动工…...

网盘下载新革命:一劳永逸的直链解析方案
网盘下载新革命:一劳永逸的直链解析方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅雷云…...

RT1064驱动ICM42605避坑指南:从SPI配置到数据转换,新手也能搞定的IMU实战
RT1064与ICM42605传感器深度开发实战:从硬件连接到数据处理的完整指南 在智能车和机器人竞赛中,精确的姿态感知系统往往是决定胜负的关键因素。恩智浦RT1064微控制器搭配TDK ICM42605六轴惯性测量单元(IMU)的方案,因其出色的性能和合理的成本…...