sql-语句
文章目录
- SQL语句的学习
- sql是什么
- sql的内置命令
- sql的种类
- sql mode
- 库,表属性介绍:字符集,存储引擎
- 列的数据类型:数字,字符串,时间
- 列的约束
- DDL: 数据定义语言
- 库
- 表
- Online DDL(ALGORITHM) *
- DML :数据操纵语言
- 资源组
- linux上查看帮助
- insert
- update
- delete
- 伪删除
- 面试题:1亿数据 drop table truncate table delete from table 有什么区别?快慢?
- select
- 基本查询(单表)
- group by+聚合函数操作,底层处理的基本逻辑
- having的使用
- order by
- limit
- DML-多表连接的语法
- 多表连接基本使用方法
- 别名
- 子查询
- DML子-union-unionall
- 对语句的压测
- 面试题: union和union all的区别?
- 小知识点
- 删除表中的字段
- 导出表
SQL语句的学习
sql是什么

sql的内置命令


mysql> ?For information about MySQL products and services, visit:http://www.mysql.com/
For developer information, including the MySQL Reference Manual, visit:http://dev.mysql.com/
To buy MySQL Enterprise support, training, or other products, visit:https://shop.mysql.com/List of all MySQL commands:
Note that all text commands must be first on line and end with ';'
? (\?) Synonym for `help'.
clear (\c) Clear the current input statement.
connect (\r) Reconnect to the server. Optional arguments are db and host.
delimiter (\d) Set statement delimiter.
edit (\e) Edit command with $EDITOR.
ego (\G) Send command to mysql server, display result vertically.
exit (\q) Exit mysql. Same as quit.
go (\g) Send command to mysql server.
help (\h) Display this help.
nopager (\n) Disable pager, print to stdout.
notee (\t) Don't write into outfile.
pager (\P) Set PAGER [to_pager]. Print the query results via PAGER.
print (\p) Print current command.
prompt (\R) Change your mysql prompt.
quit (\q) Quit mysql.
rehash (\#) Rebuild completion hash.
source (\.) Execute an SQL script file. Takes a file name as an argument.
status (\s) Get status information from the server.
system (\!) Execute a system shell command.
tee (\T) Set outfile [to_outfile]. Append everything into given outfile.
use (\u) Use another database. Takes database name as argument.
charset (\C) Switch to another charset. Might be needed for processing binlog with multi-byte charsets.
warnings (\W) Show warnings after every statement.
nowarning (\w) Don't show warnings after every statement.
resetconnection(\x) Clean session context.
query_attributes Sets string parameters (name1 value1 name2 value2 ...) for the next query to pick up.For server side help, type 'help contents'mysql> '试一试prompt'--->会显示正在登录的用户
vim /etc/my.cof
[mysql]
prompt=(\u@\h)[\d]>\_(root@localhost)[(none)]>
source是用来导入资源的
假如我/root/下有 t100.sql
(root@localhost)[test]> source /root/t100w.sql
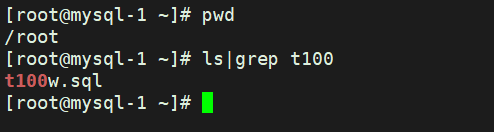

这样也可以导入↑
'status-->查看数据库的状态'
mysql里边执行linux命令↓
sql的种类

DDL、DML和DCL是数据库管理系统中使用的三种不同类型的SQL语句,它们分别代表数据定义语言、数据操纵语言和数据控制语言。
数据定义语言(DDL):DDL用于定义和修改数据库的结构。它包括CREATE、ALTER和DROP等语句,用于创建新的数据库对象(如表、索引、视图等),修改现有对象的结构,或删除数据库对象。DDL语句不会对数据库中存储的数据产生直接影响。
CREATE:用于创建新的数据库对象,如表、索引、视图等。ALTER:用于修改现有数据库对象的结构,如添加或删除列、修改数据类型等。DROP:用于删除数据库对象。数据操纵语言(DML):DML用于对数据库中的数据进行操作。它包括SELECT、INSERT、UPDATE和DELETE等语句,用于查询、插入、更新或删除数据库中的数据。
SELECT:用于查询数据库中的数据,可以指定查询条件和返回的列。INSERT:用于向数据库表中插入新的数据行。UPDATE:用于修改数据库表中已存在的数据。DELETE:用于从数据库表中删除数据。数据控制语言(DCL):DCL用于定义数据库的安全策略和访问权限。它包括GRANT和REVOKE等语句,用于授予或撤销用户对数据库对象的访问权限。
GRANT:用于授予用户对数据库对象的特定权限,如SELECT、INSERT、UPDATE等。REVOKE:用于撤销用户对数据库对象的权限。这三种语言共同构成了SQL语言的主体,用于不同的数据库管理和操作任务。
sql mode
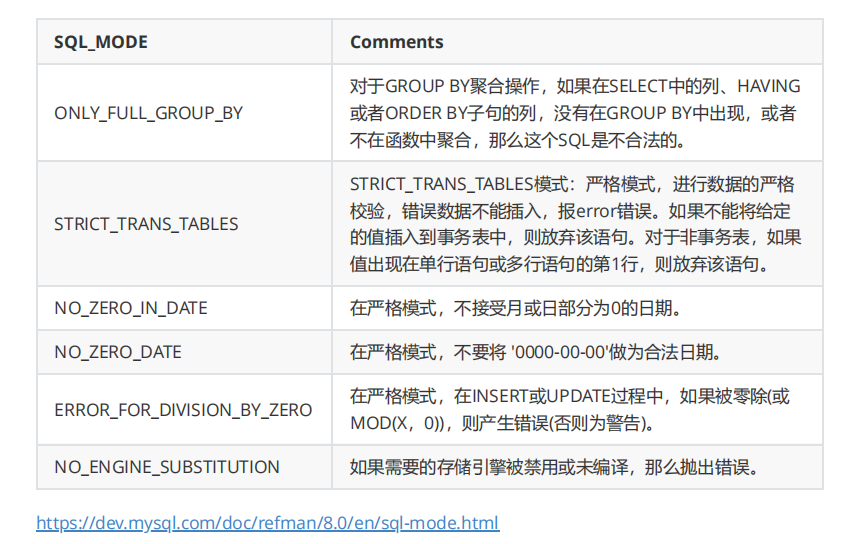
查看sql_mode
修改限制↓

库,表属性介绍:字符集,存储引擎
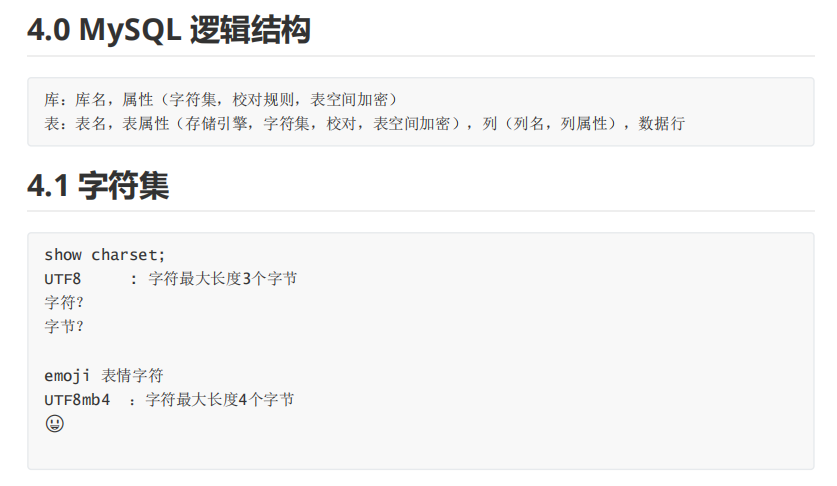


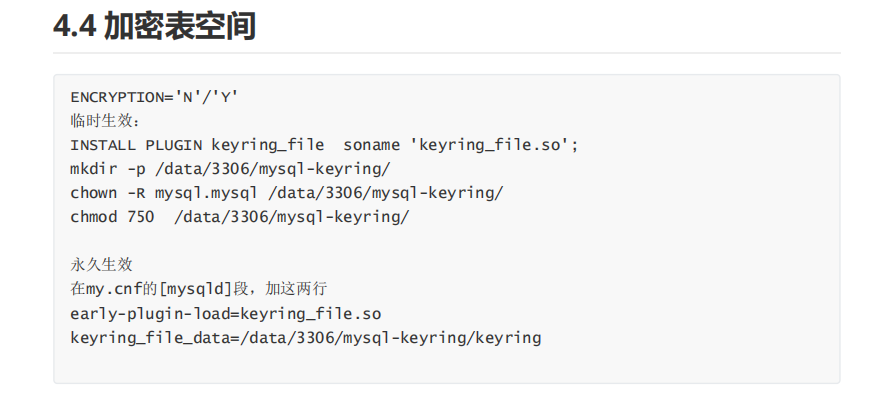
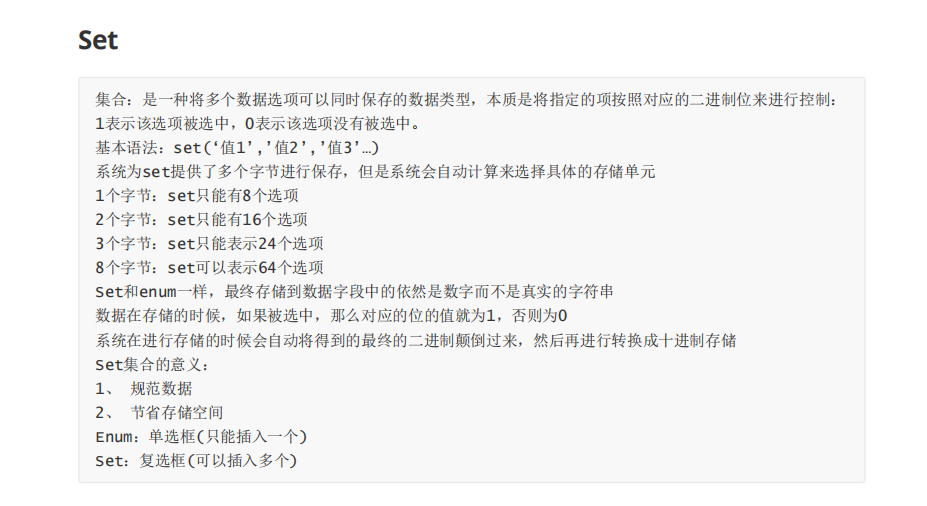
列的数据类型:数字,字符串,时间

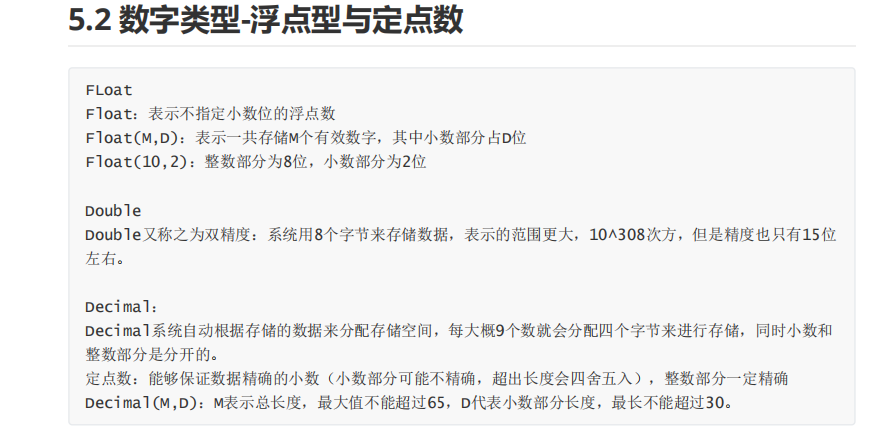

!


时间类型
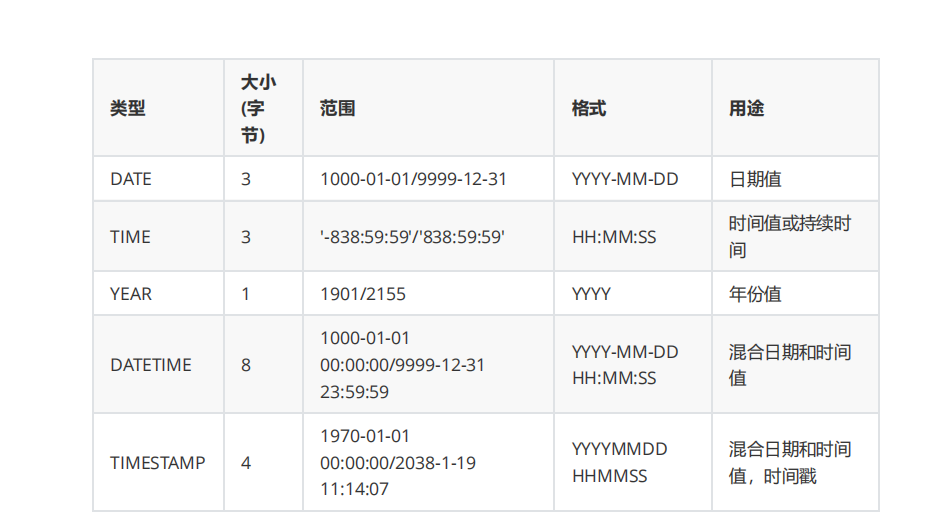
列的约束

DDL: 数据定义语言
库
## DDL 库定义## 创建数据库
CREATE DATABASE gaohui;
CREATE SCHEMA abc;
CREATE DATABASE if NOT EXISTS gaohui;
CREATE DATABASE if NOT EXISTS aaa charset utf8;
CREATE DATABASE if NOT EXISTS bbb COLLATE utf8mb4_0900_ai_ci;(root@localhost)[(none)]> show create database aaa;
+----------+-------------------------------------------------------------------------------------------------+
| Database | Create Database |
+----------+-------------------------------------------------------------------------------------------------+
| aaa | CREATE DATABASE `aaa` /*!40100 DEFAULT CHARACTER SET utf8 */ /*!80016 DEFAULT ENCRYPTION='N' */ |
+----------+-------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)(root@localhost)[(none)]>
(root@localhost)[(none)]> show create database aaa\G
*************************** 1. row ***************************Database: aaa
Create Database: CREATE DATABASE `aaa` /*!40100 DEFAULT CHARACTER SET utf8 */ /*!80016 DEFAULT ENCRYPTION='N' */
1 row in set (0.00 sec)(root@localhost)[(none)]>
## 查询库的定义 (不是DDL)
show DATABASES;
show CREATE DATABASE bbb;
### 修改库定义
alter DATABASE aaa charset utf8mb4;
### 删除库(不代表生产操作)
DROP DATABASE if EXISTS aaa;
### 规范
### 1.库名,不要数字开头、不能是关键字
### 2.生产禁用 drop database(只有管理员可以)
### 3.显示的设置字符集
### 4.起名和业务有关
表
### DDL 表定义
# 创建表定义
USE test;
CREATE TABLE IF NOT EXISTS stu(sid INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',sname VARCHAR(64) NOT NULL COMMENT '姓名',sage TINYINT UNSIGNED NOT NULL DEFAULT 18 COMMENT '年龄',sgender CHAR(1) NOT NULL DEFAULT 'M' COMMENT '性别:M|F',saddr ENUM('bj', 'tj', 'sh', 'cq', 'xk', 'am', 'tw') NOT NULL COMMENT '省份',stel CHAR(11) NOT NULL UNIQUE COMMENT '手机号',sqq CHAR(11) NOT NULL UNIQUE COMMENT 'qq号',intime DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入学时间'
) ENGINE = InnoDB CHARSET = utf8mb4 COMMENT='学生表';### 建表规范
1. 表名:不要大写字母,不要数字开头,不要超过18字符,不要用内置字符串,和业务有关。
2. 列名:业务有关,不要内置字符,不要超过18字符。
3. 数据类型:合适的,精简的,完整的。
4. 每个表要有且只有1个主键。每个列尽量Not null。尽量不要使用外键
5. 每列有注释。
6. 存储引擎InnoDB,字符集utf8mb41. 每个表建议在30个字段以内。
2. 需要存储emoji字符的,则选择utf8mb4字符集。
3. 机密数据,加密后存储。
4. 整型数据,默认加上UNSIGNED。
5. 存储IPV4地址建议用INT UNSIGNE,查询时再利用INET_ATON()、INET_NTOA()函数转换。
6. 如果遇到BLOB、TEXT大字段单独存储表或者附件形式存储。
7. 选择尽可能小的数据类型,用于节省磁盘和内存空间。
8. 存储浮点数,可以放大倍数存储。
9. 每个表必须有主键,INT/BIGINT并且自增做为主键,分布式架构使用sequence序列生成器保存。
10. 每个列使用not null,或增加默认值。
### 查询表定义
show tables;
show create table stu;
desc stu;### 复制创建一张表,只复制表结构
create table t1 like stu;
### 修改表定义
rename table stu to stu_1;
show tables;
alter table stu_1 engine= myisam;
alter table stu_1 engine= innodb;
### 生产需求1:在stu_1表中添加一个状态列is_deleted,表示这个行是否被删除(1:删除,0:没删)
alter table stu_1 add is_deleted tinyint not null DEFAULT 0 comment '状态列:1:删除,0:没删';
desc stu_1;### 加到字段后边
alter table stu_1 add a int after sname;
### 删除列
alter table stu_1 drop a;
### 生产需求2: 修改数据类型长度
alter table stu_1 modify sname varchar(100) not null COMMENT'学生名';### 生产需求3:添加索引,在表的某个列加一个索引
alter table stu_1 add index i_sname(sname);
desc stu_1;
### 删除表(不代表生产操作)
drop table student;### 清空表
truncate table stu_1;
Online DDL(ALGORITHM) *





DML :数据操纵语言

资源组





linux上查看帮助
(root@localhost)[(none)]> Data Manipulation-> ^C
(root@localhost)[(none)]> help Data Manipulation
You asked for help about help category: "Data Manipulation"
For more information, type 'help <item>', where <item> is one of the following
topics:CALLDELETEDODUALHANDLERIMPORT TABLEINSERTINSERT DELAYEDINSERT SELECTJOINLOAD DATALOAD XMLPARENTHESIZED QUERY EXPRESSIONSREPLACESELECTTABLEUNIONUPDATEVALUES STATEMENT(root@localhost)[(none)]>
insert
## insert
## 基本格式 inset into table_name[(colname1,colname2,...)] values(col1_value,col2_value,...);
'[]是可选'
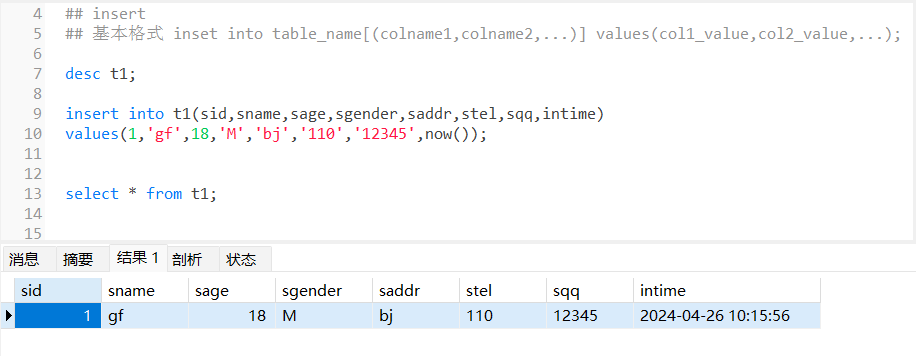
desc t1;insert into t1(sid,sname,sage,sgender,saddr,stel,sqq,intime)
values(1,'gf',18,'M','bj','110','12345',now());select * from t1;
'多行插入'
insert into t1(sid,sname,sage,sgender,saddr,stel,sqq,intime)
values
(2,'xf',18,'M','bj','119','12316245',now()),
(3,'gh',22,'M','bj','120','12345546',now()),
(4,'dj',30,'M','bj','130','12345279',now());select * from t1;

'偷懒写法'

insert into t1(sname,saddr,stel,sqq)
values('ss','sh','123123','252542');

replace 是有的话就替换
insert ignore 是有的话就跳过 有风险
update
## update 更改数据值
## update table_name set col_name=? 条件update t1 set sname='m64' where sid=5;
select * from t1;
'不加where,很可能把整列都给替换了,所以最好加上'
解决办法:
加个索引:

delete
最好加where条件
伪删除
## 伪删除(状态列的使用 is_deleted)
### 使用update进行替代delete### 1.添加状态列,并且设定默认值
alter table t1 add column is_deleted tinyint not null default 0;
desc t1;### 2.update 替代delete
### 一般删除是:delete from t1 where id=1;
### 替代为
update t1 set is_deleted=1 where sid=1;### 3.业务查询语句修改
select * from t1 where is_deleted=0;
面试题:1亿数据 drop table truncate table delete from table 有什么区别?快慢?
## 面试题:1亿数据 drop table truncate table delete from table 有什么区别?快慢?
### delete 是最慢的,逐行删除:他匹配到一行打一个标记,先查出来,再删除
### 速度: delete < drop table < truncate
### delete 是逐行打标记
### drop : 表定义删除,删除表空间文件ibd(操作系统rm)
### trucate : 保留表定义,清空表空间
select
基本查询(单表)
### select 独立使用的情况(不配合其他子句使用)### 查询系统变量(参数)
### select @@port; 看端口
### select @@datadir;
### select @@innodb_flush_log_at_trx_commit;
### show variables like '%trx%' \G### 查询函数
### select current_user()

### select 配合其他子句的应用*(单表)
### 书写顺序(语法)
select select_list
from
where
group by
having
order by
limit
### select 配合 from 使用 ---->cat /etc/passwd (生产中谨慎使用)
use test;
### a. 查询整表数据
select * from t1;
select sid,sname,sage,sgender,saddr,stel,sqq,intime,is_deleted from t1;### b.查询整表部分列数据
select sid,sname,sage from t1;
### select_from_where 使用 --->grep
### a.where = > < >= <= != between and in not in 比较判断使用


### select + from + where + (group by + 聚合函数)
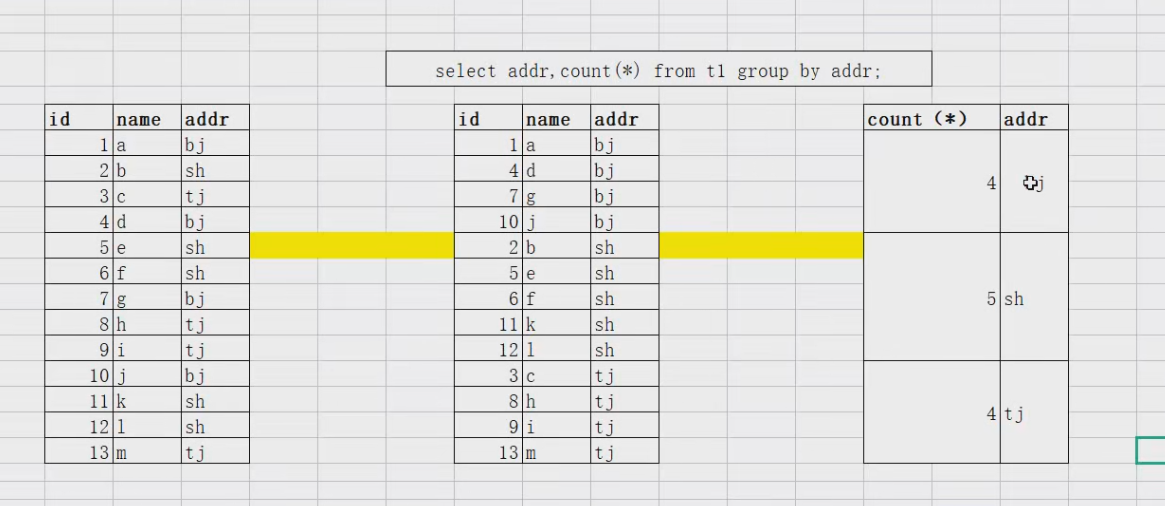
### group by + 聚合函数(count()、sum()、avg()、max()、min()、group_concat())
use world;
desc city;
### 统计每个国家的城市个数
select countrycode,count(*) from city group by countrycode;### 统计每个国家的人口总数
select countrycode,sum(population) from city group by countrycode;### 统计每个国家的城市个数,城市名列表
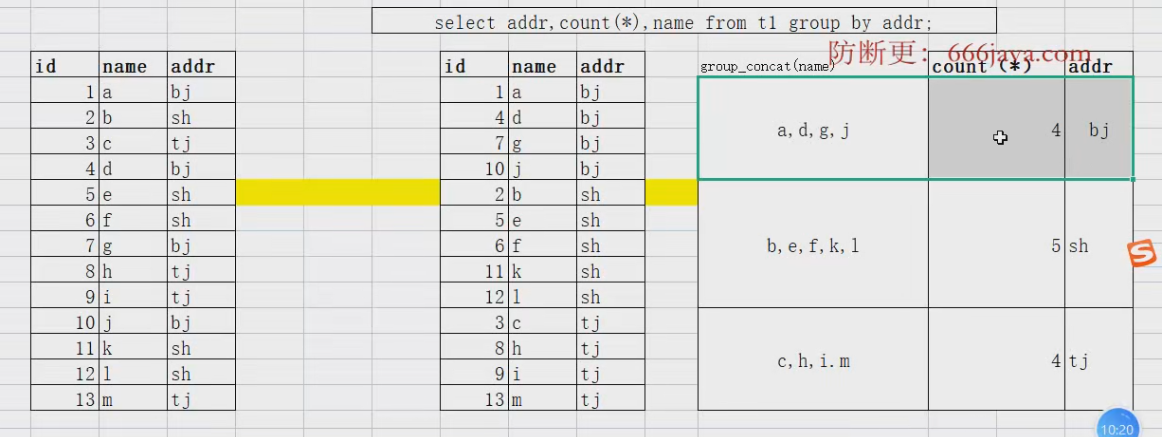
select countrycode,count(*),GROUP_CONCAT(name) from city group by countrycode;
### sql_mode=only_full_group,要求select_list中的列,要么在group by,要么在聚合函数中。
### GROUP_CONCAT()把一列数据,转换成一行来显示.
group by+聚合函数操作,底层处理的基本逻辑

having的使用
### having 使用,类似于where,需要在group by 聚合函数过滤后
### 统计每个国家的城市个数,截取城市数量大于100的
select countrycode,count(*) from city group by countrycode having count(*)>100;
order by
## order by 排序
select * from city order by population; --升序
select * from city order by population desc; --降序### 统计每个国家的城市个数,截取城市数量大于100的
select countrycode,count(*) from city group by countrycode having count(*)>100 order by count(*);
limit
## limit ,一般是配合order by 一起使用才有意义.
select * from city order by population desc limit 10; --只显示前10名
-- limit N offset M ---->输出n行,跳过m行 limit 3 offset 5 显示6-8行
-- limit M,N limit 5,3 --->反过来 跳过5行,显示3行
DML-多表连接的语法


(root@localhost)[test]> CREATE TABLE a (-> id INT AUTO_INCREMENT,-> name VARCHAR(255),-> age INT,-> bid INT,-> PRIMARY KEY (id)-> );
Query OK, 0 rows affected (0.00 sec)(root@localhost)[test]> CREATE TABLE b (-> id INT,-> addr VARCHAR(255),-> PRIMARY KEY (id)-> );
Query OK, 0 rows affected (0.00 sec)(root@localhost)[test]> INSERT INTO b (id, addr) VALUES-> (1001, 'bj'),-> (1002, 'sh'),-> (1003, 'tj'),-> (1004, 'cq');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0(root@localhost)[test]> INSERT INTO a (name, age, bid) VALUES-> ('a', 16, 1001),-> ('b', 12, 1002),-> ('C', 13, 1003),-> ('d', 16, 1006);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0(root@localhost)[test]> (root@localhost)[test]> select * from a;
+----+------+------+------+
| id | name | age | bid |
+----+------+------+------+
| 1 | a | 16 | 1001 |
| 2 | b | 12 | 1002 |
| 3 | C | 13 | 1003 |
| 4 | d | 16 | 1006 |
+----+------+------+------+
4 rows in set (0.00 sec)(root@localhost)[test]> select * from b;
+------+------+
| id | addr |
+------+------+
| 1001 | bj |
| 1002 | sh |
| 1003 | tj |
| 1004 | cq |
+------+------+
4 rows in set (0.00 sec)(root@localhost)[test]>
select * from a,b where a.bid=b.id; --'内连接'
-- 语法升级↓
select * from a join b on a.bid=b.id;
## 查询b的老家在哪
SELECT addr FROM b WHERE id = 1001;'外连接'
select * from a left join b on a.bid=b.id;

 ``
``
'内连接'
select * from a where a.bid in (select b.bid from b);
## 变成↓
select a.* from a join b on a.bid=b.id;

图解

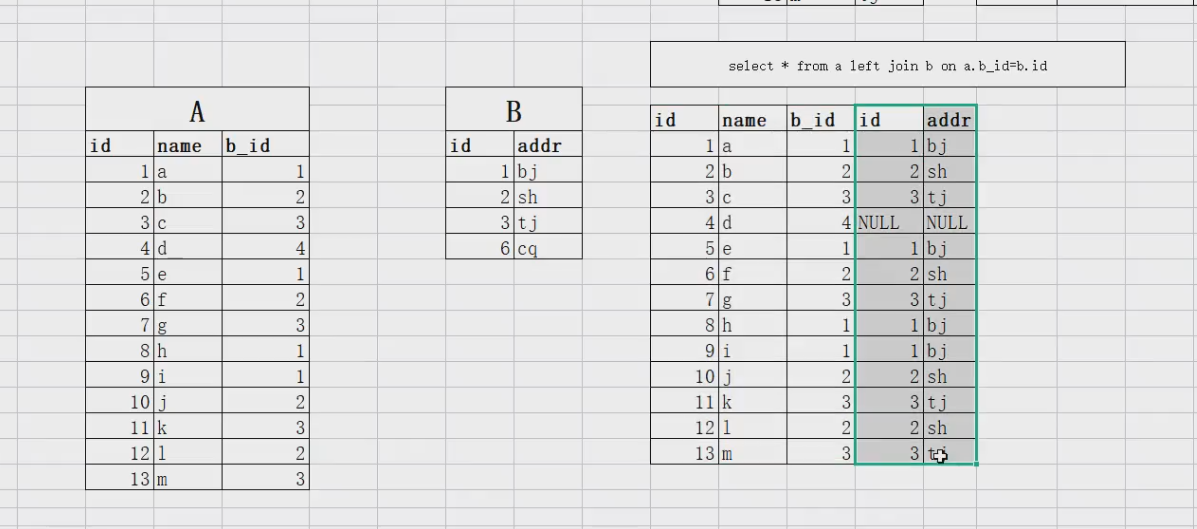
多表连接基本使用方法
‘先创建一些基本的表’
CREATE DATABASE school CHARSET utf8;
USE school;
CREATE TABLE student(sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',sname VARCHAR(20) NOT NULL COMMENT '姓名',sage TINYINT UNSIGNED NOT NULL COMMENT '年龄',ssex ENUM('f','m') NOT NULL DEFAULT 'm' COMMENT '性别'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE course(cno INT NOT NULL PRIMARY KEY COMMENT '课程编号',cname VARCHAR(20) NOT NULL COMMENT '课程名字',tno INT NOT NULL COMMENT '教师编号'
)ENGINE=INNODB CHARSET utf8;
CREATE TABLE sc (sno INT NOT NULL COMMENT '学号',cno INT NOT NULL COMMENT '课程编号',score INT NOT NULL DEFAULT 0 COMMENT '成绩'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE teacher(tno INT NOT NULL PRIMARY KEY COMMENT '教师编号',tname VARCHAR(20) NOT NULL COMMENT '教师名字'
)ENGINE=INNODB CHARSET utf8;
INSERT INTO student(sno,sname,sage,ssex)
VALUES (1,'zhang3',18,'m');
INSERT INTO student(sno,sname,sage,ssex)
VALUES
(2,'zhang4',18,'m'),
(3,'li4',18,'m'),
(4,'wang5',19,'f');
INSERT INTO student
VALUES
(5,'zh4',18,'m'),
(6,'zhao4',18,'m'),
(7,'ma6',19,'f');
INSERT INTO student(sname,sage,ssex)
VALUES
('oldboy',20,'m'),
('oldgirl',20,'f'),
('oldp',25,'m');
INSERT INTO teacher(tno,tname) VALUES
(101,'oldboy'),
(102,'hesw'),
(103,'oldguo');
DESC course;
INSERT INTO course(cno,cname,tno)
VALUES
(1001,'linux',101),
(1002,'python',102),
(1003,'mysql',103);
DESC sc;
INSERT INTO sc(sno,cno,score)
VALUES
(1,1001,80),
(1,1002,59),
(2,1002,90),
(2,1003,100),
(3,1001,99),
(3,1003,40),
(4,1001,79),
(4,1002,61),
(4,1003,99),
(5,1003,40),
(6,1001,89),
(6,1003,77),
(7,1001,67),
(7,1003,82),
(8,1001,70),
(9,1003,80),
(10,1003,96);
### 多表连接的练习使用### 1.查询每个老师教了哪些课程
#### teacher course student sc
##### 套路:a.分析题目,找到相关表
teacher course
##### b.找关联条件
teacher.tno=course.tno
##### c.组合select语句
select teacher.tname,course.cname from teacher join course on teacher.tno=course.tno;

### 2.查询zhang3学生,学习的课程信息#### 跟着套路分析 a.题目: student,sc, course
#### b.找关联条件:course.sno=sc.sno , sc.cno=course.cno ,student.sname='zhang3'
#### c.组合
select student.sname,course.cname from sc join student on student.sno=sc.sno join course on sc.cno=course.cno where student.sname='zhang3';

### 3.统计每个学生学习课程门数
#### 套路:student,sc
select student.sname,count(*) from student join sc on student.sno=sc.sno group by student.sno;

### 4.统计美国学生学习课程的名称
#### 套路:student,sc,course
select student.sname,GROUP_CONCAT(course.cname) from sc join student on student.sno=sc.sno join course on sc.cno=course.cno group by student.sno;

别名

as可以省略
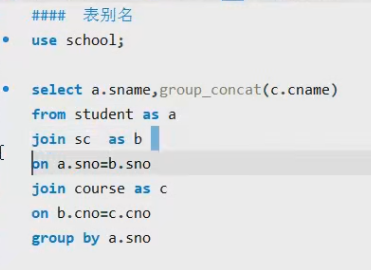
子查询
## 字查询
select from ()
select from where ()
### 子查询的查询方式: 限制性括号里边的,再执行外部的### 查询人口数是小于100人 国家名,国土面积
use world;
select name,countrycode,population from city where population<100;
select code,name,SurfaceArea from country where code='PCN';
-- 合并↓
select code,name,SurfaceArea from country where code in (select countrycode from city where population<100);
-- 高级写法,多表连接
select country.code,country.name,country.SurfaceArea
from country join city
on country.code=city.countrycode
where city.population<100;
分析一下怎么优化

DML子-union-unionall
## union 和 union all
### 查询中国或美国从城市信息
use world;
select * from city where countrycode in ('CHN','USA');
### 新思路 in or 可以转换为 union all---->优化
#### 执行计划,in range 扫描,= 使用的是等值匹配 ref
#### 但是,这种优化,对于查询条件重复值少的时候,效果比较明显,改写效果可能会变差。
select * from city where countrycode='CHN'
union all
select * from city where countrycode='USA';
对语句的压测
[root@mysql-1 ~]# mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='world' --query='select * from city where countrycode="CHN" union all select * from city where countrycode="USA"' engine=innodb --number-of-queries=2000 -u root -p123456 -verbose
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
BenchmarkRunning for engine rboseAverage number of seconds to run all queries: 0.586 secondsMinimum number of seconds to run all queries: 0.586 secondsMaximum number of seconds to run all queries: 0.586 secondsNumber of clients running queries: 100Average number of queries per client: 20[root@mysql-1 ~]#
mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 --iterations=1 --create-schema='world' \
--query=" select * from city where countrycode='CHN' union all select * from
city where countrycode='USA';" engine=innodb \
--number-of-queries=2000 -uroot -p123 -verbose
[root@mysql-1 ~]# mysqlslap --defaults-file=/etc/my.cnf \
> --concurrency=100 --iterations=1 --create-schema='world' \
> --query="SELECT * FROM city WHERE countrycode IN ('CHN','USA');" \
> engine=innodb \
> --number-of-queries=2000 -u root -p123456 -verbose
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
BenchmarkRunning for engine rboseAverage number of seconds to run all queries: 0.464 secondsMinimum number of seconds to run all queries: 0.464 secondsMaximum number of seconds to run all queries: 0.464 secondsNumber of clients running queries: 100Average number of queries per client: 20[root@mysql-1 ~]#
面试题: union和union all的区别?
union 会去重复,排序去重,消耗会比较高,需要临时表。
小知识点
删除表中的字段
ALTER TABLE table_name DROP COLUMN column_name;
ALTER TABLE a DROP COLUMN com;
导出表
相关文章:
sql-语句
文章目录 SQL语句的学习sql是什么sql的内置命令sql的种类sql mode库,表属性介绍:字符集,存储引擎列的数据类型:数字,字符串,时间列的约束DDL: 数据定义语言库表 Online DDL(ALGORITHM) *DML :数据操纵语言资…...

解决Vue3项目中跨域问题的步骤
决Vue3项目中跨域问题的步骤可以按照以下方式清晰地分点表示和归纳: 1. 使用代理服务器(Proxy) 步骤: 在Vue项目的根目录下找到或创建vue.config.js文件。在vue.config.js中配置devServer的proxy选项。设定需要代理的接口前缀&a…...

macos scroll direction
If there is no Trackpad option, we can change it in the Mouse option. How to Change the Scroll Direction on a Mac: 2 Ways...

Websocket实现方式二——注解方式
添加Websocket依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dependency>根据ServerEndpoint注解注册Websocket Configuration public class AgentWsConfig …...

零基础开始学习鸿蒙开发-页面导航栏布局设计
目录 1.设定初始页(Idex.ets) 2.自定义首页组件 3.自定义发现页面组件 4.自定义设置页面组件 总结:主要是运用 了Tabs组件对导航栏进行布局,然后运用BottomTabBarStyle组件嵌套图标和文字,完成导航栏的制作。 1.设定初始页(Idex.ets) import {find}…...
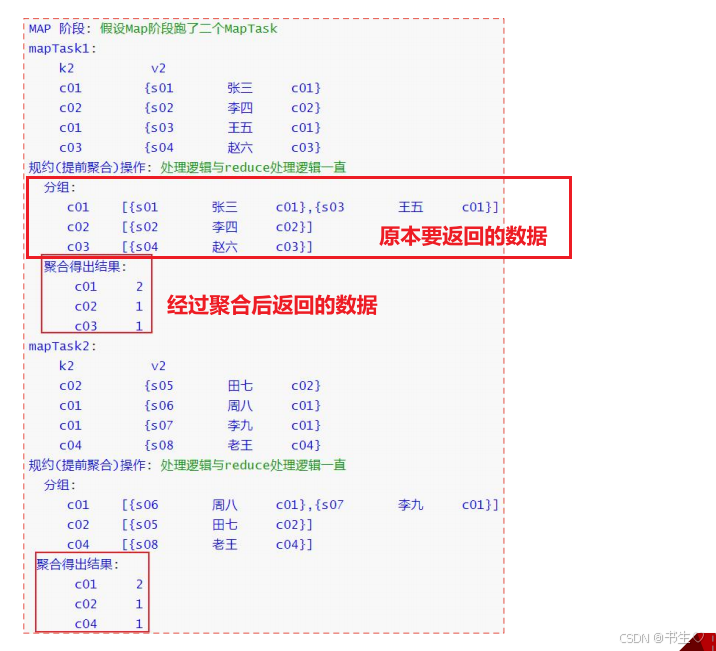
【Hive中常见的优化手段----数据采集!Join 优化!Hive索引!数据倾斜!mapreduce本地模式!map和reduce数量调整!】
前言: 💞💞大家好,我是书生♡,今天主要和大家分享一下Hive中常见的优化手段----数据采集!常见的Join 优化有哪几种!什么是Hive索引!数据怎么发生倾斜!什么是mapreduce的本…...

【面试系列】软件工程师高频面试题及详细解答
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、…...
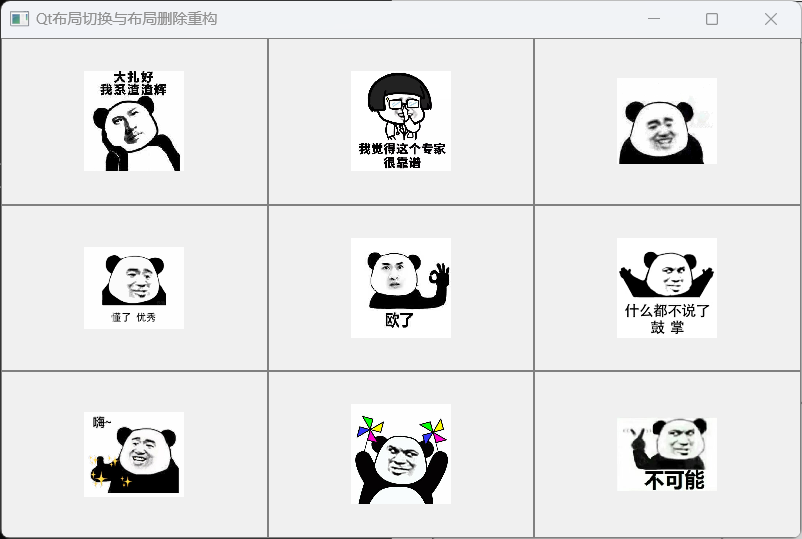
Qt开发 | Qt界面布局 | 水平布局 | 竖直布局 | 栅格布局 | 分裂器布局 | setLayout使用 | 添加右键菜单 | 布局切换与布局删除重构
文章目录 一、Qt界面布局二、Qt水平布局--QHBoxLayout三、Qt竖直布局四、Qt栅格布局五、分裂器布局代码实现六、setLayout使用说明七、布局切换与布局删除重构1.如何添加右键菜单2.布局切换与布局删除重构 一、Qt界面布局 Qt的界面布局类型可分为如下几种 水平布局(…...

LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection 论文链接:http://arxiv.org/abs/2406.03459 代码链接:https://github.com/Atten4Vis/LW-DETR 一、摘要 介绍了一种轻量级检测变换器LWDETR,它在实时物体检测方面超越…...

前端技术(二)——javasctipt 介绍
一、javascript基础 1. javascript简介 ⑴ javascript的起源 ⑵ javascript 简史 ⑶ javascript发展的时间线 ⑷ javascript的实现 ⑸ js第一个代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>…...
FireFox 编译指南2024 Windows10篇-环境准备(一)
1. 引言 在开源浏览器项目中,Firefox因其高性能和灵活性而备受开发者青睐。为了在本地环境中编译和定制Firefox,开发者需要做好充分的环境准备工作。这不仅是编译成功的基础,也是后续调试、优化和二次开发的关键步骤。 编译Firefox是一个复…...

Spring Boot中的热部署配置
Spring Boot中的热部署配置 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何在Spring Boot项目中实现热部署配置,提升开发效率和项…...

用ChatGPT快速打造一个专业WordPress网站
作为一个使用HostEase多年的老用户,我想和大家分享一下如何利用HostEase和ChatGPT快速构建一个WordPress网站的经验。这不仅仅是一个简单的操作步骤,更是一次从零到有的实战经历。希望我的分享能给你们带来一些实用的帮助。 获取主机服务和域名 首先&a…...

dsp入门
安装环境 安装 ccs5.5安装 BIOS-MCSDK 多核软件开发包安装 仿真器驱动 工程创建与导入工程 创建工程 创建工程填信息添加.cmd文件,配置内存编译 导入工程 导入 配置工程 选择properties 环境变量 头文件 库文件 仿真器 添加仿真器 先调出仿真器界面创建仿…...

Java并发编程-Atomiclnteger、LongAdder等原子类的使用及案例实战
文章目录 i++和Atomiclnteger之间的差别分析以及使用介绍i++AtomicInteger使用介绍i++ 示例AtomicInteger 示例总结Atomiclnteger中的CAS无锁化原理和思路介绍CAS 原理AtomicInteger 的 CAS 应用无锁化思路Atomiclnteger源码剖析:仅限JDK内部使用的Unsafe类`Unsafe` 类的关键作…...
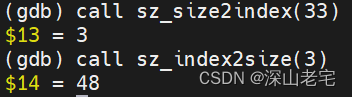
九浅一深Jemalloc5.3.0 -- ②浅*size class
目前市面上有不少分析Jemalloc老版本的博文,但5.3.0却少之又少。而且5.3.0的架构与之前的版本也有较大不同,本着“与时俱进”、“由浅入深”的宗旨,我将逐步分析Jemalloc5.3.0的实现。 另外,单讲实现代码是极其枯燥的,…...

JavaScript——属性的增删改查
目录 任务描述 相关知识 属性的获取 方式一 方式二 属性的修改与新增 删除属性 编程要求 任务描述 Luma Restaurant 以前的财务人员在统计销售额的时候不小心把数据弄错了,现在的财务人员想通过一个 JavaScript 函数方便的修改数据,并署上自己的…...

51单片机第15步_串口多机通讯使用CRC8校验
本章重点介绍串口多机通讯使用CRC8校验。 数据格式:"$123xxxx*crc8\r\n"; 如:"$1234567890ABCDEF*06\r\n" 如:"$1231234567890*31\r\n" crc8是CRC校验值,为十六进制的ASCII码,不包含$和校验值前面的那个* #include <REG51.h> //包含…...

WPF----进度条ProgressBar(渐变色)
ProgressBar 是一种用于指示进程或任务的进度的控件,通常在图形用户界面(GUI)中使用。它提供了一种视觉反馈,显示任务的完成程度,帮助用户了解任务的进展情况。 基本特性 Minimum 和 Maximum 属性: 这些属…...
)
Apipost接口测试工具的原理及应用详解(四)
本系列文章简介: 随着软件行业的快速发展,API(应用程序编程接口)作为不同软件组件之间通信的桥梁,其重要性日益凸显。API的质量直接关系到软件系统的稳定性、性能和用户体验。因此,对API进行严格的测试成为…...

百川2-13B-4bits量化模型微基准测试:OpenClaw常用任务性能对比
百川2-13B-4bits量化模型微基准测试:OpenClaw常用任务性能对比 1. 测试背景与动机 上周在折腾OpenClaw自动化办公流程时,发现我的RTX 3090显卡在运行13B模型时显存频繁告警。这让我开始关注量化模型的实际表现——特别是当OpenClaw需要连续调用模型完成…...

Z-Image-Turbo孙珍妮LoRA模型部署教程:支持WebP/AVIF新格式输出
Z-Image-Turbo孙珍妮LoRA模型部署教程:支持WebP/AVIF新格式输出 1. 引言:快速上手明星风格AI绘图 想用AI生成特定明星风格的图片吗?今天给大家介绍一个非常实用的工具——基于Z-Image-Turbo的孙珍妮LoRA模型。这个模型专门针对孙珍妮的风格…...
)
Linux命令-mkswap(设置交换分区或交换文件)
mkswap 命令用于在 Linux 系统中设置交换分区或交换文件,将其格式化为交换空间(swap space)。交换空间是磁盘上的一块区域,当物理内存不足时,系统会将不常用的内存页交换到这里。 📖 基本语法 mkswap [选项…...

时光守护者:一键备份QQ空间历史说说的终极解决方案
时光守护者:一键备份QQ空间历史说说的终极解决方案 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字时代,我们的记忆被分散在各个社交平台,QQ空…...
轻量库)
Arduino ESP平台MQTT固件空中升级(FUOTA)轻量库
1. 项目概述mqtt_fuota_duino是一个面向资源受限嵌入式物联网终端的轻量级固件空中升级(Firmware Update Over-The-Air, FUOTA)库,专为 Arduino 生态设计,深度适配 ESP8266 和 ESP32 平台。其核心使命并非替代标准 HTTP/HTTPS OTA…...

【CP AUTOSAR】Icu驱动模块:从原理到实战的配置与优化指南
1. Icu驱动模块在AUTOSAR架构中的核心作用 第一次接触AUTOSAR的Icu模块时,我完全被它复杂的配置项搞懵了。直到在S32K3项目上实际调试电机转速测量功能,才真正理解这个模块的价值。简单来说,Icu就像汽车电子系统的"脉搏检测仪"&…...

如何快速使用LivePortrait实现AI肖像动画:终极指南
如何快速使用LivePortrait实现AI肖像动画:终极指南 【免费下载链接】LivePortrait Bring portraits to life! 项目地址: https://gitcode.com/GitHub_Trending/li/LivePortrait LivePortrait 是一款革命性的AI肖像动画工具,能够将静态照片转化为栩…...

DownKyi:3分钟掌握B站视频下载的高效方法
DownKyi:3分钟掌握B站视频下载的高效方法 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)。 项…...

终极指南:5分钟为群晖Audio Station添加QQ音乐歌词插件
终极指南:5分钟为群晖Audio Station添加QQ音乐歌词插件 【免费下载链接】qq_music_aum Synology LRC Plugin. 群晖 Audio Station 歌词插件,歌词来自QQ音乐。 项目地址: https://gitcode.com/gh_mirrors/qq/qq_music_aum 还在为群晖Audio Station…...
分类的小项目,踩了不少坑也攒了点能直接跑的代码,今天掏出来跟大伙唠唠)
最近折腾了一波心音信号(PCG)分类的小项目,踩了不少坑也攒了点能直接跑的代码,今天掏出来跟大伙唠唠
MATLAB环境下一种基于连续小波变换和GoogLeNet的PCG信号分类算法 算法运行环境为MATLAB r2021b,共5种PCG信号,即normal, AR,AS,MR,MS五类 算法可迁移至金融时间序列,地震信号,语音信号,声信号,生理信号&…...