【数据结构】(C语言):二叉搜索树
二叉搜索树:
- 树不是线性的,是层级结构。
- 基本单位是节点,每个节点最多2个子节点。
- 有序。每个节点,其左子节点都比它小,其右子节点都比它大。
- 每个子树都是一个二叉搜索树。每个节点及其所有子节点形成子树。
- 可以是空树。
添加元素:从根节点开始,比对数值。若比它小,往左子树比对;若比它大,往右子树比对;直到找到为空,则为新元素的位置。
删除元素:
- 若删除的节点为叶子节点(即无子节点),则直接删除。
- 若删除的节点只有左子节点,则左子节点替代删除节点。
- 若删除的节点只有右子节点,则右子节点替代删除节点。
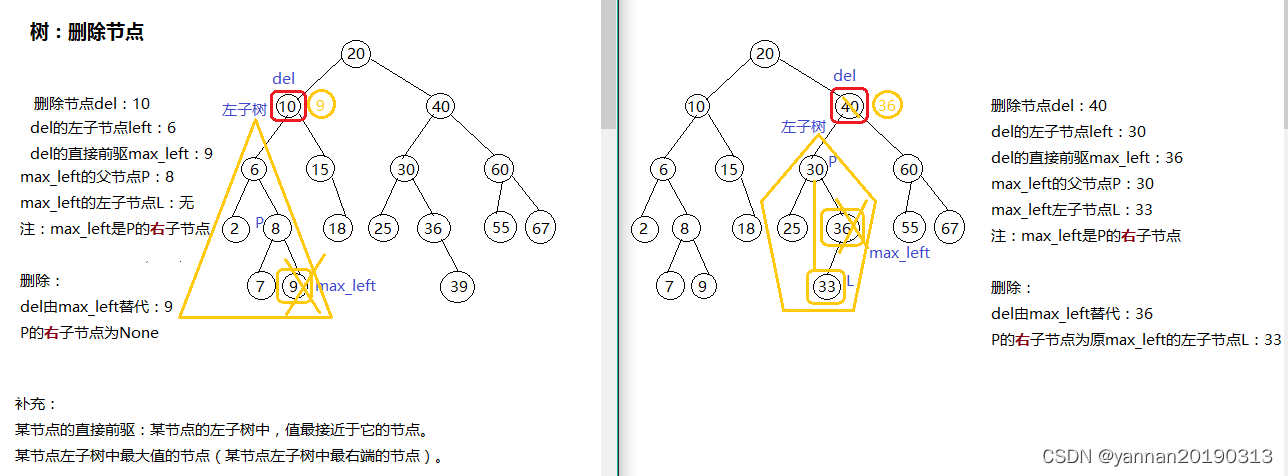
- 若删除的节点既有左子节点又有右子节点,则找到直接前驱(即删除节点的左子树中的最大值,即删除节点的左子节点的最右节点),直接前驱的值替代删除节点的值,删除直接前驱节点。
遍历元素:(可使用递归)
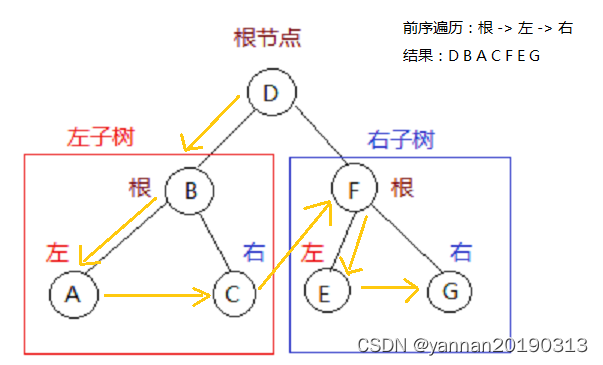
- 前序遍历(顺序:根节点、左子节点、右子节点)。
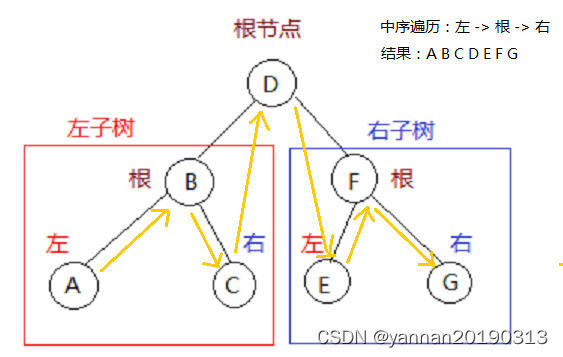
- 中序遍历(顺序:左子节点、根节点、右子节点)。
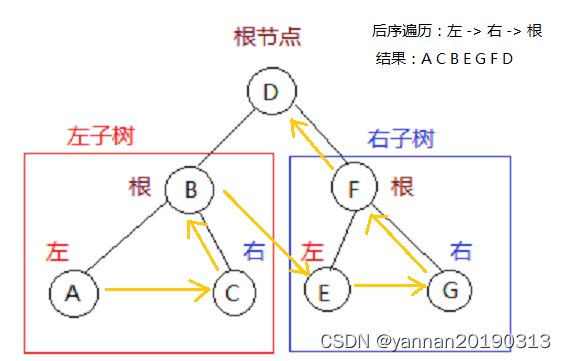
- 后序遍历(顺序:左子节点、右子节点、根节点)。
查找元素:从根节点开始,比对数值。若比它小,往左子树查找;若比它大,往右子树查找;直到找到该元素,则返回1(true),若没有,则返回0(false)。
C语言实现:(使用链表实现)
创建结构体数据类型(记录二叉搜索树的根节点和数据个数):
typedef struct Link
{LinkNode *root; // 根节点int length; // 统计有多少数据
} LinkBST; // 别名创建二叉搜索树,并初始化:
LinkBST bst;
bst.root = NULL; // 根节点,初始化为NULL
bst.length = 0; // 数据个数,初始化为0创建节点(结构体数据类型),并创建具体节点实例的函数:
// 节点(结构体数据类型)
typedef struct Node
{int value; // 数据类型为整型struct Node *left; // 左子节点struct Node *right; // 右子节点
}LinkNode; // 别名// 函数:创建节点
LinkNode *createNode(int data)
{LinkNode *node = (LinkNode *)malloc(sizeof(LinkNode)); // 分配节点内存空间if(node == NULL){perror("Memory allocation failed");exit(-1);}node->value = data; // 数据node->left = NULL; // 左子节点,初始化为NULLnode->right = NULL; // 右子节点,初始化为NULLreturn node;
}添加元素:
void add(LinkBST *bst, int data) // add element
{// 函数:往二叉搜索树中添加元素 LinkNode *addNode(LinkNode *node, int data){if(node == NULL){LinkNode *newnode = createNode(data);node = newnode;bst->length++; // 每添加一个元素,length+1return node;}if(data < node->value) node->left = addNode(node->left, data);else if(data > node->value) node->right = addNode(node->right, data);return node;}// 从根节点开始比对,root指针始终指向二叉搜索树的根节点bst->root = addNode(bst->root, data);
}删除元素:
void delete(LinkBST *bst, int data) // delete element
{// 函数:删除节点 LinkNode *del(LinkNode *node){ // 若只有右子节点,则右子节点替代删除节点if(node->left == NULL){bst->length--; // 每删除一个元素,length-1return node->right;}// 若只有左子节点,则左子节点替代删除节点else if(node->right == NULL){bst->length--; // 每删除一个元素,length-1return node->left;}// 左右子节点都有,则直接前驱(左子节点的最右节点)替代删除节点,并删除直接前驱else if(node->left && node->right){LinkNode *tmp = node, *cur = node->left;while(cur->right){tmp = cur;cur = cur->right;}node->value = cur->value;if(tmp != node) tmp->right = cur->left;else tmp->left = cur->left;bst->length--; // 每删除一个元素,length-1return node;}}// 函数:找到将要删除的节点LinkNode *delNode(LinkNode *node, int data){if(node == NULL) return node;if(data == node->value) node = del(node);else if(data < node->value) node->left = delNode(node->left, data);else if(data > node->value) node->right = delNode(node->right, data);return node;} // 从根节点开始比对。root指针始终指向二叉搜索树的根节点bst->root = delNode(bst->root, data);
}遍历元素:(使用递归)
// 前序遍历(根,左,右)
void pretravel(LinkNode *node)
{if(node == NULL) return ;printf("%d ", node->value);pretravel(node->left);pretravel(node->right);
}// 中序遍历(左,根,右)
void midtravel(LinkNode *node)
{if(node == NULL) return ;midtravel(node->left);printf("%d ", node->value);midtravel(node->right);
}// 后序遍历(左,右,根)
void posttravel(LinkNode *node)
{if(node == NULL) return ;posttravel(node->left);posttravel(node->right);printf("%d ", node->value);
}查找元素:
找到元素,返回1(true);没找到,返回0(false)。
int find(LinkNode *node, int data)
{if(node == NULL) return 0;if(data == node->value) return 1;if(data < node->value) find(node->left, data);else if(data > node->value) find(node->right, data);
}完整代码:(bst.c)
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>/* structure */
typedef struct Node // linkedlist node
{int value; // value type is integerstruct Node *left; // left child nodestruct Node *right; // right child node
}LinkNode;typedef struct Link // binary search tree
{LinkNode *root; // root node of the treeint length; // the number of the tree
} LinkBST;/* function prototype */
void add(LinkBST *, int); // add element to the tree
void delete(LinkBST *, int); // delete element from the tree
void pretravel(LinkNode *); // show element one by one,(root,left,right)
void midtravel(LinkNode *); // show element one by one,(left,root,right)
void posttravel(LinkNode *); // show element one by one,(left,right,root)
int find(LinkNode *, int); // if find data,return 1(true),or return 0(false)/* main function */
int main(void)
{// create binary search tree and initializationLinkBST bst;bst.root = NULL;bst.length = 0;printf("isempty(1:true, 0:false): %d, length is %d\n", bst.root==NULL, bst.length);add(&bst, 15);add(&bst, 8);add(&bst, 23);add(&bst, 10);add(&bst, 12);add(&bst, 19);add(&bst, 6);printf("isempty(1:true, 0:false): %d, length is %d\n", bst.root==NULL, bst.length);printf("midtravel: ");midtravel(bst.root);printf("\n");printf("pretravel: ");pretravel(bst.root);printf("\n");printf("posttravel: ");posttravel(bst.root);printf("\n");printf("find 10 (1:true, 0:false): %d\n", find(bst.root, 10));printf("find 9 (1:true, 0:false): %d\n", find(bst.root, 9));delete(&bst, 23);delete(&bst, 15);delete(&bst, 6);printf("isempty(1:true, 0:false): %d, length is %d\n", bst.root==NULL, bst.length);printf("midtravel: ");midtravel(bst.root);printf("\n");printf("pretravel: ");pretravel(bst.root);printf("\n");printf("posttravel: ");posttravel(bst.root);printf("\n");return 0;
}/* subfunction */
LinkNode *createNode(int data) // create a node
{LinkNode *node = (LinkNode *)malloc(sizeof(LinkNode));if(node == NULL){perror("Memory allocation failed");exit(-1);}node->value = data;node->left = NULL;node->right = NULL;return node;
}void add(LinkBST *bst, int data) // add element
{// subfunction(recursion): add element to the binary search tree LinkNode *addNode(LinkNode *node, int data){if(node == NULL){LinkNode *newnode = createNode(data);node = newnode;bst->length++;return node;}if(data < node->value) node->left = addNode(node->left, data);else if(data > node->value) node->right = addNode(node->right, data);return node;}// root node receive the resultbst->root = addNode(bst->root, data);
}void delete(LinkBST *bst, int data) // delete element
{// subfunction(recursion): delete element from the binary search tree LinkNode *del(LinkNode *node){if(node->left == NULL){bst->length--;return node->right;}else if(node->right == NULL){bst->length--;return node->left;}else if(node->left && node->right){LinkNode *tmp = node, *cur = node->left;while(cur->right){tmp = cur;cur = cur->right;}node->value = cur->value;if(tmp != node) tmp->right = cur->left;else tmp->left = cur->left;bst->length--;return node;}}// subfunction: find delete node,return nodeLinkNode *delNode(LinkNode *node, int data){if(node == NULL) return node;if(data == node->value) node = del(node);else if(data < node->value) node->left = delNode(node->left, data);else if(data > node->value) node->right = delNode(node->right, data);return node;} // root node receive the resultbst->root = delNode(bst->root, data);
}void pretravel(LinkNode *node) // show element one by one,(root,left,right)
{if(node == NULL) return ;printf("%d ", node->value);pretravel(node->left);pretravel(node->right);
}void midtravel(LinkNode *node) // show element one by one,(left,root,right)
{if(node == NULL) return ;midtravel(node->left);printf("%d ", node->value);midtravel(node->right);
}void posttravel(LinkNode *node) // show element one by one,(left,right,root)
{if(node == NULL) return ;posttravel(node->left);posttravel(node->right);printf("%d ", node->value);
}int find(LinkNode *node, int data) // if find data,return 1(true),or return 0(false)
{if(node == NULL) return 0;if(data == node->value) return 1;if(data < node->value) find(node->left, data);else if(data > node->value) find(node->right, data);
}编译链接: gcc -o bst bst.c
执行可执行文件: ./bst
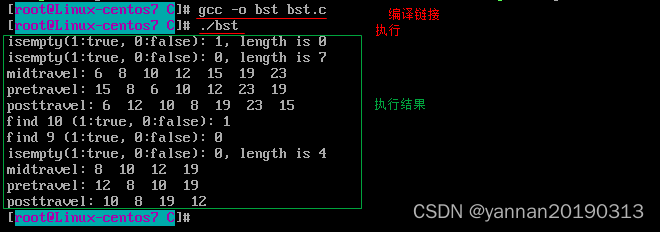
相关文章:
【数据结构】(C语言):二叉搜索树
二叉搜索树: 树不是线性的,是层级结构。基本单位是节点,每个节点最多2个子节点。有序。每个节点,其左子节点都比它小,其右子节点都比它大。每个子树都是一个二叉搜索树。每个节点及其所有子节点形成子树。可以是空树。…...
)
泛微开发修炼之旅--23基于ecology自研的数据库分页组件(分页组件支持mysql、sqlserver、oracle、达梦等)
一、使用场景 ecology二开开发过程中,经常要使用到分页查询,随着信创项目的到来,各种国产数据库的出现,对于数据库分页查询兼容何种数据库,就迫在眉睫。 于是,我自己基于ecology开发了一个分页插件&#…...
《昇思25天学习打卡营第4天 | mindspore Transforms 数据变换常见用法》
1. 背景: 使用 mindspore 学习神经网络,打卡第四天; 2. 训练的内容: 使用 mindspore 的常见的数据变换 Transforms 的使用方法; 3. 常见的用法小节: 支持一系列常用的 Transforms 的操作 3.1 Vision …...
【Python时序预测系列】基于LSTM实现多输入多输出单步预测(案例+源码)
这是我的第312篇原创文章。 一、引言 单站点多变量输入多变量输出单步预测问题----基于LSTM实现。 多输入就是输入多个特征变量 多输出就是同时预测出多个标签的结果 单步就是利用过去N天预测未来1天的结果 二、实现过程 2.1 读取数据集 dfpd.read_csv("data.csv&qu…...
git客户端工具之Github,适用于windows和mac
对于我本人,我已经习惯了使用Github Desktop,不同的公司使用的代码管理平台不一样,就好奇Github Desktop是不是也适用于其他平台,结果是可以的。 一、克隆代码 File --> Clone repository… 选择第三种URL方式,输入url &…...

ai除安卓手机版APP软件一键操作自动渲染去擦消稀缺资源下载
安卓手机版:点击下载 苹果手机版:点击下载 电脑版(支持Mac和Windows):点击下载 一款全新的AI除安卓手机版APP,一键操作,轻松实现自动渲染和去擦消效果,稀缺资源下载 1、一键操作&…...

Unity获取剪切板内容粘贴板图片文件文字
最近做了一个发送消息的unity项目,需要访问剪切板里面的图片文字文件等,翻遍了网上的东西,看了不是需要导入System.Windows.Forms(关键导入了unity还不好用,只能用在纯c#项目中),所以我看了下py…...
利用谷歌云serverless代码托管服务Cloud Functions构建Gemini Pro API
谷歌在2024年4月发布了全新一代的多模态模型Gemini 1.5 Pro,Gemini 1.5 Pro不仅能够生成创意文本和代码,还能理解、总结上传的图片、视频和音频内容,并且支持高达100万tokens的上下文。在多个基准测试中表现优异,性能超越了ChatGP…...

极狐GitLab 17.0 重磅发布,100+ DevSecOps功能更新来啦~【一】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab :https://gitlab.cn/install?channelcontent&utm_sourcecsdn 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署…...
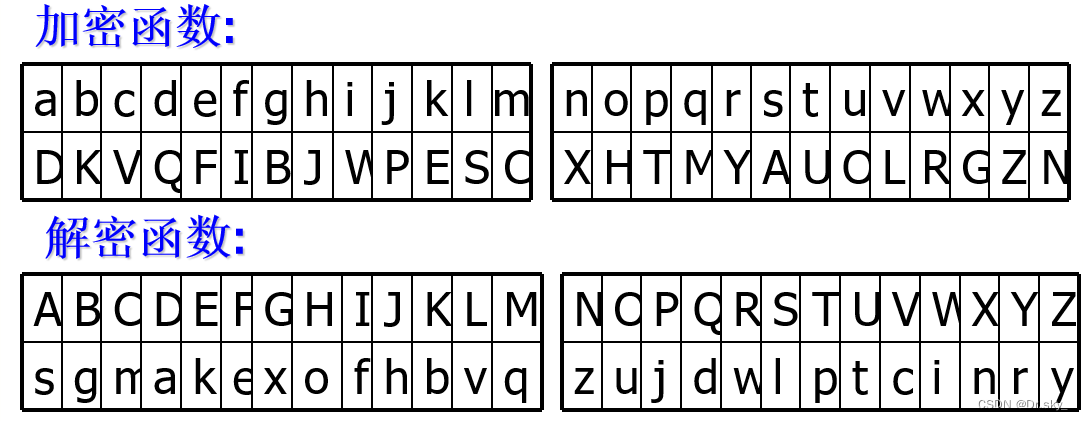
python实现符文加、解密
在历史悠久的加密技术中,恺撒密码以其简单却有效的原理闻名。通过固定的字母位移,明文可以被转换成密文,而解密则是逆向操作。这种技术不仅适用于英文字母,还可以扩展到其他语言的字符体系,如日语的平假名或汉语的拼音…...

【解释】i.MX6ULL_IO_电气属性说明
【解释】i.MX6ULL_IO_电气属性说明 文章目录 1 Hyst1.1 迟滞(Hysteresis)是什么?1.2 GPIO的Hyst. Enable Field 参数1.3 应用场景 2 Pull / Keep Select Field2.1 PUE_0_Keeper — Keeper2.2 PUE_1_Pull — Pull2.3 选择Keeper还是Pull 3 Dr…...

02-《石莲》
石 莲 石莲(学名:Sinocrassula indica A.Berger),别名因地卡,为二年生草本植物,全株无毛,具须根。花茎高15-60厘米,直立,常被微乳头状突起。茎生叶互生,宽倒披…...
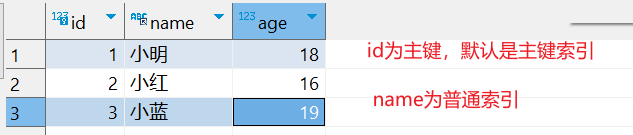
MySQL之聚簇索引和非聚簇索引
1、什么是聚簇索引和非聚簇索引? 聚簇索引,通常也叫聚集索引。 非聚簇索引,指的是二级索引。 下面看一下它们的含义: 1.1、聚集索引选取规则 如果存在主键,主键索引就是聚集索引。如果不存在主键,将使…...
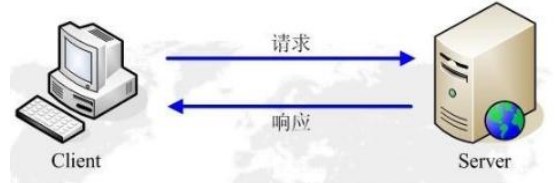
Web后端开发之前后端交互
http协议 http ● 超文本传输协议 (HyperText Transfer Protocol)服务器传输超文本到本地浏览器的传送协议 是互联网上应用最为流行的一种网络协议,用于定义客户端浏览器和服务器之间交换数据的过程。 HTTP是一个基于TCP/IP通信协议来传递数据. HTT…...

520. 检测大写字母 Easy
我们定义,在以下情况时,单词的大写用法是正确的: 全部字母都是大写,比如 "USA" 。 单词中所有字母都不是大写,比如 "leetcode" 。 如果单词不只含有一个字母,只有首字母大写࿰…...

vue的跳转传参
1、接收参数使用route,route包含路由信息,接收参数有两种方式,params和query path跳转只能使用query传参,name跳转都可以 params:获取来自动态路由的参数 query:获取来自search部分的参数 写法 path跳,query传 传参数 import { useRout…...

docker配置镜像源
1)打开 docker配置文件 sudo nano /etc/docker/daemon.json 2)添加 国内镜像源 {"registry-mirrors": ["https://akchsmlh.mirror.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc…...
MySQL高级-SQL优化-insert优化-批量插入-手动提交事务-主键顺序插入
文章目录 1、批量插入1.1、大批量插入数据1.2、启动Linux中的mysql服务1.3、客户端连接到mysql数据库,加上参数 --local-infile1.4、查询当前会话中 local_infile 系统变量的值。1.5、开启从本地文件加载数据到服务器的功能1.6、创建表 tb_user 结构1.7、上传文件到…...
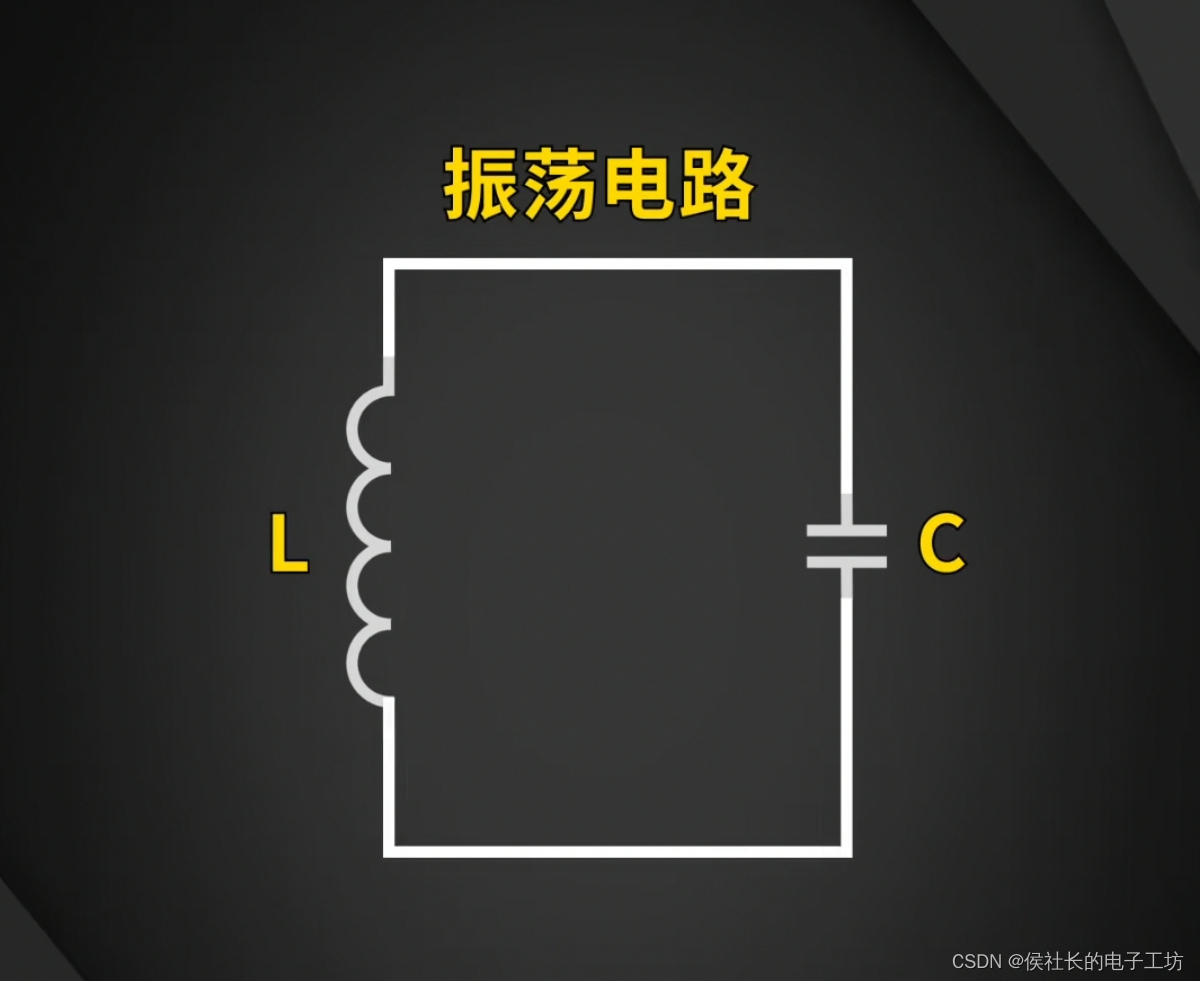
认识100种电路之振荡电路
在电子电路领域,振荡是一项至关重要的功能。那么,为什么电路中需要振荡?其背后的原理是什么?让我们一同深入探究。 【为什么需要振荡电路】 简单来说,振荡电路的存在是为了产生周期性的信号。在众多电子设备中&#…...
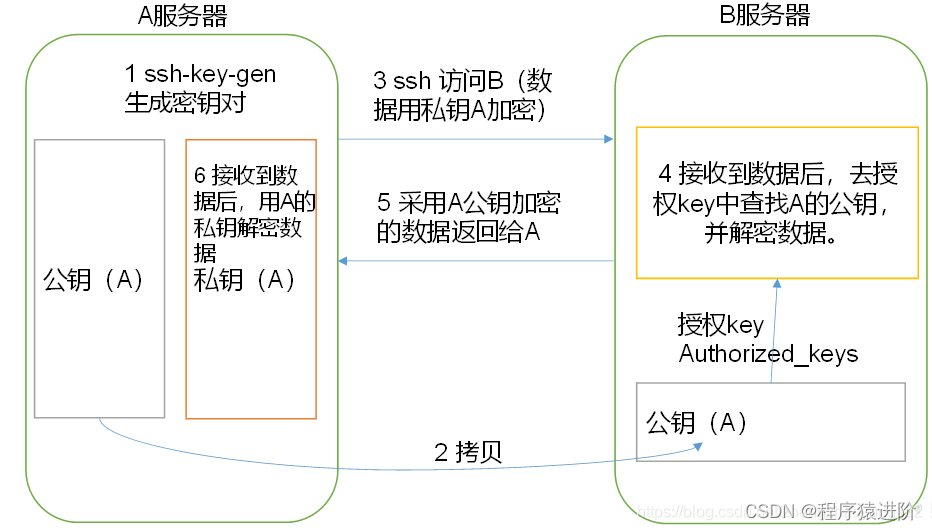
SSH 无密登录配置流程
一、免密登录原理 非对称加密: 由于对称加密的存在弊端,就产生了非对称加密,非对称加密中有两个密钥:公钥和私钥。公钥由私钥产生,但却无法推算出私钥;公钥加密后的密文,只能通过对应的私钥来解…...

Hermes Agent框架对接Taotoken聚合API的详细配置步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent框架对接Taotoken聚合API的详细配置步骤指南 1. 准备工作 在开始配置之前,你需要准备好两样东西…...

Windows-build-tools终极指南:5个步骤快速配置C++构建环境
Windows-build-tools终极指南:5个步骤快速配置C构建环境 【免费下载链接】windows-build-tools :package: Install C Build Tools for Windows using npm 项目地址: https://gitcode.com/gh_mirrors/wi/windows-build-tools Windows-build-tools是一个专为Wi…...

终极二维码修复指南:如何用QrazyBox轻松恢复损坏的QR码数据
终极二维码修复指南:如何用QrazyBox轻松恢复损坏的QR码数据 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾经遇到过这样的情况?打印出来的二维码模糊不清&…...

Taotoken助力初创团队以可控成本集成大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken助力初创团队以可控成本集成大模型能力 为产品添加智能对话功能是许多初创团队提升用户体验的关键一步。然而,…...

你的显卡真的在干活吗?Pycharm里用这行代码快速验证PyTorch GPU加速是否生效
你的显卡真的在干活吗?Pycharm里用这行代码快速验证PyTorch GPU加速是否生效 当你在Pycharm中完成了PyTorch GPU版的安装,torch.cuda.is_available()也返回了True,是否就意味着GPU加速已经完美运行?现实情况往往比这复杂得多。很多…...

从零到一:RK3588s平台imx415双目相机模组点亮与ISP调优实战
1. 环境准备:从零搭建开发环境 第一次接触RK3588s平台时,最头疼的就是环境搭建。我用的Firefly AIO-3588S-JD4开发板配套资料比较分散,光是找齐所有软件包就花了半天时间。这里分享下我的踩坑经验: 硬件清单必须严格核对&#x…...

9.9元ESP32-C3移植RT-Thread Nano:低成本RTOS开发与调试实战
1. 项目概述:当开源RTOS遇上性价比神板最近在捣鼓嵌入式开发,发现了一块宝藏开发板——ESP32-C3的某个简约款,价格直接干到了9.9元。这个价格,别说喝杯奶茶了,连个像样的模块都买不到,但它不仅能跑起来&…...

三步构建高效笔记迁移系统:Obsidian Importer完全指南
三步构建高效笔记迁移系统:Obsidian Importer完全指南 【免费下载链接】obsidian-importer Obsidian Importer lets you import notes from other apps and file formats into your Obsidian vault. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-import…...

从 SU01 到 SAP HANA,DBMS 用户管理里的 SSO 选项到底在管什么
项目里讨论 SSO 时,大家很容易把它想成一个单点登录按钮,好像在某处勾选一下,用户就能从 SAP GUI、Fiori、报表工具一路无感访问到数据库。到了 SAP NetWeaver AS 和 SAP HANA 组合的系统里,这个理解会带来不少误会。因为从 ABAP 侧维护 DBMS 用户的 SSO 选项,只是在用户主…...

ChatGPT对话导出工具:一键保存结构化对话记录到Markdown
1. 项目概述:一个帮你“打包”对话记录的工具如果你经常使用ChatGPT的网页版进行深度对话,无论是用它来辅助编程、学习新知识,还是进行创意写作,你可能会遇到一个共同的痛点:那些充满价值的对话记录,被“锁…...