LLama-Factory使用教程
本文是github项目llama-factory的使用教程
注意,最新的llama-factory的github中训练模型中,涉及到本文中的操作全部使用了.yaml配置。
新的.yaml的方式很简洁但不太直观,本质上是一样的。新的readme中的.yaml文件等于下文中的bash指令
PS: 大模型基础和进阶付费课程(自己讲的):《AIGC大模型理论与工业落地实战》-CSDN学院 或者《AIGC大模型理论与工业落地实战》-网易云课堂。感谢支持!
一,数据准备和模型训练
step1-下载项目:
从github中克隆LLaMa-Factory项目到本地
step2-准备数据:
将原始LLaMA-Factory/data/文件夹下的dataset_info.json,增加本地的数据。注意,本地数据只能改成LLama-Factory接受的形式,即本地数据只能支持”promtp/input/output“这种对话的格式,不支持传统的文本分类/实体抽取/关系抽取等等schema数据,如果需要,请想办法改成对话形式的数据。
你需要参考其中的一个文件和它的配置,例如:alpaca_gpt4_data_zh.json,训练和验证数据同样改成这种格式,并在dataset_info.json中新增一个你自己的字典:
{"alpaca_en": {"file_name": "alpaca_data_en_52k.json","file_sha1": "607f94a7f581341e59685aef32f531095232cf23"
},
..."your_train": {"file_name": "/path/to/your/train.json","columns": {"prompt": "instruction","query": "input","response": "output"}},
... 其中的key,your_train,将在训练/测试的shell命令中使用
step3-模型训练:
数据准备好之后,编写shell脚本训练模型,以mixtral为例根目录下新建run_mixtral.sh
需要改动的主要是:model_name_or_path,dataset,output_dir;和其他可选的改动信息,例如save_steps,per_device_train_batch_size等等。
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \--stage sft \--do_train \--model_name_or_path /path/to/your/Mixtral-8x7B-Instruct-v0.1 \--dataset my_train \--template default \--finetuning_type lora \--lora_target q_proj,v_proj \--output_dir ./output/mixtral_train \--overwrite_output_dir \--overwrite_cache \--per_device_train_batch_size 4 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 200 \--learning_rate 5e-5 \--num_train_epochs 1.0 \--plot_loss \--quantization_bit 4 \--fp16
step4-模型融合
模型融合的意义在于合并训练后的lora权重,保持参数和刚从huggingface中下载的一致,以便更加方便地适配一些推理和部署框架
基本流程/原理:将微调之后的lora参数,融合到原始模型参数中,以mixtral为例新建:LLama-Factory/run_mixtral_fusion.sh:
python src/export_model.py \--model_name_or_path path_to_huggingface_model \--adapter_name_or_path path_to_mixtral_checkpoint \--template default \--finetuning_type lora \--export_dir path_to_your_defined_export_dir \--export_size 2 \--export_legacy_format False
step5-模型推理
模型推理即模型在新的验证集上的推理和验证过程
指令和训练的基本一致,只是差别几个参数:
1.增加了do_predict,2.数据集改成一个新的eval数据集
LLama-Factory/runs/run_mixtral_predict.sh
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \--stage sft \--do_predict \--model_name_or_path /path/to/huggingface/Mixtral-8x7B-Instruct-v0.1 \--adapter_name_or_path /path/to/mixtral_output/checkpoint-200 \--dataset my_eval \--template default \--finetuning_type lora \--output_dir ./output/mixtral_predict \--per_device_eval_batch_size 4 \--predict_with_generate \--quantization_bit 4 \--fp16
step6-API接口部署
部署接口的作用是可以让你把接口开放出去给到外部调用
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 python src/api_demo.py \--model_name_or_path path_to_llama_model \--adapter_name_or_path path_to_checkpoint \--template default \--finetuning_type lora相关文章:

LLama-Factory使用教程
本文是github项目llama-factory的使用教程 注意,最新的llama-factory的github中训练模型中,涉及到本文中的操作全部使用了.yaml配置。 新的.yaml的方式很简洁但不太直观,本质上是一样的。新的readme中的.yaml文件等于下文中的bash指令 PS: …...

Java面试题:讨论在Java Web应用中实现安全的认证和授权机制,如使用Spring Security
在Java Web应用中,实现安全的认证和授权是至关重要的,Spring Security是一个强大的框架,可以简化这项工作。以下是详细讨论如何在Java Web应用中使用Spring Security实现安全的认证和授权机制。 Spring Security简介 Spring Security是一个…...

如何在Vue3项目中使用Pinia进行状态管理
**第一步:安装Pinia依赖** 要在Vue3项目中使用Pinia进行状态管理,首先需要安装Pinia依赖。可以使用以下npm命令进行安装: bash npm install pinia 或者如果你使用的是yarn,可以使用以下命令: bash yarn add pinia *…...

【初阶数据结构】深入解析队列:探索底层逻辑
🔥引言 本篇将深入解析队列:探索底层逻辑,理解底层是如何实现并了解该接口实现的优缺点,以便于我们在编写程序灵活地使用该数据结构。 🌈个人主页:是店小二呀 🌈C语言笔记专栏:C语言笔记 &#…...

Go 语言环境搭建
本篇文章为Go语言环境搭建及下载编译器后配置Git终端方法。 目录 安装GO语言SDK Window环境安装 下载 安装测试 安装编辑器 下载编译器 设置git终端方法 总结 安装GO语言SDK Window环境安装 网站 Go下载 - Go语言中文网 - Golang中文社区 还有 All releases - The…...

javascript v8编译器的使用记录
我的机器是MacOS Mx系列。 一、v8源码下载构建 1.1 下载并更新depot_tools git clone https://chromium.googlesource.com/chromium/tools/depot_tools.git export PATH/path/to/depot_tools:$PATH 失败的话可能是网络问题,可以试一下是否能ping通,连…...
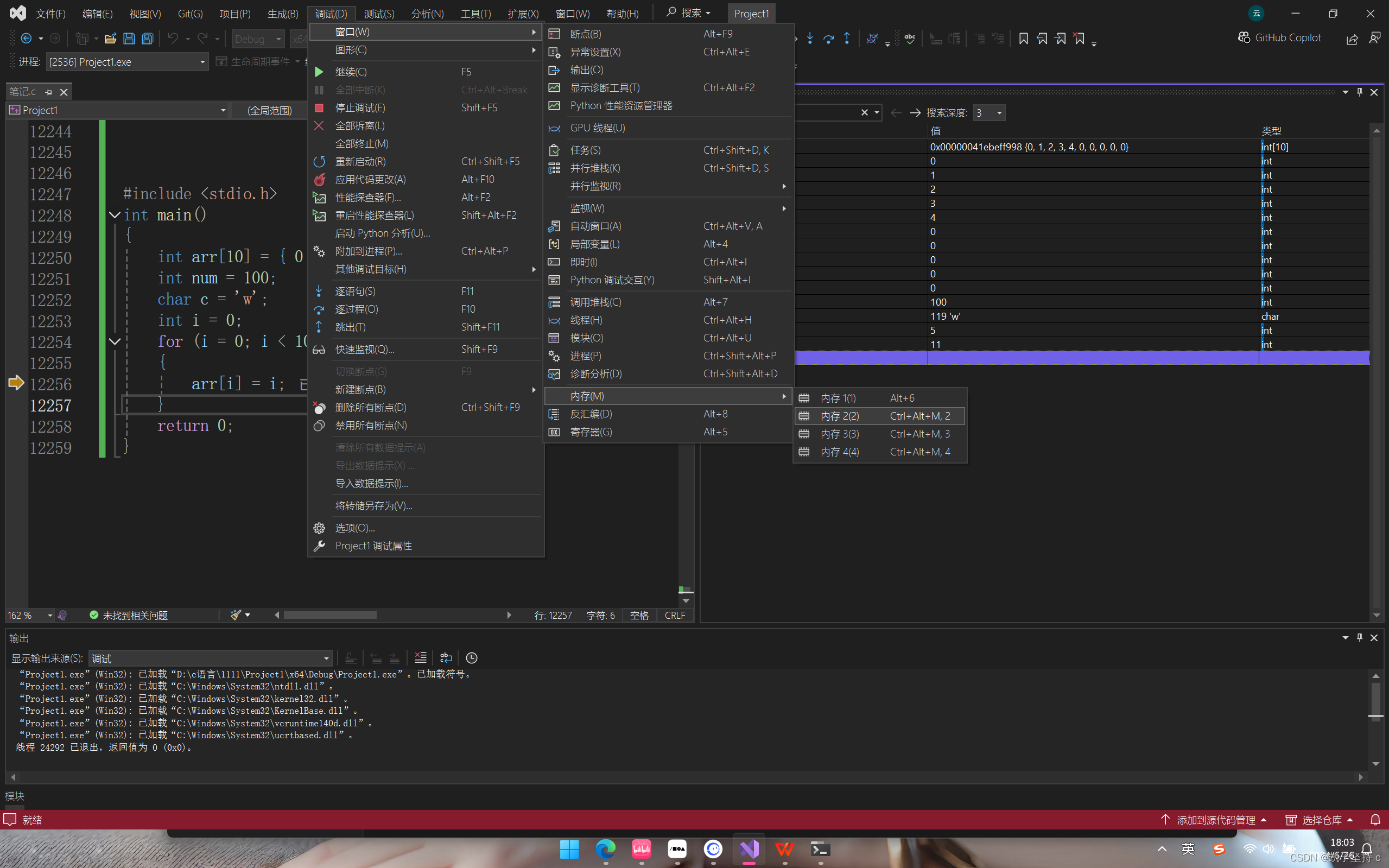
C语言--vs使用调试技巧
1.什么是bug? 1.产品说明书中规定要做的事情,而软件没有实现。 2.产品说明书中规定不要做的事情,而软件确实现了。 3.产品说明书中没有提到过的事情,而软件确实现了。 4.产品说明书中没有提到但是必须要做的事情,软件确没有实…...

Spring Boot中的国际化配置
Spring Boot中的国际化配置 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何在Spring Boot应用中实现国际化配置,使得应用能够轻松…...
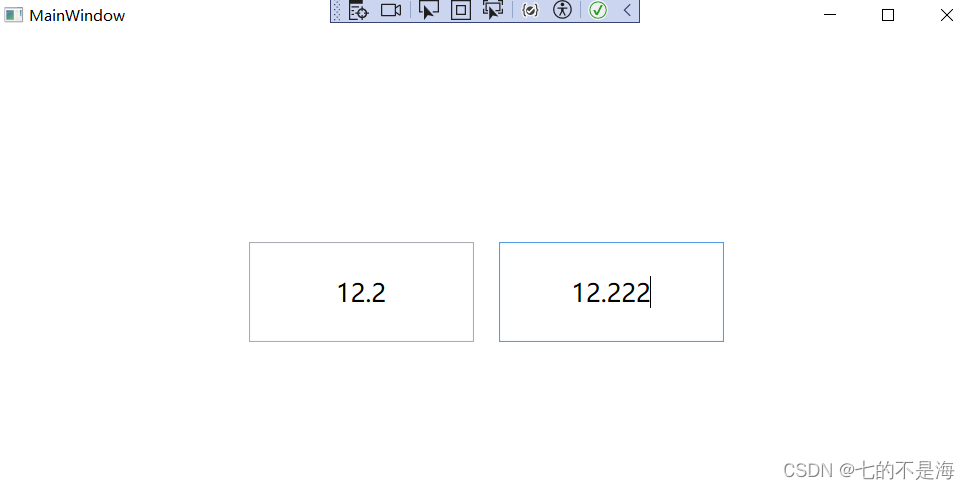
WPF的IValueConverter用于校验和格式化TextBox的数字输入
在数据绑定(Data Binding)的上下文中,我们经常使用继承 IValueConverter 接口的类,用于在源值和目标值之间进行转换。该接口定义了两个方法:Convert 和 ConvertBack,这两个方法分别用于从源值到目标值的转换…...

SQL Server的守护神:Always On 高可用性详解
🛡️ SQL Server的守护神:Always On 高可用性详解 在企业级应用中,数据的可用性和业务连续性至关重要。SQL Server的Always On功能提供了一个高可用性解决方案,确保数据库服务的持续运行和快速故障恢复。本文将详细解释SQL Serve…...

Eureka入门
Eureka是一种服务发现工具,广泛应用于微服务架构中。它主要由Netflix开源,帮助服务在分布式系统中自动注册和发现。以下是Eureka的基本入门指南。 前提条件 在开始之前,确保你已经安装了以下软件: JDK 8或更高版本Maven或Gradl…...

高阶面试-netty部分
介绍下netty Netty 是一个基于 Java 的异步事件驱动的网络应用框架,提供了用于快速开发高性能、高可扩展性的协议服务器和客户端的工具 BIO、NIO、AIO 的区别是什么 BIO blocking io,同步阻塞IO,比较简单,为每个请求分配一个线…...

在 C++的跨平台开发中,如何处理不同操作系统和编译器之间的细微差异,以确保程序能够稳定且高效地运行?
在 C 的跨平台开发中,处理不同操作系统和编译器之间的细微差异是非常重要的。以下是一些处理差异的技巧: 使用条件编译:使用预处理指令,根据不同的操作系统和编译器来编写不同的代码。 #if defined(_WIN32)// Windows 特定代码 …...

独孤思维:脑子不好使,副业稳赚钱
01 副业,贴身级模仿。 比如独孤最近在测试dy虚拟资料项目。 跑了三个多月。 赚了点下小钱。 从最开始的自动生成视频,到后来的抽帧优化,再到先做的矩阵玩法。 一直都在迭代。 是独孤脑子好使吗? 恰恰相反。 正式因为独孤…...
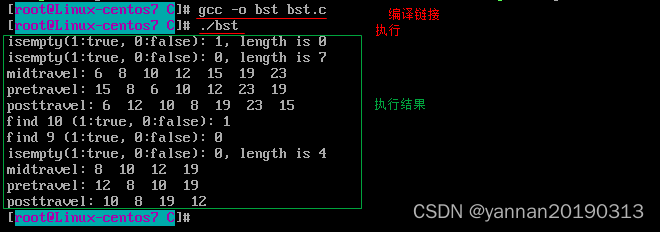
【数据结构】(C语言):二叉搜索树
二叉搜索树: 树不是线性的,是层级结构。基本单位是节点,每个节点最多2个子节点。有序。每个节点,其左子节点都比它小,其右子节点都比它大。每个子树都是一个二叉搜索树。每个节点及其所有子节点形成子树。可以是空树。…...
)
泛微开发修炼之旅--23基于ecology自研的数据库分页组件(分页组件支持mysql、sqlserver、oracle、达梦等)
一、使用场景 ecology二开开发过程中,经常要使用到分页查询,随着信创项目的到来,各种国产数据库的出现,对于数据库分页查询兼容何种数据库,就迫在眉睫。 于是,我自己基于ecology开发了一个分页插件&#…...
《昇思25天学习打卡营第4天 | mindspore Transforms 数据变换常见用法》
1. 背景: 使用 mindspore 学习神经网络,打卡第四天; 2. 训练的内容: 使用 mindspore 的常见的数据变换 Transforms 的使用方法; 3. 常见的用法小节: 支持一系列常用的 Transforms 的操作 3.1 Vision …...
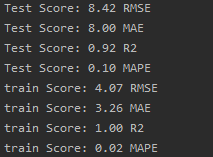
【Python时序预测系列】基于LSTM实现多输入多输出单步预测(案例+源码)
这是我的第312篇原创文章。 一、引言 单站点多变量输入多变量输出单步预测问题----基于LSTM实现。 多输入就是输入多个特征变量 多输出就是同时预测出多个标签的结果 单步就是利用过去N天预测未来1天的结果 二、实现过程 2.1 读取数据集 dfpd.read_csv("data.csv&qu…...
git客户端工具之Github,适用于windows和mac
对于我本人,我已经习惯了使用Github Desktop,不同的公司使用的代码管理平台不一样,就好奇Github Desktop是不是也适用于其他平台,结果是可以的。 一、克隆代码 File --> Clone repository… 选择第三种URL方式,输入url &…...

ai除安卓手机版APP软件一键操作自动渲染去擦消稀缺资源下载
安卓手机版:点击下载 苹果手机版:点击下载 电脑版(支持Mac和Windows):点击下载 一款全新的AI除安卓手机版APP,一键操作,轻松实现自动渲染和去擦消效果,稀缺资源下载 1、一键操作&…...

7-Zip ZS:六大压缩引擎如何让你的文件管理效率提升3倍
7-Zip ZS:六大压缩引擎如何让你的文件管理效率提升3倍 【免费下载链接】7-Zip-zstd 7-Zip with support for Brotli, Fast-LZMA2, Lizard, LZ4, LZ5 and Zstandard 项目地址: https://gitcode.com/gh_mirrors/7z/7-Zip-zstd 在数字时代,我们每天都…...

大模型爆发期!程序员现在转型,还能赶上风口吗?
文章目录前言一、2026年,大模型风口到底有多猛?二、90%的人不敢转型,都是被这3个误区坑了误区1:转大模型必须会高数、会从头训模型误区2:我只会写CRUD,没资格转大模型误区3:现在转已经晚了&…...

终极指南:如何用DroidCam OBS插件将手机变成专业直播摄像头
终极指南:如何用DroidCam OBS插件将手机变成专业直播摄像头 【免费下载链接】droidcam-obs-plugin DroidCam OBS Source 项目地址: https://gitcode.com/gh_mirrors/dr/droidcam-obs-plugin 想要将手机摄像头变成OBS直播的高清视频源吗?DroidCam …...

Windows内核级硬件指纹伪装终极指南:EASY-HWID-SPOOFER深度解析
Windows内核级硬件指纹伪装终极指南:EASY-HWID-SPOOFER深度解析 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在数字隐私日益重要的今天,硬件指纹识别技术…...

网络安全新态势与应对策略
网络安全新态势与应对策略 在数字化浪潮席卷全球的今天,网络空间已成为国家竞争的新战场、经济发展的新引擎和社会生活的新空间。然而,伴随技术飞速发展的,是日益严峻和复杂的网络安全挑战。传统的边界防御模式在AI驱动的自动化攻击、无孔不…...

基于Agentify框架构建AI智能体:从核心原理到实战应用
1. 项目概述:从代码仓库到智能体构建平台最近在开源社区里,一个名为harindukavishka/agentify的项目引起了我的注意。乍一看,这只是一个GitHub上的代码仓库,但当你点进去,深入其文档和代码结构,你会发现它远…...

HX‑01 USB 音频编码模块:全行业通用的稳定音频核心解决方案
HX‑01 USB 音频编码模块凭借免驱即用、高清语音处理、宽温稳定运行、强抗干扰设计、灵活配置模式的核心优势,不仅在矿山行业构建了可靠的语音通讯体系,更能适配安防监控、智能楼宇、教育会议、工业自动化、机器人设备、医疗健康等多行业场景,…...
)
别让电源拖后腿!手把手教你用Sigrity PowerDC搞定PCB直流压降仿真(附HyperLynx SPD转换指南)
电源完整性实战:从零掌握Sigrity PowerDC直流压降仿真全流程 在高速PCB设计中,电源网络的稳定性往往决定了整个系统的可靠性。想象一下这样的场景:一款精心设计的硬件产品在实验室测试时频繁出现异常重启,经过两周的排查最终定位到…...
)
别再猜了!手把手教你识别并解码家里那些“身份不明”的红外遥控器(NEC/RC5/RC6初步判断)
红外遥控器协议侦探指南:快速识别NEC/RC5/RC6编码 家里积攒的旧遥控器越来越多,每个按键背后究竟藏着什么秘密?当你试图用智能家居系统整合这些设备时,第一步往往不是学习信号,而是破解这些"黑盒子"的通信语…...

1 个开发技巧,餐饮小程序加载速度飙升 70%
对于餐饮小程序而言,加载速度直接决定用户留存——据调研,用户打开小程序后,若加载时间超过3秒,流失率会高达80%。很多餐饮门店的小程序,明明功能完善、设计美观,却因为加载缓慢,导致用户刚打开…...