动手学深度学习(Pytorch版)代码实践 -计算机视觉-39实战Kaggle比赛:狗的品种识别(ImageNet Dogs)
39实战Kaggle比赛:狗的品种识别(ImageNet Dogs)
比赛链接:Dog Breed Identification | Kaggle
1.导入包
import torch
from torch import nn
import collections
import math
import os
import shutil
import torchvision
from d2l import torch as d2l
import matplotlib.pyplot as plt
import liliPytorch as lp
2.数据集处理
# 精简数据集
# file_path = '../data/kaggle_dog_tiny/'
# 原数据集
file_path = '../data/dog-breed-identification/'# 整理数据集
# 从原始训练集中拆分验证集,然后将图像移动到按标签分组的子文件夹中。
#@save
def read_csv_labels(fname):"""读取CSV文件中的标签,它返回一个字典,该字典将文件名中不带扩展名的部分映射到其标签"""with open(fname, 'r') as f:# 跳过文件头行(列名)lines = f.readlines()[1:]tokens = [l.rstrip().split(',') for l in lines]return dict(((name, label) for name, label in tokens))# labels = read_csv_labels(os.path.join(file_path, 'labels.csv'))
# print(labels) # {'0097c6242c6f3071762d9f85c3ef1b2f': 'bedlington_terrier', '00a338a92e4e7bf543340dc849230e75': 'dingo'}
# print('训练样本 :', len(labels)) # 训练样本 : 1000
# print('类别 :', len(set(labels.values()))) # 类别 : 120# 定义reorg_train_valid函数来将验证集从原始的训练集中拆分出来
#@save
def copyfile(filename, target_dir):"""将文件复制到目标目录"""os.makedirs(target_dir, exist_ok=True)shutil.copy(filename, target_dir)#@save
def reorg_train_valid(data_dir, labels, valid_ratio):"""将验证集从原始的训练集中拆分出来"""# 训练数据集中样本最少的类别中的样本数n = collections.Counter(labels.values()).most_common()[-1][1]# 验证集中每个类别的样本数n_valid_per_label = max(1, math.floor(n * valid_ratio))label_count = {}for train_file in os.listdir(os.path.join(data_dir, 'train')): # 遍历训练集文件夹中的所有文件。label = labels[train_file.split('.')[0]] # 获取文件名(去掉扩展名)fname = os.path.join(data_dir, 'train', train_file) # 构建完整的文件路径copyfile(fname, os.path.join(data_dir, 'train_valid_test','train_valid', label))if label not in label_count or label_count[label] < n_valid_per_label:copyfile(fname, os.path.join(data_dir, 'train_valid_test','valid', label))label_count[label] = label_count.get(label, 0) + 1else:copyfile(fname, os.path.join(data_dir, 'train_valid_test','train', label))return n_valid_per_label# reorg_test函数用来在预测期间整理测试集
#@save
def reorg_test(data_dir):"""在预测期间整理测试集,以方便读取"""for test_file in os.listdir(os.path.join(data_dir, 'test')):copyfile(os.path.join(data_dir, 'test', test_file),os.path.join(data_dir, 'train_valid_test', 'test','unknown'))def reorg_dog_data(data_dir, valid_ratio):labels = read_csv_labels(os.path.join(data_dir, 'labels.csv'))reorg_train_valid(data_dir, labels, valid_ratio)reorg_test(data_dir)reorg_dog_data(file_path, valid_ratio = 0.1)
3.数据集加载
# 数据图像增广
# 训练
transform_train = torchvision.transforms.Compose([# 随机裁剪图像,所得图像为原始面积的0.08~1之间,高宽比在3/4和4/3之间。# 然后,缩放图像以创建224x224的新图像torchvision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0),ratio=(3.0/4.0, 4.0/3.0)),torchvision.transforms.RandomHorizontalFlip(),# 随机更改亮度,对比度和饱和度torchvision.transforms.ColorJitter(brightness=0.4,contrast=0.4,saturation=0.4),# 添加随机噪声torchvision.transforms.ToTensor(),# 标准化图像的每个通道torchvision.transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])
# 测试
transform_test = torchvision.transforms.Compose([torchvision.transforms.Resize(256),# 从图像中心裁切224x224大小的图片torchvision.transforms.CenterCrop(224),torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])# 读取数据集
# 创建数据集对象
# 通常用于定义数据源及其预处理方法。
train_dataset, train_valid_dataset = [# ImageFolder 创建数据集时,它会遍历指定目录下的所有子文件夹,# 并将每个子文件夹的名称作为一个类别标签。然后,它会按字母顺序给每个类别分配一个索引torchvision.datasets.ImageFolder(os.path.join(file_path, 'train_valid_test', folder),transform=transform_train) for folder in ['train', 'train_valid']]valid_dataset, test_dataset = [torchvision.datasets.ImageFolder(os.path.join(file_path, 'train_valid_test', folder),transform=transform_test) for folder in ['valid', 'test']]# 显示每个类别名称和对应的索引
# print(train_dataset.class_to_idx) 4
# {'affenpinscher': 0, 'afghan_hound': 1, 'african_hunting_dog': 2}batch_size = 128
# 创建数据加载器
# 通常用于训练过程中按批次提供数据,具有更高效的数据加载和处理能力。
train_iter, train_valid_iter = [torch.utils.data.DataLoader(dataset, batch_size, shuffle=True, drop_last=True) for dataset in (train_dataset, train_valid_dataset)]valid_iter = torch.utils.data.DataLoader(valid_dataset, batch_size, shuffle=False,drop_last=True)test_iter = torch.utils.data.DataLoader(test_dataset, batch_size, shuffle=False,drop_last=False)4.预训练模型resnet34
# 用于创建和配置训练模型
def get_net(devices):# 创建一个空的 nn.Sequential 容器finetune_net = nn.Sequential()# 加载预训练的 ResNet-34 模型,并将其特征层(features)部分添加到 finetune_net 中finetune_net.features = torchvision.models.resnet34(pretrained=True)# 定义一个新的输出网络finetune_net.output_new = nn.Sequential(nn.Linear(1000, 256),nn.ReLU(),nn.Linear(256, 120))# 将模型参数分配到指定的设备(如 GPU 或 CPU)finetune_net = finetune_net.to(devices[0])# 冻结预训练的特征层参数,以避免在训练过程中更新这些参数for param in finetune_net.features.parameters():param.requires_grad = False# 返回配置好的模型return finetune_net
5.模型训练
def train_batch(net, X, y, loss, trainer, devices):"""使用多GPU训练一个小批量数据。参数:net: 神经网络模型。X: 输入数据,张量或张量列表。y: 标签数据。loss: 损失函数。trainer: 优化器。devices: GPU设备列表。返回:train_loss_sum: 当前批次的训练损失和。train_acc_sum: 当前批次的训练准确度和。"""# 如果输入数据X是列表类型if isinstance(X, list):# 将列表中的每个张量移动到第一个GPU设备X = [x.to(devices[0]) for x in X]else:X = X.to(devices[0])# 如果X不是列表,直接将X移动到第一个GPU设备y = y.to(devices[0])# 将标签数据y移动到第一个GPU设备net.train() # 设置网络为训练模式trainer.zero_grad()# 梯度清零pred = net(X) # 前向传播,计算预测值l = loss(pred, y) # 计算损失l.sum().backward()# 反向传播,计算梯度trainer.step() # 更新模型参数train_loss_sum = l.sum()# 计算当前批次的总损失train_acc_sum = d2l.accuracy(pred, y)# 计算当前批次的总准确度return train_loss_sum, train_acc_sum# 返回训练损失和与准确度和def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay):trainer = torch.optim.SGD(# net.parameters():返回模型 net 中所有参数。# if param.requires_grad:仅选择那些 requires_grad 为 True 的参数。# 这些参数是需要进行梯度更新的(即未冻结的参数)(param for param in net.parameters()if param.requires_grad), # momentum用于加速 SGD 的收敛速度,通过在更新参数时考虑之前的更新方向,减少震荡# weight_decay权重衰减用于防止过拟合lr=lr,momentum=0.9, weight_decay=wd)# trainer = torch.optim.Adam(net.parameters(), lr=lr,weight_decay=wd)scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)loss = nn.CrossEntropyLoss(reduction="none")num_batches, timer = len(train_iter), d2l.Timer()legend = ['train loss', 'train acc']if valid_iter is not None:legend.append('valid acc')animator = lp.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=legend)net = nn.DataParallel(net, device_ids=devices).to(devices[0])for epoch in range(num_epochs):net.train()metric = lp.Accumulator(3)for i, (features, labels) in enumerate(train_iter):timer.start()l, acc = train_batch(net, features, labels,loss, trainer, devices)metric.add(l, acc, labels.shape[0])timer.stop()# train_l = metric[0] / metric[2] # 计算训练损失# train_acc = metric[1] / metric[2] # 计算训练准确率if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[2],None))if valid_iter is not None:valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)animator.add(epoch + 1, (None, None, valid_acc))scheduler.step()# print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '# f'valid_acc {valid_acc:.3f}')measures = (f'train loss {metric[0] / metric[2]:.3f}, 'f'train acc {metric[1] / metric[2]:.3f}')if valid_iter is not None:measures += f', valid acc {valid_acc:.3f}'print(measures + f'\n{metric[2] * num_epochs / timer.sum():.1f}'f' examples/sec on {str(devices)}')
6.模型预测
def predict(file_path_module):# 预测net = get_net(d2l.try_all_gpus())net.load_state_dict(torch.load(file_path_module + 'imageNet_Dogs.params'))# 初始化一个空列表preds用于存储预测结果preds = []# 遍历测试集中的每一个数据和标签for data, label in test_iter:# 使用神经网络(net)对数据进行预测,并使用softmax函数将输出转化为概率分布output = torch.nn.functional.softmax(net(data.to(devices[0])), dim=1)# 将预测结果从GPU中取出,转换为NumPy数组后,添加到preds列表中preds.extend(output.cpu().detach().numpy())# 获取测试数据文件夹中所有文件的id,并按字典顺序排序ids = sorted(os.listdir(os.path.join(file_path, 'train_valid_test', 'test', 'unknown')))# 打开一个新的CSV文件submission.csv用于写入预测结果with open(file_path + 'submission.csv', 'w') as f:# 写入CSV文件的表头,包含'id'和所有类别标签f.write('id,' + ','.join(train_valid_dataset.classes) + '\n')# 遍历文件id和对应的预测结果for i, output in zip(ids, preds):# 写入每个文件的id和对应的预测概率f.write(i.split('.')[0] + ',' + ','.join([str(num) for num in output]) + '\n')
7.定义超参数并保存训练参数
# 定义模型
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 1e-4, 1e-4
lr_period, lr_decay, net = 10, 0.1, get_net(devices)
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay)
# num_epochs, lr, wd, lr_period, lr_decay = 20, 1e-4, 1e-4, 4, 0.9 (简略数据集)
# train loss 0.750, train acc 0.814, valid acc 0.646
# 647.4 examples/sec on [device(type='cuda', index=0)]# num_epochs, lr, wd, lr_period, lr_decay = 20, 1e-4, 1e-4, 10, 0.1 (原数据集)
# train loss 0.863, train acc 0.759, valid acc 0.844
# 830.8 examples/sec on [device(type='cuda', index=0)]
plt.show()net = get_net(devices)
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period,lr_decay)
# num_epochs, lr, wd, lr_period, lr_decay = 20, 1e-4, 1e-4, 4, 0.9 (简略数据集)
# train loss 0.721, train acc 0.815
# 704.9 examples/sec on [device(type='cuda', index=0)]# num_epochs, lr, wd, lr_period, lr_decay = 20, 1e-4, 1e-4, 10, 0.1 (原数据集)
# train loss 0.865, train acc 0.758
# 845.4 examples/sec on [device(type='cuda', index=0)]plt.show()
# 保存模型参数
file_path_module = '../limuPytorch/module/'
torch.save(net.state_dict(), file_path_module + 'imageNet_Dogs.params')
简略数据集:


原始数据集:


8.预测提交kaggle
predict(file_path_module)

相关文章:
动手学深度学习(Pytorch版)代码实践 -计算机视觉-39实战Kaggle比赛:狗的品种识别(ImageNet Dogs)
39实战Kaggle比赛:狗的品种识别(ImageNet Dogs) 比赛链接:Dog Breed Identification | Kaggle 1.导入包 import torch from torch import nn import collections import math import os import shutil import torchvision from…...

在Linux系统中挂载硬盘
目录 1. 查看硬盘信息 2. 分区硬盘(如果硬盘没有分区) 3. 格式化分区 4. 创建挂载点 5. 挂载分区 6. 验证挂载 7.设置开机自动挂载(可选) 1. 查看硬盘信息 lsblk 这个命令会列出所有的块设备,包括硬盘 2.…...
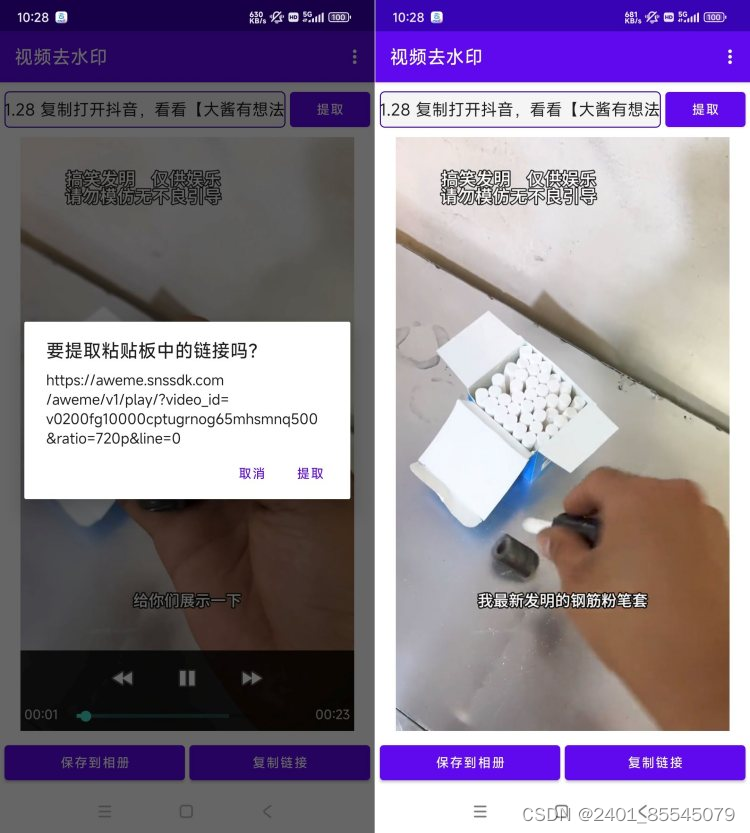
安卓短视频去水印v1.7 简洁好用
各大平台视频无水印提取,登录即永久会员! 无水印提取,图片无水印提取 视频旋转,倒放,转gif等功能。 链接:https://pan.baidu.com/s/1UgO4V16ZM34tG5uDog74Pg?pwdcn0u 提取码:cn0u...
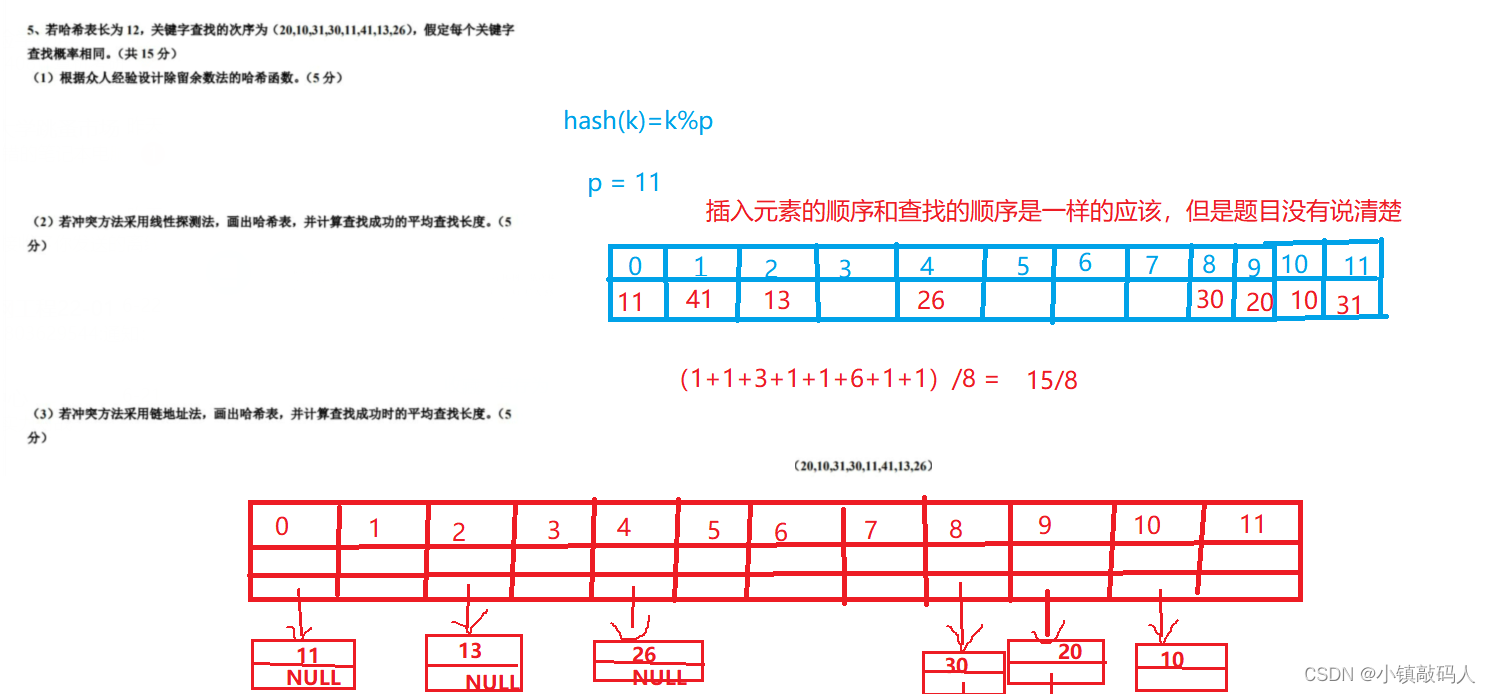
【征服数据结构】:期末通关秘籍
【征服数据结构】:期末通关秘籍 💘 数据结构的基本概念😈 数据结构的基本概念😈 逻辑结构和存储结构的区别和联系😈 算法及其特性😈 简答题 💘 线性表(链表、单链表)&…...

GIT 基于master分支创建hotfix分支的操作
基于master分支创建hotfix分支的操作通常遵循以下步骤: 切换到master分支: 首先,确保你的工作区是最新的,并且你在master分支上。如果不在master分支,你需要先切换过去。 Bash git checkout master 拉取最新的master…...
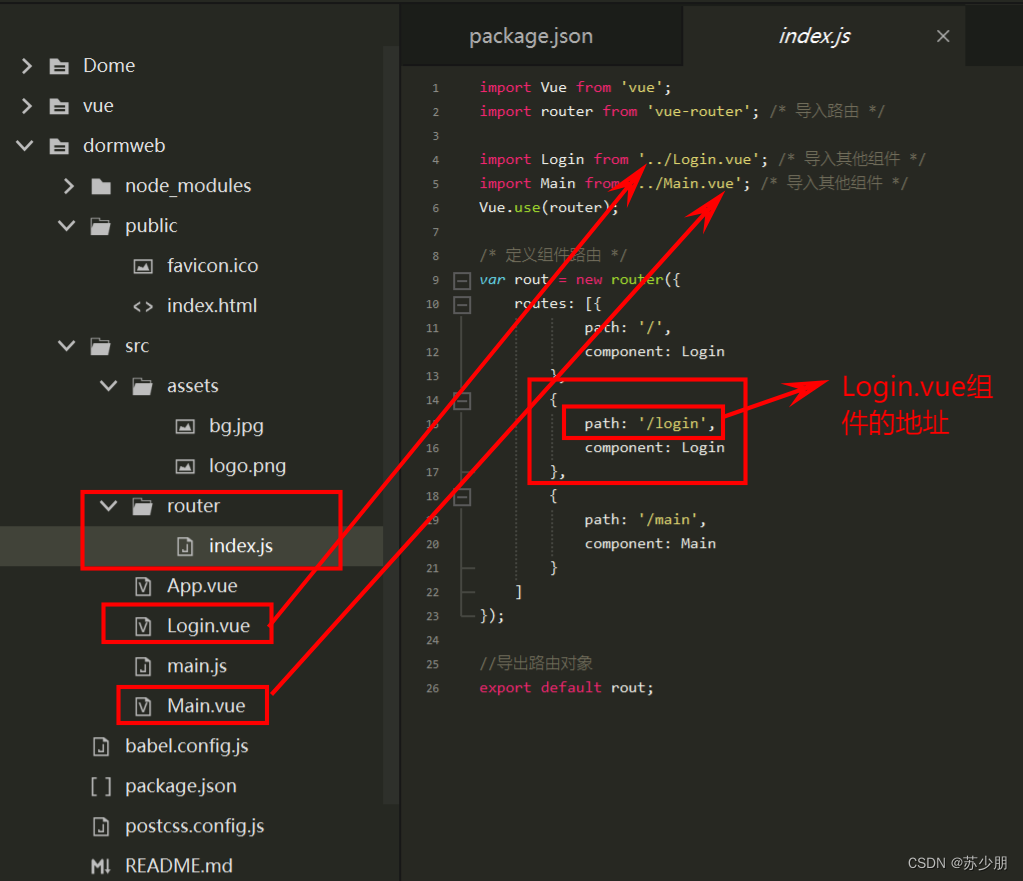
Vue-CLI脚手架与node.js安装
前言: Vue-CLI 是一个基于 Vue.js 快速开发单页应用的官方脚手架工具,能够帮助开发者快速搭建前端项目的基础结构。在开始使用 Vue-CLI 前,首先需要安装 Node.js,因为 Vue-CLI 是基于 Node.js 构建的。 Node.js 是一个基于 Chrom…...
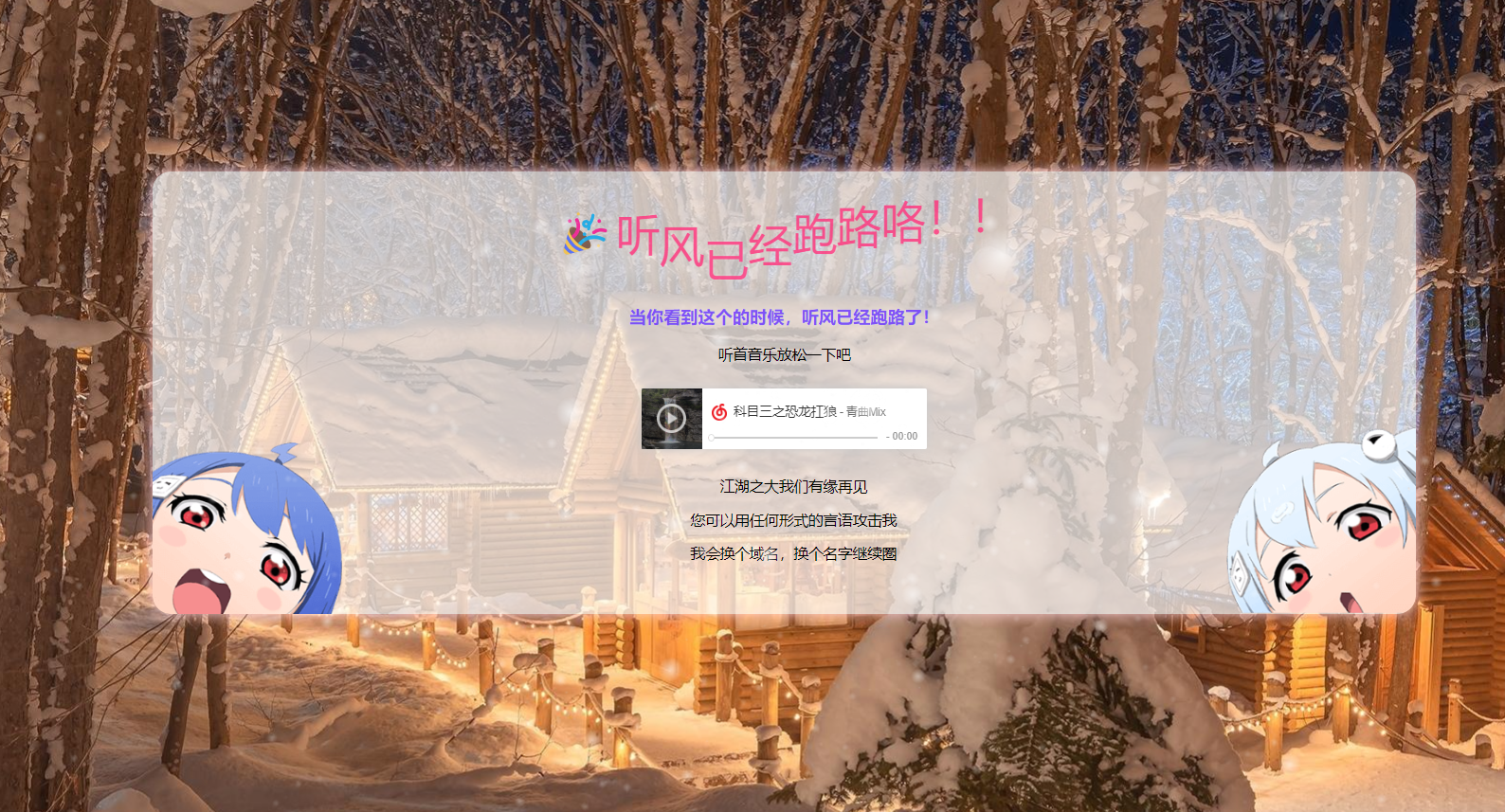
自适应站长跑路单页网站源码
跑路单页HTML源码自行修改文字就行了,上传到服务器里面运行即可,本地运行的话音乐会加载不出来,涉及到跨域问题 自适应站长跑路单页网站源码...

Java基础(判断和循环)
一、流程控制语句-顺序结构 顺序结构语句是Java程序默认的执行流程,按照代码的先后顺序,从上到下依次执行。 二、流程控制语句-分支结构(分支结构包括if、switch) if语句:在程序中用来进行判断 1、If语句的第一种格式…...

51单片机第12步_使用stdio.h库函数仿真串口通讯
本章介绍如何使用stdio.h库函数仿真串口通讯,学会使用view下面的“serial window #1”,实现模拟串口通讯。 Keil C51中有一些关键字,需要牢记: interrupt0:指定当前函数为外部中断0; interrupt1:指定当前函数为定时器0中断&…...

simulink-esp32开发foc电机
1. ESP32 和 STM32 都是流行的微控制器,但它们的刷写方式有所不同。 ESP32 ESP32 可以通过以下几种方式刷写: USB 下载模式:这是最常见的一种刷写方式。将 ESP32 连接到计算机的 USB 端口,然后将 ESP32 置于下载模式。可以使用…...

Python教程--基本技能
】TOC 5.1 解析命令行参数 在Python中,解析命令行参数是一项常见的任务,尤其是在开发命令行工具或脚本时。Python标准库提供了argparse模块,它可以帮助你轻松地编写用户友好的命令行接口。下面是使用argparse模块解析命令行参数的基本步骤&…...
干货分享:Spring中经常使用的工具类(提示开发效率)
环境:Spring5.3…30 1、资源工具类 ResourceUtils将资源位置解析为文件系统中的文件的实用方法。 读取classpath下文件 File file ResourceUtils.getFile(ResourceUtils.CLASSPATH_URL_PREFIX "logback.xml") ; // ...读取文件系统文件 file Resou…...
一文讲懂npm link
前言 在本地开发npm模块的时候,我们可以使用npm link命令,将npm 模块链接到对应的运行项目中去,方便地对模块进行调试和测试 用法 包链接是一个两步过程: 1.为依赖项创建全局软链npm link。一个符号链接,简称软链&a…...
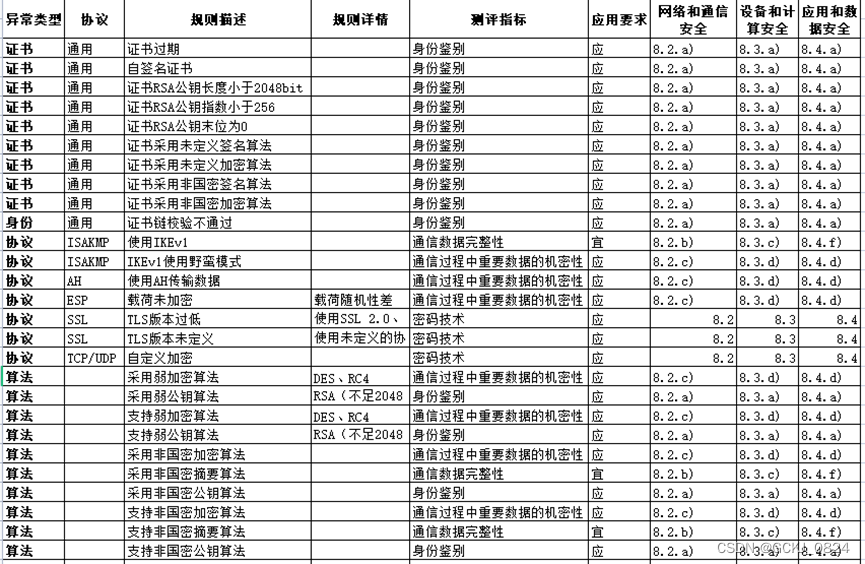
观成科技:证券行业加密业务安全风险监测与防御技术研究
摘要:解决证券⾏业加密流量威胁问题、加密流量中的应⽤⻛险问题,对若⼲证券⾏业的实际流量内容进⾏调研分析, 分析了证券⾏业加密流量⾯临的合规性⻛险和加密协议及证书本⾝存在的⻛险、以及可能存在的外部加密流量威 胁,并提出防…...

使用Swoole开发高性能的Web爬虫
使用swoole开发高性能的web爬虫 Web爬虫是一种自动化获取网络数据的工具,它可以在互联网上收集数据,并且可以被应用于各种不同的领域,如搜索引擎、数据分析、竞争对手分析等。随着互联网规模和数据量的快速增长,如何开发一个高性…...

【Elasticsearch】Elasticsearch索引创建与管理详解
文章目录 📑引言一、Elasticsearch 索引的基础概念二、创建索引2.1 使用默认设置创建索引2.2 自定义设置创建索引2.3 创建索引并设置映射 三、索引模板3.1 创建索引模板3.2 使用索引模板创建索引 四、管理索引4.1 查看索引4.2 更新索引设置4.3 删除索引 五、索引别名…...

[数据集][目标检测]棉花检测数据集VOC+YOLO格式389张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):389 标注数量(xml文件个数):389 标注数量(txt文件个数):389 标注类别…...

使用Java实现实时数据处理系统
使用Java实现实时数据处理系统 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 引言 在当今信息爆炸的时代,实时数据处理系统变得越来越重要。无论…...

整合web-socket的常见bug
整合文章连接 此文是记录我上网查找整合方案时候踩的坑,特别是注册失败的问题,比如还有什么去掉Compoent就可以,但是这样这个端点就失效了 特别是报错: at org.springframework.web.socket.server.standard.ServerEndpointExporter.registerEndpoint(ServerEndpointExporter.…...

Python 中字符串的常用操作都有哪些?
在 Python 中字符串的表达方式有四种 一对单引号 一对双引号 一对三个单引号 一对三个双引号 a ‘abc’ b “abc” c ‘’‘abc’’’ d “”“abc”"" print(type(a)) # <class ‘str’> print(type(b)) # <class ‘str’> print(type©) # <…...

Kafka Connect集群部署踩坑实录:从单机到高可用的完整配置与监控方案
Kafka Connect生产级部署实战:高可用架构设计与监控体系构建 当数据管道成为企业核心基础设施时,Kafka Connect的稳定性直接关系到业务连续性。去年某电商大促期间,因单点故障导致数据同步延迟6小时的教训仍历历在目——这正是我们需要深入探…...

等压雨幕原理在铝合金窗的应用
等压雨幕原理在铝合金窗的应用 摘要: 针对常见的样窗水密气密不达标,首先概述等压雨幕的作用原理,然后介绍其在铝合金门窗应用中的代表性细节。可以看出,控制框扇搭接处的间隙很重要,以及密封胶条合理设计选用的重要性。而且日系推拉采用等压设计的方式很值得借鉴。 关键…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导?
NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导? 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: ht…...

基于轨道模型构建现代化流程编排系统:从概念到实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫s4kuraN4gi/orbit-app。乍一看这个仓库名,可能很多人会有点懵,不知道它具体是做什么的。我花了一些时间深入研究,发现这是一个围绕“轨道”概念构建的现代化应用。这…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

【Canvas动画录制实战】从WebM到MP4:MediaRecorder全流程解析与避坑指南
1. Canvas动画录制基础与准备工作 如果你正在开发一个数据可视化项目或者HTML5小游戏,可能会遇到需要将动态内容保存为视频的需求。Canvas动画录制就是解决这个问题的关键技术方案。相比传统的录屏软件,直接通过代码录制能获得更清晰的画质,还…...

面向开发者的轻量级计划管理工具:配置驱动与命令行优先
1. 项目概述:一个为开发者而生的计划管理工具在软件开发的世界里,我们每天都在与各种“计划”打交道:版本迭代计划、个人学习计划、项目里程碑、甚至是每日的待办清单。然而,一个尴尬的现实是,市面上大多数项目管理工具…...

Claude API钩子框架设计:非侵入式中间件与生命周期管理实践
1. 项目概述与核心价值最近在折腾一些AI应用开发,发现一个挺有意思的现象:很多开发者想给Claude API的调用过程加点“料”,比如在请求发出前或收到响应后,自动执行一些自定义逻辑。可能是为了日志记录、数据清洗、请求重试&#x…...

React轻量级代码编辑器组件:基于Textarea的语法高亮方案
1. 项目概述:一个为React开发者量身打造的代码编辑器组件 如果你在React项目中需要嵌入一个代码编辑器,并且希望它轻量、美观、开箱即用,那么 uiwjs/react-textarea-code-editor 这个组件库很可能就是你一直在寻找的解决方案。它不是一个像…...