PDF 生成(5)— 内容页支持由多页面组成
当学习成为了习惯,知识也就变成了常识。 感谢各位的 关注、点赞、收藏和评论。
新视频和文章会第一时间在微信公众号发送,欢迎关注:李永宁lyn
文章已收录到 github 仓库 liyongning/blog,欢迎 Watch 和 Star。
回顾
在本篇开始之前,我们先来回顾一下上篇 PDF 生成(4)— 目录页 的内容:
- 开头,我们通过
page.evaluate方法为浏览器注入 JS 代码,通过这段 JS 在 PDF 内容页的开始位置(body 的第一个子元素)插入由 a 标签和对应的样式组成的目录页 DOM,从而通过 HTML 锚点实现目录项的页面跳转能力 - 接下来,我们通过为目录页的容器元素设置
break-after: page样式实现目录页自成一页的效果(和内容页分别两页) - 然后剩下的所有篇幅都是在讲如何生成带有准确页码的目录项
- 首先,页码是按照锚点元素在页面中的高度 / PDF 一页的高度来计算的
- 后来,我们通过下面三步来保证目录页中目录项对应页码的准确性
- 规范化设计稿尺寸(按照 A4 纸对应的 2 倍图尺寸设计)
- 通过页面缩放解决设计稿 DPI 和实际生成 PDF 时 DPI 的差异问题(彻底统一计算时 PDF 一页的像素高度)
- 通过页面高度补充的方案解决章节标题换页引起目录项页码计算错误的问题
上篇结束之后,PDF 文件的整体框架已完全成型,包括封面、目录页、内容页和尾页四部分。但系列还没结束,接下来我们会通过本文来提升接入方的使用体验和前端代码可维护性。
开始之前,上篇给大家留了一个问题:回顾一下现在 PDF 文件内容页的生成,站在接入方的角度看,是否存在问题?假设一个场景,接入方的 PDF 文件呈现的内容量非常大,比如拥有几十甚至几百页的内容,那接入方的这个前端页面的代码该怎么维护?页面性能又该怎么保证呢?
简介
本系列的 PDF 生成(1)— 开篇、PDF 生成(2)— 生成 PDF 文件、PDF 生成(3)— 封面、尾页、PDF 生成(4)— 目录页 都是在一步步完善 PDF 文件的整体框架,包括封面、目录页、内容页和尾页四部分,截止上篇,PDF 文件的整体框架已完全成型。
本篇是站在用户角度(接入方)来进行的一次技术迭代。目的是为了解决用户前端代码的可维护性问题。
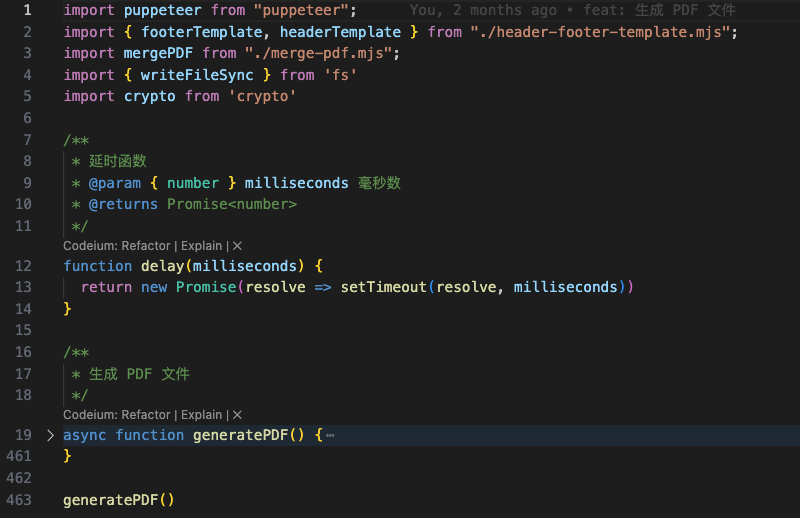
问题
问题 1:到目前为止,我们的 PDF 文件内容页是怎么生成的?
答:关键代码之一 await page.goto('https://content.cn', { waitUntil: ['load', 'networkidle0'] }),也就是说,PDF 文件的内部部分都是由该链接背后的前端页面提供的。
问题 2:如果一份 PDF 文件由几十、几百页组成,其中包含几十个模块,这份 PDF 背后的前端页面的代码该怎么维护?页面性能怎么保障?
答:首先,这么庞大的一个页面的前端代码,基本上是非常难维护的;至于性能问题,可以通过滚动懒加载的方案来解决,但这个优化本来是没必要的,完全是由于现有的 PDF 生成服务能力不足导致的。
分析
我们在做架构设计时,不论是一个系统,还是一个项目,亦或是一个页面甚至一个组件一个方法,都会尽量去避免模块过于复杂,导致难以维护,所以为了更好的可维护性,会尽量将内容进行拆分,比如微服务、组件化。
一个包含几十个模块的页面,不论你怎么去组件化,都避免不了这个页面的庞大,做的再极致,一个由几十个组件组成的页面都是难以维护的,而且如果不做滚动懒加载,这个页面首屏的性能会非常差。当下我们的用户就面临这样的问题,因为我们的 PDF 内容页必须是由一个前端页面构成。
所以,就在想,怎么才能让我们的用户不这么难受呢?开发 PDF 需求,就像开发普通的 Web 项目一样(这句话我们 PDF 生成(1)— 开篇 的技术选型中就提过),代码可以按照业务逻辑进行合理的划分,而不是全部模块堆叠在一个页面上。
其实,经过上面的问题和分析之后,解决方向很明确:PDF 生成服务不应该限制用户对于项目的设计和编码,所以,PDF 的内容页应该支持多页面。但怎么支持呢?
方案限制
- puppeteer 生成 PDF 文件,只能是一个页面对应一份 PDF 文件,这是最底层的限制。
page.goto和page.pdf都是针对当前页面的(浏览器的打印功能,只能打印当前渲染的页面) - 目录页方案的限制
- 页面跳转能力是基于 HTML 锚点实现的,意味着相关 DOM 必须在一个页面中
- 目录项对应的页码是通过 DOM 节点在页面中的位置(高度)来计算的,所以如果 DOM 位于不同的页面就意味着没办法计算了
这两个既是限制,也是进一步迭代的大前提。也就是说,我们现有的能力(大框架)不能动,也没办法动。PDF 内容页必须只能对应一个前端页面,至少在 puppeteer 层面是这样的。
怎么做?
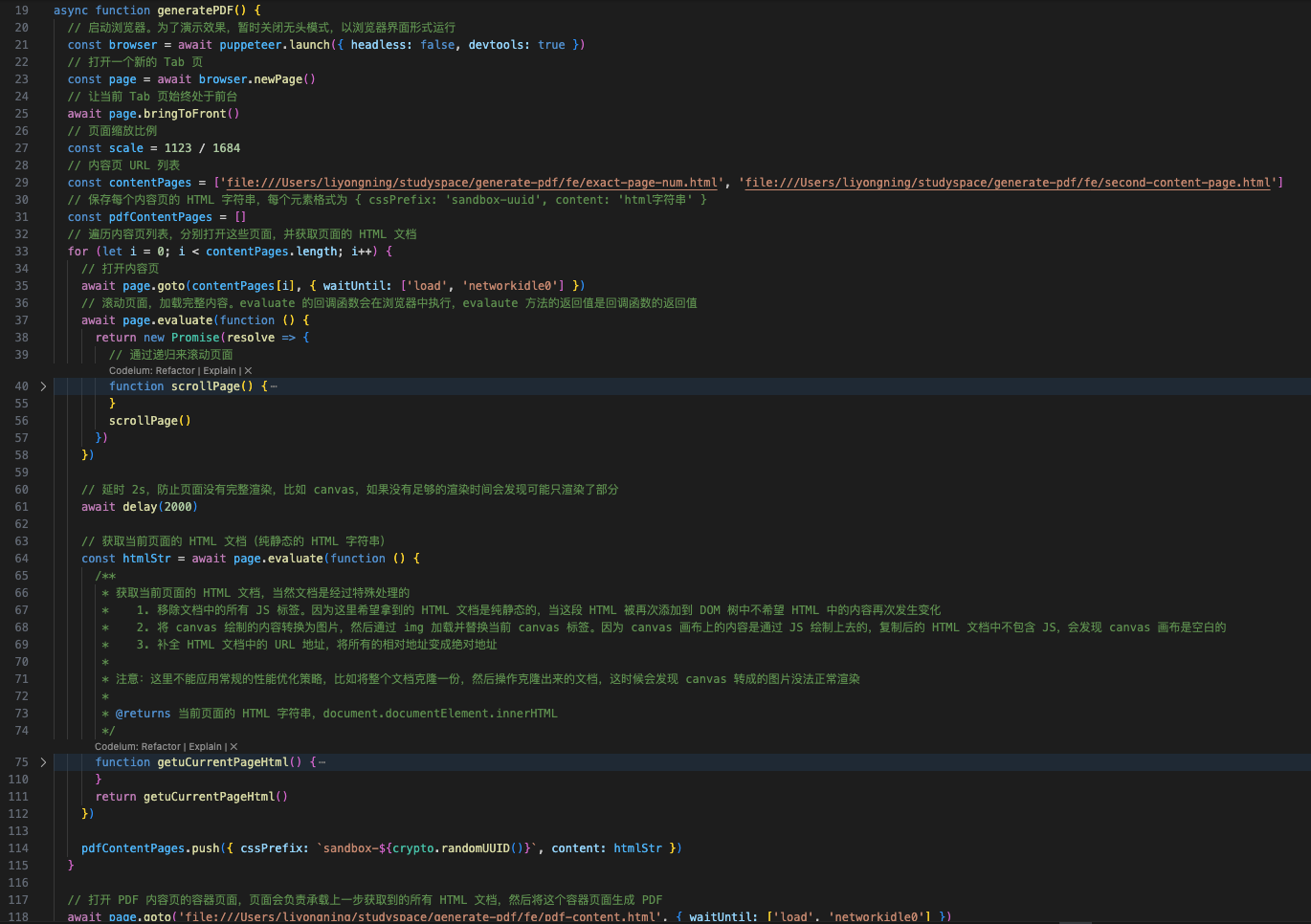
PDF 生成服务是基于 puppeteer 来实现的,也就是说 puppeteer 和用户之间还隔着一个 PDF 生成服务。那如果在 PDF 生成服务上增加一个胶水层呢?即 PDF 生成服务将用户提供的众多内容页合并成一个,然后将合并后的页面提供给 puppeteer。这是在现有技术架构上做加法,完全不影响现有技术方案和效果。
简单来讲就是:
- 首先,通过 page.goto 方法依次打开用户提供的众多内容页,并拿到这些内容页的 HTML 信息
- 然后,通过 page.gogo 打开 PDF 生成服务提供的容器页面,将上一步拿到的所有 HTML 信息都填充到该容器页中
- 最后,通过 page.pdf 方法打印填充后的容器页得到 PDF 内容页
这方案可行,但有问题,这就遇到了整套方案中第二个难点了。
难点(问题)
问题:我们将用户提供的所有页面的 HTML 都塞到了一个页面中渲染,怎么解决可能会出现的样式和 JS 冲突?
答:首先,冲突问题很有可能会出现,用户有义务保证自己的页面内部不出现冲突,但她没有义务确保不同的页面不出现冲突。解决问题的关键是沙箱,PDF 生成服务需要提供一套沙箱来确保容器页中各个页面的隔离性。
沙箱
浏览器中的沙箱包括样式沙箱和 JS 沙箱,实现沙箱方式一般有以下几种:
- JS 沙箱
- iframe
- 代理,比如微前端框架 qiankun 的 JS 沙箱实现方案之一就是 Proxy
- 样式沙箱
- iframe
- Web Component,通过 shadow dom 将不同页面的 HTML 和 CSS 包裹起来,以实现和外部环境的隔离
- scoped,比如 Vue 组件中的 scoped 属性,qiankun 的样式沙箱方案之一
JS 沙箱
首先,我们不需要 JS 沙箱,因为我们获取的是已经渲染好的 HTML 页面,所以会剔除掉 script 标签(打印成 PDF 文件也用不上 JS),JS 的存在反而会带来不确定性和复杂性。
样式沙箱
iframe 最简单,但浏览器的 Web 安全策略会导致我们计算页码时存在问题,因为,跨域场景下没办法操作 iframe 中的 DOM。
Web Component,其整体实现思路是:
- 利用 Web Component 的隔离特性作为各个页面的容器,来实现页面的样式隔离
- 通过 JS 给目录项增加点击事件,借用 JS 的能力取到 Web Component 内的目标节点,通过 scrollIntoView 滚动到对应的位置
- 最后,在容器页面中,拼接目录、各个页面对应的 Web Component 组件。
这套方案在浏览器场景中没有任何问题,而且也比较简单,但生成 PDF 就有问题了,因为生成 PDF 文件后,JS 的能力就丢了,之前的目录跳转是依靠原生的 HTML 锚点能力,现在有了 Web Component 的隔离,a 标签的 href 就取不到 Web Component 内部的元素了。但是,Web Component 实在是一个不错的样式沙箱方案,其实现思路如下,以后有机会可以在浏览器中使用:
/*** 生成 PDF 内容页* @param { Array<htmlElStr> } htmlElList */
function generatePdfContent(htmlElList) {// 定义 Web Component,用来承载 PDF 内容class PDFContent extends HTMLElement {constructor() {super()this.shadow = this.attachShadow({ mode: 'open' })}connectedCallback() {const htmlStr = this.getAttribute('html-content')this.shadow.innerHTML = htmlStr}}customElements.define('pdf-content', PDFContent)// 向 页面内 添加 pdf-content 组件const fragment = document.createDocumentFragment()for (let i = 0; i < htmlElList.length; i++) {const pdfContentEl = document.createElement('pdf-content')pdfContentEl.setAttribute('html-content', htmlElList[i])fragment.appendChild(pdfContentEl)}document.body.appendChild(fragment)
} Ï/*** 为目录设置锚点。这里的锚点跳转是通过 JS 的 scrollIntoView 来实现的*/
function setAnchorPointForDir() {// 获取目录页所有的 a 标签const links = document.querySelectorAll('.pdf-directory__wrapper a')links.forEach(link => {// 为每个目录项添加点击事件link.addEventListener('click', function (e) {// 阻止元素的默认行为 —— a 标签的链接跳转行为e.preventDefault()// 获取被点击目录项的 href 属性,是一个 id 选择器,比如: #xxconst targetId = link.getAttribute('href')// 找到页面上所有的 pdf-content 元素,这些元素是 web componentconst pdfContentComps = document.querySelectorAll('pdf-content')// 遍历这些 web component,从 web component 里查找对应的元素(目录上的 id 选择器),找到后将目标元素滚动到屏幕中间for (let i = 0, len = pdfContentComps.length; i < len; i++) {const targetElement = pdfContentComps[i].shadowRoot.querySelector(targetId)if (targetElement) {targetElement.scrollIntoView({ behavior: 'smooth' })break;}}})})
}
所以,样式沙箱,就只剩方案三 —— Scoped,这里我们借鉴 qiankun 的实验性样式隔离方案,以页面为维度,为页面中的所有样式规则增加一个特殊的选择器来限定其影响范围,因此改写后的样式会变成如下结构:
/* 原始样式 */
.app-main {font-size: 14px;color: #EFEFEF;
}/* 改写后的样式 */
.sandbox-cae17ae7-ad3a-7269-b9a0-07da189346a7 .app-main {font-size: 14px;color: #EFEFEF;
}
到这里,整个方案分析就结束了,接下来就进入实操阶段。
实战
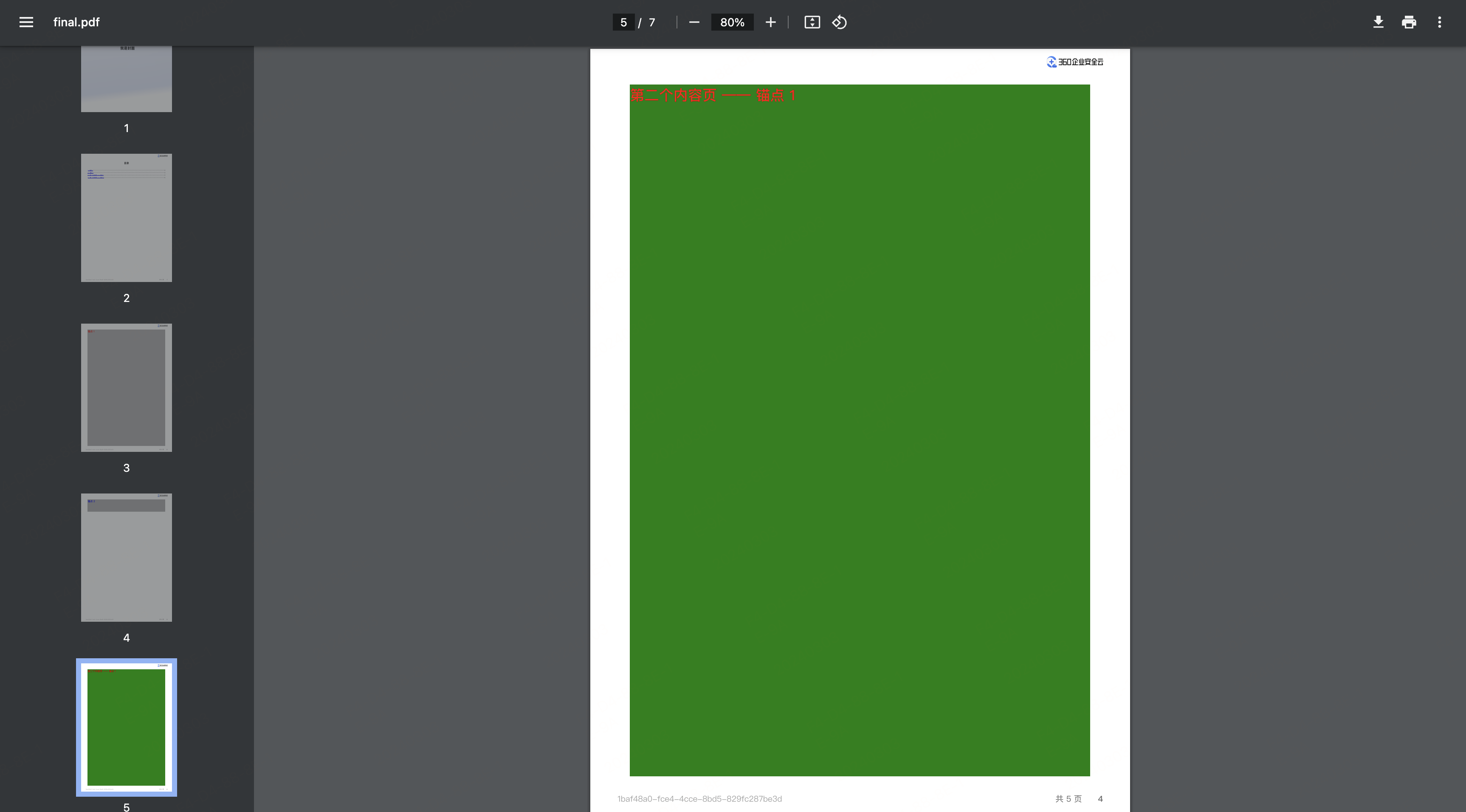
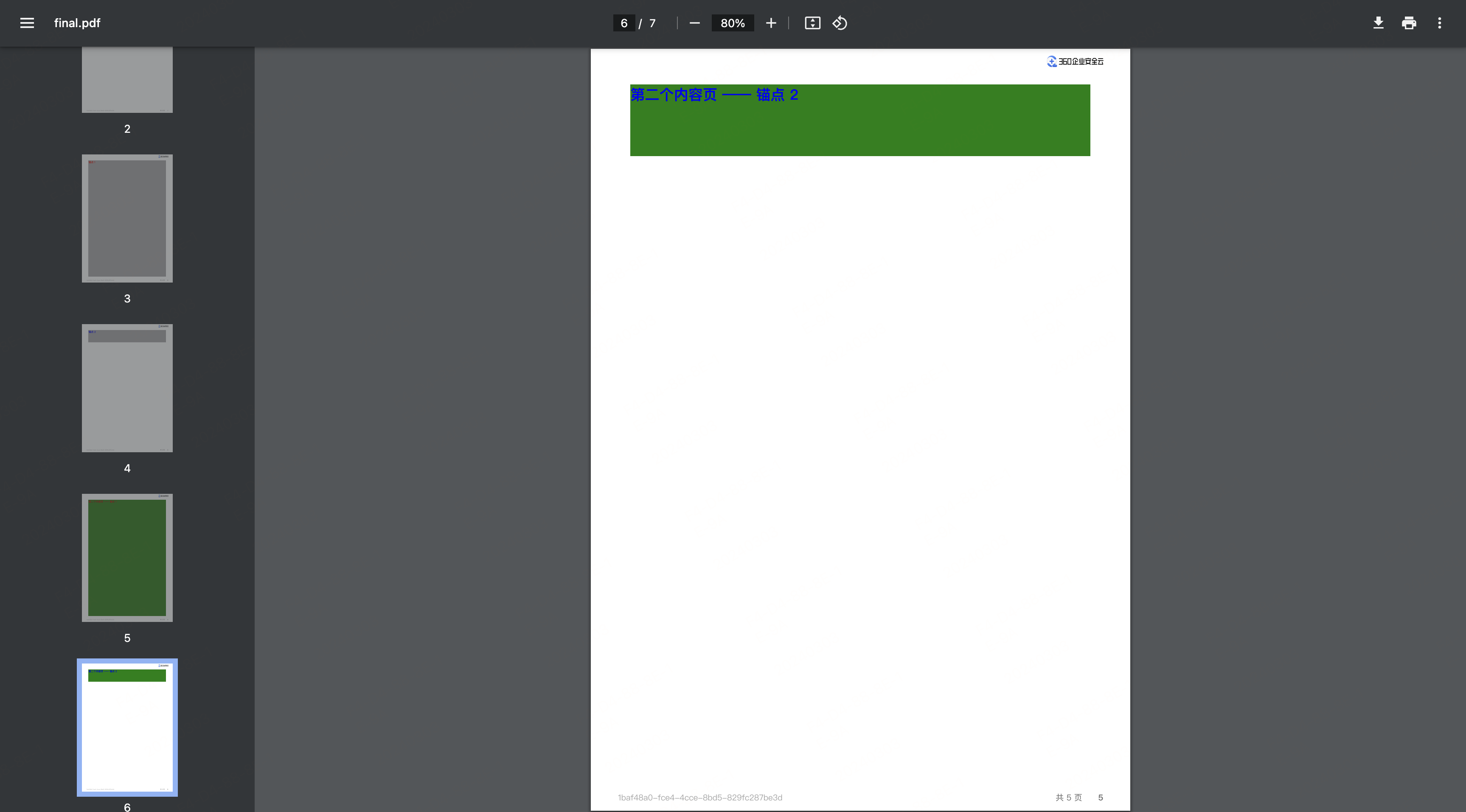
- 新建第二个内容页 /fe/second-content-page.html,并制造和第一个内容页的样式冲突(body 选择器)
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>第二个内容页</title><style>* {margin: 0;padding: 0;}body {width: 100%;height: 1684px;/* 和 exact-page-num.html 的背景色不一样,但都是样式选择器都是 body */background-color: green;}.anchor-wrapper1 {width: 100%;height: 1400px;}#second-content-page-anchor1 {color: red;break-before: page;}#second-content-page-anchor2 {color: blue;break-before: page;}</style>
</head>
<body><div class="anchor-wrapper1"><h1 id="second-content-page-anchor1">第二个内容页 —— 锚点 1</h1></div><div class="anchor-wrapper2"><h1 id="second-content-page-anchor2">第二个内容页 —— 锚点 2</h1></div>
</body>
</html>
- 新建 PDF 内容页的容器页面 /fe/pdf-content.html,来承载目录和众多 PDF 内容页的 HTML + CSS
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>PDF 生成服务</title><meta name="description" content="PDF 内容页的容器页面,内容全部由 PDF 生成服务中的 JS 动态添加,由 目录 和 众多 PDF 内容页组成">
</head>
<body>
</body>
</html>
- 改动 /server/index.mjs,由于代码量太大,就不像之前一样贴详细的改动逻辑了,以主流程为主,另外为了方便演示,相关代码都放在了一个文件中,没有进一步模块化,详细代码大家可以通过 github 访问,顺便 Star 一下呗
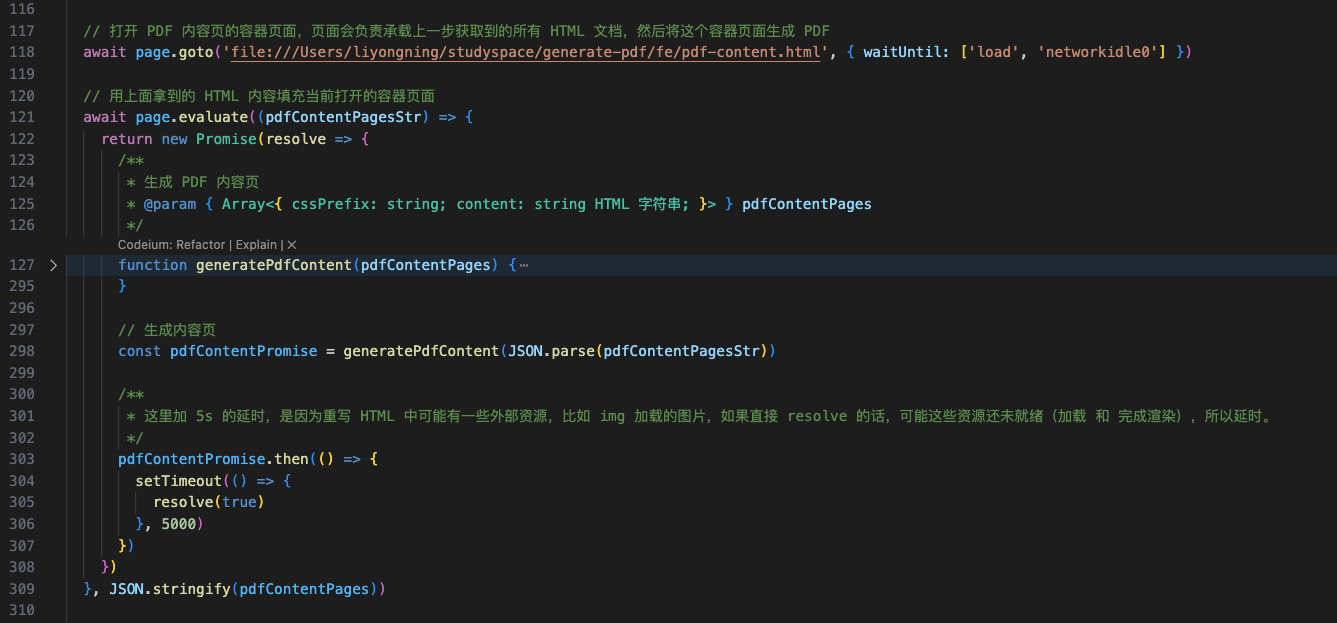
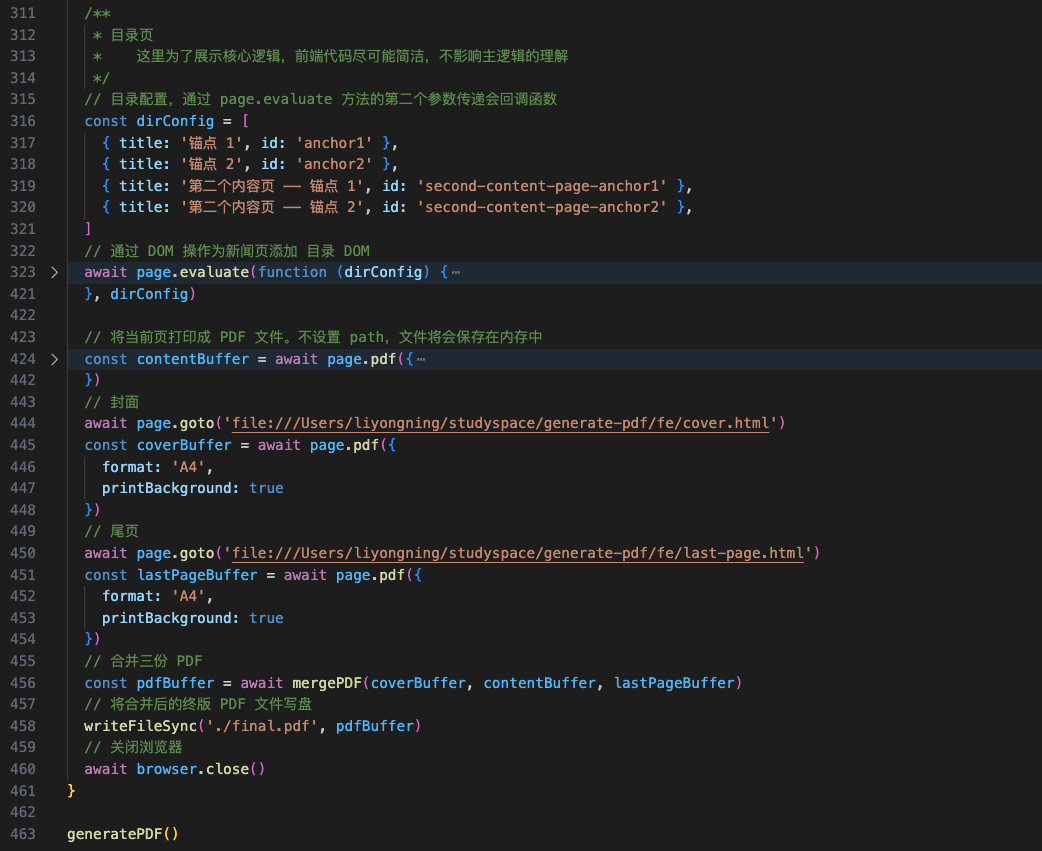
PDF 内容页生成过程如下,特别是最后多页面合并后的效果(目录、页面 1 和 页面 2)
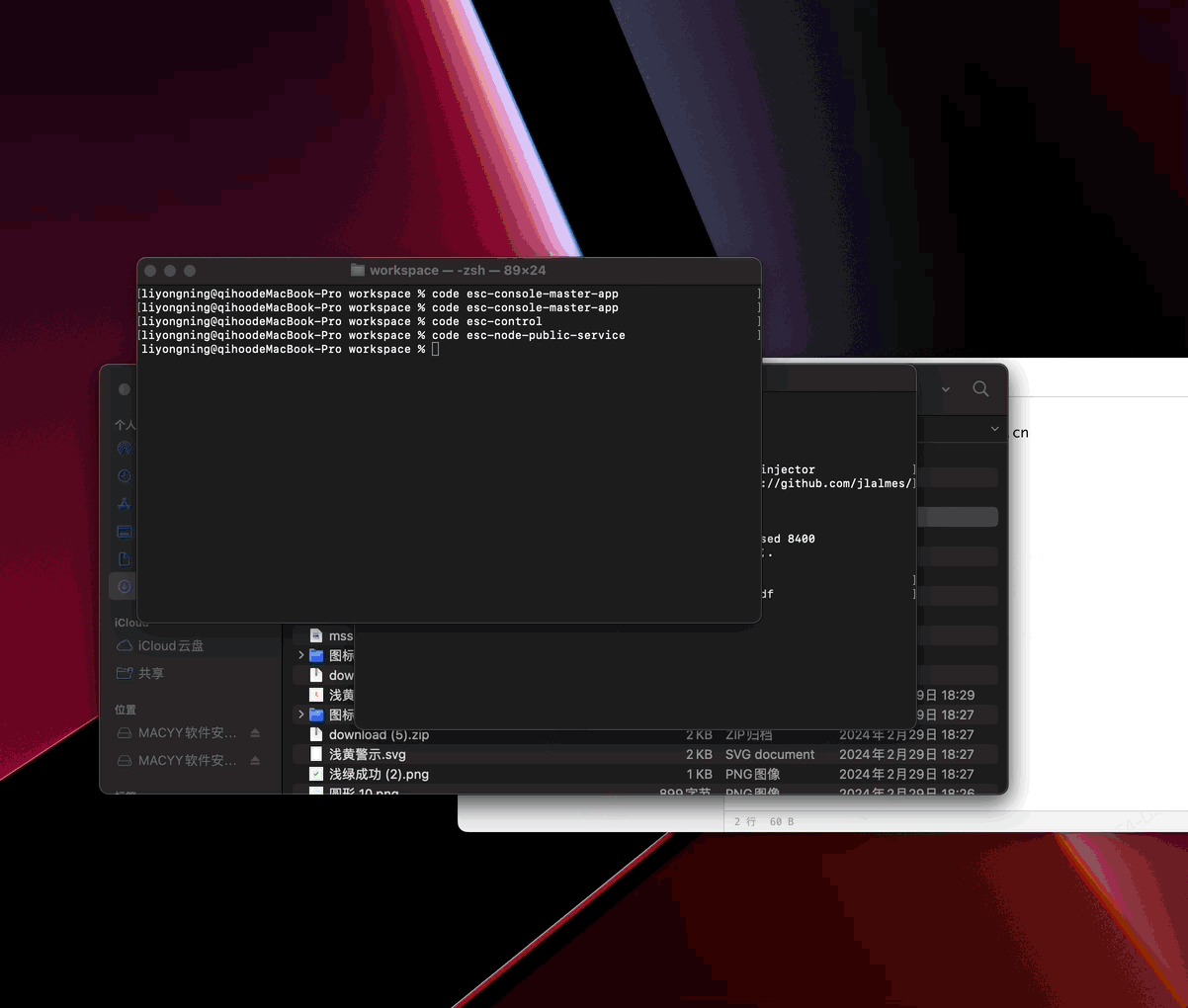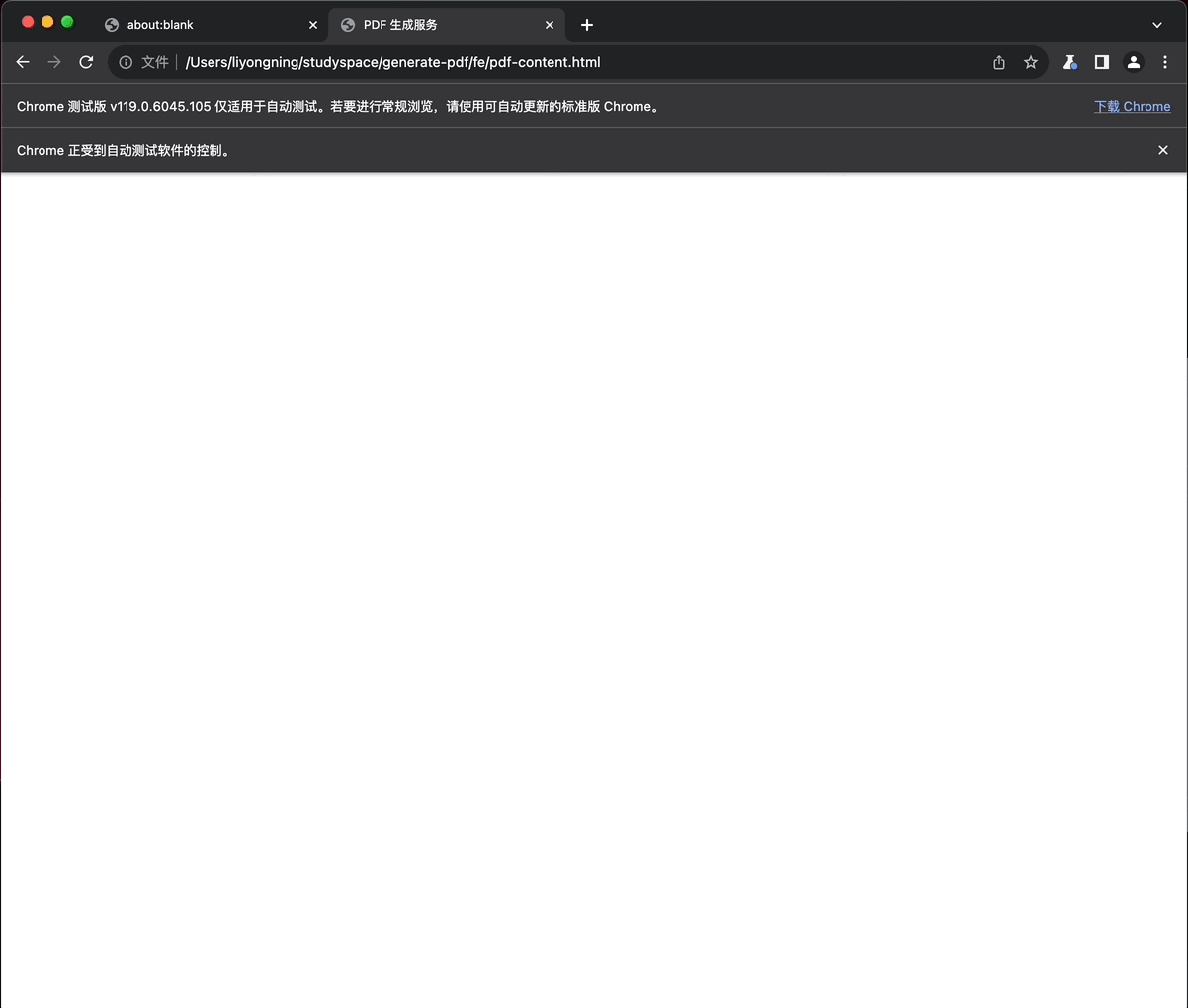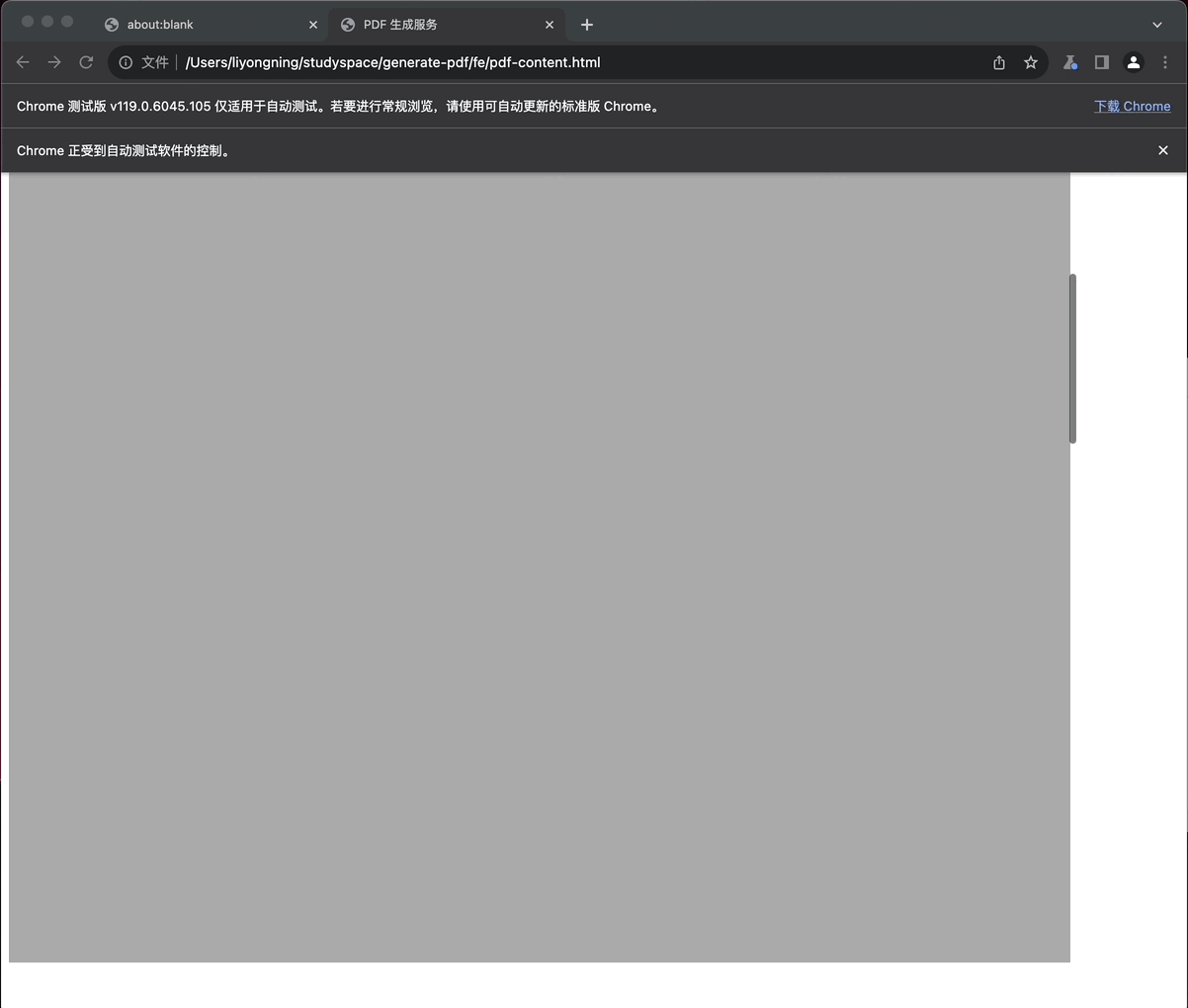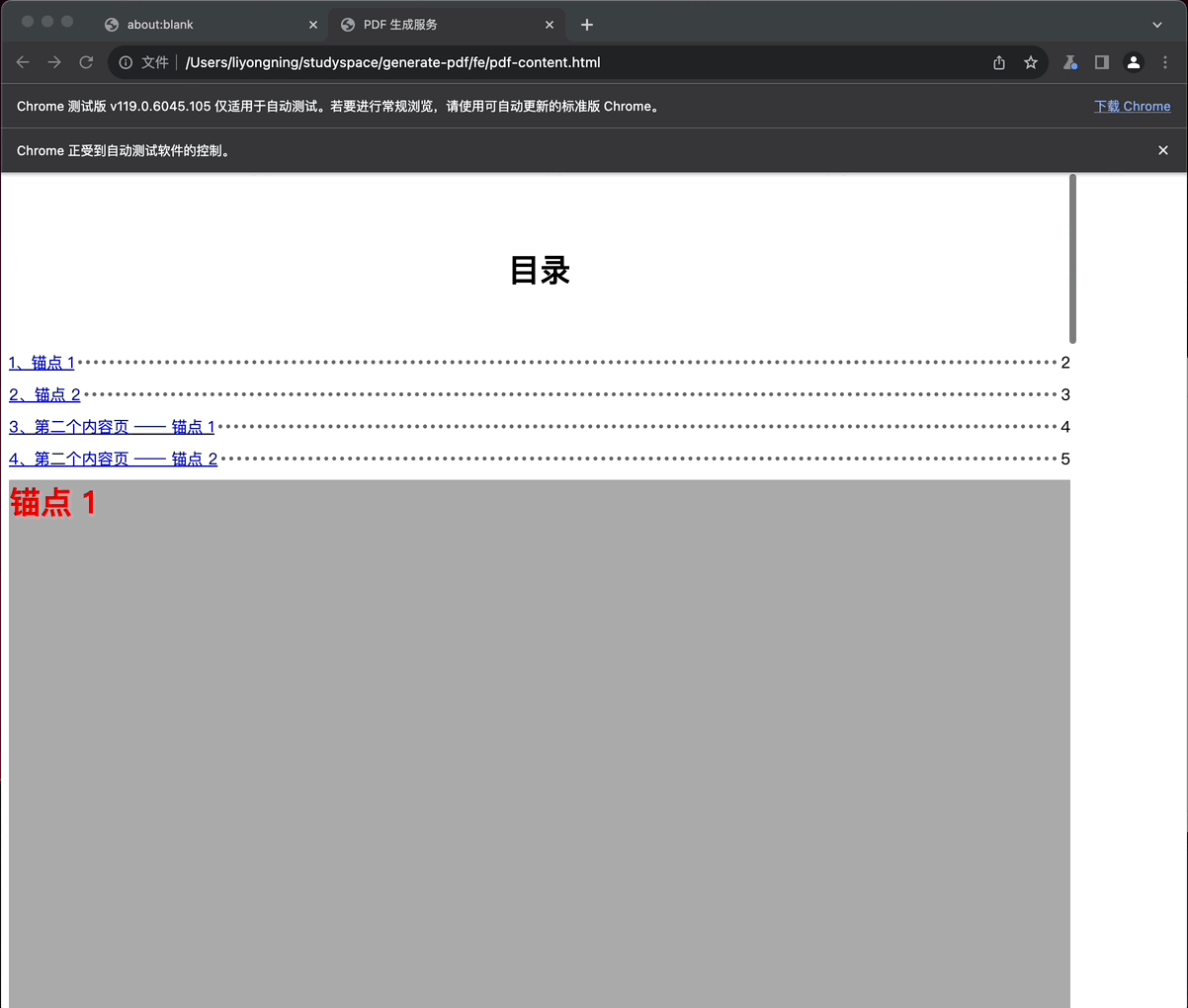
最终的 PDF 效果如下:
总结
我们再来回顾一下本文:
- 首先,PDF 内容页只能由一个前端页面构成,这样的限制在复杂 PDF 文件中会给接入方的前端项目带来代码可维护性问题
- 接着,我们通过在 PDF 服务中引入胶水层,支持将多个页面黏合成一个页面,然后交给 puppeteer 来打印
- 然后,讲了在浏览器中沙箱的实现方案,并通过样式沙箱来解决多页面黏合后出现的样式冲突问题
到目前为止,整套 PDF 生成方案基本完成了:
- 我们通过 PDF 文件合并技术让一份 PDF 文件包含封面、内容页和尾页三部分
- 通过在内容页的开始位置动态插入 HTML 锚点、页面缩放、锚点元素高度计算、换页高度补偿等技术让 PDF 文件拥有了包含准确页码 + 页面跳转能力的目录页
- 通过多页面合并技术 + 样式沙箱解决了用户在复杂 PDF 场景下前端代码维护问题,让用户的开发更自由、更符合业务逻辑
至此,PDF 生成的能力齐了,但怎么给用户使用呢?接下来我们会再用一篇来讲 PDF 生成的服务化和配置化,这样整个方案就彻底完善了。
链接
- PDF 生成(1)— 开篇 中讲解了 PDF 生成的技术背景、方案选型和决策,以及整个方案的技术架构图,所以后面的几篇一直都是在实现整套技术架构
- PDF 生成(2)— 生成 PDF 文件 中我们通过 puppeteer 来生成 PDF 文件,并讲了自定义页眉、页脚的使用和其中的坑。本文结束之后 puppeteer 在 PDF 文件生成场景下的能力也基本到头了,所以,接下来的内容就全是基于 puppeteer 的增量开发了,也是整套架构的核心和难点
- PDF 生成(3)— 封面、尾页 通过 PDF 文件合并技术让一份 PDF 文件包含封面、内容页和尾页三部分。
- PDF 生成(4)— 目录页 通过在内容页的开始位置动态插入 HTML 锚点、页面缩放、锚点元素高度计算、换页高度补偿等技术让 PDF 文件拥有了包含准确页码 + 页面跳转能力的目录页
- PDF 生成(5)— 内容页支持由多页面组成 通过多页面合并技术 + 样式沙箱解决了用户在复杂 PDF 场景下前端代码维护问题,让用户的开发更自由、更符合业务逻辑
- PDF 生成(6)— 服务化、配置化 就是本文了,本系列的最后一篇,以服务化的方式对外提供 PDF 生成能力,通过配置服务来维护接入方的信息,通过队列来做并发控制和任务分类
- 代码仓库 欢迎 Star
当学习成为了习惯,知识也就变成了常识。 感谢各位的 关注、点赞、收藏和评论。
新视频和文章会第一时间在微信公众号发送,欢迎关注:李永宁lyn
文章已收录到 github 仓库 liyongning/blog,欢迎 Watch 和 Star。
相关文章:
PDF 生成(5)— 内容页支持由多页面组成
当学习成为了习惯,知识也就变成了常识。 感谢各位的 关注、点赞、收藏和评论。 新视频和文章会第一时间在微信公众号发送,欢迎关注:李永宁lyn 文章已收录到 github 仓库 liyongning/blog,欢迎 Watch 和 Star。 回顾 在本篇开始…...

day 51 115.不同的子序列 583. 两个字符串的删除操作 72. 编辑距离
115. 不同的子序列 给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数,结果需要对 109 7 取模。 示例 1: 输入:s "rabbbit", t "rabbit" 输出:3 解释: 如下所示,…...

http包详解
http包的作用及使用 go的http包是go的web编程的核心内容,go的web框架本质上都是基于http提供的组件进行再度封装。我们来看一下http基本的使用: func main() {http.Handle("/get", GetVal())http.Handle("/hello", Hello())http.H…...
Reqable实战系列:Flutter移动应用抓包调试教程
Flutter应用网络请求调试一直是业内难题,原因在于Dart语言标准库的网络请求不会走Wi-Fi代理,常规通过配置Wi-Fi代理来抓包的方式行不通。这给我们日常开发测试造成了很大的阻碍,严重降低工作效率。因此写一篇教程,讲解如何使用Req…...

乾元通渠道商中标吴忠市自然灾害应急能力提升项目
近日,乾元通渠道商中标宁夏回族自治区吴忠市自然灾害应急能力提升项目,乾元通作为设备厂家,为项目提供通信指挥类装备(多链路聚合设备)QYT-X1。 青岛乾元通数码科技有限公司作为国家应急产业企业,深耕于数据…...

护网蓝队面试
一、sql注入分类 **原理:**没有对用户输入项进行验证和处理直接拼接到查询语句中 查询语句中插⼊恶意SQL代码传递后台sql服务器分析执行 **从注入参数类型分:**数字型注入、字符型注入 **从注入效果分:**报错注入、布尔注入、延时注入、联…...

【高考志愿】金融学
目录 一、金融学类专业概述 二、主要课程 三、就业前景与方向 四、适合人群 五、金融学学科排名 六、总结 高考志愿选择金融学,无疑是一个既充满挑战又极具前景的决策。金融学,作为经济学门类下的重要分支,不仅涵盖了广泛的金融领域知识…...

返利App的用户行为分析与数据驱动决策
返利App的用户行为分析与数据驱动决策 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨返利App中的用户行为分析与数据驱动决策的技术细节和实…...

python基础:高级数据类型:集合
1、集合的定义 集合是一个无序且无重复元素的列表。其定义与数学定义一致。其无序和不重复和字典特征类似,但是无“值”。 2、集合的创建 集合一般由列表创建,在初始化列表时保证其元素唯一性,即为集合。 创建方法:x set(list…...
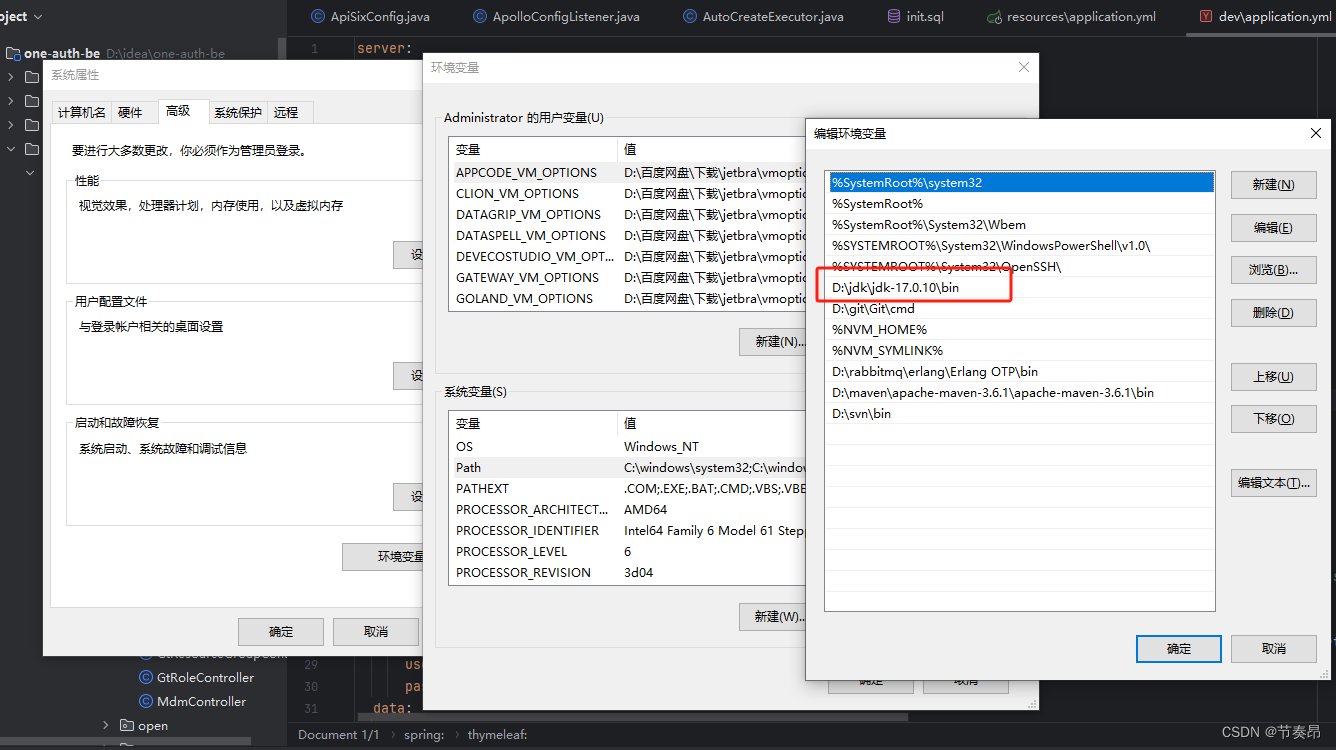
idk17配置
只需要把zip包解压,然后配置环境变量: bin目录路径粘到path里面就好了 然后打开cmd窗口分别输入 java javac java -version 验证...
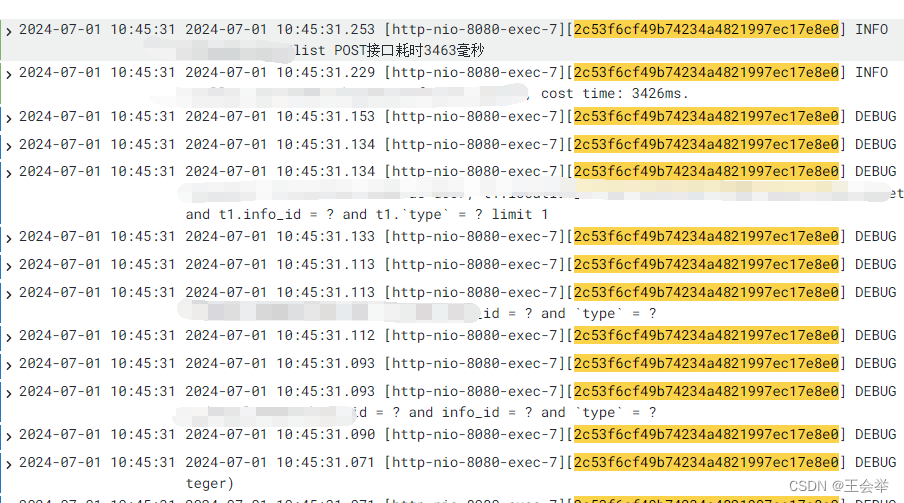
Java实现日志全链路追踪.精确到一次请求的全部流程
广大程序员在排除线上问题时,会经常遇见各种BUG.处理这些BUG的时候日志就格外的重要.只有完善的日志才能快速有效的定位问题.为了提高BUG处理效率.我决定在日志上面优化.实现每次请求有统一的id.通过id能获取当前接口的全链路流程走向. 实现效果如下: 一次查询即可找到所有关…...

你敢相信吗,AI绘画正在逐渐取代你的工作!
前言 在当今信息技术高速发展的时代,AI绘画技术的崛起已引起了广泛关注和讨论。许多人开始担心AI技术是否会逐渐取代传统绘画师的工作。人类无疑是感性的动物,创作出来的艺术作品常常带有浓郁的个人风格和情感。但AI绘画在某些方面的突破,使…...
博途PLC轴工艺对象随动误差监视功能
S7-1200PLC和V90总线伺服通过工艺对象实现定位控制时在组态工艺对象里有这样的随动误差监视功能介绍,关于这个功能,今天我们解读下,工艺对象组态编程可以参考下面文章链接: S7-1200PLC和V90总线伺服通过工艺对象实现定位控制(标准报文3应用)_v90工艺对象3号报文-CSDN博客文…...

《昇思25天学习打卡营第24天 | 昇思MindSporeResNet50图像分类》
24天 本节学习了使用ResNet50网络对CIFAR-10数据集进行分类。 步骤: 1.数据集准备与加载 2.构建网络 残差网络结构(Residual Network)是ResNet网络的主要亮点,ResNet使用残差网络结构后可有效地减轻退化问题,实现更深的网络结构设计&#x…...

糟糕的管理者都有这几个特征
在我们的职业生涯中,我们都期望能遇到一位英明睿智、引领团队走向辉煌的管理者。然而,现实往往并非总是如此美好,总会有一些管理能力差的人混迹其中,给团队带来诸多困扰。今天,我们就来看看糟糕的管理者身上都有哪些特…...
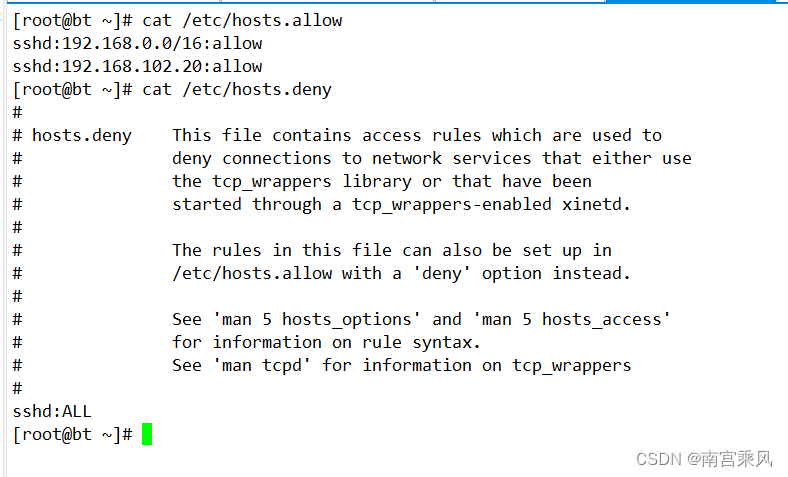
Python (Ansbile)脚本高效批量管理服务器和安全
1、简介 在现代 IT 基础设施中,管理大量服务器是一项复杂而繁琐的任务。特别是在检查服务器的存活状态以及 SSH 登录等任务上,手动操作非常耗时且容易出错。本文将介绍如何使用 Python 脚本实现对多台服务器的批量检查和管理,包括检查服务器…...

《数字图像处理与机器视觉》案例三 (基于数字图像处理的物料堆积角快速测量)
一、前言 物料堆积角是反映物料特性的重要参数,传统的测量方法将物料自然堆积,测量物料形成的圆锥表面与水平面的夹角即可,该方法检测效率低。随着数字成像设备的推广和应用,应用数字图像处理可以更准确更迅速地进行堆积角测量。 …...
)
Postman接口测试工具的原理及应用详解(四)
本系列文章简介: 在当今软件开发的世界中,接口测试作为保证软件质量的重要一环,其重要性不言而喻。随着前后端分离开发模式的普及,接口测试已成为连接前后端开发的桥梁,确保前后端之间的数据交互准确无误。在这样的背景…...

扛鼎中国AI搜索,天工凭什么?
人类的创作不会没有瓶颈,但AI的热度可不会消停。 大模型之战依旧精彩,OpenAI选择在Google前一天举行发布会,两家AI企业之间的拉扯赚足了热度。 反观国内,百模大战激发了大家对于科技变革的热切期盼,而如今行业已逐渐…...

【Ant Design Vue的更新日志】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共…...

MATLAB/Simulink模型化设计驱动树莓派:从LED闪烁到快速原型开发
1. 项目概述:当MATLAB/Simulink遇见树莓派 如果你是一名算法工程师、控制工程师,或者正在学习嵌入式系统,那么“模型化设计”和“快速原型开发”这两个词对你来说一定不陌生。它们听起来很高大上,但核心目标其实很朴素࿱…...

基于Stellar的智能体经济安全与效率优化框架解析
1. 项目概述:一个面向智能体经济的安全与效率优化框架最近在探索智能体(Agent)应用生态时,我遇到了一个普遍存在的痛点:如何在一个去中心化、多智能体协作的网络中,既保证交互的安全与可信,又能…...

小米汽车Q3真车现身:科技巨头跨界造车的技术路径与市场挑战
1. 项目概述:从“Q3真车现身”看小米汽车的阶段性成果最近,小米汽车项目代号“Q3”的测试车辆在公开道路上被频繁捕获,这已经不是简单的谍照,而是接近量产状态的“真车”现身。作为一名长期关注汽车产业变革,特别是科技…...

量子纠错程序的形式化验证方法与工程实践
1. 量子纠错程序验证的核心挑战量子纠错(Quantum Error Correction, QEC)是量子计算实现实用化的关键技术屏障。与传统经典计算不同,量子系统面临着更为复杂的噪声环境:退相干、门操作误差、测量错误等量子特异性噪声会迅速破坏脆…...

2026年冰袋吸水粉厂家大揭秘:选择指南与行业趋势题
随着冷链物流行业的快速发展,冰袋吸水粉作为冷链运输中不可或缺的保冷材料,其市场需求持续增长。然而,市场上冰袋吸水粉的质量参差不齐,如何选择一家值得信赖的厂家成为许多采购商关注的重点。本文将从行业背景、技术特点及市场趋…...

AI如何学习科学品味:从多模态特征到科研评估系统构建
1. 项目概述:当AI开始学习“科学品味” 最近在GitHub上看到一个挺有意思的项目,叫“AI-Can-Learn-Scientific-Taste”。光看名字,你可能觉得这又是一个关于AI模型训练或者科学计算的常规项目。但点进去仔细琢磨,你会发现它的野心远…...

PoE Overlay终极指南:3个核心技巧解决流放之路玩家最头疼的问题
PoE Overlay终极指南:3个核心技巧解决流放之路玩家最头疼的问题 【免费下载链接】PoE-Overlay An Overlay for Path of Exile. Built with Overwolf and Angular. 项目地址: https://gitcode.com/gh_mirrors/po/PoE-Overlay 你是否曾经在《流放之路》中面对满…...

基于CircuitPython与Adafruit IO的DIY智能门铃摄像头全栈开发指南
1. 项目概述与核心思路几年前,我还在用传统的猫眼和门铃,每次快递员敲门或者有访客,都得急匆匆跑到门口,从那个小小的、视野受限的孔洞里费力张望。后来市面上出现了各种智能门铃摄像头,功能是挺诱人,但要么…...

保姆级教程:在OBS Studio里开启H.264帧内刷新,解决录屏文件体积暴增问题
保姆级教程:在OBS Studio里开启H.264帧内刷新,解决录屏文件体积暴增问题 你是否遇到过这样的困扰:用OBS Studio录制静态界面(比如文档、代码编辑器)时,明明画面几乎没有变化,生成的视频文件却像…...

Playnite完整指南:高效统一你的跨平台游戏库管理体验
Playnite完整指南:高效统一你的跨平台游戏库管理体验 【免费下载链接】Playnite Video game library manager with support for wide range of 3rd party libraries and game emulation support, providing one unified interface for your games. 项目地址: http…...