66、基于长短期记忆 (LSTM) 网络对序列数据进行分类
1、基于长短期记忆 (LSTM) 网络对序列数据进行分类的原理及流程
基于长短期记忆(LSTM)网络对序列数据进行分类是一种常见的深度学习任务,适用于处理具有时间或序列关系的数据。下面是在Matlab中使用LSTM网络对序列数据进行分类的基本原理和流程:
-
准备数据:
- 确保数据集中包含带有标签的序列数据,例如时间序列数据、文本数据等。
- 将数据进行预处理和归一化,以便输入到LSTM网络中。
-
构建LSTM网络:
- 在Matlab中,可以使用内置函数
lstmLayer来构建LSTM层。 - 指定输入数据维度、LSTM单元数量、输出层大小等参数。
- 通过
layers = [sequenceInputLayer(inputSize), lstmLayer(numHiddenUnits), fullyConnectedLayer(numClasses), classificationLayer()]构建完整的LSTM分类网络。
- 在Matlab中,可以使用内置函数
-
定义训练选项:
- 设置训练选项,例如学习率、最大迭代次数、小批量大小等。
- 使用
trainingOptions函数来定义训练选项。
-
训练网络:
- 使用
trainNetwork函数来训练构建好的LSTM网络。 - 输入训练数据和标签,并使用定义好的训练选项进行训练。
- 使用
-
评估网络性能:
- 使用测试数据评估训练好的网络的性能,可以计算准确率、混淆矩阵等。
- 通过
classify函数对新数据进行分类预测。
-
模型调优:
- 可以通过调整LSTM网络结构、训练参数等进行进一步优化模型性能。
在实际的应用中,可以根据具体数据和任务需求对LSTM网络进行调整和优化,以获得更好的分类性能。Matlab提供了丰富的工具和函数来支持LSTM网络的构建、训练和评估,利用这些工具可以更高效地完成序列数据分类任务。
2、基于长短期记忆 (LSTM) 网络对序列数据进行分类说明
使用 LSTM 神经网络对序列数据进行分类,LSTM 神经网络将序列数据输入网络,并根据序列数据的各个时间步进行预测。
3、加载序列数据
1)说明
使用 Waveform 数据集,训练数据包含四种波形的时间序列数据。每个序列有三个通道,且长度不同。
从 WaveformData 加载示例数据。
序列数据是序列的 numObservations×1 元胞数组,其中 numObservations 是序列数。每个序列都是一个 numTimeSteps×-numChannels 数值数组,其中 numTimeSteps 是序列的时间步,numChannels 是序列的通道数。标签数据是 numObservations×1 分类向量。
2)加载数据代码
load WaveformData 3)绘制部分序列
代码
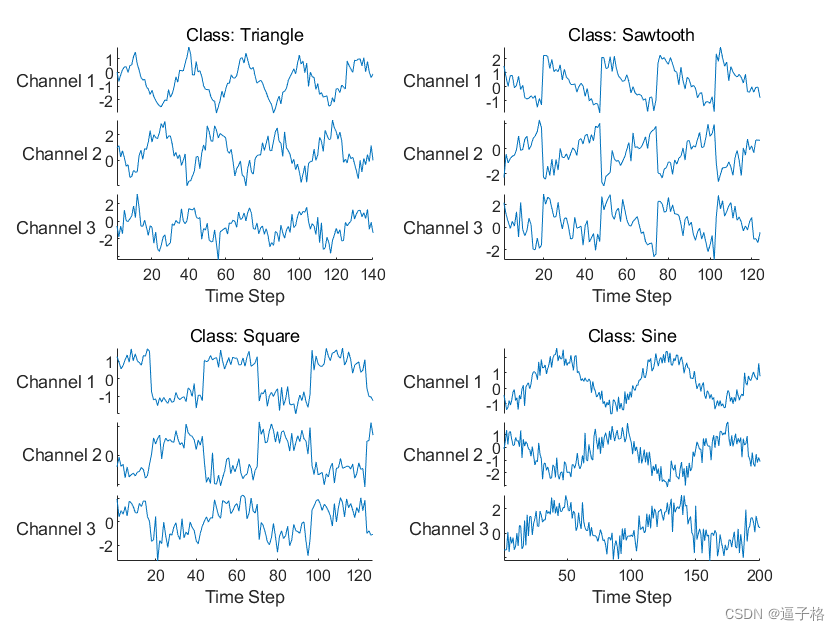
numChannels = size(data{1},2);idx = [3 4 5 12];
figure
tiledlayout(2,2)
for i = 1:4nexttilestackedplot(data{idx(i)},DisplayLabels="Channel "+string(1:numChannels))xlabel("Time Step")title("Class: " + string(labels(idx(i))))
end视图效果
4)查看分类
实现代码
classNames = categories(labels)classNames = 4×1 cell{'Sawtooth'}{'Sine' }{'Square' }{'Triangle'}
5)划分数据
说明
使用 trainingPartitions 函数将数据划分为训练集(包含 90% 数据)和测试集(包含其余 10% 数据)
实现代码
numObservations = numel(data);
[idxTrain,idxTest] = trainingPartitions(numObservations,[0.9 0.1]);
XTrain = data(idxTrain);
TTrain = labels(idxTrain);XTest = data(idxTest);
TTest = labels(idxTest);4、准备要填充的数据
1)说明
默认情况下,软件将训练数据拆分成小批量并填充序列,使它们具有相同的长度
2)获取观测值序列长度代码
numObservations = numel(XTrain);
for i=1:numObservationssequence = XTrain{i};sequenceLengths(i) = size(sequence,1);
end3)序列长度排序代码
[sequenceLengths,idx] = sort(sequenceLengths);
XTrain = XTrain(idx);
TTrain = TTrain(idx);4)查看序列长度
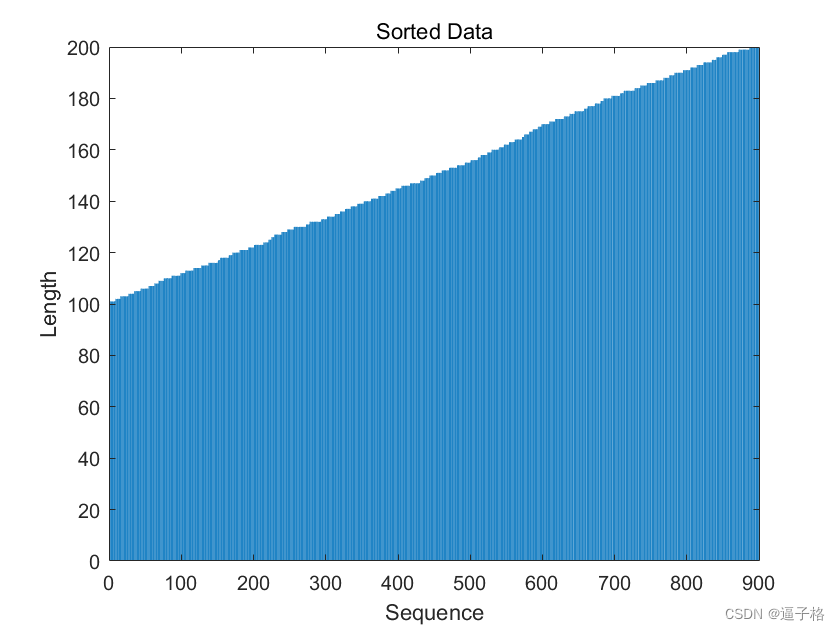
代码
figure
bar(sequenceLengths)
xlabel("Sequence")
ylabel("Length")
title("Sorted Data")视图效果
5、定义 LSTM 神经网络架构
1)说明
将输入大小指定为输入数据的通道数。
指定一个具有 120 个隐藏单元的双向 LSTM 层,并输出序列的最后一个元素。
最后,包括一个输出大小与类的数量匹配的全连接层,后跟一个 softmax 层。
2)实现代码
numHiddenUnits = 120;
numClasses = 4;layers = [sequenceInputLayer(numChannels)bilstmLayer(numHiddenUnits,OutputMode="last")fullyConnectedLayer(numClasses)softmaxLayer]layers = 4×1 Layer array with layers:1 '' Sequence Input Sequence input with 3 dimensions2 '' BiLSTM BiLSTM with 120 hidden units3 '' Fully Connected 4 fully connected layer4 '' Softmax softmax6、指定训练选项
1)说明
使用 Adam 求解器进行训练。
进行 200 轮训练。
指定学习率为 0.002。
使用阈值 1 裁剪梯度。
为了保持序列按长度排序,禁用乱序。
在图中显示训练进度并监控准确度。
2)实现代码
options = trainingOptions("adam", ...MaxEpochs=200, ...InitialLearnRate=0.002,...GradientThreshold=1, ...Shuffle="never", ...Plots="training-progress", ...Metrics="accuracy", ...Verbose=false);7、训练 LSTM 神经网络
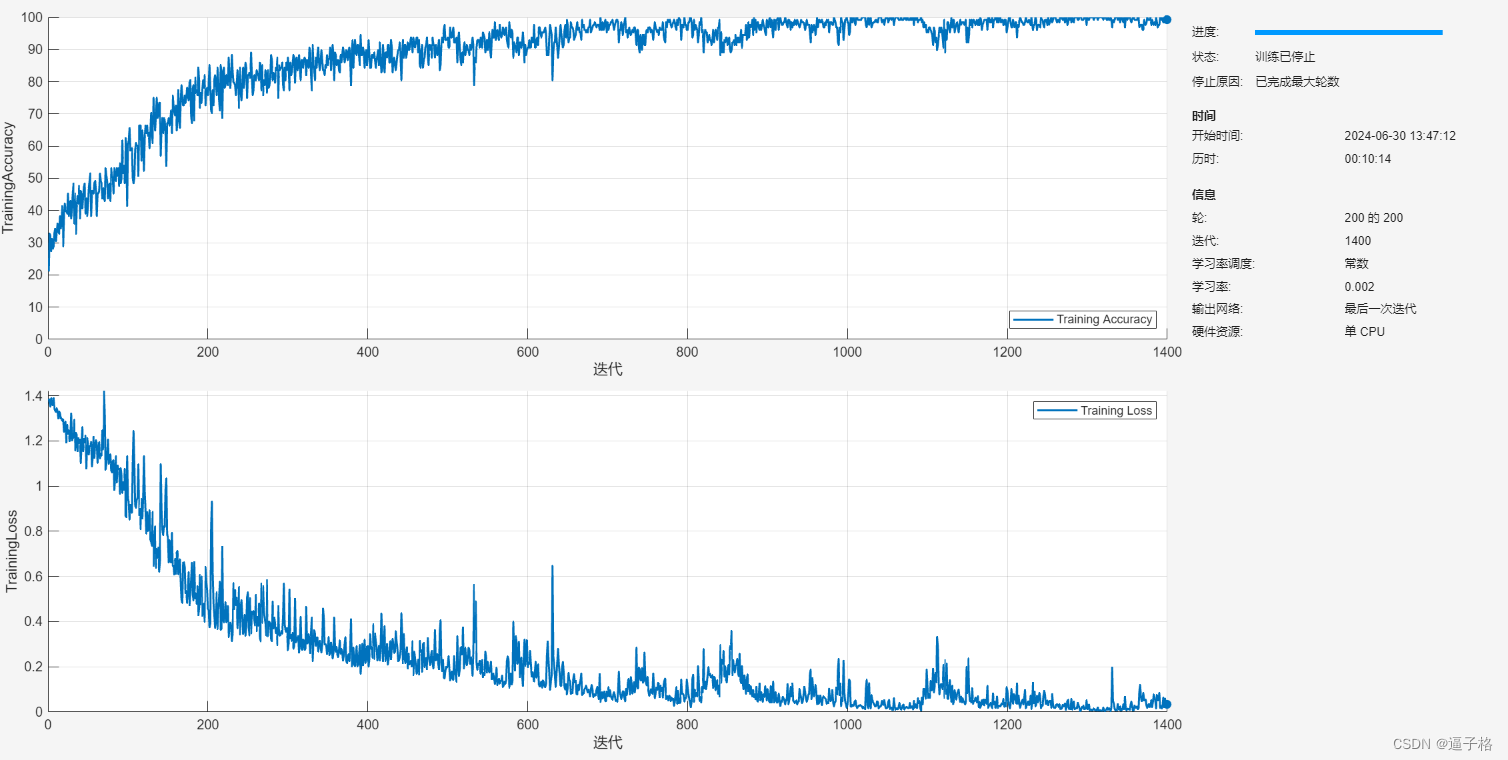
1)说明
使用 trainnet 函数训练神经网络
2)实现代码
net = trainnet(XTrain,TTrain,layers,"crossentropy",options);3)视图效果
8、测试 LSTM 神经网络
1)对测试数据进行分类,并计算预测的分类准确度。
numObservationsTest = numel(XTest);
for i=1:numObservationsTestsequence = XTest{i};sequenceLengthsTest(i) = size(sequence,1);
end[sequenceLengthsTest,idx] = sort(sequenceLengthsTest);
XTest = XTest(idx);
TTest = TTest(idx);2)对测试数据进行分类,并计算预测的分类准确度。
scores = minibatchpredict(net,XTest);
YTest = scores2label(scores,classNames);3)计算分类准确度
acc = mean(YTest == TTest)acc = 0.87004)混淆图中显示分类结果
figure
confusionchart(TTest,YTest)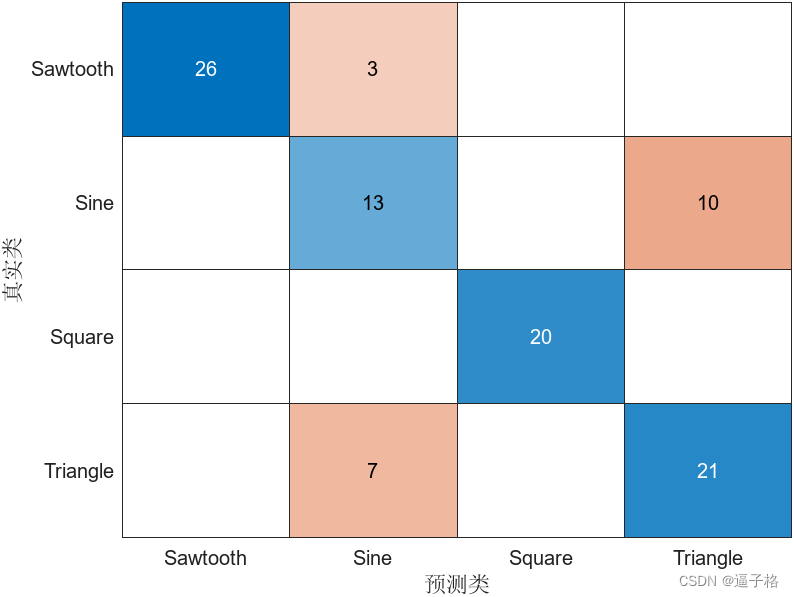
9、总结
基于长短期记忆(LSTM)网络对序列数据进行分类是一种重要的深度学习任务,适用于处理具有序列关系的数据,如时间序列数据、自然语言处理等。以下是对使用LSTM网络进行序列数据分类的总结:
-
LSTM网络结构:
- LSTM是一种适用于处理长期依赖问题的循环神经网络(RNN)变种,能够有效地捕捉序列数据中的长期依赖关系。
- LSTM网络包含输入门、遗忘门、输出门等核心部分,通过这些门控机制来控制信息的输入、遗忘和输出。
-
数据准备:
- 准备带有标签的序列数据,确保数据格式正确且包含标签信息。
- 进行数据预处理和归一化操作,以便于网络训练。
-
网络构建:
- 使用深度学习框架(如TensorFlow、Pytorch或Matlab)构建LSTM网络,定义输入层、LSTM层、全连接层和输出层。
- 设置网络参数,包括输入维度、LSTM单元个数、输出类别数等。
-
模型训练:
- 使用标记好的数据集对构建好的LSTM网络进行训练。
- 设置优化器、损失函数和训练参数,如学习率、迭代次数等。
- 调整网络参数以提高模型性能,避免过拟合。
-
模型评估:
- 使用验证集或测试集对训练好的模型进行评估,计算准确率、精确率、召回率等指标。
- 分析模型在不同类别上的表现,进行结果可视化分析。
-
模型应用和优化:
- 将训练好的模型用于实际应用中,对新数据进行分类预测。
- 根据实际需求对模型进行调优和优化,如调整网络结构、训练参数或使用模型集成等方法。
综合来看,基于LSTM网络对序列数据进行分类是一种强大的方法,可在许多领域中发挥作用。通过合理设计网络结构、优化数据准备和训练过程,可以有效地构建出具有良好泛化能力的序列数据分类模型。
10、源代码
代码
%% 基于长短期记忆 (LSTM) 网络对序列数据进行分类
%使用 LSTM 神经网络对序列数据进行分类,LSTM 神经网络将序列数据输入网络,并根据序列数据的各个时间步进行预测。%% 加载序列数据
%使用 Waveform 数据集,训练数据包含四种波形的时间序列数据。每个序列有三个通道,且长度不同。
%从 WaveformData 加载示例数据。
%序列数据是序列的 numObservations×1 元胞数组,其中 numObservations 是序列数。每个序列都是一个 numTimeSteps×-numChannels 数值数组,其中 numTimeSteps 是序列的时间步,numChannels 是序列的通道数。标签数据是 numObservations×1 分类向量。
load WaveformData
%绘制部分序列
numChannels = size(data{1},2);idx = [3 4 5 12];
figure
tiledlayout(2,2)
for i = 1:4nexttilestackedplot(data{idx(i)},DisplayLabels="Channel "+string(1:numChannels))xlabel("Time Step")title("Class: " + string(labels(idx(i))))
end
%查看类名称
classNames = categories(labels)
%划分数据
%使用 trainingPartitions 函数将数据划分为训练集(包含 90% 数据)和测试集(包含其余 10% 数据),
numObservations = numel(data);
[idxTrain,idxTest] = trainingPartitions(numObservations,[0.9 0.1]);
XTrain = data(idxTrain);
TTrain = labels(idxTrain);XTest = data(idxTest);
TTest = labels(idxTest);
%% 准备要填充的数据
%默认情况下,软件将训练数据拆分成小批量并填充序列,使它们具有相同的长度
%获取观测值序列长度
numObservations = numel(XTrain);
for i=1:numObservationssequence = XTrain{i};sequenceLengths(i) = size(sequence,1);
end
%序列长度排序
[sequenceLengths,idx] = sort(sequenceLengths);
XTrain = XTrain(idx);
TTrain = TTrain(idx);
%查看序列长度
figure
bar(sequenceLengths)
xlabel("Sequence")
ylabel("Length")
title("Sorted Data")%% 定义 LSTM 神经网络架构
%将输入大小指定为输入数据的通道数。
%指定一个具有 120 个隐藏单元的双向 LSTM 层,并输出序列的最后一个元素。
%最后,包括一个输出大小与类的数量匹配的全连接层,后跟一个 softmax 层。
numHiddenUnits = 120;
numClasses = 4;layers = [sequenceInputLayer(numChannels)bilstmLayer(numHiddenUnits,OutputMode="last")fullyConnectedLayer(numClasses)softmaxLayer]
%% 指定训练选项
%使用 Adam 求解器进行训练。
%进行 200 轮训练。
%指定学习率为 0.002。
%使用阈值 1 裁剪梯度。
%为了保持序列按长度排序,禁用乱序。
%在图中显示训练进度并监控准确度。
options = trainingOptions("adam", ...MaxEpochs=200, ...InitialLearnRate=0.002,...GradientThreshold=1, ...Shuffle="never", ...Plots="training-progress", ...Metrics="accuracy", ...Verbose=false);
%% 训练 LSTM 神经网络
%使用 trainnet 函数训练神经网络
net = trainnet(XTrain,TTrain,layers,"crossentropy",options);
%% 测试 LSTM 神经网络
%对测试数据进行分类,并计算预测的分类准确度。
numObservationsTest = numel(XTest);
for i=1:numObservationsTestsequence = XTest{i};sequenceLengthsTest(i) = size(sequence,1);
end[sequenceLengthsTest,idx] = sort(sequenceLengthsTest);
XTest = XTest(idx);
TTest = TTest(idx);
%对测试数据进行分类,并计算预测的分类准确度。
scores = minibatchpredict(net,XTest);
YTest = scores2label(scores,classNames);
%计算分类准确度
acc = mean(YTest == TTest)
%混淆图中显示分类结果
figure
confusionchart(TTest,YTest)工程文件
https://download.csdn.net/download/XU157303764/89499744
相关文章:
66、基于长短期记忆 (LSTM) 网络对序列数据进行分类
1、基于长短期记忆 (LSTM) 网络对序列数据进行分类的原理及流程 基于长短期记忆(LSTM)网络对序列数据进行分类是一种常见的深度学习任务,适用于处理具有时间或序列关系的数据。下面是在Matlab中使用LSTM网络对序列数据进行分类的基本原理和流…...

RabbitMQ消息可靠性等机制详解(精细版三)
目录 七 RabbitMQ的其他操作 7.1 消息的可靠性(发送可靠) 7.1.1 confim机制(保证发送可靠) 7.1.2 Return机制(保证发送可靠) 7.1.3 编写配置文件 7.1.4 开启Confirm和Return 7.2 手动Ack(保证接收可靠) 7.2.1 添加配置文件 7.2.2 手动ack 7.3 避免消息重复消费 7.3.…...

88888
49615...

深度学习之激活函数
激活函数的公式根据不同的函数类型而有所不同。以下是一些常见的激活函数及其数学公式: Sigmoid函数: 公式:f(x)特性:输出范围在0到1之间,常用于二分类问题,将输出转换为概率值。但存在梯度消失问题&#…...

OpenStack开源虚拟化平台(一)
目录 一、OpenStack背景介绍(一)OpenStack是什么(二)OpenStack的主要服务 二、计算服务Nova(一)Nova组件介绍(二)Libvirt简介(三)Nova中的RabbitMQ解析 OpenS…...

C++ | Leetcode C++题解之第207题课程表
题目: 题解: class Solution { private:vector<vector<int>> edges;vector<int> indeg;public:bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {edges.resize(numCourses);indeg.resize(numCo…...

vue3中的自定义指令
全局自定义指令 假设我们要创建一个全局指令v-highlight,用于高亮显示元素。这个指令将接受一个颜色参数,并有一个可选的修饰符bold来决定是否加粗文本。 首先,在创建Vue应用时定义这个指令:(这里可以将指令抽离成单…...
)
Postman接口测试工具的原理及应用详解(一)
本系列文章简介: 在当今软件开发的世界中,接口测试作为保证软件质量的重要一环,其重要性不言而喻。随着前后端分离开发模式的普及,接口测试已成为连接前后端开发的桥梁,确保前后端之间的数据交互准确无误。在这样的背景…...

C++ initializer_list类型推导
目录 initializer_list C自动类型推断 auto typeid decltype initializer_list<T> C支持统一初始化{ },出现了一个新的类型initializer_list<T>,一切类型都可以用列表初始化。提供了一种更加灵活、安全和明确的方式来初始化对象。 class…...

造一个交互式3D火山数据可视化
本文由ScriptEcho平台提供技术支持 项目地址:传送门 使用 Plotly.js 创建交互式 3D 火山数据可视化 应用场景 本代码用于将火山数据库中的数据可视化,展示火山的高度、类型和状态。可用于地质学研究、教育和数据探索。 基本功能 该代码使用 Plotly…...

【网络安全】一文带你了解什么是【CSRF攻击】
CSRF(Cross-Site Request Forgery,跨站请求伪造)是一种网络攻击方式,它利用已认证用户在受信任网站上的身份,诱使用户在不知情的情况下执行恶意操作。具体来说,攻击者通过各种方式(如发送恶意链…...

短视频电商源码如何选择
在数字时代的浪潮下,短视频电商以其直观、生动、互动性强的特点,迅速崛起成为电商行业的一股新势力。对于有志于进军短视频电商领域的创业者来说,选择一款合适的短视频电商源码至关重要。本文将从多个角度探讨如何选择短视频电商源码…...

444444
356前期...

初识LangChain的快速入门指南
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119qq.com] 📱…...

OpenBayes 教程上新 | CVPR 获奖项目,BioCLlP 快速识别生物种类,再也不会弄混小浣熊和小熊猫了!
市面上有很多植物识别的 App,通过对植物的叶片、花朵、果实等特征进行准确的识别,从而确定植物的种类、名称。但动物识别的 App 却十分有限,这使我们很难区分一些外形相似的动物,例如小浣熊和小熊猫。 左侧为小浣熊,右…...
24 年程序员各岗位薪资待遇汇总(最新)
大家好,我是程序员鱼皮。今天分享 24 年 6 月最新的程序员各岗位薪资待遇汇总。 数据是从哪儿来的呢?其实很简单,BOSS 直聘上有一个免费的薪酬查询工具,只要认证成为招聘者就能直接看,便于招聘者了解市场,…...
)
Android SurfaceFlinger——系统动画服务启动(十四)
在了解了 SurfaceFlinger、HWC、OpenGL ES 和 EGL 等相关概念和基础信息后,我们通过系统动画的调用流程引入更多的内容。 一、解析init.rc 开机就启动进程,肯定就要从 rc 文件开始。负责开机动画的进程是 bootanimation。 1、bootanim.rc 源码位置:/frameworks/base/cmds…...

VaRest插件常用节点以及Http请求数据
1.解析json (1)Construct Json Object:构建json对象 (2)Decode Json:解析json 将string转换为json (3)Encode json:将json转换为string (4)Get S…...

【Linux】线程id与互斥(线程三)
上一期我们进行了线程控制的了解与相关操作,但是仍旧有一些问题没有解决 本章第一阶段就是解决tid的问题,第二阶段是进行模拟一个简易线程库(为了加深对于C库封装linux原生线程的理解),第三阶段就是互斥。 目录 线程id…...

JavaEE—什么是服务器?以及Tomcat安装到如何集成到IDEA中?
目录 ▐ 前言 ▐ JavaEE是指什么? ▐ 什么是服务器? ▐ Tomcat安装教程 * 修改服务端口号 ▐ 将Tomcat集成到IDEA中 ▐ 测试 ▐ 结语 ▐ 前言 至此,这半年来我已经完成了JavaSE,Mysql数据库,以及Web前端知识的学习了&am…...
)
双边滤波Bilateral_Filter(调参的重要性)
一、双边滤波的基本概念 1.双边滤波是一种非线性滤波 2.双边滤波的作用是保边降噪平滑滤波器 3.卷积核大小:33、55、77这个是比较常用的卷积核。二、双边滤波的关键参数 1.空间方差 用用控制空间位置差异的平滑程度。 空间方差越大,空间高斯的影响范围越…...

正规全能艺术台制造厂:可靠厂商选择要点解析
正规全能艺术台制造厂选择指南:5大可靠厂商评估要点FAQ“选对全能艺术台制造厂,不是看广告多响,而是看这5个‘隐性指标’——合规资质、自研技术、服务体系、数据安全、内容迭代能力!”很多公共文化场馆在采购全能艺术台时&#x…...

极简fastapi框架
# 自己手写一个极简版 FastAPI 框架 class MiniFastAPI:def __init__(self):# 路由表:存储 {("GET", "/url1"): 对应函数}self.router_map {}# 模仿 app.get("/path") 装饰器def get(self, path: str):def decorator(func):# 把 请求…...

实测Taotoken多模型路由的稳定性与延迟体感观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken多模型路由的稳定性与延迟体感观察 本文基于一段时间的实际调用体验,分享对Taotoken平台稳定性和延迟的直…...

ColorBrewer完整指南:如何为地图和数据可视化选择完美配色方案
ColorBrewer完整指南:如何为地图和数据可视化选择完美配色方案 【免费下载链接】colorbrewer 项目地址: https://gitcode.com/gh_mirrors/co/colorbrewer ColorBrewer是一个专为地图着色和数据可视化设计的开源配色工具,基于Cynthia Brewer博士的…...

Python实战:从时序数据到ARIMA预测的完整建模指南
1. 时间序列分析与ARIMA模型入门 时间序列分析就像是一位经验丰富的老中医把脉——通过观察数据随时间变化的"脉搏",我们能诊断出背后的规律并预测未来走势。ARIMA模型正是其中最经典的"听诊器"之一,我在处理销售预测、库存管理等项…...

Arm Neoverse CMN-650信号接口架构与设计解析
1. Arm Neoverse CMN-650信号接口架构解析在现代SoC设计中,一致性互连网络如同城市交通系统,负责协调各个功能区块的数据流动。Arm Neoverse CMN-650作为第五代一致性网状网络IP,其信号接口设计体现了高性能计算对带宽、延迟和可靠性的极致追…...

终极魔兽争霸3兼容性修复指南:WarcraftHelper让你的经典游戏重获新生
终极魔兽争霸3兼容性修复指南:WarcraftHelper让你的经典游戏重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸III…...

基于RT-Thread与PSoC 6的智能环境监测系统设计与实现
1. 项目概述:当嵌入式RTOS遇上混合信号MCU最近在捣鼓一个智能环境监测的小玩意儿,核心需求很简单:实时采集环境的温湿度数据,一旦超过预设的阈值,就通过声光或者网络的方式发出警报。听起来像是毕业设计的经典题目&…...

Beyond Compare 5密钥生成终极指南:快速激活与完全使用教程
Beyond Compare 5密钥生成终极指南:快速激活与完全使用教程 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare是一款广受欢迎的文件对比工具,但当30天试用期…...