Kafka基本原理详解
(一)概念理解
Apache Kafka是一种开源的分布式流处理平台,专为高性能、高吞吐量的实时数据处理而设计。它最初由LinkedIn公司开发,旨在解决其网站活动中产生的大量实时数据处理和传输问题,后来于2011年开源,并捐赠给了Apache软件基金会,逐渐发展成为大数据和实时数据管道领域的核心组件之一。
(1)产生背景
在Kafka诞生之前,很多大型互联网公司面临着处理海量实时数据的挑战,这些数据通常来源于用户活动跟踪、日志生成、传感器数据、金融交易等。传统的消息队列系统,如RabbitMQ或ActiveMQ,虽然能够处理消息传递,但在处理极高吞吐量、大规模数据存储以及实时分析方面显得力不从心。具体来说,这些挑战包括:
- 高吞吐量需求:传统的消息系统难以应对每秒数百万条消息的处理需求。
- 可扩展性问题:随着数据量的快速增长,系统需要能够容易地横向扩展。
- 数据持久化与实时处理:需要一种既能快速处理数据,又能保证数据可靠存储的解决方案,以便进行即时分析和事后分析。
- 复杂的数据流处理:随着业务需求的增长,单一的消息传递已不能满足,需要一个能够支持复杂数据处理逻辑的平台。
(2)关键特性
Kafka正是为了解决这些问题而设计的,它的关键特性包括:
- 高吞吐量:通过优化磁盘I/O、批量处理和零拷贝技术,Kafka能够达到非常高的数据处理速度。
- 分布式架构:支持数据的分区和复制,既提高了系统的可用性,也使得系统可以横向扩展以应对更大的数据量。
- 持久化与实时性:Kafka的消息被持久化到磁盘,并且支持实时消费,实现了数据的可靠存储与近实时处理的平衡。
- 灵活的消息模型:支持发布-订阅模式和队列模式,满足不同场景的需求。
- 生态丰富:Kafka不仅仅是消息队列,还发展出了Kafka Streams用于流处理,以及与其他大数据处理框架(如Apache Spark、Flink)的紧密集成,形成了强大的数据处理生态系统。
(3)应用场景
- 日志收集与处理: Kafka常用于收集各种服务的日志数据,便于日志分析和监控。
- 实时流处理: 结合Spark、Flink等流处理框架,Kafka可以用于实时数据分析和决策。
- 事件驱动架构: Kafka作为消息中间件,支撑微服务间的解耦通信,实现事件驱动的系统设计。
- 数据集成: Kafka可以作为不同数据源和数据仓库之间的桥梁,支持数据的实时同步和ETL流程。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
(二)消息队列的通信模式
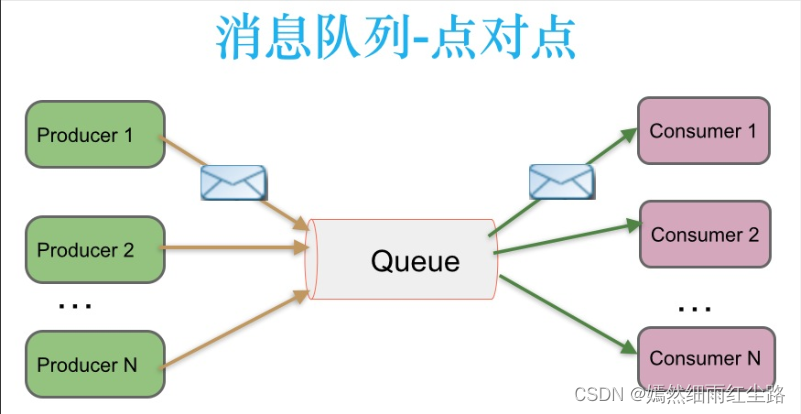
(1)点对点(P2P)模式
在点对点模式中,消息队列扮演着“中间人”的角色,用于连接一个消息生产者(发送者)和一个或多个消息消费者(接收者),但是每条消息只会被一个消费者接收和处理。
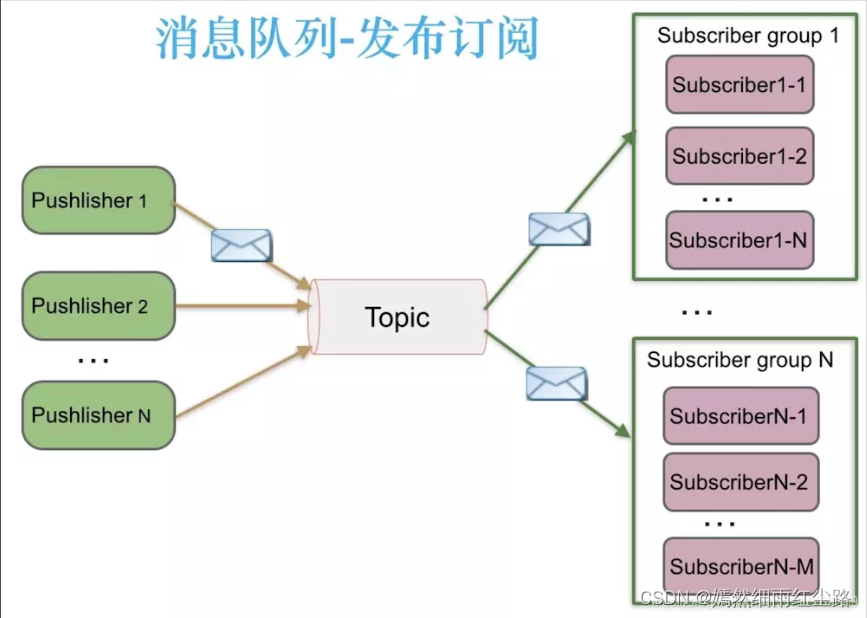
(2)发布/订阅(Pub/Sub)模式
发布/订阅模式与点对点模式的主要区别在于消息的分发方式。在这种模式下,消息生产者发布消息到一个主题(Topic)上,所有订阅了这个主题的消费者都能收到该主题下的所有消息。
(三) Kafka设计架构
(1)基础架构与名词解释
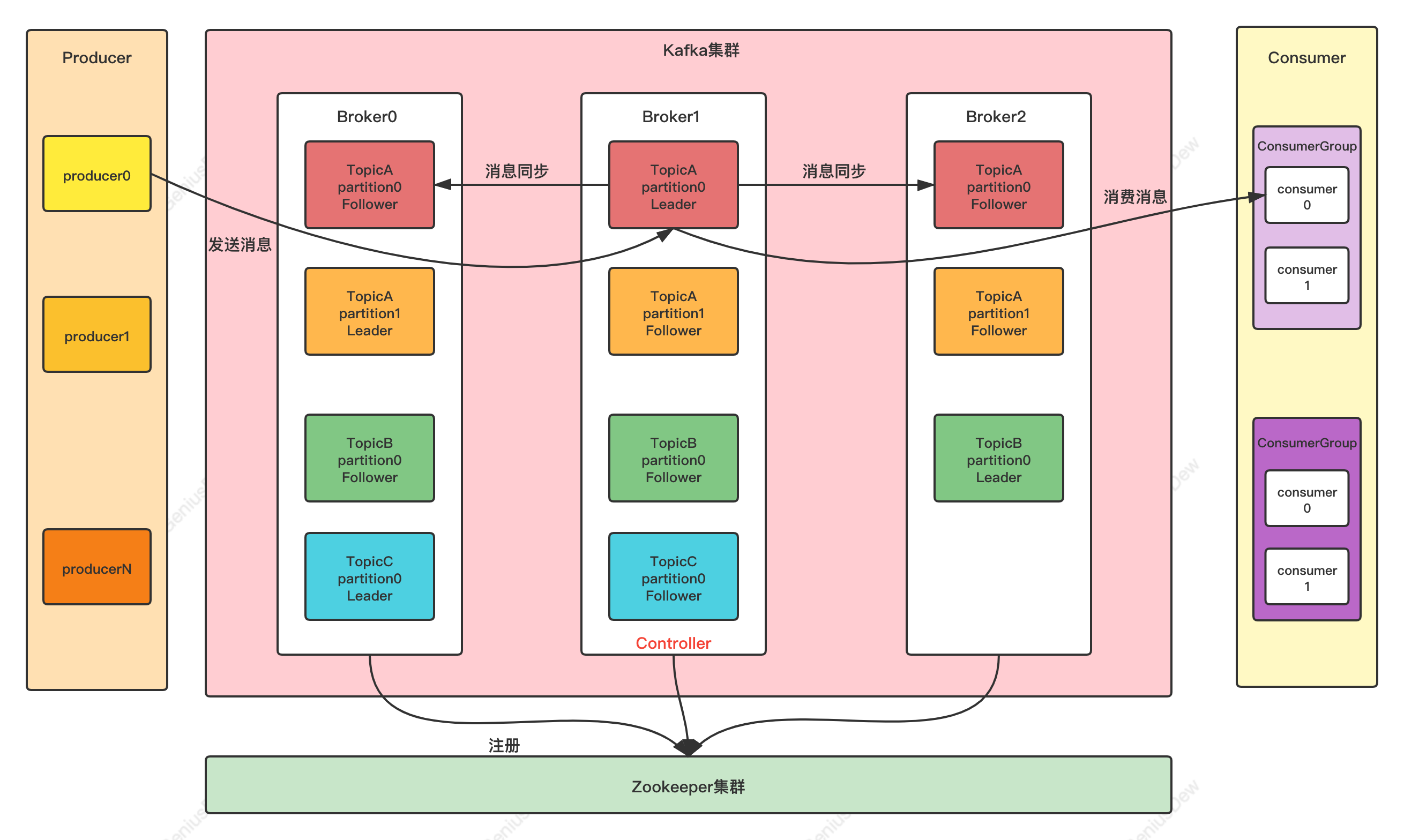
- Producer:Producer即生产者,消息的产生者,是消息的入口。
- Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
- Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
- Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
- Message:每一条发送的消息主体。
- Consumer:消费者,即消息的消费方,是消息的出口。
- Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
- Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
(2)工作流程分析
1.发送数据
我们看上面的架构图中,producer就是生产者,是数据的入口。注意看图中的箭头,Producer在写入数据的时候永远的找leader,不会直接将数据写入follower!那leader怎么找呢?写入的流程又是什么样的呢?我们看下图: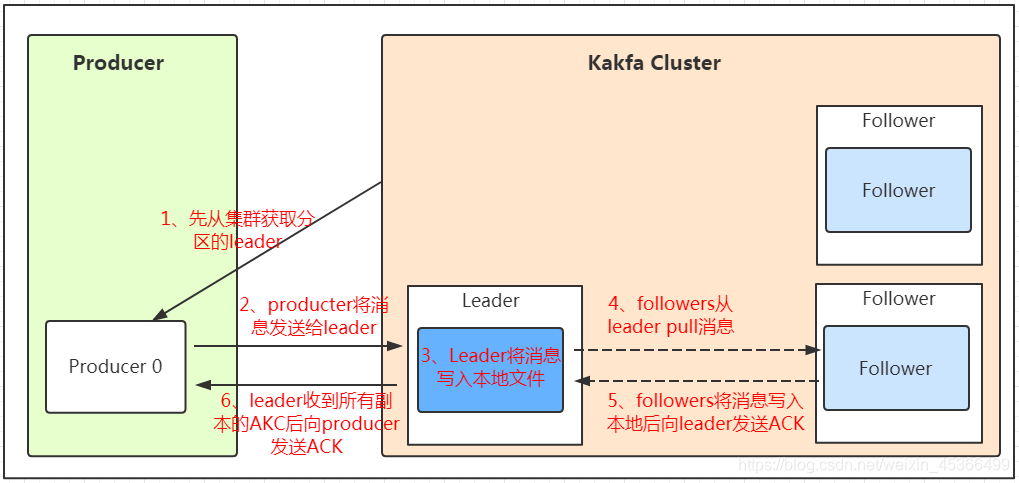
发送的流程就在图中已经说明了,就不单独在文字列出来了!需要注意的一点是,消息写入leader后,follower是主动的去leader进行同步的!producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的!写入示意图如下: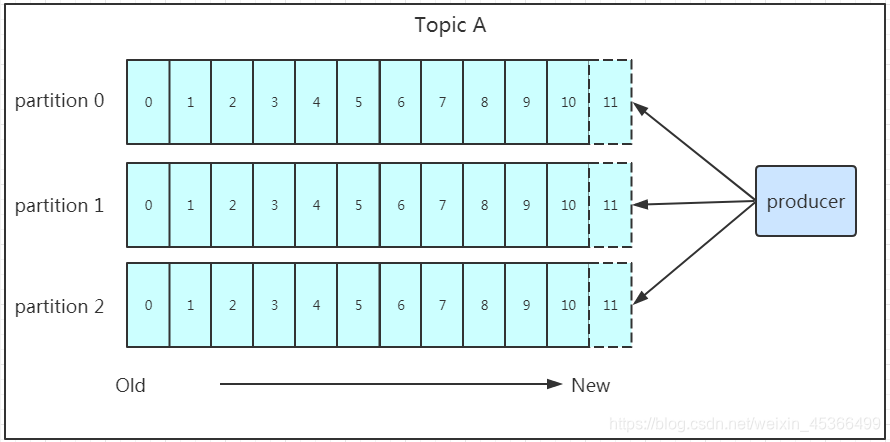
上面说到数据会写入到不同的分区,那kafka为什么要做分区呢?相信大家应该也能猜到,分区的主要目的是:
- 方便扩展:因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。
- 提高并发:以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
在Kafka中,当一个topic拥有多个partition时,producer会通过特定的策略决定数据发送至哪个:
-
指定分区(Manual Partitioning):生产者在发送消息时,可以明确指定消息应写入哪个分区。这种方式给予生产者最大的控制权,适用于需要确保某些消息逻辑上相邻或者实现特定消息处理顺序的场景。例如,如果消息关联到特定用户且希望该用户的所有消息保持顺序,可以通过用户ID作为分区键来实现。
-
基于键的分区(Key-based Partitioning):如果生产者没有明确指定分区,但是设置了消息的键(key),Kafka会使用该键的哈希值来决定消息的分区。这种方式可以自然地实现某种程度的消息排序和分组,因为具有相同键的消息会被发送到相同的分区。例如,使用用户ID作为键可以确保来自同一用户的请求被顺序处理,尽管这要求消费者端也要按照分区消费并处理消息顺序。
-
轮询分区(Round-Robin Partitioning):当生产者既没有指定分区,也没有为消息设置键时,Kafka会采用轮询的方式将消息均匀地分配到各个分区。这种方法简单且有效,可以很好地分散写入负载,确保没有单个分区过载,适合对消息顺序没有严格要求的场景。
Kafka通过ACK应答机制确保消息在生产者向队列写入时不丢失,允许用户根据可靠性需求选择不同级别的确认策略:
- acks=0策略牺牲数据安全性换取最高写入效率,不等待任何确认直接认为消息发送成功。
- acks=1策略在消息被首领节点接收后即确认,平衡了可靠性和性能,确保至少被一个副本接收。
- acks=all策略最为安全,需等待所有副本(包括首领和跟随者)确认消息,确保数据得到备份,但牺牲了一定的写入效率。
若尝试向未创建的Topic发送消息,Kafka默认配置下会自动创建该Topic,初始化其分区数为1,且副本数也为1,虽确保消息发送成功,但这种自动创建行为可能不符合特定场景的安全或性能要求,故生产环境中通常会预先定义Topic并配置合适的分区和副本数量。
2.保存数据
Producer将数据写入kafka后,集群就需要对数据进行保存了!kafka将数据保存在磁盘,可能在我们的一般的认知里,写入磁盘是比较耗时的操作,不适合这种高并发的组件。Kafka初始会单独开辟一块磁盘空间,顺序写入数据(效率比随机写入高)。
(四)Kafka 文件存储架构

这里比较好理解:
一个Topic分别存储在不同的partition中
一个partitioin对应着多个replica备份
一个replica对应着一个Log
一个Log对应多个LogSegment
而在LogSegment中存储着log文件、索引文件、其它文件
(1)Message结构
上面说到log文件就实际是存储message的地方,我们在producer往kafka写入的也是一条一条的message,那存储在log中的message是什么样子的呢?消息主要包含消息体、消息大小、offset、压缩类型……等等!我们重点需要知道的是下面三个:
- offset:offset是一个占8byte的有序id号,它可以唯一确定每条消息在parition内的位置!
- 消息大小:消息大小占用4byte,用于描述消息的大小。
- 消息体:消息体存放的是实际的消息数据(被压缩过),占用的空间根据具体的消息而不一样。
(2)存储策略
无论消息是否被消费,kafka都会保存所有的消息。那对于旧数据有什么删除策略呢?
- 基于时间,默认配置是168小时(7天)。
- 基于大小,默认配置是1073741824。
需要注意的是,kafka读取特定消息的时间复杂度是O(1),所以这里删除过期的文件并不会提高kafka的性能!
(五)Kafka 消费者架构
消费者使用一个 消费组 名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例.
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.

消息存储在log文件后,消费者就可以进行消费了。在讲消息队列通信的两种模式的时候讲到过点对点模式和发布订阅模式。Kafka采用的是发布订阅模式,消费者主动的去kafka集群拉取消息,与producer相同的是,消费者在拉取消息的时候也是找leader去拉取。
(1)消费数据
多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id!同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会组内多个消费者消费同一分区的数据!!!我们看下图: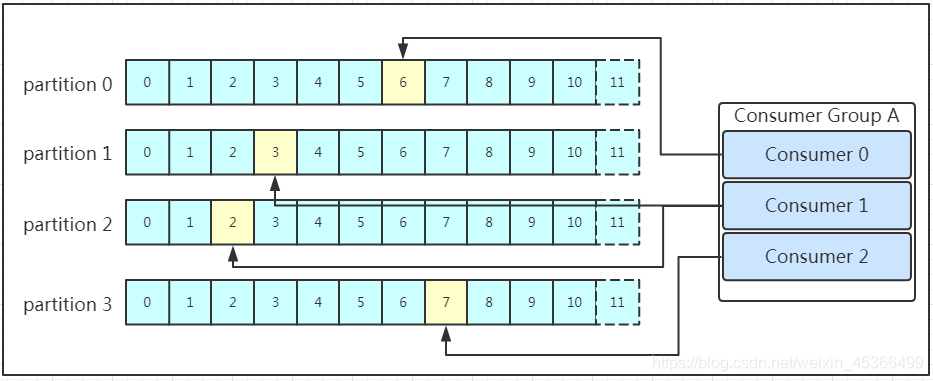
图示是消费者组内的消费者小于partition数量的情况,所以会出现某个消费者消费多个partition数据的情况,消费的速度也就不及只处理一个partition的消费者的处理速度!如果是消费者组的消费者多于partition的数量,那会不会出现多个消费者消费同一个partition的数据呢?上面已经提到过不会出现这种情况!多出来的消费者不消费任何partition的数据。所以在实际的应用中,建议消费者组的consumer的数量与partition的数量一致!
参考文章:
Kafka基本原理详解(超详细!)_kafka工作原理-CSDN博客
Kafka 设计架构原理详细解析(超详细图解)_kafka架构原理-CSDN博客
相关文章:
Kafka基本原理详解
(一)概念理解 Apache Kafka是一种开源的分布式流处理平台,专为高性能、高吞吐量的实时数据处理而设计。它最初由LinkedIn公司开发,旨在解决其网站活动中产生的大量实时数据处理和传输问题,后来于2011年开源࿰…...
关卡编辑器之剧情编辑)
【Unity】RPG2D龙城纷争(七)关卡编辑器之剧情编辑
更新日期:2024年7月1日。 项目源码:第五章发布(正式开始游戏逻辑的章节) 索引 简介一、剧情编辑1.对话数据集2.对话触发方式3.选择对话角色4.设置对话到关卡5.通关条件简介 严格来说,剧情编辑不在关卡编辑器界面中完成,只不过它仍然属于关卡编辑的范畴。 在我们的设想中…...

uniapp启动页面鉴权页面闪烁问题
在使用uni-app开发app 打包完成后如果没有token,那么就在onLaunch生命周期里面判断用户是否登录并跳转至登录页。 但是在app中页面会先进入首页然后再跳转至登录页,十分影响体验。 处理方法: 使用plus.navigator.closeSplashscreen() 官网…...

全志H616交叉编译工具链的安装与使用
交叉编译的概念 1. 什么是交叉编译? 交叉编译是指在一个平台上生成可以在另一个平台上运行的可执行代码。例如,在Ubuntu Linux上编写代码,并编译生成可在Orange Pi Zero2上运行的可执行文件。这个过程是通过使用一个专门的交叉编译工具链来…...
深入解析Java和Go语言中String与byte数组的转换原理
1.Java String与byte[]互相转换存在的问题 java中,按照byte[] 》string 》byte[]的流程转换后,byte数据与最初的byte不一致。 多说无益,上代码,本地macos机器执行,统一使用的UTF-8编码。 import java.nio.charset.S…...

什么是strcmp函数
目录 开头1.什么是strcmp函数2.strcmp函数里的内部结构3.strcmp函数的实际运用(这里只列举其一)脑筋急转弯 结尾 开头 大家好,我叫这是我58。今天,我们要来认识一下C语言中的strcmp函数。 1.什么是strcmp函数 strcmp函数来自于C语言中的头文件<str…...

Follow Carl To Grow|【LeetCode】491.递增子序列,46.全排列,47.全排列 II
【LeetCode】491.递增子序列 题意:给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。 数组中可能含有重复元素,如出现两个整数相等,也可以…...

pytorch nn.Embedding 用法和原理
nn.Embedding 是 PyTorch 中的一个模块,用于将离散的输入(通常是词或子词的索引)映射到连续的向量空间。它在自然语言处理和其他需要处理离散输入的任务中非常常用。以下是 nn.Embedding 的用法和原理。 用法 初始化 nn.Embedding nn.Embed…...

Python中常用的有7种值(数据)的类型及type()语句的用法
目录 0.Python中常用的有7种值(数据)的类型Python中的数据类型主要有:Number(数字)、Boolean(布尔)、String(字符串)、List(列表)、Tuple…...
某配送平台未授权访问和弱口令(附赠nuclei默认密码验证脚本)
找到一个某src的子站,通过信息收集插件,发现ZABBIX-监控系统,可以日一下 使用谷歌搜索历史漏洞:zabbix漏洞 通过目录扫描扫描到后台,谷歌搜索一下有没有默认弱口令 成功进去了,挖洞就是这么简单 搜索文章还…...

01.总览
目录 简介Course 1: Natural Language Processing with Classification and Vector SpaceWeek 1: Sentiment Analysis with Logistic RegressionWeek 2: Sentiment Analysis with Nave BayesWeek 3: Vector Space ModelsWeek 4: Machine Translation and Document Search Cours…...
Linux换源
前言 安装完Linux系统,尽量更换源以提高安装软件的速度。 步骤 备份原始源列表sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak修改sources.list sudo vim /etc/apt/sources.list将内容替换成对应的源 **PS:清华源地址:https:…...

【高考志愿】 化学工程与技术
目录 一、专业概述 二、就业前景 三、就业方向 四、报考注意 五、专业发展与深造 六、化学工程与技术专业排名 七、总结 一、专业概述 化学工程与技术专业,这是一门深具挑战与机遇的综合性学科。它融合了工程技术的实用性和化学原理的严谨性,为毕…...

2024上半年网络与数据安全法规政策、国标、报告合集
事关大局,我国数据安全立法体系已基本形成并逐步细化。数据基础制度建设事关国家发展和安全大局,数据安全治理贯穿构建数据基础制度体系全过程。随着我国数字经济建设进程加快,数据安全立法实现由点到面、由面到体加速构建,目前已…...
基于SpringBoot扶农助农政策管理系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,…...

淘宝商铺电话怎么获取?使用爬虫工具采集
访问淘宝商铺是一个合法的行为,你可以使用爬虫工具来提取淘宝商铺的信息。下面是一个基本的Python程序示例,用于使用爬虫工具访问淘宝商铺: import requestsdef get_store_info(store_id):url fhttps://shop{id}.taobao.comresponse reque…...

ModStart:开源免费的PHP企业网站开发建设管理系统
大家好!今天我要给大家介绍一款超级强大的开源工具——ModStart,它基于Laravel框架,是PHP企业网站开发建设的绝佳选择! 为什么选择ModStart? 模块化设计:ModStart采用模块化设计,内置了众多基…...

npm安装依赖报错——npm ERR gyp verb cli的解决方法
1. 问题描述 1.1 npm安装依赖报错——npm ERR! gyp verb cli npm MARN deprecated axiosQ0.18.1: critical security vuLnerability fixed in v0.21.1. For more information, npm WARN deprecated svg001.3.2: This SVGO version is no Longer supported. upgrade to v2.x.x …...
公网环境使用Potplayer远程访问家中群晖NAS搭建的WebDAV听歌看电影
文章目录 前言1 使用环境要求:2 配置webdav3 测试局域网使用potplayer访问webdav4 内网穿透,映射至公网5 使用固定地址在potplayer访问webdav 前言 本文主要介绍如何在Windows设备使用potplayer播放器远程访问本地局域网的群晖NAS中的影视资源ÿ…...
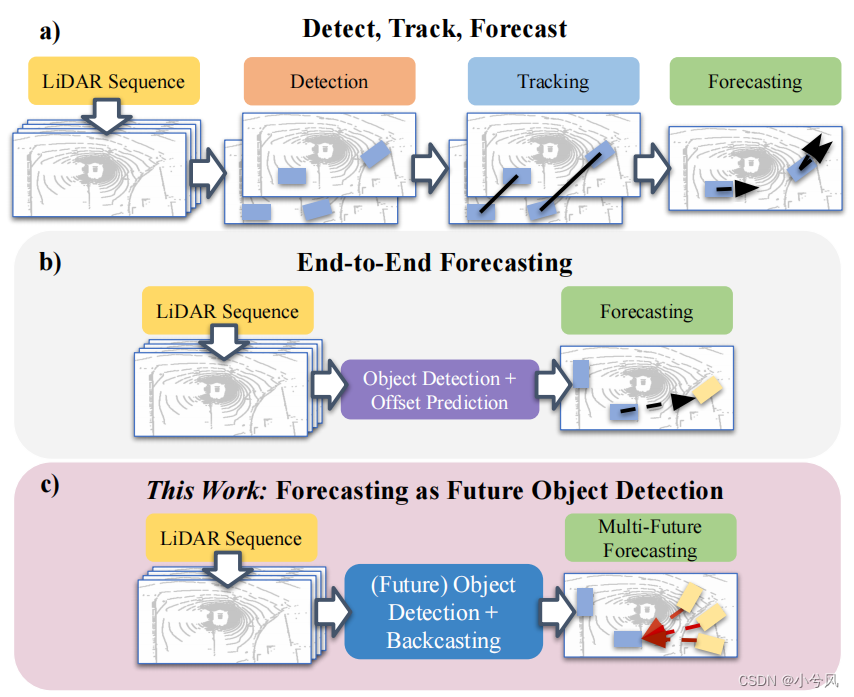
Forecasting from LiDAR via Future Object Detection
Forecasting from LiDAR via Future Object Detection 基础信息 论文:cvpr2022paper https://openaccess.thecvf.com/content/CVPR2022/papers/Peri_Forecasting_From_LiDAR_via_Future_Object_Detection_CVPR_2022_paper.pdfgithub:https://github.co…...

ARM TLBIP指令解析与应用实践
1. ARM TLBIP指令深度解析在ARMv8/v9架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,负责缓存虚拟地址到物理地址的转换结果。当页表发生变更时,必须及时使TLB中对应的缓存条目失效,以确保内存访问的正…...

QT5之串口
QT的串口概述 Qt Serial Port 模块中只有两个类: QSerialPortInfo 和 QSerialPort。 QSerialPortInfo 类 作用:获取串口的信息 类包含如下: QString portName() //串口名称,如 COM1、 COM2 QString description() //串口的文字描述 bool isNull() //串口是否为空,若返…...

QtScrcpy:将手机屏幕变成电脑扩展屏的终极解决方案
QtScrcpy:将手机屏幕变成电脑扩展屏的终极解决方案 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy …...

Cool-Request全局请求头配置终极指南:告别重复配置的API测试新体验
Cool-Request全局请求头配置终极指南:告别重复配置的API测试新体验 【免费下载链接】cool-request IDEA API、Java Method debug tools 项目地址: https://gitcode.com/gh_mirrors/co/cool-request 你是否厌倦了在每个API请求中重复配置相同的认证Token、内容…...
)
告别单调列表!用Unity Dropdown组件打造游戏中的动态交互式菜单(附事件处理完整代码)
告别单调列表!用Unity Dropdown组件打造游戏中的动态交互式菜单(附事件处理完整代码) 在独立游戏开发中,UI交互的细腻程度往往决定了玩家的沉浸感。想象一下:当玩家在角色创建界面选择职业时,下拉菜单不仅显…...

Adafruit退货政策全解析:电子元件退货的核心逻辑与实操指南
1. 退货政策的核心逻辑与适用场景 在创客圈和电子爱好者社群里,Adafruit 几乎是无人不晓的名字。无论是 Arduino 开发板、各种传感器,还是炫目的 NeoPixel LED 灯带,他们的产品是无数项目从想法变为现实的基石。但即便是最资深的玩家…...

3分钟搞定Windows和Office永久激活:KMS智能激活工具完整指南
3分钟搞定Windows和Office永久激活:KMS智能激活工具完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然…...

AUBO机械臂视觉跟踪避坑指南:手眼标定后,如何让末端稳定跟随移动的ArUco码?
AUBO机械臂视觉跟踪避坑指南:手眼标定后如何实现稳定动态跟随 在工业自动化领域,机械臂的视觉跟踪能力直接决定了柔性制造系统的智能化水平。AUBO i5作为国产协作机械臂的代表性产品,其与视觉系统的集成应用越来越广泛。然而,许多…...

告别混乱!用EPLAN高效管理端子连接图的5个实战技巧与常见坑点复盘
告别混乱!用EPLAN高效管理端子连接图的5个实战技巧与常见坑点复盘 在电气工程设计领域,端子连接图的质量直接影响着生产效率和调试准确性。许多工程师在项目后期常常陷入反复修改端子图表的泥潭,不仅耗费宝贵时间,还可能因疏忽导致…...

基于Arduino HID与红外解码的遥控键鼠系统设计与实现
1. 项目概述如果你曾经想过,能不能用一个电视遥控器来控制电脑的鼠标光标,或者快速触发一些键盘快捷键,那么这个项目就是为你准备的。我最近基于Arduino平台,成功搭建了一个红外遥控鼠标和键盘系统,它不仅能让你在沙发…...