【机器学习】Whisper:开源语音转文本(speech-to-text)大模型实战

目录
一、引言
二、Whisper 模型原理
2.1 模型架构
2.2 语音处理
2.3 文本处理
三、Whisper 模型实战
3.1 环境安装
3.2 模型下载
3.3 模型推理
3.4 完整代码
3.5 模型部署
四、总结
一、引言
上一篇对ChatTTS文本转语音模型原理和实战进行了讲解,第6次拿到了热榜第一🏆。今天,分享其对称功能(语音转文本)模型:Whisper。Whisper由OpenAI研发并开源,参数量最小39M,最大1550M,支持包含中文在内的多种语言。由于其低资源成本、优质的生存效果,被广泛应用于音乐识别、私信聊天、同声传译、人机交互等各种语音转文本场景,且商业化后价格不菲。今天免费分享给大家,不要再去花钱买语音识别服务啦!
二、Whisper 模型原理
2.1 模型架构
Whisper是一个典型的transformer Encoder-Decoder结构,针对语音和文本分别进行多任务(Multitask)处理。
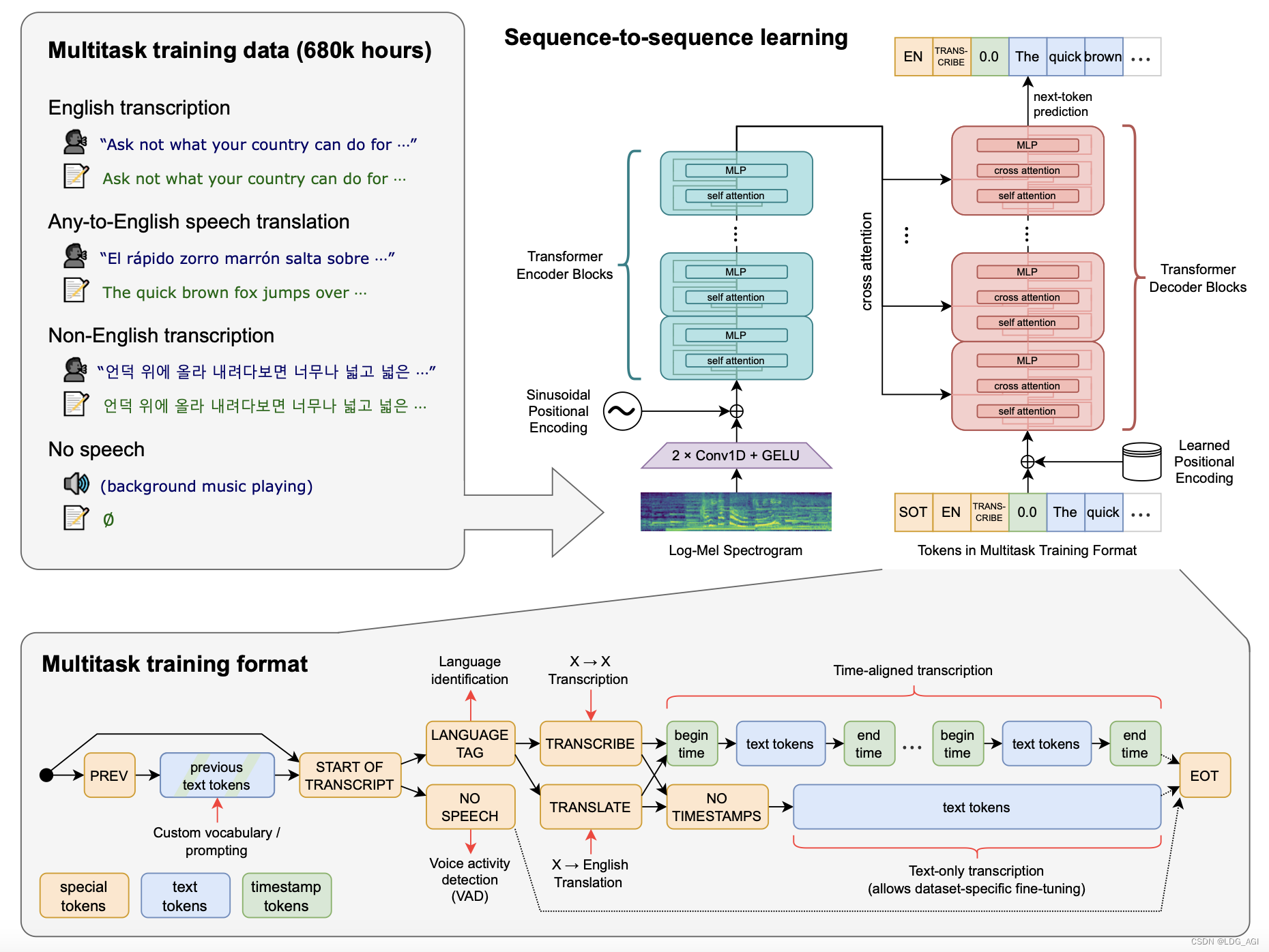
2.2 语音处理
Whisper语音处理:基于680000小时音频数据进行训练,包含英文、其他语言转英文、非英文等多种语言。将音频数据转换成梅尔频谱图,再经过两个卷积层后送入 Transformer 模型。
2.3 文本处理
Whisper文本处理:文本token包含3类:special tokens(标记tokens)、text tokens(文本tokens)、timestamp tokens(时间戳),基于标记tokens控制文本的开始和结束,基于timestamp tokens让语音时间与文本对其。
仅用通俗易懂的语言描述了下Whisper的原理,如果想更深入的了解,请参考OpenAI官方Whisper论文。
三、Whisper 模型实战
3.1 环境安装
本文基于HuggingFace的transfomers库,采用pipeline方式进行极简单的模型实用实战,具体的pipeline以及其他transformers模型使用方式可以参考我之前的文章。
所以,您仅需要安装transformers库。
pip install transformers当前,语音经常会和视频等其他媒介联系起来,所以我建议您顺带安装多媒体处理工具ffmpeg,没有提供pip库,仅能依靠apt-get安装。
sudo apt-get update && apt-get install ffmpeg3.2 模型下载
基于pipeline会自动进行模型下载,当然,如果您的网速不行,请替换HF_ENDPOINT为国内镜像。
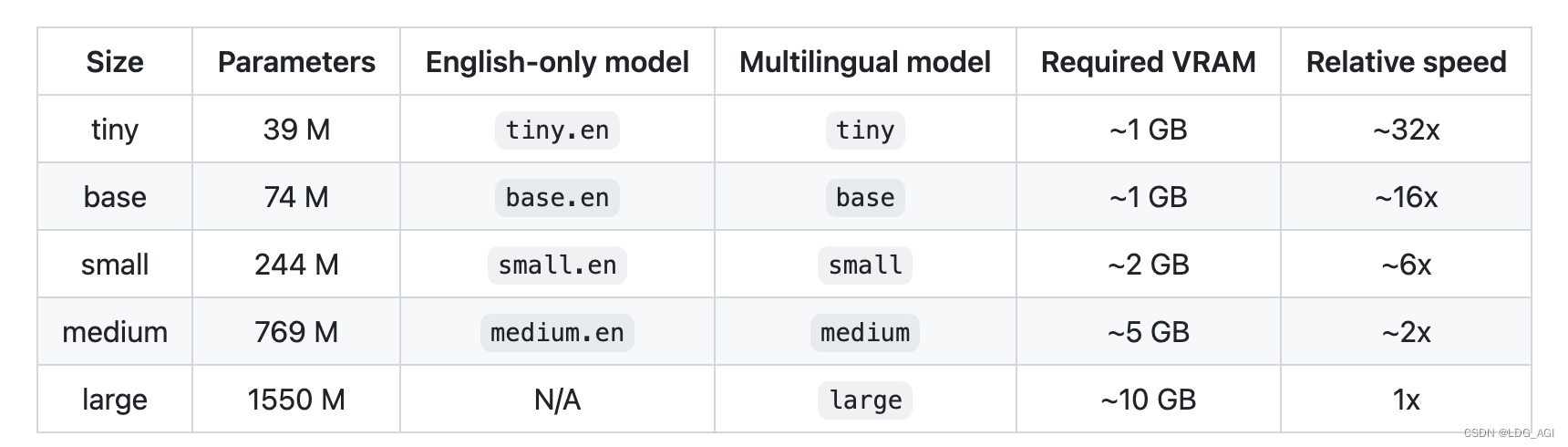
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")不同尺寸模型参数量、多语言支持情况、需要现存大小以及推理速度如下
3.3 模型推理
推理函数仅需2行,非常简单,基于pipeline实例化1个模型对象,将要转换的音频文件传至模型对象中即可:
def speech2text(speech_file):transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")text_dict = transcriber(speech_file)return text_dict3.4 完整代码
运行完整代码:
python run_whisper.py -a output_video_enhanced.mp3 完整代码如下:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
os.environ["TF_ENABLE_ONEDNN_OPTS"] = "0"from transformers import pipeline
import subprocessdef speech2text(speech_file):transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")text_dict = transcriber(speech_file)return text_dictimport argparse
import json
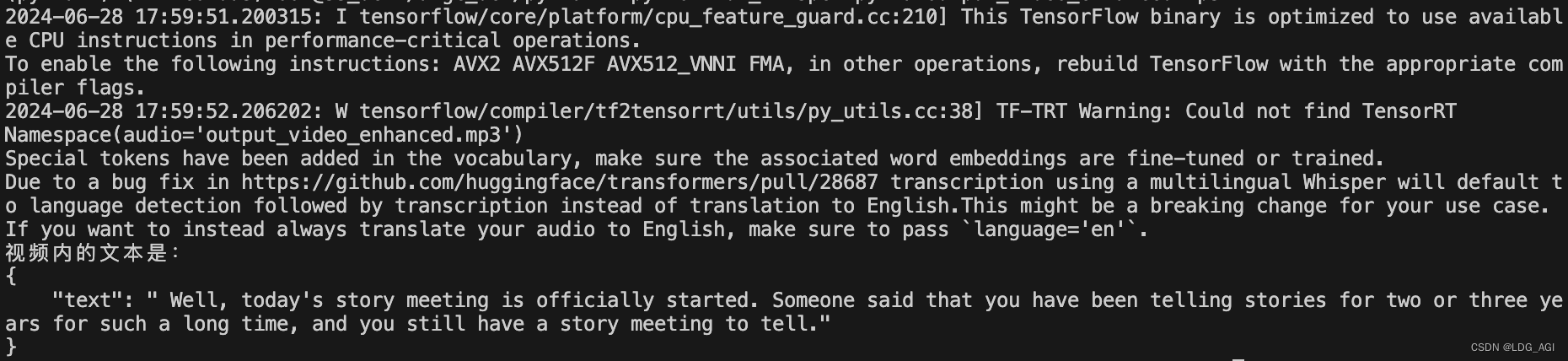
def main():parser = argparse.ArgumentParser(description="语音转文本")parser.add_argument("--audio","-a", type=str, help="输出音频文件路径")args = parser.parse_args()print(args) text_dict = speech2text(args.audio)#print("视频内的文本是:\n" + text_dict["text"])print("视频内的文本是:\n"+ json.dumps(text_dict,indent=4))if __name__=="__main__":main()这里采用argparse处理命令行参数,将mp3音频文件输入后,经过speech2text语音转文本函数处理,返回对应的文本,结果如下:
3.5 模型部署
如果想将该服务部署成语音识别API服务,可以参考之前的FastAPI相关文章。
四、总结
本文是上一篇chatTTS文章的夫妻篇,既然教了大家如何将文本转语音,就一定要教大家如何将语音转成文本,这样技术体系才完整。首先简要概述了Whisper的模型原理,然后基于transformers的pipeline库2行代码实现了Whisper模型推理,希望可以帮助到大家。码字不易,如果喜欢期待您的关注+3连+投票。
如果您还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
AI智能体研发之路-模型篇(五):pytorch vs tensorflow框架DNN网络结构源码级对比
AI智能体研发之路-模型篇(六):【机器学习】基于tensorflow实现你的第一个DNN网络
AI智能体研发之路-模型篇(七):【机器学习】基于YOLOv10实现你的第一个视觉AI大模型
AI智能体研发之路-模型篇(八):【机器学习】Qwen1.5-14B-Chat大模型训练与推理实战
AI智能体研发之路-模型篇(九):【机器学习】GLM4-9B-Chat大模型/GLM-4V-9B多模态大模型概述、原理及推理实战
AI智能体研发之路-模型篇(十):【机器学习】Qwen2大模型原理、训练及推理部署实战
《AI—Transformers应用》
【AI大模型】Transformers大模型库(一):Tokenizer
【AI大模型】Transformers大模型库(二):AutoModelForCausalLM
【AI大模型】Transformers大模型库(三):特殊标记(special tokens)
【AI大模型】Transformers大模型库(四):AutoTokenizer
【AI大模型】Transformers大模型库(五):AutoModel、Model Head及查看模型结构
【AI大模型】Transformers大模型库(六):torch.cuda.OutOfMemoryError: CUDA out of memory解决
【AI大模型】Transformers大模型库(七):单机多卡推理之device_map
【AI大模型】Transformers大模型库(八):大模型微调之LoraConfig
相关文章:
【机器学习】Whisper:开源语音转文本(speech-to-text)大模型实战
目录 一、引言 二、Whisper 模型原理 2.1 模型架构 2.2 语音处理 2.3 文本处理 三、Whisper 模型实战 3.1 环境安装 3.2 模型下载 3.3 模型推理 3.4 完整代码 3.5 模型部署 四、总结 一、引言 上一篇对ChatTTS文本转语音模型原理和实战进行了讲解&a…...

ubuntu22.04 编译安装openssl C++ library
#--------------------------------------------------------------------------- # openssl C library # https://www.openssl.org/source/index.html #--------------------------------------------------------------------------- cd /opt/download # 下载openssl-3.0.13…...
百度Agent初体验(制作步骤+感想)
现在AI Agent很火,最近注册了一个百度Agent体验了一下,并做了个小实验,拿它和零一万物(Yi Large)和文心一言(ERNIE-4.0-8K-latest)阅读了相同的一篇网页资讯,输出资讯摘要࿰…...
)
7-491 3名同学5门课程成绩,输出最好成绩及所在的行和列(二维数组作为函数的参数)
编程:数组存储3名同学5门课程成绩 输出最好成绩及所在的行和列 要求:将输入、查找和打印的功能编写成函数 并将二维数组通过指针参数传递的方式由主函数传递到子函数中 输入格式: 每行输入一个同学的5门课的成绩,每个成绩之间空一格,见输入…...
OpenCloudOS开源的操作系统
OpenCloudOS 是一款开源的操作系统,致力于提供高性能、稳定和安全的操作系统环境,以满足现代计算和应用程序的需求。它结合了现代操作系统设计的最新技术和实践,为开发者和企业提供了一个强大的平台。本文将详细介绍 OpenCloudOS 的背景、特性…...

排序题目:多数元素 II
文章目录 题目标题和出处难度题目描述要求示例数据范围进阶 前言解法一思路和算法代码复杂度分析 解法二思路和算法代码复杂度分析 解法三思路和算法代码复杂度分析 题目 标题和出处 标题:多数元素 II 出处:229. 多数元素 II 难度 3 级 题目描述 …...

<电力行业> - 《第1课:电力行业的五大四小》
1 什么是电力行业的五大四小? 我们常说的电力行业的五大四小,指的是电力行业有实力的公司,分为:较强梯队的五大集团、较弱梯队的四小豪门。 五个实力雄厚的集团,分别是: 中国华能集团公司中国大唐集团公…...

数据库定义语言(DDL)
数据库定义语言(DDL) 一、数据库操作 1、 查询所有的数据库 SHOW DATABASES;效果截图: 2、使用指定的数据库 use 2403 2403javaee;效果截图: 3、创建数据库 CREATE DATABASE 2404javaee;效果截图: 4、删除数据…...

mybatis实现多表查询
mybatis高级查询【掌握】 1、准备工作 【1】包结构 创建java项目,导入jar包和log4j日志配置文件以及连接数据库的配置文件; 【2】导入SQL脚本 运行资料中的sql脚本:mybatis.sql 【3】创建实体来包,导入资料中的pojo 【4】User…...

数据结构:队列详解 c++信息学奥赛基础知识讲解
目录 一、队列概念 二、队列容器 三、队列操作 四、代码实操 五、队列遍历 六、案例实操 题目描述: 输入格式: 输出格式: 输入样例: 输出样例: 详细代码: 一、队列概念 队列是一种特殊的线性…...
硬件开发笔记(二十三):贴片电阻的类别、封装介绍,AD21导入贴片电阻原理图封装库3D模型
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/140110514 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...
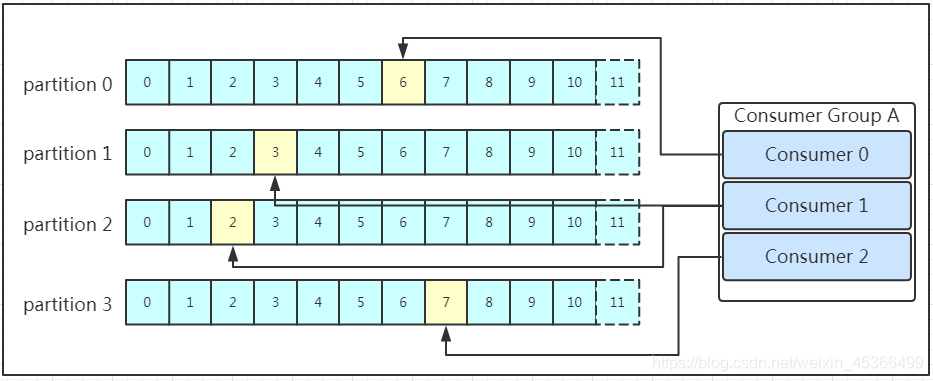
Kafka基本原理详解
(一)概念理解 Apache Kafka是一种开源的分布式流处理平台,专为高性能、高吞吐量的实时数据处理而设计。它最初由LinkedIn公司开发,旨在解决其网站活动中产生的大量实时数据处理和传输问题,后来于2011年开源࿰…...
关卡编辑器之剧情编辑)
【Unity】RPG2D龙城纷争(七)关卡编辑器之剧情编辑
更新日期:2024年7月1日。 项目源码:第五章发布(正式开始游戏逻辑的章节) 索引 简介一、剧情编辑1.对话数据集2.对话触发方式3.选择对话角色4.设置对话到关卡5.通关条件简介 严格来说,剧情编辑不在关卡编辑器界面中完成,只不过它仍然属于关卡编辑的范畴。 在我们的设想中…...

uniapp启动页面鉴权页面闪烁问题
在使用uni-app开发app 打包完成后如果没有token,那么就在onLaunch生命周期里面判断用户是否登录并跳转至登录页。 但是在app中页面会先进入首页然后再跳转至登录页,十分影响体验。 处理方法: 使用plus.navigator.closeSplashscreen() 官网…...

全志H616交叉编译工具链的安装与使用
交叉编译的概念 1. 什么是交叉编译? 交叉编译是指在一个平台上生成可以在另一个平台上运行的可执行代码。例如,在Ubuntu Linux上编写代码,并编译生成可在Orange Pi Zero2上运行的可执行文件。这个过程是通过使用一个专门的交叉编译工具链来…...
深入解析Java和Go语言中String与byte数组的转换原理
1.Java String与byte[]互相转换存在的问题 java中,按照byte[] 》string 》byte[]的流程转换后,byte数据与最初的byte不一致。 多说无益,上代码,本地macos机器执行,统一使用的UTF-8编码。 import java.nio.charset.S…...

什么是strcmp函数
目录 开头1.什么是strcmp函数2.strcmp函数里的内部结构3.strcmp函数的实际运用(这里只列举其一)脑筋急转弯 结尾 开头 大家好,我叫这是我58。今天,我们要来认识一下C语言中的strcmp函数。 1.什么是strcmp函数 strcmp函数来自于C语言中的头文件<str…...

Follow Carl To Grow|【LeetCode】491.递增子序列,46.全排列,47.全排列 II
【LeetCode】491.递增子序列 题意:给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。 数组中可能含有重复元素,如出现两个整数相等,也可以…...

pytorch nn.Embedding 用法和原理
nn.Embedding 是 PyTorch 中的一个模块,用于将离散的输入(通常是词或子词的索引)映射到连续的向量空间。它在自然语言处理和其他需要处理离散输入的任务中非常常用。以下是 nn.Embedding 的用法和原理。 用法 初始化 nn.Embedding nn.Embed…...

Python中常用的有7种值(数据)的类型及type()语句的用法
目录 0.Python中常用的有7种值(数据)的类型Python中的数据类型主要有:Number(数字)、Boolean(布尔)、String(字符串)、List(列表)、Tuple…...

HBuilderX网站打包APP
下载HBuilderX安装包官网地址:https://www.dcloud.io/ 选择HBuilderX极客开发工具 点击DOWNLOAD 点击历史版本,这里为什么不下载最新的版本,是因为我一开始下载的最新版本,打包一直提示cannot find module babel-core 将HBuilder…...

[GESP202512 C++ 三级] 判断题第 3 题 ← strcmp
【题目描述】 strcmp(str1, str2) 返回 0 表示 str1 大于 str2 ,返回正数表示两者相等。(❌️)【题目解析】 返回 0 → 两个字符串完全相等。 返回正数 → str1 > str2。 返回负数 → str1 < str2。...
HSTracker:macOS上免费的炉石传说套牌追踪器终极指南
HSTracker:macOS上免费的炉石传说套牌追踪器终极指南 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker 你是否想在macOS上免费提升炉石传说胜率?HS…...

87456238
8637452...

基于smartcat的智能文件自动分类与归档系统实践
1. 项目概述:一个智能化的文件分类与归档工具最近在整理个人电脑和服务器上的文件时,我又一次陷入了混乱。下载文件夹里混杂着PDF、图片、代码压缩包、安装程序;项目文档和历史备份散落在各处。手动分类不仅耗时,而且容易出错。我…...
)
LangGraph Agent 开发指南(9~工具 Tools)
一、什么是工具? 1.1 通俗解释 想象你有一个智能助手: 没有工具:你: 帮我查一下北京明天的天气助手: 抱歉,我没有联网功能,无法查询实时天气有工具:你: 帮我查一下北京明天的天气助手: 好的,…...
)
运维老鸟复盘:一次CentOS7物理机安装踩坑全记录(从RAID0到安装源验证)
运维实战:CentOS7物理机安装全流程避坑指南 引言 那台尘封已久的联想RD550服务器静静躺在仓库角落,表面覆盖着一层薄灰。作为运维工程师,我们总会遇到这样的挑战——老旧设备突然需要重新部署系统。这次任务看似简单:为这台双盘…...

JiYuTrainer终极指南:三步解锁极域电子教室,恢复学习自由
JiYuTrainer终极指南:三步解锁极域电子教室,恢复学习自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 在数字化教学时代,极域电子教室为学生…...

保姆级教程:将LabelImg标注的VOC数据一键转为Ultralytics RT-DETR训练格式
从VOC到RT-DETR:零基础完成目标检测数据格式转换实战 当你第一次尝试用Ultralytics框架训练RT-DETR模型时,最令人头疼的往往不是模型调参,而是数据准备阶段——特别是当你的标注数据还停留在LabelImg生成的VOC格式(XML文件&#x…...

3分钟掌握网页视频下载:Chrome扩展VideoDownloadHelper完全指南
3分钟掌握网页视频下载:Chrome扩展VideoDownloadHelper完全指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否曾经遇到想…...