七月论文审稿GPT第5版:拿我司七月的早期paper-7方面review数据集微调LLama 3
前言
llama 3出来后,为了通过paper-review的数据集微调3,有以下各种方式
- 不用任何框架 工具 技术,直接微调原生的llama 3,毕竟也有8k长度了
效果不期望有多高,纯作为baseline - 通过PI,把llama 3的8K长度扩展到12k,但需要什么样的机器资源,待查
apple为主,不染为辅 - 阿里云百练大模型服务平台、百度智能云千帆大模型平台对llama 3的支持
文弱zu - 通过llama factory微调3,但等他们适配3(除非我们改factory),类似
llama factory + pi
llama factory + longlora/longqlora - 我们自行改造longqlora(longlora也行,但所需机器资源更大),以适配3
类似之前的经典组合:longqlora(PI + s2-Attn + qlora) + flash attention + zero3 - 基于xtuner微调llama 3
三太子则在与70b微调工作不冲突的前提下,试下这个xtuner
第一部分 拿我司的paper-review数据集通过PI微调LLama 3
1.1 使用PI微调llama3-8b
// 待更
1.2 通过百度智能云的千帆大模型平台微调Llama 3
// 待更
第二部分 基于llama factory和paper-review数据集微调LLama3
LLaMA Factory 现已支持 Llama 3 模型,提供了在 Colab 免费 T4 算力上微调 Llama 3 模型的详细实战教程:https://colab.research.google.com/drive/1d5KQtbemerlSDSxZIfAaWXhKr30QypiK?usp=sharing
同时社区已经公开了两款利用本框架微调的中文版 LLaMA3 模型,分别为:
- Llama3-8B-Chinese-Chat,首个使用 ORPO 算法微调的中文 Llama3 模型,文章介绍:https://zhuanlan.zhihu.com/p/693905042
- Llama3-Chinese,首个使用 DoRA 和 LoRA+ 算法微调的中文 Llama3 模型,仓库地址:https://github.com/seanzhang-zhichen/llama3-chinese
// 待更
第三部分 不用PI和S2-attn,调通Llama-3-8B-Instruct-262k
3.1 基于15K的「情况1:晚4数据」微调Llama 3 8B Instruct 262k
3.1.1 基于1.5K的「情况1:晚4数据」微调Llama 3 8B Instruct 262k
24年5.25日,我司审稿项目组的青睐同学,通过我司的paper-review数据集(先只取了此文情况1中晚期paper-4方面review数据中的1.5K的规模,另,本3.1.1节和3.1.2节都统一用的情况1中的晚期paper-4方面review数据),把llama3调通了
至于llama3的版本具体用的Llama-3-8B-Instruct-262k,这个模型不是量化的版本,其他很多版本虽然扩展长度了,但基本都传的量化后的,这个模型的精度是半精的(当然,还有比较重要的一点是这个模型的下载量比较高)
以下是关于本次微调的部分细节,如青睐所说
- 一开始用A40 + 1.5K数据微调时,用了可以节省所需显存资源的s2atten(S2-attention + flash attention),且由于用了 26k 长度扩展的那个模型,便不用插值PI了
但48g的A40在保存模型的时候显存会超过48g(训练过程中不会出现),而zero3模型保存时会报oom,后来经验证发现原因是:per_eval_device_batch size设置太大导致了oom
总之,用A40 训练时其具有的48g显存是可以训练超过 12k上下文数据的,不一定非得用s2atten(毕竟上面也说了,过程中微调llama3出现oom是因为per_eval_device_batch size设置太大照成的,与训练没啥关系,一个很重要的原因是llama3的词汇表比较大,从32K拓展到了128K,压缩率比较高,导致论文的长度比llama2短,所以A40也放的下) - 后来改成了用A100训练(数据规模还是1.5K),由于用了A100,故关闭了s2atten,直接拿12K的长度开训,且用上了flash atten v2,得到下图这个结果

3.1.2 用5K-15K的「情况1:晚4数据」微调Llama-3
再后来用8卡A40对5K或15K数据微调时,便也都没有用S2-attention(关闭了),使用12K长度 + flash attention v2 微调
代码和上面跑1.5K的数据一样,也还是用的「七月大模型线上营那套longqlora代码」,但把单卡设置成多卡
且直接租2台「8卡的A40」,一台5K的数据,一台15K的数据,直接一块跑

以下是15K数据(晚期paper-4方面review)微调后针对YaRN那篇论文得到的推理结果

接下来,青睐先推理下测试集中的晚期paper,输出4方面review
最后,文弱测评一下,让GPT4-1106、情况1的llama2(也是晚期paper-4方面review),都统一跟人工4方面review做下匹配
// 待更
3.2 基于15K的「情况3:早4数据」微调Llama 3 8B Instruct 262k
3.2.1 llama3版本的情况3 PK 上两节llama3版本的情况1
上两节用了晚期paper-4方面的review微调llama3-262k,类似于此文开头总结的情况1:用晚期paper-4方面review微调llama2
本节咱们将基于15K的早期paper-4方面review,类似于此文开头总结的情况3:用早期paper-4方面review微调llama2
本节微调完之后,自然便可以与以下模型PK(针对哪个情况,则用那个情况的paper,所以评估llama3-262k版本的情况3时,则都统一早期paper)
llama3版本的情况3 当PK 上两节的llama3版本的情况1,情况如下(当然,按理得胜,毕竟情况3的数据更强,相当于都是llama3,但数据质量不一样,当然,无论是llama2 还是llama3,按道理情况3就得好过情况1,毕竟情况3 早4,情况1 晚4,情况3-早4的数据质量是更高的)
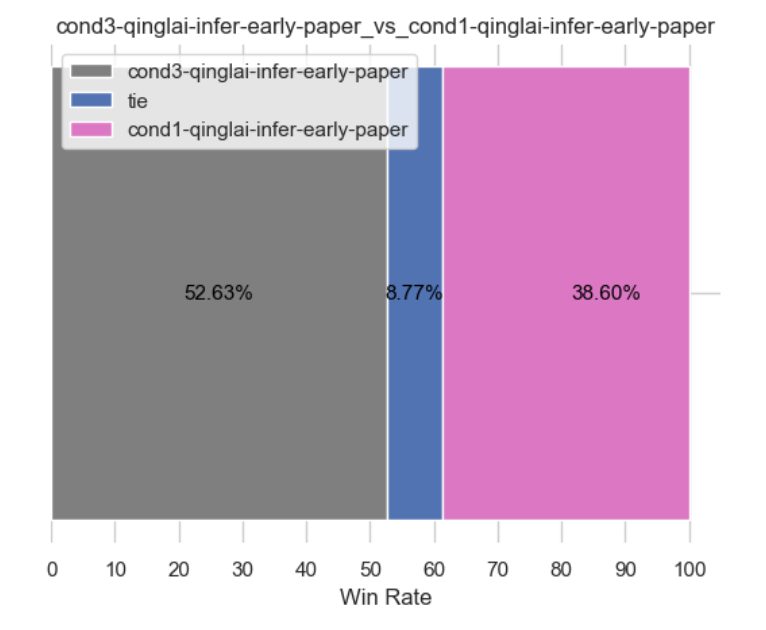
当llama3版本的情况3 PK llama2版本的情况3,按理得胜,毕竟llama3更强
当llama3版本的情况3 PK llama2版本的情况1(以阿荀微调的longqlora 7B做为情况1的基准),按理更得胜,毕竟llama3更强且情况3的数据更强,但目前得到的结果有些奇怪(如下图所示),没达预期,正在找原因中,待后续更新..


// 更多细节暂见我司的:大模型商用项目之审稿微调实战营
3.2.2 llama3情况1 PK llama2情况1——评估微调llama3-8b-instruct-262k基座性能
之后,我们发现使用 15k 情况1样本仅flash attention v2直接微调 llama3-8b-instruct-262k效果不佳,具体可以下面评估结果

- 左图:情况1样本仅flash attention v2直接微调 llama3-8b-instruct-262k
- 右图:情况1样本微调 llama2-7b-chat + PI 扩展长度
可以看到两者性能相当,这个阶段,并没有得到微调llama3性能超过微调llama2的结论,推断可能是llama3-8b-262k原始微调数据集与审稿12k数据集长度分布不太匹配,请看下文第四部分将使用llama-3-8B-Instruct-8k + PI 重新微调,最后获得大幅度性能提升
第四部分 使用PI和flash atten v2 微调llama-3-8B-Instruct-8k
下面训练的数据集皆为15k样本(样本长度普遍9k左右,最长不超过12k),评估方法为基于groud truth 命中数pk,模型取验证集loss最低的模型
此阶段将评估微调llama3-8b-8k与微调llama3-8b-262k&llama2性能差距
4.1 情况3早4数据下的:llama3-8b-instruct-8k + PI 与llama3-8b-instruct-262k 性能pk
经过评估发现,llama3-8b-8k + PI 性能较大幅度领先llama3-8b-262k的性能,如下所示

- 左图:情况3样本仅flash attention v2微调 llama3-8b-8k + PI 扩展长度
- 右图:情况3样本仅flash attention v2直接微调 llama3-8b-instruct-262k
4.2 llama3-8b-instruct-8k + PI 与 llama2-7b-chat 性能pk
4.2.1 llama3下的情况3 强于llama2下的情况3
且经过测试,llama3 在论文审稿场景下的性能确实领先 llama2

- 左图:情况3样本仅flash attention v2微调 llama3-8b-8k + PI 扩展长度
- 右图:情况3样本微调 llama2-7b-chat + PI 扩展长度
4.2.2 llama3下的情况3 更强于llama2下的情况1
此外,下面的这个实验,也无疑再次证明llama3 性能领先 llama2

- 左图:情况3样本仅flash attention v2微调 llama3-8b-8k + PI 扩展长度
- 右图:情况1样本微调 llama2-7b-chat + PI 扩展长度
第五部分 论文审稿GPT第5版:通过15K的早期paper-7方面review数据集(情况4)微调llama3
5.1 llama3-b-8b-8k微调情况4
5.1.1 情况4微调较情况3改动:微调参数、情况4的微调system prompt
一方面是微调参数(主要)
- 为了保证与情况1、情况3更公平的性能对比,选择与前两者相同的迭代次数,情况4推理选择的checkpoint迭代次数为1800,大约1.95个epoch
- 情况3的多次参数组合实验并没有得到较好的效果提升,因此本次情况4的参数基本都是原来的默认值
| 参数 | 说明 |
| batch size=16 | 梯度累计总batch size=16 |
| lr=1e-4 | 学习率的大小 |
| max_prompt_length=11138 | paper 最长的大小,超过将被截取 |
| max_response_length=1150 | review 最长的大小,超过将被截取 |
| save_steps=100 | 迭代100次保存一次模型 |
| num_train_epoch=3 | 迭代3个epoch |
二方面是情况4 微调system prompt
青睐微调的system prompt 采用与阿荀v4版prompt摘要出来的7方面review的大项对齐(详见此文《七月论文审稿GPT第4.5版、第4.6版、第4.8版:提升大模型数据质量的三大要素》的1.2.5节通过7要点摘要prompt第4版重新摘要整理7方面review数据)

比如微调prompt中的Potential项,便与7review中的Potential项对齐,具体为
SYSTEM_PROMPT = """Below is an "Instruction" that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
Instruction:
You are a professional machine learning conference reviewer who reviews a given paper and considers 7 criteria:
** How to evaluate the idea of the paper **
** Compared to previous similar works, what are the essential differences, such as any fundamental differences, improvements, innovations **
** How to evaluate the experimental results in the paper **
** Potential reasons for acceptance **
** Potential reasons for rejection **
** Other suggestions for further improving the quality of the paper **
** Other important review comments **
The given paper is as follows."""5.1.2 情况4推理结果分析
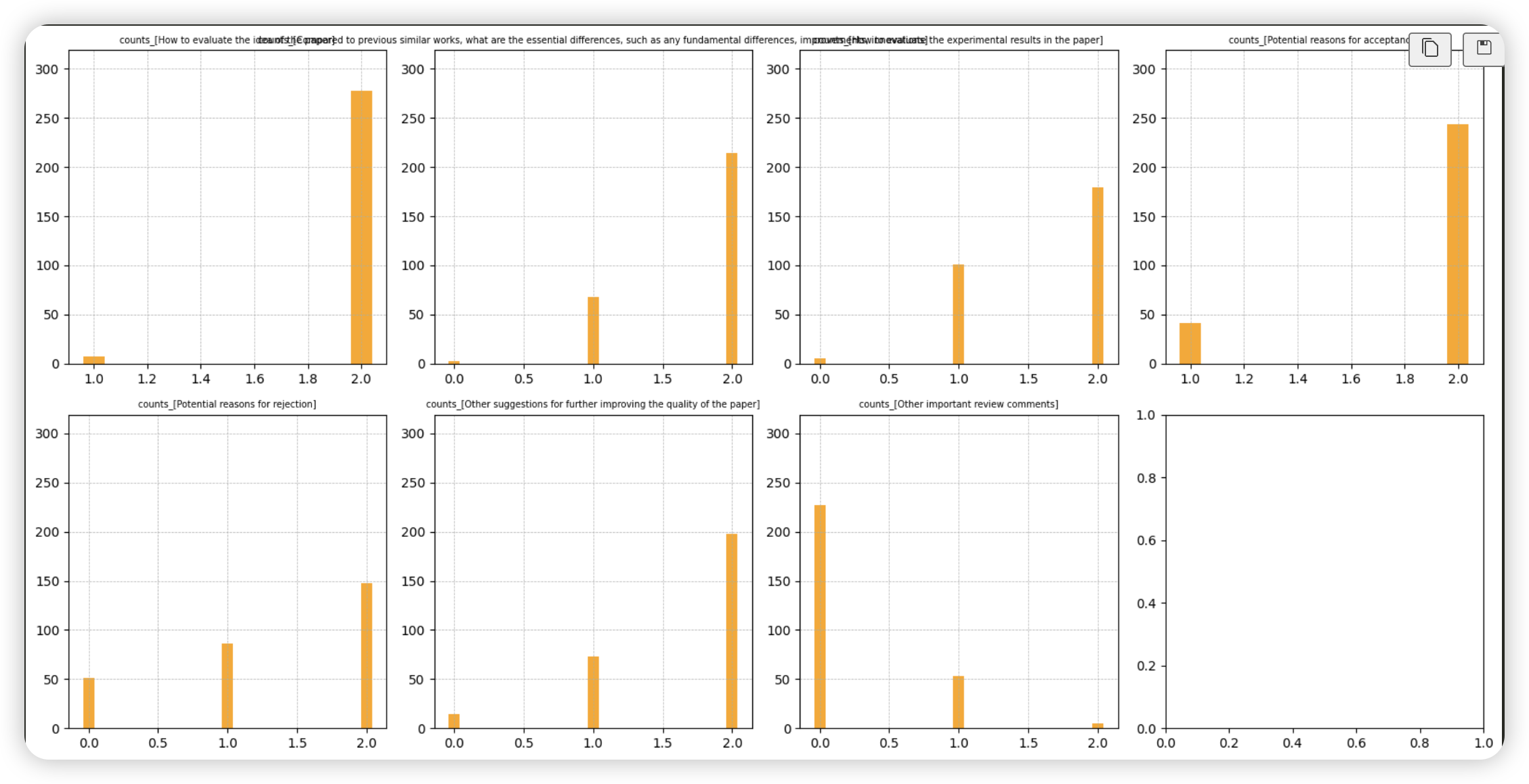
- a) 推理样本的总数为285条
- b) 推理结果中平均子项项数:10.3894
- c) 推理结果中子项总数分布情况(下图左侧),可以看到12条子项的样本占绝大数
- d) 空项数分布情况(下图右侧),可以看到大多数样本含有一个空项(“空项”代表着“拒答”的意思,也就是模型没有给出大项相关的理由),约占50%


- e) 各大项子项数分布情况(下图)
- 1. 可以看到上述d) 空项数分布中的“大多数样本含有一个空项”数据主要集中于最后一项(第二排最后一个图),这是由于训练集存在较多最后大项为空项的数据
- 2. 除了上述最后一大项外,“拒绝理由”(第二排第一个)的大项存在少量的空项,而其他大项中空项的数量较少
5.1.3 微调情况4性能评估
下面训练的数据集皆为15k样本(样本长度普遍9k左右,最长不超过12k),评估方法为基于groud truth 命中数pk
5.1.3.1 情况4数据下:llama3-8b-8k vs llama2-7b-chat
- 下图左侧:情况4 7review仅flash attention v2 微调llama3-8b-instruct-8k
- 下图右侧:情况4 7review微调llama2-7b-chat

结论:同样为情况4 7review数据下,llama3的效果较llama2有较大提升
5.1.3.2 情况4 摘要7方面review vs 情况3 摘要4review
为了保证评估的公平性,对于微调llama3-8b-instruct-8k来说情况3与情况4仅数据不同,微调的策略完全一致
- 下图左侧:情况4 7review仅flash attention v2 微调llama3-8b-instruct-8k
- 下图右侧:情况3 4review仅flash attention v2 微调llama3-8b-instruct-8k

结论:微调策略一致的前提下,摘要7review微调的性能相对于4review有大幅度提升
5.1.3.3 情况4 llama3-8b-8k vs gpt4-1106
- 下图左侧:情况4 7review仅flash attention v2 微调llama3-8b-instruct-8k
- 下图右侧:情况4 paper使用7大项提示工程gpt4-1106的结果
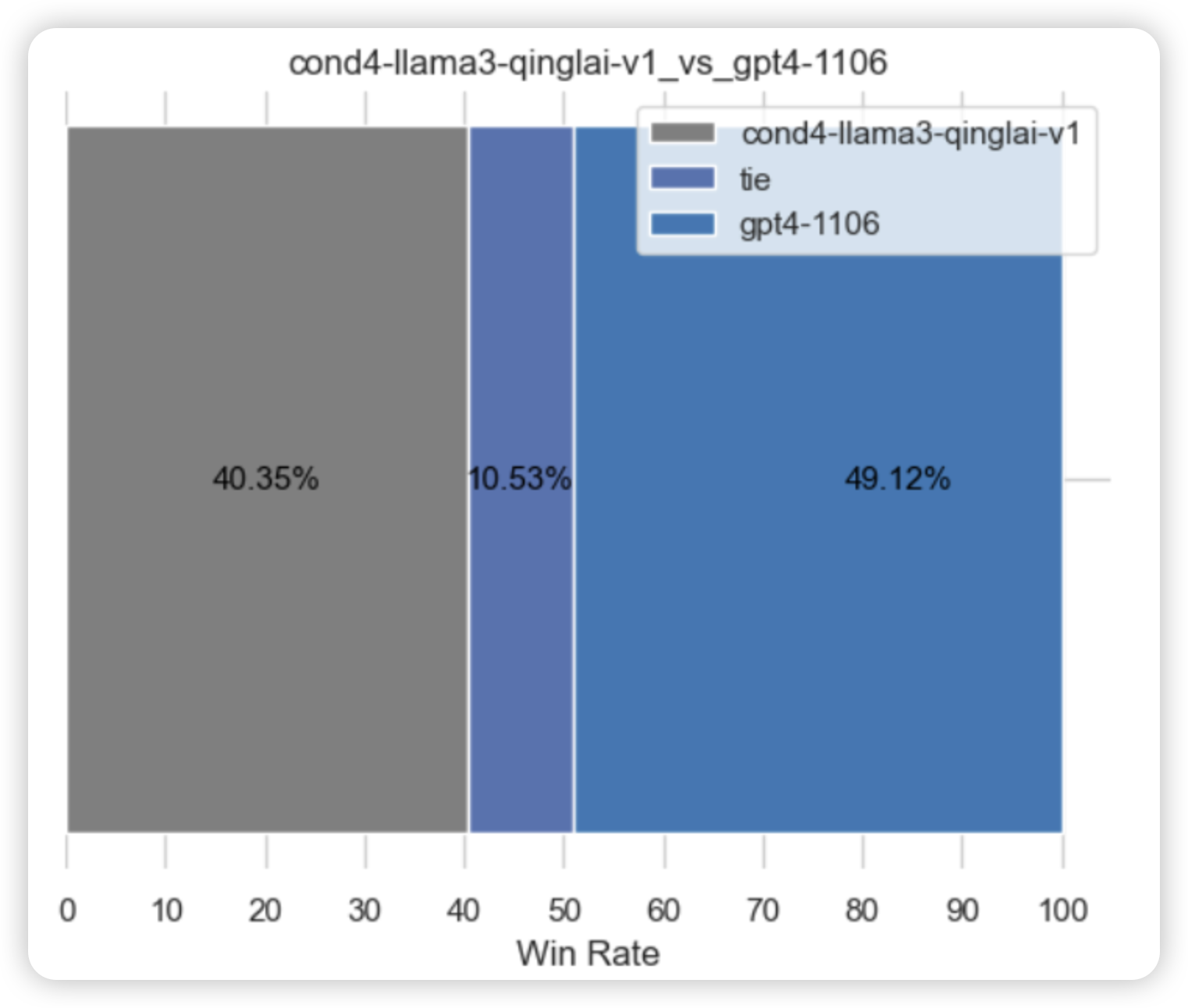
结论:gpt4-1106基于7 大项提示工程生成的观点数相比于基于4 大项提示工程的观点数要多很多,gpt4展现出了“话痨”的特点,虽说其观点的精确率不高,但基于命中数的评估方式还是让gpt4占尽了优势,从1.3节“情况4推理结果分析”可知,llama3推理过程中有不少项存在着“拒答”的现象,这在pk中是处于劣势的
因此,尝试是否可以通过对空项序列也就是“<No related terms>”略加惩罚的方式,合理地降低其采样的概率,减少模型拒答的概率,提升模型的推理性能呢,具体见下文
// 待更
相关文章:
七月论文审稿GPT第5版:拿我司七月的早期paper-7方面review数据集微调LLama 3
前言 llama 3出来后,为了通过paper-review的数据集微调3,有以下各种方式 不用任何框架 工具 技术,直接微调原生的llama 3,毕竟也有8k长度了 效果不期望有多高,纯作为baseline通过PI,把llama 3的8K长度扩展…...

盘古5.0,靠什么去解最难的题?
文|周效敬 编|王一粟 当大模型的竞争开始拼落地,商业化在B端和C端都展开了自由生长。 在B端,借助云计算向千行万业扎根;在C端,通过软件App和智能终端快速迭代。 在华为,这家曾经以通信行业起…...
2.3章节Python中的数值类型
1.整型数值 2.浮点型数值 3.复数 Python中的数值类型清晰且丰富,主要分为以下几种类型,每种类型都有其特定的用途和特性。 一、整型数值 1.定义:整数类型用于表示整数值,如1、-5、100等。 2.特点: Python 3中的…...

每日Attention学习7——Frequency-Perception Module
模块出处 [link] [code] [ACM MM 23] Frequency Perception Network for Camouflaged Object Detection 模块名称 Frequency-Perception Module (FPM) 模块作用 获取频域信息,更好识别伪装对象 模块结构 模块代码 import torch import torch.nn as nn import to…...
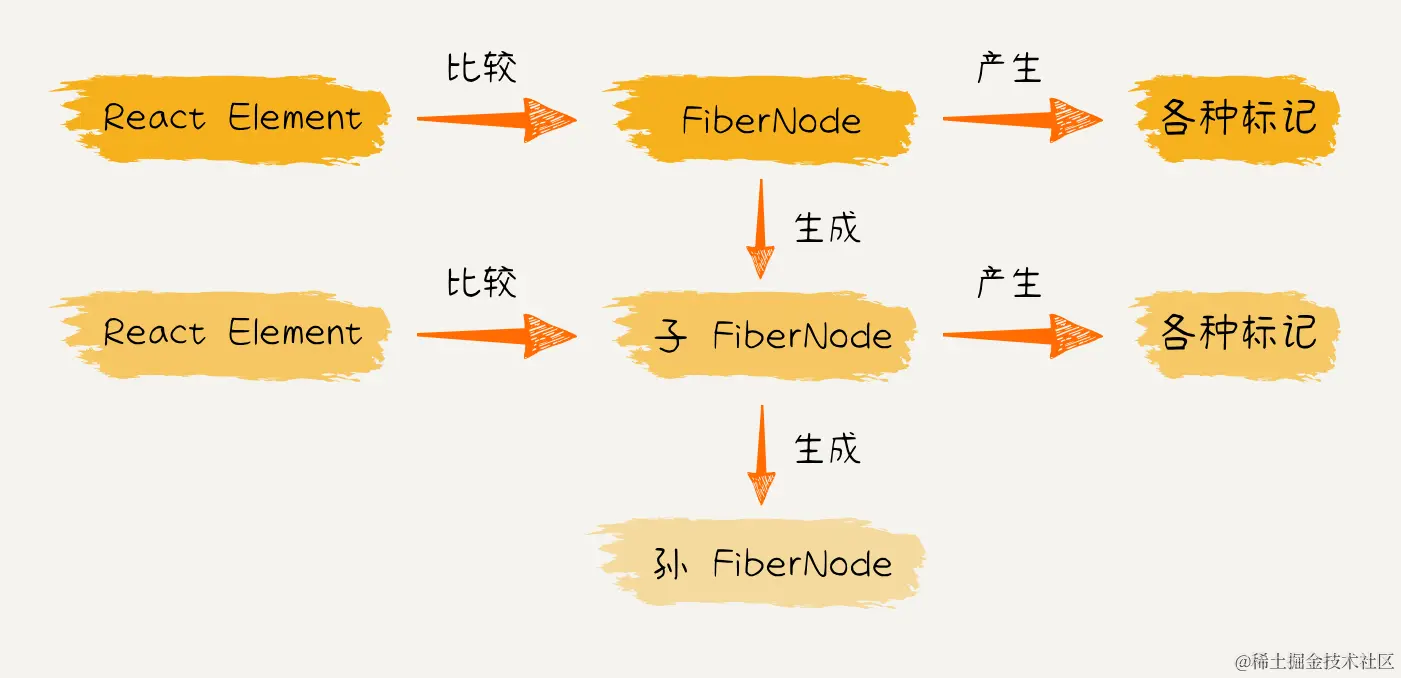
【从0实现React18】 (五) 初探react mount流程 完成核心递归流程
更新流程的目的: 生成wip fiberNode树标记副作用flags 更新流程的步骤: 递:beginWork归:completeWork 在 上一节 ,我们探讨了 React 应用在首次渲染或后续更新时的整体更新流程。在 Reconciler 工作流程中ÿ…...
0-30 VDC 稳压电源,电流控制 0.002-3 A
怎么运行的 首先,有一个次级绕组额定值为 24 V/3 A 的降压电源变压器,连接在电路输入点的引脚 1 和 2 上。(电源输出的质量将直接影响与变压器的质量成正比)。变压器次级绕组的交流电压经四个二极管D1-D4组成的电桥整流。桥输出端…...
HTML5+CSS3+JS小实例:图片九宫格
实例:图片九宫格 技术栈:HTML+CSS+JS 效果: 源码: 【HTML】 <!DOCTYPE html> <html lang="zh-CN"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1…...

湘潭大学软件工程数据库总结
文章目录 前言试卷结构给学弟学妹的一些参考自己的一些总结 前言 自己可能很早很早之前就准备复习了,但是感觉还是没有学到要点,主要还是没啥紧迫的压力,我们是三月份开学,那时候实验室有朋友挺认真开始学习数据库了,…...

Codeforces Testing Round 1 B. Right Triangles 题解 组合数学
Right Triangles 题目描述 You are given a n m nm nm field consisting only of periods (‘.’) and asterisks (‘*’). Your task is to count all right triangles with two sides parallel to the square sides, whose vertices are in the centers of ‘*’-cells. …...

怎样将word默认Microsoft Office,而不是WPS
设置——>应用——>默认应用——>选择"word"——>将doc和docx都选择Microsoft Word即可...

C语言之进程的学习2
Env环境变量(操作系统的全局变量)...
web使用cordova打包Andriod
一.安装Gradel 1.下载地址 Gradle Distributions 2.配置环境 3.测试是否安装成功 在cmd gradle -v 二.创建vite项目 npm init vitelatest npm install vite build 三.创建cordova项目 1.全局安装cordova npm install -g cordova 2. 创建项目 cordova create cordova-app c…...

内卷情况下,工程师也应该了解的项目管理
简介:大家好,我是程序员枫哥,🌟一线互联网的IT民工、📝资深面试官、🌹Java跳槽网创始人。拥有多年一线研发经验,曾就职过科大讯飞、美团网、平安等公司。在上海有自己小伙伴组建的副业团队&…...

【解锁未来:深入了解机器学习的核心技术与实际应用】
解锁未来:深入了解机器学习的核心技术与实际应用 💎1.引言💎1.1 什么是机器学习? 💎2 机器学习的分类💎3 常用的机器学习算法💎3.1 线性回归(Linear Regression)…...

1-3.文本数据建模流程范例
文章最前: 我是Octopus,这个名字来源于我的中文名–章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…...
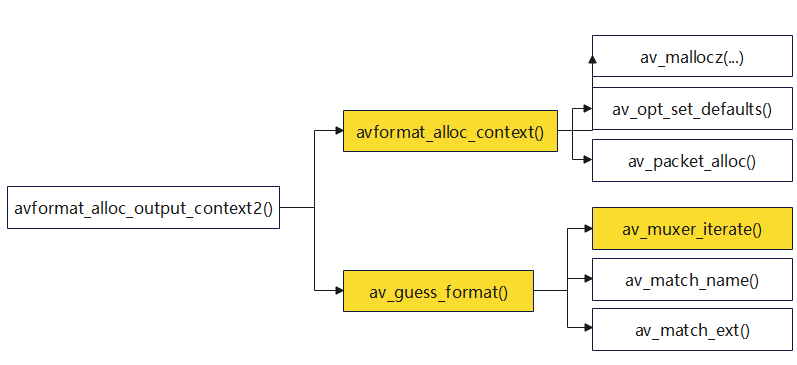
【FFmpeg】avformat_alloc_output_context2函数
【FFmpeg】avformat_alloc_output_context2函数 1.avformat_alloc_output_context21.1 初始化AVFormatContext(avformat_alloc_context)1.2 格式猜测(av_guess_format)1.2.1 遍历可用的fmt(av_muxer_iterate࿰…...

Flask 缓存和信号
Flask-Caching Flask-Caching 是 Flask 的一个扩展,它为 Flask 应用提供了缓存支持。缓存是一种优化技术,可以存储那些费时且不经常改变的运算结果,从而加快应用的响应速度。 一、初始化配置 安装 Flask-Caching 扩展: pip3 i…...
基于weixin小程序农场驿站系统的设计
管理员账户功能包括:系统首页,个人中心,农场资讯管理,用户管理,卖家管理,用户分享管理,分享类型管理,商品信息管理,商品类型管理 开发系统:Windows 架构模式…...

JAVA将List转成Tree树形结构数据和深度优先遍历
引言: 在日常开发中,我们经常会遇到需要将数据库中返回的数据转成树形结构的数据返回,或者需要对转为树结构后的数据绑定层级关系再返回,比如需要统计当前节点下有多少个节点等,因此我们需要封装一个ListToTree的工具类…...

设计模式——开闭、单一职责及里氏替换原则
设计原则是指导软件设计和开发的一系列原则,它们帮助开发者创建出易于维护、扩展和理解的代码。以下是你提到的几个关键设计原则的简要说明: 开闭原则(Open/Closed Principle, OCP): 开闭原则由Bertrand Meyer提出&am…...

3分钟掌握FSearch:Linux系统文件搜索效率提升300%的终极方案
3分钟掌握FSearch:Linux系统文件搜索效率提升300%的终极方案 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 还在为Linux系统中寻找文件而烦恼吗ÿ…...
)
别再死记硬背了!图解STM32按键状态机:从消抖到双击识别的完整逻辑(蓝桥杯适用)
图解STM32按键状态机:从消抖到双击识别的可视化逻辑拆解 在嵌入式开发中,按键处理看似简单,实则暗藏玄机。许多初学者在实现短按、长按和双击识别时,往往陷入代码调试的泥潭——明明逻辑看起来正确,实际运行却总出现误…...

别再只盯着CVE-2017-7529复现了,聊聊Nginx缓存机制下的那些‘信息泄露’风险
深入解析Nginx缓存机制与敏感信息防护实践 Nginx作为现代Web架构的核心组件,其高效的缓存机制在提升性能的同时也隐藏着不容忽视的安全隐患。当开发者们热衷于讨论CVE-2017-7529这类高危漏洞的复现时,我们更需要将目光投向日常配置中那些容易被忽视的信息…...

【大白话说Java面试题 第55题】【JVM篇】第15题:JVM有哪些垃圾收集算法?
📌 PDF:大白话说Java面试题 — 02-JVM篇 第15题:JVM有哪些垃圾收集算法 📚 回答: 核心概念: JVM 的垃圾收集算法是垃圾回收的核心机制,决定了如何高效地标记和回收内存中的垃圾对象。常见的垃…...
)
【新手实用技能指南】OpenClaw 2.7.1 实用 Skill 技能全推荐(含安装包)
OpenClaw 实用 Skill 技能推荐|办公效率全面提升(新手必开) OpenClaw(小龙虾)的核心优势在于Skill 技能扩展,开启适配技能后,AI 可脱离单纯对话模式,自主完成各类电脑操作任务。本文…...

CST实战指南 | 场路协同仿真中的元器件模型导入与验证
1. 场路协同仿真中的元器件模型导入基础 我第一次接触CST场路协同仿真时,最头疼的就是如何把各种元器件模型正确导入到仿真环境中。经过多次项目实践,我发现这其实是个系统性工程,需要根据不同的仿真场景和元器件类型采取不同的处理策略。 在…...

Linux系统变更追踪工具whatdiditdo:实现文件级监控与审计
1. 项目概述:一个追踪系统变更的“时光机”最近在排查一个线上服务故障,问题最终定位到是某个依赖库在几天前的一次静默升级上。为了搞清楚到底是谁、在什么时候、改了什么东西,我不得不翻遍了近一周的服务器操作日志、CI/CD流水线记录和版本…...

Kubernetes二进制文件管理器KBM:高效管理kubectl、helm等工具版本
1. 项目概述:为什么我们需要一个Kubernetes二进制文件管理器? 如果你和我一样,长期在多个Kubernetes集群、不同版本的环境之间切换,或者需要为CI/CD流水线、离线环境准备特定版本的 kubectl 、 helm 、 kustomize 等工具&am…...

树莓派AI智能体进化框架:轻量级边缘持续学习实践
1. 项目概述:一个面向树莓派的AI智能体进化框架最近在折腾树莓派上的AI应用时,发现了一个挺有意思的项目,叫pk-pi-hermes-evolve。光看这个名字,就能拆出不少信息量:“pk”可能指代项目作者或一个特定系列,…...

GitHub仓库自动化同步工具xpull:原理、配置与实战应用
1. 项目概述:一个被低估的GitHub数据同步利器 如果你经常在GitHub上管理多个仓库,或者需要将某个仓库的特定分支、标签甚至整个提交历史同步到另一个仓库,那么你很可能经历过手动操作的繁琐。无论是为了备份、镜像、还是将上游的更新合并到自…...