自然语言处理基本知识(1)
一 分词基础
NLP:搭建了计算机语言和人类语言之间的转换



1 精确分词,试图将句子最精确的分开,适合文本分析
>>> import jieba
>>> content = "工信处女干事每月经过下属科室"
>>> jieba.cut(content,cut_all = False)
<generator object Tokenizer.cut at 0x0000026F1DA55DE0>
>>> jieba.lcut(content cut_all = False)File "<stdin>", line 1jieba.lcut(content cut_all = False)^
SyntaxError: invalid syntax
>>> jieba.lcut(content, cut_all = False)
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.797 seconds.
Prefix dict has been built successfully.
['工信处', '女干事', '每月', '经过', '下属', '科室']
2 全模式分词,把句子中所有的可以成词的词语都扫描出来,速度很快,但是不能消除歧义
>>> jieba.lcut(content, cut_all = Ture)
Traceback (most recent call last):
>>> jieba.lcut(content, cut_all = True)
['工信处', '处女', '女干事', '干事', '每月', '月经', '经过', '下属', '科室']
3 搜索引擎模式分词, 在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词
>>> jieba.cut_for_search(content)
<generator object Tokenizer.cut_for_search at 0x0000026F1DA55DE0>
>>> jieba.lcut_for_search(content)
['工信处', '干事', '女干事', '每月', '经过', '下属', '科室']
4 繁体字

5 用户自定义字典
jieba内部有自己的一个词典库,但是允许用户自己自定义补充词典

>>> import jieba
>>> jieba.lcut("八一双鹿更名为八一南昌篮球队")
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.729 seconds.
Prefix dict has been built successfully.
['八', '一双', '鹿', '更名', '为', '八一', '南昌', '篮球队']
>>> jieba.load_userdict("./userdict.txt")
>>> jieba.lcut("八一双鹿更名为八一南昌篮球队")
['八一双鹿', '更名', '为', '八一', '南昌', '篮球队']

cmd常用编辑命令:
退出python环境,ctrl+z, 然后回车
创建文件:vim
写文件
6 中英文分词工具 hanlp
中文分词
import hanlp
tokenizer = hanlp.load('CTB6_CONVSEG')
tokenizer('工信处女干事每月经过下属科室')
英文分词
import hanlp
tokenizer = hanlp.utils.rules.tokenizer_english('CTB6_CONVSEG')
tokenizer('Mr. Hankcs bought hankcs.com for 1.5 thousand dollars.')
(1) 命名实体识别:把任意的专有名词,识别出来




import hanlp
//中文实体识别
recongnizer = hanlp.load(hanlp.pretrained.ner.MSRA_NER_BERT_BASE_ZH)
recongnizer (list('上海华安工业(集团)公司董事长谭旭光和秘书张晚霞来到美国纽约现代艺术博物馆参观'))//英文实体识别
recongnizer = hanlp.load(hanlp.pretrained.ner.CONLL03_NER_BERT_BASE_UNCASED_EN)
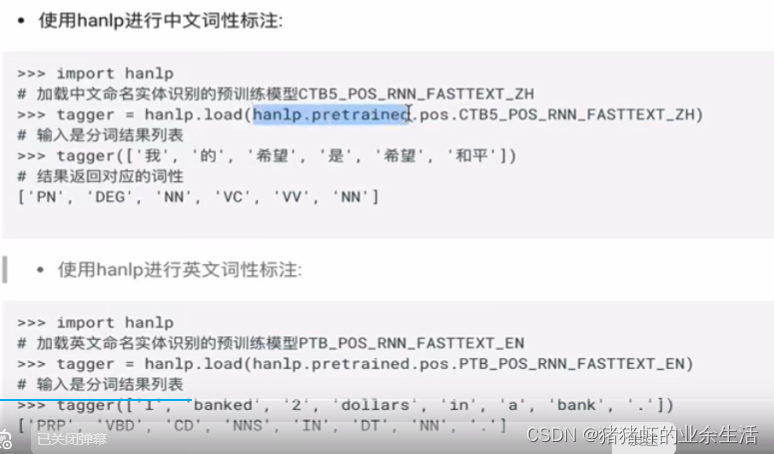
6 词性标注,每一个次不仅要分开,还要标记词性。是建立在分词的基础上


>>> import jieba.posseg as pseg
>>> pseg.lcut("我爱北京天安门")
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.725 seconds.
Prefix dict has been built successfully.
[pair('我', 'r'), pair('爱', 'v'), pair('北京', 'ns'), pair('天安门', 'ns')]
二 文本张量
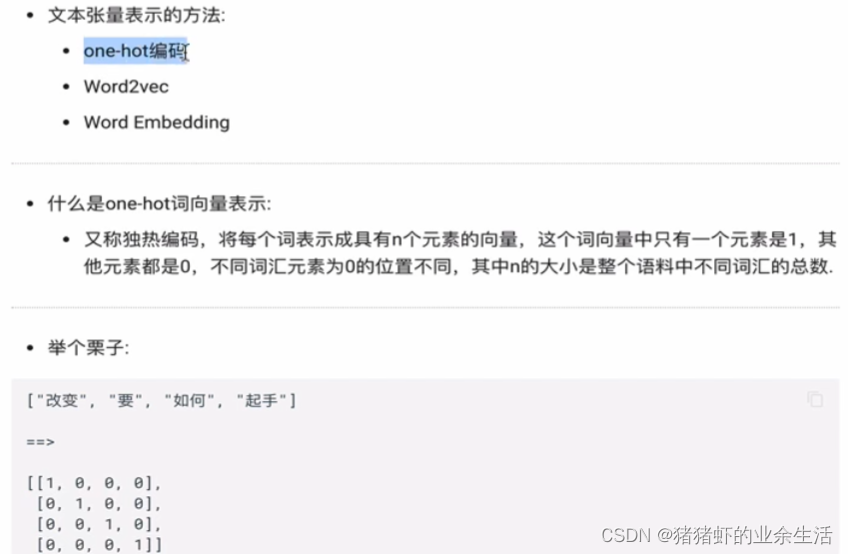
1 ONE-HOT
- 维度灾难,数据多长,就需要多长的维度
- 数据之间的相似性无法衡量,余弦相似度计算,相似度,所有结果都是0

矩阵里面的每一行数据,表示一个词。计算机能识别,一一对应



(1)one-hot编码器实现
from sklearn.externals import joblib
from keras.preprocessing.text import Tokenizer
vocab = {"周杰伦","陈奕迅"," 王力宏", "李宗盛 " }
//num_words=None:意味着不限制词汇表的大小
//char_level=False:表示按词处理文本,而不是按字符
t = Tokenizer(num_words = None, char_level = False)
t.fit_on_texts(vocab) //使用提供的词汇表对Tokenizer进行训练,构建词汇索引
for token in vocab:zero_list = [0]*len(vocab) //创建一个与词汇表长度相等的全零列表zero_list//t.texts_to_sequences([token])将词转换为其对应的索引序列。//[0][0]从嵌套列表中提取实际的索引值//-1调整索引,使其从0开始。token_index = t.texts_to_sequences([token])[0][0] -1zero_list [token_index ] = 1print(token, " one-hot 编码是:",zero_list )//使用joblib.dump保存训练好的Tokenizer对象到指定路径
tokenizer_path = "./Tokenizer"
joblib.dump(t,tokenizer_path)
李宗盛 one-hot 编码是: [1, 0, 0, 0]
周杰伦 one-hot 编码是: [0, 1, 0, 0]
陈奕迅 one-hot 编码是: [0, 0, 1, 0]
王力宏 one-hot 编码是: [0, 0, 0, 1]
(2)one-hot编码器使用
from sklearn.externals import joblib
t = joblib.load("./Tokenizer");
token = "周杰伦"
token_index = t.texts_to_sequences([token])[0][0] -1
zero_list = [0]*4
zero_list[token_index] = 1
print(token, "one-hot code :",zero_list)

(3)one-hot 编码优劣

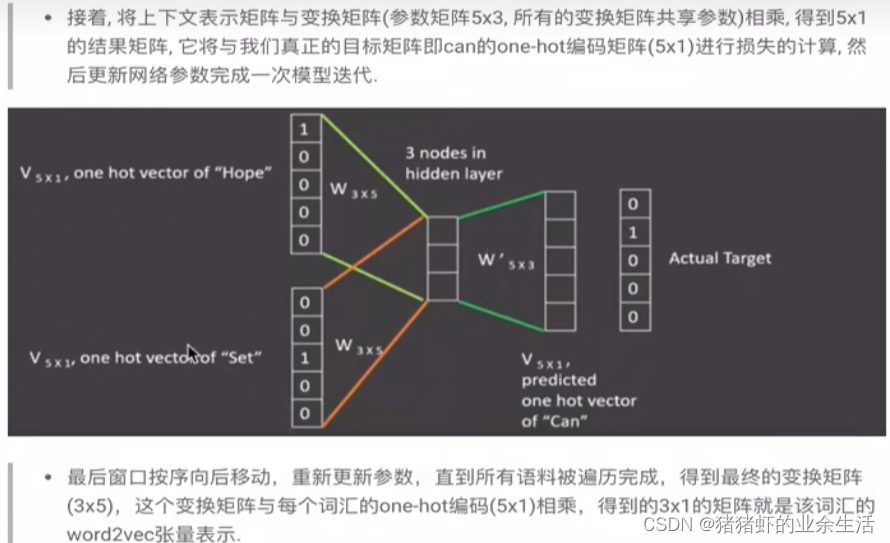
2 word2vec
- 重要假设,离得越近的词语相似度越高
- 中心词的上下文是由什么来规定的,由窗口大小来限定
- 窗口限制外的非上下文词,太多了,导致负样本太多,所以只能采样一部分来作为负样本
- 如何评估词向量:可视化;输出相关度比较高的词语;类比实验
缺点

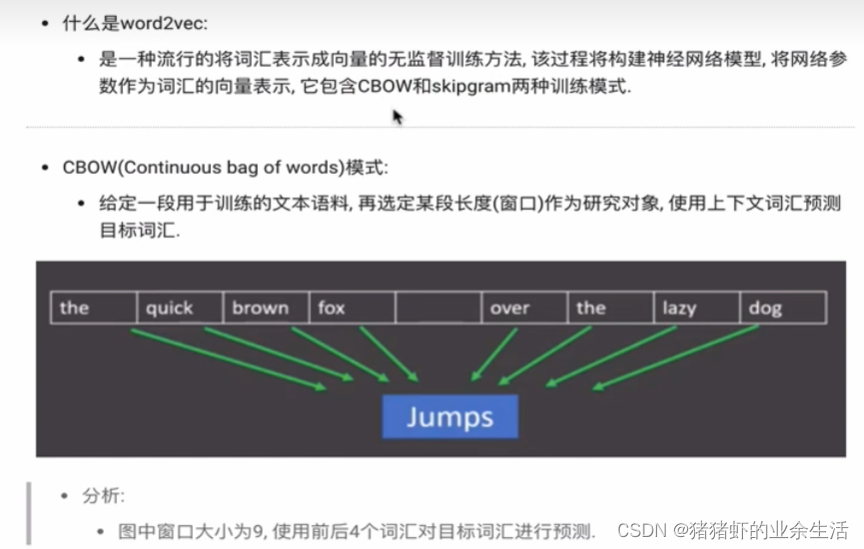
(1) CBOW
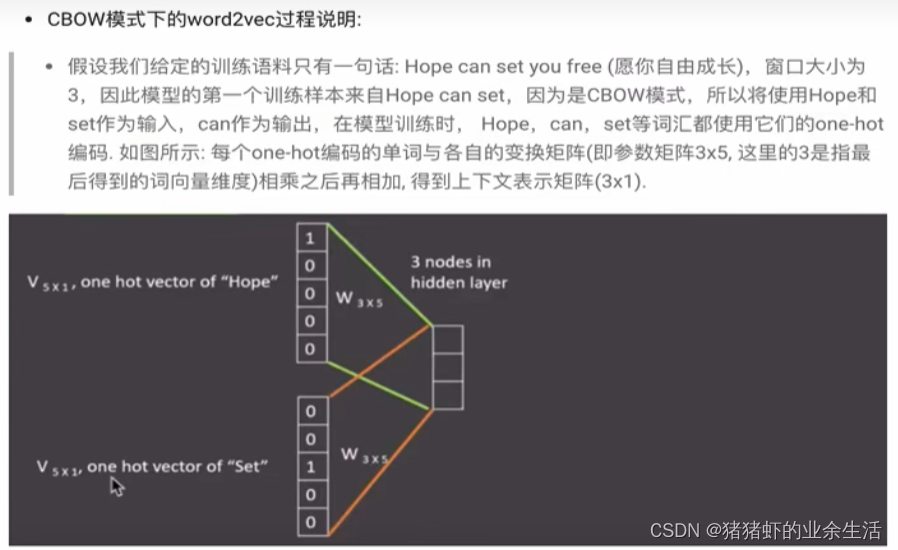
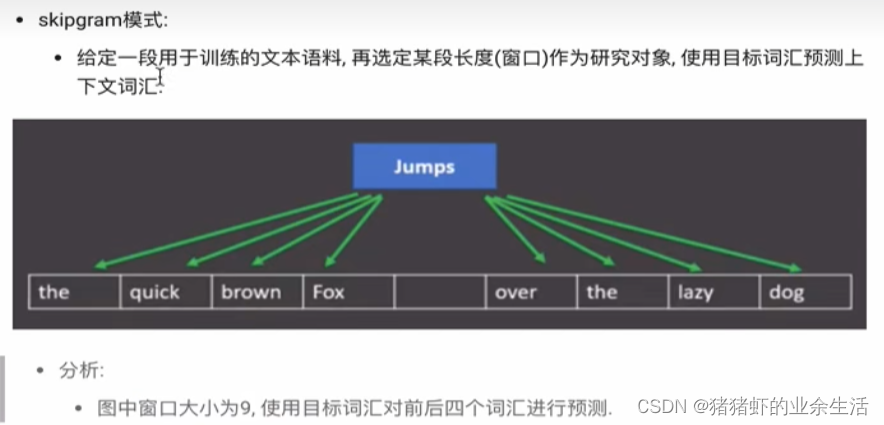
(2) skipgram
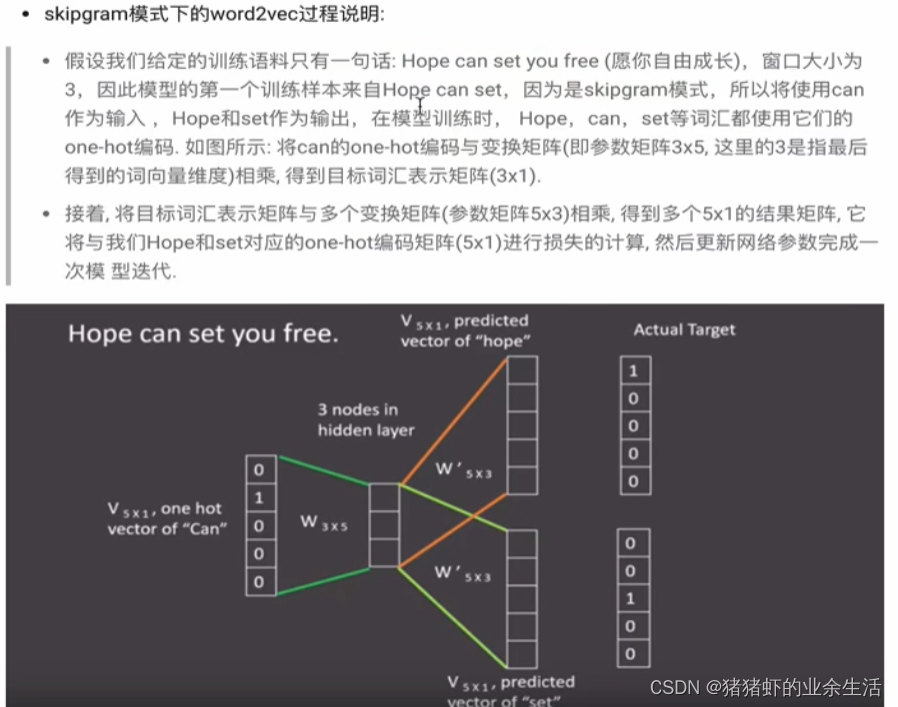

(3) skipgram
(4) 案例运行

cmd上进入python环境运行
- 数据准备
mkdir data
unzip data/enwik9.zip -d data
head -10 data/enwik9
perl wikifil.pl data/enwik9 >data/fil9
head -c 80 data/fil9


- 训练词向量
三 CMD 内安装jupyter
参考链接,可在不同地方安装该插件
-
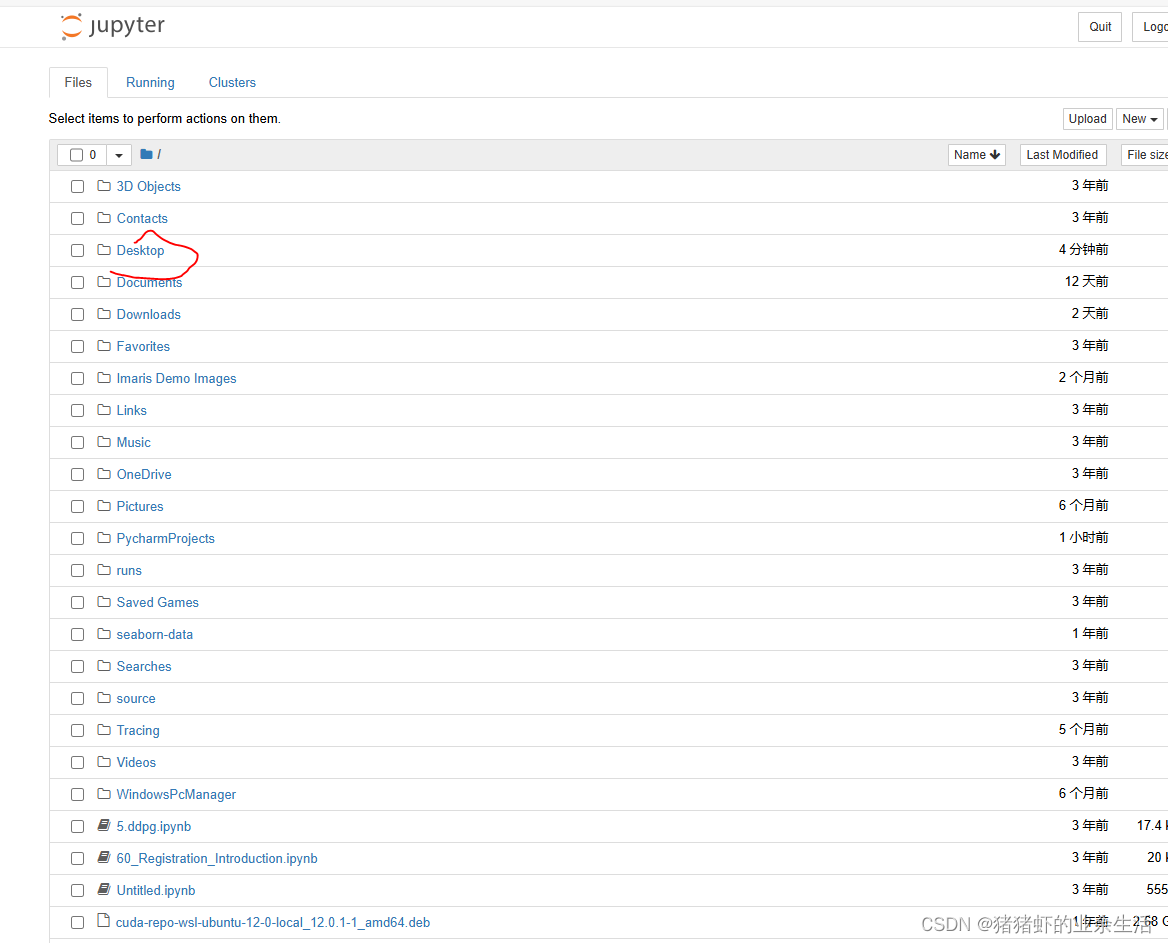
直接打开CMD,然后直接输入
pip install jupyter即安装完毕 -
然后输入
jupyter notebook即运行jupyter,会出现一个网页,然后选Desktop,右上角创建Folder,最后在Folder里面创建.py文件即可
相关文章:
自然语言处理基本知识(1)
一 分词基础 NLP:搭建了计算机语言和人类语言之间的转换 1 精确分词,试图将句子最精确的分开,适合文本分析 >>> import jieba >>> content "工信处女干事每月经过下属科室" >>> jieba.cut(content,cut_all …...

Java中的数据加密与安全传输
Java中的数据加密与安全传输 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们来探讨一下在Java中如何实现数据加密与安全传输。 随着互联网的普及和网络…...

UG NX二次开发(C++)-根据草图创建拉伸特征(UFun+NXOpen)
1、前言 UG NX是基于特征的三维建模软件,其中拉伸特征是一个很重要的特征,有读者问如何根据草图创建拉伸特征,我在这篇博客中讲述一下草图创建拉伸特征的UG NX二次开发方法,感兴趣的可以加入QQ群:749492565,或者在评论区留言。 2、在UG NX中创建草图,然后创建拉伸特征 …...

TS_开发一个项目
目录 一、编译一个TS文件 1.安装TypeScript 2.创建TS文件 3.编译文件 4.用Webpack打包TS ①下载依赖 ②创建文件 ③启动项目 TypeScript是微软开发的一个开源的编程语言,通过在JavaScript的基础上添加静态类型定义构建而成。TypeScript通过TypeScript编译器或…...
)
2024年华为OD机试真题-传递悄悄话 -C++-OD统一考试(C卷D卷)
2024年OD统一考试(D卷)完整题库:华为OD机试2024年最新题库(Python、JAVA、C++合集) 题目描述: 给定一个二叉树,每个节点上站着一个人,节点数字表示父节点到该节点传递悄悄话需要花费的时间。 初始时,根节点所在位置的人有一个悄悄话想要传递给其他人,求二叉树所有节…...
eclipse基础工程配置( tomcat配置JRE环境)
文章目录 I eclipse1.1 工程配置1.2 编译工程1.3 添加 JRE for the project build pathII tomcat配置JRE环境2.1 Eclipse编辑tomcat运行环境(Mac版本)2.2 Eclipse编辑tomcat运行环境(windows版本)2.3 通过tomcat7W.exe配置运行环境(windows系统)I eclipse 1.1 工程配置 …...

Spring Boot 学习第八天:AOP代理机制对性能的影响
1 概述 在讨论动态代理机制时,一个不可避免的话题是性能。无论采用JDK动态代理还是CGLIB动态代理,本质上都是在原有目标对象上进行了封装和转换,这个过程需要消耗资源和性能。而JDK和CGLIB动态代理的内部实现过程本身也存在很大差异。下面将讨…...

Linux[高级管理]——Squid代理服务器的部署和应用(传统模式详解)
🏡作者主页:点击! 👨💻Linux高级管理专栏:点击! ⏰️创作时间:2024年6月24日11点11分 🀄️文章质量:95分 目录 ————前言———— Squid功能 Squ…...

使用Vue 2 + Element UI搭建后台管理系统框架实战教程
后台管理系统作为企业内部的核心业务平台,其界面的易用性和功能性至关重要。Vue 2作为一个成熟的前端框架,以其轻量级和高效著称,而Element UI则是一套专为桌面端设计的Vue 2组件库,它提供了丰富的UI元素和组件,大大简…...

Carla安装教程
1.前言 对于从事自动驾驶的小伙伴而言,或多或少应该都接触过一些的仿真软件,今天要给大家介绍的这款仿真软件应该算的上是业界非常有名的一款仿真软件——carla。 目前carla的学习教程也还是蛮多的,但是写的都不是很全,在配置的…...

【PYG】处理Cora数据集分类任务使用的几个函数log_softmax,nll_loss和argmax
文章目录 log_softmax解释作用示例解释输出 nll_loss解释具体操作示例代码解释 nll_losslog_softmaxcross_entropy解释代码示例解释 argmax()解释作用示例代码解释示例输出 log_softmax F.log_softmax(x, dim1) 是 PyTorch 中的一个函数,用于对输入张量 x 应用 log…...

Labview绘制柱状图
废话不多说,直接上图 我喜欢用NXG风格,这里我个人选的是xy图。 点击箭头指的地方 选择直方图 插值选择第一个 直方图类型我选的是第二个效果如图。 程序部分如图。 最后吐槽一句,现在看CSDN好多文章都要收费了,哪怕一些简单的入…...

使用Python实现一个简单的密码管理器
文章目录 一、项目概述二、实现步骤2.1 安装必要的库2.2 设计密码数据结构2.3 实现密码加密和解密2.4 实现主要功能2.4.1 添加新密码2.4.2 显示所有密码2.4.3 查找特定密码2.4.4 更新密码2.4.5 删除密码 2.5 实现用户界面 三、代码示例3.1 加密和解密示例3.2 用户界面示例 在现…...

【云原生】服务网格(Istio)如何简化微服务通信
🐇明明跟你说过:个人主页 🏅个人专栏:《未来已来:云原生之旅》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、微服务架构的兴起 2、Istio:服务网格的佼…...

spring boot 整合 sentinel
注意版本问题 我这是jdk11 、spring boot 2.7.15 、 alibaba-sentinel 2.1.2.RELEASE <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.15</version><…...
蜜雪冰城小程序逆向
app和小程序算法一样 小程序是wasm...

pbootcms提交留言成功后跳转到指定的网址
pbootcms在线留言表单提交成功后,如何跳转到指定的网址,默认提交留言后留在原来的页面,如果提交后需要跳转到指定网址,我们需要对文件进行修改。首先我们打开/core-/function/helper.php文件找到第162行左右代码: ech…...

16、matlab求导、求偏导、求定积分、不定积分、数值积分和数值二重积分
0)前言 在MATLAB中,对函数进行不同形式的求导、求积分操作是非常常见的需求,在工程、科学等领域中经常会用到。以下是关于求导、求积分以及数值积分的简介: 求导:在MATLAB中可以使用diff函数对函数进行求导操作。diff…...
MySQL 9.0创新版发布!功能又进化了!
作者:IT邦德 中国DBA联盟(ACDU)成员,10余年DBA工作经验, Oracle、PostgreSQL ACE CSDN博客专家及B站知名UP主,全网粉丝10万 擅长主流Oracle、MySQL、PG、高斯及Greenplum备份恢复, 安装迁移,性能优化、故障…...

后端系统的安全性
后端系统的安全性 后端系统的安全性是任何Web应用或服务的核心组成部分,它涉及保护数据、用户隐私以及系统免受恶意攻击。以下是后端安全的一些关键点: 认证和授权:确保只有经过身份验证的用户才能访问特定资源。这通常包括使用用户名/密码…...

智能工厂能源监测管理平台解决方案
在某大型制造企业的生产园区,管理人员长期面临着一系列能源管理困境:由于厂区各个电表仍依赖人工抄录,数据滞后且易出错,导致管理层无法实时掌握每条生产线甚至每台关键设备的真实耗电情况;同时,由于电表分…...

USGv6新规驱动IPv6单栈部署:从协议原理到实战测试的全面指南
1. 从USGv6新版规范看IPv6单栈部署的必然性与实战准备最近,行业里关于IPv6单栈网络(IPv6-Only)的讨论又热了起来。这阵风潮的源头,是美国国家标准与技术研究院(NIST)近期更新了其“美国政府IPv6配置文件”&…...

代码托管工具在GEO工具中表现分析
随着生成式引擎优化(GEO)在技术选型决策中的影响持续扩大,AI搜索工具对代码托管、DevOps及制品管理工具的推荐结果,正在成为企业评估平台价值的重要参考。2026年,不同规模和需求的团队在借助AI搜索获取工具推荐时&…...

毫米波雷达测心率靠谱吗?聊聊TI方案在车载健康监测中的真实挑战与未来
毫米波雷达在车载健康监测中的技术突破与实践挑战 当方向盘成为健康监测的第一道防线,毫米波雷达正在重新定义智能座舱的生物感知能力。不同于医院里笨重的心电监护仪或智能手表上时灵时不灵的光电传感器,藏在汽车顶棚或座椅背后的毫米波芯片,…...

设计系统文本化:用YAML/JSON统一管理设计令牌,实现多端一致与自动化
1. 项目概述:当设计系统遇上纯文本 最近在跟一个跨职能团队协作时,我们遇到了一个典型的老大难问题:设计师在Figma里更新了一个按钮的主色调,前端工程师在代码库里改了对应的CSS变量,但负责撰写产品文档和营销材料的同…...

别再只会用ActivePart了!CATIA二次开发中,如何用C#递归遍历任意复杂结构树?
CATIA二次开发进阶:用C#递归算法征服任意复杂装配树 在CATIA二次开发领域,ActivePart就像新手司机的自动挡——简单易用却限制重重。当面对包含数百个零件的飞机发动机装配体,或是横跨多个产品的汽车底盘系统时,仅能操作当前激活零…...

运放数据手册没明说的秘密:5种ESD保护电路全解析与避坑指南
运放数据手册没明说的秘密:5种ESD保护电路全解析与避坑指南 在工业现场、医疗设备或精密测量系统中,运算放大器往往需要直面静电放电(ESD)的威胁。许多工程师在选型时只关注增益带宽积和噪声指标,却忽略了数据手册中那…...

基于MCP协议构建智能Telegram助手:连接AI与外部服务的实践指南
1. 项目概述:一个连接AI与Telegram的智能桥梁如果你正在寻找一种方法,让你在Telegram上使用的AI助手(比如ChatGPT、Claude等)能够“活”起来,不仅能聊天,还能帮你查天气、看新闻、管理待办事项,…...

Python自动化数据简报:从零构建代码驱动的报告系统
1. 项目概述:数据简报的“瑞士军刀”在数据驱动的时代,无论是数据分析师、产品经理还是业务运营,每天都要面对海量的数据源和复杂的分析需求。我们常常陷入这样的困境:为了一个简单的数据洞察,需要打开多个工具&#x…...

DeepSeek-R1大模型微调实战:从LoRA原理到完整项目部署指南
1. 项目概述:一个面向开发者的开源大模型微调项目最近在开源社区里,一个名为FareedKhan-dev/train-deepseek-r1的项目引起了我的注意。乍一看,这只是一个托管在代码托管平台上的仓库,但如果你像我一样,在过去几年里深度…...