【论文阅读】伸缩密度比估计:Telescoping Density-Ratio Estimation
文章目录
- 一、文章概览
- (一)问题提出
- (二)文章工作
- 二、判别比估计和密度鸿沟问题
- 三、伸缩密度比估计
- (一)核心思想
- (二)路标创建
- (三)桥梁构建
- (四)TRE应用于互信息估计
- (五)TRE 应用于基于能量的建模
- 四、实验
- (一)1维峰值比率的设置及TRE的表现
- (二)高维度比率问题及TRE在大互信息(MI)估计中的表现
- (三)SpatialMultiOmniglot 上的 MI 估计和表示学习
- (四)MNIST 上基于能量的建模
一、文章概览
(一)问题提出
密度比估计:
- 通过密度比估计进行的无监督学习是机器学习中的一个强大范例,是该领域重大进展的源泉
- 根据数据样本估计p/q比率,而不单独估计分子和分母。
判别性密度比估计:
- 训练神经网络分类器来区分两组样本,因为对于许多损失函数,可以从最佳分类器中提取 p/q 比值。
- 这种判别性方法在多个领域中产生了先进的结果,是无监督学习的基石。
密度鸿沟问题:
- 在两个密度显著不同的情况下,分类器就可以通过相对较差的密度比估计来获得几乎完美的精度。
- 实验表明,每当 p 和 q 之间的KL散度超过几十自然单位时,这种情况尤为明显。
(二)文章工作
伸缩密度比估计(TRE) 框架:
- 用于克服密度鸿沟问题,实现在高维空间中准确估计高度不同的密度之间的比率
- 采用由两个步骤组成的“分而治之”策略:
- 第一步是逐渐将 p 中的样本传输到 q 中的样本,创建中间数据集链
- 然后估计沿着这条链的连续数据集之间的密度比,与原始比率 p/q 不同,这些“链式比率”可以通过分类准确估计
- 最后通过伸缩乘积组合链式比率以获得原始密度比 p/q 的估计。
实验证明,TRE 相对于现有的单一比率方法在互信息估计、表示学习和能量基建模等任务中能够显著改善表现。
- 在互信息估计的背景下,TRE 可以准确估计 30+ nat 的大 MI 值
- 表示学习实验结果证实,TRE 比一系列现有的单比率基线提供了显着的收益
- 基于能量的建模背景下,TRE 可以被视为噪声对比估计 的扩展,可以更有效地扩展到高维数据。
二、判别比估计和密度鸿沟问题
假设p和q是有样本的两个密度,满足 p ( x ) > 0 p(x)>0 p(x)>0, q ( x ) > 0 q(x)>0 q(x)>0,可以估计密度比 r ( x ) = p ( x ) / q ( x ) r(x)=p(x)/q(x) r(x)=p(x)/q(x) 来区分 p p p 和 q q q中的样本。分类器的损失假设为广泛使用的逻辑损失:
L ( θ ) = − E x 1 ∼ p log ( r ( x 1 ; θ ) 1 + r ( x 1 ; θ ) ) − E x 2 ∼ q log ( 1 1 + r ( x 2 ; θ ) ) L(\theta)=-E_{x_1\sim p}\log (\frac{r(x_1;\theta)}{1+r(x_1;\theta)})-E_{x_2\sim q}\log (\frac{1}{1+r(x_2;\theta)}) L(θ)=−Ex1∼plog(1+r(x1;θ)r(x1;θ))−Ex2∼qlog(1+r(x2;θ)1)
其中 r ( x ; θ ) r(x;\theta) r(x;θ)是非负比率估计模型,为了强制非负性, r r r通常表示为无约束函数的指数。
密度鸿沟问题:
- 可能的误差来源有很多:
- 使用错误指定的模型
- 不完善的优化算法
- 上式中的期望的蒙特卡洛近似所产生的不准确性
由于样本量有限而产生的蒙特卡罗误差实际上足以引发密度鸿沟问题,如果我们使用n=10000的样本量并最小化有限样本损失,最终得到的估计值 θ ^ \hat{\theta} θ^ 就会远离渐近极小值 θ ∗ = a r g m i n L ( θ ) \theta^*=argmin L(\theta) θ∗=argminL(θ)。
L n ( θ ) = ∑ i = 1 n − log ( r ( x 1 i ; θ ) 1 + r ( x 1 i ; θ ) ) − log ( 1 1 + r ( x 2 i ; θ ) ) , x i i ∼ p , x 2 i ∼ q L^n(\theta)=\sum_{i=1}^n -\log (\frac{r(x_1^i;\theta)}{1+r(x_1^i;\theta)})-\log (\frac{1}{1+r(x_2^i;\theta)}), \ x_i^i\sim p,x_2^i\sim q Ln(θ)=i=1∑n−log(1+r(x1i;θ)r(x1i;θ))−log(1+r(x2i;θ)1), xii∼p,x2i∼q对不同的样本量重复相同的实验,可以凭经验测量该方法的样本效率.对于绘制的情况,我们看到样本量的指数增加只会导致估计值线性下降错误。这一经验结果与理论结果一致,即基于密度比的 KL 散度下限仅对于 nats 数量呈指数级的样本大小是严格的。

三、伸缩密度比估计
(一)核心思想
为了方便起见,进行如下符号转换: p = = p 0 p == p_0 p==p0, q = = p m q == p_m q==pm ,并通过伸缩乘积扩展比率:
p 0 ( x ) p m ( x ) = p 0 ( x ) p 1 ( x ) p 1 ( x ) p 2 ( x ) . . . p m − 2 ( x ) p m − 1 ( x ) p m − 1 ( x ) p m ( x ) \frac{p_0(x)}{p_m(x)}=\frac{p_0(x)}{p_1(x)}\frac{p_1(x)}{p_2(x)}... \frac{p_{m-2}(x)}{p_{m-1}(x)}\frac{p_{m-1}(x)}{p_m(x)} pm(x)p0(x)=p1(x)p0(x)p2(x)p1(x)...pm−1(x)pm−2(x)pm(x)pm−1(x)
理想情况下, p k p_k pk 能使分类器无法轻松将其与其两个相邻密度区分开。因此,该方法的两个关键组成部分是:
- 路标创建:将样本 { x 0 1 , . . . , x 0 n } \{x_0^1,...,x_0^n\} {x01,...,x0n}从 p 0 p_0 p0分布逐渐转换到分布为 p m p_m pm的样本 { x m 1 , . . . , x m n } \{x_m^1,...,x_m^n\} {xm1,...,xmn}。转换的每一步会获得一个新数据集 { x k 1 , . . . , x k n } \{x_k^1,...,x_k^n\} {xk1,...,xkn},每个中间数据集都可以被视为来自隐式分布 p k p_k pk 的样本,可称为路标分布。
- 桥梁构建:桥梁构建方法涉及学习一组参数化的密度比率,这些比率是在连续的分布对之间估算的。用数学符号表示为 r k ( x ; θ k ) ≈ p k ( x ) p k + 1 ( x ) r_k(x;\theta_k)\approx \frac{p_k(x)}{p_{k+1}(x)} rk(x;θk)≈pk+1(x)pk(x),其中 k = 0 , . . . , m − 1 k=0,...,m-1 k=0,...,m−1,每个 r k r_k rk都是一个非负函数,被称为桥梁。
然后通过桥的乘积给出原始比率的估计:
r ( x ; θ ) = ∏ k = 0 m − 1 r k ( x ; θ k ) ≈ ∏ k = 0 m − 1 p k ( x ) p k + 1 ( x ) = p 0 ( x ) p m ( x ) r(x;\theta)=\prod_{k=0}^{m-1}r_k(x;\theta_k)\approx \prod_{k=0}^{m-1}\frac{p_k(x)}{p_{k+1}(x)}=\frac{p_0(x)}{p_m(x)} r(x;θ)=k=0∏m−1rk(x;θk)≈k=0∏m−1pk+1(x)pk(x)=pm(x)p0(x)
其中 θ θ θ 是所有 θ k θ_k θk 向量的串联。
(二)路标创建
考虑两种简单的、确定性的路标创建机制:线性组合和维度混合。
线性组合: 给定一个随机对 x 0 ∼ p 0 x_0 \sim p_0 x0∼p0 和 x m ∼ p m x_m \sim p_m xm∼pm,通过以下方式定义第 k k k 个路标:
x k = 1 − α k 2 x 0 + α k x m , k = 0 , . . . , m x_k=\sqrt{1-\alpha_k^2}x_0+\alpha_kx_m,\ k=0,...,m xk=1−αk2x0+αkxm, k=0,...,m
其中 α k α_k αk形成从0到1递增的序列,用于控制 x k x_k xk到 x 0 x_0 x0的距离。
维度混合: 将两个向量的不同维度子集进行拼接。给定一个长度为 d d d 的向量 x x x ,将其划分为 m m m 个长度为 d / m d/m d/m 的子向量,表示为 x = ( x [ 1 ] , . . . , x [ m ] ) x = (x[1], ..., x[m]) x=(x[1],...,x[m]),每个 x [ i ] x[i] x[i]的长度为 d / m d/m d/m 。使用此表示法下,可以通过以下方式定义第 k 个路标:
x k = ( x m [ 1 ] , . . . , x m [ k ] , x 0 [ k + 1 ] , . . . , x 0 [ m ] ) , k = 0 , . . . , m x_k=(x_m[1],...,x_m[k],x_0[k+1],...,x_0[m]),\ k=0,...,m xk=(xm[1],...,xm[k],x0[k+1],...,x0[m]), k=0,...,m
(三)桥梁构建
每个桥 r k ( x ; θ k ) r_k(x; θ_k) rk(x;θk) 都可以使用逻辑损失函数通过二元分类来学习。因此,解决这个分类任务集合是一个多任务学习 (MTL) 问题, MTL 中的两个关键问题是如何共享参数和如何定义联合目标函数。
参数共享:
将桥 r k ( x ; θ k ) r_k(x; θ_k) rk(x;θk) 的构造分为两个阶段:
- 共享的隐藏向量 f k ( x ) f_k(x) fk(x):
- 是一个深度神经网络,其参数在不同的桥梁 r k r_k rk中是共享的
- 每个桥梁有自己的预激活尺度和偏置,用于每个隐藏单元
- 头部映射:
- 将隐藏向量 f k ( x ) f_k(x) fk(x)映射到标量 log r k ( x ; θ k ) \log r_k(x;\theta_k) logrk(x;θk)
- 映射可以是线性的或者二次的,具体的参数化根据实验的具体情况而定
TRE 损失函数:
-
TRE 损失函数由 m 个逻辑损失的平均值给出:
L T R E ( θ ) = 1 m ∑ k = 0 m − 1 L k ( θ k ) L k ( θ k ) = − E x k ∼ p k log ( r k ( x k ; θ k ) 1 + r k ( x k ; θ k ) ) − E x k + 1 ∼ q k + 1 log ( 1 1 + r ( x k + 1 ; θ k ) ) L_{TRE}(\theta)=\frac{1}{m}\sum_{k=0}^{m-1}L_k(\theta_k)\\ L_k(\theta_k)=-E_{x_k\sim p_k}\log (\frac{r_k(x_k;\theta_k)}{1+r_k(x_k;\theta_k)})-E_{x_{k+1}\sim q_{k+1}}\log (\frac{1}{1+r(x_{k+1};\theta_k)}) LTRE(θ)=m1k=0∑m−1Lk(θk)Lk(θk)=−Exk∼pklog(1+rk(xk;θk)rk(xk;θk))−Exk+1∼qk+1log(1+r(xk+1;θk)1) -
训练中的样本分配与潜在问题:
- 在训练过程中,每个比率估计器 r k r_k rk会看到不同的样本: r 0 r_0 r0会看到接近真实数据的样本,即从 p 0 p_0 p0和 p 1 p_1 p1中采样的样本;最终的比率 r m − 1 r_{m-1} rm−1则会看到来自 p m − 1 p_{m-1} pm−1和 p m p_m pm的样本
- 这种训练样本分配方式可能会在训练和部署之间造成不匹配的问题。因为在学习之后,我们希望在相同的输入 x x x 上评估所有的比率 r k r_k rk,然而每个比率估计器在训练期间看到的输入分布不同,这可能导致在新测试点上的泛化能力受到影响。
实验结果没有显示这种不匹配是一个问题,这表明尽管在训练期间看到不同的输入,每个比率都能够推广到新的测试点。我们推测,这种泛化是通过参数共享来促进的,这使得每个比率估计器都可以间接地受到来自所有路标分布的样本的影响。尽管如此,对这个泛化问题进行更深入的分析值得进一步开展工作。
(四)TRE应用于互信息估计
两个随机变量 u u u 和 v v v 之间的互信息 (MI) 可以写为:
I ( u , v ) = E p ( u , v ) [ log r ( u , v ) ] , r ( u , v ) = p ( u , v ) p ( u ) p ( v ) I(u,v)=E_{p(u,v)}[\log r(u,v)],\ r(u,v)=\frac{p(u,v)}{p(u)p(v)} I(u,v)=Ep(u,v)[logr(u,v)], r(u,v)=p(u)p(v)p(u,v)
从联合密度和边际乘积生成样本:
从联合密度 p ( u , v ) p(u,v) p(u,v)中获取样本 ( u , v ) (u,v) (u,v),通过将数据集中的 v v v 向量打乱,可以从边际乘积 p ( u ) p ( v ) p(u)p(v) p(u)p(v)中获取样本。具体来说,我们保留 u u u 不变,将 v v v 在数据集中进行随机重排。
路标样本的生成:
为了执行TRE(密度比率估计),我们需要生成路标样本:
先从联合密度 p ( u , v ) p(u,v) p(u,v)中获取一个样本 x 0 = ( u , v 0 ) x_0=(u,v_0) x0=(u,v0),从边际乘积 p ( u ) p ( v ) p(u)p(v) p(u)p(v) 中取一个样本 x m = ( u , v m ) x_m=(u,v_m) xm=(u,vm),其中 u u u 保持固定,仅 v v v 不变,然后使用路标构建机制来生成中间路标样本 x k = ( u , v k ) x_k=(u,v_k) xk=(u,vk),其中 k = 0 , . . . , m k=0,...,m k=0,...,m。
(五)TRE 应用于基于能量的建模
基于能量的模型 (EBM) 是一个灵活的非负函数参数族 { ϕ ( x ; θ ) } \{\phi(x; θ)\} {ϕ(x;θ)},其中每个函数与概率密度成正比。给定密度为 p ( x ) p(x) p(x) 的数据分布样本,基于能量的建模的目标是找到一个参数 θ ∗ θ^* θ∗,使得 ϕ ( x ; θ ∗ ) \phi(x; θ^*) ϕ(x;θ∗)近似于 c p ( x ) cp(x) cp(x) ,其中 c c c为一个正常数。
本文作者考虑 ϕ ( x ; θ ) = r ( x ; θ ) q ( x ) \phi(x; θ)=r(x;\theta)q(x) ϕ(x;θ)=r(x;θ)q(x), q q q是可以从中采样的已知密度(例如高斯流或归一化流),而 r r r 是一个无约束的正函数。给定这个参数化,最优 r r r 简单地等于密度比 p ( x ) / q ( x ) p(x)/q(x) p(x)/q(x),因此学习 EBM 的问题变成了估计密度比的问题,这可以通过 TRE 来解决。由于 TRE 实际上估计比率乘积,因此最终EBM的形式为:
ϕ ( x ; θ ) = ∏ k = 0 m − 1 r k ( x ; θ k ) q ( x ) \phi(x;\theta)=\prod_{k=0}^{m-1}r_k(x;\theta_k)q(x) ϕ(x;θ)=k=0∏m−1rk(x;θk)q(x)
四、实验
(一)1维峰值比率的设置及TRE的表现
实验设置:
- 使用单参数二次分类器的极端峰值高斯 p (σ = 10−6) 和宽高斯 q (σ = 1) 之间的密度比估计

- 使用二次形式的桥梁,其中 b k b_k bk设置为其真实值,而 w k w_k wk被重新参数化为 e x p ( θ k ) exp(\theta_k) exp(θk)以避免出现不必要的对数尺度。
log r k ( x ) = w k x 2 + b k \log r_k(x)=w_kx^2+b_k logrk(x)=wkx2+bk
实验结果:
- 样本效率:TRE在使用100个样本时就获得了比单一比率估计使用100,000个样本更好的解决方案,显示出三数量级的改进。
- 准确性提升:通过样本效率曲线,可以清楚地看到TRE在所有样本规模下都具有显著的准确性提升。

(二)高维度比率问题及TRE在大互信息(MI)估计中的表现
实验设置:
- x ∈ R 2 d x\in R^{2d} x∈R2d是一个高斯随机变量,具有块对角协方差矩阵。每个块是2x2的矩阵,对角线上为1,非对角线上为0.8,目标是估计这个高斯分布与标准正态分布之间的比率。
- 使用二次形式桥梁,其中 W k W_k Wk是对称矩阵, b k b_k bk是偏置项
log r k ( x ) = x T W k x + b k \log r_k(x)=x^TW_kx+b_k logrk(x)=xTWkx+bk
实验结果:
单一比率估计在MI值大于20 nats时变得非常不准确,相比之下,TRE能够准确估计高达80 nats的MI值,即使对于320维的变量也是如此。

(三)SpatialMultiOmniglot 上的 MI 估计和表示学习
实验设置:
- SpatialMultiOmniglot问题源于Omniglot数据集,其中字符被空间排列成一个 n × n n \times n n×n 的网格,每个网格位置包含来自固定字母表的字符。在此设置中,每个网格位置被视为一个类别随机变量,其实现是相应字母表中的字符。我们形成的网格对 ( u , v ) (u,v) (u,v) 使得对应的网格位置包含按字母顺序排列的字符。根据这种设置,可以计算出真实的MI值。
- 每个桥梁使用的可分离架构形式如下,其中 g g g和 f k f_k fk是14层卷积ResNets, f k f_k fk使用了参数共享方案。
log r k ( u , v ) = g ( u ) T W k f k ( v ) \log r_k(u,v)=g(u)^TW_kf_k(v) logrk(u,v)=g(u)TWkfk(v) - 路标构建使用按维度混合机制,其中 m = n 2 m=n^2 m=n2,即一次混合一个维度。
实验结果:
- MI估计(左图):结果显示,只有TRE能够准确估计高达约35 nats的高MI值。
- 表示学习(右图):随着网格中字符数量的增加(即MI的增加),所有单一密度比率基线的性能显著下降。相比之下,TRE始终获得超过97%的准确率。

(四)MNIST 上基于能量的建模
能量模型的形式:
ϕ ( x ; θ ) = ∏ k = 0 m − 1 r k ( x ; θ k ) q ( x ) \phi(x;\theta)=\prod_{k=0}^{m-1}r_k(x;\theta_k)q(x) ϕ(x;θ)=k=0∏m−1rk(x;θk)q(x)
其中 q q q是预先指定的“噪声”分布,从中可以进行采样,比率的乘积由TRE给出。
实验设置:
- 使用MNIST手写数字数据集,每个样本是28x28像素的灰度图像,代表一个手写数字。
- 考虑三种噪声分布的选择:多变量高斯分布、高斯copula、有耦合层的有理二次神经样条流(RQ-NSF)
- 每种噪声分布都首先通过最大似然估计拟合到数据上。
TRE中构建路标:
每种噪声分布可以表示为标准正态分布的可逆变换。也就是说每个随机变量可以表示为 F ( z ) F(z) F(z),其中 z ∼ N ( 0 , I ) z\sim N(0,I) z∼N(0,I)。我们可以在z-空间中通过线性组合方式生成路标,然后映射回x-空间,进而得到:
x k = F ( 1 − α k 2 F − 1 ( x 0 ) + α k F − 1 ( x m ) ) x_k=F(\sqrt{1-\alpha_k^2}F^{-1}(x_0)+\alpha_kF^{-1}(x_m)) xk=F(1−αk2F−1(x0)+αkF−1(xm))
能量基准模型的构建:
每个桥梁 r k ( x ) r_k(x) rk(x)的形式为:
log r k ( x ) = − f k ( x ) T W k f k ( x ) − f k ( x ) T b k − c k \log r_k(x)=-f_k(x)^TW_kf_k(x)-f_k(x)^Tb_k-c_k logrk(x)=−fk(x)TWkfk(x)−fk(x)Tbk−ck
其中 f k ( x ) f_k(x) fk(x)是一个18层卷积ResNet, W k W_k Wk被约束为正定矩阵。这个约束确保了EBM的对数密度有一个上限。
- 通过表格中的估计对数似然来定量评估学习到的EBM模型。

- 通过下图中从模型中随机采样的样本来进行定性评估

从上述结果可以看出,对于简单的噪声分布选择,单一比率估计在高维情况下表现不佳,只有在使用复杂的神经密度估计器(如RQ-NSF)时表现良好。相比之下,TRE在所有噪声选择中都显示出改进,这通过近似对数似然和样本的视觉保真度来衡量。特别是在高斯噪声分布下,TRE的改进尤为显著:每维比特数(bits per dimension, bpd)大约降低了0.66,对应着大约360 nats的改进。此外,生成的样本显著更加连贯,并且在视觉保真度上比RQ-NSF样本要好。
相关文章:
【论文阅读】伸缩密度比估计:Telescoping Density-Ratio Estimation
文章目录 一、文章概览(一)问题提出(二)文章工作 二、判别比估计和密度鸿沟问题三、伸缩密度比估计(一)核心思想(二)路标创建(三)桥梁构建(四&…...
语句大全)
MongoDB数据库 MQL (MongoDB Query Language)语句大全
基本命令 连接到 MongoDB mongo显示所有数据库 show dbs选择(或创建)数据库 db集合操作 显示当前数据库中的所有集合 show collections创建集合 db.createCollection("myCollection")删除集合 db.myCollection.drop()文档操作 插入文…...
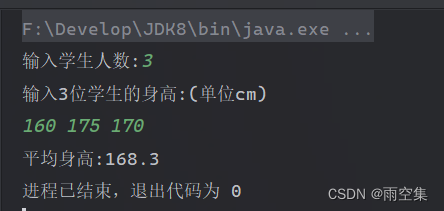
Java代码基础算法练习-计算平均身高-2024.07.02
任务描述: n个同学站成一排,求它们的平均身高 解决思路: 输入的学生人数为 for 循环次数,循环中每输入一个值就添加在总数中,循环结束总数除以对应的学生人数得到平均身高 代码示例: package a4_2024_07;…...
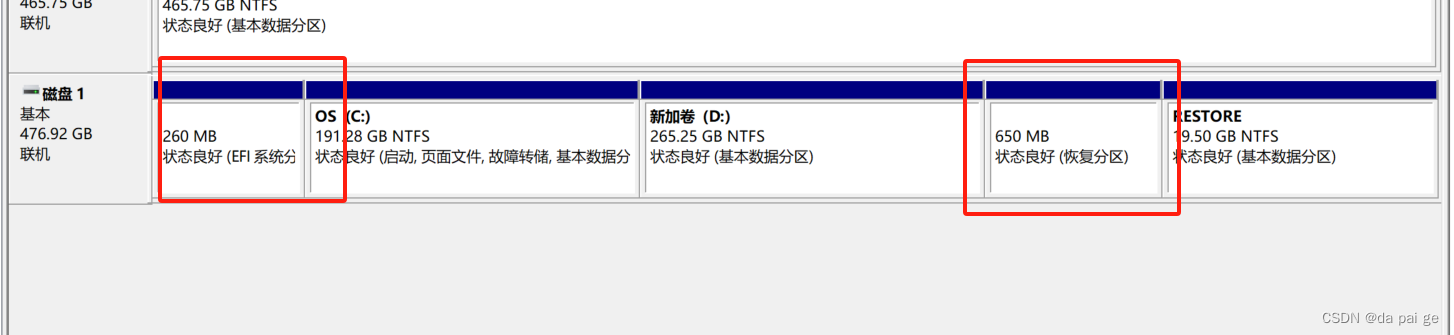
BIOS设置与系统分区
📑打牌 : da pai ge的个人主页 🌤️个人专栏 : da pai ge的博客专栏 ☁️宝剑锋从磨砺出,梅花香自苦寒来 目录 一BIOS 1破解密码的前提 2B…...

linux的安装程序 与 文件 相关的命令
软件安装卸载命令 软件包介绍软件包命名格式dpkg命令apt-get命令apt-get命令 压缩和解压命令 压缩文件后缀 压缩命令打包和解包命令 tar命令 文件分割命令 split命令 文件操作相关命令 cat命令head命令tail命令more命令less命令管道命令wc 命令grep 命令find 命令cut 命令sort …...

SAP_ABAP相关日语单词
基本概念 1. プログラミング言語 (プログラミングげんご, Puroguramingu gengo) - 编程语言 2. 開発 (かいはつ, Kaihatsu) - 开发 3. システム (システム, Shisutemu) - 系统 4. モジュール (モジュール, Mojūru) - 模块 5. トランザクションコード (トランザクションコード,…...

Python中的除法操作详解
在Python编程中,除法是一个基础但极其重要的算术操作。Python提供了多种除法运算方式,以适应不同的计算需求。以下是对Python中除法操作的全面介绍,包括示例代码。 1. 普通除法 / 普通除法使用/运算符,它返回一个浮点数结果&…...

第1章 人工智能的基础概念与应用导论
亲爱的读者朋友们,你们好!欢迎来到这个充满神奇与奥秘的人工智能世界。我知道,对于很多人来说,人工智能(AI)可能是个既神秘又高大上的词汇,仿佛遥不可及,只存在于科幻电影或者顶级科…...
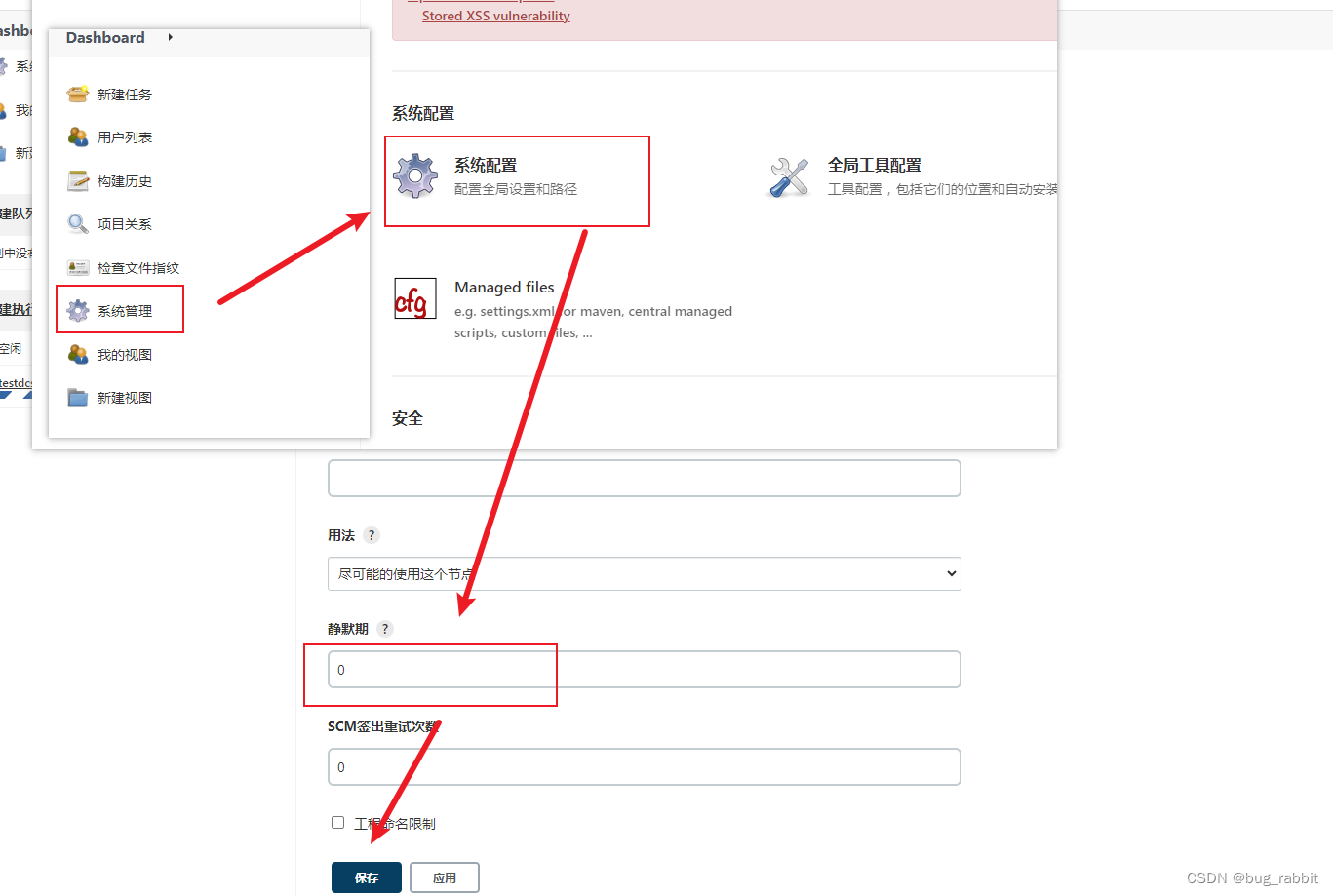
jenkins api部署时,一直提示pending-Finished waiting
问题: 调用jenkins api部署时,一直提示pending-Finished waiting 解决方案: 这个问题困扰了很久,一直没有思路,后面看到调用jenkinsAPI本身会出现一段提示,pending in the quiet period,通过搜…...

AI在创造还是毁掉音乐之论文
AI在创造还是毁掉音乐? 简介:最近一个月,轮番上线的音乐大模型,一举将素人生产音乐的门槛降到了最低,并掀起了音乐圈会不会被AI彻底颠覆的讨论。短暂的兴奋后,AI产品的版权归属于谁,创意产业要…...

C++ STL容器:序列式容器-数组string,vector,array,bitset
摘要: CC STL(Standard Template Library,标准模板库)在C编程中的重要性不容忽视,STL提供了一系列容器、迭代器、算法和函数对象,这些组件极大地提高了C程序的开发效率和代码质量。 STL 容器 分为 2 大类 …...
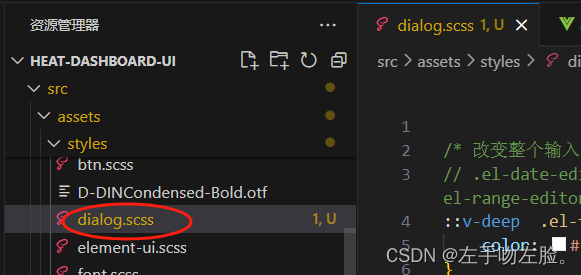
ElementUI样式优化:el-input修改样式、el-table 修改表头样式、斑马格样式、修改滚动条样式、
效果图: 1、改变日期时间组件的字体颜色背景 .form-class ::v-deep .el-date-editor { border: 1px solid #326AFF; background: #04308D !important; } .form-class ::v-deep .el-date-editor.el-input__wrapper { box-shadow: 0 0 0 0px #326AFF inset; } // 输入…...
)
大数据面试题之Spark(6)
Spark输出文件的个数,如何合并小文件? Spark的driver是怎么驱动作业流程的? Spark SQL的劣势? 介绍下Spark Streaming和Structed Streaming Spark为什么比Hadoop速度快? DAG划分Spark源码实现? Spark Streaming的双流join的过程,怎么做的? …...
)
SpringSecurity中文文档(Servlet Anonymous Authentication)
Anonymous Authentication Overview 通常认为采用“默认拒绝”立场是良好的安全实践,您明确指定允许的内容并拒绝其他所有内容。定义未经身份验证的用户可以访问的内容是类似的情况,特别是对于 Web 应用程序。许多网站要求用户必须经过身份验证才能访问…...

【Spring Boot 事务管理】
Spring Boot 事务管理 一、Spring Boot中的事务管理1.声明式事务管理Transactional注解基本使用配置选项 2.编程式事务管理TransactionTemplatePlatformTransactionManager 二、Transactional注解深入1.基本使用基本属性 2.传播行为3.隔离级别4.事务超时设置5.回滚规则 三、事务…...

【C++】C++指针在线程中调用与受保护内存空间读取方法
引言 在C的多线程编程中,正确地管理内存和同步访问是确保程序稳定性和安全性的关键。特别是当涉及到指针在线程中的调用时,对受保护内存空间的访问必须谨慎处理,以防止数据竞争、死锁和内存损坏等问题。本文将详细探讨C指针在线程中调用时如何…...
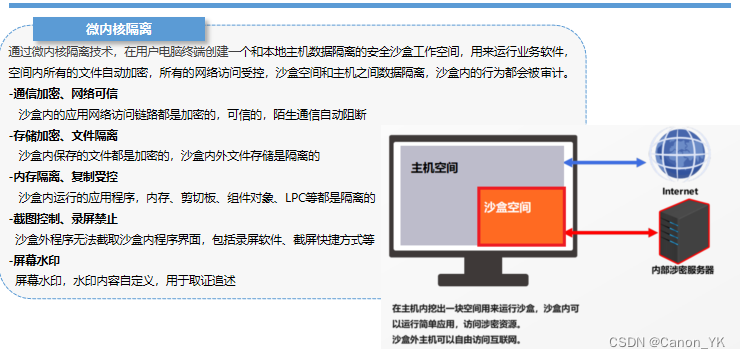
安全隔离上网的有效途径:沙箱
在数字化浪潮日益汹涌的今天,网络安全成为了不可忽视的重要议题。沙箱技术作为一种高效的隔离机制,为企业和个人提供了一种在享受网络便利的同时,保障系统安全的解决方案。本文旨在深入探讨沙箱技术如何做到隔离上网,从而为用户提…...

jenkins下后台运行链接Jenkins服务脚本方法
为了编写一个用于在后台运行 Jenkins agent 的批处理脚本,你可以使用 start 命令来启动 Java 进程并将其设置为在后台运行。以下是一个示例批处理脚本 run_agent.bat: bat echo off setlocalREM Set the path to the Jenkins agent JAR file set AGENT…...

宠物空气净化器哪个品牌性价比高?宠物空气净器Top3品牌推荐
养猫确实给家庭带来了无尽的欢乐,但猫毛无处不在的问题确实让不少猫主人感到头疼。不论是长毛猫还是短毛猫,它们掉落的浮毛飘浮在空气中,不仅影响家居环境的整洁度,还可能成为过敏的源头。因此,如何高效地处理这些猫浮…...

苏州大厂面试题JAVA 面试集
基础知识1、强引用、软引用、弱引用、幻象引用有什么区别?(java基础) 答案参考:https://time.geekbang.org/column/article/6970 2、 对比Hashtable、HashMap、TreeMap有什么不同?(数据结构) 答案参考:https://time.geekbang.org/column/article/8053 3、一个线程调用两次…...

高密度PCB贴装实战:如何用模块化治具解决0.3mm间距元件定位难题
高密度PCB贴装实战:模块化治具在0.3mm间距元件定位中的创新应用 当智能手表的PCB板面积缩小到指甲盖大小时,上面的0402元件间距已经突破0.3mm极限——这相当于在1元硬币上精准摆放50根头发丝。消费电子微型化浪潮下,传统治具的定位误差正在吞…...

SDL窗口自适应实战:解决视频卡顿与分辨率切换崩溃的完整方案
SDL窗口自适应实战:解决视频卡顿与分辨率切换崩溃的完整方案 在多媒体应用开发中,流畅的视频播放体验是用户体验的关键指标之一。SDL(Simple DirectMedia Layer)作为一款跨平台的多媒体开发库,被广泛应用于游戏、视频播…...

3D打印桥接工具:从设计到输出的全流程优化
3D打印桥接工具:从设计到输出的全流程优化 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl SketchUp STL插件是连接…...

实用扩散模型完整指南:100行代码实现高效图像生成
实用扩散模型完整指南:100行代码实现高效图像生成 【免费下载链接】Diffusion-Models-pytorch Pytorch implementation of Diffusion Models (https://arxiv.org/pdf/2006.11239.pdf) 项目地址: https://gitcode.com/gh_mirrors/di/Diffusion-Models-pytorch …...
)
DeepChat一键启动揭秘:Llama3:8b镜像免配置部署教程(含端口自愈与模型缓存)
DeepChat一键启动揭秘:Llama3:8b镜像免配置部署教程(含端口自愈与模型缓存) 想体验一个完全私密、响应迅速、且能进行深度对话的AI助手吗?今天,我们将一起揭开DeepChat的神秘面纱。它不是一个需要复杂API密钥和网络调…...

Llama-3.2V-11B-cot应用场景:跨境电商多语言商品图信息提取案例
Llama-3.2V-11B-cot应用场景:跨境电商多语言商品图信息提取案例 1. 项目背景与价值 跨境电商平台每天需要处理海量商品图片,传统人工标注方式面临三大痛点: 语言障碍:商品图可能包含多种语言的文字信息效率瓶颈:人工…...

LabVIEW新手避坑指南:用For循环和数组搞定水仙花数,别再手动算啦!
LabVIEW实战:用For循环与数组高效求解水仙花数的5个关键技巧 水仙花数这个经典的编程练习题,在文本编程语言中可能只需十几行代码,但切换到LabVIEW的图形化编程环境时,不少初学者会陷入连线混乱和逻辑纠结。本文将从实际工程视角…...
Stable Diffusion像素艺术工作站:Pixel Fashion Atelier支持LoRA在线热切换
Stable Diffusion像素艺术工作站:Pixel Fashion Atelier支持LoRA在线热切换 1. 像素时装锻造坊简介 Pixel Fashion Atelier是一款基于Stable Diffusion与Anything-v5的图像生成工作站,专为像素艺术创作而设计。与传统AI工具不同,它采用了复…...
与torch.cat()的5个典型场景对比)
PyTorch张量拼接实战:torch.stack()与torch.cat()的5个典型场景对比
PyTorch张量拼接实战:torch.stack()与torch.cat()的5个典型场景对比 在深度学习项目中,数据维度的操作就像乐高积木的拼装——选错连接方式可能导致模型结构崩塌。作为PyTorch中高频使用的两种拼接操作,torch.stack()和torch.cat()常被混淆使…...

别再只会用PS修图了!用Python的Richardson-Lucy算法,5分钟搞定模糊老照片修复
用Python拯救模糊老照片:零基础也能上手的Richardson-Lucy算法实战 翻箱倒柜找到一张泛黄的老照片,却发现画面模糊得连人脸都看不清?别急着叹气,更不用花大价钱找专业修图师。今天我要分享一个连Python新手都能轻松上手的黑科技—…...