大数据面试题之Spark(6)
Spark输出文件的个数,如何合并小文件?
Spark的driver是怎么驱动作业流程的?
Spark SQL的劣势?
介绍下Spark Streaming和Structed Streaming
Spark为什么比Hadoop速度快?
DAG划分Spark源码实现?
Spark Streaming的双流join的过程,怎么做的?
Spark的Block管理
Spark怎么保证数据不丢失
Spark SQL如何使用UDF?
Spark温度二次排序
Spark输出文件的个数,如何合并小文件?
在Apache Spark中,输出文件的个数通常由RDD(弹性分布式数据集)或DataFrame/Dataset在进行保存操作(如saveAsTextFile, saveAsParquet, write等)时的分区数量决定。默认情况下,每个分区会产生一个输出文件。因此,减少输出文件数量通常涉及到减少RDD或DataFrame的分区数。
如何合并小文件:
1、使用coalesce()或repartition()方法:
在DataFrame或RDD上使用coalesce(numPartitions)或repartition(numPartitions)方法可以改变分区数,进而影响输出文件的数量。repartition()会导致全量的Shuffle,而coalesce()在减少分区时尝试避免全量Shuffle,因此在需要减少文件数量但又不想增加过多计算开销时更为推荐。但需注意,当从大量分区合并到极少数分区时,coalesce()也可能导致数据倾斜。
2、自适应分区(Adaptive Partitioning):
在Spark SQL中,可以通过设置spark.sql.adaptive.enabled = true来启用自适应查询执行特性,它可以在执行过程中动态地调整分区数,有助于减少小文件的生成。
3、控制文件格式的输出配置:
对于Parquet、ORC等支持块大小或行数配置的文件格式,在保存DataFrame时,可以通过设置相应的配置(如parquet.block.size、orc.stripe.size)来控制输出文件的大小,间接影响文件数量。
4、使用单个任务合并文件:
可以创建一个新的Spark作业,其目的仅为读取先前产生的小文件,并使用coalesce(1)或repartition(1)将所有数据合并到一个分区中,然后输出为一个大文件。这种方法适用于处理已经生成的小文件情况。
5、修改默认shuffle分区数:
如果问题是由于默认的shuffle分区数过多导致的,可以调整spark.sql.shuffle.partitions配置来减少默认的分区数。
6、使用输出文件提交机制:
考虑FileOutputCommitter的不同版本(V1和V2),虽然这不是直接合并文件的方法,但理解这些机制有助于优化输出过程,特别是在如何管理临时文件和最终文件方面。
通过上述方法,可以有效地控制和减少Spark作业产生的输出文件数量,从而优化存储空间使用和后续的数据处理效率。
Spark的driver是怎么驱动作业流程的?
Spark的Driver是Spark应用程序的核心协调组件,负责管理并驱动整个作业的执行流程。以下是Driver驱动作业流程的主要步骤:
1、初始化SparkContext: 当Spark应用启动时,Driver首先会创建一个SparkContext对象(常简称为sc)。SparkContext是Spark与集群资源管理器(如Standalone、YARN或Mesos)交互的入口点,负责初始化Spark应用并与之建立连接,包括请求必要的资源。
2、构建DAG(有向无环图): Driver会接收用户程序中的RDD(弹性分布式数据集)操作,如map、filter、reduceByKey等,并将这些操作转换为一系列任务。这一系列操作会被组织成一个DAG,这个DAG描述了数据处理的逻辑和依赖关系。
3、划分Stage: Driver会进一步分析DAG,基于shuffle操作将其划分为不同的Stage。宽依赖(如reduceByKey)会触发新的Stage的开始,而窄依赖(如map)则可以在同一个Stage内连续执行。这样做的目的是为了优化执行计划,减少数据的跨节点传输。
4、任务调度: Driver根据划分好的Stage生成具体的任务(Tasks),并将这些任务分发到各个Executor上执行。Driver负责跟踪任务的状态,包括任务的成功、失败或重试,并且根据Executor的资源使用情况和任务执行进度动态地调整任务调度。
5、资源管理: Driver与集群管理器(Master)协作,根据应用的需求动态申请和释放Executor资源。Executor是实际执行计算任务的进程,它们在Worker节点上运行,并由Driver分配任务。
6、监控和故障恢复: Driver还会监控整个作业的执行情况,包括Executor的运行状态。如果Executor失败或任务执行出错,Driver可以重新安排任务执行,以确保作业的最终完成。
7、结果收集与展示: 当所有任务执行完毕后,Driver负责收集Executor返回的结果,并可能进一步处理这些结果,最终将应用的输出呈现给用户。对于交互式查询,例如Spark SQL,Driver还负责维护结果集并提供查询接口。
整个流程中,Driver作为大脑,不断地接收用户程序指令,制定执行策略,与集群资源管理系统交互,调度任务,并确保作业能够高效、正确地执行完毕。
Spark SQL的劣势?
Spark SQL作为Apache Spark中用于处理结构化数据的模块,虽然在处理大规模数据、支持多种数据源、提供高性能的查询和分析能力等方面具有显著优势,但仍然存在一些劣势,具体可以归纳如下:
1、稳定性问题:
相对于Hive等传统的大数据查询工具,Spark SQL在处理大规模任务时,特别是在SQL复杂度较高或数据量巨大的情况下,可能会出现稳定性问题,如内存溢出(OOM)等问题。
在某些情况下,如进行join或group by等操作时,如果数据量过大,Spark SQL可能会遇到性能瓶颈和稳定性挑战。
2、资源利用率:
在某些部署模式下,如Spark SQL模式(即每次提交SQL任务都会启动一个新的application),可能会导致资源利用率较低,因为每个任务都需要独立启动和占用资源。
相对于Hive等基于MapReduce的框架,Spark SQL可能无法充分利用集群资源,尤其是在处理某些特定类型的工作负载时。
3、学习曲线:
Spark SQL虽然提供了SQL查询接口和DataFrame API两种操作方式,但对于不熟悉Spark生态系统的用户来说,可能需要花费一定的时间来学习和掌握这些工具和技术。
DataFrame和DataSet等高级抽象概念的使用也需要一定的编程经验和技能。
4、多租户和权限管理:
在某些部署模式下,如使用ThriftServer时,由于资源没有隔离,不同用户之间的SQL任务可能会相互影响,导致稳定性问题。
Spark SQL本身可能不提供完善的多租户和权限管理功能,需要依赖外部工具或框架来实现。
5、与其他组件的集成:
虽然Spark SQL作为Spark生态系统的一部分,可以与其他Spark组件(如Spark Streaming、MLlib等)无缝集成,但在与其他非Spark组件(如Hadoop生态系统中的其他工具)集成时可能会面临一些挑战和限制。
6、错误检查和调试:
虽然DataSet提供了编译时的类型检查功能,但DataFrame并不具备这种能力,这可能导致在运行时才发现类型错误等问题。
在处理复杂的数据转换和计算任务时,可能需要花费一定的时间来调试和排查问题。
7、部署和维护:
根据不同的业务需求和集群环境,选择合适的Spark SQL部署模式可能需要一定的技术决策和经验。
部署和维护一个高性能、稳定的Spark SQL集群也需要一定的技术能力和资源投入。
综上所述,虽然Spark SQL在处理结构化数据方面具有显著优势,但在稳定性、资源利用率、学习曲线、多租户和权限管理、与其他组件的集成、错误检查和调试以及部署和维护等方面仍然存在一些挑战和限制。在使用Spark SQL时,需要根据具体的业务需求和场景来权衡这些因素,并采取相应的策略和技术来优化性能和提高稳定性。
介绍下Spark Streaming和Structed Streaming
Spark Streaming和Structured Streaming都是Apache Spark生态系统中的组件,用于处理实时数据流。以下是关于这两个组件的详细介绍:
Spark Streaming
1. 概述
Spark Streaming是Apache Spark的一个核心扩展,用于进行可扩展、高吞吐量和容错的实时数据流处理。它允许用户通过流式计算引擎处理实时数据流,并以低延迟的方式对数据进行分析、处理和存储。
2. 主要特点
实时数据处理:能够实时处理来自各种数据源(如Kafka、Flume、Kinesis等)的数据流。
低延迟:相比传统的批处理系统,Spark Streaming能够实现毫秒级的延迟。
容错性:提供了高度的容错性,能够在节点故障时自动恢复,保证数据处理的可靠性和稳定性。
扩展性:通过Spark的弹性分布式计算模型,Spark Streaming能够轻松地扩展到数千台节点,处理大规模的数据流。
3. 实现原理
Spark Streaming将实时数据流划分为一系列称为微批次(micro-batches)的小批量数据,并在每个微批次内使用Spark引擎进行批处理计算。这种微批次的方式使得Spark Streaming具有与批处理系统相似的编程模型,并且能够利用Spark引擎的优化和性能。
Structured Streaming
1. 概述
Structured Streaming是Spark SQL的一个扩展,用于处理实时数据流。它是一个基于Spark SQL引擎构建的可伸缩的且具有容错性的实时流处理引擎,主要处理无界数据。
2. 主要特点
实时计算框架:作为一个实时计算框架,Structured Streaming使用Dataset作为数据模型,支持多种编程语言(如Scala、Java、Python)。
容错性:通过checkpoint和WAL(Write-Ahead Logging)进行数据容错,保证数据处理的可靠性。
Exactly-Once语义:确保每条记录仅被处理一次,即使在故障恢复后也是如此。
与Spark SQL的集成:Structured Streaming与Spark SQL紧密集成,使得流处理和批处理可以使用相同的代码和工具。
3. 编程模型
在Structured Streaming中,流数据被视为一个无界的表,其数据随着时间的推移而不断增长。开发人员可以使用与批处理相同的DataFrame和Dataset API来处理流数据。Structured Streaming还提供了丰富的转换操作(如map、reduce、join等),使用户可以方便地对数据流进行处理。
4. 与Spark Streaming的比较
Structured Streaming可以看作是Spark Streaming的进化版,它提供了更高的抽象级别和更简洁的API,使得实时数据处理变得更加容易和直观。同时,Structured Streaming还利用了Spark SQL的优化器(如Catalyst)来优化执行计划,从而提高了处理效率。
综上所述,Spark Streaming和Structured Streaming都是用于实时数据流处理的强大工具,但它们在实现原理、编程模型和特性上有所不同。根据具体的应用场景和需求,可以选择适合的组件来处理实时数据流。
Spark为什么比Hadoop速度快?
Spark 相比于 Hadoop MapReduce 在速度上有显著提升,主要原因包括以下几个方面:
1、基于内存的计算:Spark 设计之初就强调内存计算能力,它能够将数据载入内存中进行处理,极大地加速了数据处理速度。当数据在内存中时,访问速度远超硬盘I/O,尤其是在迭代计算和需要多次访问相同数据集的场景下,如机器学习算法的训练过程。
2、DAG执行模型:Spark 引入了有向无环图(DAG)执行引擎,这使得它能更灵活地优化作业执行计划。不同于Hadoop MapReduce的线性作业流程,Spark可以构建复杂的多阶段计算流程,并且优化执行顺序,减少不必要的数据读写操作,尤其是减少了shuffle过程中磁盘I/O的需求。
3、减少磁盘I/O操作:在Hadoop MapReduce中,每次Map和Reduce操作之间的数据交换都需要写入磁盘,然后读取。而Spark在很多情况下能避免这样的中间结果落地磁盘,直接在内存中进行传递或者仅在必要时才写入磁盘,显著减少了I/O开销。
4、任务调度优化:Spark的DAGScheduler能够更好地理解整个作业的依赖关系,并据此做出更智能的调度决策。它能够合并任务,减少Job的执行阶段,进一步提高执行效率。
5、JVM和线程优化:Spark利用多线程模型在Executor进程中执行任务,而不是为每个任务启动一个新的JVM实例,这样减少了JVM启动的开销。同时,Spark对JVM进行了优化,比如使用了基于内存的序列化库Kryo,以提高序列化和反序列化的效率。
6、数据持久化与缓存:Spark支持将经常访问的数据集持久化到内存中,甚至可以将数据存储在磁盘上以应对内存不足的情况,这使得重复访问的数据无需重新计算,进一步加速了处理过程。
7、统一的数据处理平台:Spark提供了统一的API来处理批处理、实时流处理、交互式查询以及机器学习等多种工作负载,这意味着数据处理流程可以在同一框架内无缝集成,减少了数据在不同系统间移动的开销。
综上所述,Spark通过内存计算、高效的执行模型、减少磁盘I/O、智能调度以及对JVM和数据处理流程的优化,实现了比Hadoop MapReduce更快的数据处理速度。
DAG划分Spark源码实现?
在Apache Spark中,DAG(Directed Acyclic Graph,有向无环图)是一个核心概念,用于表示一个Spark作业中各个任务之间的依赖关系。然而,Spark源码中并没有直接名为“DAG划分”的特定部分,因为DAG的构建和划分是分散在多个组件和阶段中的。不过,我可以概述一下在Spark中如何构建和处理DAG的大致流程。
1、构建DAG:
当用户提交一个Spark作业(如一个Spark SQL查询或一个RDD转换链)时,Spark的Driver会解析这个作业并构建一个逻辑执行计划(Logical Plan)。
这个逻辑执行计划可以被视为一个DAG,其中每个节点代表一个操作(如投影、过滤、连接等),而边则代表数据在这些操作之间的流动。
接着,Spark的优化器(Catalyst Optimizer)会对逻辑执行计划进行优化,可能会改变DAG的结构以提高执行效率。
2、物理执行计划的生成:
优化后的逻辑执行计划会被转换为物理执行计划(Physical Plan),这个物理执行计划更接近于实际的执行流程。
在物理执行计划的生成过程中,Spark会考虑数据的分区、可用的资源以及其他物理因素,以便为每个任务分配适当的资源。
3、DAG划分(任务划分):
物理执行计划中的每个节点最终都会映射到一个或多个具体的任务(Task)上。这些任务会被发送到Executor上执行。
DAG划分的主要目标是将物理执行计划中的节点划分为可以并行执行的任务,并尽量减少跨节点数据传输的开销。
Spark使用了一种称为“窄依赖”和“宽依赖”的概念来区分不同类型的依赖关系,并根据这些依赖关系来划分任务。窄依赖通常可以在单个任务内解决,而宽依赖则可能需要跨多个任务进行shuffle操作。
4、任务调度和执行:
一旦DAG被划分为一系列任务,Spark的TaskScheduler就会负责将这些任务调度到集群中的Executor上执行。
TaskScheduler会考虑Executor的资源使用情况、任务的优先级以及其他因素来制定调度决策。
Executor在接收到任务后会执行相应的代码,并将结果返回给Driver。
需要注意的是,虽然DAG划分是Spark内部的一个重要过程,但这个过程对用户来说是透明的。用户通常只需要关注如何编写高效的Spark作业(如优化数据分区、减少跨节点数据传输等),而不需要直接关心DAG是如何被构建和划分的。
Spark Streaming的双流join的过程,怎么做的?
Spark Streaming的双流join是指在实时数据处理场景中,将来自两个不同数据流(DStream)的数据根据某些共有的键(key)进行匹配和合并的操作。下面是进行双流join的基本步骤:
1、准备数据流:首先,你需要有两个DStream实例,这两个流可以源自不同的数据源,比如Kafka、Flume、socket连接等。
2、定义窗口:由于流处理是连续不断的,为了控制join的范围,通常会定义一个时间窗口。例如,你可能会说“只在最近30秒内的数据中进行join”。窗口定义帮助限制了数据的范围,确保join操作是在合理的时间界限内进行的。
3、键值对转换:为了执行join操作,需要将两个DStream中的数据转换成键值对(K,V)的形式。这里的键(K)就是你想要基于其进行join的字段。
4、执行Join操作:Spark Streaming提供了多种类型的join操作,如内连接(inner join)、左外连接(leftOuterJoin)、右外连接(rightOuterJoin)等。选择合适的join类型取决于你的具体需求。这个join操作是在每个定义好的窗口上独立进行的,意味着它会匹配每个窗口内两个流中的对应键值对。
5、处理延迟和数据不一致性:在实际应用中,由于网络延迟或处理时间的差异,两个流的数据可能不会完全对齐。为了解决这个问题,可能需要设置适当的滑动窗口大小以允许数据对齐,或者采用一些补偿策略,如缓存数据或设置等待时间来尽量保证数据的一致性。
6、结果处理:join操作完成后,得到的新DStream包含了匹配后的数据,你可以继续对此DStream应用其他转换或输出操作,如存储到数据库、文件系统或发送到消息队列等。
通过上述步骤,Spark Streaming实现了在实时数据流上的灵活且高效的数据合并功能,这对于需要整合多个数据来源进行综合分析的场景非常有用。
Spark的Block管理
Spark的Block管理是其存储和计算框架中的核心组件之一,主要负责管理在集群中分布式存储的数据块(Block)。以下是关于Spark Block管理的详细解释:
1. Block的定义与重要性
定义:在Spark中,Block是数据处理的基本单元,用于存储RDD(弹性分布式数据集)的分区、Shuffle输出、广播变量等。
重要性:通过Block管理,Spark能够高效地处理和共享数据,提高数据处理的速度和可靠性。
2. BlockManager的角色
功能:BlockManager是Spark中用于管理Block的模块,它负责Block的存储、复制、交换、缓存和回收等操作。
分布性:在Spark集群中,每个Executor都会启动一个BlockManager来管理该Executor上的Block。
通信:BlockManager通过Driver上的Master节点(BlockManagerMaster)进行通信,Master节点负责协调所有Executor上的BlockManager。
3. Block的标识符与元数据
BlockId:每个Block都有唯一的标识符(BlockId),用于在集群中定位和管理Block。
BlockInfo:BlockInfo类包含了Block的元数据,如BlockId、存储级别(StorageLevel)、数据内容等。
4. Block的存储与复制
存储:Block可以存储在内存或磁盘上,对于小数据块,BlockManager会优先将其存储在内存中以提高访问速度;对于大数据块,则会将其存储在磁盘上。
复制:为了保证数据的可靠性和高可用性,BlockManager会自动将数据块复制到其他节点上,以避免数据丢失或节点故障导致数据无法访问。复制策略可以根据具体需求进行配置。
5. Block的缓存与回收
缓存:为了提高计算效率,BlockManager支持将数据块缓存在内存中,以避免频繁地从磁盘或外部存储系统中读取数据块。
回收:BlockManager还会定期清除一些不再使用的数据块,以释放资源。
6. Block的传输与序列化
传输:在Spark中,数据块经常需要在不同的节点之间传输和共享,因此需要进行序列化和反序列化。BlockManager提供了常用的序列化和反序列化方式,如Java序列化、Kryo序列化等。
7. 故障恢复与数据迁移
故障恢复:当一个节点出现故障或者网络出现问题时,BlockManager会自动进行故障恢复,将丢失的数据块重新复制到其他节点上。
数据迁移:在集群扩容或缩容时,BlockManager还支持数据迁移,以保证数据块的平衡分布。
8. BlockManager的实现
类结构:BlockManager主要由几个关键类组成,包括BlockManagerMaster(负责管理集群中所有节点的BlockManager)、BlockManager(负责管理本地节点的数据块)、BlockInfo(表示一个数据块的信息)等。
API操作:开发人员可以通过BlockManager提供的API来操作Block,以满足不同的数据处理需求。
Spark怎么保证数据不丢失
Spark通过多种机制来保证数据处理过程中的高容错性和防止数据丢失,主要机制包括但不限于以下几点:
1、RDD的不可变性和血统(Lineage):
RDD(弹性分布式数据集)是Spark的核心数据结构,具有不可变性。这意味着创建之后的RDD不能被修改,只能通过对现有RDD进行转换来生成新的RDD。
每个RDD都维护着一个血统信息,记录了从原始数据到当前RDD的所有转换步骤。如果部分数据丢失,Spark可以根据这些转换步骤重新计算丢失的数据,从而实现数据恢复。
2、Write-Ahead Log (WAL):
特别是在Spark Streaming与外部数据源(如Kafka)集成时,使用Write-Ahead Log可以确保数据在接收后立即被记录到持久化存储(如HDFS或S3)中,即使在处理过程中发生故障,也能从日志中恢复数据,防止数据丢失。
3、Checkpointing(检查点机制):
Checkpointing允许Spark定期将计算状态信息(包括DStream的元数据和累加器的值)保存到可靠的存储系统(如HDFS),以在Driver故障时恢复状态。这对于长时间运行的流处理应用尤为重要,可以恢复到最近的检查点状态继续执行。
4、Direct API(直接模式):
Spark Streaming的直接(Direct)API,特别是与Kafka集成时,允许直接从Kafka读取数据并管理偏移量,消除了Receiver这一潜在的故障点。结合WAL和Checkpointing,可以实现端到端的数据不丢失处理。
5、Receiver Recovery and Reliability:
使用Reliable Receiver确保即使在Receiver失败的情况下也不会丢失数据。当Receiver重启时,它能从上次成功消费的位置继续消费数据。
6、事务管理:
在处理需要保证数据一致性的场景时,如Spark与Kafka集成时,通过事务管理机制确保数据处理和偏移量提交的原子性,防止数据重复消费或丢失。
这些机制共同作用,确保了Spark在面对各种故障情况时能够保持数据的完整性,从而提供一个高可用和可靠的数据处理环境。
Spark SQL如何使用UDF?
在Spark SQL中使用用户自定义函数(UDF)是一种常见做法,用于扩展Spark SQL的内置函数集,以便执行自定义逻辑。以下是使用不同编程语言(Scala、Python、Java)创建和注册UDF的基本步骤:
Scala
1、定义UDF: 首先,你需要定义一个函数,这个函数接受一个或多个列作为输入,并返回一个结果。你可以使用Scala的函数语法或表达式。
import org.apache.spark.sql.functions.udf// 定义一个简单的UDF,计算字符串长度
val strLengthUDF = udf((input: String) => input.length)2、注册UDF: 然后,使用udf.register方法将其注册到SparkSession中。
spark.udf.register("strLength", strLengthUDF)3、在查询中使用UDF: 注册后,你可以在Spark SQL查询中像使用任何其他内置函数一样使用它。
val df = spark.read.text("input.txt")
df.selectExpr("strLength(value)").show()或者在DataFrame API中直接使用:
df.select(strLengthUDF($"value")).show()Python (PySpark)
1、定义UDF: 使用pyspark.sql.functions.udf装饰器定义一个Python函数。
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType# 定义一个简单的UDF,计算字符串长度
def str_length(input):return len(input)strLengthUDF = udf(str_length, IntegerType())2、注册和使用UDF: 在Python中,UDF会自动注册到当前的SparkSession,并可以直接在DataFrame操作中使用。
df = spark.read.text("input.txt")
df.select(strLengthUDF(df["value"])).show()Java
1、定义和注册UDF: 在Java中,你需要创建一个继承自org.apache.spark.sql.api.java.UDF1(或相应的UDF2, UDF3等,取决于输入参数的数量)的类,并实现call方法。
import org.apache.spark.sql.api.java.*;
import static org.apache.spark.sql.functions.udf;public class StrLengthUDF extends UDF1<String, Integer> {@Overridepublic Integer call(String input) {return input.length();}
}// 在SparkSession中注册UDF
SparkSession spark = SparkSession.builder().appName("JavaUDFExample").getOrCreate();
UDF1<String, Integer> udf = new StrLengthUDF();
spark.udf().register("strLength", udf, DataTypes.IntegerType);2、使用UDF:
Dataset<Row> df = spark.read().text("input.txt");
df.createOrReplaceTempView("textTable");
Dataset<Row> result = spark.sql("SELECT strLength(value) FROM textTable");
result.show();注意,对于复杂的逻辑或需要访问外部资源的情况,你可能需要考虑使用更高级的函数类型,如Pandas UDF(仅限Python)或在Scala/Java中实现更复杂的类结构。
Spark温度二次排序
在Spark中实现温度的二次排序,通常涉及到对数据集中的记录首先按照一个键(例如年份)进行排序,然后在同一键内再按照另一个键(例如温度)进行排序。这种需求常见于需要在特定时间段内找出最高或最低温度等场景。下面是一个基于Scala的示例,展示如何实现这样的二次排序:
步骤说明:
1、定义自定义排序键:首先,需要定义一个自定义的类来表示排序键,这个类需要实现Ordered接口(Scala特有,用于自然排序)和Serializable接口(以便在网络间传输)。这个类应该包含所有用于排序的字段,并重写compare方法来定义排序逻辑。
2、加载数据:使用SparkContext或SparkSession从数据源加载数据。
3、转换数据:将原始数据映射到包含自定义排序键和原始记录的键值对。
4、排序:使用sortByKey方法对转换后的数据进行排序。Spark 2.x及以后版本推荐使用Dataset的orderBy方法,因为它更加灵活和高效。
5、提取结果:排序后,去除排序用的键,只保留原始记录。
示例代码:
假设我们有一个文本文件,每行包含年份、月份和温度,格式如:“年 月 温度”。
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._object TemperatureSecondSort {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("TemperatureSecondSort").master("local[1]").getOrCreate()// 假设数据已加载到DataFrame中,格式为(year, month, temperature)val data = Seq((2023, 1, 15),(2023, 2, 18),(2023, 1, 20),(2024, 1, 16),(2024, 2, 19)).toDF("year", "month", "temperature")// 二次排序:首先按年份升序,然后在同一年份内按温度降序val sortedData = data.orderBy($"year".asc, $"temperature".desc)// 显示排序后的结果sortedData.show()spark.stop()}
}在这个例子中,我们没有使用自定义类来实现Ordered接口,因为Spark DataFrame提供了丰富的排序API,可以直接通过.orderBy方法实现多列排序。这里我们先按year列升序排序,然后在相同年份内部按temperature列降序排列。
引用:https://www.nowcoder.com/discuss/353159520220291072
通义千问、文心一言
相关文章:
)
大数据面试题之Spark(6)
Spark输出文件的个数,如何合并小文件? Spark的driver是怎么驱动作业流程的? Spark SQL的劣势? 介绍下Spark Streaming和Structed Streaming Spark为什么比Hadoop速度快? DAG划分Spark源码实现? Spark Streaming的双流join的过程,怎么做的? …...
)
SpringSecurity中文文档(Servlet Anonymous Authentication)
Anonymous Authentication Overview 通常认为采用“默认拒绝”立场是良好的安全实践,您明确指定允许的内容并拒绝其他所有内容。定义未经身份验证的用户可以访问的内容是类似的情况,特别是对于 Web 应用程序。许多网站要求用户必须经过身份验证才能访问…...

【Spring Boot 事务管理】
Spring Boot 事务管理 一、Spring Boot中的事务管理1.声明式事务管理Transactional注解基本使用配置选项 2.编程式事务管理TransactionTemplatePlatformTransactionManager 二、Transactional注解深入1.基本使用基本属性 2.传播行为3.隔离级别4.事务超时设置5.回滚规则 三、事务…...

【C++】C++指针在线程中调用与受保护内存空间读取方法
引言 在C的多线程编程中,正确地管理内存和同步访问是确保程序稳定性和安全性的关键。特别是当涉及到指针在线程中的调用时,对受保护内存空间的访问必须谨慎处理,以防止数据竞争、死锁和内存损坏等问题。本文将详细探讨C指针在线程中调用时如何…...
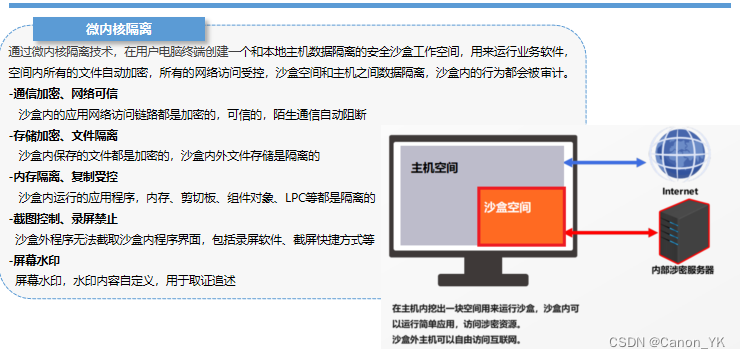
安全隔离上网的有效途径:沙箱
在数字化浪潮日益汹涌的今天,网络安全成为了不可忽视的重要议题。沙箱技术作为一种高效的隔离机制,为企业和个人提供了一种在享受网络便利的同时,保障系统安全的解决方案。本文旨在深入探讨沙箱技术如何做到隔离上网,从而为用户提…...

jenkins下后台运行链接Jenkins服务脚本方法
为了编写一个用于在后台运行 Jenkins agent 的批处理脚本,你可以使用 start 命令来启动 Java 进程并将其设置为在后台运行。以下是一个示例批处理脚本 run_agent.bat: bat echo off setlocalREM Set the path to the Jenkins agent JAR file set AGENT…...

宠物空气净化器哪个品牌性价比高?宠物空气净器Top3品牌推荐
养猫确实给家庭带来了无尽的欢乐,但猫毛无处不在的问题确实让不少猫主人感到头疼。不论是长毛猫还是短毛猫,它们掉落的浮毛飘浮在空气中,不仅影响家居环境的整洁度,还可能成为过敏的源头。因此,如何高效地处理这些猫浮…...

苏州大厂面试题JAVA 面试集
基础知识1、强引用、软引用、弱引用、幻象引用有什么区别?(java基础) 答案参考:https://time.geekbang.org/column/article/6970 2、 对比Hashtable、HashMap、TreeMap有什么不同?(数据结构) 答案参考:https://time.geekbang.org/column/article/8053 3、一个线程调用两次…...
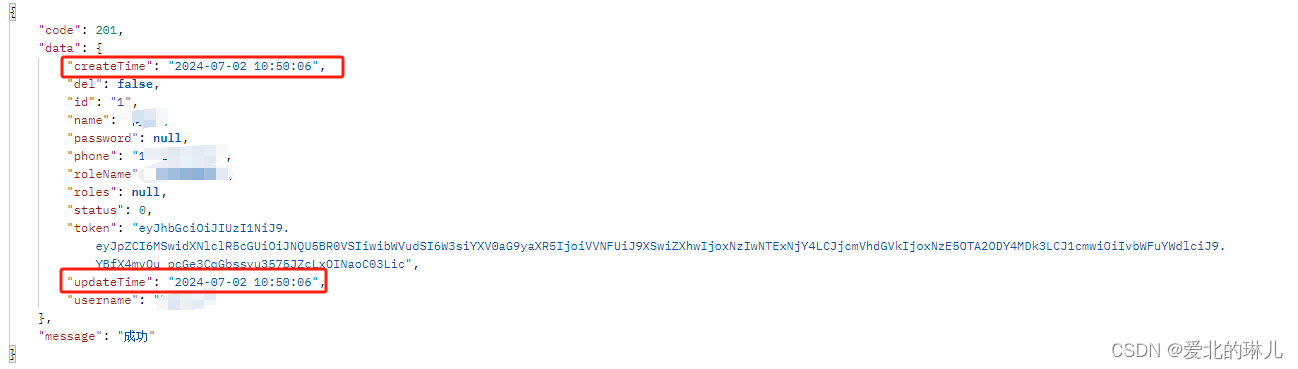
数据库取出来的日期格式是数组格式,序列化日期格式
序列化前,如图所示: 解决方式,序列化日期(localdatetime)格式 步骤一、添加序列化类 package com.abliner.test.common.configure;import com.alibaba.fastjson.serializer.JSONSerializer; import com.alibaba.fas…...

【Android】创建一个可以在屏幕上拖动的悬浮窗
项目需求 在界面上创建一个悬浮窗,可以自由的移动这个悬浮窗 需求解决 1.添加权限 <uses-permission android:name"android.permission.SYSTEM_ALERT_WINDOW"/>2.请求权限 从 Android 6.0 (API 23) 开始,应用需要动态请求显示悬浮窗…...
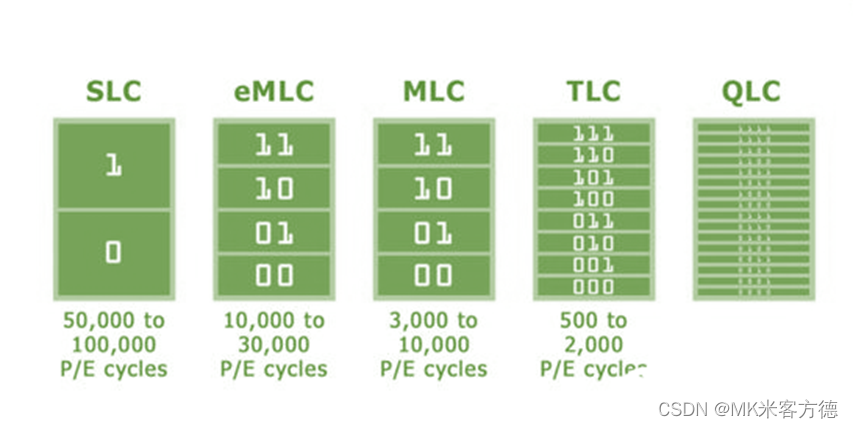
SPI NAND、SD NAND和eMMC对比—MK米客方德
目录 1. 容量: 2.封装类型: 3.速度: 4.性能: 5.寿命: 6. 使用方式: 7. 其他优缺点: 8.常见应用场景: 1. 容量: SPI NAND通常提供从几百MB到几GB的存储容量。 SD NAND的容量覆盖范围比SPI NAND更广,从几GB到几十GB不等。 eMMC的容量范围更大&a…...

“深入解析:YUM仓库、RPM包与源码编译——Linux软件安装方式全面对比“
目录 YUM 仓库安装 概念: 优点: 缺点: RPM 包安装 概念: 优点: 缺点: 源码编译安装 概念: 优点: 缺点: 三者区别 YUM 仓库安装 概念: YUM&…...
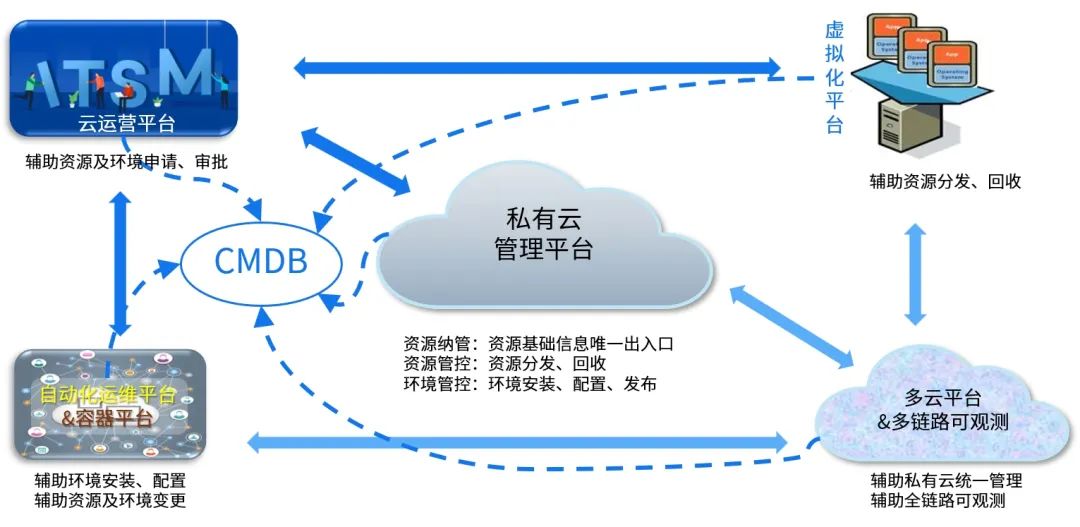
中电金信:银行业私有云何去何从
2009年,云计算开始从概念走向实践。在这一年,Gartner在预测2010十大发展趋势中,将云计算列在榜首。在这之后,谷歌、亚马逊、IBM等科技巨头纷纷加码对云计算的研发投入。2010年正式迎来云计算时代,这一年也被定为“云元…...
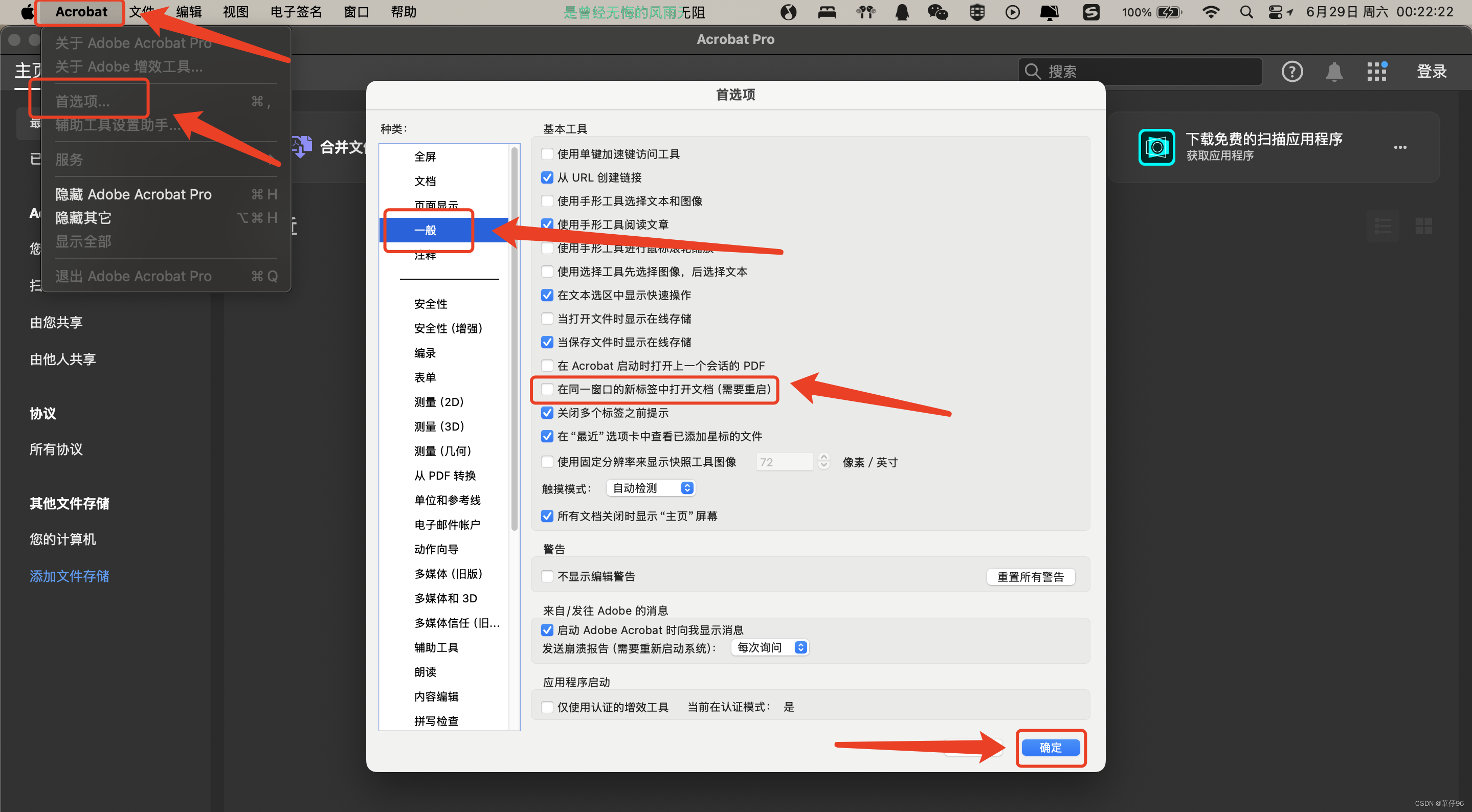
Adobe Acrobat Pro或者Adobe Acrobat Reader取消多标签页显示,设置打开一个pdf文件对应一个窗口。
Windows系统:Adobe Acrobat Pro或者Adobe Acrobat Reader首选项-一般-取消在同一窗口的新标签中打开文档(需要重启)的对勾,点击确定,彻底关闭后重启,这样打开的每一个PDF文件对应的是一个窗口,并…...

从0开始学习pyspark--pyspark的数据读取[第4节]
在PySpark中,读取文件型数据是一个常见的操作,Spark支持多种数据格式,如CSV、JSON、Parquet、Avro等。以下是一些常用的方法来读取不同格式的文件数据。 读取文本型数据 读取CSV文件: 使用spark.read.csv方法读取CSV文件,可以通…...

极速升级:MacOS系统中Pip源的切换指南
极速升级:MacOS系统中Pip源的切换指南 在MacOS系统中,Python的包管理工具Pip是我们管理和安装Python库的得力助手。然而,默认的Pip源在国外,对于国内用户来说,访问速度可能较慢。因此,更换Pip源以提高下载…...

服务器的分类,主流服务器的应用场景
一、服务器分类 服务器可以按应用层次、体系架构、用途、外形等进行分类。以下是详细说明: 按应用层次分类 入门级服务器:这些服务器一般用于小型企业或部门的简单任务,如文件共享和打印服务。工作组级服务器:适用于中小型企业&…...
Objects and Classes (对象和类)
Objects and Classes [对象和类] 1. Procedural and Object-Oriented Programming (过程性编程和面向对象编程)2. Abstraction and Classes (抽象和类)2.1. Classes in C (C 中的类)2.2. Implementing Class Member Functions (实现类成员函数)2.3. Using Classes (使用类) Ref…...
从单点到全景:视频汇聚/安防监控EasyCVR全景视频监控技术的演进之路
在当今日新月异的科技浪潮中,安防监控领域的技术发展日新月异,全景摄像机便是这一领域的杰出代表。它以其独特的360度无死角监控能力,为各行各业提供了前所未有的安全保障,成为现代安防体系中的重要组成部分。 一、全景摄像机的技…...

Java学习 -Golang开发环境+目录结构+编译+部署
开发环境 环境变量设置 GOROOT 指定 golang sdk 的安装目录GOPATH golang 工作目录,项目的源码放在这个目录下PATH 将 GOROOT/bin 放在 Path 路径下,方便命令行能直接运行 golang的命令行工具项目目录结构 |--project // 位于G…...

Acton性能调优终极指南:10个提升TON智能合约开发效率的技巧 [特殊字符]
Acton性能调优终极指南:10个提升TON智能合约开发效率的技巧 🚀 【免费下载链接】acton Toolchain for TON smart contract development and beyond 项目地址: https://gitcode.com/GitHub_Trending/acto/acton Acton是TON区块链上强大的智能合约开…...

5分钟重塑游戏性能管理:DLSS Swapper带来的工作流革命
5分钟重塑游戏性能管理:DLSS Swapper带来的工作流革命 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 痛点洞察:当DLSS管理成为游戏玩家的技术负担 作为一名现代PC游戏玩家,你是否曾…...

中小团队在ubuntu服务器利用taotoken管理多项目api密钥与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小团队在 Ubuntu 服务器利用 Taotoken 管理多项目 API 密钥与用量 在 Ubuntu 服务器上运行多个 AI 实验项目是许多中小型技术团队…...
利用CTranslate2与INT8量化,实现Whisper语音识别7倍加速
1. 项目概述:当Whisper遇上CTranslate2,语音转文字的“涡轮增压”如果你尝试过OpenAI的Whisper模型来做语音识别,大概率会被它的准确性所折服,但同时也可能被其缓慢的推理速度所困扰。尤其是在处理长音频文件或需要批量处理时&…...

弹球打砖块
<!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0, user-scalableno"><title>弹球打砖块</title><…...

别再死记硬背了!Vivado伪双口RAM的wea、ena信号到底怎么用?一个实例讲透
Vivado伪双口RAM控制信号实战指南:从原理到避坑 第一次接触Vivado的伪双口RAM时,那些密密麻麻的控制信号确实让人头疼。尤其是wea和ena这两个看似简单却暗藏玄机的信号,稍不注意就会导致数据读取异常或者意外覆盖。记得去年我在一个图像处理项…...

单片机显示开发避坑:手把手教你用C语言搞定RGB888、RGB565和RGB666的颜色格式转换
单片机显示开发实战:C语言高效处理RGB888、RGB565与RGB666格式转换 当你在STM32或ESP32上驱动一块LCD屏幕时,是否遇到过这样的场景:精心设计的UI界面在屏幕上显示时,颜色却变得怪异扭曲?这往往源于颜色格式的错配——你…...

用STM32 HAL库和MPU6050 DIY平衡小车:PID参数整定实战与小车‘站起来’的调试日记
STM32平衡小车PID调参实战:从剧烈抖动到稳定站立的调试手记 1. 平衡小车的核心挑战 当我第一次按下电源开关,看着这个小家伙像醉汉一样左右摇摆然后轰然倒下时,才真正理解到平衡控制的精妙之处。基于STM32和MPU6050的平衡小车项目,…...

GenAIScript:用脚本化AI工作流提升代码生成效率与工程化实践
1. 项目概述:当AI遇上代码生成,GenAIScript带来了什么?如果你最近在关注AI如何改变开发工作流,特别是微软在AI领域的动作,那么microsoft/genaiscript这个项目绝对值得你花时间深入研究。这不仅仅是一个简单的代码生成工…...
详解与优化实践)
ARM AArch32性能监控寄存器(PMU)详解与优化实践
1. ARM AArch32性能监控寄存器深度解析在嵌入式系统和移动计算领域,性能监控单元(PMU)是处理器微架构中至关重要的组成部分。作为一位长期从事ARM架构开发的工程师,我经常需要深入理解PMU寄存器的工作原理,以优化关键代码段的执行效率。本文将…...