从0开始学习pyspark--pyspark的数据读取[第4节]
在PySpark中,读取文件型数据是一个常见的操作,Spark支持多种数据格式,如CSV、JSON、Parquet、Avro等。以下是一些常用的方法来读取不同格式的文件数据。
读取文本型数据
- 读取CSV文件:
- 使用
spark.read.csv方法读取CSV文件,可以通过参数指定列分隔符、头部等信息。
from pyspark.sql import SparkSession spark = SparkSession.builder \.appName("CSV Read Example") \.getOrCreate() df = spark.read.csv("path/to/your/csv/file.csv", header=True, inferSchema=True)header=True表示文件包含头部信息。inferSchema=True表示让Spark自动推断列的数据类型。
- 使用
- 读取JSON文件:
- 使用
spark.read.json方法读取JSON文件,可以是单个JSON文件或者一个包含多个JSON对象的文件。
df = spark.read.json("path/to/your/json/file.json") - 使用
- 读取Parquet文件:
- 使用
spark.read.parquet方法读取Parquet文件,这是一种列式存储格式,非常适合用于大数据处理。
df = spark.read.parquet("path/to/your/parquet/file.parquet") - 使用
- 读取Avro文件:
- Spark没有内置的Avro支持,但是可以通过添加依赖并使用
spark.read.format方法来读取Avro文件。
df = spark.read.format("com.databricks.spark.avro").load("path/to/your/avro/file.avro")- 在使用Avro之前,需要确保已经将Avro的Spark插件添加到你的项目中。
- Spark没有内置的Avro支持,但是可以通过添加依赖并使用
- 读取文本文件:
- 使用
spark.read.text方法读取文本文件,每一行都会成为DataFrame中的一行。
df = spark.read.text("path/to/your/text/file.txt") - 使用
- 读取其他格式:
- 对于其他格式,可以使用
spark.read.format方法指定格式,并使用load方法加载文件。
df = spark.read.format("your_format").load("path/to/your/file") - 对于其他格式,可以使用
在读取文件时,还可以指定其他选项,如分区信息、编码、压缩等。例如,如果文件存储在HDFS上,或者需要指定特定的文件系统,可以使用spark.read.format("csv").option("path", "hdfs://path/to/your/file.csv").load()。
读取hive数据
在PySpark中读取Hive数据需要确保你的Spark环境已经正确配置了Hive支持,并且你的Spark集群可以访问Hive Metastore。以下是一些基本步骤来在PySpark中读取Hive数据:
- 确保Hive依赖:
确保你的PySpark环境中包含了Hive依赖。如果你使用的是Apache Spark内置的Hive支持,通常这些依赖已经包含在内。如果你是在本地运行,可能需要添加Hive依赖到你的Spark环境中。 - 配置Hive Metastore:
你需要配置Spark来连接到Hive Metastore。这通常涉及到设置hive.metastore.uris参数,该参数指向Hive Metastore服务的URI。 - 初始化SparkSession:
使用SparkSession.builder来配置和初始化你的SparkSession,确保启用了Hive支持。 - 读取Hive表:
使用SparkSession的table方法来读取Hive表。
以下是一个示例代码:
from pyspark.sql import SparkSession
# 初始化SparkSession,启用Hive支持
spark = SparkSession.builder \.appName("Hive Read Example") \.enableHiveSupport() \.getOrCreate()
# 读取Hive表
df = spark.table("your_database.your_table")
# 显示DataFrame的内容
df.show()
在这个例子中,your_database是Hive数据库的名称,your_table是你要读取的表的名称。
如果你需要指定Hive Metastore的URI,可以在SparkSession.builder中设置相关的Hive配置:
spark = SparkSession.builder \.appName("Hive Read Example") \.enableHiveSupport() \.config("hive.metastore.uris", "thrift://<metastore_host>:<port>") \.getOrCreate()
替换<metastore_host>和<port>为你的Hive Metastore服务的主机和端口。
请注意,如果你的Spark集群是在YARN上运行的,或者你有其他的集群管理器,你可能需要根据你的环境进行额外的配置。此外,确保你有足够的权限来访问Hive表和Metastore。
从HDFS读取数据
在PySpark中读取存储在HDFS(Hadoop Distributed File System)上的数据相对简单。你只需要确保你的Spark环境已经配置了与HDFS的连接,并且你的Spark应用程序有权限访问HDFS上的数据。
以下是一些基本步骤来在PySpark中读取HDFS数据:
- 确保Hadoop依赖:
确保你的PySpark环境中包含了Hadoop依赖。如果你是在本地运行,可能需要添加Hadoop的jar包到你的Spark环境中。 - 配置HDFS连接:
你需要配置Spark来连接到HDFS。这通常涉及到设置fs.defaultFS参数,该参数指向HDFS的NameNode的URI。 - 初始化SparkSession:
使用SparkSession.builder来配置和初始化你的SparkSession。 - 读取HDFS上的数据:
使用SparkSession的read方法来读取HDFS上的数据。你可以指定数据格式,如CSV、JSON、Parquet等。
以下是一个示例代码:
from pyspark.sql import SparkSession
# 初始化SparkSession
spark = SparkSession.builder \.appName("HDFS Read Example") \.getOrCreate()
# 读取HDFS上的CSV文件
df = spark.read.csv("hdfs://<namenode_host>:<port>/<path_to_file>", header=True, inferSchema=True)
# 读取HDFS上的JSON文件
df = spark.read.json("hdfs://<namenode_host>:<port>/<path_to_file>")
# 读取HDFS上的Parquet文件
df = spark.read.parquet("hdfs://<namenode_host>:<port>/<path_to_file>")
# 显示DataFrame的内容
df.show()
在这个例子中,<namenode_host>和<port>是HDFS NameNode的主机和端口,<path_to_file>是HDFS上文件的路径。你需要根据你的HDFS集群配置替换这些值。
如果你的Spark集群已经在Hadoop环境中配置好了,并且你的Spark应用程序有权限访问HDFS,那么通常不需要额外配置就可以直接读取HDFS上的数据。如果你的Spark集群是在YARN上运行的,或者你有其他的集群管理器,你可能需要根据你的环境进行额外的配置。此外,确保你有足够的权限来访问HDFS上的数据。
相关文章:

从0开始学习pyspark--pyspark的数据读取[第4节]
在PySpark中,读取文件型数据是一个常见的操作,Spark支持多种数据格式,如CSV、JSON、Parquet、Avro等。以下是一些常用的方法来读取不同格式的文件数据。 读取文本型数据 读取CSV文件: 使用spark.read.csv方法读取CSV文件,可以通…...

极速升级:MacOS系统中Pip源的切换指南
极速升级:MacOS系统中Pip源的切换指南 在MacOS系统中,Python的包管理工具Pip是我们管理和安装Python库的得力助手。然而,默认的Pip源在国外,对于国内用户来说,访问速度可能较慢。因此,更换Pip源以提高下载…...

服务器的分类,主流服务器的应用场景
一、服务器分类 服务器可以按应用层次、体系架构、用途、外形等进行分类。以下是详细说明: 按应用层次分类 入门级服务器:这些服务器一般用于小型企业或部门的简单任务,如文件共享和打印服务。工作组级服务器:适用于中小型企业&…...
Objects and Classes (对象和类)
Objects and Classes [对象和类] 1. Procedural and Object-Oriented Programming (过程性编程和面向对象编程)2. Abstraction and Classes (抽象和类)2.1. Classes in C (C 中的类)2.2. Implementing Class Member Functions (实现类成员函数)2.3. Using Classes (使用类) Ref…...
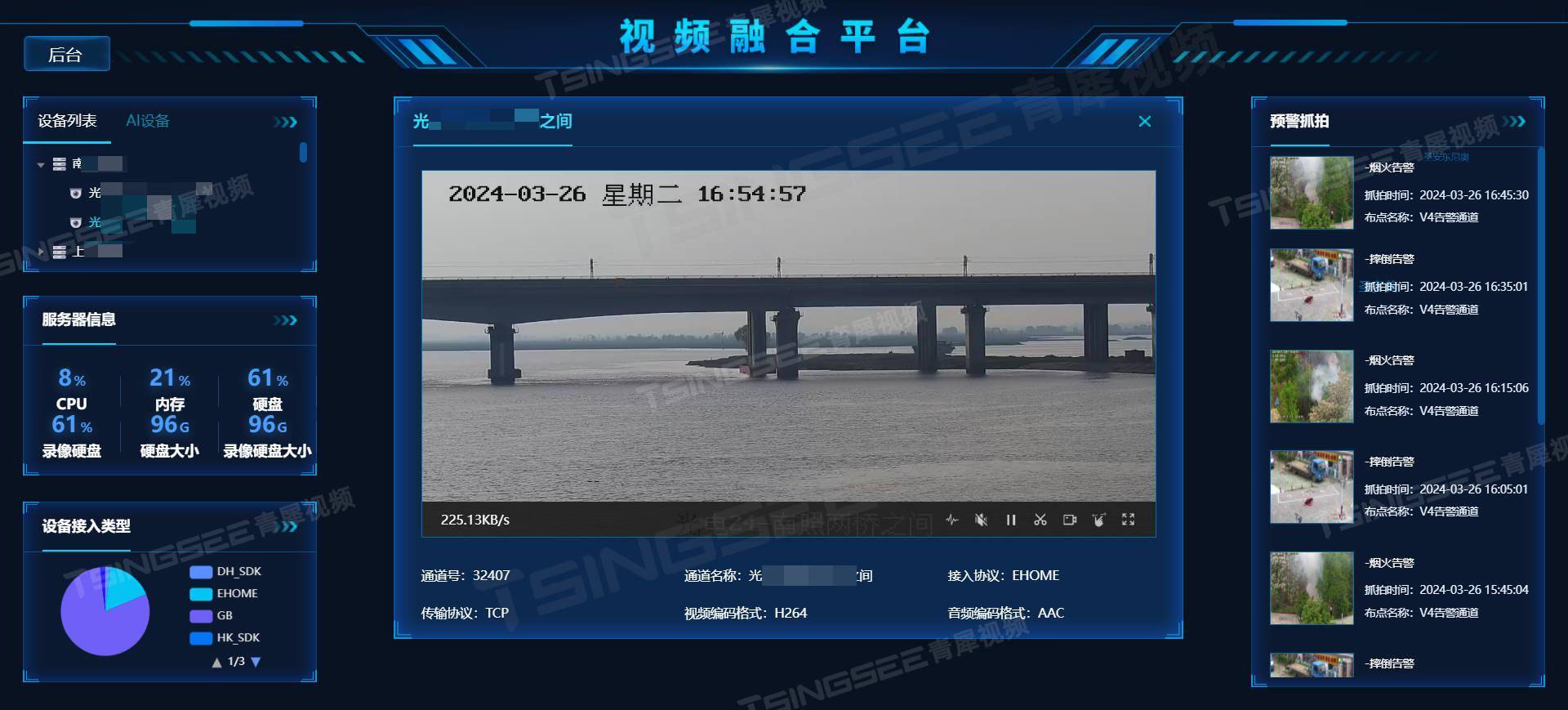
从单点到全景:视频汇聚/安防监控EasyCVR全景视频监控技术的演进之路
在当今日新月异的科技浪潮中,安防监控领域的技术发展日新月异,全景摄像机便是这一领域的杰出代表。它以其独特的360度无死角监控能力,为各行各业提供了前所未有的安全保障,成为现代安防体系中的重要组成部分。 一、全景摄像机的技…...

Java学习 -Golang开发环境+目录结构+编译+部署
开发环境 环境变量设置 GOROOT 指定 golang sdk 的安装目录GOPATH golang 工作目录,项目的源码放在这个目录下PATH 将 GOROOT/bin 放在 Path 路径下,方便命令行能直接运行 golang的命令行工具项目目录结构 |--project // 位于G…...
)
Redis 典型应用——缓存(缓存预热,穿透,雪崩,击穿)
一、缓存 缓存是计算机中一个很经典的概念,核心思路是把一些常用的数据放到访问速度更快的地方,方便随时读取; 但对于计算机硬件来说,往往访问速度越快的设备,成本越高,存储空间越小,缓存是更…...

Sharding-JDBC分库分表的基本使用
前言 传统的小型应用通常一个项目一个数据库,单表的数据量在百万以内,对于数据库的操作不会成为系统性能的瓶颈。但是对于互联网应用,单表的数据量动辄上千万、上亿,此时通过数据库优化、索引优化等手段,对数据库操作…...

7月信用卡新规下:信用卡欠的钱不用还了?
说到信用卡,现在基本上人手一张,大家都有使用过。但你知道吗,使用信用卡不是这么简单容易的事,比如会对你的贷款有影响,透支不还逾期对生活的影响,信用卡新规对持卡人和银行那边的影响。 一、只要不逾期&am…...

坑——python的redis库的decode_responses设置
python的redis库查询返回的值默认是返回字节串,可以在redis.Redis()方法中通过设置decode_responses参数,让返回值直接是字符串; 查询返回字节串是因为Redis()方法中decode_responses默认值是False: 设置decode_responses为True就…...
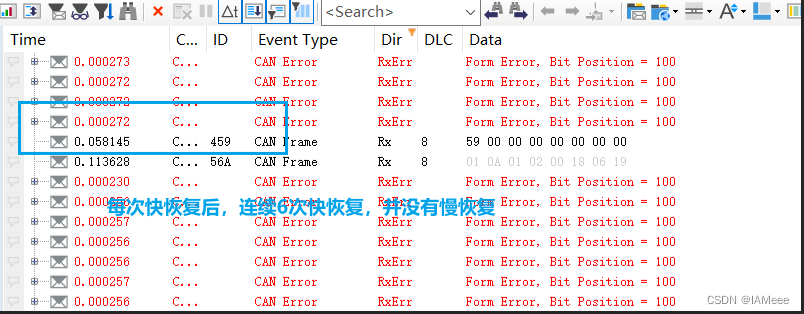
从项目中学习Bus-Off的快慢恢复
0 前言 说到Bus-Off,大家应该都不陌生,使用VH6501干扰仪进行测试的文章在网上数不胜数,但是一般大家都是教怎么去干扰,但是说如何去看快慢恢复以及对快慢恢复做出解释比较少,因此本文以实践的视角来讲解Bus-Off的快慢恢…...
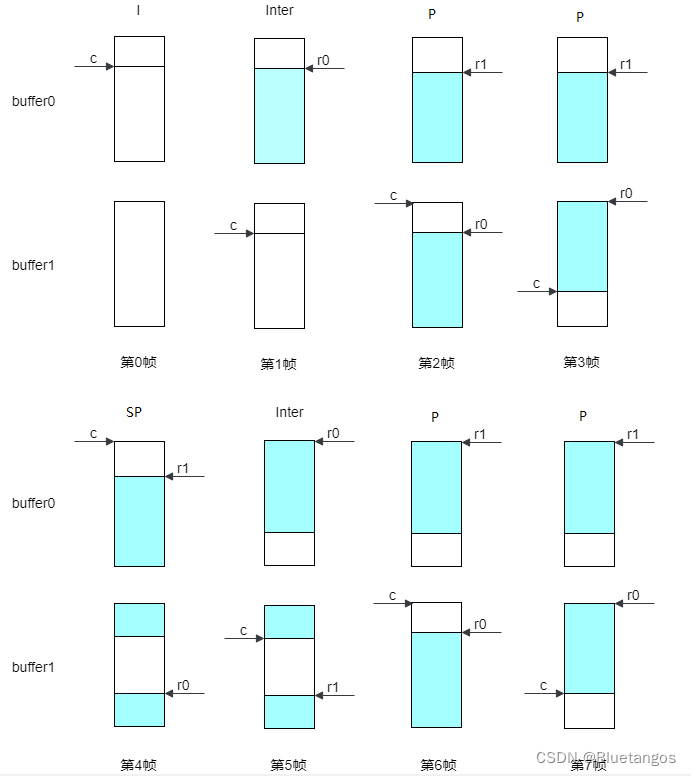
视频参考帧和重构帧复用
1、 视频编码中的参考帧和重构帧 从下图的编码框架可以看出,每编码一帧需要先使用当前帧CU(n)减去当前帧的参考帧CU(n)得到残差。同时,需要将当前帧的重构帧CU*(n)输出,然后再读取重构帧进行预测…...
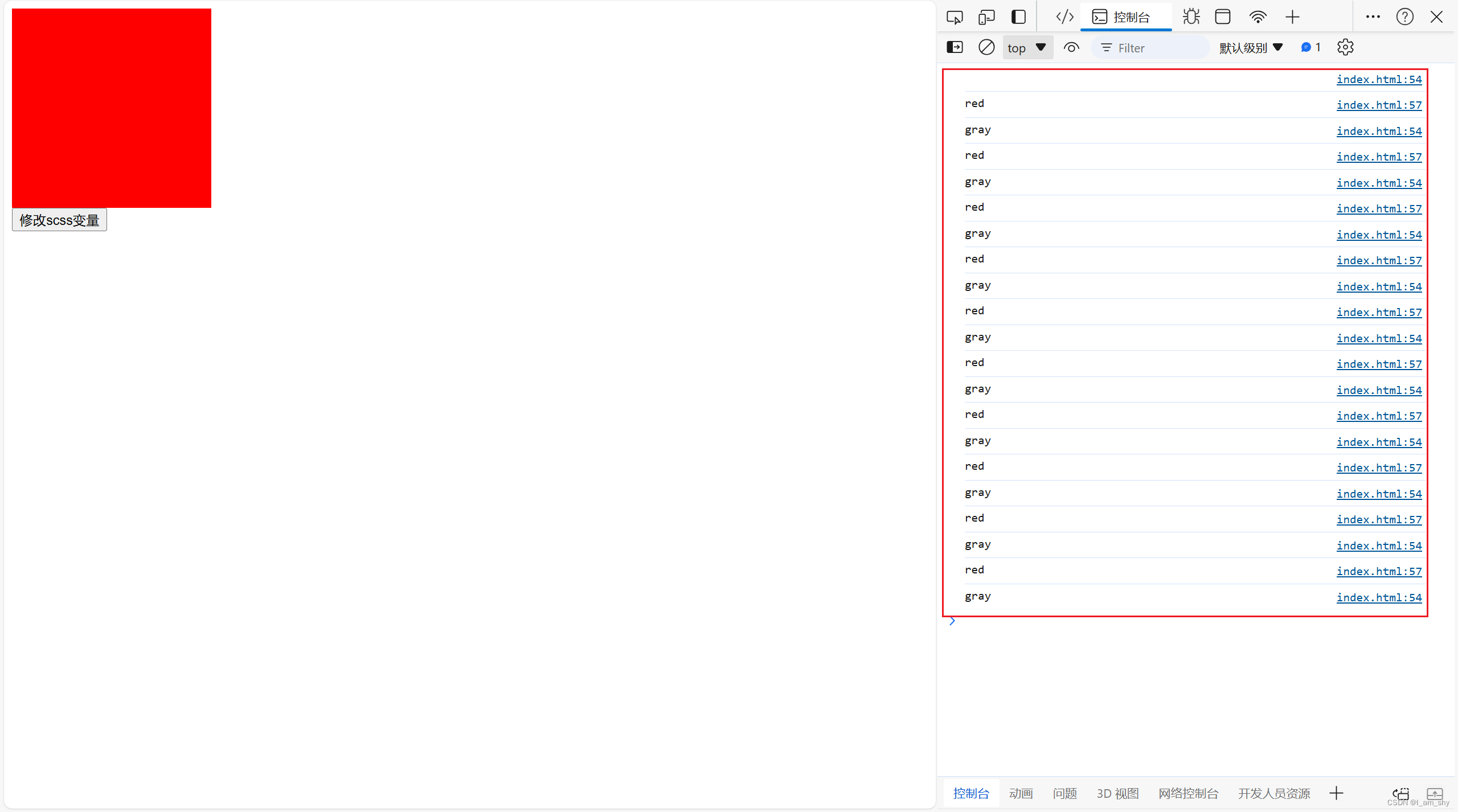
js修改scss变量
style.scss $color : var(--color,#ccc); // 默认值 #ccc .color{background: $color; } 定义了一个scss变量($color),用普通的css变量(--color)给他赋值,这里需要一个默认值,此时css变量(--co…...

【中霖教育怎么样】报考注册会计师有年龄限制吗?
【中霖教育怎么样】报考注册会计师有年龄限制吗? 申请参加注册会计师考试有没有年龄约束? 对于注册会计师的考试,不存在具体的年龄上限。而且该考试的入学门栏相对低,主要对考生的年龄下限规定。 在专业阶段,注册会计师考试要求考生具备…...
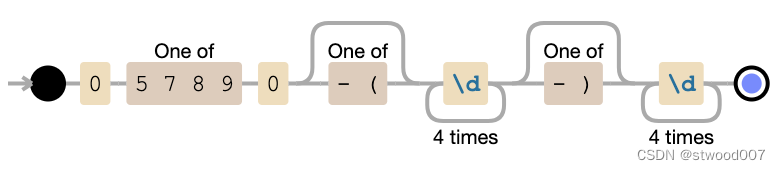
PHP验证日本手机电话号码
首先,您需要了解手机号码的规格。 根据 ,手机和PHS(个人手持电话系统)可以理解为以“070”、“080”和“090”开头的11位数字。 此外,以“050”开头的11位特定IP电话号码也将包含在该目标中。 关于以“060”开头的F…...

Qt 配置ASan
Qt 配置ASan 文章目录 Qt 配置ASan摘要关于ASan(AddressSanitizer)在Qt中配置 ASan1. 安装必要的工具2. 修改项目的 .pro 文件3. 重新构建项目4. 运行应用程序5. 分析错误报告示例注意事项 关键字: Qt、 ASan、 AddressSanitizer 、 GCC …...

MySQL常用操作命令大全
文章目录 一、连接与断开数据库1.1 连接数据库1.2 选择数据库1.3 断开数据库 二、数据库操作2.1 创建数据库2.2 查看数据库列表2.3 删除数据库 三、表操作3.1 创建表3.2 查看表结构3.3 修改表结构3.3.1 添加列3.3.2 删除列3.3.3 修改列数据类型 3.4 删除表 四、数据操作4.1 插入…...
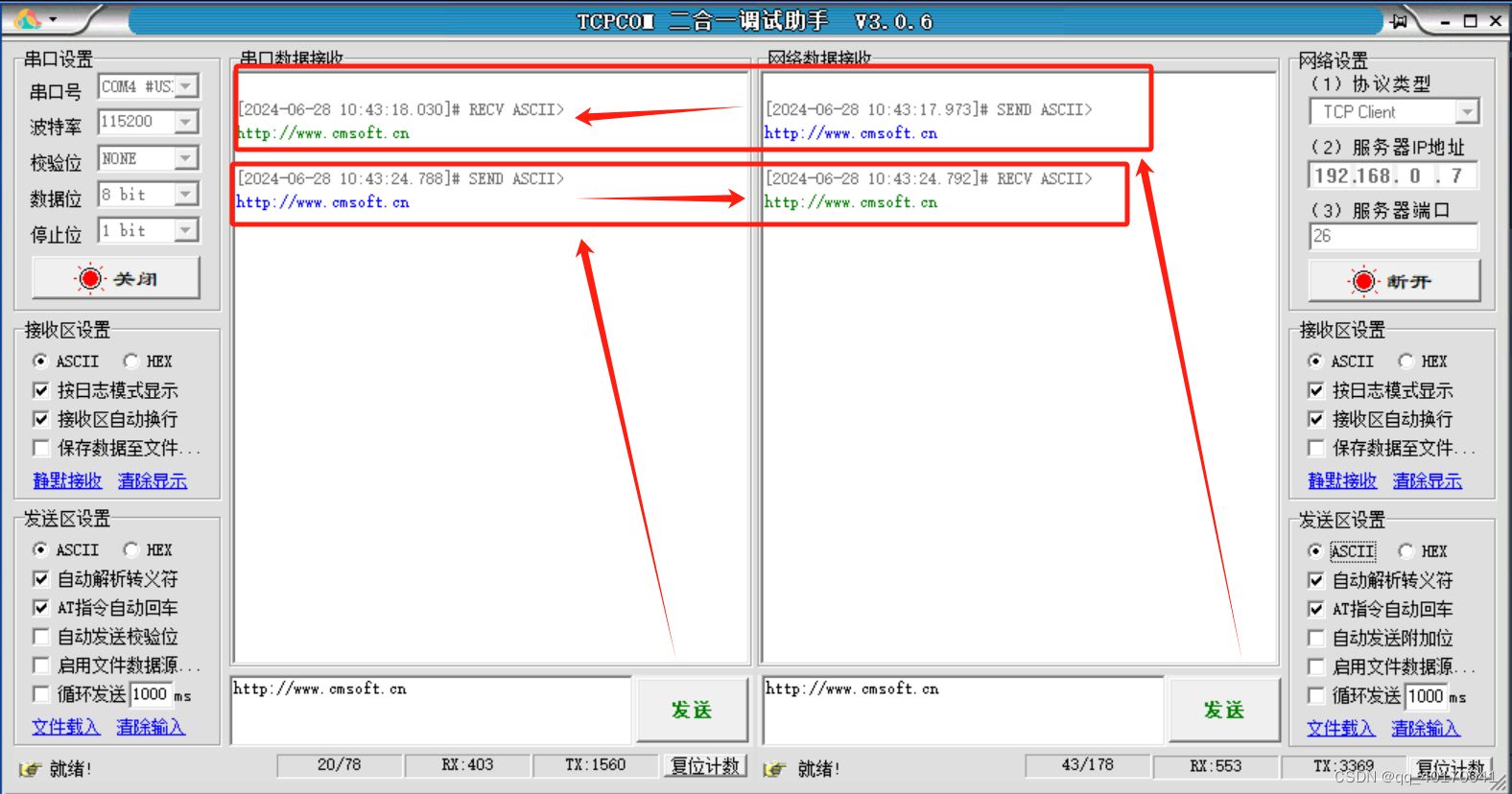
有人物联的串口服务器USR-TCP232-410S基本测试通信和使用方案(485串口和232串口)
1.将 410S(USR-TCP232-410S,简称 410S 下同)的串口通过串口线(或USB 转串口线)与计算机相连接,通过网线将 410S 的网口 PC 的网口相连接,检测硬件连接无错误后,接入我们配送的电源适配器,给 410S 供电。观察指示灯状态…...

二维码登录的原理
二维码登录的原理: 二维码登录是一种基于移动设备和网络技术的便捷登录方式。其原理主要依赖于以下几个关键要素: 随机生成:服务器端随机生成一个具有唯一性和时效性的二维码。编码信息:这个二维码包含了特定的登录信息,例如用户标识、会话标识、时间戳等。扫描识别:用户…...
归并排序详解(递归与非递归)
归并排序是建立在归并操作上的一种有效算法。该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列间断有序。若将两个有序表合并成一个有序表,成为二路归并。 一…...

SQL 中 OR 与 UNION ALL选择指南
一句话总结普通小表、无索引场景:用 OR 更简单、代码更短大表、有索引场景:用 UNION ALL 性能远优于 OR需要去重:必须用 UNION(性能比 UNION ALL 差)核心区别只扫描一次表 / 索引数据库需要同时判断两个条件致命问题&a…...

Diablo Edit2:暗黑破坏神2角色存档编辑器的终极指南
Diablo Edit2:暗黑破坏神2角色存档编辑器的终极指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾经在暗黑破坏神2中花费数小时刷装备却一无所获?是否因为技能点…...

星链引擎:AI 驱动的全域营销决策自动化系统技术实现
一、引言在当前数字化营销时代,企业面临着前所未有的数据爆炸和决策复杂度。一个典型的全域营销场景中,企业每天需要处理来自多个平台的数百万条用户行为数据,同时还要根据市场变化、竞品动态和用户反馈,实时调整内容策略、发布策…...

GenAIScript:用脚本化AI工作流提升代码生成效率与工程化实践
1. 项目概述:当AI遇上代码生成,GenAIScript带来了什么?如果你最近在关注AI如何改变开发工作流,特别是微软在AI领域的动作,那么microsoft/genaiscript这个项目绝对值得你花时间深入研究。这不仅仅是一个简单的代码生成工…...

OpenMC多群截面计算的3个颠覆性优化策略:从理论到工程实践
OpenMC多群截面计算的3个颠覆性优化策略:从理论到工程实践 【免费下载链接】openmc OpenMC Monte Carlo Code 项目地址: https://gitcode.com/gh_mirrors/op/openmc 核反应堆物理计算中,多群截面精度直接决定了整个模拟系统的可靠性。传统方法在处…...

机器人抓取仿真与数据分析:从PyBullet集成到抓取性能评估
1. 项目概述与核心价值最近在机器人控制与仿真领域,一个名为PyroMind-Dynamics/openclaw-tracer的项目引起了我的注意。乍一看这个标题,它像是一个典型的GitHub仓库名,由组织名“PyroMind-Dynamics”和项目名“openclaw-tracer”组成。作为一…...
)
DeepSeek MMLU成绩暴涨11.2分的秘密武器:不是更大参数,而是这个被顶会论文雪藏2年的校准框架(附开源复现代码)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek MMLU成绩暴涨11.2分的实证现象 近期,DeepSeek-R1 在大规模多任务语言理解(MMLU)基准测试中取得显著突破——其零样本准确率从 72.3% 提升至 83.5%ÿ…...

从零到一:手把手部署openGauss极简版并完成基础运维
1. 环境准备:从零搭建openGauss的基石 第一次接触openGauss时,我被它"极简版"的宣传吸引,但真正动手部署才发现,前期环境准备才是决定成败的关键。就像盖房子需要打地基,数据库安装前的系统配置直接影响后续…...

在Visual Studio 2022中搭建LVGL 8.3模拟器:从零开始的嵌入式GUI开发环境配置
1. 环境准备:搭建LVGL模拟器的基石 第一次接触嵌入式GUI开发时,我被各种硬件兼容性问题折磨得够呛。直到发现LVGL模拟器这个神器,才真正体会到"先模拟后部署"的开发乐趣。在Visual Studio 2022中配置LVGL 8.3模拟器,就…...

面向AI系统的非功能测试:公平性、可解释性与鲁棒性验证
一、引言:当“功能正确”不再是终点在软件测试的早期时代,我们的职责边界相对清晰——功能符合需求文档、性能达到指标、界面无错别字,测试便可宣告完成。然而,当AI系统从实验室的象牙塔走向社会决策的核心地带,这套传…...