雪花算法(SnowFlake)
简介
现在的服务基本是分布式、微服务形式的,而且大数据量也导致分库分表的产生,对于水平分表就需要保证表中 id 的全局唯一性。
对于 MySQL 而言,一个表中的主键 id 一般使用自增的方式,但是如果进行水平分表之后,多个表中会生成重复的 id 值。那么如何保证水平分表后的多张表中的 id 是全局唯一性的呢?
如果还是借助数据库主键自增的形式,那么可以让不同表初始化一个不同的初始值,然后按指定的步长进行自增。例如有3张拆分表,初始主键值为1,2,3,自增步长为3。
当然也有人使用 UUID 来作为主键,但是 UUID 生成的是一个无序的字符串,对于 MySQL 推荐使用增长的数值类型值作为主键来说不适合。
也可以使用 Redis 的自增原子性来生成唯一 id,但是这种方式业内比较少用。
当然还有其他解决方案,不同互联网公司也有自己内部的实现方案。雪花算法是其中一个用于解决分布式 id 的高效方案,也是许多互联网公司在推荐使用的。
SnowFlake 雪花算法
SnowFlake 中文意思为雪花,故称为雪花算法。最早是 Twitter 公司在其内部用于分布式环境下生成唯一 ID。在2014年开源 scala 语言版本。
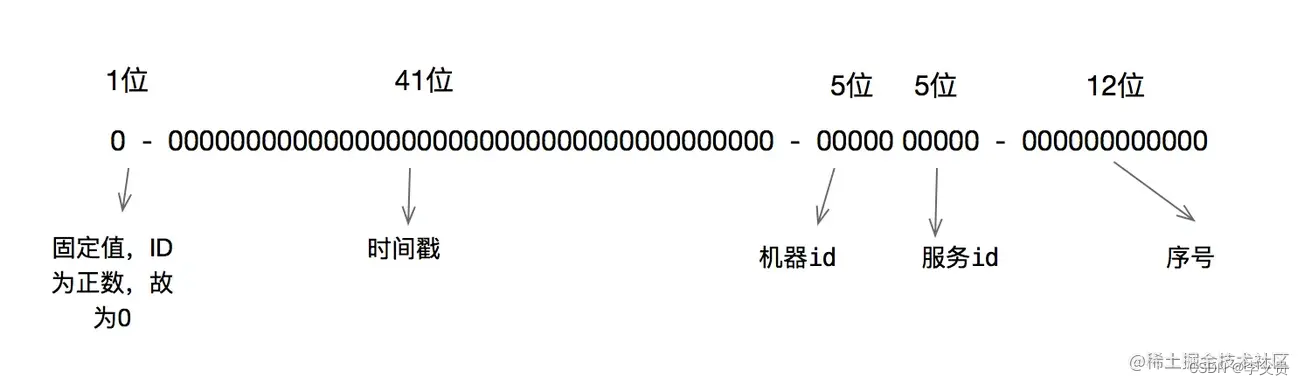
雪花算法的原理就是生成一个的 64 位比特位的 long 类型的唯一 id。
最高 1 位固定值 0,因为生成的 id 是正整数,如果是 1 就是负数了。
接下来 41 位存储毫秒级时间戳,2^41/(1000*60*60*24*365)=69,大概可以使用 69 年。
再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。
最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一 id 的系统,请求雪花算法服务获取 id 即可。
对于每一个雪花算法服务,需要先指定 10 位的机器码,这个根据自身业务进行设定即可。例如机房号+机器号,机器号+服务号,或者是其他可区别标识的 10 位比特位的整数值都行。
算法实现
package com.ruoyi.common.utils;import java.util.Date;/*** @ClassName: SnowFlakeUtil* 雪花算法*/
public class SnowFlakeUtil {private static SnowFlakeUtil snowFlakeUtil;static {snowFlakeUtil = new SnowFlakeUtil();}// 初始时间戳(纪年),可用雪花算法服务上线时间戳的值// 1650789964886:2022-04-24 16:45:59private static final long INIT_EPOCH = 1650789964886L;// 时间位取&private static final long TIME_BIT = 0b1111111111111111111111111111111111111111110000000000000000000000L;// 记录最后使用的毫秒时间戳,主要用于判断是否同一毫秒,以及用于服务器时钟回拨判断private long lastTimeMillis = -1L;// dataCenterId占用的位数private static final long DATA_CENTER_ID_BITS = 5L;// dataCenterId占用5个比特位,最大值31// 0000000000000000000000000000000000000000000000000000000000011111private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);// dataCenterIdprivate long dataCenterId;// workId占用的位数private static final long WORKER_ID_BITS = 5L;// workId占用5个比特位,最大值31// 0000000000000000000000000000000000000000000000000000000000011111private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);// workIdprivate long workerId;// 最后12位,代表每毫秒内可产生最大序列号,即 2^12 - 1 = 4095private static final long SEQUENCE_BITS = 12L;// 掩码(最低12位为1,高位都为0),主要用于与自增后的序列号进行位与,如果值为0,则代表自增后的序列号超过了4095// 0000000000000000000000000000000000000000000000000000111111111111private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);// 同一毫秒内的最新序号,最大值可为 2^12 - 1 = 4095private long sequence;// workId位需要左移的位数 12private static final long WORK_ID_SHIFT = SEQUENCE_BITS;// dataCenterId位需要左移的位数 12+5private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;// 时间戳需要左移的位数 12+5+5private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;/*** 无参构造*/public SnowFlakeUtil() {//实际分布式系统中,一种参考方案是dataCenterId为mac地址,workerId为pid相关this(1, 1);}/*** 有参构造* @param dataCenterId* @param workerId*/public SnowFlakeUtil(long dataCenterId, long workerId) {// 检查dataCenterId的合法值if (dataCenterId < 0 || dataCenterId > MAX_DATA_CENTER_ID) {throw new IllegalArgumentException(String.format("dataCenterId 值必须大于 0 并且小于 %d", MAX_DATA_CENTER_ID));}// 检查workId的合法值if (workerId < 0 || workerId > MAX_WORKER_ID) {throw new IllegalArgumentException(String.format("workId 值必须大于 0 并且小于 %d", MAX_WORKER_ID));}this.workerId = workerId;this.dataCenterId = dataCenterId;}/*** 获取唯一ID* @return*/public static Long getSnowFlakeId() {return snowFlakeUtil.nextId();}/*** 通过雪花算法生成下一个id,注意这里使用synchronized同步* @return 唯一id*/public synchronized long nextId() {long currentTimeMillis = System.currentTimeMillis();System.out.println(currentTimeMillis);// 当前时间小于上一次生成id使用的时间,可能出现服务器时钟回拨问题if (currentTimeMillis < lastTimeMillis) {throw new RuntimeException(String.format("可能出现服务器时钟回拨问题,请检查服务器时间。当前服务器时间戳:%d,上一次使用时间戳:%d", currentTimeMillis,lastTimeMillis));}if (currentTimeMillis == lastTimeMillis) {// 还是在同一毫秒内,则将序列号递增1,序列号最大值为4095// 序列号的最大值是4095,使用掩码(最低12位为1,高位都为0)进行位与运行后如果值为0,则自增后的序列号超过了4095// 那么就使用新的时间戳sequence = (sequence + 1) & SEQUENCE_MASK;if (sequence == 0) {currentTimeMillis = getNextMillis(lastTimeMillis);}} else { // 不在同一毫秒内,则序列号重新从0开始,序列号最大值为4095sequence = 0;}// 记录最后一次使用的毫秒时间戳lastTimeMillis = currentTimeMillis;// 核心算法,将不同部分的数值移动到指定的位置,然后进行或运行// <<:左移运算符, 1 << 2 即将二进制的 1 扩大 2^2 倍// |:位或运算符, 是把某两个数中, 只要其中一个的某一位为1, 则结果的该位就为1// 优先级:<< > |return// 时间戳部分((currentTimeMillis - INIT_EPOCH) << TIMESTAMP_SHIFT)// 数据中心部分| (dataCenterId << DATA_CENTER_ID_SHIFT)// 机器表示部分| (workerId << WORK_ID_SHIFT)// 序列号部分| sequence;}/*** 获取指定时间戳的接下来的时间戳,也可以说是下一毫秒* @param lastTimeMillis 指定毫秒时间戳* @return 时间戳*/private long getNextMillis(long lastTimeMillis) {long currentTimeMillis = System.currentTimeMillis();while (currentTimeMillis <= lastTimeMillis) {currentTimeMillis = System.currentTimeMillis();}return currentTimeMillis;}/*** 获取随机字符串,length=13* @return*/public static String getRandomStr() {return Long.toString(getSnowFlakeId(), Character.MAX_RADIX);}/*** 从ID中获取时间* @param id 由此类生成的ID* @return*/public static Date getTimeBySnowFlakeId(long id) {return new Date(((TIME_BIT & id) >> 22) + INIT_EPOCH);}public static void main(String[] args) {SnowFlakeUtil snowFlakeUtil = new SnowFlakeUtil();long id = snowFlakeUtil.nextId();System.out.println("id:" + id);Date date = SnowFlakeUtil.getTimeBySnowFlakeId(id);System.out.println(date);long time = date.getTime();System.out.println("time:" + time);System.out.println(getRandomStr());}}算法优缺点
雪花算法有以下几个优点:
高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
不依赖第三方库或者中间件。
算法简单,在内存中进行,效率高。
雪花算法有如下缺点:
依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
注意事项
其实雪花算法每一部分占用的比特位数量并不是固定死的。例如你的业务可能达不到 69 年之久,那么可用减少时间戳占用的位数,雪花算法服务需要部署的节点超过1024 台,那么可将减少的位数补充给机器码用。
注意,雪花算法中 41 位比特位不是直接用来存储当前服务器毫秒时间戳的,而是需要当前服务器时间戳减去某一个初始时间戳值,一般可以使用服务上线时间作为初始时间戳值。
对于机器码,可根据自身情况做调整,例如机房号,服务器号,业务号,机器 IP 等都是可使用的。对于部署的不同雪花算法服务中,最后计算出来的机器码能区分开来即可。
相关文章:
雪花算法(SnowFlake)
简介现在的服务基本是分布式、微服务形式的,而且大数据量也导致分库分表的产生,对于水平分表就需要保证表中 id 的全局唯一性。对于 MySQL 而言,一个表中的主键 id 一般使用自增的方式,但是如果进行水平分表之后,多个表…...

Linux防火墙
一、Linux防火墙Linux的防火墙体系主要在网络层,针对TCP/IP数据包实施过滤和限制,属于典型的包过滤防火墙(或称为网络层防火墙)。Linux系统的防火墙体系基于内核编码实现,具有非常稳定的性能和极高的效率,因…...

网络安全系列-四十七: IP协议号大全
IP协议号列表 这是用在IPv4头部和IPv6头部的下一首部域的IP协议号列表。 十进制十六进制关键字协议引用00x00HOPOPTIPv6逐跳选项RFC 246010x01ICMP互联网控制消息协议(ICMP)RFC 79220x02IGMP...
HTTP协议格式以及Fiddler用法
目录 今日良言:焦虑和恐惧改变不了明天,唯一能做的就是把握今天 一、HTTP协议的基本格式 二、Fiddler的用法 1.Fidder的下载 2.Fidder的使用 今日良言:焦虑和恐惧改变不了明天,唯一能做的就是把握今天 一、HTTP协议的基本格式 先来介绍一下http协议: http 协议(全称为 &q…...

自动写代码?别闹了!
大家好,我是良许。 这几天,GitHub 上有个很火的插件在抖音刷屏了——Copilot。 这个神器有啥用呢?简单来讲,它就是一款由人工智能打造的编程辅助工具。 我们来看看它有啥用。 首先就是代码补全功能,你只要给出函数…...
项目心得--网约车
一、RESTFULPost:新增Put:全量修改Patch:修改某个值Delete: 删除Get:查询删除接口也可以用POST请求url注意:url中不要带有敏感词(用户id等)url中的名词用复数形式url设计:api.xxx.co…...

【二叉树广度优先遍历和深度优先遍历】
文章目录一、二叉树的深度优先遍历0.建立一棵树1. 前序遍历2.中序遍历3. 后序遍历二、二叉树的广度优先遍历层序遍历三、有关二叉树练习一、二叉树的深度优先遍历 学习二叉树结构,最简单的方式就是遍历。 所谓二叉树遍历(Traversal)是按照某种特定的规则ÿ…...
Spring Cloud微服务架构必备技术
单体架构 单体架构,也叫单体应用架构,是一个传统的软件架构模式。单体架构是指将应用程序的所有组件部署到一个单一的应用程序中,并统一进行部署、维护和扩展。在单体架构中,应用程序的所有功能都在同一个进程中运行,…...
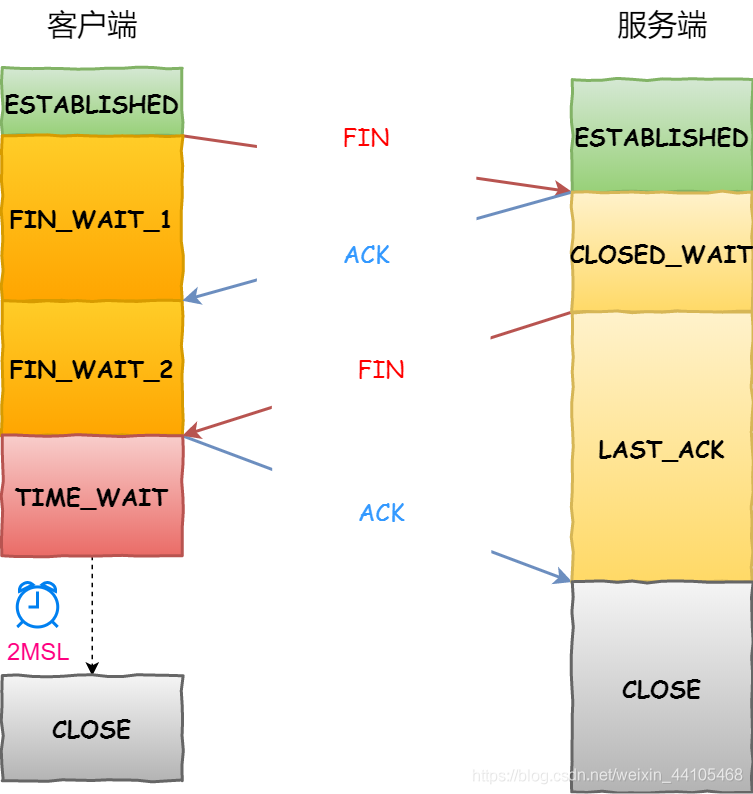
TCP三次握手与四次挥手(一次明白)
TCP基本信息 默认端口号:80 LINUX中TIME_WAIT的默认时间是30s TCP三次握手 三次握手过程:每行代表发起握手到另一方刚刚收到数据包时的状态 客户端服务端客户端状态服务端状态握手前CLOSELISTEN客户端发送带有SYN标志的数据包到服务端一次握手SYN_SENDLISTEN二次握手服务端发送…...

pyside6@Mouse events实例@QApplication重叠导致的报错@keyboardInterrupt
文章目录报错内容鼠标事件演示报错内容 在pyside图形界面应用程序开发过程中,通常只允许运行一个实例 假设您重复执行程序A,那么可能会导致一些意向不到的错误并且,从python反馈的信息不容易判断错误的真正来源 鼠标事件演示 下面是一段演示pyside6的鼠标事件mouseEvent对象…...

订单30分钟未支付自动取消怎么实现?
目录了解需求方案 1:数据库轮询方案 2:JDK 的延迟队列方案 3:时间轮算法方案 4:redis 缓存方案 5:使用消息队列了解需求在开发中,往往会遇到一些关于延时任务的需求。例如生成订单 30 分钟未支付࿰…...

< 开源项目框架:推荐几个开箱即用的开源管理系统 - 让开发不再复杂 >
文章目录👉 SCUI Admin 中后台前端解决方案👉 Vue .NetCore 前后端分离的快速发开框架👉 next-admin 适配移动端、pc的后台模板👉 django-vue-admin-pro 快速开发平台👉 Admin.NET 通用管理平台👉 RuoYi 若…...

内网渗透-基础环境
解决依赖,scope安装 打开要给cmd powershell 打开远程 Set-ExecutionPolicy RemoteSigned -scope CurrentUser; 我试了好多装这东西还是得科学上网,不然不好用 iwr -useb get.scoop.sh | iex 查看下载过的软件 安装sudo 安装git 这里一定要配置bu…...

Go语言学习的第一天(对于Go学习的认识和工具选择及环境搭建)
首先学习一门新的语言,我们要知道这门语言可以帮助我们做些什么?为什么我们要学习这门语言?就小wei而言学习这门语言是为了区块链,因为自身是php出身,因为php的一些特性只能通过一些算法模拟的做一个虚拟链,…...

C和C++到底有什么关系
C++ 读作”C加加“,是”C Plus Plus“的简称。顾名思义,C++是在C的基础上增加新特性,玩出了新花样,所以叫”C Plus Plus“,就像 iPhone 6S 和 iPhone 6、Win10 和 Win7 的关系。 C语言是1972年由美国贝尔实验室研制成功的,在当时算是高级语言,它的很多新特性都让汇编程序…...
14个Python处理Excel的常用操作,非常好用
自从学了Python后就逼迫用Python来处理Excel,所有操作用Python实现。目的是巩固Python,与增强数据处理能力。 这也是我写这篇文章的初衷。废话不说了,直接进入正题。 数据是网上找到的销售数据,长这样: 一、关联公式:…...

async/await 用法
1. 什么是 async/await async/await 是 ES8(ECMAScript 2017)引入的新语法,用来简化 Promise 异步操作。在 async/await 出 现之前,开发者只能通过链式 .then() 的方式处理 Promise 异步操作。示例代码如下: import …...
好意外,发现永久免费使用的云服务器
原因就不说了,说一下过程,在百度搜pythonIDE的时候,发现了一个网站 https://lightly.teamcode.com/https://lightly.teamcode.com/ 就是这个网站,看见这个免费试用,一开始觉得没什么,在尝试使用的过程中发…...
VSCode使用技巧,代码编写效率提升2倍以上!
VSCode是一款开源免费的跨平台文本编辑器,它的可扩展性和丰富的功能使得它成为了许多程序员的首选编辑器。在本文中,我将分享一些VSCode的使用技巧,帮助您更高效地使用它。 1. 插件 VSCode具有非常丰富的插件生态系统,通过安装插…...
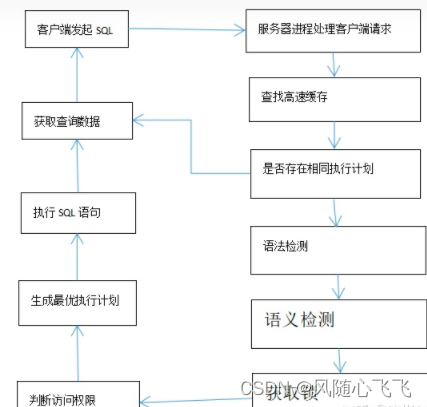
SQL执行过程详解
1 、用户在客户端执行 SQL 语句时,客户端把这条 SQL 语句发送给服务端,服务端的进程,会处理这条客户端的SQL语句。 2 、服务端进程收集到SQL信息后,会在进程全局区PGA 中分配所需内存,存储相关的登录信息等。 3 、客…...

掌握AI专著撰写技巧,借助工具3天完成20万字专著创作!
学术专著的生命力在于逻辑的严谨性,而逻辑论证正是写作中最容易出现问题的地方。专著的撰写必须围绕核心观点展开系统的论证,既需要对每一个论点进行详细的阐述,还要面对不同学派的争议观点,同时保证理论框架的自洽,避…...

CentOS7网络配置与XShell连接实战:从零搭建远程管理环境
1. 环境准备与工具安装 第一次接触Linux服务器管理的新手,往往会被网络配置和远程连接这两个基础操作难住。我自己刚开始学习时,光是让虚拟机联网就折腾了大半天。其实只要掌握正确的方法,整个过程完全可以像搭积木一样简单明了。 首先需要准…...

PCB高级工艺如何降本:盲孔、微孔与HDI设计的成本优化实战
1. 项目概述:当高级PCB技术成为降本利器在硬件研发圈子里待久了,总有一个根深蒂固的印象:但凡沾上“高级”、“高密度”这些词的技术,比如盲孔、埋孔和微孔,那成本肯定是蹭蹭往上涨。我刚开始接触HDI板设计时也是这么想…...

Anaconda环境翻车实录:从‘CondaMemoryError’到完美恢复的完整指南
Anaconda环境崩溃自救手册:从诊断到彻底修复的实战指南 那天下午,当你在终端第15次尝试运行conda update --all时,屏幕上突然跳出鲜红的"CondaMemoryError"字样,整个开发环境瞬间陷入瘫痪。这不是普通的报错,…...

基于RAG与LangChain的AI阅读助手BookWith架构与实现
1. 项目概述:当AI成为你的阅读伙伴作为一名深度阅读爱好者和技术实践者,我一直在寻找一种能真正“理解”内容,并与我进行深度对话的阅读工具。传统的电子书阅读器,无论是Kindle还是其他应用,本质上都只是将纸质书数字化…...

深度解析Layui formSelects:现代Web应用中的多选下拉框终极解决方案
深度解析Layui formSelects:现代Web应用中的多选下拉框终极解决方案 【免费下载链接】layui-formSelects Layui select多选小插件 项目地址: https://gitcode.com/gh_mirrors/la/layui-formSelects 在当今的Web开发领域,表单交互体验直接影响着用…...

基于堆叠自编码器与LSTM的金融时间序列预测框架解析
1. 项目概述:一个基于多层神经网络的股票回报预测框架如果你对量化交易和机器学习结合感兴趣,并且已经厌倦了那些简单的线性回归或者单层LSTM模型,那么这个名为AIAlpha的项目可能会让你眼前一亮。它不是一个“即插即用”的盈利策略࿰…...

北京AGG专用配件哪家性价比高
在选择AGG聚砂吸声系统的专用配件时,不少工程方和设计师都会问“北京哪家性价比高”。我的建议是:别只看标价,要看配件与系统的适配度、长期使用的稳定性,以及能否提供及时的技术支持。AGG系统本身是一个完整的声学解决方案&#…...

从‘不好用的CE’到‘好用的OD’:一次逆向实战中的工具选择与思路转换
逆向工程实战:从工具局限到思维跃迁的破解之道 当那个MFC程序弹出第一个窗口时,我习惯性地打开了Cheat Engine——这个在游戏修改领域堪称神器的工具。但十分钟后,面对毫无进展的扫描结果和不断跳出的错误提示,我突然意识到&#…...

SyntaxUI:基于Tailwind CSS与Framer Motion的React组件库实战指南
1. 项目概述:SyntaxUI,一个为现代Web开发者提速的组件库如果你和我一样,常年奋战在React、Next.js项目的一线,那你一定对“重复造轮子”这件事深恶痛绝。每次新项目启动,从零开始搭建按钮、卡片、模态框、导航栏&#…...