14个Python处理Excel的常用操作,非常好用
自从学了Python后就逼迫用Python来处理Excel,所有操作用Python实现。目的是巩固Python,与增强数据处理能力。
这也是我写这篇文章的初衷。废话不说了,直接进入正题。
数据是网上找到的销售数据,长这样:
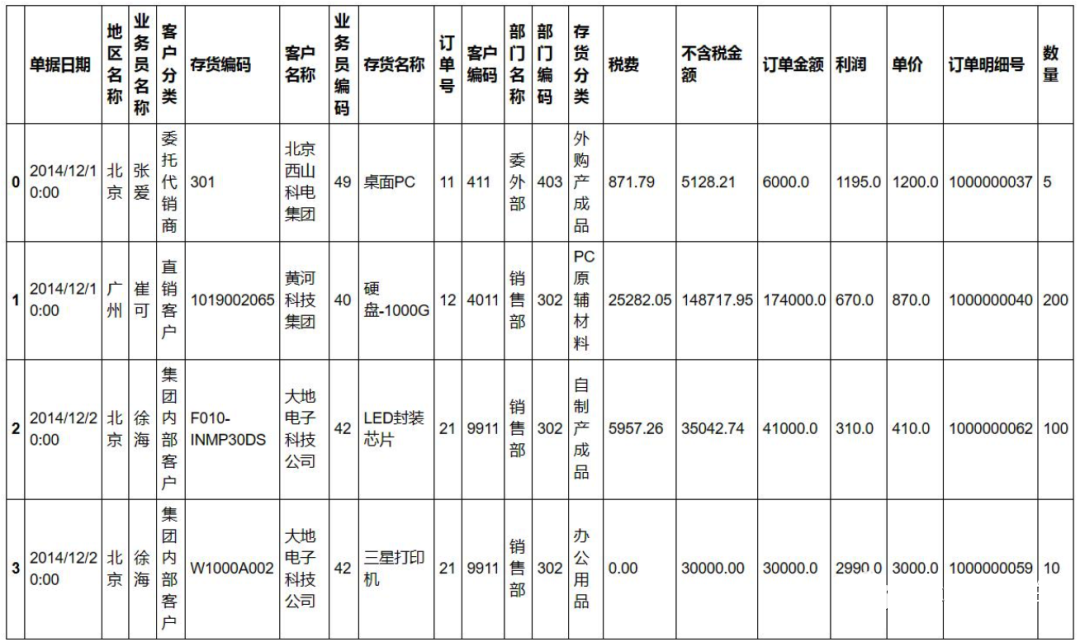
一、关联公式:Vlookup
vlookup是excel几乎最常用的公式,一般用于两个表的关联查询等。所以我先把这张表分为两个表。
df1=sale[['订单明细号','单据日期','地区名称', '业务员名称','客户分类', '存货编码', '客户名称', '业务员编码', '存货名称', '订单号','客户编码', '部门名称', '部门编码']]
df2=sale[['订单明细号','存货分类', '税费', '不含税金额', '订单金额', '利润', '单价','数量']]
需求:想知道df1的每一个订单对应的利润是多少。
利润一列存在于df2的表格中,所以想知道df1的每一个订单对应的利润是多少。用excel的话首先确认订单明细号是唯一值,然后在df1新增一列写:=vlookup(a2,df2!a:h,6,0) ,然后往下拉就ok了。(剩下13个我就不写excel啦)
那用python是如何实现的呢?
#查看订单明细号是否重复,结果是没。
df1["订单明细号"].duplicated().value_counts()
df2["订单明细号"].duplicated().value_counts()df_c=pd.merge(df1,df2,on="订单明细号",how="left")
兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。
那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及源代码!
还会有大佬解答!
文末名片扫码自取哈
二、数据透视表
需求:想知道每个地区的业务员分别赚取的利润总和与利润平均数。
pd.pivot_table(sale,index="地区名称",columns="业务员名称",values="利润",aggfunc=[np.sum,np.mean])
三、对比两列差异
因为这表每列数据维度都不一样,比较起来没啥意义,所以我先做了个订单明细号的差异再进行比较。
需求:比较订单明细号与订单明细号2的差异并显示出来。
sale["订单明细号2"]=sale["订单明细号"]#在订单明细号2里前10个都+1.
sale["订单明细号2"][1:10]=sale["订单明细号2"][1:10]+1#差异输出
result=sale.loc[sale["订单明细号"].isin(sale["订单明细号2"])==False]
四、去除重复值
需求:去除业务员编码的重复值
sale.drop_duplicates("业务员编码",inplace=True)
五、缺失值处理
先查看销售数据哪几列有缺失值。
#列的行数小于index的行数的说明有缺失值,这里客户名称329<335,说明有缺失值
sale.info()

需求:用0填充缺失值或则删除有客户编码缺失值的行。
实际上缺失值处理的办法是很复杂的,这里只介绍简单的处理方法,若是数值变量,最常用平均数或中位数或众数处理,比较复杂的可以用随机森林模型根据其他维度去预测结果填充。若是分类变量,根据业务逻辑去填充准确性比较高。
比如这里的需求填充客户名称缺失值: 就可以根据存货分类出现频率最大的存货所对应的客户名称去填充。
这里我们用简单的处理办法:用0填充缺失值或则删除有客户编码缺失值的行。
#用0填充缺失值
sale["客户名称"]=sale["客户名称"].fillna(0)
#删除有客户编码缺失值的行
sale.dropna(subset=["客户编码"])
六、多条件筛选
需求:想知道业务员张爱,在北京区域卖的商品订单金额大于6000的信息。
sale.loc[(sale["地区名称"]=="北京")&(sale["业务员名称"]=="张爱")&(sale["订单金额"]>5000)]
七、 模糊筛选数据
需求:筛选存货名称含有"三星"或则含有"索尼"的信息。
sale.loc[sale["存货名称"].str.contains("三星|索尼")]
八、分类汇总
需求:北京区域各业务员的利润总额。
sale.groupby(["地区名称","业务员名称"])["利润"].sum()
九、条件计算
需求:存货名称含“三星字眼”并且税费高于1000的订单有几个?这些订单的利润总和和平均利润是多少?(或者最小值,最大值,四分位数,标注差)
sale.loc[sale["存货名称"].str.contains("三星")&(sale["税费"]>=1000)][["订单明细号","利润"]].describe()

十、删除数据间的空格
需求:删除存货名称两边的空格。
sale["存货名称"].map(lambda s :s.strip(""))
十一、数据分列
需求:将日期与时间分列。
sale=pd.merge(sale,pd.DataFrame(sale["单据日期"].str.split(" ",expand=True)),how="inner",left_index=True,right_index=True)
十二、异常值替换
首先用describe()函数简单查看一下数据有无异常值。
#可看到销项税有负数,一般不会有这种情况,视它为异常值。
sale.describe()
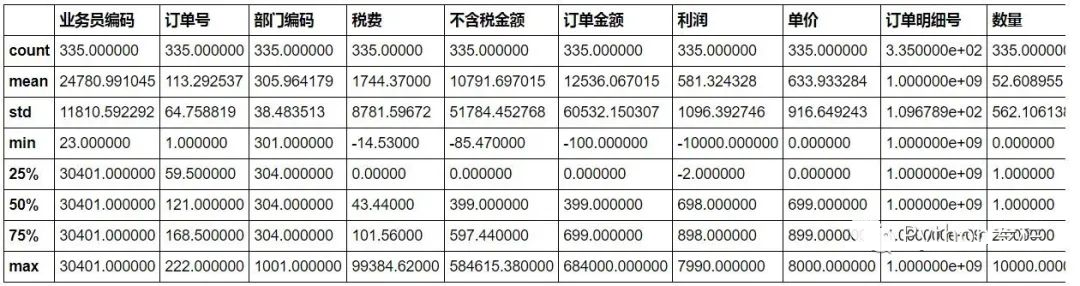
需求:用0代替异常值。
sale["订单金额"]=sale["订单金额"].replace(min(sale["订单金额"]),0)
十三、分组
需求:根据利润数据分布把地区分组为:“较差”,“中等”,“较好”,“非常好”
首先,当然是查看利润的数据分布呀,这里我们采用四分位数去判断。
sale.groupby("地区名称")["利润"].sum().describe()
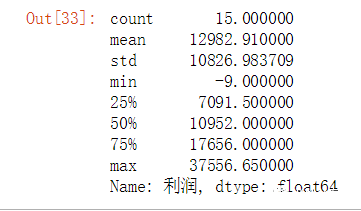
根据四分位数把地区总利润为[-9,7091]区间的分组为“较差”,(7091,10952]区间的分组为"中等" (10952,17656]分组为较好,(17656,37556]分组为非常好。
#先建立一个Dataframe
sale_area=pd.DataFrame(sale.groupby("地区名称")["利润"].sum()).reset_index()#设置bins,和分组名称
bins=[-10,7091,10952,17656,37556]
groups=["较差","中等","较好","非常好"]#使用cut分组
#sale_area["分组"]=pd.cut(sale_area["利润"],bins,labels=groups)
十四、根据业务逻辑定义标签
需求:销售利润率(即利润/订单金额)大于30%的商品信息并标记它为优质商品,小于5%为一般商品。
sale.loc[(sale["利润"]/sale["订单金额"])>0.3,"label"]="优质商品"
sale.loc[(sale["利润"]/sale["订单金额"])<0.05,"label"]="一般商品"
其实excel常用的操作还有很多,我就列举了14个自己比较常用的,若还想实现哪些操作可以评论一起交流讨论,另外我自身也知道我写python不够精简,惯性使用loc。(其实query会比较精简)。若大家对这几个操作有更好的写法请务必评论告知我,感谢!
最后想说说,我觉得最好不要拿excel和python做对比,去研究哪个好用,其实都是工具,excel作为最为广泛的数据处理工具,垄断这么多年必定在数据处理方便也是相当优秀的,有些操作确实python会比较简单,但也有不少excel操作起来比python简单的。
比如一个很简单的操作:对各列求和并在最下一行显示出来,excel就是对一列总一个sum()函数,然后往左一拉就解决,而python则要定义一个函数(因为python要判断格式,若非数值型数据直接报错。)
总结一下就是:无论用哪个工具,能解决问题就是好数据分析师!
相关文章:
14个Python处理Excel的常用操作,非常好用
自从学了Python后就逼迫用Python来处理Excel,所有操作用Python实现。目的是巩固Python,与增强数据处理能力。 这也是我写这篇文章的初衷。废话不说了,直接进入正题。 数据是网上找到的销售数据,长这样: 一、关联公式:…...

async/await 用法
1. 什么是 async/await async/await 是 ES8(ECMAScript 2017)引入的新语法,用来简化 Promise 异步操作。在 async/await 出 现之前,开发者只能通过链式 .then() 的方式处理 Promise 异步操作。示例代码如下: import …...
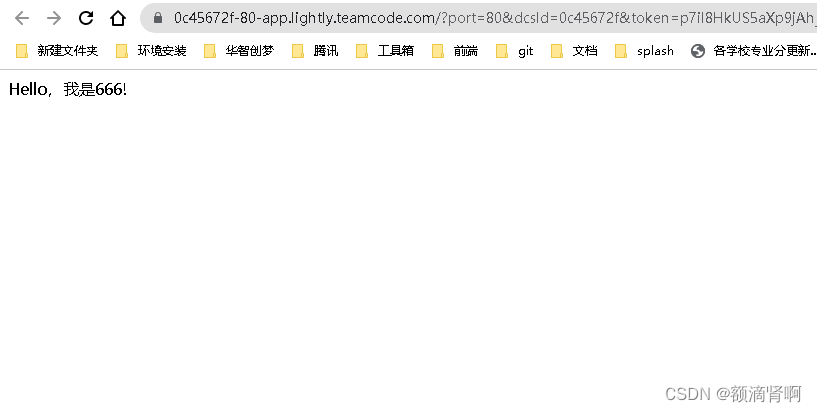
好意外,发现永久免费使用的云服务器
原因就不说了,说一下过程,在百度搜pythonIDE的时候,发现了一个网站 https://lightly.teamcode.com/https://lightly.teamcode.com/ 就是这个网站,看见这个免费试用,一开始觉得没什么,在尝试使用的过程中发…...
VSCode使用技巧,代码编写效率提升2倍以上!
VSCode是一款开源免费的跨平台文本编辑器,它的可扩展性和丰富的功能使得它成为了许多程序员的首选编辑器。在本文中,我将分享一些VSCode的使用技巧,帮助您更高效地使用它。 1. 插件 VSCode具有非常丰富的插件生态系统,通过安装插…...
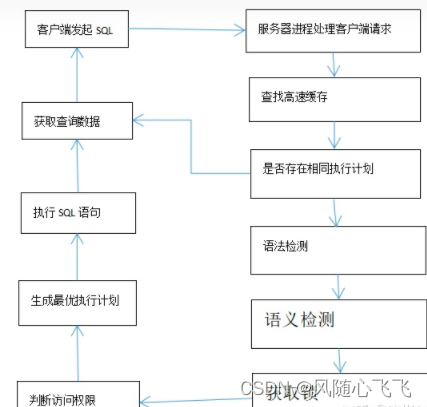
SQL执行过程详解
1 、用户在客户端执行 SQL 语句时,客户端把这条 SQL 语句发送给服务端,服务端的进程,会处理这条客户端的SQL语句。 2 、服务端进程收集到SQL信息后,会在进程全局区PGA 中分配所需内存,存储相关的登录信息等。 3 、客…...
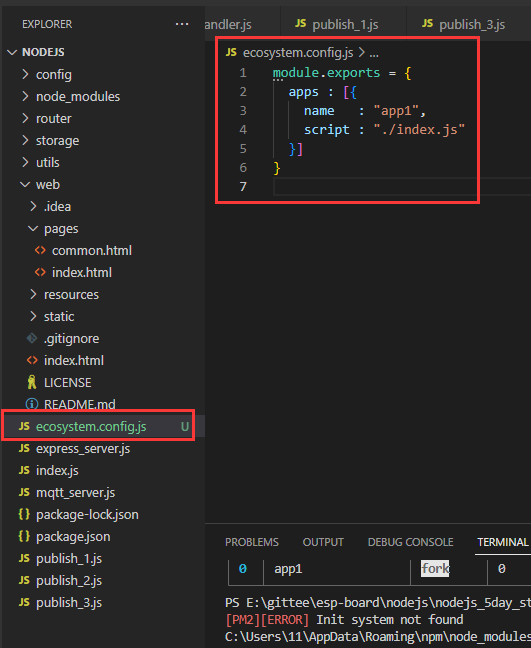
【物联网NodeJs-5天学习】第四天存储篇⑤ ——PM2,node.js应用进程管理器
【NodeJs-5天学习】第四天存储篇⑤ ——PM2,node.js应用进程管理器1. 前言2. 官方说明3. 安装PM24. PM2常用命令4.1 启动命令4.2 重新启动命令4.3 热重载命令4.4 停止命令4.5 删除命令4.6 查看进程运行状态4.4 显示某一个进程的具体信息4.8 显示日志信息4.9 终端监控…...

【C++学习】【STL】deque容器
dequeDouble Ended Queues(双向队列)deque和vector很相似,但是它允许在容器头部快速插入和删除(就像在尾部一样)。所耗费的时间复杂度也为常数阶O(1)。并且更重要的一点是,deque 容器中存储元素并不能保证所有元素都存储到连续的内…...

当 App 有了系统权限,真的可以为所欲为?
看到群里发了两篇文章,出于好奇,想看看这些个 App 在利用系统漏洞获取系统权限之后,都干了什么事,于是就有了这篇文章。由于准备仓促,有些 Code 没有仔细看,感兴趣的同学可以自己去研究研究,多多…...

vue3.js的介绍
一.vue.js简述 Vue是一套用于构建用户开源的MVVM结构的Javascript渐进式框架,尤雨溪在2015年10月27日发布了vue.js 1.0Eavangelion版本,在2016年9月30日发布了2.0Ghost in the Shell版本,目前项目由官方负责 vue的核心只关注图层࿰…...

【Three.js】shader特效 能量盾
shader特效之能量盾前言效果噪点图主要代码index.htmldepth-fs.jsdepth-vs.jsshield-fs.jsshield-vs.js相关项目前言 效果噪点图 为了可以自定义能量球的效果,这里使用外部加载来的噪点图做纹理,省去用代码写特效的过程。 主要代码 index.html <…...

【6000字长文】需求评审总是被怼?强烈推荐你试试这三招
前段时间和一个合作部门的产品新人沟通需求,结束的时候,他问了我一个问题,“你在产品新人阶段,最害怕做的事情是什么”? 我不假思索的回答说,“需求评审,是曾经最不想面对的环节,甚至在评审之前几个小时就开始心跳加速了。当然这也是产品修炼路上的必经之路,其实只要掌…...

Hive介绍及DDL
1.OLTP和OLAP OLTP: 联机事务处理系统。在前台接收的用户数据可以立即传送到后台进行处理,并在很短的时间内给出处理结果。关系型数据库是OLTP典型应用,如MySQL OLTP环境开展数据分析是否可行? 为了更好的开展数据分析&#x…...

Simulink 自动代码生成电机控制:在某国产ARM0定点MCU上实现自动代码生成无感电机控制
目录 前言 开发流程 定点化的技巧 代码生成运行演示 总结 前言 这次尝试了在国产arm0内核的MCU上实现Simulink自动代码生成永磁同步电机无传感控制。机缘巧合之下拿到了一块国产MCU的电机控制板和一个5000RPM的小电机。最后实现了无传感控制,在这里总结下一些经…...
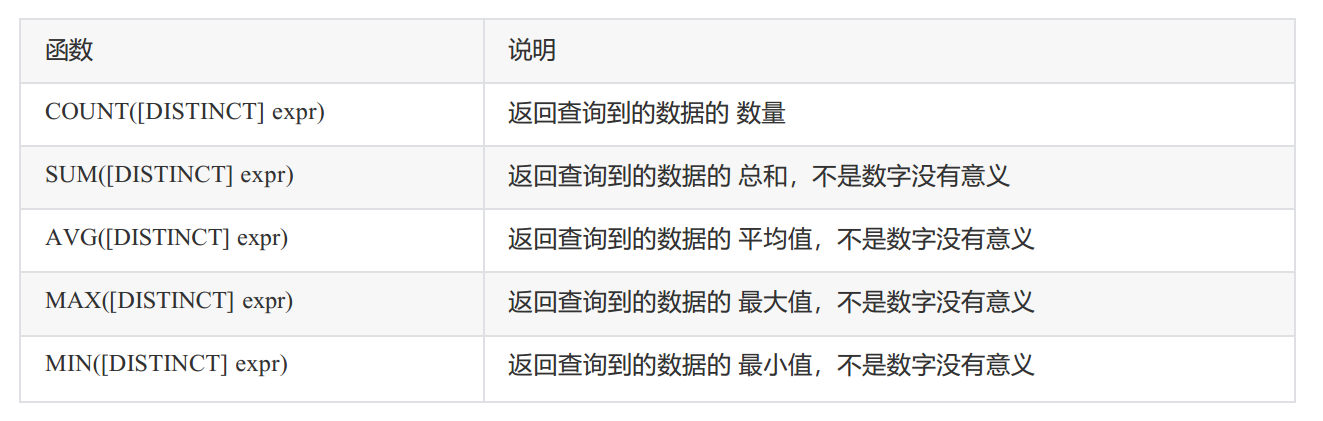
MySQL基本查询
文章目录表的增删查改Create(创建)单行数据 全列插入多行数据 指定列插入插入否则更新替换Retrieve(读取)SELECT列全列查询指定列查询查询字段为表达式查询结果指定别名结果去重WHERE 条件基本比较BETWEEN AND 条件连接OR 条件连…...

你需要知道的 7 个 Vue3 技巧
VNode 钩子在每个组件或html标签上,我们可以使用一些特殊的(文档没写的)钩子作为事件监听器。这些钩子有:onVnodeBeforeMountonVnodeMountedonVnodeBeforeUpdateonVnodeUpdatedonVnodeBeforeUnmountonVnodeUnmounted我主要是在组件…...

行政区划获取
行政区划获取一、导入jar包二、代码展示背景:公司的行政区划代码有问题,有的没有街道信息,有的关联信息有误,然后找到了国家的网站国家统计局-行政区划,这个里面是包含了所有的行政信息,但是全是html页面&a…...

让ChatGPT介绍一下ChatGPT
申请新必应内测通过了,我在New Bing中使用下ChatGPT,让ChatGPT介绍一下ChatGPT 问题1:帮我生成一篇介绍chatGPT的文章,不少于2000字 回答: chatGPT是什么?它有什么特点和用途? chatGPT是一种…...
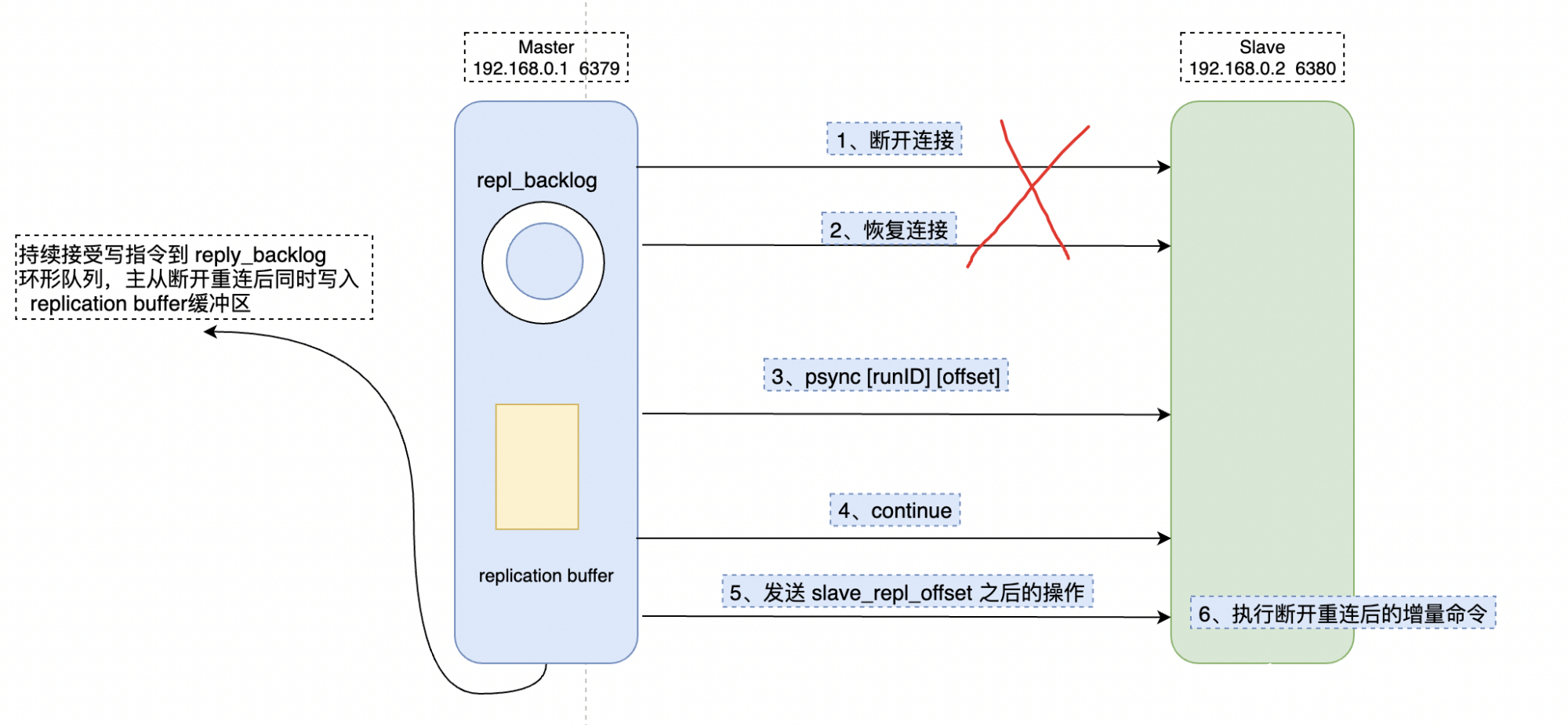
【Redis】Redis 主从复制 + 读写分离
Redis 主从复制 读写分离1. Redis 主从复制 读写分离介绍1.1 从数据持久化到服务高可用1.2 主从复制1.3 如何保证主从数据一致性?1.4 为何采用读写分离模式?2. 一主两从环境准备2.1 配置文件2.2 启动 Redis3. 主从复制原理3.1 全量同步3.1.1 建立连接3…...

2023届秋招,鬼知道我经历了什么
仅记录个人经历,充满主观感受,甚至纯属虚构,仅供参考,杠就是你对 本想毕业再写,但是考虑到等毕业了,24秋招的提前批就快开始了,大概就来不及了,正好现在有点时间,陆陆续…...
ChatGPT助力校招----面试问题分享(一)
1 ChatGPT每日一题:期望薪资是多少 问题:面试官问期望薪资是多少,如何回答 ChatGPT:当面试官问及期望薪资时,以下是一些建议的回答方法: 1、调查市场行情:在回答之前,可以先调查一…...

实战复盘:我是如何用Elastic Security+Zeek构建一个小型企业安全监控平台的
实战复盘:Elastic SecurityZeek构建小型企业安全监控平台 当企业规模扩张到50人以上时,网络资产和终端设备数量会呈现指数级增长。去年为某电商团队部署安全系统时,他们的CTO向我展示了一份令人不安的数据:平均每天遭遇23次暴力破…...
函数挪到自己的.c文件里(STM32F4实战))
告别CubeMX代码洁癖:教你如何把main()函数挪到自己的.c文件里(STM32F4实战)
重构STM32工程的艺术:将main()迁移到自定义文件的实战指南 每次打开CubeMX生成的工程,看到那个被各种初始化代码塞满的main.c文件,你是否也感到一丝不适?作为一名有追求的嵌入式开发者,我们渴望对项目结构拥有绝对掌控…...

国家中小学智慧教育平台电子课本下载工具:教育资源获取的完整解决方案
国家中小学智慧教育平台电子课本下载工具:教育资源获取的完整解决方案 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内…...

解锁PS4游戏存档的终极掌控:Apollo Save Tool深度技术解析
解锁PS4游戏存档的终极掌控:Apollo Save Tool深度技术解析 【免费下载链接】apollo-ps4 Apollo Save Tool (PS4) 项目地址: https://gitcode.com/gh_mirrors/ap/apollo-ps4 在PlayStation 4的游戏生态中,PS4存档管理和游戏数据修改一直是玩家和开…...

NeuroSynth脑成像元分析:Python神经影像数据处理终极指南
NeuroSynth脑成像元分析:Python神经影像数据处理终极指南 【免费下载链接】neurosynth Neurosynth core tools 项目地址: https://gitcode.com/gh_mirrors/ne/neurosynth NeuroSynth是一个功能强大的Python包,专门用于大规模功能性神经影像数据的…...

TEdit地图编辑器:从零开始掌握泰拉瑞亚世界创作
TEdit地图编辑器:从零开始掌握泰拉瑞亚世界创作 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you change w…...

peaqOS 给机器发了一份穆迪式评级,机器经济缺的最后一块零件被补上了
作者:PaperMoon团队 “It’s time for blockchain to live up to its full potential。” 这种句子在 2026 年的 Web3 推文里已经少见了,大部分项目方学会了克制。peaq 这次不克制,而且把"全新资产类别"这种 2017 年级别的措辞重新…...

macOS OBS虚拟摄像头技术实现指南:CoreMediaIO架构与DAL插件开发
macOS OBS虚拟摄像头技术实现指南:CoreMediaIO架构与DAL插件开发 【免费下载链接】obs-mac-virtualcam ARCHIVED! This plugin is officially a part of OBS as of version 26.1. See note below for info on upgrading. 🎉🎉🎉Cr…...

暗黑2存档编辑器:免费开源工具助你轻松修改角色与装备
暗黑2存档编辑器:免费开源工具助你轻松修改角色与装备 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 暗黑2存档编辑器是一款专门为《暗黑破坏神2》玩家设计的免费开源工具,让你能够轻松修改游戏存档&…...

谷歌seo搜索引擎优化教程有吗?资深SEO总结的15个高效提速工具
很多企业主每年在独立站开发上投入超过 10 万人民币,但网站上线半年,每天的自然访问量依然是个位数。面对“谷歌seo搜索引擎优化教程有吗?”这种疑问,行业内的真实情况是:绝大部分公开课都在讲十年前的套路,…...