【PYG】Cora数据集分类任务计算损失,cross_entropy为什么不能直接替换成mse_loss
- cross_entropy计算误差方式,输入向量z为[1,2,3],预测y为[1],选择数为2,计算出一大坨e的式子为3.405,再用-2+3.405计算得到1.405
- MSE计算误差方式,输入z为[1,2,3],预测向量应该是[1,0,0],和输入向量维度相同
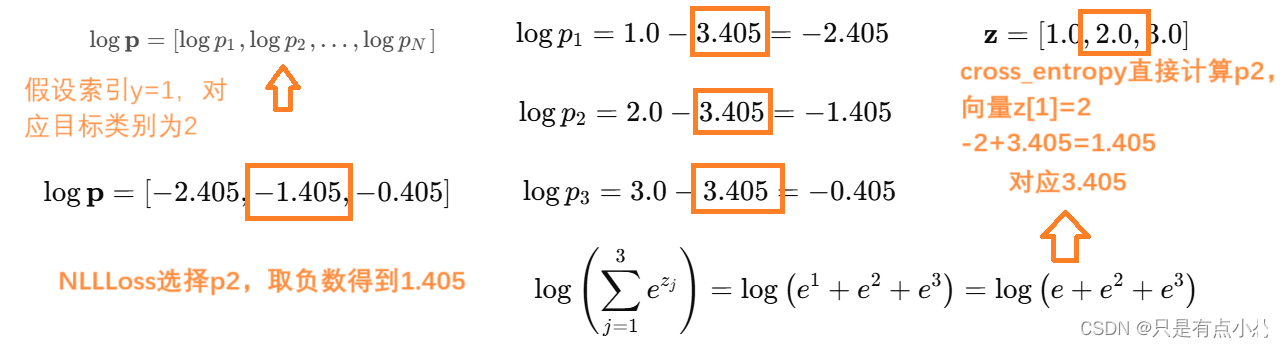
将cross_entropy直接替换成mse_loss报错RuntimeError: The size of tensor a (7) must match the size of tensor b (140) at non-singleton dimension 1
将 cross_entropy 换成 mse_loss 会报错的原因是,这两个损失函数的输入和输出形状要求不同。cross_entropy 是一个分类损失函数,它期望输入是未归一化的logits(形状为 [batch_size, num_classes]),而标签是整数类别(形状为 [batch_size])。mse_loss 是一个回归损失函数,它期望输入和标签的形状相同。
如果你想使用 mse_loss 来替代 cross_entropy,你需要对标签进行one-hot编码,使它们与模型的输出形状匹配。下面是如何修改代码以使用 mse_loss 的示例:
修改代码以使用 mse_loss
-
加载必要的库:
你需要一个工具来将标签转换为one-hot编码。这里我们使用torch.nn.functional.one_hot。 -
修改训练函数:
在训练函数中,将标签转换为one-hot编码,然后计算mse_loss。
核心测试代码讲解
out=model(data)模型输出形状为torch.Size([140, 7])
data.y中测试数据输出形状为torch.Size([140]),打印第一个数据为3,7个类别中的第4个类别
将3转化为7位置独热码计算MSE,对应train_labels_one_hot第一个数据[0., 0., 0., 1., 0., 0., 0.]为4
out形状为torch.Size([140, 7]),train_labels_one_hot的形状为[140, 7]
torch.Size([140, 7]) torch.Size([140])
tensor([-0.0166, 0.0191, -0.0036, -0.0053, -0.0160, 0.0071, -0.0042],device='cuda:0', grad_fn=<SelectBackward0>) tensor(3, device='cuda:0')
tensor([[0., 0., 0., 1., 0., 0., 0.],...[0., 1., 0., 0., 0., 0., 0.]], device='cuda:0')
train_labels_one_hot shape torch.Size([140, 7])
test out torch.Size([2708, 7])
train_labels_one_hot = F.one_hot(data.y[data.train_mask], num_classes=dataset.num_classes).float()
print(out[data.train_mask].shape, data.y[data.train_mask].shape)
print(out[data.train_mask][0], data.y[data.train_mask][0])
print(train_labels_one_hot)
print(f"train_labels_one_hot shape {train_labels_one_hot.shape}")
loss = F.mse_loss(out[data.train_mask], train_labels_one_hot)
解释
- 加载库:我们使用
torch.nn.functional.one_hot将标签转换为one-hot编码。 - 修改训练函数:
- 将标签
train_labels转换为one-hot编码,train_labels_one_hot = F.one_hot(train_labels, num_classes=dataset.num_classes).float()。 - 使用
mse_loss计算均方误差损失loss = F.mse_loss(train_out, train_labels_one_hot)。
- 将标签
- 保持评估函数不变:评估函数仍然使用
argmax提取预测类别,并计算准确性。
魔改完整代码
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures# 加载Cora数据集
dataset = Planetoid(root='/tmp/Cora', name='Cora', transform=NormalizeFeatures())
data = dataset[0]# 定义GCN模型
class GCN(torch.nn.Module):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = F.dropout(x, training=self.training)x = self.conv2(x, edge_index)return x# return F.log_softmax(x, dim=1)# 初始化模型和优化器
model = GCN()
print(model)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
data = data.to('cuda')
model = model.to('cuda')# 打印归一化后的特征
print(data.x[0])print(f"data.train_mask{data.train_mask}")# 训练模型
def train():model.train()optimizer.zero_grad()out = model(data)# print(f"out[data.train_mask] {data.train_mask.shape} {out[data.train_mask].shape} {out[data.train_mask]}")# loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])train_labels_one_hot = F.one_hot(data.y[data.train_mask], num_classes=dataset.num_classes).float()print(out[data.train_mask].shape, data.y[data.train_mask].shape)print(out[data.train_mask][0], data.y[data.train_mask][0])print(train_labels_one_hot)print(f"train_labels_one_hot shape {train_labels_one_hot.shape}")loss = F.mse_loss(out[data.train_mask], train_labels_one_hot)loss.backward()optimizer.step()return loss.item()# 评估模型
def test():model.eval()out = model(data)print(f"test out {out.shape}")print(f"test out[0] {out[0].shape} {out[0]}")print(f"test out[0:1,:] {out[0:1,:].shape} {out[0:1,:]}")print(f"test out[0:1,:].argmax(dim=1) {out[0:1,:].argmax(dim=1)}")pred = out.argmax(dim=1)print(f"test pred {pred[data.test_mask].shape} {pred[data.test_mask]}")print(f"data {data.y[data.test_mask].shape} {data.y[data.test_mask]}")correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()acc = int(correct) / int(data.test_mask.sum())return accfor epoch in range(1):loss = train()acc = test()print(f'Epoch {epoch+1}, Loss: {loss:.4f}, Accuracy: {acc:.4f}')
原始代码
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures# 加载Cora数据集,并应用NormalizeFeatures变换
dataset = Planetoid(root='/tmp/Cora', name='Cora', transform=NormalizeFeatures())
data = dataset[0]# 计算训练、验证和测试集的大小
num_train = data.train_mask.sum().item()
num_val = data.val_mask.sum().item()
num_test = data.test_mask.sum().item()print(f'Number of training nodes: {num_train}')
print(f'Number of validation nodes: {num_val}')
print(f'Number of test nodes: {num_test}')# 定义GCN模型
class GCN(torch.nn.Module):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = F.dropout(x, training=self.training)x = self.conv2(x, edge_index)return x # 返回未归一化的logits# 初始化模型和优化器
model = GCN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
data = data.to('cuda')
model = model.to('cuda')# 训练模型
def train():model.train()optimizer.zero_grad()out = model(data) # out 的形状是 [num_nodes, num_classes]train_out = out[data.train_mask] # 选择训练集节点的输出train_labels = data.y[data.train_mask] # 选择训练集节点的标签# 将标签转换为one-hot编码train_labels_one_hot = F.one_hot(train_labels, num_classes=dataset.num_classes).float()# 计算均方误差损失loss = F.mse_loss(train_out, train_labels_one_hot)loss.backward()optimizer.step()return loss.item()# 评估模型
def test():model.eval()out = model(data)pred = out.argmax(dim=1) # 提取预测类别correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()acc = int(correct) / int(data.test_mask.sum())return accfor epoch in range(200):loss = train()acc = test()print(f'Epoch {epoch+1}, Loss: {loss:.4f}, Accuracy: {acc:.4f}')
通过这些修改,你可以将交叉熵损失函数替换为均方误差损失函数,并确保输入和标签的形状匹配,从而避免报错。
- 简单版本的的答案
Cross Entropy vs. MSE Loss
-
Cross Entropy Loss:
- 输入:模型的logits,形状为 ([N, C]),其中 (N) 是批次大小,(C) 是类别数量。
- 目标:目标类别的索引,形状为 ([N])。
-
MSE Loss:
- 输入:模型的预测值,形状为 ([N, C])。
- 目标:实际值,形状为 ([N, C])(通常是 one-hot 编码)。
要将 cross_entropy 换成 mse_loss,需要确保输入和目标的形状匹配。具体来说,你需要将目标类别索引转换为 one-hot 编码。
示例代码
假设你有一个分类任务,其中模型输出的是 logits,目标是类别索引。我们将这个设置转换为使用 MSE Loss。
import torch
import torch.nn.functional as F# 假设有一个批次的模型输出和目标标签
logits = torch.tensor([[1.0, 2.0, 3.0], [1.0, 2.0, 3.0]], requires_grad=True) # 模型输出
target = torch.tensor([0, 2]) # 目标类别# 使用 cross_entropy
cross_entropy_loss = F.cross_entropy(logits, target)
print("Cross-Entropy Loss:")
print(cross_entropy_loss)# 转换目标类别为 one-hot 编码
target_one_hot = F.one_hot(target, num_classes=logits.size(1)).float()
print("One-Hot Encoded Targets:")
print(target_one_hot)# 计算 MSE Loss
mse_loss = F.mse_loss(F.softmax(logits, dim=1), target_one_hot)
print("MSE Loss:")
print(mse_loss)
输出
Cross-Entropy Loss:
tensor(1.4076, grad_fn=<NllLossBackward>)
One-Hot Encoded Targets:
tensor([[1., 0., 0.],[0., 0., 1.]])
MSE Loss:
tensor(0.2181, grad_fn=<MseLossBackward>)
解释
logits: 模型的原始输出,形状为 ([N, C])。target: 原始目标类别索引,形状为 ([N])。target_one_hot: 将目标类别索引转换为 one-hot 编码,形状为 ([N, C])。F.mse_loss: 使用F.softmax(logits, dim=1)计算模型的概率分布,然后与target_one_hot计算 MSE 损失。
通过将目标类别转换为 one-hot 编码并确保输入和目标的形状匹配,可以成功地将 cross_entropy 换成 mse_loss。
相关文章:
【PYG】Cora数据集分类任务计算损失,cross_entropy为什么不能直接替换成mse_loss
cross_entropy计算误差方式,输入向量z为[1,2,3],预测y为[1],选择数为2,计算出一大坨e的式子为3.405,再用-23.405计算得到1.405MSE计算误差方式,输入z为[1,2,3],预测向量应该是[1,0,0]࿰…...
MyBatis-plus这么好用,不允许还有人不会
你好呀,我是 javapub. 做 Java 的同学都会用到的三件套,Spring、SpringMV、MyBatis。但是由于使用起来配置较多,依赖冲突频发。所有,各路大佬又在这上边做了包装,像我们常用的 SpringBoot、MyBatisPlus。 基于当前要…...

Linux驱动开发实战宝典:设备模型、模块编程、I2C/SPI/USB外设精讲
摘要: 本文将带你走进 Linux 驱动开发的世界,从设备驱动模型、内核模块开发基础开始,逐步深入 I2C、SPI、USB 等常用外设的驱动编写,结合实际案例,助你掌握 Linux 驱动开发技能。 关键词: Linux 驱动,设备驱动模型,内核模块,I2C,SPI,USB 一、Linux 设备驱动模型 Li…...
安全技术和防火墙
1、安全技术 1.1入侵检测系统 特点是不阻断网络访问,主要提供报警和事后监督。不主动介入,默默的看着你(类似于监控) 1.2入侵防御系统 透明模式工作, 数据包,网络监控,服务攻击,…...
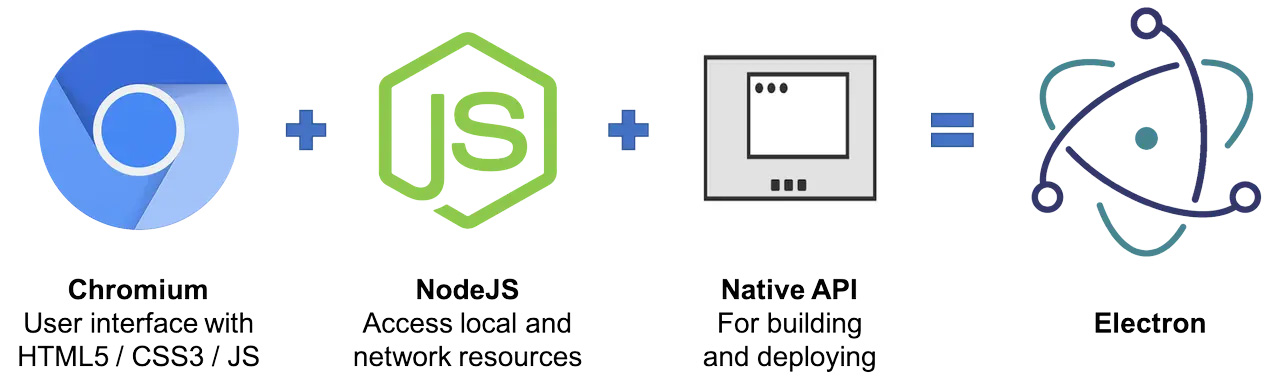
Webpack: 开发 PWA、Node、Electron 应用
概述 毋庸置疑,对前端开发者而言,当下正是一个日升月恒的美好时代!在久远的过去,Web 页面的开发技术链条非常原始而粗糙,那时候的 JavaScript 更多用来点缀 Web 页面交互而不是用来构建一个完整的应用。直到 2009年5月…...

python处理txt文件, 如果第一列和第二列的值在连续的行中重复,则只保留一行
处理txt文件, 如果第一列和第二列的值在连续的行中重复,则只保留一个实例,使用Python的内置函数来读取文件,并逐行检查和处理数据。 一个txt文件,里面的数据是893.554382324,-119.955825806,0.0299997832626,-0.133618548512,28.1155740884,112.876833236,46.7922,19.62582…...

C++17中引入了什么新的重要特性
C17是C标准的一个重要版本,它在语言核心和标准库中引入了许多新特性和改进,使得C编程更加现代化和高效。以下是C17中引入的一些重要新特性: 语言核心新特性 结构化绑定(Structured Bindings): 结构化绑定…...

Andrej Karpathy提出未来计算机2.0构想: 完全由神经网络驱动!网友炸锅了
昨天凌晨,知名人工智能专家、OpenAI的联合创始人Andrej Karpathy提出了一个革命性的未来计算机的构想:完全由神经网络驱动的计算机,不再依赖传统的软件代码。 嗯,这是什么意思?全部原生LLM硬件设备的意思吗?…...
)
用国内镜像安装docker 和 docker-compose (ubuntu)
替代方案,改用国内的镜像站(网易镜像) 1.清除旧版本(可选操作) for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do apt-get remove $pkg; done 2.安装docker apt-get update 首先安装依赖 apt-g…...
Linux多线程【线程互斥】
文章目录 Linux线程互斥进程线程间的互斥相关背景概念互斥量mutex模拟抢票代码 互斥量的接口初始化互斥量销毁互斥量互斥量加锁和解锁改进模拟抢票代码(加锁)小结对锁封装 lockGuard.hpp 互斥量实现原理探究可重入VS线程安全概念常见的线程不安全的情况常…...
os实训课程模拟考试(大题复习)
目录 一、Linux操作系统 (1)第1关:Linux初体验 (2)第2关:Linux常用命令 (3)第3关:Linux 查询命令帮助语句 二、Linux之进程管理—(重点) &…...
)
QT/QML国际化:中英文界面切换显示(cmake方式使用)
目录 前言 实现步骤 1. 准备翻译文件 2. 翻译字符串 3.设置应用程序语言 cmake 构建方式 示例代码 总结 1. 使用 file(GLOB ...) 2. 引入其他资源文件 再次生成翻译文件 5. 手动更新和生成.qm文件 其他资源 前言 在当今全球化的软件开发环境中,应用程…...

设计模式在Java项目中的实际应用
设计模式在Java项目中的实际应用 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 引言 设计模式是软件开发中重要的思想工具,它提供了解决特定问题…...

js制作随机四位数验证码图片
<div class"lable lable2"><div class"l"><span>*</span>验证码</div><div class"r"><input type"number" name"vercode" placeholder"请输入验证码"></div>&l…...
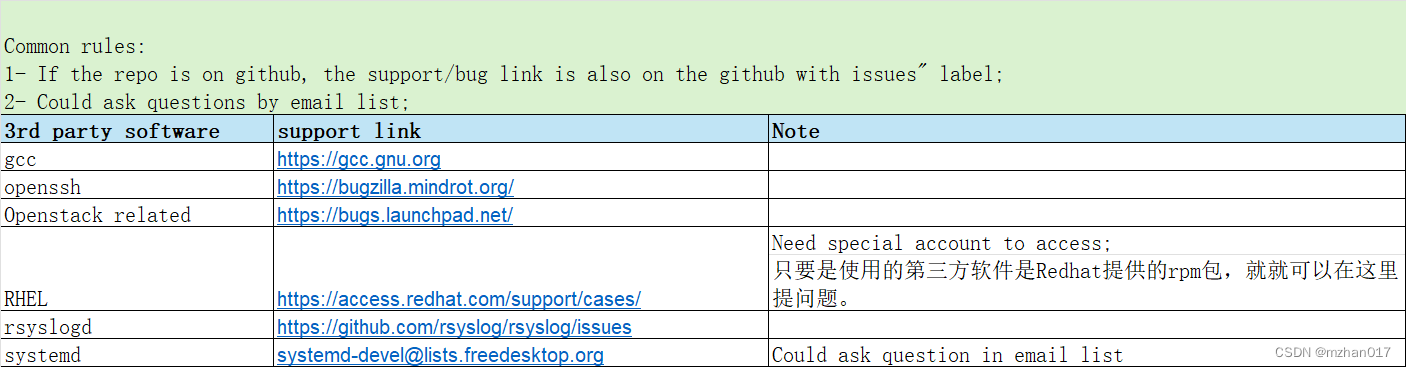
[开源软件] 支持链接汇总
“Common rules: 1- If the repo is on github, the support/bug link is also on the github with issues”" label; 2- Could ask questions by email list;" 3rd party software support link Note gcc https://gcc.gnu.org openssh https://bugzilla.mindrot.o…...
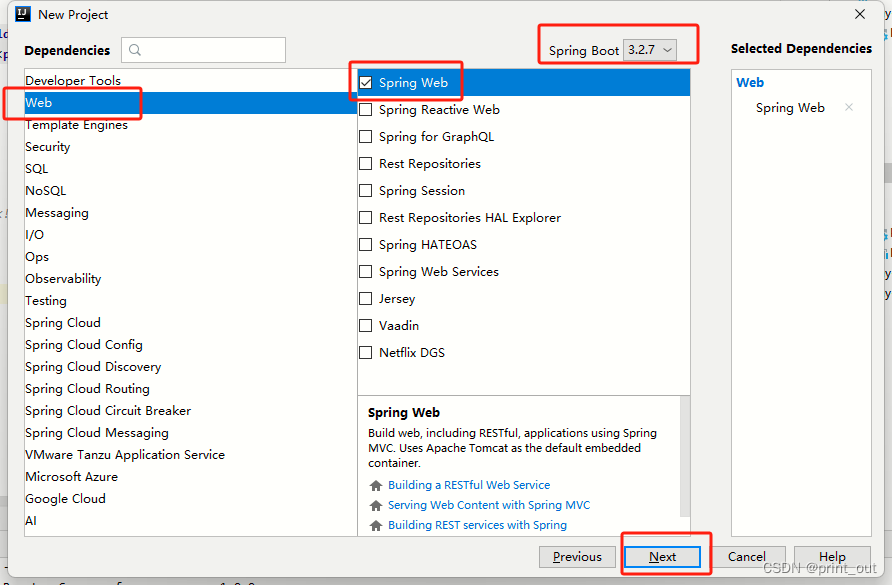
从零开始搭建spring boot多模块项目
一、搭建父级模块 1、打开idea,选择file–new–project 2、选择Spring Initializr,选择相关java版本,点击“Next” 3、填写父级模块信息 选择/填写group、artifact、type、language、packaging(后面需要修改)、java version(后面需要修改成和第2步中版本一致)。点击“…...

Iot解决方案开发的体系结构模式和技术
前言 Foreword 计算机技术起源于20世纪40年代,最初专注于数学问题的基本原理;到了60年代和70年代,它以符号系统为中心,该领域首先开始面临复杂性问题;到80年代,随着个人计算的兴起和人机交互的问题&#x…...
02.C1W1.Sentiment Analysis with Logistic Regression
目录 Supervised ML and Sentiment AnalysisSupervised ML (training)Sentiment analysis Vocabulary and Feature ExtractionVocabularyFeature extractionSparse representations and some of their issues Negative and Positive FrequenciesFeature extraction with freque…...

Stable Diffusion秋叶AnimateDiff与TemporalKit插件冲突解决
文章目录 Stable Diffusion秋叶AnimateDiff与TemporalKit插件冲突解决描述错误描述:找不到模块imageio.v3解决:参考地址 其他文章推荐:专栏 : 人工智能基础知识点专栏:大语言模型LLM Stable Diffusion秋叶AnimateDiff与…...

PCL 渐进形态过滤器实现地面分割
点云地面分割 一、代码实现二、结果示例🙋 概述 渐进形态过滤器:采用先腐蚀后膨胀的运算过程,可以有效滤除场景中的建筑物、植被、车辆、行人以及交通附属设施,保留道路路面及路缘石点云。 一、代码实现 #include <iostream> #include <pcl/io/pcd_io.h> #in…...

一篇搞懂计算机网络之IP协议
目录 一. IP地址结构 核心规则 例子拆解 IPV4 vs IPV6 二. 子网掩码 拆分规则 常见子网掩码 公网IP vs 私网IP 三. 特殊的IP地址 IP协议是计算机网络中网络层的主要协议,全名叫互联网协议地址。用于唯一标识互联网中的一个网络或一台主机。就类似于身份证&…...

kill-doc:打破文档平台壁垒,一键下载30+主流文库的终极解决方案
kill-doc:打破文档平台壁垒,一键下载30主流文库的终极解决方案 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档…...

【目标检测系统】基于YOLOv8的DOTA遥感小目标检测系统
一、系统介绍本系统是一套基于深度学习的DOTA遥感目标检测系统,采用 Ultralytics YOLOv8 作为核心检测引擎,PySide6 构建图形用户界面,专门用于遥感解译、地理空间分析、军事侦察、城市规划等场景。用户只需加载预训练模型并选择图片、视频或…...

Windows APK安装器:告别模拟器,直接在Windows上安装安卓应用
Windows APK安装器:告别模拟器,直接在Windows上安装安卓应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上运行安…...

别再瞎勾选了!SuperMap iDesktop切MVT矢量瓦片时,‘分离数据与风格’到底怎么选?
MVT矢量瓦片生产中的关键决策:数据与风格分离的深度解析 当你在SuperMap iDesktop中准备生成MVT矢量瓦片时,那个看似简单的"分离数据与风格"复选框背后,隐藏着一系列影响深远的架构决策。这个选择不仅关系到瓦片文件的结构…...

ARM64虚拟化实战:Proxmox VE在ARM平台上的完整部署指南
ARM64虚拟化实战:Proxmox VE在ARM平台上的完整部署指南 【免费下载链接】Proxmox-Arm64 Proxmox VE & PBS unofficial arm64 version 项目地址: https://gitcode.com/gh_mirrors/pr/Proxmox-Arm64 随着ARM64架构在树莓派、Rockpi等开发板以及服务器领域的…...

Xenos DLL注入器:Windows动态加载5个核心技巧完整指南
Xenos DLL注入器:Windows动态加载5个核心技巧完整指南 【免费下载链接】Xenos Windows dll injector 项目地址: https://gitcode.com/gh_mirrors/xe/Xenos Xenos是一款基于Blackbone库开发的强大Windows DLL注入工具,专为软件开发者和系统管理员设…...

如何高效解锁艾尔登法环帧率限制:专业玩家的完整配置指南
如何高效解锁艾尔登法环帧率限制:专业玩家的完整配置指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/…...

11个系统、8000张表,这家环保集团如何让沉睡的数据真正“用起来”
很多大型集团企业都有过这样一段经历:信息化建设做了好几轮,ERP上线了,OA部署了,生产监控系统也跑起来了,业务数据越积越厚——看起来数字化建设卓有成效。但真到需要数据的时候,才发现麻烦来了。财务要汇报…...

终极窗口尺寸调整工具:WindowResizer完整使用指南
终极窗口尺寸调整工具:WindowResizer完整使用指南 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些无法拖拽大小的顽固应用程序窗口而烦恼吗?Wind…...