02.C1W1.Sentiment Analysis with Logistic Regression
目录
- Supervised ML and Sentiment Analysis
- Supervised ML (training)
- Sentiment analysis
- Vocabulary and Feature Extraction
- Vocabulary
- Feature extraction
- Sparse representations and some of their issues
- Negative and Positive Frequencies
- Feature extraction with frequencies
- Preprocessing
- Preprocessing: stop words and punctuation
- Preprocessing: Handles and URLs
- Preprocessing: Stemming and lowercasing
- Putting it all together
- General overview
- General Implementation
- Logistic Regression Overview
- Logistic Regression: Training
- 图形化
- 数学化
- Logistic Regression: Testing
- opt. Logistic Regression:Cost Function
- 作业注意事项
Supervised ML and Sentiment Analysis
Supervised ML (training)
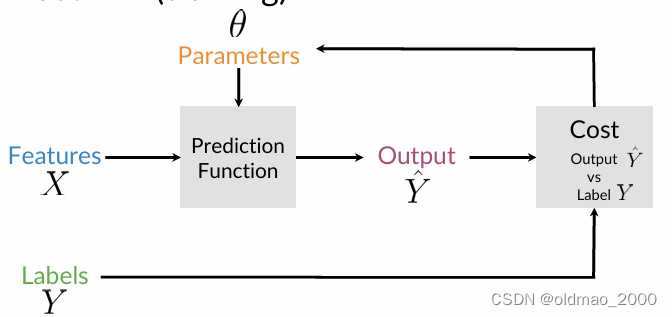
模型吃参数 θ θ θ来映射特征 X X X以输出标签 Y ^ \hat Y Y^,之前讲过太多,不重复了
Sentiment analysis
SA任务的目标是用逻辑回归分类器,预测一条推文的情绪是积极的还是消极的,如下图所示,积极情绪的推文都有一个标签:1,负面情绪的推文标签为0
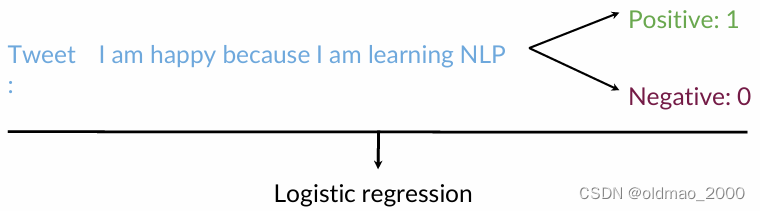
大概步骤如上图:
- 处理训练集中的原始tweets并提取有用的特征 X X X
- 训练Logistic回归分类器,同时最小化成本函数
- 使用训练好的分类器对指定推文进行情感分析预测
Vocabulary and Feature Extraction
Vocabulary
假设有训练集中有m条推文:
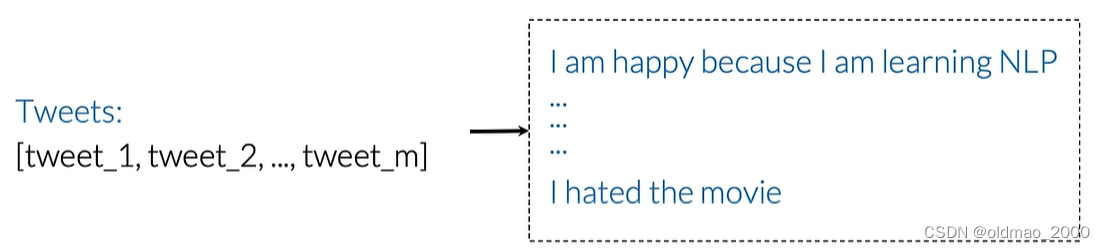
则词表(库)可表示为所有不重复出现的所有单词列表,例如上面的I出现两次,只会记录一次:

Feature extraction
这里直接简单使用单词是否出现来对某个句子进行特征提取:

如果词表大小为10W,则该句子的特征向量大小为1×10W的,单词出现在句子中,则该词的位置为1,否则为0,可以看到,句子的特征向量非常稀疏(称为稀疏表示Sparse representation)。
Sparse representations and some of their issues
稀疏表示使得参数量大,对于逻辑回归模型,需要学习的参数量为n+1,n为词表大小,进而导致以下两个问题:

Negative and Positive Frequencies
将推文语料库分为两类:正面和负面 ;
计算每个词在两个类别中出现的次数。
假设语料如下(四个句子):
| Corpus |
|---|
| I am happy because I am learning NLP |
| I am happy |
| I am sad, I am not learning NLP |
| I am sad |
对应的词表如下(八个词):
| Vocabulary |
|---|
| I |
| am |
| happy |
| because |
| learning |
| NLP |
| sad |
| not |
对语料进行分类:
| Positive tweets | Negative tweets |
|---|---|
| I am happy because I am learning NLP | I am sad, I am not learning NLP |
| I am happy | I am sad |
按类型构造词频表(小伙伴们可以自行写上对应的数字,例如:happy数字为2)


总表如下:
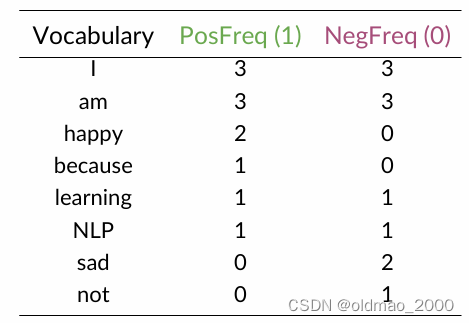
接下来就是要利用以上信息来进行特征提取。
Feature extraction with frequencies
推文的特征可由以下公式表示:
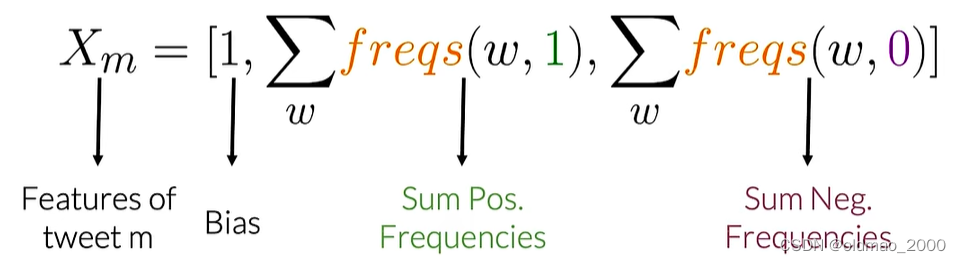
其中freqs函数就是上节表中单词与情感分类对应的频率。
例子:
I am sad, I am not learning NLP
对应正例词频表(图中应该是下划线):

可以算出正例词频总和为:3+3+1+1=8
对应负例词频表:

可以算出负例词频总和为:3+3+1+1+2+1=11
则该推文的特征可以表示为三维向量:
X m = [ 1 , 8 , 11 ] X_m=[1,8,11] Xm=[1,8,11]
这样的表示去掉了推文稀疏表示中不重要的信息。
Preprocessing
数据预处理包括:
Removing stopwords, punctuation, handles and URLs;
Stemming;
Lowercasing.
中心思想:去掉不重要和非必要信息,提高运行效率
Preprocessing: stop words and punctuation
推文实例(广告植入警告):
@YMourri and @AndrewYNg are tuning a GREAT AI model at https://deeplearning.ai!!!
假设停用词表如下(词表通常包含的停用词比实际语料中的停用词要多):
| Stop words |
|---|
| and |
| is |
| are |
| at |
| has |
| for |
| a |
交叉比较去掉停用词中的内容后:
@YMourri @AndrewYNg tuning GREAT AI model https://deeplearning.ai!!!
假设标点表如下:
| Punctuation |
|---|
| , |
| . |
| : |
| ! |
| “ |
| ‘ |
去掉标点后结果如下:
@YMourri @AndrewYNg tuning GREAT AI model https://deeplearning.ai
际这两个表可以合并在一块,当然有些任务标点符号也包含重要信息,因此是否去掉标点要根据实际需要来做。
Preprocessing: Handles and URLs
这里继续对标识符和网址进行处理,通常这些内容对于SA任务而言,并不能提供任何情绪价值。
上面的推文处理后结果如下:
tuning GREAT AI model
可以看到,去掉非必要信息后,得到结果是一条正面的推文。
Preprocessing: Stemming and lowercasing
Stemming 是一种文本处理技术,目的是将词汇还原到其基本形式,即词干。例如,将 “running” 还原为 “run”。
Lowercasing 是将所有文本转换为小写,以消除大小写带来的差异,便于统一处理。
例如第一个单词词干为tun:
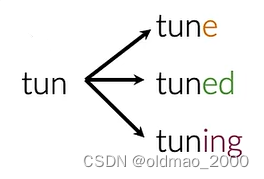
第二个单词:
这样处理能减少词库中单词数量。最后推文处理后结果为:
[tun, great, ai, model]
Putting it all together
General overview
本节将对整组推文执行特征提取算法(Generalize the process)
根据之前的内容:数据预处理,特征提取,我们可以将下面推文进行处理:
| I am Happy Because i am learning NLP @deeplearning |
|---|
| ↓ Preprocessing后 |
| [happy, learn, nlp] |
| ↓ Feature Extraction后 |
| [1,4 ,2] |
其中,1 是Bias,4是Sum positive frequencies,2是Sum negative frequencies
对于多条推文则有:

最后的多个特征向量就可以组合成一个矩阵,大小为m×3,矩阵每一行都对应一个推文的特征向量
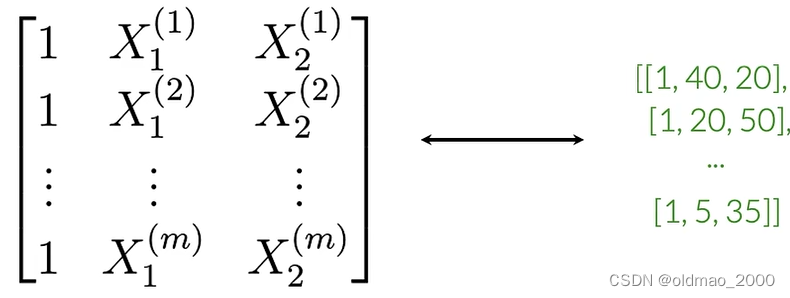
General Implementation
freqs =build_freqs(tweets,labels) #Build frequencies dictionary,已提供
X = np.zeros((m, 3 )) #Initialize matrix X
for i in range (m): #For every tweetp_tweet = process_tweet(tweets[i]) #Process tweet,已提供X[i, :]= extract_features(train_x[i], freqs)#需要在作业中自己实现
Logistic Regression Overview
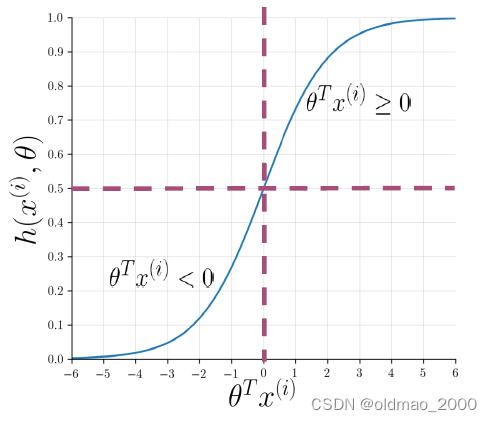
最开始的有监督的机器学习中,回顾了主要步骤,这里我们只需要将中间的预测函数替换为逻辑回归函数Sigmoid即可。
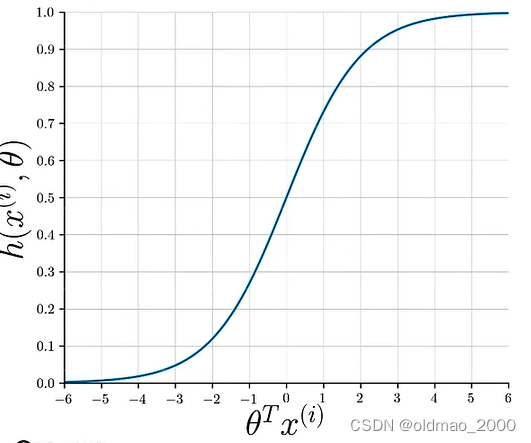
Sigmoid函数形式为:
h ( x ( i ) , θ ) = 1 1 + e − θ T x ( i ) h(x^{(i)},\theta)=\cfrac{1}{1+e^{-\theta^Tx^{(i)}}} h(x(i),θ)=1+e−θTx(i)1
i为第i条数据
θ是参数
x是数据对应的特征向量
图像形式为:
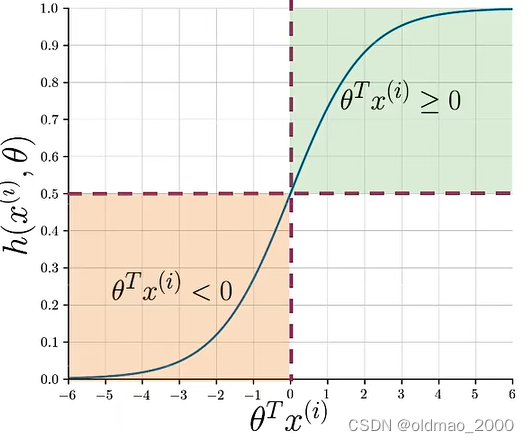
其函数值取决于 θ T x ( i ) \theta^Tx^{(i)} θTx(i):
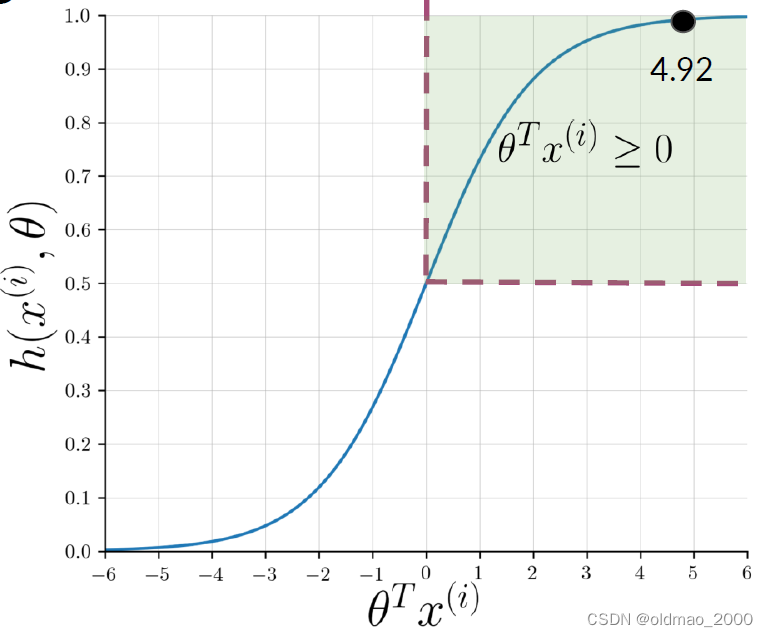
例如:
@YMourri and @AndrewYNg are tuning a GREAT AI model
预处理后结果为:
[tun, ai, great, model]
根据词库进行特征提取后可能得到以下结果:
x ( i ) = [ 1 3476 245 ] and θ = [ 0.00003 0.00150 − 0.00120 ] \begin{equation*} x^{(i)} = \begin{bmatrix} 1 \\ 3476 \\ 245 \end{bmatrix} \quad \text{and} \quad \theta = \begin{bmatrix} 0.00003 \\ 0.00150 \\ -0.00120 \end{bmatrix} \end{equation*} x(i)= 13476245 andθ= 0.000030.00150−0.00120
带入sigmoid函数后得到:
Logistic Regression: Training
上一节内容中,我们使用了给定的参数 θ \theta θ来计算推文的结果,这一节我们将学会如何通过训练逻辑回归模型来找到最佳的参数 θ \theta θ(梯度下降)。
图形化
先将问题简化,假设LR模型中只有两个参数 θ 1 \theta_1 θ1和 θ 2 \theta_2 θ2则函数的参数图像为下左,下右为Cost函数的迭代过程:
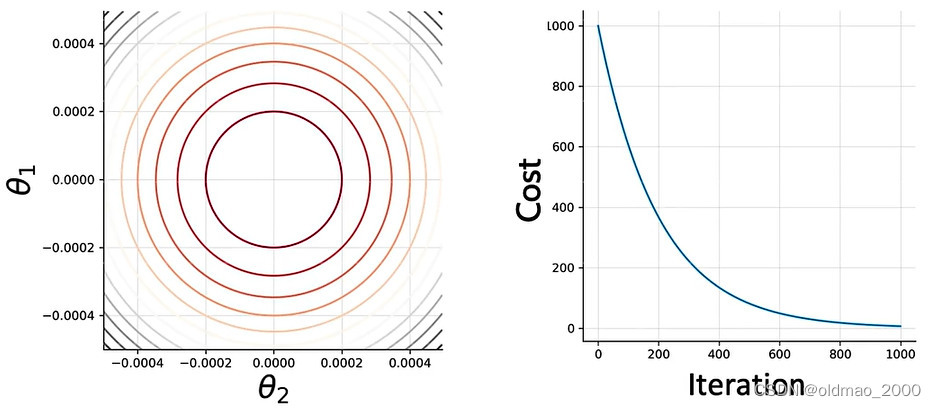
刚开始,我们初始化两个参数 θ 1 \theta_1 θ1和 θ 2 \theta_2 θ2,对应的Cost值为:
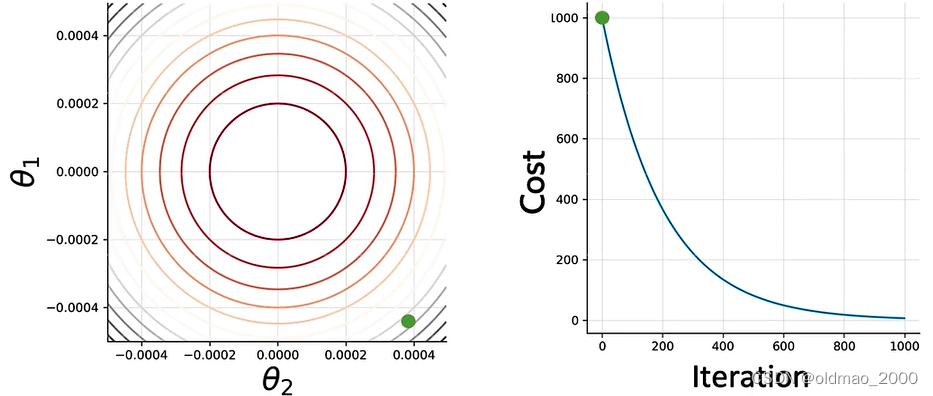
根据GD方向进行参数更新,100次后:
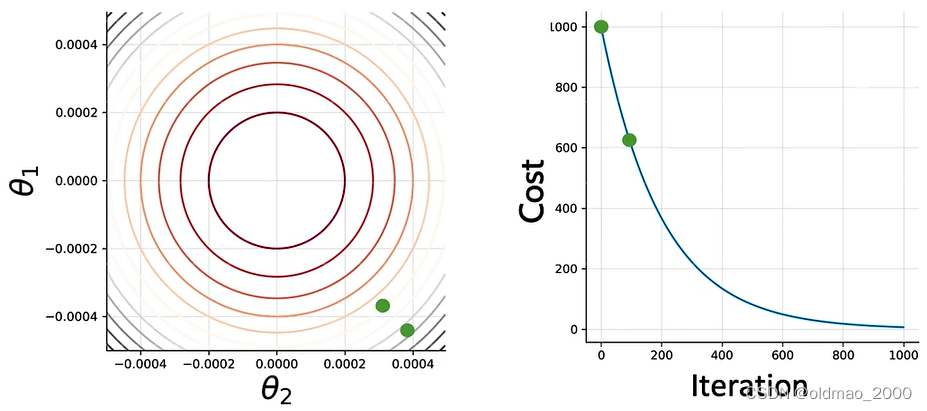
200次后:
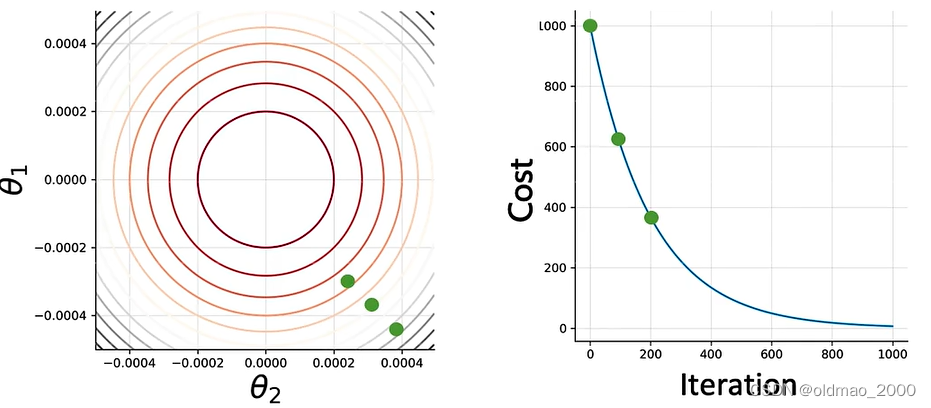
若干次后:
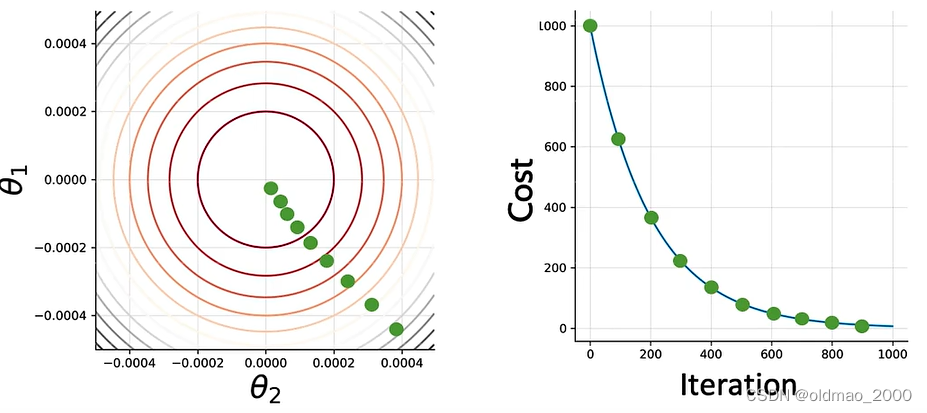
直到最佳cost附近:
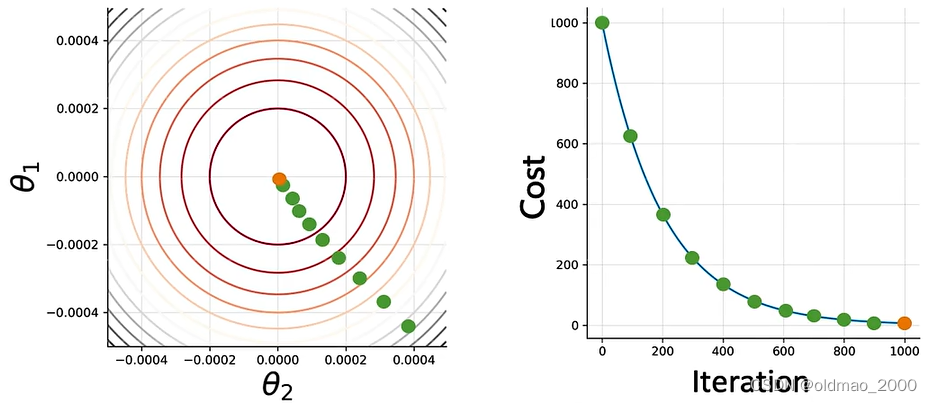
数学化
整个梯度下降过程可以表示为下图,注意左右是一一对应关系,结合起来看:
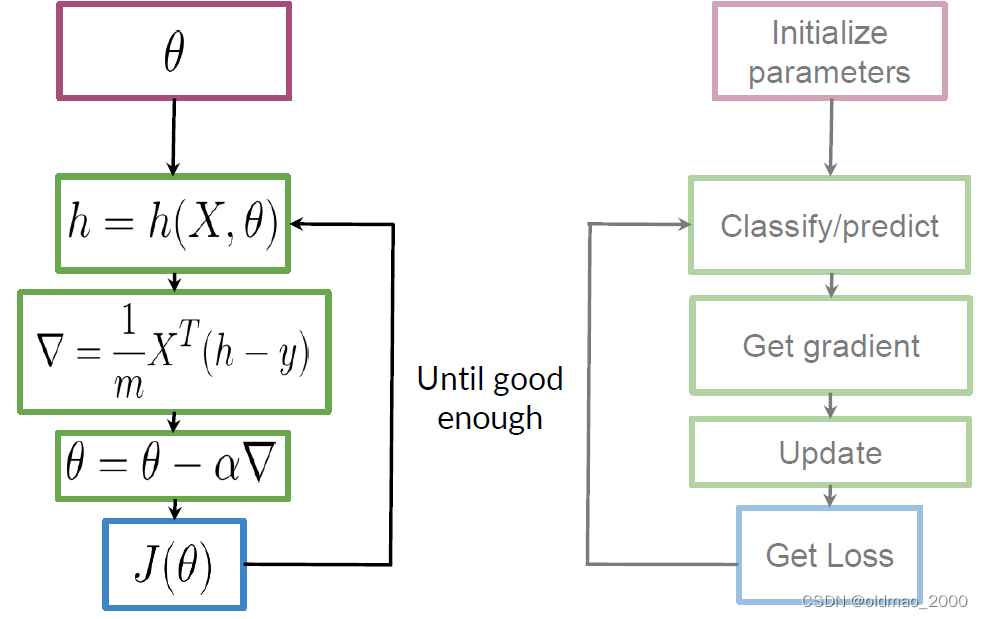
Logistic Regression: Testing
使用验证集计算模型精度,并了解准确度指标的含义。
现在我们手上有验证集: X v a l , Y v a l X_{val},Y_{val} Xval,Yval,以及训练好的参数 θ \theta θ
先计算sigmoid函数值(预测值): h ( X v a l , θ ) h(X_{val},\theta) h(Xval,θ)
然后判断验证集中每一个数据的预测值是否大于阈值(通常为0.5):
p r e d = h ( X v a l , θ ) ≥ 0.5 pred=h(X_{val},\theta)\ge 0.5 pred=h(Xval,θ)≥0.5
最后的预测结果是一组矩阵:
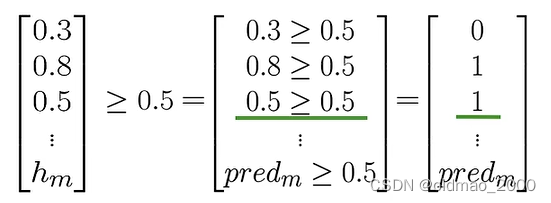
有了预测结果,就可以将其与标签 Y v a l Y_{val} Yval比较,计算准确率:
∑ i = 1 m ( p r e d i = = y v a l ( i ) ) m \sum_{i=1}^m\cfrac{(pred^{i}==y^{(i)}_{val})}{m} i=1∑mm(predi==yval(i))
m是验证集中数据个数
分子如下图所示,绿色是预测正确,黄色是预测不正确的:
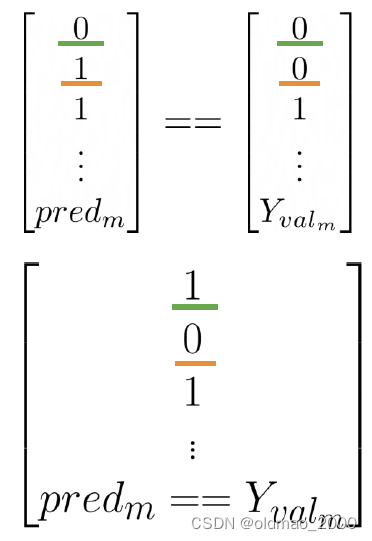
正确率计算实例:
假设计算的预测值与标签如下:
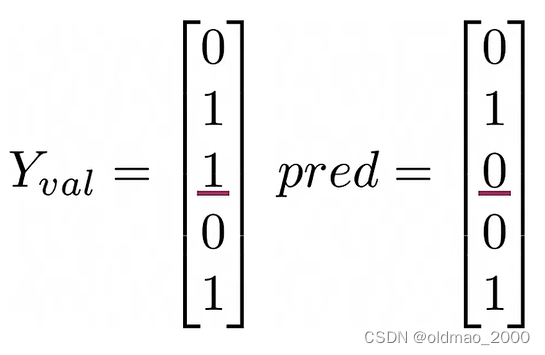
分子则为:
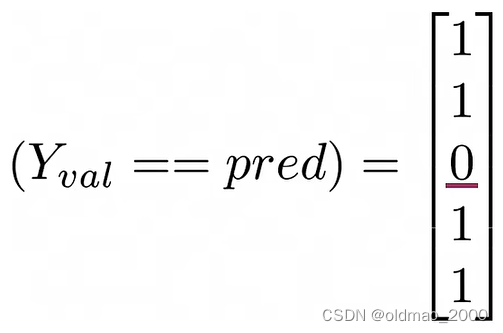
正确率: a c c u r a c y = 4 5 accuracy=\cfrac{4}{5} accuracy=54
opt. Logistic Regression:Cost Function
可选看内容:逻辑成本函数(又称二元交叉熵函数),公式为:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) log h ( x ( i ) , θ ) + ( 1 − y ( i ) ) log ( 1 − h ( x ( i ) , θ ) ] J(\theta)=-\cfrac{1}{m}\sum_{i=1}^m\left[y^{(i)}\log h(x^{(i)},\theta)+(1-y^{(i)})\log (1-h(x^{(i)},\theta)\right] J(θ)=−m1i=1∑m[y(i)logh(x(i),θ)+(1−y(i))log(1−h(x(i),θ)]
1 m ∑ i = 1 m \cfrac{1}{m}\sum_{i=1}^m m1∑i=1m中,m是样本数量,这里是将所有训练样本的cost进行累加,然后求平均。
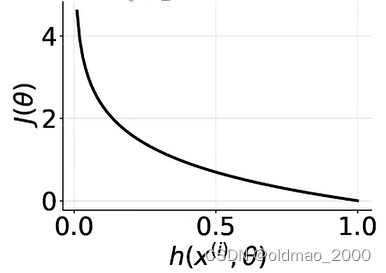
对于中括号的第一项 y ( i ) log h ( x ( i ) , θ ) y^{(i)}\log h(x^{(i)},\theta) y(i)logh(x(i),θ),不同取值有不同结果,总体而言,负例样本 y ( i ) = 0 y^{(i)}=0 y(i)=0,无论预测值 h ( x ( i ) , θ ) h(x^{(i)},\theta) h(x(i),θ)是什么这项为0,而预测值与标签值相差越大,Cost越大:
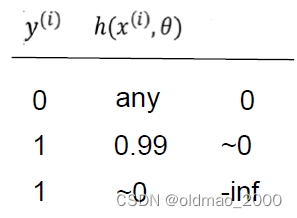
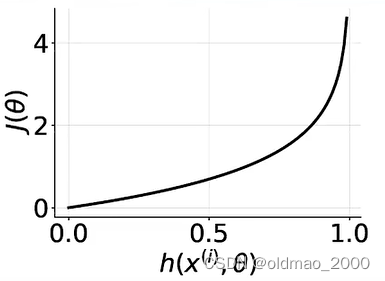
对于中括号的第二项 ( 1 − y ( i ) ) log ( 1 − h ( x ( i ) , θ ) (1-y^{(i)})\log (1-h(x^{(i)},\theta) (1−y(i))log(1−h(x(i),θ),正例样本 y ( i ) = 1 y^{(i)}=1 y(i)=1,无论预测值 h ( x ( i ) , θ ) h(x^{(i)},\theta) h(x(i),θ)是什么这项为0,同样预测值与标签值相差越大,Cost越大:
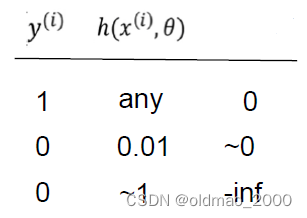
由于中括号里面的log是针对0-1之间的值,所以得到的结果是负数,为保证Cost函数是正值(这样才能求最小),在最前面加上了负号。
作业注意事项
nltk.download(‘twitter_samples’)失败可以到:
https://www.nltk.org/nltk_data/
手工下载twitter_samples.zip后放corpora目录,不用解压
utils.py文件可以在Assignment中找到
相关文章:
02.C1W1.Sentiment Analysis with Logistic Regression
目录 Supervised ML and Sentiment AnalysisSupervised ML (training)Sentiment analysis Vocabulary and Feature ExtractionVocabularyFeature extractionSparse representations and some of their issues Negative and Positive FrequenciesFeature extraction with freque…...

Stable Diffusion秋叶AnimateDiff与TemporalKit插件冲突解决
文章目录 Stable Diffusion秋叶AnimateDiff与TemporalKit插件冲突解决描述错误描述:找不到模块imageio.v3解决:参考地址 其他文章推荐:专栏 : 人工智能基础知识点专栏:大语言模型LLM Stable Diffusion秋叶AnimateDiff与…...

PCL 渐进形态过滤器实现地面分割
点云地面分割 一、代码实现二、结果示例🙋 概述 渐进形态过滤器:采用先腐蚀后膨胀的运算过程,可以有效滤除场景中的建筑物、植被、车辆、行人以及交通附属设施,保留道路路面及路缘石点云。 一、代码实现 #include <iostream> #include <pcl/io/pcd_io.h> #in…...
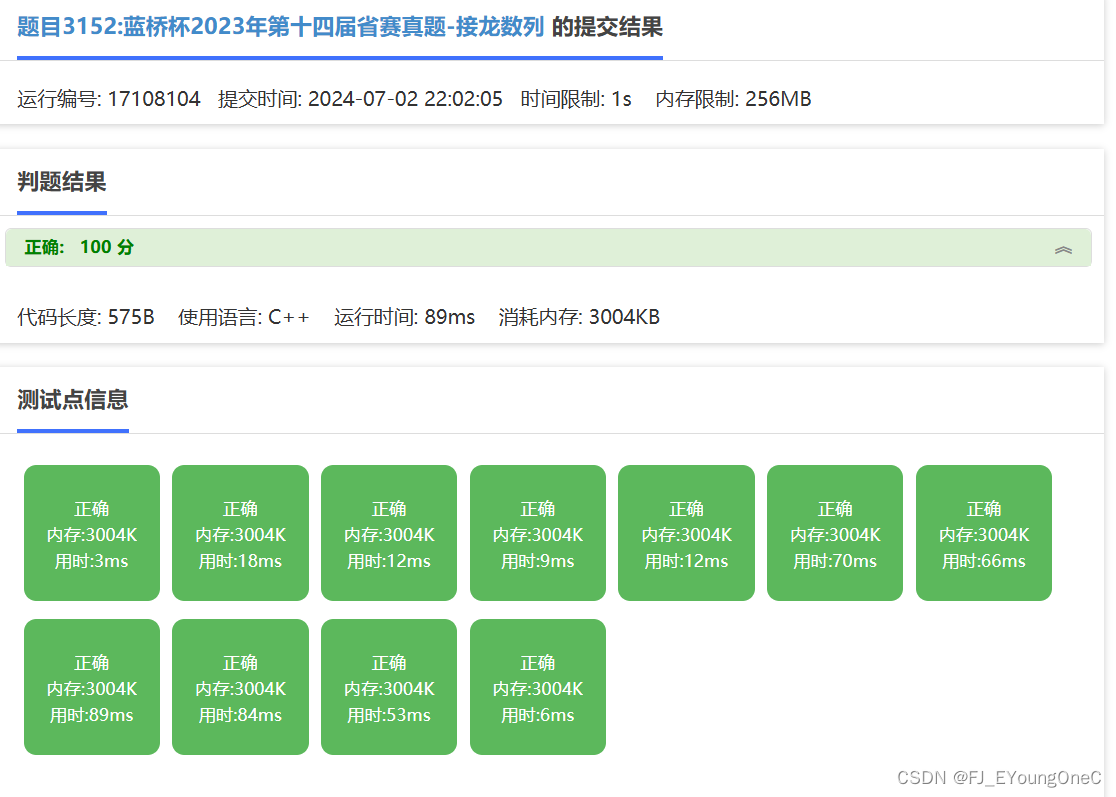
第十四届蓝桥杯省赛C++B组E题【接龙数列】题解(AC)
需求分析 题目要求最少删掉多少个数后,使得数列变为接龙数列。 相当于题目要求求出数组中的最长接龙子序列。 题目分析 对于一个数能不能放到接龙数列中,只关系到这个数的第一位和最后一位,所以我们可以先对数组进行预处理,将…...

Ubuntu 20.04.4 LTS 离线安装docker 与docker-compose
Ubuntu 20.04.4 LTS 离线安装docker 与docker-compose 要在Ubuntu 20.04.4 LTS上离线安装Docker和Docker Compose,你需要首先从有网络的环境下载Docker和Docker Compose的安装包,然后将它们传输到离线的服务器上进行安装。 在有网络的环境中:…...

vue3+ts 写echarts 中国地图
需要引入二次封装的echarts和在ts文件写的option <template><div class"contentPage"><myEcharts :options"chartOptions" class"myEcharts" id"myEchartsMapId" ref"mapEcharts" /></di…...
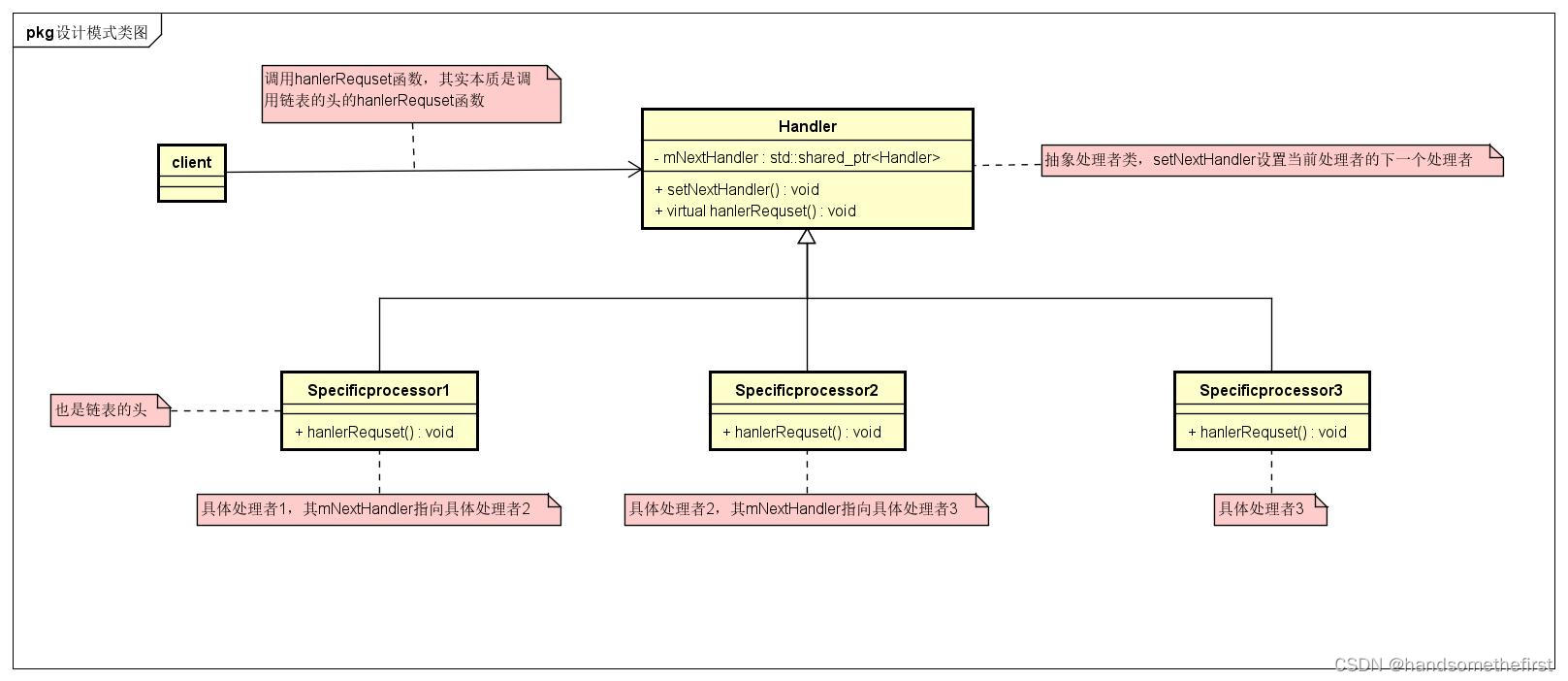
【设计模式】【行为型模式】【责任链模式】
系列文章目录 可跳转到下面链接查看下表所有内容https://blog.csdn.net/handsomethefirst/article/details/138226266?spm1001.2014.3001.5501文章浏览阅读2次。系列文章大全https://blog.csdn.net/handsomethefirst/article/details/138226266?spm1001.2014.3001.5501 目录…...
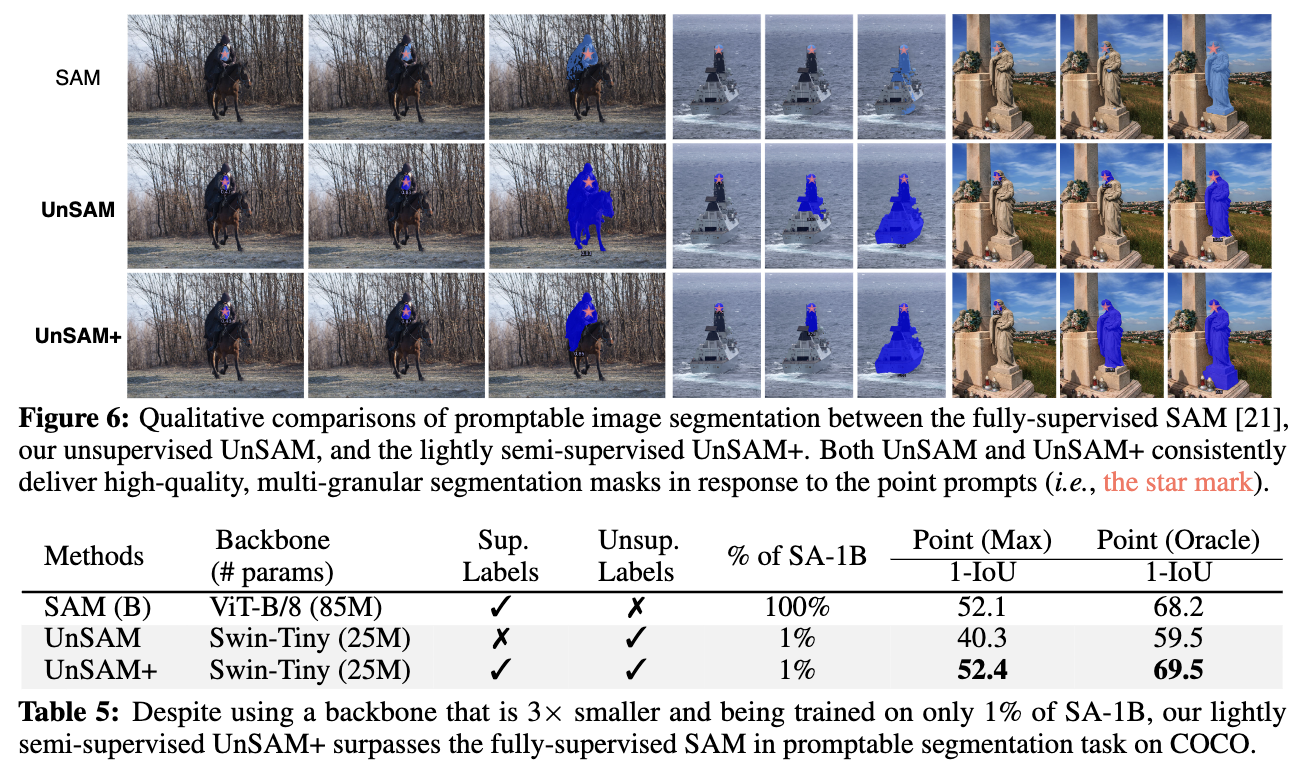
超越所有SOTA达11%!媲美全监督方法 | UC伯克利开源UnSAM
文章链接:https://arxiv.org/pdf/2406.20081 github链接:https://github.com/frank-xwang/UnSAM SAM 代表了计算机视觉领域,特别是图像分割领域的重大进步。对于需要详细分析和理解复杂视觉场景(如自动驾驶、医学成像和环境监控)的应用特别有…...
)
享元模式(设计模式)
享元模式(Flyweight Pattern)是一种结构型设计模式,它通过共享细粒度对象来减少内存使用,从而提高性能。在享元模式中,多个对象可以共享相同的状态以减少内存消耗,特别适合用于大量相似对象的场景。 享元模…...
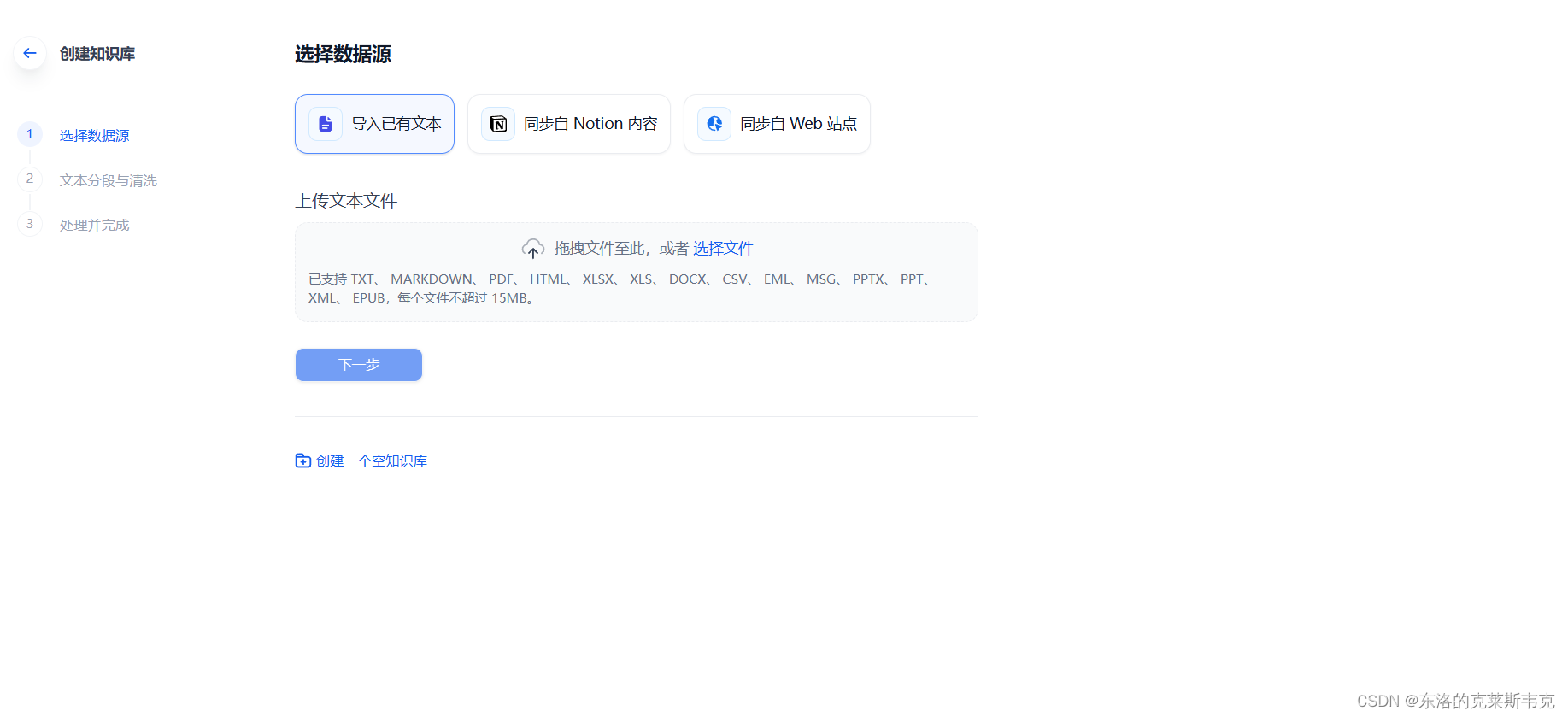
【机器学习】大模型训练的深入探讨——Fine-tuning技术阐述与Dify平台介绍
目录 引言 Fine-tuning技术的原理阐 预训练模型 迁移学习 模型初始化 模型微调 超参数调整 任务设计 数学模型公式 Dify平台介绍 Dify部署 创建AI 接入大模型api 选择知识库 个人主页链接:东洛的克莱斯韦克-CSDN博客 引言 Fine-tuning技术允许用户根…...
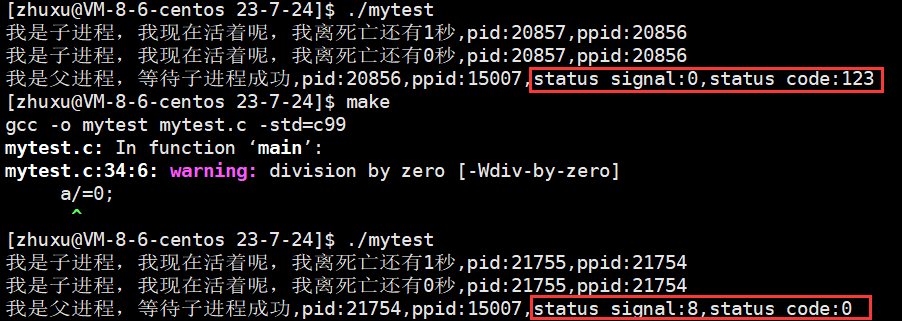
【Linux从入门到放弃】探究进程如何退出以进程等待的前因后果
🧑💻作者: 情话0.0 📝专栏:《Linux从入门到放弃》 👦个人简介:一名双非编程菜鸟,在这里分享自己的编程学习笔记,欢迎大家的指正与点赞,谢谢! 进…...

QT5 static_cast实现显示类型转换
QT5 static_cast实现显示类型转换,解决信号重载情况...
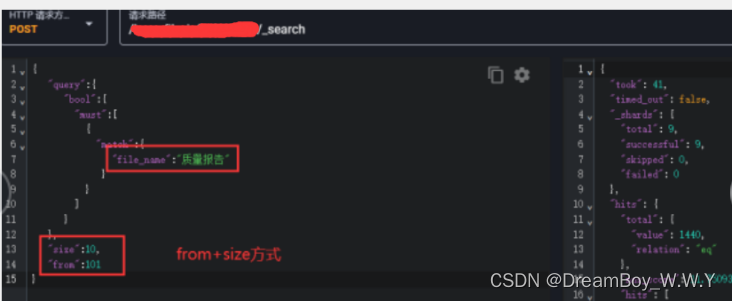
【ES】--Elasticsearch的翻页详解
目录 一、前言二、from+size浅分页1、from+size导致深度分页问题三、scroll深分页1、scroll原理2、scroll可以返回总计数量四、search_after深分页1、search_after避免深度分页问题一、前言 ES的分页常见的主要有三种方式:from+size浅分页、scroll深分页、search_after分页。…...

3.js - 纹理的重复、偏移、修改中心点、旋转
你瞅啥 上字母 // ts-nocheck // 引入three.js import * as THREE from three // 导入轨道控制器 import { OrbitControls } from three/examples/jsm/controls/OrbitControls // 导入lil.gui import { GUI } from three/examples/jsm/libs/lil-gui.module.min.js // 导入twee…...

RS232隔离器的使用
RS232隔离器在通信系统中扮演着至关重要的角色,其主要作用可以归纳如下: 一、保护通信设备 电气隔离:RS232隔离器通过光电隔离技术,将RS-232接口两端的设备电气完全隔离,从而避免了地线回路电压、浪涌、感应雷击、静电…...

一切为了安全丨2024中国应急(消防)品牌巡展武汉站成功召开!
消防品牌巡展武汉站 6月28日,由中国安全产业协会指导,中国安全产业协会应急创新分会、应急救援产业网联合主办,湖北消防协会协办的“一切为了安全”2024年中国应急(消防)品牌巡展-武汉站成功举办。该巡展旨在展示中国应急(消防&am…...

【面试系列】PHP 高频面试题
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、…...
JAVA极简图书管理系统,初识springboot后端项目
前提条件: 具备基础的springboot 知识 Java基础 废话不多说! 创建项目 配置所需环境 将application.properties>application.yml 配置以下环境 数据库连接MySQL 自己创建的数据库名称为book_test server:port: 8080 spring:datasource:url:…...

MySQL 重新初始化实例
1、关闭mysql服务 service mysqld stop 2、清理datadir(本例中指定的是/var/lib/mysql)指定的目录下的文件,将该目录下的所有文件删除或移动至其他位置 cd /var/lib/mysql mv * /opt/mysql_back/ 3、初始化实例 /usr/local/mysql/bin/mysqld --initialize --u…...
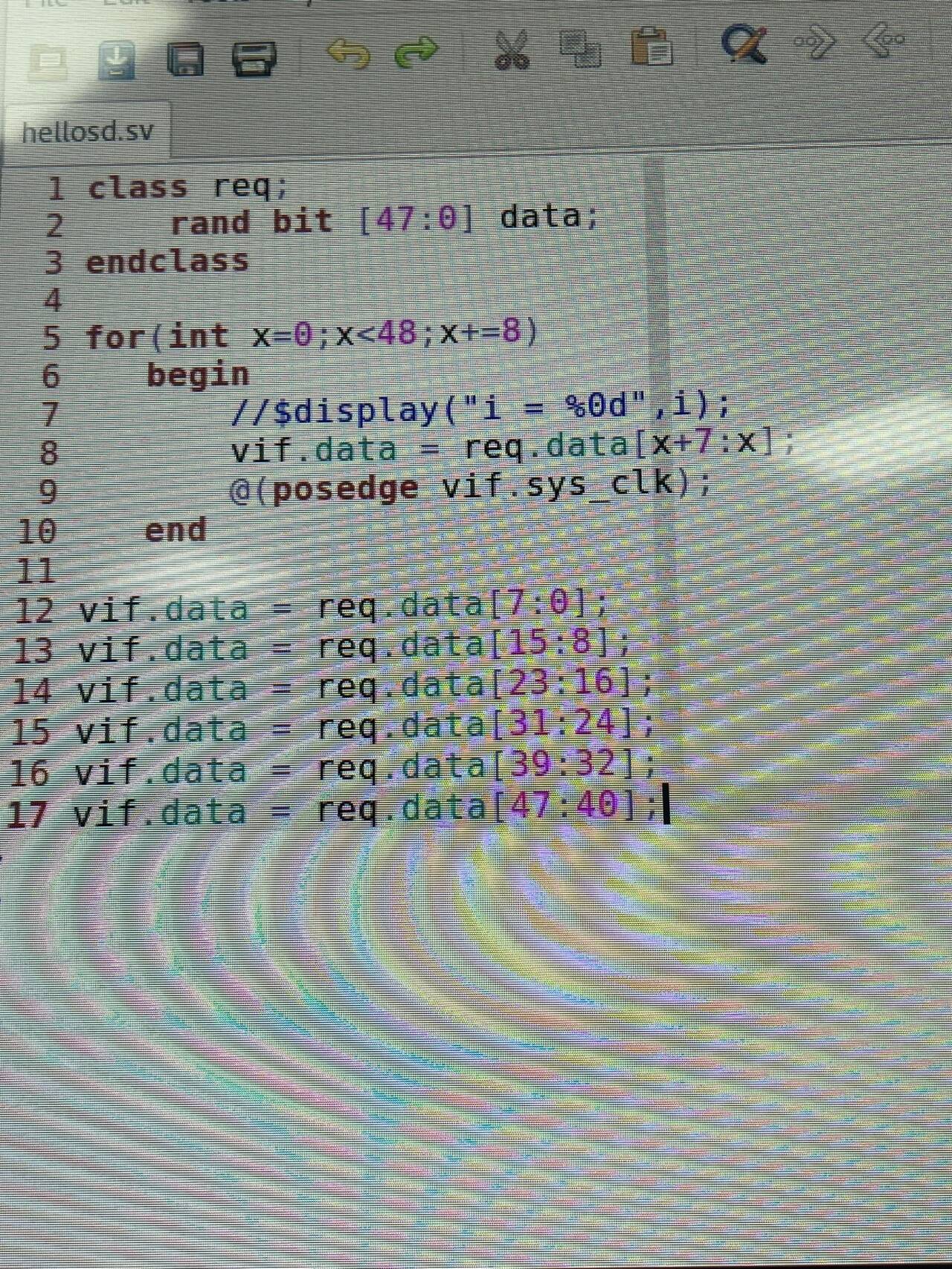
VCS编译bug汇总
‘typedef’ is not expected to be used in this contex 注册前少了分号。 Scope resolution error resolution : 声明指针时 不能与类名同名,即 不能声明为adapter. cannot find member "type_id" 忘记注册了 拼接运算符使用 关键要加上1b࿰…...

开源协作团队实践:从零构建高效技术团队的“团队即代码”方法论
1. 项目概述:一个开源协作团队的诞生与运作最近在GitHub上看到一个挺有意思的项目,叫jefferyjob/openclaw-it-team。光看这个名字,可能有点摸不着头脑,它不像一个具体的软件工具或框架,更像是一个团队或组织的代号。没…...

SolidityPy全课程:从零到一的区块链智能合约开发终极指南
SolidityPy全课程:从零到一的区块链智能合约开发终极指南 【免费下载链接】full-blockchain-solidity-course-py Ultimate Solidity, Blockchain, and Smart Contract - Beginner to Expert Full Course | Python Edition 项目地址: https://gitcode.com/gh_mirro…...

ARM调试接口技术:SWD与JTAG协议切换机制详解
1. ARM调试接口技术深度解析 在嵌入式系统开发领域,调试接口如同工程师的"听诊器",是连接开发环境与目标芯片的重要通道。作为行业标准,ARM架构提供了两种主流的调试协议:串行线调试(SWD)和JTAG。这两种协议各有特点&am…...

科技史上的今天:5月14日-百年技术沉淀,引领时代变革
2015年:HTTP/2 正式发布2015年5月14日,HTTP/2 标准正式发布,作为HTTP/1.1的重大升级,采用二进制分帧、多路复用等技术,解决串行阻塞痛点,显著提升网页加载速度与传输效率,为现代Web及物联网通信…...

运行软件时提示找不到VCRUNTIME140_1.dll
运行软件时提示找不到VCRUNTIME140_1.dll前言解决办法说明参考前言 我们将cpp程序打包之后,放到别的电脑上,新电脑可能会提示: 运行软件时提示找不到VCRUNTIME140_1.dll 解决办法 根据电脑的型号,选择性的安装64位和32位的,如果你不懂电脑,那两个全都安装即可. https://aka.…...

期刊屡投不中?虎贲等考 AI:真文献 + 实证图表 + 期刊规范,高效冲击录用
职称评审、课题结题、科研评优、学业深造……一篇高质量期刊论文是所有学术人绕不开的硬指标。但框架难搭、文献难找、实证难做、格式难调、审稿太严,让无数人陷入 “写得慢、返修多、录用难” 的困境。通用 AI 爱编文献、普通工具无实证、办公软件不学术࿰…...

Kubernetes安全扫描利器KubeClaw:轻量配置审计与CI/CD集成实践
1. 项目概述:一个Kubernetes集群的“安全爪牙”最近在搞Kubernetes安全审计和合规检查,发现市面上的工具要么太重,要么太散,要么就是云厂商绑定的。直到我遇到了jianan1104/kubeclaw这个项目,第一眼看到这个名字就觉得…...

终极PRML学术研究指南:最新论文解读与机器学习算法实践秘籍
终极PRML学术研究指南:最新论文解读与机器学习算法实践秘籍 【免费下载链接】PRML PRML algorithms implemented in Python 项目地址: https://gitcode.com/gh_mirrors/pr/PRML PRML(Pattern Recognition and Machine Learning)作为机…...

多模态AI在移动端测试中的应用:视觉+日志+性能联合分析
一、从单点验证到全景追溯:测试范式的必然演进 移动端测试的复杂性早已超越传统Web应用。设备碎片化、网络环境多变、系统资源受限、跨应用交互频繁,这些因素使得单一维度的测试手段越来越力不从心。过去,测试工程师习惯在UI自动化、接口测试…...

LLM 推理优化:加速与量化
LLM 推理优化:加速与量化 1. 技术分析 1.1 LLM 推理挑战 LLM 推理面临的主要挑战: 推理挑战计算量大: O(nd)内存占用高: 参数 KV Cache延迟要求: 实时应用需求1.2 推理优化方法 方法原理加速比精度损失量化降低精度2-4x小蒸馏知识迁移1.5-2x小剪枝移除冗…...