TensorFlow代码逻辑 vs PyTorch代码逻辑
文章目录
- 一、TensorFlow
- (一)导入必要的库
- (二)加载MNIST数据集
- (三)数据预处理
- (四)构建神经网络模型
- (五)编译模型
- (六)训练模型
- (七)评估模型
- (八)将模型的输出转化为概率
- (九)预测测试集的前5个样本
- 二、PyTorch
- (一)导入必要的库
- (二)定义神经网络模型
- (三)数据预处理和加载
- (四)初始化模型、损失函数和优化器
- (五)训练模型
- (六)评估模型
- (七)设置设备为GPU或CPU
- (八)运行训练和评估
- (九)预测测试集的前5个样本
- 三、TensorFlow和PyTorch代码逻辑上的对比
- (一)模型定义
- (二)数据处理
- (三)训练过程
- (四)自动求导
- 四、TensorFlow和PyTorch的应用
- 五、动态图计算
- (一)TensorFlow(静态图计算):
- (二)PyTorch(动态图计算):
一、TensorFlow
使用TensorFlow构建一个简单的神经网络来对MNIST数据集进行分类
(一)导入必要的库
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
(二)加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
(三)数据预处理
将图像数据归一化到[0, 1]范围,以提高模型的训练效果
x_train, x_test = x_train / 255.0, x_test / 255.0
(四)构建神经网络模型
- Flatten层:将输入的28x28像素图像展平成784个特征的一维向量。
- Dense层:全连接层,包含128个神经元,使用ReLU激活函数。
- Dropout层:在训练过程中随机丢弃20%的神经元,防止过拟合。
- 输出层:包含10个神经元,对应10个类别(数字0-9)。
model = models.Sequential([layers.Flatten(input_shape=(28, 28)),layers.Dense(128, activation='relu'),layers.Dropout(0.2),layers.Dense(10)
])
(五)编译模型
- optimizer=‘adam’:使用Adam优化器。
- loss=‘SparseCategoricalCrossentropy’:使用交叉熵损失函数。
- metrics=[‘accuracy’]:使用准确率作为评估指标。
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
(六)训练模型
model.fit(x_train, y_train, epochs=5)
(七)评估模型
model.evaluate(x_test, y_test, verbose=2)
(八)将模型的输出转化为概率
probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()
])
(九)预测测试集的前5个样本
predictions = probability_model.predict(x_test[:5])
print(predictions)
二、PyTorch
使用PyTorch来构建、训练和评估一个用于MNIST数据集的神经网络模型
(一)导入必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
(二)定义神经网络模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.flatten = nn.Flatten()self.fc1 = nn.Linear(28 * 28, 128)self.dropout = nn.Dropout(0.2)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.flatten(x)x = F.relu(self.fc1(x))x = self.dropout(x)x = self.fc2(x)return x
(三)数据预处理和加载
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
(四)初始化模型、损失函数和优化器
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
(五)训练模型
def train(model, device, train_loader, optimizer, epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()if batch_idx % 100 == 0:print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} 'f'({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
(六)评估模型
def test(model, device, test_loader):model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)accuracy = 100. * correct / len(test_loader.dataset)print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} 'f'({accuracy:.0f}%)\n')
(七)设置设备为GPU或CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
(八)运行训练和评估
for epoch in range(1, 6):train(model, device, train_loader, optimizer, epoch)test(model, device, test_loader)
(九)预测测试集的前5个样本
model.eval()
with torch.no_grad():samples = next(iter(test_loader))[0][:5].to(device)output = model(samples)predictions = F.softmax(output, dim=1)print(predictions)
三、TensorFlow和PyTorch代码逻辑上的对比
(一)模型定义
- 在TensorFlow中,通常使用tf.keras模块来定义模型。可以使用Sequential API或Functional API。
import tensorflow as tf# Sequential API
model = tf.keras.Sequential([tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(10, activation='softmax')
])# Functional API
inputs = tf.keras.Input(shape=(784,))
x = tf.keras.layers.Dense(64, activation='relu')(inputs)
outputs = tf.keras.layers.Dense(10, activation='softmax')(x)
model = tf.keras.Model(inputs, outputs)
- PyTorch中,定义模型时需要继承nn.Module类并实现forward方法
import torch
import torch.nn as nnclass Model(nn.Module):def __init__(self):super(Model, self).__init__()self.dense1 = nn.Linear(784, 64)self.relu = nn.ReLU()self.dense2 = nn.Linear(64, 10)self.softmax = nn.Softmax(dim=1)def forward(self, x):x = self.relu(self.dense1(x))x = self.softmax(self.dense2(x))return xmodel = Model()
(二)数据处理
- TensorFlow有tf.data模块来处理数据管道
import tensorflow as tfdef preprocess(data):# 数据预处理逻辑return datadataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
dataset = dataset.map(preprocess).batch(32)
- PyTorch使用torch.utils.data.DataLoader和Dataset类来处理数据管道
import torch
from torch.utils.data import DataLoader, Datasetclass CustomDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, idx):x = self.data[idx]y = self.labels[idx]return x, ydataset = CustomDataset(X_train, y_train)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
(三)训练过程
- TensorFlow的tf.keras提供了高阶API来进行模型编译和训练
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=5, batch_size=32)
- PyTorch中,训练过程需要手动编写,包括前向传播、损失计算、反向传播和优化步骤
import torch.optim as optimcriterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)for epoch in range(5):for data, labels in dataloader:optimizer.zero_grad()outputs = model(data)loss = criterion(outputs, labels)loss.backward()optimizer.step()
(四)自动求导
- TensorFlow在后端自动处理梯度计算和应用
# 使用model.fit自动处理
- PyTorch的自动求导功能非常灵活,可以使用autograd模块
# 使用loss.backward()和optimizer.step()手动处理
四、TensorFlow和PyTorch的应用
总体来说,PyTorch提供了更多的灵活性和控制,适合需要自定义复杂模型和训练过程的场景。而TensorFlow则更加高级和简洁,适合快速原型和标准模型的开发。
TensorFlow:
- 高阶API:使用tf.keras简化模型定义、训练和评估,适合快速原型开发和生产部署。
- 性能优化:支持图计算,优化执行速度和资源使用,适合大规模分布式训练。
- 广泛生态:拥有丰富的工具和库,如TensorBoard用于可视化,TensorFlow Lite用于移动端部署。
- 企业支持:由Google支持,广泛应用于工业界,提供稳定的长期支持和更新。
PyTorch:
- 灵活性:采用动态图计算,代码易于调试和修改,适合研究和实验。
- 简单直观:符合Python语言习惯,API设计简洁明了,降低学习曲线。
- 社区活跃:由Facebook支持,拥有活跃的开源社区,快速响应用户需求和改进。
- 科研应用:广泛应用于学术界,支持多种前沿研究,如自定义损失函数和复杂模型结构。
五、动态图计算
动态图计算是PyTorch的一个显著特点,它让模型的计算图在每次前向传播时动态生成,而不是像TensorFlow那样预先定义和编译。
动态图计算的定义与特性:
- 动态生成:每次执行前向传播时,计算图都会根据当前输入数据动态构建。
- 即时调试:允许在代码执行时使用标准的Python调试工具(如pdb),进行逐步调试和检查。
- 灵活性高:支持更复杂和动态的模型结构,如条件控制流和递归神经网络,更适合研究实验和快速原型开发。
(一)TensorFlow(静态图计算):
在TensorFlow中,计算图是预先定义并编译的。在模型定义和编译之后,图结构固定,随后输入数据进行计算。
import tensorflow as tf# 定义计算图
x = tf.placeholder(tf.float32, shape=(None, 784))
y = tf.placeholder(tf.float32, shape=(None, 10))
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
logits = tf.matmul(x, W) + b
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits))# 创建会话并执行
with tf.Session() as sess:sess.run(tf.global_variables_initializer())for i in range(1000):batch_x, batch_y = ... # 获取训练数据sess.run(loss, feed_dict={x: batch_x, y: batch_y})
(二)PyTorch(动态图计算):
在PyTorch中,计算图在每次前向传播时动态构建,代码更接近标准的Python编程风格。
import torch
import torch.nn as nn
import torch.optim as optim# 定义模型
class Model(nn.Module):def __init__(self):super(Model, self).__init__()self.dense = nn.Linear(784, 10)def forward(self, x):return self.dense(x)model = Model()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练过程
for epoch in range(1000):for data, target in dataloader:optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()
相关文章:

TensorFlow代码逻辑 vs PyTorch代码逻辑
文章目录 一、TensorFlow(一)导入必要的库(二)加载MNIST数据集(三)数据预处理(四)构建神经网络模型(五)编译模型(六)训练模型…...
boost asio异步服务器(4)处理粘包
粘包的产生 当客户端发送多个数据包给服务器时,服务器底层的tcp接收缓冲区收到的数据为粘连在一起的。这种情况的产生通常是服务器端处理数据的速率不如客户端的发送速率的情况。比如:客户端1s内连续发送了两个hello world!,服务器过了2s才接…...

【QT】常用控件|widget|QPushButton|RadioButton|核心属性
目录 编辑 概念 信号与槽机制 控件的多样性和定制性 核心属性 enabled geometry 编辑 windowTiltle windowIcon toolTip styleSheet PushButton RadioButton 概念 QT 控件是构成图形用户界面(GUI)的基础组件,它们是实现与…...

【C++ Primer Plus学习记录】函数参数和按值传递
函数可以有多个参数。在调用函数时,只需使用都逗号将这些参数分开即可: n_chars(R,25); 上述函数调用将两个参数传递给函数n_chars(),我们将稍后定义该函数。 同样,在定义函数时,也在函数头中使用由逗号分隔的参数声…...
MySQL:设计数据库与操作
设计数据库 1. 数据建模1.1 概念模型1.2 逻辑模型1.3 实体模型主键外键外键约束 2. 标准化2.1 第一范式2.2 链接表2.3 第二范式2.4 第三范式 3. 数据库模型修改3.1 模型的正向工程3.2 同步数据库模型3.3 模型的逆向工程3.4 实际应用建议 4. 数据库实体模型4.1 创建和删除数据库…...
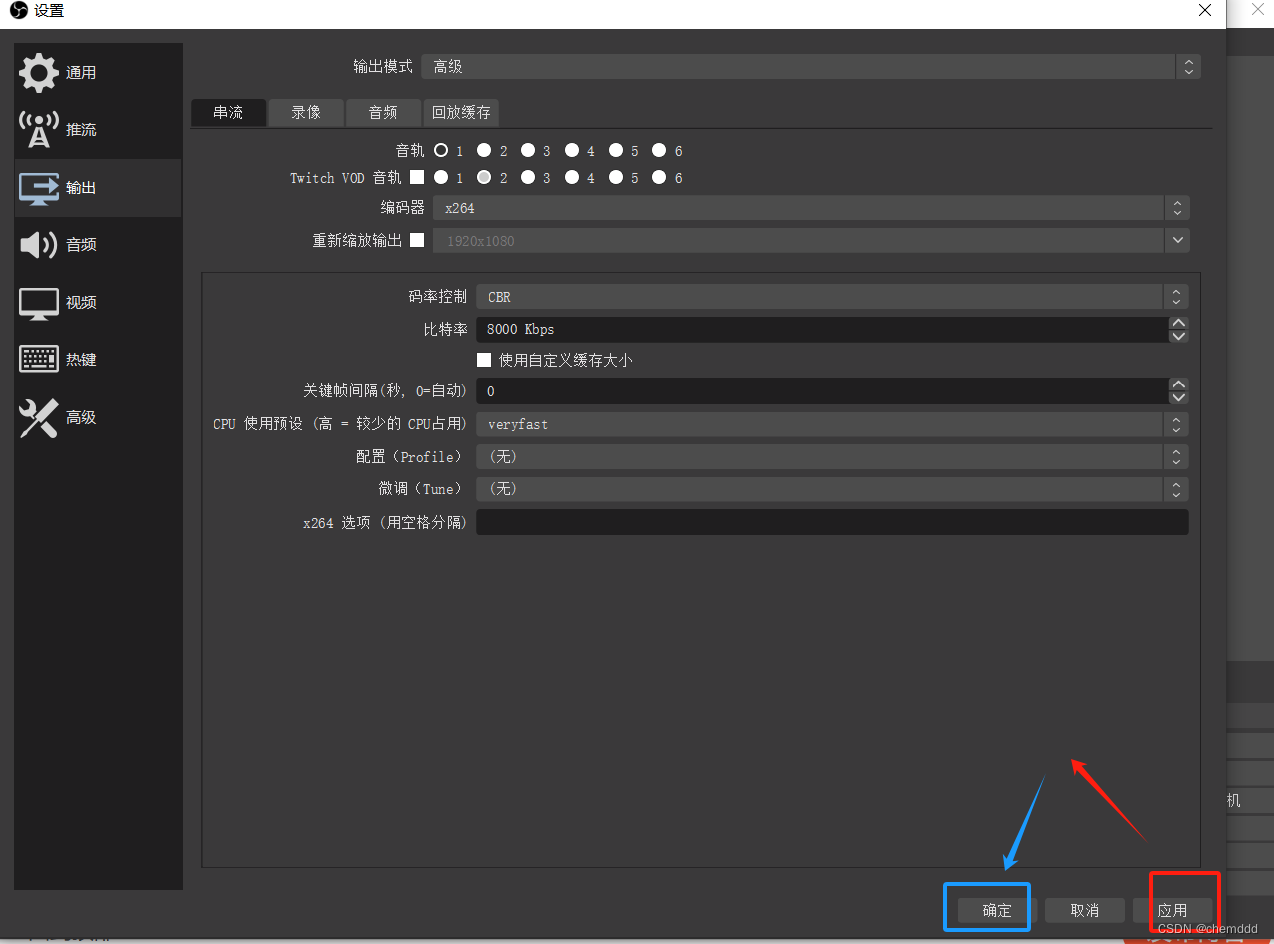
OBS 免费的录屏软件
一、下载 obs 【OBS】OBS Studio 的安装、参数设置和录屏、摄像头使用教程-CSDN博客 二、使用 obs & 输出无黑屏 【OBS任意指定区域录屏的方法-哔哩哔哩】 https://b23.tv/aM0hj8A OBS任意指定区域录屏的方法_哔哩哔哩_bilibili 步骤: 1)获取区域…...
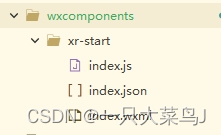
uniapp微信小程序使用xr加载模型
1.在根目录与pages同级创建如下目录结构和文件: // index.js Component({properties: {modelPath: { // vue页面传过来的模型type: String,value: }},data: {},methods: {} }) { // index.json"component": true,"renderer": "xr-frame&q…...

机器人运动范围检测 c++
地上有一个m行n列的方格,一个机器人从坐标(0,0)的格子开始移动,它每次可以向上下左右移动一个格子,但不能进入行坐标和列坐标的位数之和大于k的格子,请问机器人能够到达多少个格子 #include &l…...

kettle从入门到精通 第七十四课 ETL之kettle kettle调用https接口教程,忽略SSL校验
场景:kettle调用https接口,跳过校验SSL。(有些公司内部系统之间的https的接口是没有SSL校验这一说,无需使用用证书的) 解决方案:自定义插件或者自定义jar包通过javascript调用https接口。 1、http post 步…...
)
C++轻量级 线程间异步消息架构(向曾经工作的ROSA-RB以及共事的DOPRA的老兄弟们致敬)
1 啰嗦一番背景 这么多年,换着槽位做牛做马,没有什么钱途 手艺仍然很潮,唯有对于第一线的码农工作,孜孜不倦,其实没有啥进步,就是在不断地重复,刷熟练度,和同期的老兄弟们…...

Kotlin中的类
类初始化顺序 constructor 里的参数列表是首先被执行的,紧接着是 init 块和属性初始化器,最后是次构造函数的函数体。 主构造函数参数列表firstProperty 初始化第一个 init 块secondProperty 初始化第二个 init 块次构造函数函数体 class Example const…...

VSCode中常用的快捷键
通用操作快捷键 显示命令面板:Ctrl Shift P or F1,用于快速访问VSCode的各种命令。 快速打开:Ctrl P,可以快速打开文件、跳转到某个行号或搜索项目内容。 新建窗口/实例:Ctrl Shift N,用于打开一个新的…...
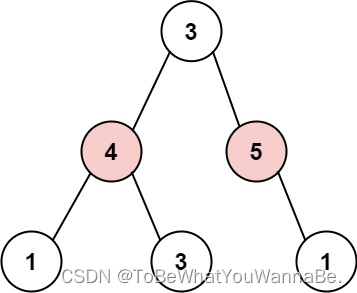
代码随想录-Day45
198. 打家劫舍 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 给定一个代表每个…...
Rust Eq 和 PartialEq
Eq 和 PartialEq 在 Rust 中,想要重载操作符,你就需要实现对应的特征。 例如 <、<、> 和 > 需要实现 PartialOrd 特征: use std::fmt::Display;struct Pair<T> {x: T,y: T, }impl<T> Pair<T> {fn new(x: T, y: T) ->…...

思考如何学习一门编程语言?
一、什么是编程语言 编程语言是一种用于编写计算机程序的人工语言。通过编程语言,程序员可以向计算机发出指令,控制计算机执行各种任务和操作。编程语言由一组语法规则和语义规则组成,这些规则定义了如何编写代码以及代码的含义。 编程语言…...
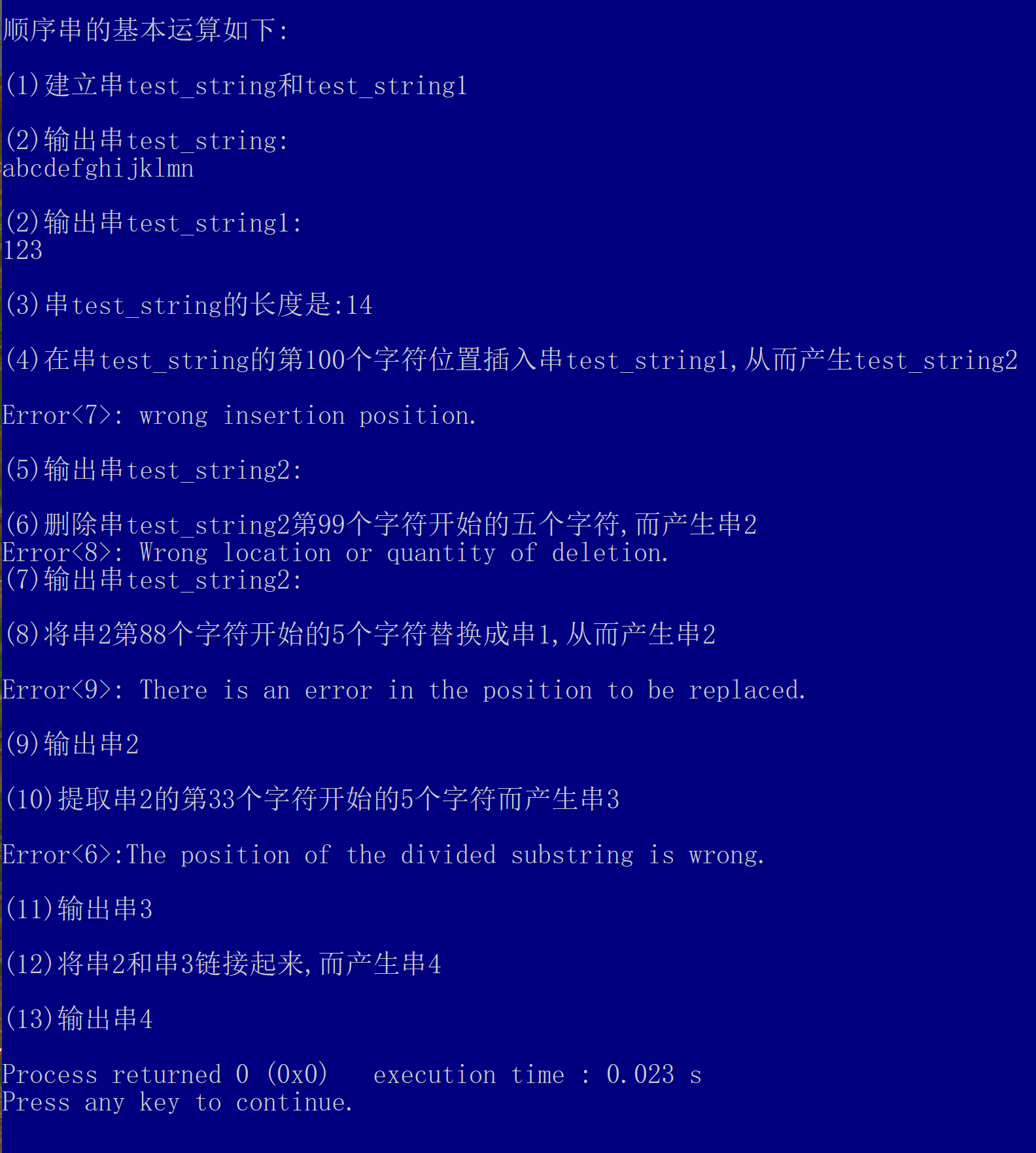
顺序串算法库构建
学习贺利坚老师顺序串算法库 数据结构之自建算法库——顺序串_创建顺序串s1,创建顺序串s2-CSDN博客 本人详细解析博客 串的概念及操作_串的基本操作-CSDN博客 版本更新日志 V1.0: 在贺利坚老师算法库指导下, 结合本人详细解析博客思路基础上,进行测试, 加入异常弹出信息 v1.0补…...
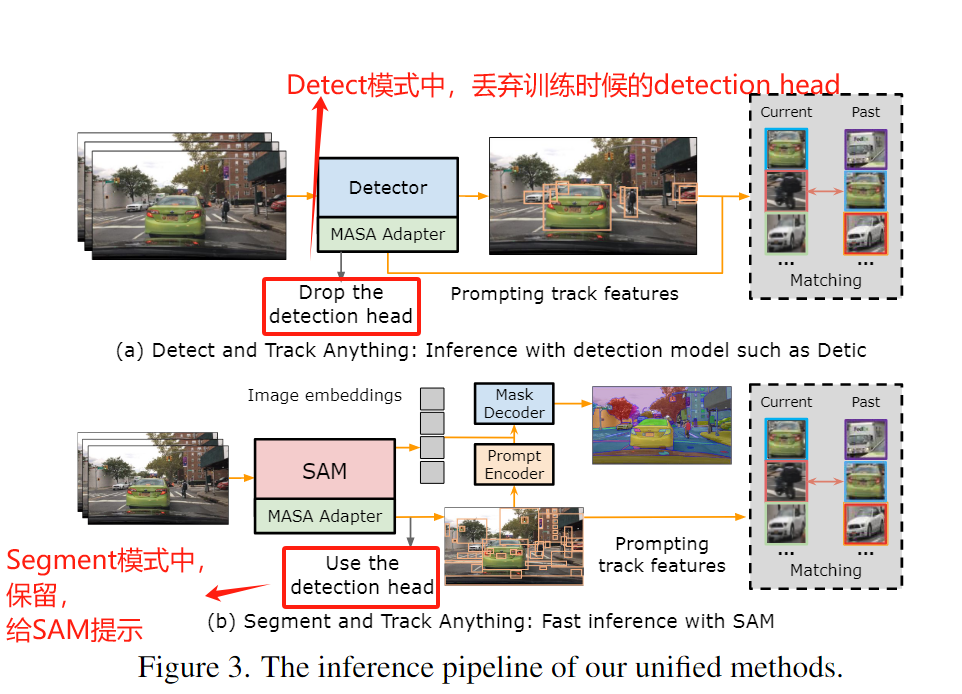
[论文阅读笔记33] Matching Anything by Segmenting Anything (CVPR2024 highlight)
这篇文章借助SAM模型强大的泛化性,在任意域上进行任意的多目标跟踪,而无需任何额外的标注。 其核心思想就是在训练的过程中,利用strong augmentation对一张图片进行变换,然后用SAM分割出其中的对象,因此可以找到一组图…...
阿里Nacos下载、安装(保姆篇)
文章目录 Nacos下载版本选择Nacos安装Windows常见问题解决 更多相关内容可查看 Nacos下载 Nacos官方下载地址:https://github.com/alibaba/nacos/releases 码云拉取(如果国外较慢或者拉取超时可以试一下国内地址) //国外 git clone https:…...

四、golang基础之defer
文章目录 一、定义二、作用三、结果四、recover错误拦截 一、定义 defer语句被用于预定对一个函数的调用。可以把这类被defer语句调用的函数称为延迟函数。 二、作用 释放占用的资源捕捉处理异常输出日志 三、结果 如果一个函数中有多个defer语句,它们会以LIFO…...

机器人----四元素
四元素 四元素的大小 [-1,1] 欧拉角转四元素...

等压雨幕原理在铝合金窗的应用
等压雨幕原理在铝合金窗的应用 摘要: 针对常见的样窗水密气密不达标,首先概述等压雨幕的作用原理,然后介绍其在铝合金门窗应用中的代表性细节。可以看出,控制框扇搭接处的间隙很重要,以及密封胶条合理设计选用的重要性。而且日系推拉采用等压设计的方式很值得借鉴。 关键…...

Go语言实现跨平台系统更新检查器:自动化运维与安全监控实践
1. 项目概述:一个被低估的系统运维“哨兵”在服务器和桌面系统的日常运维中,有一个场景大家一定不陌生:某天,你管理的服务器突然因为一个已知漏洞被攻击,事后排查发现,相关的安全补丁其实在几周前就已经发布…...

CircuitPython状态灯、安全模式与文件系统故障排查实战指南
1. 项目概述与核心价值 如果你正在用CircuitPython做项目,无论是物联网传感器节点、智能穿戴设备还是互动艺术装置,大概率都遇到过这样的瞬间:板子上的RGB状态灯突然开始闪烁诡异的颜色,或者电脑上那个熟悉的 CIRCUITPY U盘图标…...

技术解构:逆向工程视角下的百度网盘下载链接解析机制
技术解构:逆向工程视角下的百度网盘下载链接解析机制 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 想象一下,当你收到朋友分享的百度网盘链接时&…...

U-Boot实战:FAT文件系统五大核心命令详解与应用
1. U-Boot与FAT文件系统基础认知 刚接触嵌入式开发时,我第一次在U-Boot环境下操作FAT文件系统就踩了个大坑——试图用ext4write命令操作FAT32格式的SD卡,结果系统直接报错"Unknown command"。这个经历让我深刻认识到:U-Boot对文件系…...

Kubernetes上Jenkins全栈部署:动态Agent与生产环境调优指南
1. 项目概述:一个面向Kubernetes的Jenkins全栈部署方案在容器化和云原生技术成为主流的今天,如何高效、稳定地部署和管理持续集成/持续交付(CI/CD)流水线,是每个开发团队和运维工程师必须面对的课题。传统的单体Jenkin…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十四)用户指引自助教学源码—东方仙盟
软件教学引导功能说明书未来之窗昭和仙君 - cyberwin_fairyalliance_webquery一、功能概述软件教学引导功能主要用于为用户提供软件操作的引导,通过一系列步骤逐步引导用户完成软件的重要操作。该功能会创建遮罩层、高亮框和提示框,引导用户点击特定元素…...

MQ-3与MiCS-5524气体传感器对比:从原理到实战的选型指南
1. 项目概述与核心价值在嵌入式开发、环境监测乃至一些创意DIY项目中,气体检测是一个常见且关键的需求。无论是为了安全预警(如天然气泄漏),还是进行环境质量评估(如VOC监测),选择一款合适的传感…...

GitHub自动化运维:构建模块化Operator集提升开发效率
1. 项目概述:一个为GitHub开发者量身定制的“操作集”如果你是一个重度GitHub用户,无论是维护个人项目、参与开源贡献,还是管理团队仓库,大概率都经历过这样的场景:每天要重复执行一堆琐碎但必要的操作。比如ÿ…...

HTTP客户端设计哲学:从axios到hoomanity的易用性演进
1. 项目概述:一个为人类设计的HTTP客户端在构建现代应用程序时,与外部API或服务进行HTTP通信几乎是每个开发者都会遇到的日常任务。无论是调用一个天气接口、上传文件到云存储,还是与自家的微服务进行数据交换,我们都需要一个可靠…...