Datawhale - 角色要素提取竞赛
文章目录
- 赛题要求
- 一、赛事背景
- 二、赛事任务
- 三、评审规则
- 1.平台说明
- 2.数据说明
- 3.评估指标
- 4.评测及排行
- 四、作品提交要求
- 五、 运行Baseline
- Step1:下载相关库
- Step2:配置导入
- Step3:模型测试
- Step4:数据读取
- Step5:Prompt设计
- Step6:主函数启动
- Step7:生成提交文件
- Step8:下载 output.json 文件
- 六、补充
- -- 应用的库
- --- tqdm
- --- json
赛题要求
一、赛事背景
在当今数字化时代,企业积累了丰富的对话数据,这些数据不仅是客户与企业之间交流的记录,更是隐藏着宝贵信息的宝库。在这个背景下,群聊对话分角色要素提取成为了企业营销和服务的一项重要策略。
群聊对话分角色要素提取的理念是基于企业对话数据的深度分析和挖掘。通过对群聊对话数据进行分析,企业可以更好地理解客户的需求、兴趣和行为模式,从而精准地把握客户的需求和心理,提供更加个性化和优质的服务。这不仅有助于企业更好地满足客户的需求,提升客户满意度,还可以为企业带来更多的商业价值和竞争优势。
群聊对话分角色要素提取的研究,将企业对话数据转化为可用的信息和智能的洞察,为企业营销和服务提供了新的思路和方法。通过挖掘对话数据中隐藏的客户行为特征和趋势,企业可以更加精准地进行客户定位、推广营销和产品服务,实现营销效果的最大化和客户价值的最大化。这将为企业带来更广阔的发展空间和更持续的竞争优势。
二、赛事任务
从给定的<客服>与<客户>的群聊对话中, 提取出指定的字段信息,待提取的全部字段见下数据说明。
三、评审规则
1.平台说明
参赛选手需基于讯飞星火大模型V3.5完成任务。允许使用大模型微调的方式进行信息抽取, 但微调的基座模型仅限星火大模型。
关于星火V3.5资源,组委会将为报名参赛选手统一发放API资源福利,选手用个人参赛账号登录讯飞开放平台:https://www.xfyun.cn/ ,前往控制台中查看使用。关于微调训练资源,选手用参赛账户登陆大模型训练平台( https://training.xfyun.cn/overview ),可领取本次比赛的训练资源福利。
2.数据说明
赛题方提供了184条真实场景的群聊对话数据以及人工标注后的字段提取结果,其中训练数据129条,测试数据 55条。按照各类字段提取的难易程度,共设置了1、2、3三种难度分数。待提取的字段以及提取正确时的得分规则如下:
| 序号 | 字段名称 | 是否单值 | 是否可为空 | 难度分数 | 答案是否唯一 | 备注 |
|---|---|---|---|---|---|---|
| 1 | 基本信息-姓名 | 是 | 是 | 1 | 是 | |
| 2 | 基本信息-手机号码 | 是 | 是 | 1 | 是 | |
| 3 | 基本信息-邮箱 | 是 | 是 | 1 | 是 | |
| 4 | 基本信息-地区 | 是 | 是 | 1 | 是 | |
| 5 | 基本信息-详细地址 | 是 | 是 | 1 | 是 | |
| 6 | 基本信息-性别 | 是 | 是 | 1 | 是 | |
| 7 | 基本信息-年龄 | 是 | 是 | 1 | 是 | |
| 8 | 基本信息-生日 | 是 | 是 | 1 | 是 | |
| 9 | 咨询类型 | 否 | 是 | 2 | 是 | |
| 10 | 意向产品 | 否 | 是 | 3 | 是 | |
| 11 | 购买异议点 | 否 | 是 | 3 | 是 | |
| 12 | 客户预算-预算是否充足 | 是 | 是 | 2 | 是 | |
| 13 | 客户预算-总体预算金额 | 是 | 是 | 2 | 是 | |
| 14 | 客户预算-预算明细 | 是 | 是 | 3 | 否 | |
| 15 | 竞品信息 | 是 | 是 | 2 | 是 | |
| 16 | 客户是否有意向 | 是 | 是 | 1 | 是 | |
| 17 | 客户是否有卡点 | 是 | 是 | 1 | 是 | |
| 18 | 客户购买阶段 | 是 | 是 | 2 | 是 | |
| 19 | 下一步跟进计划-参与人 | 否 | 是 | 2 | 是 | |
| 20 | 下一步跟进计划-时间点 | 是 | 是 | 2 | 是 | |
| 21 | 下一步跟进计划-具体事项 | 是 | 是 | 3 | 否 |
备注:
1)可为空的字段,当判定无相应信息、无法做出判断等情况,统一取值为空字符串
2)对于非单值字段,请使用list来表示
3.评估指标
测试集的每条数据同样包含共21个字段, 按照各字段难易程度划分总计满分36分。每个提取正确性的判定标准如下:
1)对于答案唯一字段,将使用完全匹配的方式计算提取是否正确,提取正确得到相应分数,否则为0分
2)对于答案不唯一字段,将综合考虑提取完整性、语义相似度等维度判定提取的匹配分数,最终该字段得分为 “匹配分数 * 该字段难度分数”
每条测试数据的最终得分为各字段累计得分。最终测试集上的分数为所有测试数据的平均得分。
4.评测及排行
1)本赛题均提供下载数据,选手在本地进行算法调试,在比赛页面提交结果。
2)排行按照得分从高到低排序,排行榜将选择团队的历史最优成绩进行排名。
四、作品提交要求
1、文件格式:按照 json格式提交
2、文件大小:无要求
3、提交次数限制:每支队伍每天最多3次
4、文件详细说明:编码为UTF-8,具体格式参考提交示例
5、关于大模型的使用说明&限制。
• 如果使用大模型进行信息抽取, 本次仅限使用星火大模型。
• 为了排除人工校验、修正等作弊方式,本次比赛除了提交答案之外,排行榜前3名选手需要提供完整的源代码进行审核,要求抽取的结果必须可以准确复现。
• 注:排行榜前3名有审核不通过现象时,依次按得分顺延。满分36分,原则上最终入围决赛三甲得分不得低于20分。
• 允许使用大模型微调的方式进行信息抽取, 微调的基座模型仅限星火大模型。
五、 运行Baseline
项目链接 : 基于星火大模型的群聊对话分角色要素提取挑战-baseline - 飞桨AI Studio星河社区 (baidu.com)
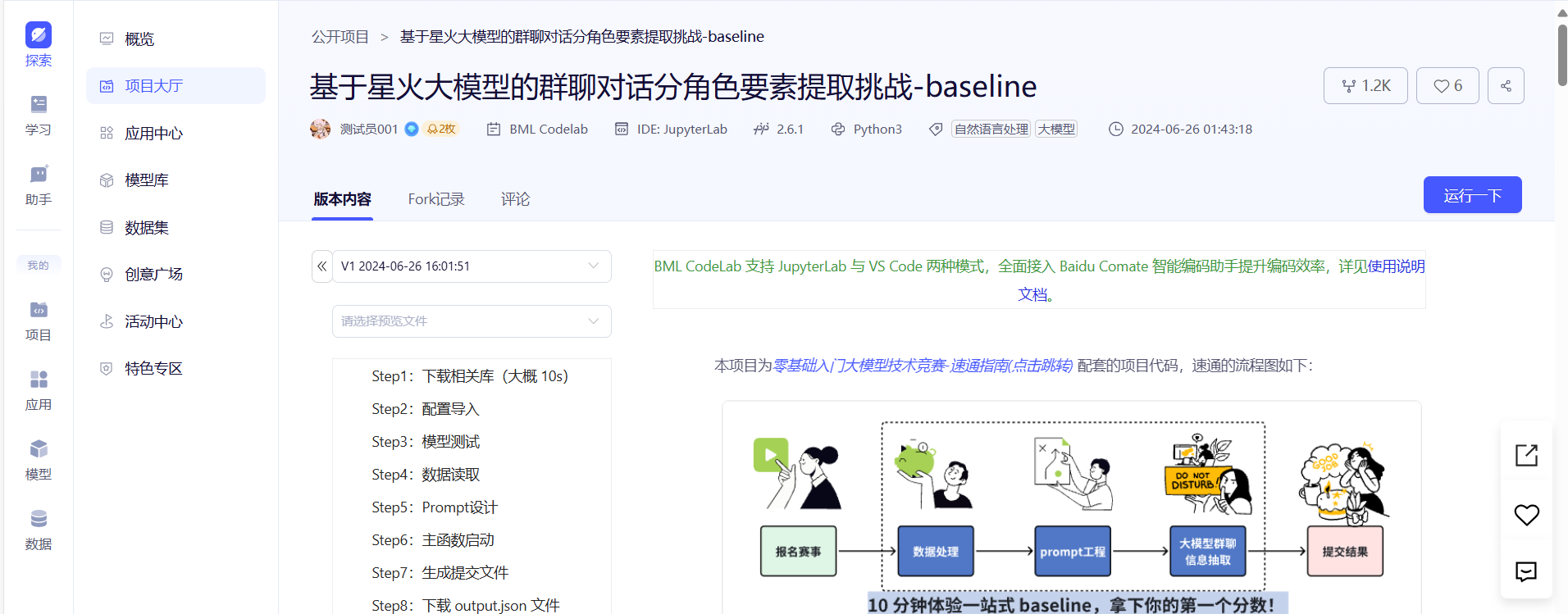
进入之后在 探索 -> 项目大厅 中进入该页面,点击 运行一下
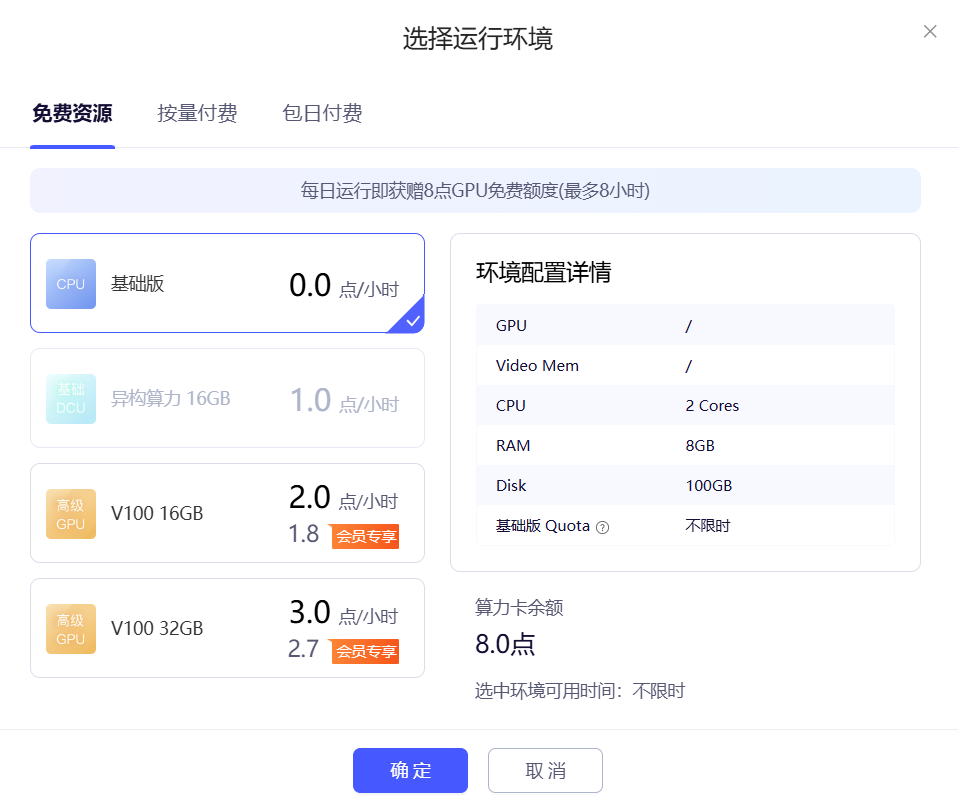
选择运行环境后,点击确定

出现图示启动成功,单击 进入
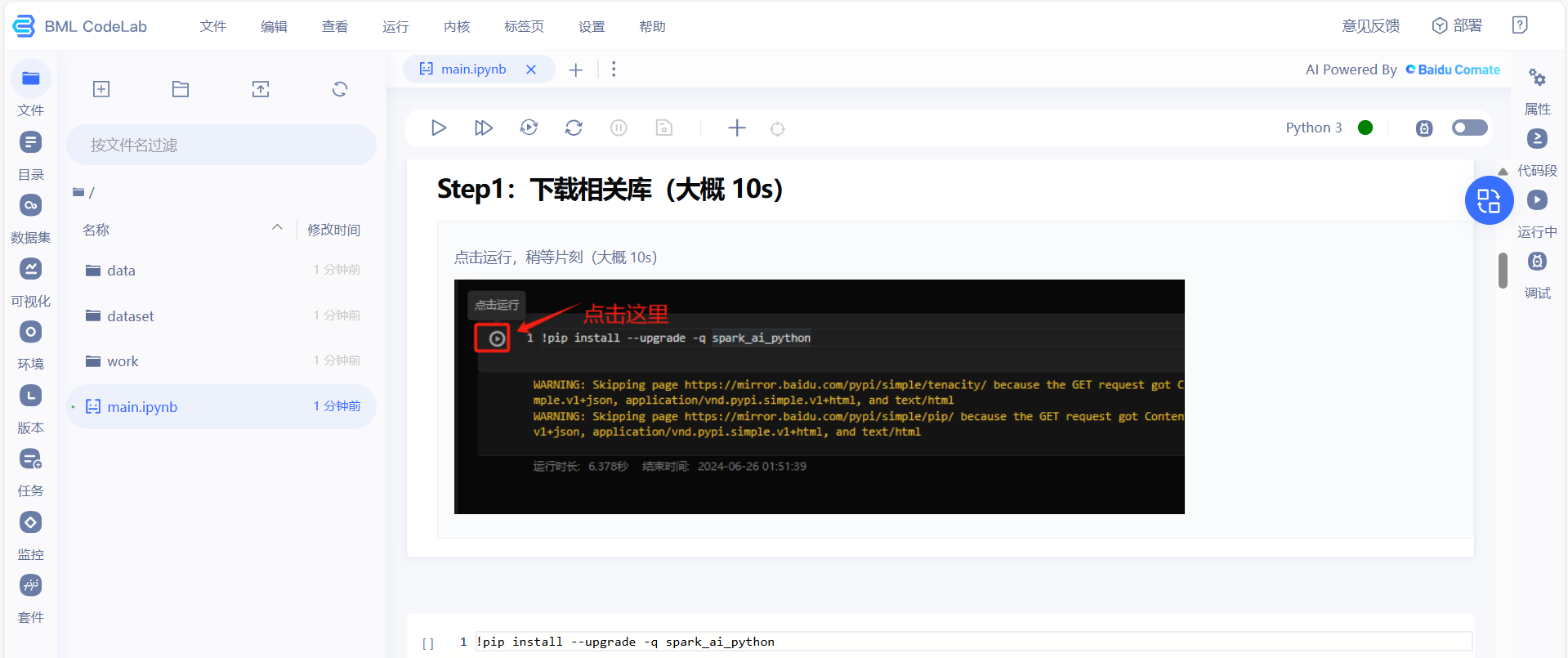
进入界面后可以直接操作运行
Step1:下载相关库

!pip install --upgrade -q spark_ai_python
注意: 此处的 ! 为jupyter notebook 形式的魔法命令
Step2:配置导入
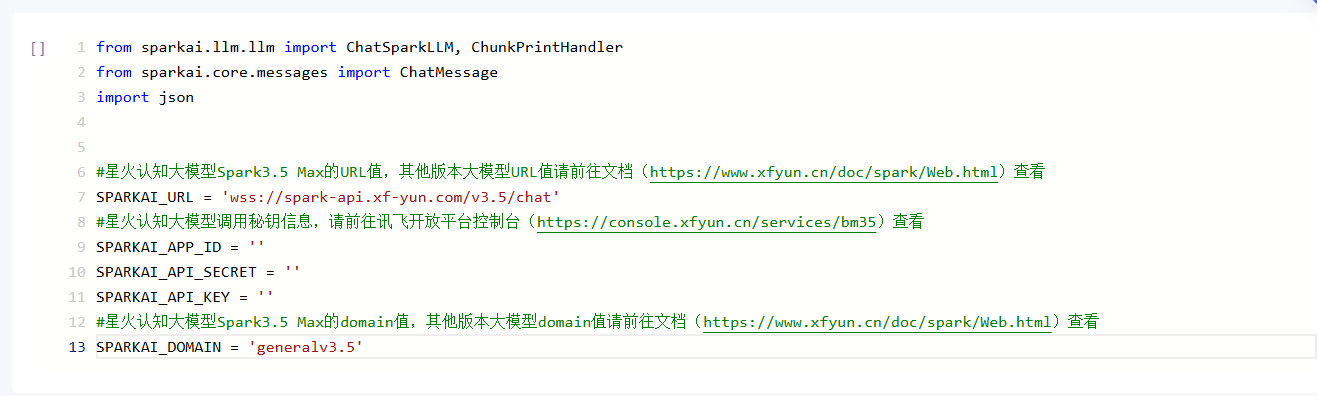
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandlerfrom sparkai.core.messages import ChatMessageimport json#星火认知大模型Spark3.5 Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'#星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看SPARKAI_APP_ID = ''SPARKAI_API_SECRET = ''SPARKAI_API_KEY = ''#星火认知大模型Spark3.5 Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看SPARKAI_DOMAIN = 'generalv3.5'
在此处设置调用星火大模型的基础信息
Step3:模型测试
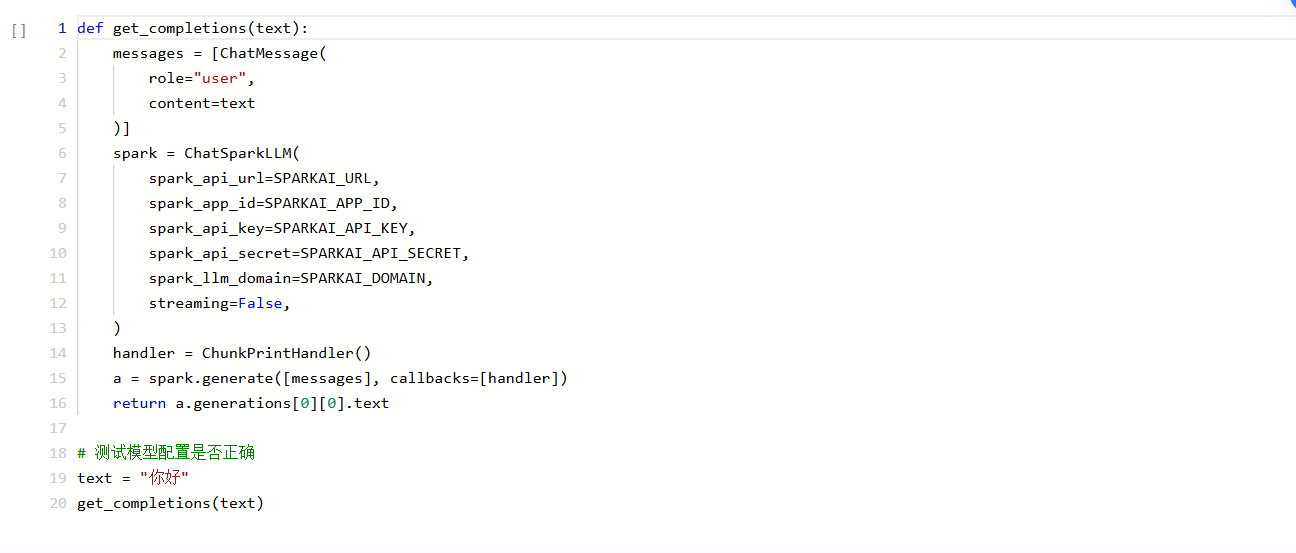
def get_completions(text):messages = [ChatMessage(role="user",content=text)]spark = ChatSparkLLM(spark_api_url=SPARKAI_URL,spark_app_id=SPARKAI_APP_ID,spark_api_key=SPARKAI_API_KEY,spark_api_secret=SPARKAI_API_SECRET,spark_llm_domain=SPARKAI_DOMAIN,streaming=False,)handler = ChunkPrintHandler()a = spark.generate([messages], callbacks=[handler])return a.generations[0][0].text# 测试模型配置是否正确text = "你好"get_completions(text)
该处使用代码的形式构建了大模型的问答处理功能,比较简单,只有text一个参数
Step4:数据读取
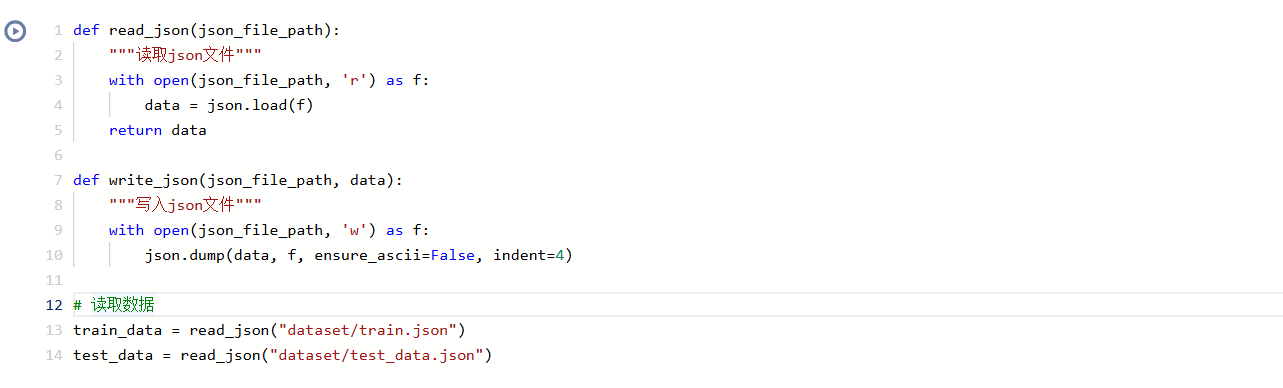
def read_json(json_file_path):"""读取json文件"""with open(json_file_path, 'r') as f:data = json.load(f)return datadef write_json(json_file_path, data):"""写入json文件"""with open(json_file_path, 'w') as f:json.dump(data, f, ensure_ascii=False, indent=4)# 读取数据train_data = read_json("dataset/train.json")test_data = read_json("dataset/test_data.json")
该处代码主要为了获取比赛提供的数据
Step5:Prompt设计

此处详细的设置了提示词的内容, 具体内容如下:
# prompt 设计PROMPT_EXTRACT = """你将获得一段群聊对话记录。你的任务是根据给定的表单格式从对话记录中提取结构化信息。在提取信息时,请确保它与类型信息完全匹配,不要添加任何没有出现在下面模式中的属性。表单格式如下:info: Array<Dict("基本信息-姓名": string | "", // 客户的姓名。"基本信息-手机号码": string | "", // 客户的手机号码。"基本信息-邮箱": string | "", // 客户的电子邮箱地址。"基本信息-地区": string | "", // 客户所在的地区或城市。"基本信息-详细地址": string | "", // 客户的详细地址。"基本信息-性别": string | "", // 客户的性别。"基本信息-年龄": string | "", // 客户的年龄。"基本信息-生日": string | "", // 客户的生日。"咨询类型": string[] | [], // 客户的咨询类型,如询价、答疑等。"意向产品": string[] | [], // 客户感兴趣的产品。"购买异议点": string[] | [], // 客户在购买过程中提出的异议或问题。"客户预算-预算是否充足": string | "", // 客户的预算是否充足。示例:充足, 不充足"客户预算-总体预算金额": string | "", // 客户的总体预算金额。"客户预算-预算明细": string | "", // 客户预算的具体明细。"竞品信息": string | "", // 竞争对手的信息。"客户是否有意向": string | "", // 客户是否有购买意向。示例:有意向, 无意向"客户是否有卡点": string | "", // 客户在购买过程中是否遇到阻碍或卡点。示例:有卡点, 无卡点"客户购买阶段": string | "", // 客户当前的购买阶段,如合同中、方案交流等。"下一步跟进计划-参与人": string[] | [], // 下一步跟进计划中涉及的人员(客服人员)。"下一步跟进计划-时间点": string | "", // 下一步跟进的时间点。"下一步跟进计划-具体事项": string | "" // 下一步需要进行的具体事项。)>请分析以下群聊对话记录,并根据上述格式提取信息:**对话记录:**\```{content}\```请将提取的信息以JSON格式输出。不要添加任何澄清信息。输出必须遵循上面的模式。不要添加任何没有出现在模式中的附加字段。不要随意删除字段。**输出:**\```[{{"基本信息-姓名": "姓名","基本信息-手机号码": "手机号码","基本信息-邮箱": "邮箱","基本信息-地区": "地区","基本信息-详细地址": "详细地址","基本信息-性别": "性别","基本信息-年龄": "年龄","基本信息-生日": "生日","咨询类型": ["咨询类型"],"意向产品": ["意向产品"],"购买异议点": ["购买异议点"],"客户预算-预算是否充足": "充足或不充足","客户预算-总体预算金额": "总体预算金额","客户预算-预算明细": "预算明细","竞品信息": "竞品信息","客户是否有意向": "有意向或无意向","客户是否有卡点": "有卡点或无卡点","客户购买阶段": "购买阶段","下一步跟进计划-参与人": ["跟进计划参与人"],"下一步跟进计划-时间点": "跟进计划时间点","下一步跟进计划-具体事项": "跟进计划具体事项"}}, ...]\```"""
Step6:主函数启动
import jsonclass JsonFormatError(Exception):def __init__(self, message):self.message = messagesuper().__init__(self.message)def convert_all_json_in_text_to_dict(text):"""提取LLM输出文本中的json字符串"""dicts, stack = [], []for i in range(len(text)):if text[i] == '{':stack.append(i)elif text[i] == '}':begin = stack.pop()if not stack:dicts.append(json.loads(text[begin:i+1]))return dicts# 查看对话标签def print_json_format(data):"""格式化输出json格式"""print(json.dumps(data, indent=4, ensure_ascii=False))def check_and_complete_json_format(data):required_keys = {"基本信息-姓名": str,"基本信息-手机号码": str,"基本信息-邮箱": str,"基本信息-地区": str,"基本信息-详细地址": str,"基本信息-性别": str,"基本信息-年龄": str,"基本信息-生日": str,"咨询类型": list,"意向产品": list,"购买异议点": list,"客户预算-预算是否充足": str,"客户预算-总体预算金额": str,"客户预算-预算明细": str,"竞品信息": str,"客户是否有意向": str,"客户是否有卡点": str,"客户购买阶段": str,"下一步跟进计划-参与人": list,"下一步跟进计划-时间点": str,"下一步跟进计划-具体事项": str}if not isinstance(data, list):raise JsonFormatError("Data is not a list")for item in data:if not isinstance(item, dict):raise JsonFormatError("Item is not a dictionary")for key, value_type in required_keys.items():if key not in item:item[key] = [] if value_type == list else ""if not isinstance(item[key], value_type):raise JsonFormatError(f"Key '{key}' is not of type {value_type.__name__}")if value_type == list and not all(isinstance(i, str) for i in item[key]):raise JsonFormatError(f"Key '{key}' does not contain all strings in the list")return data
-
JsonFormatError类用于自定义异常。 -
convert_all_json_in_text_to_dict函数用于从文本中提取JSON字符串并转换为字典。 -
print_json_format函数用于格式化输出JSON数据。 -
check_and_complete_json_format函数用于检查和补全JSON数据的格式,确保每个JSON对象包含所有必需的键,并且每个键的值类型正确。
from tqdm import tqdmretry_count = 5 # 重试次数result = []error_data = []for index, data in tqdm(enumerate(test_data)):index += 1is_success = Falsefor i in range(retry_count):try:res = get_completions(PROMPT_EXTRACT.format(content=data["chat_text"]))infos = convert_all_json_in_text_to_dict(res)infos = check_and_complete_json_format(infos)result.append({"infos": infos,"index": index})is_success = Truebreakexcept Exception as e:print("index:", index, ", error:", e)continueif not is_success:data["index"] = indexerror_data.append(data)
-
初始化变量:
-
retry_count被设置为 5,表示每个数据项最多尝试处理 5 次。 -
result是一个空列表,用于存储成功处理的数据结果。 -
error_data是一个空列表,用于存储处理失败的数据项。
-
-
循环处理数据:
-
使用
tqdm库的enumerate函数来遍历test_data,这样可以同时获取数据项和其索引,并且在控制台显示一个进度条。 -
index变量表示当前数据项的索引(从 1 开始)。 -
is_success变量用于标记当前数据项是否处理成功。
-
-
重试机制:
-
对于每个数据项,代码会尝试最多
retry_count次来处理它。 -
在每次尝试中,代码会调用
get_completions函数来获取结果,并使用convert_all_json_in_text_to_dict和check_and_complete_json_format函数来处理结果。 -
如果处理成功(即没有抛出异常),则将结果添加到
result列表中,并将is_success设置为True,然后跳出重试循环。
-
-
错误处理:
-
如果在任何一次尝试中抛出异常,代码会捕获该异常,并打印错误信息(包括当前数据项的索引和异常信息)。
-
如果所有重试都失败(即
is_success仍然为False),则将当前数据项添加到error_data列表中,以便后续处理。
-
Step7:生成提交文件
# 保存输出write_json("output.json", result)
Step8:下载 output.json 文件
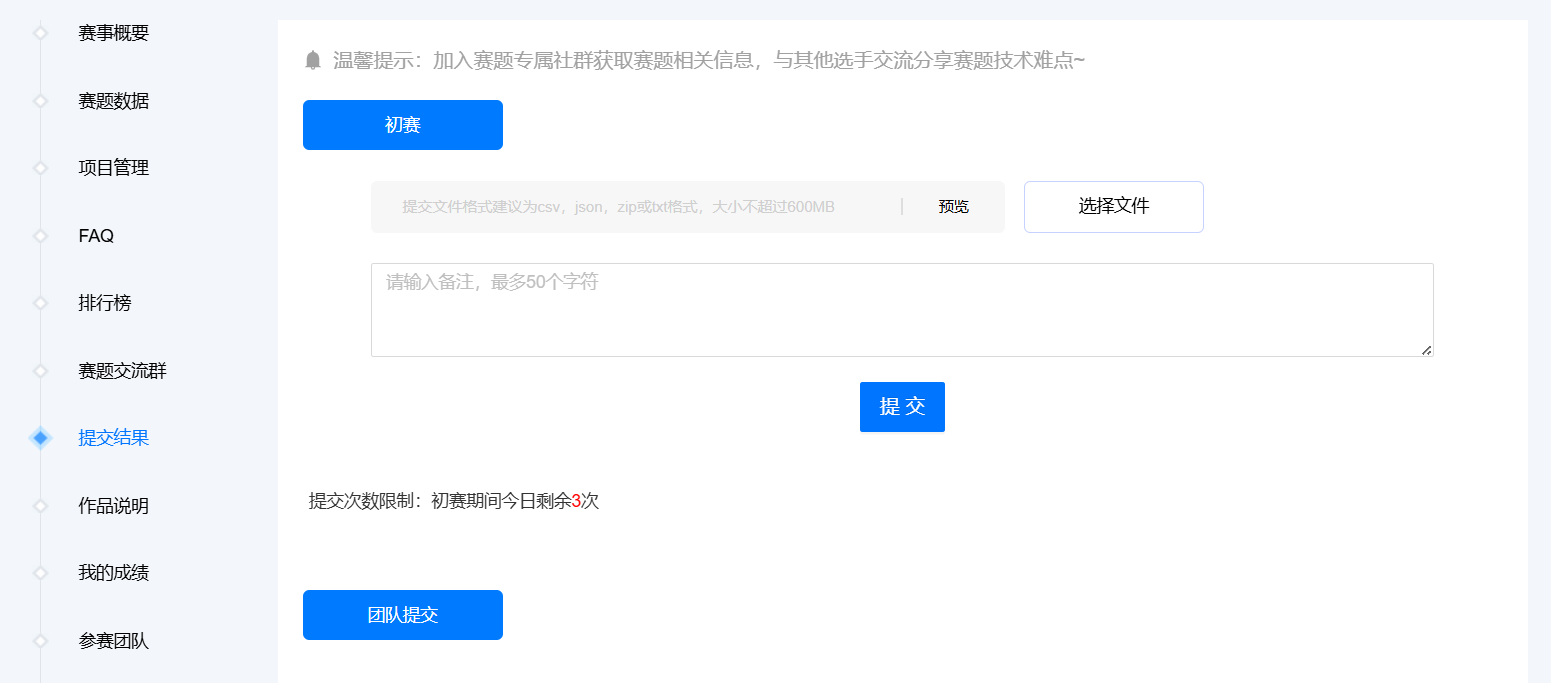
在左边文件夹栏中点击下载生成的文件,回到比赛平台提交结果即可。2024 iFLYTEK A.I.开发者大赛-讯飞开放平台 (xfyun.cn)

在 提交结果 中可以看到相应的分数:
六、补充
– 应用的库
— tqdm
python库 - tqdm-CSDN博客
— json
python库 - json-CSDN博客
如有错误,敬请批评指正!
相关文章:
Datawhale - 角色要素提取竞赛
文章目录 赛题要求一、赛事背景二、赛事任务三、评审规则1.平台说明2.数据说明3.评估指标4.评测及排行 四、作品提交要求五、 运行BaselineStep1:下载相关库Step2:配置导入Step3:模型测试Step4:数据读取Step5:Prompt设…...

【Sql-驯化】sql中对时间的处理方法技巧总结
【Sql-驯化】sql中对时间的处理方法技巧总结 本次修炼方法请往下查看 🌈 欢迎莅临我的个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地! 🎇 免费获取相关内容文档关注:微信公众…...
TFD那智机器人仿真离线程序文本转换为现场机器人程序
TFD式样那智机器人离线程序通过Process Simulation、DELMIA等仿真软件为载体给机器人出离线,下载下来的文本程序,现场机器人一般是无法导入及识别出来的。那么就需要TFD on Desk TFD控制器来进行转换,才能导入现场机器人读取程序。 导入的文…...

贪心+后缀和,CF 1903C - Theofanis‘ Nightmare
一、题目 1、题目描述 2、输入输出 2.1输入 2.2输出 3、原题链接 1903C - Theofanis Nightmare 二、解题报告 1、思路分析 我们任意一种分组其实都是若干个后缀和相加 比如我们分成了三组,第一组的数被加了一次,第二组的数被加了两次,第…...
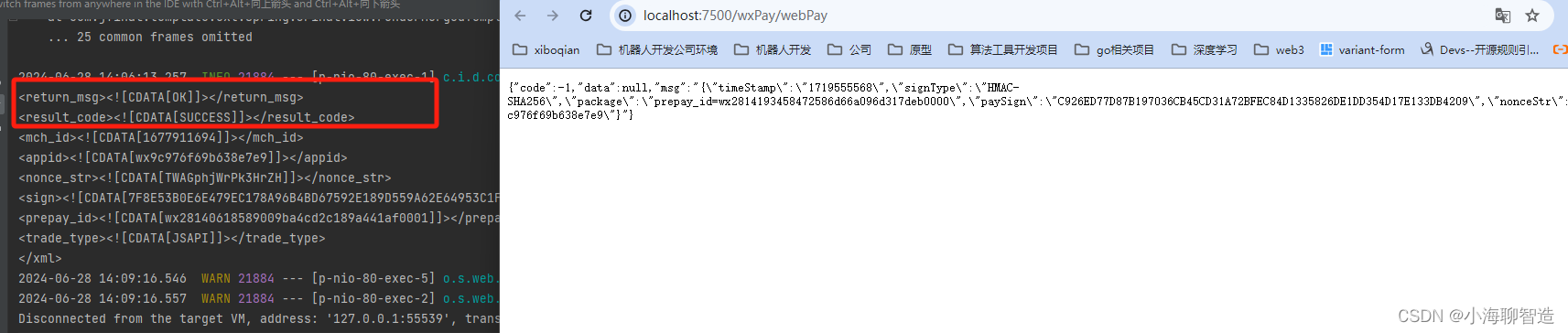
10分钟完成微信JSAPI支付对接过程-JAVA后端接口
引入架包 <dependency><groupId>com.github.javen205</groupId><artifactId>IJPay-WxPay</artifactId><version>${ijapy.version}</version></dependency>配置类 package com.joolun.web.config;import org.springframework.b…...
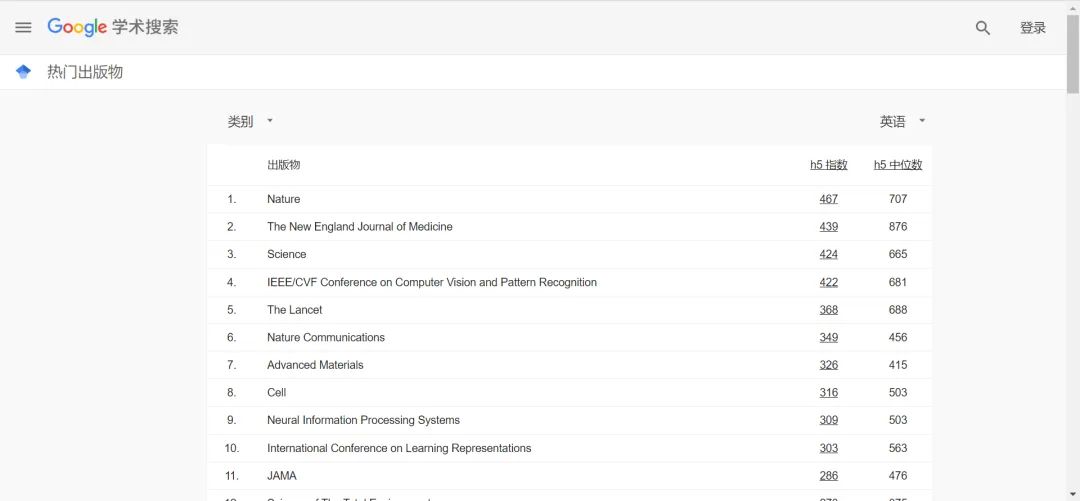
如何寻找一个领域的顶级会议,并且判断这个会议的影响力?
如何寻找一个领域的顶级会议,并且判断这个会议的影响力? 会议之眼 快讯 很多同学都在问:学术会议不是期刊,即使被SCI检索,也无法查询影响因子。那么如何知道各个领域的顶级会议,并对各个会议有初步了解呢…...

真的假不了,假的真不了
大家好,我是瑶琴呀,拥有一头黑长直秀发的女程序员。 最近,17岁的中专生姜萍参加阿里巴巴 2024 年的全球数学竞赛,取得了 12 名的好成绩,一时间在网上沸腾不止。 从最开始的“数学天才”,到被质疑ÿ…...
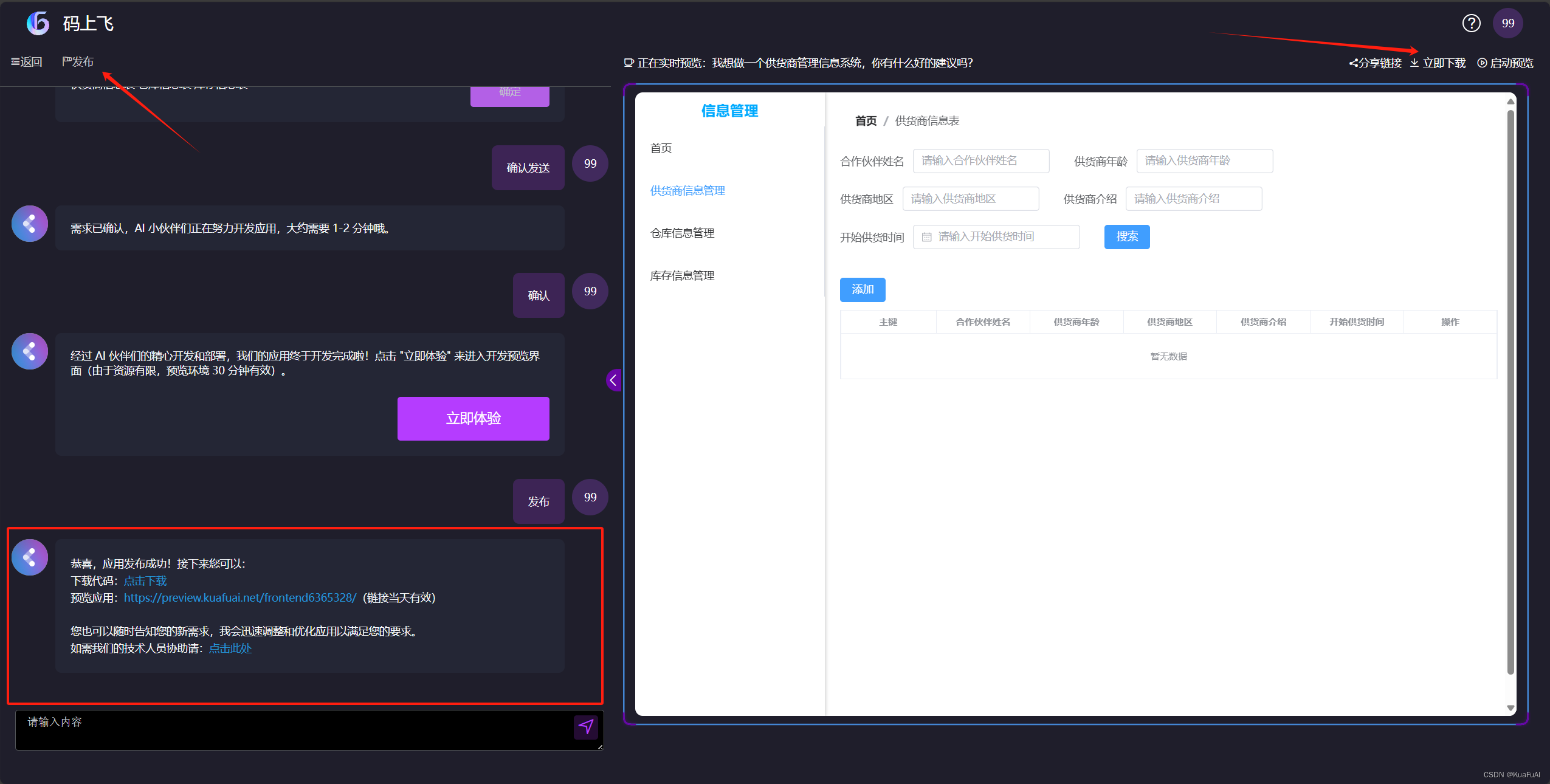
看完这篇文章你就知道什么是未来软件开发的方向了!即生成式AI在软件开发领域的革新=CodeFlying
从最早的UGC(用户生成内容)到PGC(专业生成内容)再到AIGC(人工智能生成内容)体现了web1.0→web2.0→web3.0的发展历程。 毫无疑问UGC已经成为了当前拥有群体数量最大的内容生产方式。 同时随着人工智能技术…...

HTML5五十六个民族网站模板源码
文章目录 1.设计来源高山族1.1 登录界面演示1.2 注册界面演示1.3 首页界面演示1.4 中国民族界面演示1.5 关于高山族界面演示1.6 联系我们界面演示 2.效果和源码2.1 动态效果2.2 源代码2.3 源码目录 源码下载 作者:xcLeigh 文章地址:https://blog.csdn.ne…...

Linux_fileio实现copy文件
参考韦东山老师教程:https://www.bilibili.com/video/BV1kk4y117Tu?p12 目录 1. 通过read方式copy文件2. 通过mmap映射方式copy文件 1. 通过read方式copy文件 copy文件代码: #include <sys/types.h> #include <sys/stat.h> #include <…...

【JavaEE精炼宝库】多线程进阶(2)synchronized原理、JUC类——深度理解多线程编程
一、synchronized 原理 1.1 基本特点: 结合上面的锁策略,我们就可以总结出,synchronized 具有以下特性(只考虑 JDK 1.8): 开始时是乐观锁,如果锁冲突频繁,就转换为悲观锁。 开始是轻量级锁实现ÿ…...

【Linux进程通信】使用匿名管道制作一个简单的进程池
进程池是什么呢?我们可以类比内存池的概念来理解进程池。 内存池 内存池是在真正使用内存之前,先申请分配一定数量的、大小相等(一般情况下)的内存块留作备用。当有新的内存需求时,就从内存池中分出一部分内存块,若内存块不够再继…...
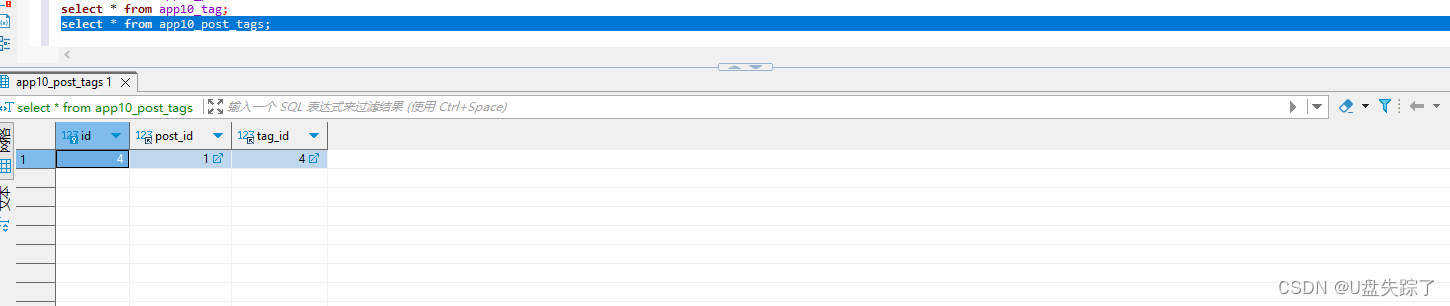
Django 多对多关系
多对多关系作用 Django 中,多对多关系模型的作用主要是为了表示两个模型之间的多对多关系。具体来说,多对多关系允许一个模型的实例与另一个模型的多个实例相关联,反之亦然。这在很多实际应用场景中非常有用,比如: 博…...
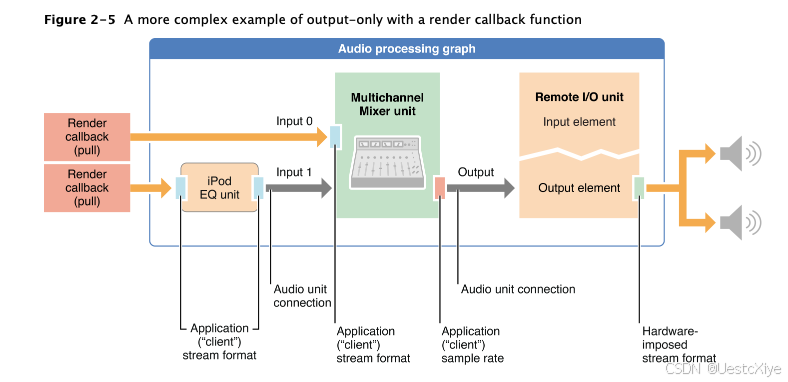
构建 Audio Unit 应用程序
构建 Audio Unit 应用程序 构建 Audio Unit 应用程序从选择设计模式开始I/O Pass ThroughI/O Without a Render Callback FunctionI/O with a Render Callback FunctionOutput-Only with a Render Callback Function其他设计模式 构建应用程序配置 audio session指定 audio uni…...

JavaScript 实用技巧
1. 使用 const 和 let 替代 var 在 ES6 之前,我们通常使用 var 声明变量。但如今,推荐使用 const 和 let,因为它们具有块级作用域,可以避免很多潜在的问题。 const PI 3.14; // 常量,无法重新赋值 let age 25; // …...

Python协作运动机器人刚体力学解耦模型
🎯要点 🎯腿式或固定式机器人模型 | 🎯网格、点云和体素网格碰撞检测 | 🎯正反向运动学和动力学 | 🎯机器人刚体力学计算 | 🎯编辑参考系姿势和路径 | 🎯软件接口实体机器人模拟 | Ἲ…...
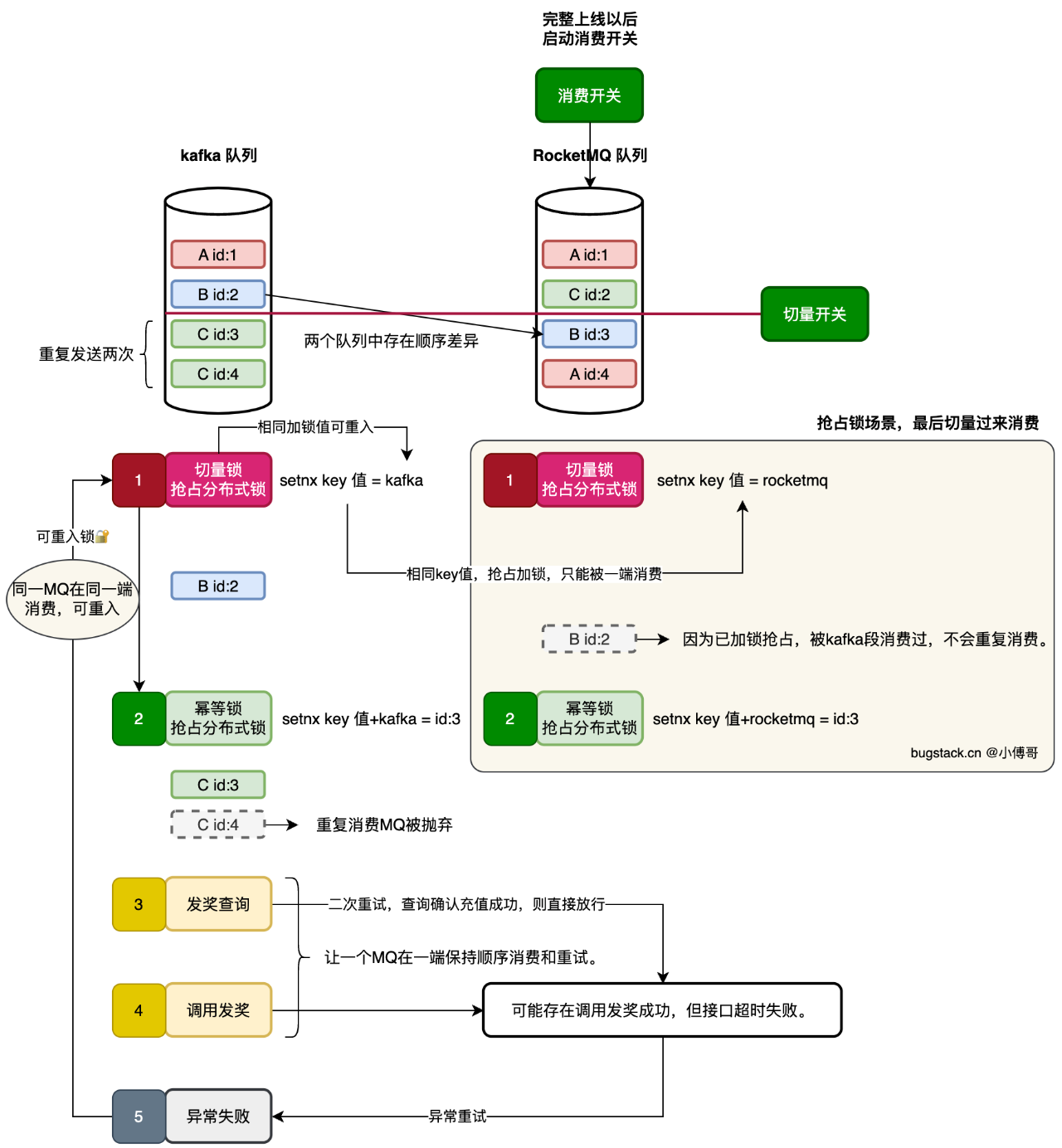
可重入锁思想,设计MQ迁移方案
如果你的MQ消息要从Kafka切换到RocketMQ且不停机,怎么做?在让这个MQ消息调用第三方发奖接口,但无幂等字段又怎么处理?今天小傅哥就给大家分享一个关于MQ消息在这样的场景中的处理手段。 这是一种比较特例的场景,需要保…...

Redis安装与使用
目录 1、介绍 1、redis的特点: 2、缓存 2、安装Redis 1、安装单机版redis 2、redis-cli命令参数 3、清空数据库的两种方式和作用域: 4、redis的增删查改命令 5、redis的查看所有分类命令 6、redis过期时间与控制键的行为 7、redis的相关工具 1、介绍 r…...

base64字符串空格问题
客户端使用的Content-Type为application/x-www-form-urlencoded时,字符串中出现了空格,base64解码时出错了,因为原来的字符有号, Spring Boot 对于Content-Type为application/x-www-form-urlencoded的HTTP请求,默认情…...

【BES2500x系列 -- RTX5操作系统】深入探索CMSIS-RTOS RTX -- 同步与通信篇 -- 消息队列和邮箱处理 --(四)
💌 所属专栏:【BES2500x系列】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! Ὁ…...

告别手改脚本!用CANoe Panel面板做个变量控制台,测试效率翻倍
告别手改脚本!用CANoe Panel面板打造智能变量控制台 在车载网络测试领域,效率提升往往隐藏在那些被忽视的日常操作细节中。当测试工程师频繁打开CAPL脚本修改超时阈值、调整诊断ID或切换测试模式时,不仅打断了工作流,更在团队协作…...

VSCode光标主题定制指南:从颜色令牌到扩展开发
1. 项目概述:一个为开发者定制的光标主题集合如果你和我一样,每天有超过8小时的时间都泡在代码编辑器里,那么你一定会对编辑器里那个千篇一律的、闪烁的竖线光标感到审美疲劳。warrenwoodhouse/cursors这个项目,就是来解决这个“小…...

用ZYNQ和LWIP搞定8路ADS8681数据采集:从Vivado Block Design到上位机TCP通信的完整流程
ZYNQ与LWIP构建的8通道高速数据采集系统实战指南 在工业自动化、测试测量和科研领域,多通道高精度数据采集系统正变得越来越重要。本文将详细介绍如何利用Xilinx ZYNQ SoC和LWIP协议栈,构建一个支持8路ADS8681同步采集的实时数据传输系统。不同于简单的代…...

OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统
OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

深度集成AI的VSCode扩展:从代码生成到调试的全流程实战指南
1. 项目概述:一个为VSCode注入AI灵魂的扩展如果你和我一样,每天有超过8小时的时间是在Visual Studio Code(VSCode)里度过的,那么你一定对提升编码效率有着近乎偏执的追求。从代码补全、语法高亮到调试、版本控制&#…...

NCM格式转换实战指南:ncmdumpGUI全面解析
NCM格式转换实战指南:ncmdumpGUI全面解析 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾为网易云音乐下载的NCM格式音乐无法在其他设备播…...

Copaw_dev:AI编程助手增强框架,提升代码生成与自动化开发效率
1. 项目概述:Copaw_dev 是什么,以及它为何值得关注如果你是一名开发者,尤其是对自动化、代码生成或者AI辅助编程感兴趣,那么“Copaw_dev”这个项目标题很可能已经引起了你的注意。乍一看,这个由“G-Divine”维护的项目…...

Python自动化股票分析工具:从数据采集到可视化报告全流程实战
1. 项目概述:一个面向个人投资者的自动化股票分析工具如果你和我一样,是个对A股市场有点兴趣,但又没时间天天盯盘的上班族,那你肯定也经历过这种纠结:早上开盘前想看看心仪的几只股票有没有什么异动,结果一…...

跨平台鼠标控制库ez-cursor-free:原理、实现与自动化实战
1. 项目概述与核心价值如果你是一名开发者,尤其是经常需要处理跨平台UI自动化、游戏脚本或者桌面应用交互的开发者,那么你一定对“鼠标控制”这个基础但又充满细节的环节感到过头疼。不同的操作系统(Windows, macOS, Linux)提供了…...

移动端Shell集成AI助手:ShellGPTMobile部署与实战指南
1. 项目概述:当ShellGPT遇见移动端如果你是一个重度命令行用户,同时又对AI助手(比如ChatGPT)的便利性爱不释手,那么你很可能面临一个尴尬的境地:在终端里敲命令时,突然需要AI帮忙解释一段日志、…...