openGauss真的比PostgreSQL差了10年?
前不久写了MogDB针对PostgreSQL的兼容性文章,我在文中提到针对PostgreSQL而言,MogDB兼容性还是不错的,其中也给出了其中一个能源客户之前POC的迁移报告数据。
But很快我发现总有人回留言喷我,而且我发现每次喷的这帮人是根本不看文章内容的,完全就是看了标题就开喷,真是一喷为快!
针对如此多的后台留言,这里为提炼一下,同时我也来尝试“诡辩”一下!
MogDB是基于openGauss,而openGauss是基于PG9.2,现在PG都16了,最差了这么多代,你们还好意思说?
首先我要说下,针对是这个想法的这些有网友,你们真的看了文章内容吗?原生pg是多进程架构,而魔改之后的openGauss是线程架构,架构都不一样了呢,毫不夸张的说,基本上是完全不同的两款数据库产品了。
因此,就谈不上什么版本差了很多代的说法了呢。
那么如果说基于openGauss迭代的MogDB具具备了PG新版本所具有的一些功能,你们又该如何评价呢?
这里我就特意挑选几个小的点!
MogDB支持全局索引而PG不支持
记得前几天PG界的第一红网德哥就吐槽说,PG不支持全局索引。当时我看了之后,我心里一阵纳闷!
不支持全局索引的数据库,这tm的能用吗?这不搞笑的吗?
首先我给大家看下MogDB对于分区表的全局索引支持情况,废话不多说,直接上测试结果:
[omm2@mogdb1 ~]$ gsql -r -d test -U roger
Password for user roger:
gsql ((MogDB 5.0.7 build c4707384) compiled at 2024-05-24 10:51:53 commit 0 last mr 1804 )
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.
test=> CREATE TABLE list_list
test-> (
test(> month_code VARCHAR2 ( 30 ) NOT NULL ,
test(> dept_code VARCHAR2 ( 30 ) NOT NULL ,
test(> user_no VARCHAR2 ( 30 ) NOT NULL ,
test(> sales_amt int
test(> )
test-> PARTITION BY LIST (month_code) SUBPARTITION BY LIST (dept_code)
test-> (
test(> PARTITION p_201901 VALUES ( '201902' )
test(> (
test(> SUBPARTITION p_201901_a VALUES ( '1' ),
test(> SUBPARTITION p_201901_b VALUES ( '2' )
test(> ),
test(> PARTITION p_201902 VALUES ( '201903' )
test(> (
test(> SUBPARTITION p_201902_a VALUES ( '1' ),
test(> SUBPARTITION p_201902_b VALUES ( '2' )
test(> )
test(> );
CREATE TABLE
test=> insert into list_list values('201902', '1', '1', 1);
INSERT 0 1
test=> insert into list_list values('201902', '2', '1', 1);
INSERT 0 1
test=> insert into list_list values('201902', '1', '1', 1);
INSERT 0 1
test=> insert into list_list values('201903', '2', '1', 1);
INSERT 0 1
test=> insert into list_list values('201903', '1', '1', 1);
INSERT 0 1
test=> insert into list_list values('201903', '2', '1', 1);
INSERT 0 1
test=> create index idx_list_list on list_list(user_no) global;
CREATE INDEX
test=> explain select * from list_list where user_no=1;
QUERY PLAN
------------------------------------------------------------------------------
Partition Iterator (cost=0.00..14.57 rows=2 width=238)
Iterations: 2, Sub Iterations: 4
Selected Partitions: 1..2
Selected Subpartitions: 1:ALL, 2:ALL
-> Partitioned Seq Scan on list_list (cost=0.00..14.57 rows=2 width=238)
Filter: ((user_no)::bigint = 1)
(6 rows)
test=> \di+
List of relations
Schema | Name | Type | Owner | Table | Size | Storage | Description
--------+-------------------------+------------------------+-------+------------------+------------+---------+-------------
public | index_prune_tt01 | index | omm2 | prune_tt01 | 64 kB | |
public | table_1188398_2_pk | index | omm2 | table_1188398_2 | 16 kB | |
roger | idx_list_list | global partition index | roger | list_list | 16 kB | |
roger | idx_test01_objectid | index | roger | test01 | 245 MB | |
roger | idx_test01_owner | index | roger | test01 | 248 MB | |
roger | t2_pkey | index | roger | t2 | 8192 bytes | |
roger | test_incresort_1_id_idx | index | roger | test_incresort_1 | 301 MB | |
(7 rows)
大家可以看到这个分区的创建与法基本上跟Oracle一致,哪怕是二级分区,也支持创建global index的。
接下来我们看看PostgreSQL 13是否支持在分区表上创建Global Index。
postgres_5432@mogdb3 bin]$ ./psql
psql (13.2)
Type "help" for help.
postgres=# select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 13.2 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
(1 row)
postgres=# CREATE TABLE list_list
postgres-# (
postgres(# month_code VARCHAR2 ( 30 ) NOT NULL ,
postgres(# dept_code VARCHAR2 ( 30 ) NOT NULL ,
postgres(# user_no VARCHAR2 ( 30 ) NOT NULL ,
postgres(# sales_amt int
postgres(# )
postgres-# PARTITION BY LIST (month_code) SUBPARTITION BY LIST (dept_code)
postgres-# (
postgres(# PARTITION p_201901 VALUES ( '201902' )
postgres(# (
postgres(# SUBPARTITION p_201901_a VALUES ( '1' ),
postgres(# SUBPARTITION p_201901_b VALUES ( '2' )
postgres(# ),
postgres(# PARTITION p_201902 VALUES ( '201903' )
postgres(# (
postgres(# SUBPARTITION p_201902_a VALUES ( '1' ),
postgres(# SUBPARTITION p_201902_b VALUES ( '2' )
postgres(# )
postgres(# );
ERROR: syntax error at or near "SUBPARTITION"
LINE 8: PARTITION BY LIST (month_code) SUBPARTITION BY LIST (dept_c...
^
postgres=#
postgres=# CREATE TABLE measurement (
postgres(# city_id int not null,
postgres(# logdate date not null,
postgres(# peaktemp int,
postgres(# unitsales int
postgres(# ) PARTITION BY RANGE (logdate);
CREATE TABLE
postgres=#
postgres=#
postgres=# create table measurement_2022_1 partition of measurement
postgres-# for values from ('2022-01-01') to ('2022-02-01');
CREATE TABLE
postgres=#
postgres=# create table measurement_2022_2 partition of measurement
postgres-# for values from ('2022-02-01') to ('2022-03-01');
CREATE TABLE
postgres=#
postgres=# create table measurement_2022_3 partition of measurement
postgres-# for values from ('2022-03-01') to ('2022-04-01');
CREATE TABLE
postgres=#
postgres=# create index idx_measurement_date on measurement(logdate) global;
ERROR: syntax error at or near "global"
LINE 1: ...e index idx_measurement_date on measurement(logdate) global;
^
postgres=# create index idx_measurement_date on measurement(logdate);
CREATE INDEX
postgres=# insert into measurement(city_id,logdate,peaktemp,unitsales) values(1,'2022-01-01',1,1);
INSERT 0 1
postgres=# insert into measurement(city_id,logdate,peaktemp,unitsales) values(2,'2022-02-01',2,2);
INSERT 0 1
postgres=# insert into measurement(city_id,logdate,peaktemp,unitsales) values(3,'2022-03-01',3,3);
INSERT 0 1
postgres=# \di+
List of relations
Schema | Name | Type | Owner | Table | Persistence | Size | Description
--------+--------------------------------+-------------------+----------+--------------------+-------------+---------+-------------
public | idx_measurement_date | partitioned index | postgres | measurement | permanent | 0 bytes |
public | measurement_2022_1_logdate_idx | index | postgres | measurement_2022_1 | permanent | 16 kB |
public | measurement_2022_2_logdate_idx | index | postgres | measurement_2022_2 | permanent | 16 kB |
public | measurement_2022_3_logdate_idx | index | postgres | measurement_2022_3 | permanent | 16 kB |
(4 rows)
postgres=#
ostgres=# explain select * from measurement where logdate > '2022-02-01';
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Append (cost=8.93..59.46 rows=1234 width=16)
-> Bitmap Heap Scan on measurement_2022_2 measurement_1 (cost=8.93..26.65 rows=617 width=16)
Recheck Cond: (logdate > '2022-02-01'::date)
-> Bitmap Index Scan on measurement_2022_2_logdate_idx (cost=0.00..8.78 rows=617 width=0)
Index Cond: (logdate > '2022-02-01'::date)
-> Bitmap Heap Scan on measurement_2022_3 measurement_2 (cost=8.93..26.65 rows=617 width=16)
Recheck Cond: (logdate > '2022-02-01'::date)
-> Bitmap Index Scan on measurement_2022_3_logdate_idx (cost=0.00..8.78 rows=617 width=0)
Index Cond: (logdate > '2022-02-01'::date)
(9 rows)
Time: 0.792 ms
postgres=# select * from measurement where logdate > '2022-02-01';
city_id | logdate | peaktemp | unitsales
---------+------------+----------+-----------
3 | 2022-03-01 | 3 | 3
(1 row)
Time: 0.491 ms
这是什么鬼?实际上我们可以看到PG的分区创建方式是有所区别的,简单的讲,其子分区已经是一个独立的表了,独立的文件。
不过从原理上来讲,我认为没有全局索引,还是一定程度上会影响查询性能,虽然local index其实也足够用了。
这个给大家举个例子,记得2014年去给某头部快递公司做数据库优化时(用的是Oracle exdata),发现一个访问非常高频的大表上的索引创建就不合理。
可能之前DBA是为了维护方便,索引几乎都是清一色的local分区,然而后面发现SQL的逻辑读非常高,在双11来临之前改成global index之后,逻辑读降低了数倍。当然最后系统CPU也降低了很多。
PG16新增的几个json函数,MogDB已经支持了
第二小的点是Postsql16新增的几个json处理函数,实际上MogDB 早就支持了。
大家可以参考pg的官方文档:https://www.postgresql.org/docs/16/release-16.html
[omm2@mogdb1 bin]$ gsql -r
gsql ((MogDB 5.0.7 build c4707384) compiled at 2024-05-24 10:51:53 commit 0 last mr 1804 )
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.
MogDB=# \c dbm
Non-SSL connection (SSL connection is recommended when requiring high-security)
You are now connected to database "dbm" as user "omm2".
dbm=#
dbm=# select json_array(1,'a','b',true,null);
json_array
---------------------------
[1, "a", "b", true, null]
(1 row)
dbm=# CREATE TEMP TABLE foo1 (serial_num int, name text, type text);
CREATE TABLE
dbm=# INSERT INTO foo1 VALUES (847001,'t15','GE1043');
INSERT 0 1
dbm=# INSERT INTO foo1 VALUES (847002,'t16','GE1043');
INSERT 0 1
dbm=# INSERT INTO foo1 VALUES (847003,'sub-alpha','GESS90');
INSERT 0 1
dbm=# SELECT json_arrayagg(type) from foo1;
json_arrayagg
--------------------------------
["GE1043", "GE1043", "GESS90"]
(1 row)
dbm=# select json_object('{a,b,"a b c"}', '{a,1,1}');
json_object
---------------------------------------
{"a" : "a", "b" : "1", "a b c" : "1"}
(1 row)
dbm=# select serial_num,JSON_OBJECTAGG(name,type) from foo1 group by serial_num;
serial_num | json_objectagg
------------+-------------------------
847003 | {"sub-alpha": "GESS90"}
847001 | {"t15": "GE1043"}
847002 | {"t16": "GE1043"}
(3 rows)
dbm=#
上述提到的几个函数,实际上我在PG13.2上测试发现是不支持的。
[postgres_5432@mogdb3 bin]$ ./psql
psql (13.2)
Type "help" for help.
postgres=# select json_array(1,'a','b',true,null);
ERROR: function json_array(integer, unknown, unknown, boolean, unknown) does not exist
LINE 1: select json_array(1,'a','b',true,null);
^
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
postgres=#
postgres=#
postgres=# CREATE TEMP TABLE foo1 (serial_num int, name text, type text);
CREATE TABLE
postgres=# INSERT INTO foo1 VALUES (847001,'t15','GE1043');
INSERT 0 1
postgres=# INSERT INTO foo1 VALUES (847002,'t16','GE1043');
INSERT 0 1
postgres=# INSERT INTO foo1 VALUES (847003,'sub-alpha','GESS90');
INSERT 0 1
postgres=# SELECT json_arrayagg(type) from foo1;
ERROR: function json_arrayagg(text) does not exist
LINE 1: SELECT json_arrayagg(type) from foo1;
^
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
postgres=#
postgres=# select serial_num,JSON_OBJECTAGG(name,type) from foo1 group by serial_num;
ERROR: function json_objectagg(text, text) does not exist
LINE 1: select serial_num,JSON_OBJECTAGG(name,type) from foo1 group ...
^
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
postgres=#
MogDB 排序算法并不比PG主流版本差
另外我在看PG16的new feature时发现提到在优化器方面又有一些改进,其中一点就是对于增量排序(Allow incremental sorts in more cases, including DISTINCT (David Rowley)。
这里我想说的是,MogDB在这方面实际上也做了一些努力,在MogDB 3.1版本之前其实还是比较慢的。不相信? 好吧,给你看看同为openGauss系的友商数据库性能。
orcl=# \copy mogdb_incresort_1 from '/tmp/MogDB_incresort_1.dat';
Time: 45158.913 ms
orcl=# select count(1) from mogdb_incresort_1;
count
----------
10000000
(1 row)
Time: 3986.539 ms
orcl=# select players.pname,
orcl-# random() as lottery_number
orcl-# from (
orcl(# select distinct pname
orcl(# from MogDB_incresort_1
orcl(# group by pname
orcl(# order by pname
orcl(# ) as players
orcl-# order by players.pname,
orcl-# lottery_number
orcl-# limit 20;
pname | lottery_number
------------------+-------------------
player# 1 | .693211137317121
player# 10 | .373950335662812
player# 100 | .748802043031901
player# 1000 | .868999985512346
player# 10000 | .708094645757228
player# 100000 | .146068200934678
player# 1000000 | .400482173077762
player# 10000000 | .0748530034907162
player# 1000001 | .951222819741815
player# 1000002 | .0985643910244107
player# 1000003 | .673836125060916
player# 1000004 | .493436659686267
player# 1000005 | .744129443541169
player# 1000006 | .45777113456279
player# 1000007 | .90621894877404
player# 1000008 | .818961981683969
player# 1000009 | .91224535740912
player# 100001 | .955949443858117
player# 1000010 | .175989827606827
player# 1000011 | .0911367381922901
(20 rows)
Time: 33222.676 ms
orcl=# explain analyze
orcl-# select players.pname,
orcl-# random() as lottery_number
orcl-# from (
orcl(# select distinct pname
orcl(# from MogDB_incresort_1
orcl(# group by pname
orcl(# order by pname
orcl(# ) as players
orcl-# order by players.pname,
orcl-# lottery_number
orcl-# limit 20;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=5984227.96..5984228.01 rows=20 width=128) (actual time=37477.723..37477.728 rows=20 loops=1)
-> Sort (cost=5984227.96..6009228.03 rows=10000029 width=128) (actual time=37477.718..37477.719 rows=20 loops=1)
Sort Key: players.pname, (random())
Sort Method: top-N heapsort Memory: 30kB
-> Subquery Scan on players (cost=5518130.20..5718130.78 rows=10000029 width=128) (actual time=17705.988..34580.240 rows=10000000 loops=1)
-> Unique (cost=5518130.20..5593130.42 rows=10000029 width=128) (actual time=17705.951..26398.773 rows=10000000 loops=1)
-> Group (cost=5518130.20..5568130.35 rows=10000029 width=128) (actual time=17705.947..23714.165 rows=10000000 loops=1)
Group By Key: mogdb_incresort_1.pname
-> Sort (cost=5518130.20..5543130.28 rows=10000029 width=128) (actual time=17705.940..20369.481 rows=10000000 loops=1)
Sort Key: mogdb_incresort_1.pname
Sort Method: external merge Disk: 1350368kB
-> Seq Scan on mogdb_incresort_1 (cost=0.00..356411.29 rows=10000029 width=128) (actual time=0.020..2464.995 rows=10000000 loops=1)
Total runtime: 37478.118 ms
(13 rows)
Time: 37480.533 ms
是的,你没有看错,这个简单的测试SQL 居然跑了30多秒。
那么我们来看在MogDB5.0.7版本中跑一下需要多久呢?
test=# \copy mogdb_incresort_1 from '/tmp/MogDB_incresort_1.dat';
test=# \timing on
test=# explain analyze
test-# select players.pname,
test-# random() as lottery_number
test-# from (
test(# select distinct pname
test(# from MogDB_incresort_1
test(# group by pname
test(# order by pname
test(# ) as players
test-# order by players.pname,
test-# lottery_number
test-# limit 20;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=2174587.26..2174588.44 rows=20 width=64) (actual time=5315.519..5315.524 rows=20 loops=1)
-> Incremental Sort (cost=2174587.26..2763354.30 rows=9999951 width=64) (actual time=5315.517..5315.518 rows=20 loops=1)
Sort Key: players.pname, (random())
Presorted Key: players.pname
Full-sort Groups: 1 Sort Method: quicksort Average Memory: 28kB Peak Memory: 28kB
-> Subquery Scan on players (cost=2172256.79..2372255.81 rows=9999951 width=64) (actual time=5315.453..5315.487 rows=21 loops=1)
-> Unique (cost=2172256.79..2247256.43 rows=9999951 width=64) (actual time=5315.433..5315.452 rows=21 loops=1)
-> Group (cost=2172256.79..2222256.55 rows=9999951 width=64) (actual time=5315.425..5315.442 rows=21 loops=1)
Group By Key: mogdb_incresort_1.pname
-> Sort (cost=2172256.79..2197256.67 rows=9999951 width=64) (actual time=5315.420..5315.425 rows=21 loops=1)
Sort Key: mogdb_incresort_1.pname
Sort Method: external merge Disk: 665520kB
-> Seq Scan on mogdb_incresort_1 (cost=0.00..223456.51 rows=9999951 width=64) (actual time=0.012..1828.749 rows=10000000 loops=1)
Total runtime: 5449.456 ms
(14 rows)
Time: 5457.669 ms
test=# select players.pname,
test-# random() as lottery_number
test-# from (
test(# select distinct pname
test(# from MogDB_incresort_1
test(# group by pname
test(# order by pname
test(# ) as players
test-# order by players.pname,
test-# lottery_number
test-# limit 20;
pname | lottery_number
------------------+--------------------
player# 1 | 0.579584513325244
player# 10 | 0.836566388607025
player# 100 | 0.843441488686949
player# 1000 | 0.718995271716267
player# 10000 | 0.892783336341381
player# 100000 | 0.10398242296651
player# 1000000 | 0.308310507796705
player# 10000000 | 0.0168832587078214
player# 1000001 | 0.446922336239368
player# 1000002 | 0.0639159493148327
player# 1000003 | 0.313714498188347
player# 1000004 | 0.516515084076673
player# 1000005 | 0.702487968374044
player# 1000006 | 0.277854182291776
player# 1000007 | 0.934525999706239
player# 1000008 | 0.72923140367493
player# 1000009 | 0.321010332554579
player# 100001 | 0.651651729829609
player# 1000010 | 0.506305878516287
player# 1000011 | 0.46931520383805
(20 rows)
Time: 4521.001 ms
test=#
大家可以看到,其实也就不到5s的样子的。还是比较快的。
最后我们看下相同的SQL在PG13中运行效率如何。
postgres=# create table MogDB_incresort_1 (id int, pname name, match text);
CREATE TABLE
postgres=# create index on MogDB_incresort_1(id);
CREATE INDEX
postgres=# insert into MogDB_incresort_1
postgres-# values (
postgres(# generate_series(1, 10000000),
postgres(# 'player# ' || generate_series(1, 10000000),
postgres(# 'match# ' || generate_series(1, 11)
postgres(# );
INSERT 0 10000000
postgres=#
postgres=#
postgres=# select count(1) from MogDB_incresort_1;
count
----------
10000000
(1 row)
postgres=# vacuum analyze MogDB_incresort_1;
VACUUM
postgres=# \timing on
Timing is on.
postgres=# set max_parallel_workers_per_gather = 0;
SET
Time: 0.250 ms
postgres=# select players.pname,
postgres-# random() as lottery_number
postgres-# from (
postgres(# select distinct pname
postgres(# from MogDB_incresort_1
postgres(# group by pname
postgres(# order by pname
postgres(# ) as players
postgres-# order by players.pname,
postgres-# lottery_number
postgres-# limit 20;
pname | lottery_number
------------------+---------------------
player# 1 | 0.0447521551191592
player# 10 | 0.408278868270898
player# 100 | 0.7921926875019913
player# 1000 | 0.11271848207791635
player# 10000 | 0.2647472418342467
player# 100000 | 0.1412932234901234
player# 1000000 | 0.4266691727193681
player# 10000000 | 0.46474439957439273
player# 1000001 | 0.23216838816411567
player# 1000002 | 0.1229366164369452
player# 1000003 | 0.3386561272461357
player# 1000004 | 0.4146373941657302
player# 1000005 | 0.28414336215408653
player# 1000006 | 0.3686260468699629
player# 1000007 | 0.1296536218416513
player# 1000008 | 0.22829014039084683
player# 1000009 | 0.15364363544027881
player# 100001 | 0.08520628747068315
player# 1000010 | 0.697556601432435
player# 1000011 | 0.7879138632733813
(20 rows)
Time: 3637.823 ms (00:03.638)
postgres=# explain analyze
postgres-# select players.pname,
postgres-# random() as lottery_number
postgres-# from (
postgres(# select distinct pname
postgres(# from MogDB_incresort_1
postgres(# group by pname
postgres(# order by pname
postgres(# ) as players
postgres-# order by players.pname,
postgres-# lottery_number
postgres-# limit 20;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1765110.33..1765111.80 rows=20 width=72) (actual time=3759.205..3759.210 rows=20 loops=1)
-> Incremental Sort (cost=1765110.33..2498764.46 rows=10000017 width=72) (actual time=3759.203..3759.206 rows=20 loops=1)
Sort Key: players.pname, (random())
Presorted Key: players.pname
Full-sort Groups: 1 Sort Method: quicksort Average Memory: 27kB Peak Memory: 27kB
-> Subquery Scan on players (cost=1762114.60..1962114.94 rows=10000017 width=72) (actual time=3759.173..3759.192 rows=21 loops=1)
-> Unique (cost=1762114.60..1837114.73 rows=10000017 width=64) (actual time=3759.168..3759.184 rows=21 loops=1)
-> Group (cost=1762114.60..1812114.69 rows=10000017 width=64) (actual time=3759.167..3759.178 rows=21 loops=1)
Group Key: mogdb_incresort_1.pname
-> Sort (cost=1762114.60..1787114.64 rows=10000017 width=64) (actual time=3759.164..3759.169 rows=21 loops=1)
Sort Key: mogdb_incresort_1.pname
Sort Method: external merge Disk: 724152kB
-> Seq Scan on mogdb_incresort_1 (cost=0.00..223457.17 rows=10000017 width=64) (actual time=0.010..1315.358 rows=10000000 loops=1)
Planning Time: 0.095 ms
Execution Time: 3897.663 ms
(15 rows)
Time: 3898.239 ms (00:03.898)
postgres=#
我们可以看到实际上PG13版本也差不多需要4s左右。
而且细心一点的朋友还可以发现,其中的sort method部分,MogDB似乎看起来比pg13还要好一些。
后面我发现去年研发团队有同事分享过MogDB排序方面的知识,看pdf材料内容,其实应该是借鉴了PostgreSQL15的相关算法。

好了,言归正传!
基于如上三点!所以你们还会觉得MogDB比PG差几代么?
本文由 mdnice 多平台发布
相关文章:
openGauss真的比PostgreSQL差了10年?
前不久写了MogDB针对PostgreSQL的兼容性文章,我在文中提到针对PostgreSQL而言,MogDB兼容性还是不错的,其中也给出了其中一个能源客户之前POC的迁移报告数据。 But很快我发现总有人回留言喷我,而且我发现每次喷的这帮人是根本不看文…...

【国产开源可视化引擎Meta2d.js】快速上手
提示 初始化引擎后,会生成一个 meta2d 全局对象,可直接使用。 调用meta2d前,需要确保meta2d所在的父容器element元素位置大小已经渲染完成。如果样式或css(特别是css动画)没有初始化完成,可能会报错&…...

c#与倍福Plc通信
bcdedit /set hypervisorlaunchtype off...

【OceanBase诊断调优】—— 如何通过trace_id找到对应的执行节点IP
1. 前言 OceanBase作为分布式数据库,查问题找对节点很关键。好在OceanBase执行的每一条SQL都能通过trace_id来关联起来,知道trace_id怎么知道是在哪个节点发起的呢,请看本文。 2. trace_id生成规则 ob内部trace_id的生成函数如下࿰…...

鸿蒙开发Ability Kit(程序访问控制):【使用粘贴控件】
使用粘贴控件 粘贴控件是一种特殊的系统安全控件,它允许应用在用户的授权下无提示地读取剪贴板数据。 在应用集成粘贴控件后,用户点击该控件,应用读取剪贴板数据时不会弹窗提示。可以用于任何应用需要读取剪贴板的场景,避免弹窗…...

PL/SQL入门到实践
一、什么是PL/SQL PL/SQL是Procedural Language/Structured Query Language的缩写。PL/SQL是一种过程化编程语言,运行于服务器端的编程语言。PL/SQL是对SQL语言的扩展。PL/SQL结合了SQL语句和过程性编程语言的特性,可以用于编写存储过程、触发器、函数等…...

双非本 985 硕,我马上要入职上海AI实验室大模型算法岗
暑期实习基本结束了,校招即将开启。 不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。 最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑&…...

C盘清理和管理
本篇是C盘一些常用的管理方法,以及定期清理C盘的方法,大部分情况下都能避免C盘爆红。 C盘清理和管理 C盘存储管理查看存储情况清理存储存储感知清理临时文件清理不需要的 迁移存储 磁盘清理桌面存储管理应用存储管理浏览器微信 工具清理 C盘存储管理 查…...

晚上睡觉要不要关路由器?一语中的
前言 前几天小白去了一个朋友家,有朋友说:路由器不关机的话会影响睡眠吗? 这个影响睡眠嘛,确实是会的。毕竟一时冲浪一时爽,一直冲浪一直爽……刷剧刷抖音刷到根本停不下来,肯定影响睡眠。 所以晚上睡觉要…...

ardupilot开发 --- 坐标变换 篇
Good Morning, and in case I dont see you, good afternoon, good evening, and good night! 0. 一些概念1. 坐标系的旋转1.1 轴角法1.2 四元素1.3 基于欧拉角的旋转矩阵1.3.1 单轴旋转矩阵1.3.2 多轴旋转矩阵1.3.3 其他 2. 齐次变换矩阵3. visp实践 0. 一些概念 相关概念&am…...

git clone 别人项目后正确的修改和同步操作
简介 git clone主要是克隆别人的开源项目。但更高端的操作是实现本地修改的同时,能同步别人的在线修改,并且不相互干扰: 克隆原始项目:从远程仓库克隆项目到本地。添加上游仓库:将原始项目的远程仓库添加为上游仓库。…...
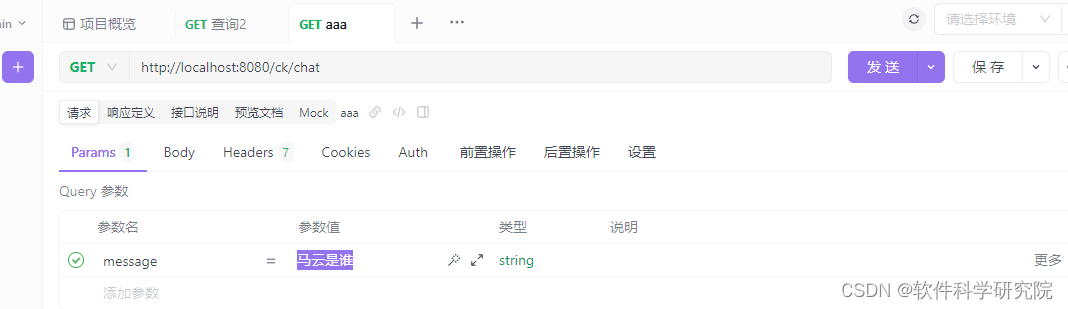
JAVA连接FastGPT实现流式请求SSE效果
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景! 一、先看效果 真正实流式请求,SSE效果,SSE解释&am…...

二分查找1
1. 二分查找(704) 题目描述: 算法原理: 暴力解法就是遍历数组来找到相应的元素,使用二分查找的解法就是每次在数组中选定一个元素来将数组划分为两部分,然后因为数组有序,所以通过大小关系舍弃…...
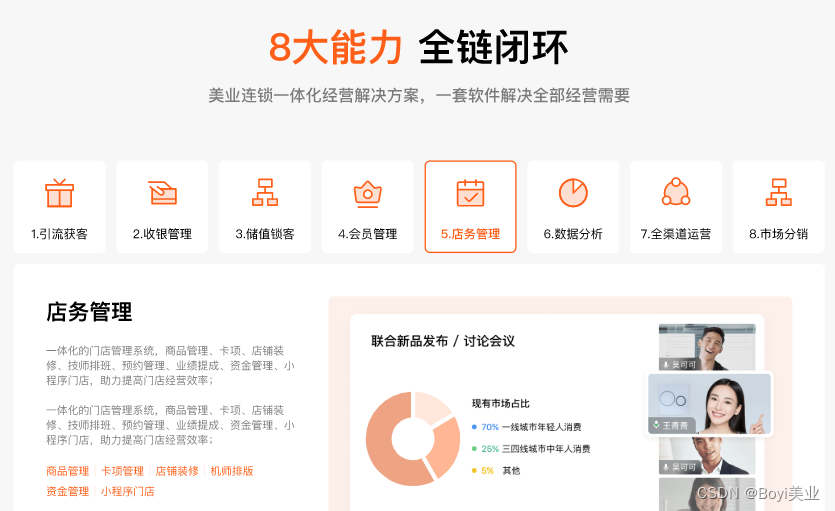
什么美业门店管理系统好用?2024美业收银系统软件排名分享
美业SAAS系统在美容、美发、美甲等行业中十分重要,这种系统为美业提供了一种数字化解决方案,帮助企业更高效地管理业务和客户关系。 美业门店管理系统通常提供预约管理、客户管理、库存管理、报表生成等一系列功能,以满足美容院、美发沙龙等…...

【文件上传】
文件上传漏洞 FileUpload 0x01 定义 服务端未对客户端上传文件进行严格的 验证和过滤造成可上传任意文件情况;0x02 攻击满足条件: 1. 上传文件能够被Web容器解释执行 2. 找到文件位置 3.上传文件未被改变内容。(躲避安全检查&#…...

Golang 单引号、双引号和反引号的概念、用法以及区别
在 Golang(Go 语言)中,单引号 ()、双引号 (") 和反引号 () 用于不同类型的字符串和字符表示。以下是它们的概念、用法和区别: 1. 单引号 () 概念 单引号用于表示 字符(rune 类型)。一个字符表示一个…...
linux和mysql基础指令
Linux中nano和vim读可以打开记事文件。 ifdown ens33 ifup ens33 关闭,开启网络 rm -r lesson1 gcc -o code1 code1.c 编译c语言代码 ./code1 执行c语言代码 rm -r dir 删除文件夹 mysql> show databases-> ^C mysql> show databases; -------…...

JDK 为什么需要配置环境变量
前言 首先,我们要知道 Java 程序的执行过程。首先将 xxx.java 文件(使用 javac 编译指令)编译成 xxx.class 文件(字节码文件),再将字节码文件(使用 java 执行指令)解释成电脑所能认识…...
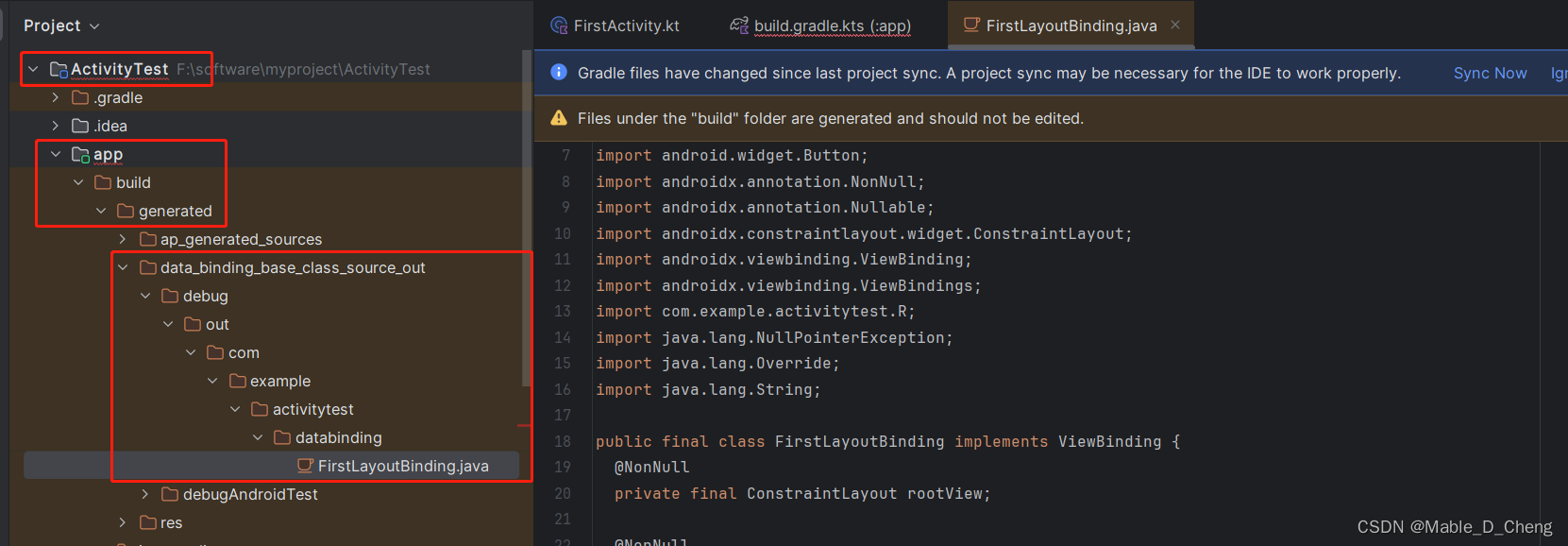
ViewBinding的使用(因为kotlin-android-extensions插件的淘汰)
书籍: 《第一行代码 Android》第三版 开发环境: Android Studio Jellyfish | 2023.3.1 问题: 3.2.4在Activity中使用Toast章节中使用到了kotlin-android-extensions插件,但是该插件已经淘汰,根据网上了解,目前使用了新的技术VewBinding替…...

IOS Swift 从入门到精通:ios 连接数据库 安装 Firebase 和 Firestore
创建 Firebase 项目 导航到Firebase 控制台并创建一个新项目。为项目指定任意名称。 在这里插入图片描述 下一步,启用 Google Analytics,因为我们稍后会用到它来发送推送通知。 在这里插入图片描述 在下一个屏幕上,选择您的 Google Analytics 帐户(如果已创建)。如果没…...

收藏!小白程序员必看:如何用Tair构建秒级响应的AI Agent记忆系统?
本文以淘宝闪购AI Agent项目为例,阐述了AI Agent对高性能记忆层的迫切需求。文章深入分析了Tair在数据模型设计(List、Hash)、压缩策略与并发控制方面的关键实践,并探讨了Tair如何通过多线程内核、读写分离、弹性扩缩容及带宽管理…...
)
FinOps还在人工对账?AISMM已实现毫秒级资源-成本-业务价值映射(2026奇点大会实时沙箱演示实录)
更多请点击: https://intelliparadigm.com 第一章:2026奇点智能技术大会:AISMM与FinOps 2026奇点智能技术大会首次将人工智能系统成熟度模型(AISMM)与云原生财务运营(FinOps)深度耦合ÿ…...

为内部工具集成 Claude Code 并配置 Taotoken 作为后端
为内部工具集成 Claude Code 并配置 Taotoken 作为后端 在企业内部开发流程中,集成智能编程助手能有效提升代码编写与审查的效率。Claude Code 作为一款基于 Anthropic 模型的编程工具,因其对代码逻辑的深度理解能力,常被团队选为辅助开发的…...

MBTI性格魔方:无代码H5交互测试平台
一、开发原因职场社交场景中,MBTI已成为新型沟通货币。2026年职场调研显示,73%的团队建设活动包含性格测试环节,但现有工具存在三大痛点:专业测试收费高昂、简易测试缺乏深度、结果呈现形式单一。本项目通过无代码方式,…...

golang如何实现表单验证_golang表单验证实现方法
用 validator 包校验结构体最省心,需导出字段、正确打标签、调用 Validate() 并处理 error;HTTP 请求解析后立即校验,避免空格等边界问题,配合 Translations 实现多语言错误提示。用 validator 包做结构体字段校验最省心Go 没有内…...

3个简单步骤:使用OpenCore Legacy Patcher让旧Mac免费升级最新macOS
3个简单步骤:使用OpenCore Legacy Patcher让旧Mac免费升级最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台性能尚可但已被A…...
)
应对2026海外新规:留学生英文论文降AI避坑指南(附4款实测工具)
不知道各位小伙伴发现没有,处理英文文章这件事要比处理中文难很多。之前我自己的英文摘要写好后满心欢喜去跑检测,结果你猜怎么着?手打的摘要部分AI率居然高达85%......我折腾了两三天时间,查了各种资料,这才算真正搞懂…...

蓝桥杯C/C++真题刷题攻略:从“猜生日”到“蛇形填数”,这5类题最容易拿分
蓝桥杯C/C竞赛五大高频题型深度解析与实战技巧 参加蓝桥杯竞赛的C/C选手们常常面临一个共同难题:如何在有限时间内快速识别题目类型并找到最优解法?根据多年竞赛辅导经验,我总结出五类出现频率最高、最容易拿分的题型,它们分别是日…...

在Hermes Agent项目中自定义Provider接入Taotoken聚合服务
在Hermes Agent项目中自定义Provider接入Taotoken聚合服务 对于使用Hermes Agent框架的开发者而言,灵活地接入不同的模型服务提供商是构建高效AI应用的关键。Taotoken作为大模型聚合分发平台,提供了与OpenAI兼容的HTTP API,可以方便地集成到…...

极简信息聚合器Nas4146/brief:用Python+Docker打造你的私人简报机器人
1. 项目概述:一个为“懒人”设计的极简信息聚合器最近在折腾个人知识管理和信息流优化时,我遇到了一个几乎所有内容创作者和重度信息消费者都会头疼的问题:信息过载与碎片化。每天,我需要关注十几个不同平台的更新——技术博客、行…...