【深入理解C指针】经典笔试题——指针和数组

🔹内容专栏:【C语言】进阶部分
🔹本文概括:一些指针和数组笔试题的解析 。
🔹本文作者:花香碟自来_
🔹发布时间:2023.3.12
目录
一、指针和数组练习题
1. 一维数组
2. 字符数组
3. 二维数组
二、 指针笔试题
1. 第一题
2. 第二题
3. 第三题
4. 第四题
5. 第五题
6. 第六题
7. 第七题
8. 第八题
一、指针和数组练习题
首先我们在练习此方面的题目前,回顾一下相关概念。
数组和指针
数组:能够存放一组相同类型的元素,数组的大小取决于数组的元素个数和元素类型。
指针:地址or指针变量,指针的大小为4/8个字节(由CPU的寻址位数决定)
数组是数组,指针是指针,二者不等价。
数组名是数组首元素的地址,这个地址可以存放到指针变量当中。
可以根据指针来遍历数组的操作。
数组名:大部分情况下表示的是数组首元素的地址。
但是除了以下两个例外:
sizeof(数组名) ,此时的数组名表示的是整个数组,且单独存放在sizeof( )内部,计算的是整个数组大小;
&数组名,此时的数组名表示的是整个数组,取出的就是数组的地址。
sizeof与strlen
1.sizeof计算的是占用内存空间的大小,单位是字节,不会关注内存中到底存放的是什么;
2.sizeof不是函数,而是操作符;
3.strlen是函数;
4.strlen是针对字符串的,求的是字符串的长度,本质上统计的是'\0'之前出现的字符的个数。
1. 一维数组
//一维数组
#include<stdio.h>
int main()
{int a[] = {1,2,3,4};printf("%d\n",sizeof(a));//1printf("%d\n",sizeof(a+0));//2printf("%d\n",sizeof(*a));//3printf("%d\n",sizeof(a+1));//4printf("%d\n",sizeof(a[1]));//5printf("%d\n",sizeof(&a));//6printf("%d\n",sizeof(*&a));//7printf("%d\n",sizeof(&a+1));//8printf("%d\n",sizeof(&a[0]));//9printf("%d\n",sizeof(&a[0]+1));//10return 0;
}分析:
//1: 数组名单独放在sizeof()内部,计算的是数组总大小,单位是字节。16
//2: 此时的a并没有单独存放在sizeof()内部,a+0计算的就是数组首元素的地址,地址的大小是4/8个字节。
//3:此时的a没有单独存放在sizeof()内部,a表示数组首元素的地址(&a[0]),*a 就等价于*&a[0],等价于a[0],计算的是第一个元素类型的大小,结果是4
//4: a是数组首元素的地址,类型是int*,a + 1就是跳过一个整型的大小,得到的是第二个元素的地址,计算的就是第二个元素地址的大小,结果就是4/8字节
//5:a[1] 等价于 *(a + 1),计算的就是第二个元素的大小,结果是4
//6:&a表示的是取出整个数组的地址,结果计算的就是整个数组地址的大小,结果是4/8个字节
//7:(1)&a表示的是整个数组的地址,*星号解引用,拿到的就是整个数组, *&a == a,sizeof(a)计算的就是整个数组的大小,结果是16
(2)也可以看做是&a 放在一个指针中,这个指针的类型就是 int (*) [4],*解引用, 访问的就是一个数组的大小,数组有4个元素,每个元素是int类型,结果就是4 * 4 为16
//8:&a 表示的是整个数组的地址,类型是 int (*)[4] ,&a + 1跳过的就是一个数组的大小,
结果是4/8个字节
//9:a[0] 等价于*(a + 0),表示的就是第一个元素,&a[0]就是第一个元素的地址, 结果就是4/8个字节
//10:&a[0] + 1 ,即第一个元素的地址 + 1,得到的是第二个元素的地址,结果是4/8个字节
2. 字符数组
#include<stdio.h>
int main()
{char arr[] = {'a','b','c','d','e','f'};printf("%d\n", sizeof(arr)); //1printf("%d\n", sizeof(arr+0));//2printf("%d\n", sizeof(*arr));//3printf("%d\n", sizeof(arr[1]));//4printf("%d\n", sizeof(&arr));//5printf("%d\n", sizeof(&arr+1));//6printf("%d\n", sizeof(&arr[0]+1));//7printf("%d\n", strlen(arr));//8printf("%d\n", strlen(arr+0));//9printf("%d\n", strlen(*arr));//10printf("%d\n", strlen(arr[1]));//11printf("%d\n", strlen(&arr));//12printf("%d\n", strlen(&arr+1));//13printf("%d\n", strlen(&arr[0]+1));//14return 0;
}//10 访问时冲突:

分析:
//1: arr数组名单独存放在sizeof()内部,计算的是整个数组的大小,故结果是6
//2: arr + 0 是数组首元素的地址,计算的是地址的大小,结果是4/8个字节。
//3: *arr,表示的是对数组首元素的地址进行解引用,拿到的就是首元素,计算的是数组首元素的大小,结果是1
//4: arr[1],等价于*(arr + 1),对数组第二个元素的地址解引用,拿到第二个元素,计算的就是第二个元素的大小,结果是1
//5: &arr 表示的就是整个数组的地址,结果是4/8个字节
//6: &arr + 1 表示跳过一个数组的大小,但还是地址,结果还是4/8个字节
//7: &arr[0]表示的就是数组首元素的地址,&arr[0] + 1 跳过一个char类型的大小,结果还是4/8个字节。
//8: 此处的数组名代表的是数组首元素的地址,计算字符串长度,所以需要寻找'\0'的位置,但是我们不确定'\0'会出现在哪个位置,故而我们认为结果是个随机值。
//9: arr + 0,还是表示的是数组首元素的地址,结果同上,依旧是一个随机值。
//10: 这里的arr表示的就是数组首元素的地址,*arr拿到的是'a',但是传入strlen()的参数必须是一个指针,而这里的'a',实际把a的ASCII码值转换为指针的形式,然后访问,但是这个地址并不是“自己”的,所以形成了非法访问的情况。(观察上方图片,0x00000061就是97,即'a'的ASCII码值。)
//11:arr[1]表示的是数组的第二元素,传入strlen,会将'b'(98)当成地址,也会形成非法访问
//12: &arr表示取出整个数组的地址,数组的起始地址仍然指向'a',向后寻找'\0',所以还是一个随机值
//13:&arr + 1跳过了一个数组的大小,仍然向后寻找'\0',直到找到'\0'结束,但它与前一条(//12)相比,会少数6次,故可以认为是随机值 - 6
//14:&arr[0] + 1是第二个元素的地址,即从指向'b'的位置开始向后数,可以认为是随机值 - 1
#inlude<stdio.h>
int main()
{char arr[] = "abcdef";printf("%d\n", sizeof(arr));//1printf("%d\n", sizeof(arr+0));//2printf("%d\n", sizeof(*arr));//3printf("%d\n", sizeof(arr[1]));//4printf("%d\n", sizeof(&arr));//5printf("%d\n", sizeof(&arr+1));//6printf("%d\n", sizeof(&arr[0]+1));//7printf("%d\n", strlen(arr));//8printf("%d\n", strlen(arr+0));//9printf("%d\n", strlen(*arr));//10printf("%d\n", strlen(arr[1]));//11printf("%d\n", strlen(&arr));//12printf("%d\n", strlen(&arr+1));//13printf("%d\n", strlen(&arr[0]+1))//14return 0;
}//12会发生警告

分析:
//1:数组名单独存放在sizeof()内部,计算的是整个数组的大小,结果是7
//2: sizeof(arr + 0)计算的是数组首元素地址的大小,结果是4/8个字节
//3: arr表示的是数组首元素的地址,*arr拿到的是数组首元素,故结果计算的是数组首元素的大小,结果是1
//4: 表示的数组第二个元素的大小,结果是1
//5: &arr表示的是整个数组地址,计算的是整个数组地址的大小,结果是4/8个字节
//6: &arr表示数组的地址,+ 1跳过了一个数组的大小,结果是4/8个字节//7: &arr[0]数组首元素的地址 + 1,跳过一个char类型的大小,表示第二个元素的地址,结果是4/8个字节
//8: arr表示首元素的地址,依次往后寻找,直到找到'\0'为止结束,结果是6
//9: arr + 0 表示的也是数组首元素的地址,依次往后寻找,直到找到'\0'为止结束,结果为6
//10: *arr表示拿到的是数组首元素,即将'a'传进strlen函数了,会造成非法访问
//11: 也会造成非法访问
//12: &arr拿到的数组的地址,起始地址指向'a', 向后寻找'\0',故结果为6
强调一下:这里的传址发生警告,因为&arr,放到一个指针里面去,它的类型应该是一个数组指针,为char (*)[7],但是strlen()函数的形式参数为const char * 来接收,如上图显示,会显示 “const char *”与“char (*) [7]”的间接级别不同,但是不会影响使用。
//13: &arr + 1 跳过了一个数组的大小,往后寻找'\0',直到找到'\0'为止结束,但这里我们并不知道'\0'的位置,所以结果是随机值
//14: &arr[0] + 1,指向的就是第二个元素的地址,往后寻找'\0',直到找到'\0'为止结束,结果是5
#inlcude<stdio.h>
int main()
{char *p = "abcdef";printf("%d\n", sizeof(p));//1printf("%d\n", sizeof(p+1));//2printf("%d\n", sizeof(*p));//3printf("%d\n", sizeof(p[0]));//4printf("%d\n", sizeof(&p));//5printf("%d\n", sizeof(&p+1));//6printf("%d\n", sizeof(&p[0]+1));//7printf("%d\n", strlen(p));//8printf("%d\n", strlen(p+1));//9printf("%d\n", strlen(*p));//10printf("%d\n", strlen(p[0]));//11printf("%d\n", strlen(&p));//12printf("%d\n", strlen(&p+1));//13printf("%d\n", strlen(&p[0]+1));//14return 0;
}

分析:
//1:这里的p是一个指针变量,指向了字符串首元素的地址,即'a'的地址,所以计算它的大小为4/8个字节
//2: p + 1指向了'b'的地址,所以计算它的大小为4/8个字节
//3: *p,即对'a'解引用操作,计算的大小就一个char 类型的大小,结果为1
//4: p[0] 等价于*(p + 0),(可以把字符串想象成一个数组,为内存连续存放的空间),即'a',结果为1
//5: &p,对指针变量p进行取地址操作,是一个一级指针的地址,为一个二级指针,但还是指针,所以大小为4/8个字节
//6: &p + 1,跳过一个char* 类型的数据,结果为4/8个字节
//7: &p[0] + 1,指向了'b'的地址,所以计算它的大小为4/8个字节
//8: 从'a'的地址开始,向后数,直到找到'\0'为止结束,结果为6
//9: p + 1 指向了'b'的地址,向后数,直到找到'\0'为止结束,结果为5
//10: 把'a'的ascii码值当成了地址,会形成非法访问
//11: p[0]等价于*(p + 0),和*p一样,同样会造成非法访问
//12:&p是从指针变量p向后数,直到找到'\0'为止结束,结果为随机值
//13: &p + 1跳过一个char * 类型的指针,向后数,结果也为一个随机值,但是与第十二条的随机值没有关系。(因为不确定 //12 中指针变量p中的4/8个字节空间中是否存在'\0')
//14: &a[0]为首元素的地址,+ 1跳过一个char 类型的大小,指向了元素'b',所以计算的结果是5
3. 二维数组
#include<stdio.h>
int main()
{int a[3][4] = {0};printf("%d\n",sizeof(a));//1printf("%d\n",sizeof(a[0][0]));//2printf("%d\n",sizeof(a[0]));//3printf("%d\n",sizeof(a[0]+1));//4printf("%d\n",sizeof(*(a[0]+1)));//5printf("%d\n",sizeof(a+1));//6printf("%d\n",sizeof(*(a+1)));//7printf("%d\n",sizeof(&a[0]+1));//8printf("%d\n",sizeof(*(&a[0]+1)));//9printf("%d\n",sizeof(*a));//10printf("%d\n",sizeof(a[3]));//11printf("%d\n",sizeof(*a + 1));//12return 0;
}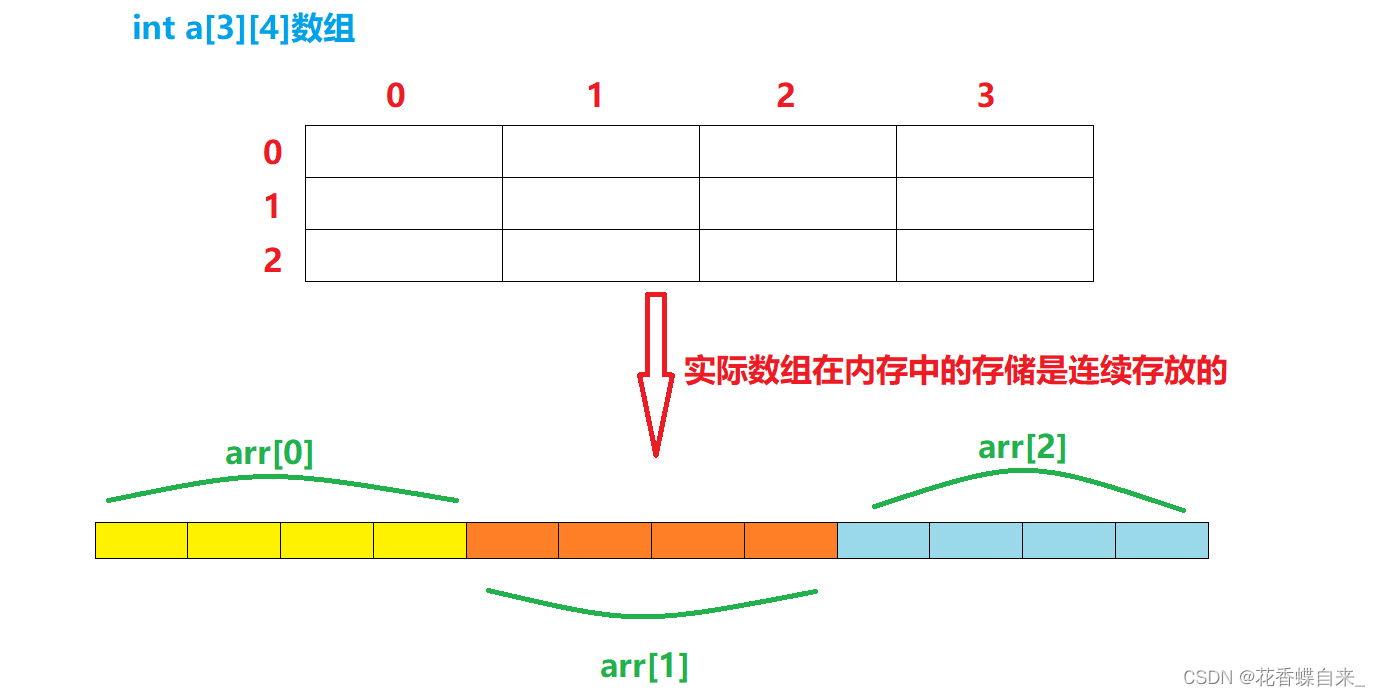
分析:
//1: 二维数组名单独存放在sizeof内部,计算的是整个二维数组大小,结果是48
//2: a[0][0]即第一行第一个元素,计算的大小是4
//3: a[0]是数组第一行的数组名,这里的数组名单独存放在sizeof()内部,计算的是第一行数组的大小,结果是16
//4: a[0]不是单独存放在sizeof()内部,a[0]表示的是首元素的地址,即第一行第一个元素的地址,相当于&a[0][0],a[0] + 1就是第一行第二个元素的地址,相当于&a[0][1],计算的大小是4/8个字节
//5: *(a[0] + 1)是对第一行第二个元素的地址解引用操作,即a[0][1],计算的大小就是4
//6: a表示二维数组名,为二维数组首元素的地址,二维数组的首元素是第一行,即第一行(第一个一维数组)的地址,类型是int (*) [4],a + 1跳过第一行,指向了第二行(第二个一维数组),即第二行的地址,等价于&a[1],那么计算的结果是4/8个字节
//7:(1)对第二行的地址解引用操作。指向第二行的指针变量的大小是 int * [4],解引用访问了一个数组的大小,数组有4个元素,一个元素占4个字节,计算的总大小是16
(2)*(a + 1)可以看作是a[1],a[1]是第二行的数组名,单独放在sizeof()内部,计算的是第二行的大小,结果是16
//8: &a[0] 是第一行的地址,&a[0] + 1就是第二行的地址,结果是4/8个字节//9: &a[0] + 1是第二行的地址,*(&a[0] + 1)计算的就是第二行的大小,等价于sizeof(a[1]),结果就是16
//10: (1) a表示数组首元素的地址,即第一行的地址,*a访问的是第一行,sizeof(*a)计算的就是第一行的大小,结果是16
(2)*a == *(a + 0)== a[0],将a[0]放在sizeof()内部,计算的也是第一行的大小,结果是16
//11: 这里的a[3]会出现越界访问吗? 结果并不会,因为sizeof这个操作符在程序编译期间就完成了操作,并不会对内部表达式进行计算,所以不会造成越界访问,编译器根据类型属性,就知道了a[3]其实和a[1]、a[2]的大小一样,都是int [4],结果就是16
//12: *a,a表示的是二维数组的数组名,数组名表示的是首元素的地址,即第一行的地址,*a得到的就是第一行,即a[0];a[0] + 1,a[0]是第一行的数组名,表示的是首元素的地址,即第一行第一个元素的地址,可以看作为&a[0][0],a[0] + 1,得到就是第一行第二个元素的地址,计算得到的结果就是4/8个字节
二、 指针笔试题
学会画图分析以下各题,更加容易让我们理解其代码的逻辑。所以画图是必不可少的!
1. 第一题
#include <stdio.h>
int main()
{int a[5] = { 1, 2, 3, 4, 5 };int *ptr = (int *)(&a + 1);printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
分析:
&a拿到整个数组的地址,类型是int * [5],&a + 1就跳过了5个int元素的大小,强制类型转换为int *,ptr - 1就指向了5,解引用操作打印5,*(a + 1),是数组首元素地址 + 1,解引用打印2
2. 第二题
//以下结构体的大小是20个字节
struct Test
{int Num;char *pcName;short sDate;char cha[2];short sBa[4];
}* p;
//假设p 的值为0x100000。 如下表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20个字节
#include <stdio.h>
int main()
{p = (struct Test*)0x100000;printf("%p\n", p + 0x1);//1printf("%p\n", (unsigned long)p + 0x1);//2printf("%p\n", (unsigned int*)p + 0x1);//3return 0;
}分析:
0x1 的意思是将十进制的1转换为了十六进制表示法。
//1: p此时是一个结构体,p + 1跳过了一个结构体的大小,跳过20个字节,即0x100020,而地址需要按十六进制打印需要打印八位,高位会补0,所以打印得到00100020
//2: 将p这个指针类型强制转换为 unsigned long 类型,即一个整型(int),那么 + 1,此时加的就是一个数字1,即0x100001
//3: 将p这个指针类型强制转换为 unsigned int*类型,+ 1跳过一个int*类型的指针,即0x100004
3. 第三题
#include<stdio.h>
int main()
{int a[4] = { 1, 2, 3, 4 };int *ptr1 = (int *)(&a + 1);//1int *ptr2 = (int *)((int)a + 1);//2printf( "%x,%x", ptr1[-1], *ptr2);//3return 0;
}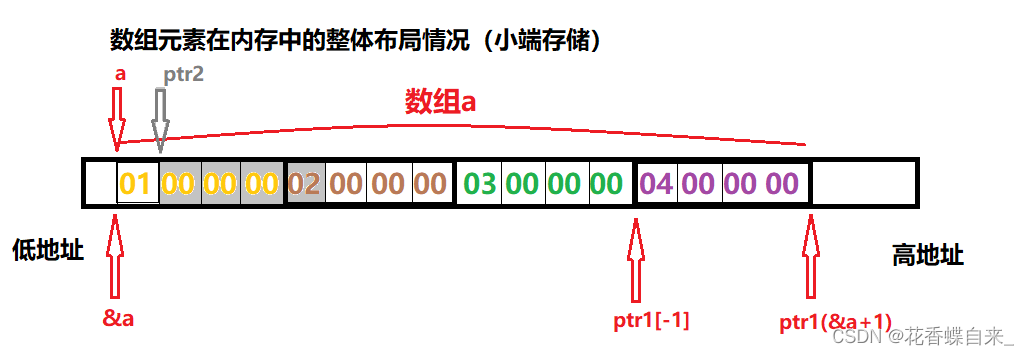
分析:
//1: 这里的&a拿到的就是整个数组的地址,&a + 1就跳过了一个数组,本来是int * [4]这个类型,强制类型转换成了int * ,ptr1 此时就成了一个int * 类型的指针。
//2: 这里的a是数组名,强制类型转换为整型(int),+ 1,就是加上数值1,也就是一个字节,假设a的地址是0x0012ff40,那么(int)a + 1得到的结果就是0x0012ff41,再次强制类型转换为(int *),放到整型指针ptr2之中,ptr2此时指向了内存中第二个字节的位置。
//3: (1) %x表示是用16进制进行打印输出,ptr1[-1]可以看作为*(ptr1 - 1),即指针ptr1向前跳转一个整型的大小,解引用操作,访问的就是04 00 00 00,打印出来就是4;
(2)ptr2指向了第一个元素的第二个字节处,解引用操作,访问四个字节的大小,且数组在内存中是连续存储的,如图中,灰色底纹部分就是访问的全部空间,即02 00 00 00,将其%x打印就是2000000
4. 第四题
#include <stdio.h>
int main()
{int a[3][2] = { (0, 1), (2, 3), (4, 5) };int *p;p = a[0];printf( "%d", p[0]);
return 0;
}老铁们,乍一看上去是不是觉得就是0了呢?哈哈哈,认为是0的老铁就踩上坑了咯~
为什么呢?下面就对题进行分析吧~
分析:
观察int a[3][2]这个数组在初始化的时候,写成了 { (0, 1), (2, 3), (4, 5) }; ,而不是{ {0,1} ,{2,3}, {4,5} };,注意里面写的是括号表达式,而不是以{ }的形式表示,括号表达式的运算法则是,里面的表达式从左向右计算,最后一个表达式的结果为整个逗号表达式的结果,所以数组初始化元素应该是{1,3,5}; ,其余部分元素均为0
a[0]即第一行的数组名,数组名是数组首元素的地址,即元素1的地址,存放到指针变量p当中去,p[0]就是*(p + 0),即对p进行解引用操作,拿到的就是1,所以结果打印1
5. 第五题
#include<stdio.h>
int main()
{int a[5][5];int(*p)[4];p = a;//1printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);//2
return 0;
}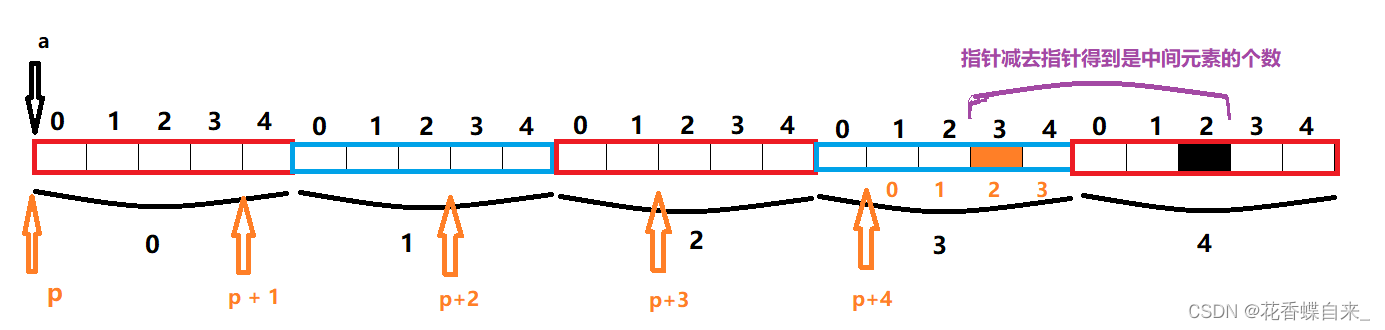
分析:
//1: p = a,这里的a就是数组首元素的地址,即第一行的地址,类型是int (*) [5],但是p的类型是int (*) [4],类型不同会造成什么影响吗?其实不会,就比如 int a = 10,char b =20,a = b,这样最后a的结果虽然是20,但是类型还是int类型。所以我们只是把a的地址值赋值给了b
//2: 观察上方画图,可以清晰地知道p指针在数组中的指向位置,p[4][2]即橙黄色方块的位置,&p[4][2] 指向的就是橙黄色方块,a[4][2]即黑色方块,&a[4][2]指向的就是黑色方块,前者与后者都是指针,前者减去后者得到就是中间元素个数,%d结果为 -4,%p的结果打印的是地址,于是会将内存中的补码转换为十六进制数就是地址了,结果是FF FF FF FC

6. 第六题
#include<stdio.h>
int main()
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int *ptr1 = (int *)(&aa + 1);//1int *ptr2 = (int *)(*(aa + 1));//2printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1)); return 0;
}
分析:
//1:&aa拿到整个二维数组的地址,&aa + 1跳过一个二维数组的大小, 强制类型转换成int *类型,ptr1此时也指向了这个位置。*(ptr1 - 1)打印9
//2:aa是数组名,表示数组首元素的地址,即第一行的地址,类型是int (*) [5] ,+1跳过了一个int [5]的大小,指向了第二行,类型也是int (*) [5],*解引用操作,拿到了第二行,强制类型转换为int *,此时ptr2也指向了6,*(ptr2 - 1)打印5
7. 第七题
#include <stdio.h>
int main()
{char *a[] = {"work","at","alibaba"};char**pa = a;pa++;printf("%s\n", *pa);
return 0;
}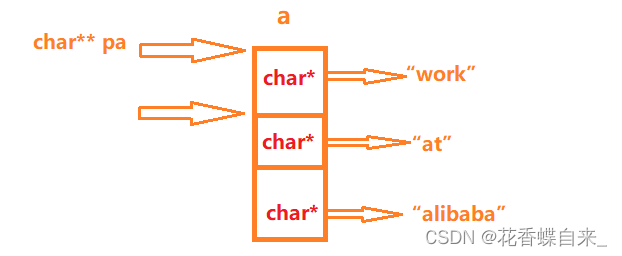
分析:
这里给出了一个名为a的指针数组,每个数组的类型是char*类型,实际存放的并不是"work","at","alibaba",其实是字符串首元素的地址,第一个char*指向了'w'的地址,第二个char*指向了'a'的地址,第三个char*指向了'a'的地址;数组名a是数组首元素的地址,char*的地址为char**类型,存放到pa这个二级指针中,pa++就跳过了一个char*的类型,*pa就拿到了数组第二个元素,即'a'的地址,%s打印出at
8. 第八题
#include <stdio.h>
int main()
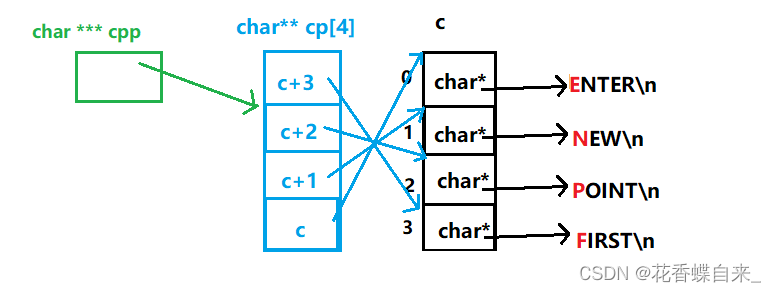
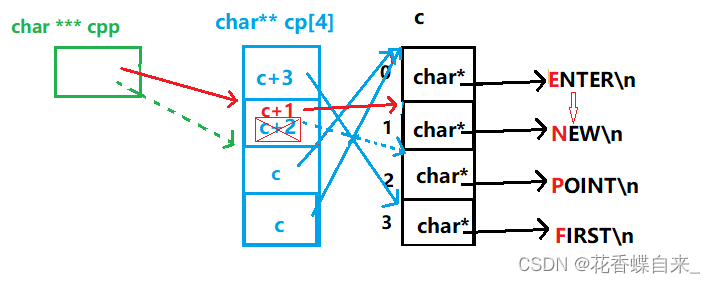
{char *c[] = {"ENTER","NEW","POINT","FIRST"};char**cp[] = {c + 3,c + 2,c + 1,c};char***cpp = cp;printf("%s\n", **++cpp);//1printf("%s\n", *-- * ++cpp + 3);//2printf("%s\n", *cpp[-2] + 3);//3printf("%s\n", cpp[-1][-1] + 1);//4return 0;
}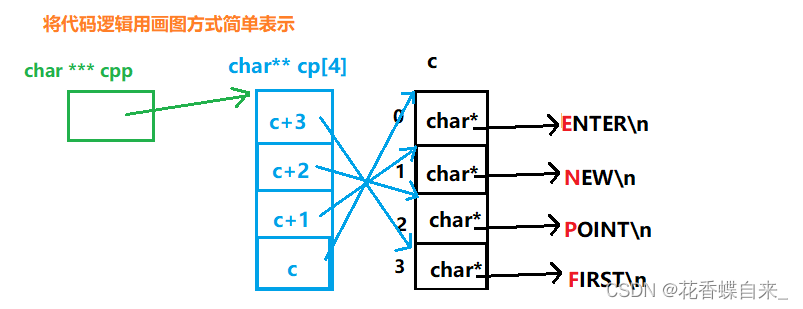
分析:
//代码的整体逻辑如上图先分析出来了。
//1: **++cpp,首先程序会执行++cpp操作,cpp会跳过一个char**的类型,此时就指向了c+2,而*一次解引用操作,我们拿到了c+2的这块空间里面的数据,即c+2,而c+2又是c数组下标为2的元素空间的地址,对其进行*解引用操作,就拿到了c数组下标为2的空间,这块空间存放了‘P’的地址,%s就会根据P的地址向后打印字符串,打印的结果就是POINT
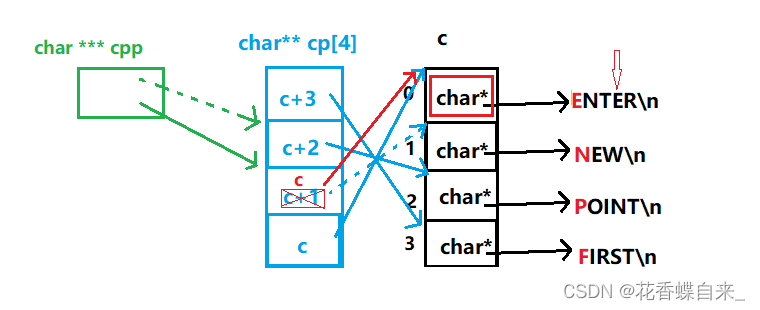
//2: *-- * ++cpp + 3,乍一看,有这么多的操作符,其实按优先级来算,还是先从++cpp开始计算,此时的cpp不再指向c+2,而是指向了c+1,然后进行*解引用操作,就拿到了c+1这块空间里面的数据,--操作,相当于c+1减去1,那么这块空间的数据就是c了,此时指向关系就再是原来的指向关系了,而是指向了c数组的第一个元素,解引用操作就拿到了数组c的第一个元素,即'E'的地址,最后+3,此时指针指向第二个'E',%s就会根据此时的地址向后打印字符串,结果打印就是ER
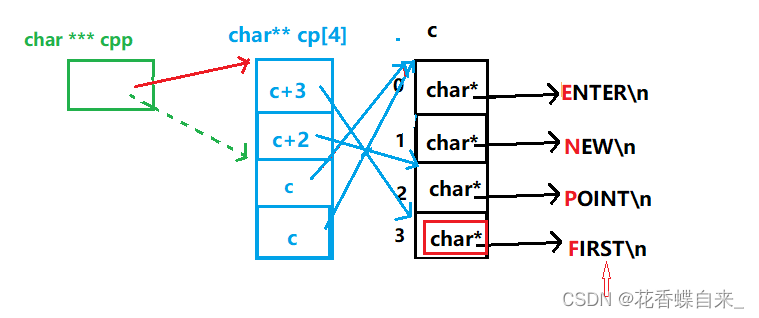
//3: *cpp[-2] + 3 ,cpp[-2]可以看作是*(cpp - 2),即 **(cpp - 2)+ 3 ,cpp - 2指向了cp数组的第一个元素的空间,*解引用操作,拿到了c+3这块空间,这块空间指向了c数组的下标为3的元素空间,解引用操作,拿到了这块空间,即'F'的地址,最后+3,指针指向了'S',%s就会根据此时的地址向后打印字符串,结果打印就是ST
//4: cpp[-1][-1] + 1,cpp[-1][-1] 可以看作是*(*(cpp - 1) - 1) ,即 *(*(cpp - 1) - 1),cpp - 1指向了cp数组的第二个元素的空间,*解引用操作,拿到了c+2这块空间, - 1即c+2减去1,那么这块空间的数据就是c+1了,此时指向关系就再是原来的指向关系了,而是指向了c数组的第二个元素,*解引用操作,拿到了这块空间的元素, 即'N'的地址,最后+1,指针指向了'E',%s就会根据此时的地址向后打印字符串,结果打印就是EW
好了,题目就到这里了,如果能对以上指针题目理解通透,那么C语言指针就没多大问题啦,而以上题目基本上需要我们去画图理解!可以看出理解代码的逻辑时画图有多么的重要!~
✨✨ 创作不易,希望能的到小伙伴的三连,感谢各位小伙伴的支持哦~~
相关文章:
【深入理解C指针】经典笔试题——指针和数组
🔹内容专栏:【C语言】进阶部分 🔹本文概括:一些指针和数组笔试题的解析 。 🔹本文作者:花香碟自来_ 🔹发布时间:2023.3.12 目录 一、指针和数组练习题 1. 一维数组 2. 字符数组 …...

雷达散射截面
雷达散射截面(Radar Cross Section, RCS)是表征目标散射强弱的物理量。 σ = 4 π R 2 ∣ E s ∣ 2 ∣ E i ∣ 2 \sigma = 4\pi R^2 \frac{|E_s |^2}{|E_i|^2}...

希腊棺材之谜——复盘
文章目录梗概推导伪解答虽然花费6-8小时来看小说,是一件很奢侈的事情。但是再荒诞的事情终归有它背后的逻辑链条。这正如Ellery所坚持的那样,逻辑为王。希腊棺材之谜是Ellery Queen首次展露头角, 因此作者特地给他安排了3次伪解答和1次真解答…...
CentOS的下载和安装
文章目录前言一、CentOS的下载二、如何下载1.选择下载版本2.选择isos3.点击isos后,进入如下页面,接着点击X86_644.一般选择下面框住的进行下载三、安装软件选择设置接着进行分区设置设置网络和主机名前言 在学习Linux时,记录下CentOS的安装 …...

new bing的chatGPT如何解析英文论文pdf
昨天我的new bing申请下来了,有了聊天的界面: 但是解析pdf的英文文献,还是不行,没有对话窗口。就问了一下chatGPT,方案如下: 要使用New Bing解析PDF文献,你需要以下几个步骤: 1&a…...

学会这12个Python装饰器,让你的代码更上一层楼
学会这12个Python装饰器,让你的代码更上一层楼 Python 装饰器是个强大的工具,可帮你生成整洁、可重用和可维护的代码。某种意义上说,会不会用装饰器是区分新手和老鸟的重要标志。如果你不熟悉装饰器,你可以将它们视为将函数作为输…...

企业使用ERP的好处
ERP系统是企业管理信息系统的简称,它是以信息技术为手段,以物流、资金流、信息流为主线,以企业的核心业务流程为对象,建立的一套适用于企业管理的、高效的企业管理信息系统。它是通过科学方法和计算机信息技术,将企业运…...
的大小或分辨率)
【QT】如何获取屏幕(桌面)的大小或分辨率
目录1. QDesktopWidget 获取系统屏幕大小2. QScreen 获取系统屏幕大小3. geometry() 与 availableGeometry() 的区别1. QDesktopWidget 获取系统屏幕大小 QDesktopWidget 提供了详细的位置信息,其能够自动返回窗口在用户窗口的位置和应用程序窗口的位置 QDesktopW…...

ETL工具的选择
正确选择 ETL 工具,可以从 ETL 对平台的支持、对数据源的支持、数据转换功能、管理 和调度功能、集成和开放性、对元数据管理等功能出发,具体如下。 支持平台 随着各种应用系统数据量的飞速增长和对业务可靠性等要求的不断提高,人们对数据抽…...

SpringBoot仿天猫商城java web购物网站的设计与实现
1,项目介绍 基于 SpringBoot 的仿天猫商城拥有两种角色,分别为管理员和用户。 迷你天猫商城是一个基于SSM框架的综合性B2C电商平台,需求设计主要参考天猫商城的购物流程。 后端页面兼容IE10及以上现代浏览器,Chrome,Edge,Firebox…...

C#基础教程22 文件的输入与输出
C# 文件的输入与输出 一个 文件 是一个存储在磁盘中带有指定名称和目录路径的数据集合。当打开文件进行读写时,它变成一个 流。 从根本上说,流是通过通信路径传递的字节序列。有两个主要的流:输入流 和 输出流。输入流用于从文件读取数据(读操作),输出流用于向文件写入数…...

Ubuntu18.04 python 开发usb通信
一、安装环境 1.安装pip sudo python3 get-pip.py 或 sudo -i apt update apt install python3-pip 确定pip是否安装成功: xxx-desktop:~$ pip3 --versionpip 9.0.1 from /usr/lib/python3/dist-packages (python 3.6)2.安装pyusb pip3 install pyusb --use…...
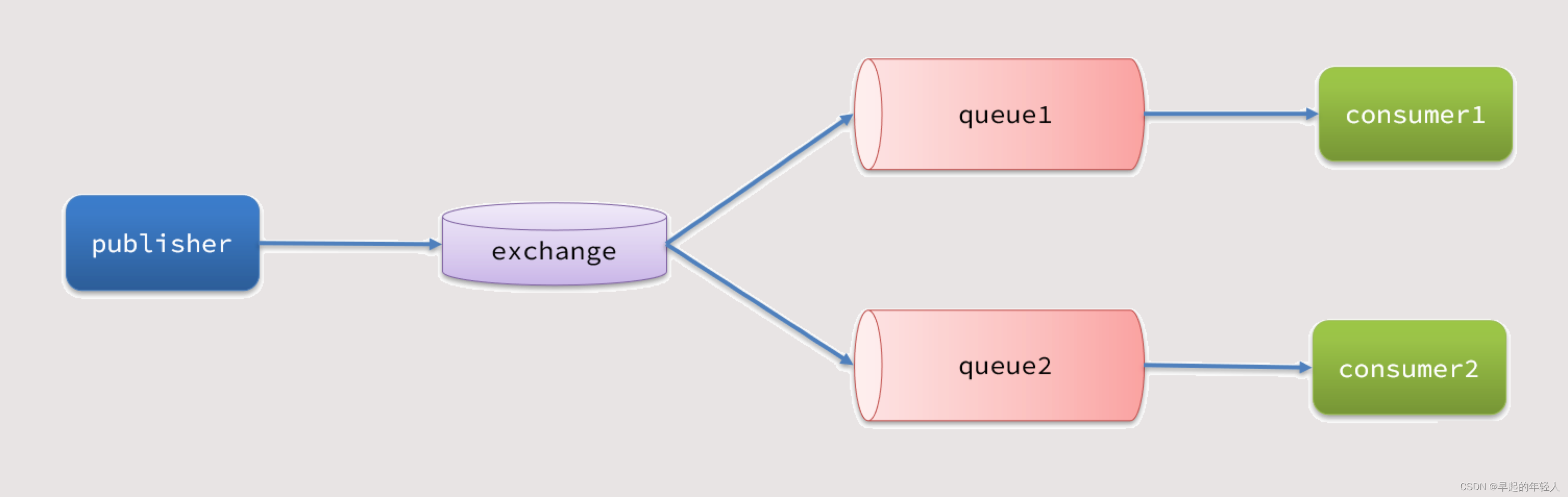
RabbitMq 消息确认机制详解 SpringCloud
1 消息可靠性 消息从发送,到消费者接收,会经理多个过程,其中的每一步都可能导致消息丢失. #### 2 常见的丢失原因 发送时丢失: 生产者发送的消息未送达exchange 消息到达exchange后未到达queueMQ宕机,queue将消息丢失 consumer…...

后台导航布局
五、后台导航实例 参考链接: 页面后台导航制作 如何实现html后台导航iframe点击换url(代码) 如何消除html页面下边和右边的滚动条 html页面有多个滚动条时的优化 页面出现不必要的滚动条,怎么调试? 一个页面有两…...

设计模式——抽象工厂模式(创建型)
一、介绍抽象工厂模式是一种创建型设计模式, 它能创建一系列相关的对象, 而无需指定其具体类。问题假设你正在开发一款家具商店模拟器。 你的代码中包括一些类, 用于表示:一系列相关产品, 例如 椅子Chair 、 沙发Sofa和…...

Java面试题--SpringMVC的执行流程
概要 SpringMVC是一种基于MVC(Model-View-Controller)框架的Web应用开发框架。下面是SpringMVC的详细执行流程。 客户端向DispatcherServlet发送请求。DispatcherServlet收到请求后,根据HandlerMapping(处理器映射)找…...
c# 32位程序突破2G内存限制
起因 在开发过程中,由于某些COM组件只能在32位程序下运行,程序不得不在X86平台下生成。而X86的32位程序默认内存大小被限制在2G。由于程序中可能存在大数量处理,期间对象若没有及时释放或则回收,内存占用达到了1.2G左右ÿ…...

【C语言】指针详解总结
指针1. 指针是什么2. 指针和指针类型2.1 指针-整数2.2 指针的解引用3. 野指针3.1 野指针成因3.2 如何规避野指针4. 指针运算4.1 指针-整数4.2 指针-指针4.3 指针的关系运算5. 指针和数组6. 二级指针7. 指针数组1. 指针是什么 指针是什么? 指针理解的2个要点…...

Java加解密(八)工具篇
目录Java加解密实用工具1 OpenSSL2 Keytool3 XCA4 KeyStore ExplorerJava加解密实用工具 1 OpenSSL OpenSSL是一个开放源代码的软件库包,应用程序可以使用这个包来进行安全通信,避免窃听,同时确认另一端连接者的身份。 例如Apache 使用它加…...

Go框架三件套(Web/RPC/ORM)
🧡 三件套介绍 Gorm Gorm 是一个已经迭代了10年的功能强大的 ORM 框架,在字节内部被广泛使用并且拥有非常丰富的开源扩展。 Kitex Kitex 是字节内部的 Golang 微服务 RPC 框架,具有高性能、强可扩展的主要特点,支持多协议并且拥有…...

工作5年的PHP程序员,转智能体开发半年,薪资翻了2倍
文章目录前言一、PHP程序员的中年危机:不是你不行,是时代变了二、为什么智能体开发是PHP程序员的最优转型方向?1. 门槛最低,上手最快2. 竞争最小,薪资最高3. 前景最好,发展空间最大三、那个转智能体半年薪资…...

AI 写论文哪个软件最好?2026 毕业论文实测:真文献 + 真图表 + 全流程,虎贲等考 AI 稳占首选
📌 配图 1:首图海报 ——AI 写论文哪个最好|虎贲等考 AI|毕业论文神器|真实文献 实证图表 每年毕业季,所有人都在问:AI 写论文哪个软件最好?市面上工具看似很多,可一用…...

TAMEn系统:触觉视觉数据采集的模块化解决方案
1. TAMEn系统概述:触觉视觉数据采集的革命性方案在机器人操作领域,接触丰富的任务(如柔性物体处理、精密装配)一直面临着数据采集的挑战。传统视觉系统难以捕捉细微的接触信号(如初始滑动、局部变形)&#…...

异构GPU推理优化:Tessera架构解析与实践
1. 异构GPU推理的性能瓶颈与挑战在当前的AI推理服务部署中,混合使用不同代际的GPU已经成为提升性价比的常见做法。比如将最新的H100与相对便宜的L40S搭配使用,或者将计算密集型的B200与内存优化的H100组合部署。然而,这种异构环境下的资源利用…...

主动悬架乘坐舒适性控制策略优化【附模型】
✨ 长期致力于随机路面、主动悬架、乘坐舒适性、控制策略、仿真分析研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)随机路面与1/4悬架动力学建模&…...

量子机器学习中的噪声效应与抗噪策略
1. 量子机器学习中的噪声效应全景解析在量子计算与机器学习交叉领域,噪声问题正成为制约实际应用的关键瓶颈。去年我在参与一个医疗影像分类项目时,首次亲身体验到量子噪声的破坏力——当我们将经典卷积神经网络迁移到量子变分电路架构时,准确…...

计算机视觉工程师必须掌握的颜色空间选型指南
1. 项目概述:为什么计算机视觉工程师必须懂颜色理论你有没有遇到过这样的情况:模型在训练集上准确率98%,一到测试集就掉到72%?调试半天发现,不是数据标注错了,也不是网络结构有问题,而是训练图像…...
)
黑莓印相≠复古滤镜!基于CIE Lab色域分析的Midjourney色彩空间偏移校准方案(附Python验证脚本)
更多请点击: https://intelliparadigm.com 第一章:黑莓印相≠复古滤镜!基于CIE Lab色域分析的Midjourney色彩空间偏移校准方案(附Python验证脚本) 黑莓印相(Blackberry Print Tone)常被误认为是…...

基于Node.js的Gemini CLI蓝图:构建高效AI命令行工具
1. 项目概述:一个让Gemini API在命令行中“活”起来的蓝图 如果你和我一样,日常工作中大量时间都泡在终端里,那么你肯定理解那种感觉:为了调用一个AI模型,不得不频繁地在浏览器、API文档和命令行之间来回切换ÿ…...

3步快速上手RobotHelper:安卓自动化脚本框架新手指南
3步快速上手RobotHelper:安卓自动化脚本框架新手指南 【免费下载链接】RobotHelper 安卓游戏自动化脚本框架|Automated script for Android games 项目地址: https://gitcode.com/gh_mirrors/ro/RobotHelper 你是否想要开发安卓游戏自动化脚本,却…...