LLM调优,大模型怎么学
背景
LLM Transparency Tool 是一个用于深入分析和理解大型语言模型(LLM)工作原理的工具,旨在增加这些复杂系统的透明度。它提供了一个交互式界面,用户可以通过它观察、分析模型对特定输入(prompts)的反应,以及模型内部的决策过程。
LLM Transparency Tool的主要功能包括:
- 选择模型和提示,并运行推理:用户可以选择一个已经集成的语言模型,并给这个模型提供一个提示(prompt),工具会显示模型是如何处理这个提示的。
- 浏览贡献图:这个功能允许用户社交从模型生成的token开始构建图表,通过调整贡献门槛来过滤信息。
- 选择任何模块后的token表示:用户可以查看每个处理块之后任意token的内部表示。
- 查看输出词汇表的投影:对于选中的表示,工具可以显示它是如何影响模型输出词汇的选择的,包括哪些token被之前的块促进或抑制了。
- 可交互的图形元素:包括连接线(展示了贡献的注意力头信息)、当选中连接线时显示的头部信息、前馈网络块(FFN blocks)、以及选中FFN块时的神经元等。
使用场景
- 模型分析与调优:研究人员或开发者在开发或优化语言模型时,可以使用此工具来观察模型对特定输入的处理过程,找出模型的优点与不足。
- 教育与学习:对深度学习和NLP(自然语言处理)感兴趣的学生或爱好者可以通过这个工具来加深对大型语言模型工作原理的理解。
- 算法透明度与可解释性:在追求算法透明度和可解释AI的推进中,该工具可作为分析工具的一种,帮助解释模型的决策依据
项目说明
- 项目地址:https://github.com/facebookresearch/llm-transparency-tool
- 项目依赖:https://github.com/TransformerLensOrg/TransformerLens
- 论文地址:https://arxiv.org/pdf/2403.00824.pdf
- Transparency Tool是基于TransformerLens开发的,TransformerLens是一个专注于生成语言模型(如GPT-2风格的模型)的可解释性的库。其核心目标是利用训练好的模型,通过分析模型的内部工作机制,来提供对模型行为的深入理解
- 凡是TransformerLens支持的模型,Transparency Tool都能支持。对于TransformerLens不支持的模型,需要实现自己的TransparentLlm类
部署
# download
git clone git@github.com:facebookresearch/llm-transparency-tool.git
cd llm-transparency-tool# install the necessary packages
conda env create --name llmtt -f env.yaml
# install the `llm_transparency_tool` package
pip install -e .# now, we need to build the frontend
# don't worry, even `yarn` comes preinstalled by `env.yaml`
cd llm_transparency_tool/components/frontend
yarn install
yarn build- 模型配置
{"allow_loading_dataset_files": true,"preloaded_dataset_filename": "sample_input.txt","debug": true,"models": {"": null,"/root/.cache/modelscope/hub/AI-ModelScope/gpt2-medium": null, // 额外添加模型"/root/.cache/Qwen1.5-14B-Chat/": null, // 额外添加模型"gpt2": null,"distilgpt2": null,"facebook/opt-125m": null,"facebook/opt-1.3b": null,"EleutherAI/gpt-neo-125M": null,"Qwen/Qwen-1_8B": null,"Qwen/Qwen1.5-0.5B": null,"Qwen/Qwen1.5-0.5B-Chat": null,"Qwen/Qwen1.5-1.8B": null,"Qwen/Qwen1.5-1.8B-Chat": null,"microsoft/phi-1": null,"microsoft/phi-1_5": null,"microsoft/phi-2": null,"meta-llama/Llama-2-7b-hf": null,"meta-llama/Llama-2-7b-chat-hf": null,"meta-llama/Llama-2-13b-hf": null,"meta-llama/Llama-2-13b-chat-hf": null,"gpt2-medium": null,"gpt2-large": null,"gpt2-xl": null,"mistralai/Mistral-7B-v0.1": null,"mistralai/Mistral-7B-Instruct-v0.1": null,"mistralai/Mistral-7B-Instruct-v0.2": null,"google/gemma-7b": null,"google/gemma-2b": null,"facebook/opt-2.7b": null,"facebook/opt-6.7b": null,"facebook/opt-13b": null,"facebook/opt-30b": null},"default_model": "","demo_mode": false
}- 适配更多模型

- 启动
streamlit run llm_transparency_tool/server/app.py -- config/local.json- 效果
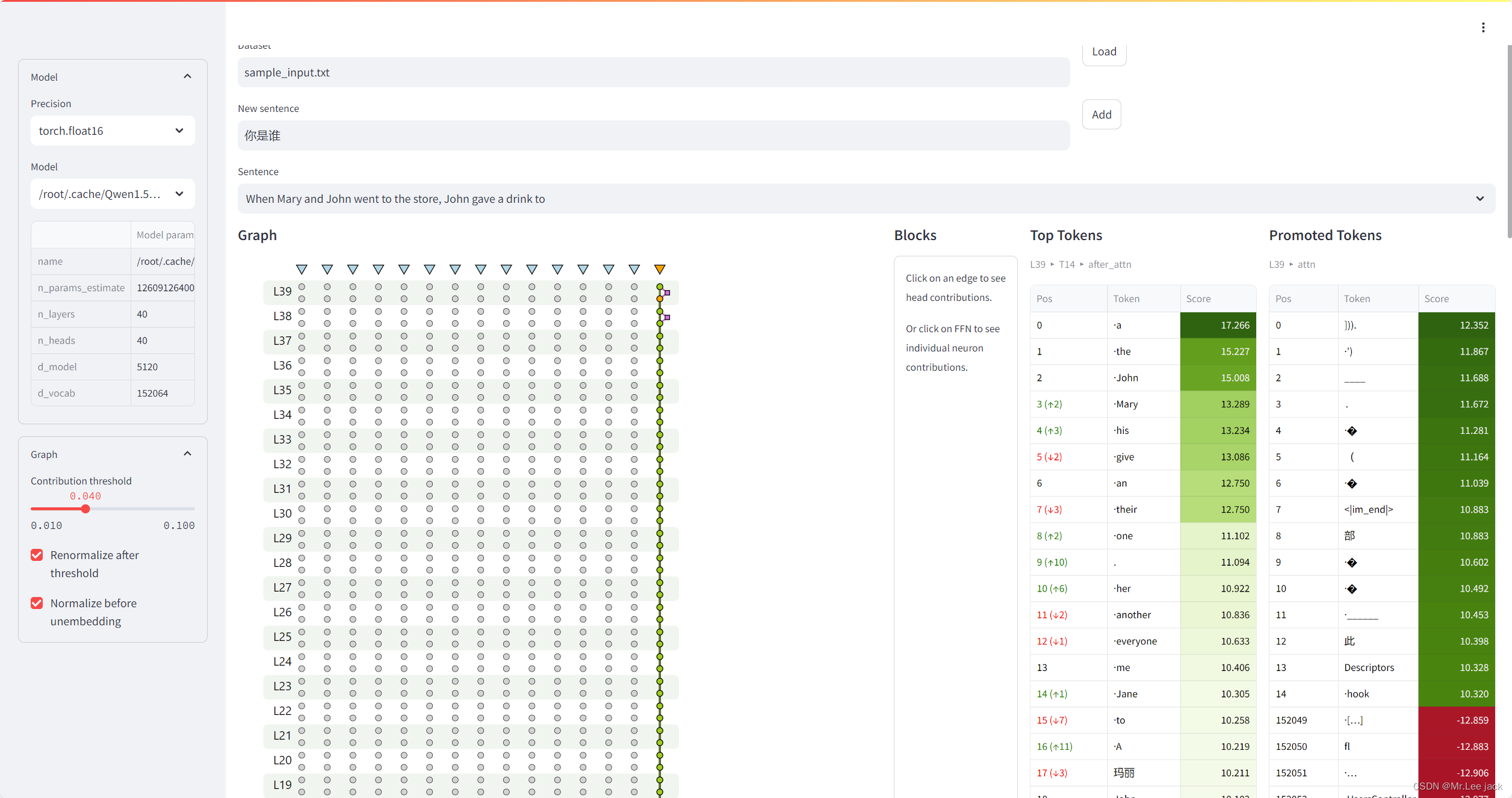
原理
引言
-
Transformer架构:作者首先指出,当前最先进的语言模型(LMs)大多基于Transformer架构,这是一种深度学习模型,广泛应用于自然语言处理任务中。Transformer模型通过自注意力机制(self-attention)和前馈网络(feed-forward networks)处理语言信息。
-
信息流的概念:在Transformer模型中,每个token的表示(representation)会随着网络层的加深而不断演化。这种演化过程可以视为信息流,即信息在模型内部的流动和转换。作者将这种信息流比作一个图,其中节点代表token的表示,边代表模型内部的计算操作。
-
信息流的重要性:尽管在模型的前向传播过程中,所有的计算路径都存在,但对于特定的预测任务,只有一部分计算是重要的。作者强调了识别和提取这些重要信息流路径的重要性,因为这有助于我们更好地理解模型是如何做出特定预测的。
-
现有方法的局限性:论文提到了现有的基于激活补丁(activation patching)的方法,这种方法通过替换模型内部的激活值来研究模型的行为。然而,这种方法存在局限性,包括需要人为设计预测模板、分析仅限于预定义模板、以及在大规模模型中不切实际等。
-
提出的新方法:为了克服现有方法的局限性,作者提出了一种新的方法来自动构建信息流图,并提取对于每个预测最重要的节点和边。这种方法不需要人为设计的模板,可以高效地应用于任何预测任务,并且只需单次前向传播即可完成。
-
实验和结果:在引言的最后,作者简要提到了他们使用Llama 2模型进行的实验,展示了新方法的有效性。他们发现某些注意力头(如处理前一个token的头和子词合并头)在整体上很重要,并且模型在处理相同词性的token时表现出相似的行为模式。
-
贡献总结:作者总结了他们的贡献,包括提出了一种新的解释Transformer LMs预测的方法,与现有方法相比,新方法具有更广泛的适用性、更高的信息量和更快的速度
信息流路径的提取
实现步骤
-
构建信息流图:首先,将模型内部的计算过程表示为一个图,其中节点代表token的表示,边代表模型内部的操作,如注意力头、前馈层等。
-
自顶向下追踪:从预测结果的节点开始,自顶向下地追踪网络中的信息流动。在每一步中,只保留对当前预测结果有重要影响的节点和边。
-
设置重要性阈值:通过设置一个阈值τ,只有当边的重要性高于这个阈值时,才会将其包含在最终的信息流路径图中。
-
利用属性方法:与传统的激活补丁方法不同,作者使用属性(attribution)方法来确定边的重要性。这种方法不需要人为设计对比模板,可以更高效地识别对预测结果有实质性影响的信息流动路径。
-
计算边的重要性:根据ALTI(Aggregation of Layer-Wise Token-to-Token Interactions)方法,计算每个边对于节点(即token表示的总和)的贡献度。贡献度与边向量与节点向量的接近程度成正比。
意义
-
提高透明度:通过提取信息流路径,可以更清晰地看到模型内部是如何进行决策的,提高了模型的透明度。
-
优化模型设计:理解信息流动的模式可以帮助研究者发现模型设计中的不足之处,从而进行优化。
-
解释预测结果:信息流路径提供了一种方式来解释模型的预测结果,有助于理解模型为何做出特定的预测。
-
发现模型组件的专门化:通过分析信息流路径,可以识别出模型中专门针对特定领域或任务的组件。
-
提高模型的可靠性:通过识别和强化重要的信息流动路径,可以提高模型在面对复杂或模糊输入时的可靠性
如何理解模型行为
-
注意力头的作用:通过分析哪些注意力头在信息流路径中起关键作用,可以理解模型在处理特定类型的输入时依赖哪些信息。
-
信息流动模式:观察信息在模型内部如何流动,可以帮助我们理解模型是如何处理和整合不同部分的信息来做出预测的。
-
模型的泛化能力:通过分析信息流路径,可以评估模型在不同任务或不同领域中的泛化能力。
-
模型的脆弱性:识别信息流路径中的脆弱环节,可以帮助我们理解模型可能在哪些情况下失效,并采取措施进行改进。
-
模型的自我修复能力:通过比较信息流路径在正常和干预(如激活补丁)情况下的差异,可以研究模型的自我修复能力。
参数解释
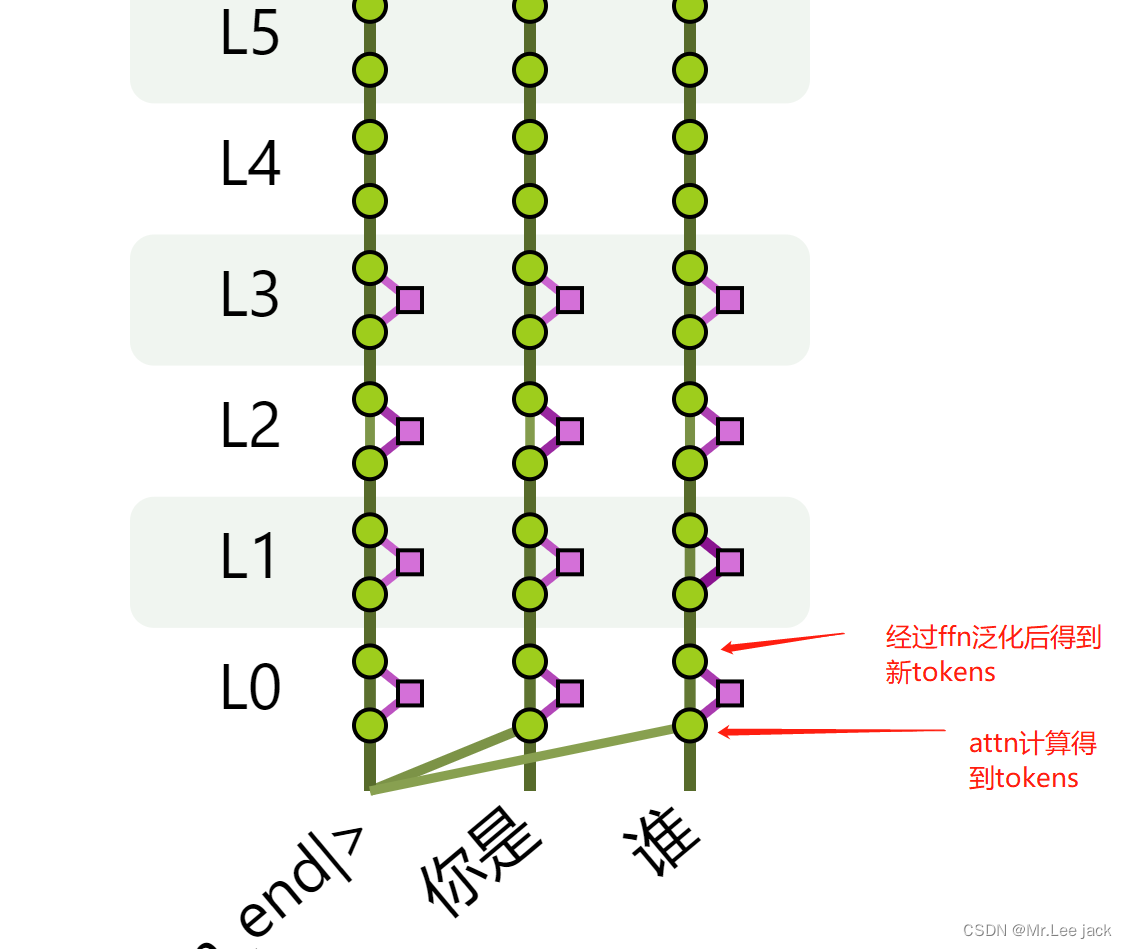
- y轴表示 模型层
- 横轴表示对应得token
- 每次计算从L0依次向上计算,并经过attention计算在经过ffn泛化,每次都得到最重要得 top k个token
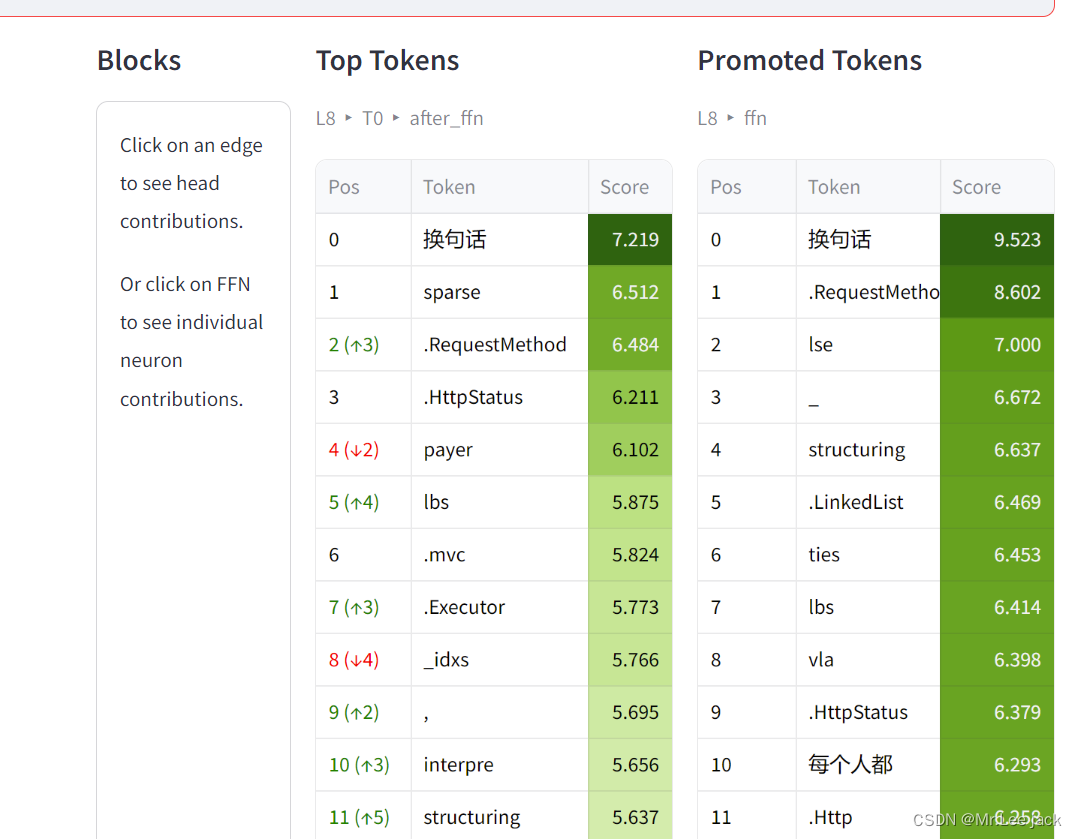
怎么理解Promoted Tokens
L39 ffn
-
在Transformer架构中,"l39 ffn"通常指的是位于模型第39层(layer 39)的前馈网络(feed-forward network,简称FFN)。以下是对"l39 ffn"的详细解释:
-
Layer(层):在深度学习模型中,尤其是Transformer模型,信息会通过多个层次(layers)进行处理。每一层都会对输入数据进行一些变换,以提取特征或进行抽象表示。
-
Feed-Forward Network(前馈网络):FFN是Transformer模型中的一种组件,通常位于每个注意力(attention)层之后。它由两个线性变换组成,中间夹着一个非线性激活函数(如ReLU)。FFN的作用是对注意力层的输出进行进一步的非线性变换,增加模型的表达能力。
-
Layer 39(第39层):在某些大型语言模型中,可能会有数十层的深度结构。"l39"指的是模型中的第39层,这意味着信息已经通过了前38层的处理,并且在第39层中进一步被变换和抽象。
-
FFN的作用:在第39层的FFN中,模型会对从第38层传递来的信息进行处理。这个过程包括:
- 一个线性变换,将输入映射到一个更高或更低维度的空间。
应用一个非线性激活函数,通常是ReLU,以引入非线性特性,帮助模型学习复杂的模式。 - 另一个线性变换,将激活后的结果映射回原始维度或另一个特定的维度。
- 一个线性变换,将输入映射到一个更高或更低维度的空间。
-
理解FFN的重要性:FFN是Transformer模型中不可或缺的一部分,它允许模型在每个层级上进行更复杂的特征转换。通过这种方式,模型可以学习到更加抽象和高级的语言特征,这对于处理复杂的语言任务至关重要。
-
在模型解释性中的作用:在论文中提到的信息流路径提取方法中,FFN的重要性也可能被评估。研究者可能会分析第39层FFN对最终预测的贡献,以及它如何与同一层次的注意力机制协同工作。
怎么理解Top Tokens
- L8 T0 after attn: 表示第8层经过attention 计算得到预测token
- L8 T0 after ffn:表示第8层经过ffn 泛化 计算得到预测token,使模型表达能力更强了
大模型如何入坑?
想要完全了解大模型,你首先要了解市面上的LLM大模型现状,学习Python语言、Prompt提示工程,然后深入理解Function Calling、RAG、LangChain 、Agents等
很多人不知道想要自学大模型,要按什么路线学?
所有大模型最新最全的资源,包括【学习路线图】、【配套自学视频+pdf】、【面试题】这边我都帮大家整理好了通过下方卡片获取哦!
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。

3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
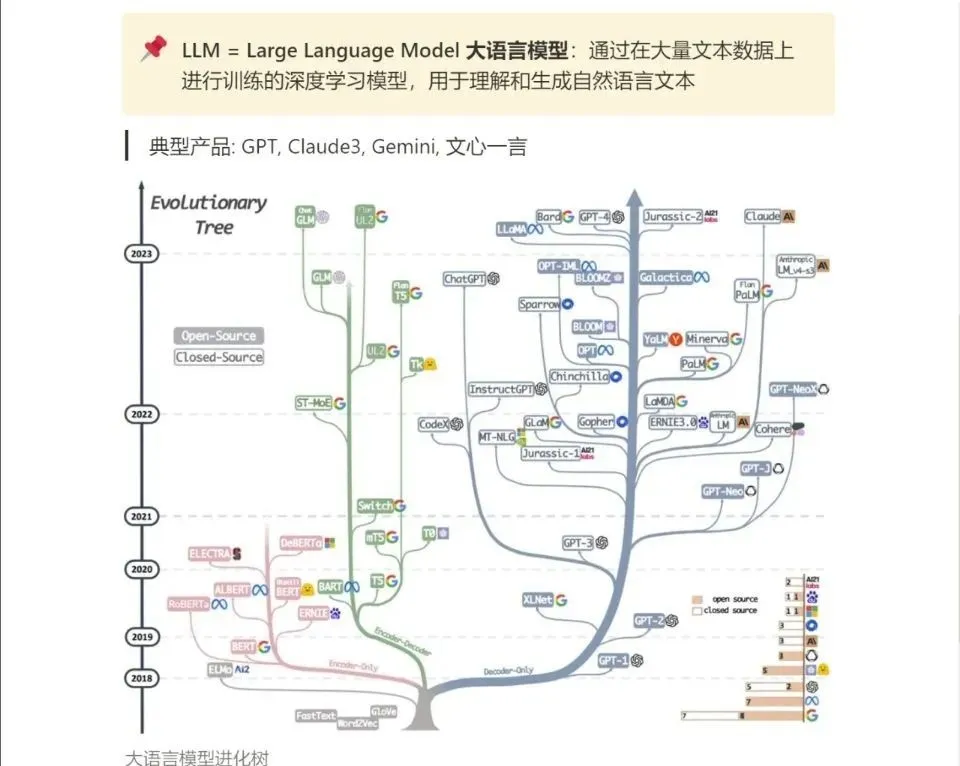
发展前景:大模型在自然语言处理、图像识别、语音识别等领域具有广泛的应用。随着大数据时代的到来,大模型技术将继续发展,为程序员提供更多的发展机会。
技能要求:要成为一名优秀的大模型程序员,需要具备以下技能:
- 掌握深度学习相关知识,如神经网络、卷积神经网络等;
- 熟悉编程语言,如Python、C++等;
- 了解大数据处理技术,如Hadoop、Spark等;
- 具备良好的数学和统计学基础,以便更好地理解和优化大模型。

相关文章:
LLM调优,大模型怎么学
背景 LLM Transparency Tool 是一个用于深入分析和理解大型语言模型(LLM)工作原理的工具,旨在增加这些复杂系统的透明度。它提供了一个交互式界面,用户可以通过它观察、分析模型对特定输入(prompts)的反应…...

XLSX + LuckySheet + LuckyExcel实现前端的excel预览
文章目录 功能简介简单代码实现效果参考 功能简介 通过LuckyExcel的transformExcelToLucky方法, 我们可以把一个文件直接转成LuckySheet需要的json字符串, 之后我们就可以用LuckySheet预览excelLuckyExcel只能解析xlsx格式的excel文件,因此对…...

在Ubuntu上创建和启用交换文件的简单步骤
文章目录 为什么使用交换文件?步骤 1:创建交换文件步骤 2:设置正确的权限步骤 3:将文件格式化为交换空间步骤 4:启用交换文件步骤 5:验证交换文件步骤 6:永久启用交换文件步骤 7:调整…...
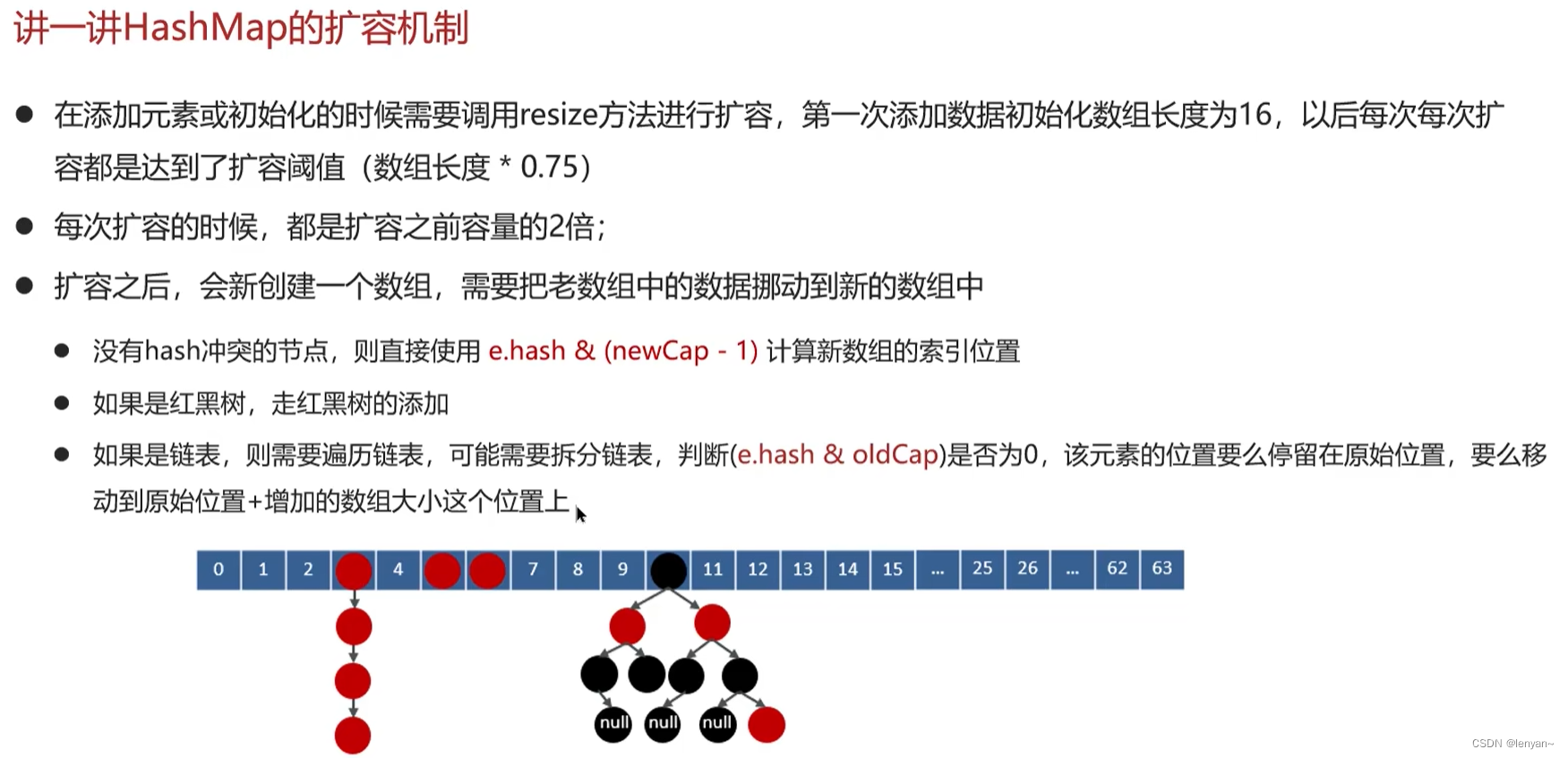
Java [ 基础 ] HashMap详解 ✨
目录 ✨探索Java基础 HashMap详解✨ 总述 主体 1. HashMap的基本概念 2. HashMap的工作原理 3. HashMap的常用操作 4. HashMap的优缺点 总结 常见面试题 常见面试题解答 1. HashMap的底层实现原理是什么? 2. 如何解决HashMap中的哈希冲突?…...

vue2项目迁移vue3与gogocode的使用
#背景 公司有个项目使用vue2jswebpack框架开发的,由于该项目内部需要安扫,导致很多框架出现了漏洞需要升级,其中主要需要从vue2升vue3,但是重新搭框架推翻重做成本太高,于是找到了gogocode。 #升级步骤踩坑 1. 安装 gogocode插…...
 #正负交错数列前n项和 #求数列前n项的平方和)
【Python123题库】#数列求和 #百分制成绩转换五分制(循环) #正负交错数列前n项和 #求数列前n项的平方和
禁止转载,原文:https://blog.csdn.net/qq_45801887/article/details/140079866 参考教程:B站视频讲解——https://space.bilibili.com/3546616042621301 有帮助麻烦点个赞 ~ ~ Python123题库 数列求和百分制成绩转换五分制(循环)正负交错数列…...
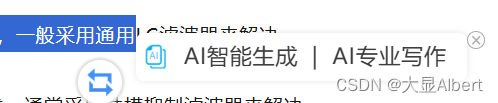
Edge浏览器选中后,出现AI智能生成 AI专业写作
这个是扩展里边的“ 网页万能复制 & ChatGPT AI写作助手”造成的,这个拓展增加了AI写作功能。关闭这个拓展就解决了。...

c++习题08-计算星期几
目录 一,问题 二,思路 三,代码 一,问题 二,思路 首先,需要注意到的是3^2000这个数值很大,已经远远超过了long long 数据类型能够表示的范围,如果想要使用指定的数据类型来保存…...

单目相机减速带检测以及测距
单目相机减速带检测以及测距项目是一个计算机视觉领域的应用,旨在使用一个摄像头(单目相机)来识别道路上的减速带,并进一步估计车辆与减速带之间的距离。这样的系统对于智能驾驶辅助系统(ADAS)特别有用&…...
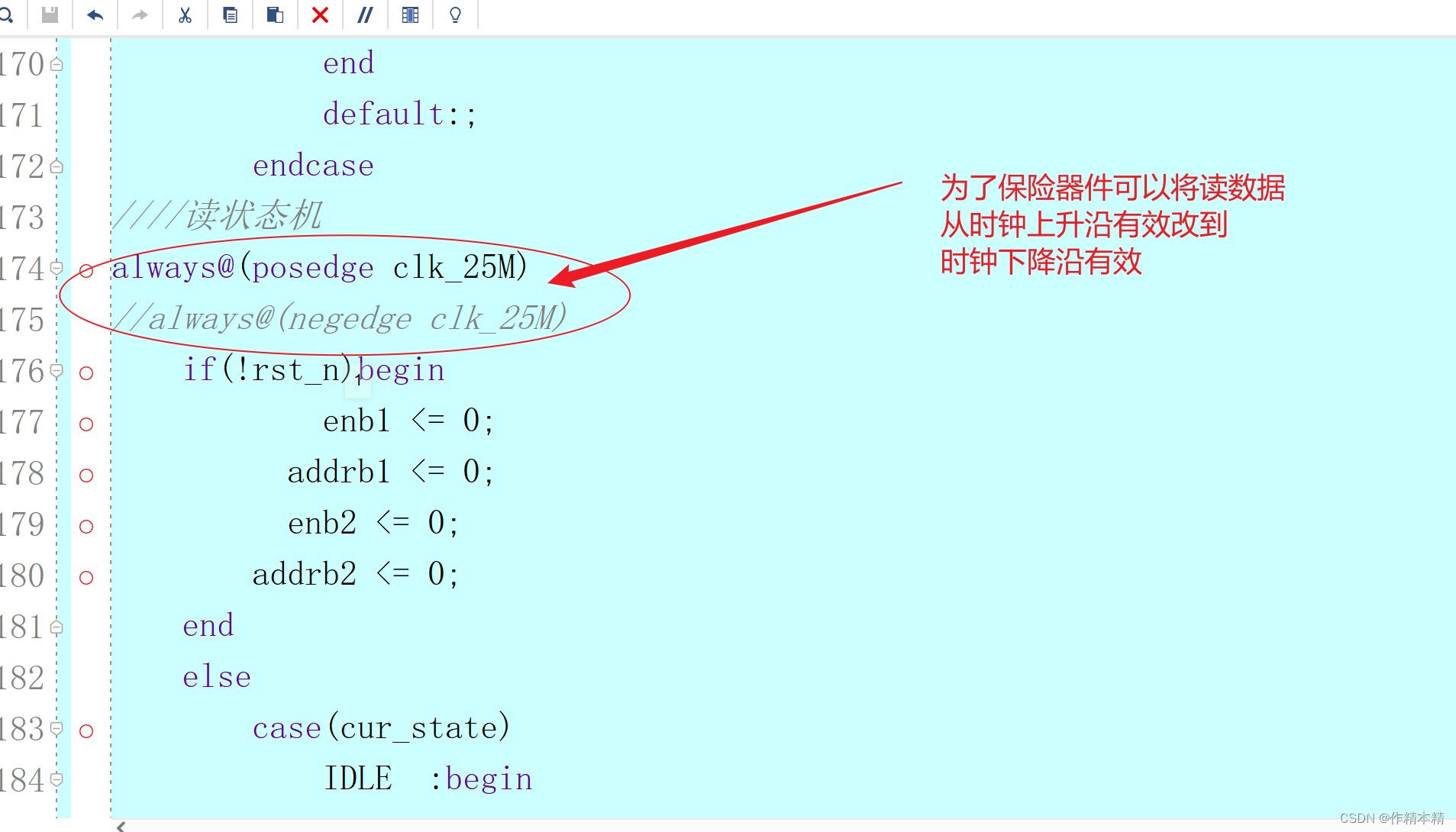
Xilinx FPGA:vivado实现乒乓缓存
一、项目要求 1、用两个伪双端口的RAM实现缓存 2、先写buffer1,再写buffer2 ,在读buffer1的同时写buffer2,在读buffer2的同时写buffer1。 3、写端口50M时钟,写入16个8bit 的数据,读出时钟25M,读出8个16…...

解决 VM 虚拟机网络连接异常导致的 Finalshell 无法连接及 ifconfig 中 ens33 丢失问题
在使用 VM 虚拟机的过程中,遇到了一个颇为棘手的网络连接问题。平时虚拟机都能够正常启动并使用,但昨天在启用虚拟机时更换了一下网络节点,结果今天打开虚拟机后。Finalshell 无法连接上虚拟机,并且输入 ifconfig 命令后也没有 en…...
)
深入Django(三)
Django视图(Views)详解 引言 在前两天的博客中,我们介绍了Django的基本概念和模型系统。今天,我们将深入探讨Django的视图(Views),它们是处理用户请求和返回响应的地方。 什么是Django视图&a…...

观测云赋能「阿里云飞天企业版」,打造全方位监控观测解决方案
近日,观测云成功通过了「阿里云飞天企业版」的生态集成认证测试,并荣获阿里云颁发的产品生态集成认证证书。作为监控观测领域的领军者,观测云一直专注于提供统一的数据视角,助力用户构建起全球范围内的端到端全链路可观测服务。此…...

51单片机第27步_单片机工作在睡眠模式
重点学习51单片机工作在睡眠模式。 1、进入“睡眠模式”的方法 通过将PCON寄存器中的PDWN置1,则CPU会进入“睡眠模式”。在“睡眠模式”中,晶振将停止工作,因此,定时器和串口都将停止工作,只有外部中断继续工作。如果单片机电源…...
互联网应用主流框架整合之SpringCloud微服务治理
微服务架构理念 关于微服务的概念、理念及设计相关内容,并没有特别严格的边界和定义,某种意义上说,适合的就是最好的,在之前的文章中有过详细的阐述,微服务[v1.0.0][Spring生态概述]、微服务[设计与运行]、微服务[v1.…...
超快的 Python 包管理工具「GitHub 热点速览」
天下武功,无坚不破,唯快不破! 要想赢得程序员的欢心,工具的速度至关重要。仅需这一优势,即可使其在众多竞争对手中脱颖而出,迅速赢得开发者的偏爱。以这款号称下一代极速 Python 包管理工具——uv 为例&…...

网络基础:OSPF 协议
OSPF(Open Shortest Path First)是一种广泛使用的链路状态路由协议,用于IP网络中的内部网关协议(IGP)。OSPF通过在网络中的所有路由器之间交换路由信息,选择从源到目的地的最优路径。OSPF工作在OSI模型的第…...

1456.定长子串中元音的最大数目
思路: 首次是滑动窗口, 然后遍历子字符串,这样复杂度太高,没过测试 改进,滑动窗口先求出第一个窗口中元音数量, 然后利用滑动式,一进一出方式判断首尾是否是原因即可 给你字符串 s 和整数 k 。 …...

基于xilinx FPGA的GTX/GTH/GTY位置信息查看方式(如X0Y0在bank几)
目录 1 概述2 参考文档3 查看方式4查询总结: 1 概述 本文用于介绍如何查看xilinx fpga GTX得位置信息(如X0Y0在哪个BANK/Quad)。 2 参考文档 《ug476_7Series_Transceivers》 《pg156-ultrascale-pcie-gen3-en-us-4.4》 3 查看方式 通过…...

JAVA小知识30:JAVA多线程篇1,认识多线程与线程安全问题以及解决方案。(万字解析)
来 多线程,一个学起来挺难但是实际应用不难的一个知识点,甚至在很多情况下都不需要考虑,最多就是写测试类的时候模拟一下并发,现在我们就来讲讲基础的多线程知识。 一、线程和进程、并发与并行 1.1、线程和进程 线程&am…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器
如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为想和朋友一起玩游戏却只有一台电脑而烦…...

Windows 11终极优化指南:一键清理系统,释放51%性能潜力
Windows 11终极优化指南:一键清理系统,释放51%性能潜力 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to decl…...
)
Midjourney辉光效果失效诊断手册(含12个隐性触发条件与4类GPU显存陷阱)
更多请点击: https://codechina.net 第一章:Midjourney辉光效果失效诊断手册(含12个隐性触发条件与4类GPU显存陷阱) 辉光效果(Glow Effect)在 Midjourney v6 的 --style raw 模式下常被用于强化主体边缘光…...