FlinkSQL 开发经验分享

作者:汤包
最近做了几个实时数据开发需求,也不可避免地在使用 Flink 的过程中遇到了一些问题,比如数据倾斜导致的反压、interval join、开窗导致的水位线失效等问题,通过思考并解决这些问题,加深了我对 Flink 原理与机制的理解,因此将这些开发经验分享出来,希望可以帮助到有需要的同学。
下文会介绍 3 个 case 案例,每个 case 都会划分为背景、原因分析和解决方法三部分来进行介绍。
一、Case1: 数据倾斜
数据倾斜无论是在离线还是实时中都会遇到,其定义是:在并行进行数据处理的时候,按照某些 key 划分的数据显著多余其他部分,分布不均匀,导致大量数据集中分布到一台或者某几台计算节点上,使得该部分的处理速度远低于平均计算速度,成为整个数据集处理的瓶颈,从而影响整体计算性能。造成数据倾斜的原因有很多种,如 group by 时的 key 分布不均匀,空值过多、count distinct 等,本文将只介绍 group by + count distinct 这种情况。
1.1 背景
对实时曝光流,实时统计近 24 小时创意的曝光 UV 和 PV。且每分钟更新一次数据。通用的方法就是使用 hop 滑动窗口来进行统计,代码如下:
select HselectHOP_START(ts,interval '1' minute,interval '24' hour) as window_start,HOP_END(ts,interval '1' minute,interval '24' hour) as window_end,creative_id,count(distinct uid) as exp_uv -- 计算曝光UV,count(uid) as exp_pv --计算曝光PVfrom dwd_expos_detailgroup byhop(ts,interval '1' minute,interval '24' hour) -- 滑动窗口开窗,窗口范围:近24小时,滑动间隔:每1分钟,creative_idOP_START( ts ,interval '1' minute ,interval '24' hour ) as window_start ,HOP_END( ts ,interval '1' minute ,interval '24' hour ) as window_end ,creative_id ,count(distinct uid) as exp_uv -- 计算曝光UV ,count(uid) as exp_pv --计算曝光PVfrom dwd_expos_detailgroup by hop( ts ,interval '1' minute ,interval '24' hour ) -- 滑动窗口开窗,窗口范围:近24小时,滑动间隔:每1分钟 ,creative_id
复制代码
1.2 问题及原因
问题发现
在上述 flink 程序运行的时候,该窗口聚合算子 GlobalWindowAggregate 出现长时间 busy 的情况,导致上游的算子出现反压,整个 flink 任务长时间延迟。

原因分析
一般面对反压的现象,首先要定位到出现拥堵的算子,在该 case 中,使用窗口聚合计算每个创意 id 对应的 UV 和 PV 时,出现了计算繁忙拥堵的情况。
针对这种情况,最常想到的就是以下两点原因:
-
数据量较大,但是设置的并发度过小(此任务中该算子的并发度设置为 3)
-
单个 slot 的 CPU 和内存等计算资源不足
点击拥堵算子,并查看 BackPressure,可以看到虽然并发度设置为 3,但是出现拥堵的只有 subtask0 这一个并发子任务,因此基本上可以排出上述两种猜想,如果还是不放心,可以设置增加并行度至 6,同时提高该算子上的 slot 的内存和 CPU,结果如下:

可以看到依然只有 subtask0 处于计算拥堵的状态,现在可以完全确认是由于 group by 时的 key 上的数据分布不均匀导致的数据倾斜问题。
解决方法
-
开启 PartialFinal 解决 count distinct 中的热点问题
-
实现:flink 中提供了针对 count distinct 的自动打散和两阶段聚合,即 PartialFinal 优化。实现方法:在作业运维中增加如下参数设置:
table.optimizer.distinct-agg.split.enabled: true复制代码
-
限制:这个参数适用于普通的 GroupAggregate 算子,对于 WindowAggregate 算子目前只适用于新的 Window TVF(窗口表值函数),老的一套 Tumble/Hop/Cumulate window 是不支持的。
由于我们的代码中并没有使用到窗口表值函数,而是直接在 group 中使用了 hop 窗口,因此该方法不适用。
人工对不均匀的 key 进行打散并实现两阶段聚合
-
思路:增加按 Distinct Key 取模的打散层
-
实现:
第一阶段:对 distinct 的字段 uid 取 hash 值,并除以 1024 取模作为 group by 的 key。此时的 group by 分组由于引入了 user_id,因此分组变得均匀。
selectHOP_START(ts,interval '1' minute,interval '24' hour) as window_start,HOP_END(ts,interval '1' minute,interval '24' hour) as window_end,creative_id,count(distinct uid) as exp_uv,count(uid) as exp_pvfrom dwd_expos_detailgroup byhop(ts,interval '1' minute,interval '24' hour),creative_id,MOD(HASH_CODE(uid), 1024)
复制代码
-
第二阶段:对上述结果,再根据 creative_id 字段进行分组,并将 UV 和 PV 的值求和
selectwindow_start,window_end,creative_id,sum(exp_uv) as exp_uv,sum(exp_pv) as exp_pvfrom (selectHOP_START(ts,interval '1' minute,interval '24' hour) as window_start,HOP_END(ts,interval '1' minute,interval '24' hour) as window_end,creative_id,count(distinct uid) as exp_uv,count(uid) as exp_pvfrom dwd_expos_detailgroup byhop(ts,interval '1' minute,interval '24' hour),creative_id,MOD(HASH_CODE(uid), 1024))group bywindow_start,window_end,creative_id;
复制代码
-
效果:在拓扑图中可以看到原窗口聚合算子被分为两个独立的聚合算子,同时每个 subtask 的繁忙程度也都接近,不再出现不均匀的情况。

二、Case2: 水位线失效
2.1 背景
需要先对两条实时流进行双流 join,然后再对 join 后的结果使用 hop 滑动窗口,计算每个创意的汇总指标。
2.2 问题及原因
问题发现
开窗后长时间无数据产生。
原因分析
水位线对于窗口函数的实现起到了决定性的作用,它决定了窗口的触发时机,Window 聚合目前支持 Event Time 和 Processing Time 两种时间属性定义窗口。最常用的就是在源表的 event_time 字段上定义水位线,系统会根据数据的 Event Time 生成的 Watermark 来进行关窗。
只有当 Watermark 大于关窗时间,才会触发窗口的结束,窗口结束才会输出结果。如果一直没有触发窗口结束的数据流入 Flink,则该窗口就无法输出数据。
-
限制:数据经过 GroupBy、双流 JOIN 或 OVER 窗口节点后,会导致 Watermark 属性丢失,无法再使用 Event Time 进行开窗。
由于我们在代码中首先使用了 interval join 来处理点击流和交易流,然后在对生成的数据进行开窗,导致水位线丢失,窗口函数无法被触发。
2.3 解决方法
思路 1: 既然双流 join 之后的时间字段丢失了水位线属性,可以考虑再给 join 之后的结果再加上一个 processing time 的时间字段,然后使用该字段进行开窗。
-
缺点:该字段无法真正体现数据的时间属性,只是机器处理该条数据的时间戳,因此会导致窗口聚合时的结果不准确,不推荐使用。
思路 2: 新建 tt 流
-
要开窗就必须有水位线,而水位线往往会在上述提及的聚合或者双流 join 加工中丢失,因此考虑新建一个 flink 任务专门用来进行双流 join,过滤出符合条件的用户交易明细流,并写入到 tt,然后再消费该 tt,并对 tt 流中的 event_time 字段定义 watermark 水位线,并直接将数据用于 hop 滑动窗口。
-
实现:
步骤 1:新建 flink 任务,通过 interval join 筛选出近六个小时内有过点击记录的用户交易明细,并 sink 到 tt
insert into sink_dwd_pop_pay_detail_riselectp1.uid,p1.order_id,p1.order_amount,p1.ts,p2.creative_idfrom (selectuid,order_amount,order_id,tsfrom dwd_trade_detail) p1join dwd_clk_uv_detail p2on p2.ts between p1.ts - interval '6' hour and p1.tsand p1.uid = p2.uid;
复制代码
-
步骤 2: 消费该加工后的交易流,并直接进行滑动窗口聚合
selectHOP_START(ts,INTERVAL '1' minute,INTERVAL '24' hour) as window_start,HOP_END(ts,INTERVAL '1' minute,INTERVAL '24' hour) as window_end,creative_id,sum(order_amount) as total_gmv,count(distinct uid) as cnt_order_uv,round(sum(order_amount) / count(distinct uid) / 1.0,2) as gmv_per_uvfrom source_dwd_pop_pay_detail_riGROUP BYHOP(ts,INTERVAL '1' minute,INTERVAL '24' hour),creative_id;
复制代码
三、Case3: group by 失效
3.1 背景
目的:对于实时流,需要给素材打上是否通过的标签。
打标逻辑:如果素材 id 同时出现在 lastValidPlanInfo 和 validPlanInfo 的两个数组字段中,则认为该素材通过(is_filtered=0),如果素材 id 只出现在 lastValidPlanInfo 数组字段中,则认为该素材未通过(is_filtered= 1)。
sink 表类型:odps/sls,不支持回撤和主键更新机制。
上述逻辑的实现 sql 如下:
SELECT`user_id`,trace_id,`timestamp`,material_id,min(is_filtered)) as is_filtered -- 最后group by聚合,每个素材得到唯一的标签FROM (SELECT`user_id`,trace_id,`timestamp`,material_id,1 as is_filtered -- lastValidPlanInfo字段中出现的素材都打上1的被过滤标签FROM dwd_log_parsing,lateral table(string_split(lastValidPlanInfo, ';')) as t1(material_id)WHERE lastValidPlanInfo IS NOT NULLUNION ALLSELECT`user_id`,trace_id,`timestamp`,material_id,0 as is_filtered -- validPlanInfo字段中出现的素材都打上0的被过滤标签FROM dwd_log_parsing,lateral table(string_split(validPlanInfo, ';')) as t2(material_id)WHERE validPlanInfo IS NOT NULL)GROUP BY`user_id`,trace_id,`timestamp`,material_id
复制代码
3.2 问题及原因
问题发现
原始数据样例:根据下图可以发现 1905 和 1906 两个素材 id 出现在 lastValidPlanInfo 中,只有 1906 这个 id 出现在 validPlanInfo 字段中,说明 1905 被过滤掉了,1906 通过了。

期望的计算结果应该是:
但是最终写入到 odps 的结果如下图,可以发现 material_id 为 1906 出现了两条结果,且不一致,所以我们不禁产生了一个疑问:是 fink 中的 group by 失效了吗?

原因分析
由于 odps sink 表不支持回撤和 upsert 主键更新机制,因此对于每一条源表的流数据,只要进入到 operator 算子并产生结果,就会直接将该条结果写入到 odps。
union all 和 lateral table 的使用都会把一条流数据拆分为多条流数据。上述代码中首先使用到了 lateral table 将 lastValidPlanInfo 和 validPlanInfo 数组字段中的 material_id 数字拆分为多条 material_id,然后再使用 union all+group by 实现过滤打标功能,这些操作早已经将原 tt 流中的一条流数据拆分成了多条。
综合上述两点,
-
针对 1906 的素材 id,由于 lateral table 的使用,使得其和 1905 成为了两条独立的流数据;
-
由于 union all 的使用,又将其拆分为 is_filtered =1 的一条流数据(union all 的前半部分),和 is_filtered=0 的一条流数据(union all 的后半部分);
-
由于 flink 一次只能处理一条流数据,因此如果先处理了素材 1906 的 is_filtered=1 的流数据,经过 group by 和 min(is_filtered)操作,将 is_filtered= 1 的结果先写入到 odps,然后再处理 is_filtered=1 的流数据,经过 group by 和 min(is_filtered)操作,状态更新 is_filtered 的最小值变更为 0,又将该条结果写入到 odps。
-
由于 odps 不支持回撤和主键更新,因此会存在两条素材 1906 的数据,且结果不一致。
3.3 解决方法
-
思路:既然 lateral table 和 union all 的使用,会把一条流数据变为多条,并引发了后续的多次写入的问题。因此我们考虑让这些衍生出的多条流数据可以一次性进入到 group by 中参与聚合计算,最终只输出 1 条结果。
-
实现:mini-batch 微批处理
table.exec.mini-batch.enabled: truetable.exec.mini-batch.allow-latency: 1s
复制代码
-
概念:mini-batch 是缓存一定的数据后再触发处理,以减少对 State 的访问,从而提升吞吐并减少数据的输出量。微批处理通过增加延迟换取高吞吐,如果您有超低延迟的要求,不建议开启微批处理。通常对于聚合场景,微批处理可以显著地提升系统性能,建议开启。
-
效果:上述问题得到解决,odps 表只输出每个用户的每次请求的每个素材 id 只有 1 条数据输出。
四、总结
FlinkSQL 的开发是最方便高效的实时数据需求的实现途径,但是它和离线的 ODPS SQL 开发在底层的机制和原理上还是有很大的区别,根本的区别就在于流和批的处理。如果按照我们已经习惯的离线思维来写 FlinkSQL,就可能会出现一些“离奇”的结果,但是遇到问题并不可怕,要始终相信根本不存在任何“离奇”,所有的问题都是可以追溯到原因的,而在这个探索的过程中,也可以学习到许多知识,所以让我们遇到更多的问题,积累更多的经验,熟练地应用 Flink。
参考链接
[01] 窗口
https://help.aliyun.com/zh/flink/developer-reference/overview-4?spm=a2c4g.11186623.0.i33
[02] 高性能优化:
https://help.aliyun.com/zh/flink/user-guide/optimize-flink-sql
相关文章:
FlinkSQL 开发经验分享
作者:汤包 最近做了几个实时数据开发需求,也不可避免地在使用 Flink 的过程中遇到了一些问题,比如数据倾斜导致的反压、interval join、开窗导致的水位线失效等问题,通过思考并解决这些问题,加深了我对 Flink 原理与机…...
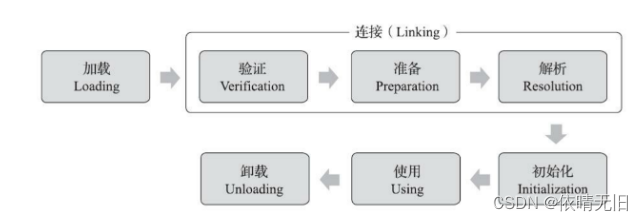
JVM原理(十二):JVM虚拟机类加载过程
一个类型从被加载到虚拟机内存中开始,到卸载为止,它的整个生命周期将会经过 加载、验证、准备、解析、初始化、使用、卸载七个阶段。其中 验证、准备、解析三个部分统称为 连接 1. 加载 加载是整个类加载的一个过程。在加载阶段,Java虚拟机…...
)
Apipost接口测试工具的原理及应用详解(三)
本系列文章简介: 随着软件行业的快速发展,API(应用程序编程接口)作为不同软件组件之间通信的桥梁,其重要性日益凸显。API的质量直接关系到软件系统的稳定性、性能和用户体验。因此,对API进行严格的测试成为软件开发过程中不可或缺的一环。在众多API测试工具中,Apipost凭…...

unity里鼠标位置是否在物体上。
1. 使用Raycast 如果你的图片是在UI Canvas上,可以使用Raycast来检测鼠标点击是否在图片上。 using UnityEngine; using UnityEngine.EventSystems; using UnityEngine.UI; public class ImageClickChecker : MonoBehaviour { public Image targetImage; voi…...

Java知识点大纲
文章目录 第一阶段:JavaSE1、面向对象编程(基础)1)面向过程和面向对象区别2)类和对象的概述3)类的属性和方法4)创建对象内存分析5)构造方法(Construtor)及其重载6)对象类型的参数传递7)this关键字详解8)static关键字详解9)局部代码块、构造代码块和静态代码块10)pac…...
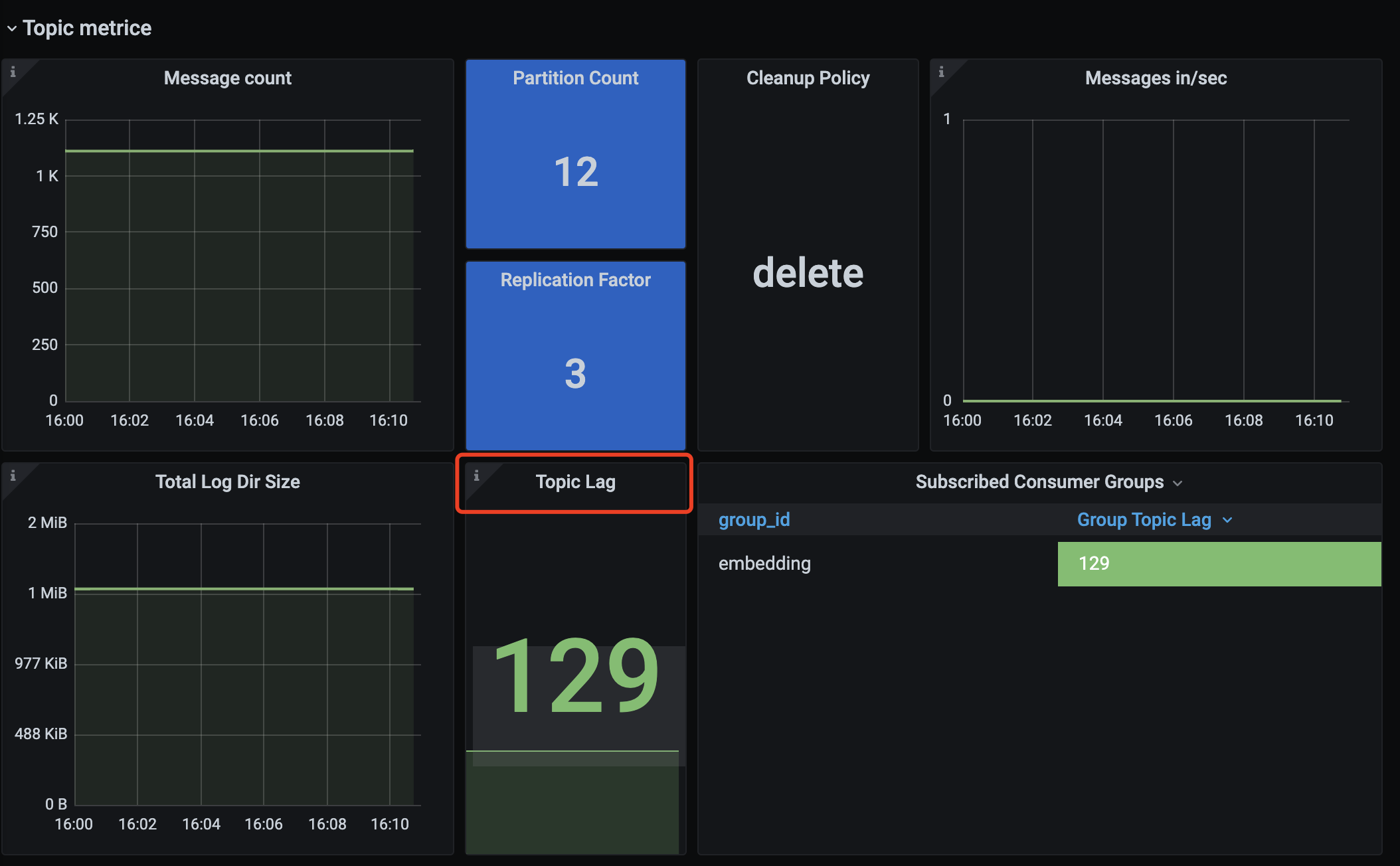
【Kafka】记录一次Kafka消费者重复消费问题
文章目录 现象业务背景排查过程Push与Pull 现象 用户反馈消费者出现消息积压,并且通过日志看,一直重复消费,且没有报错日志。 业务背景 用户的消费者是一个将文件做Embedding的任务,(由于AI技术的兴起,大…...
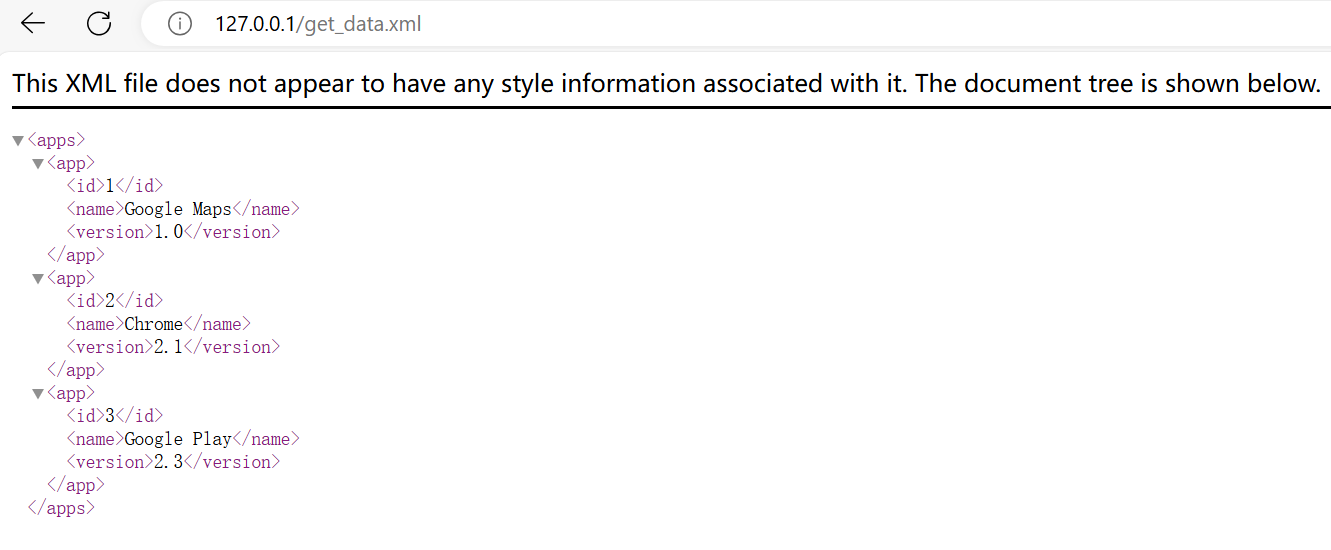
Android使用http加载自建服务器静态网页
最终效果如下图,成功加载了电脑端的静态网页内容,这是一个xml文件。 电脑端搭建http服务器 使用“Apache Http Server”,下载地址是:https://httpd.apache.org/download.cgi。 安装启动步骤,参考:Apach…...

python解耦重构,提高程序维护性
一、重构思想 思路来源 java spring设计模式学习,强调低耦合的思想,通过解耦来提高程序的可维护性。 二、代码重构 解决方案 通过单独配置文件来控制变量的改变。 spring的话可以读取xml或者是springboot 读取application.properties 来获取变量值。…...

深入解析 Laravel 事件系统:架构、实现与应用
Laravel 的事件系统是框架中一个强大且灵活的功能,它允许开发者在应用程序中定义和使用自定义事件和监听器。这个系统基于观察者模式,使得代码解耦和可维护性大大提高。在本文中,我们将深入探讨 Laravel 事件系统的工作原理、如何实现自定义事…...

视频怎么制作gif动态图片?GIF制作方法分享
视频怎么制作gif动态图片?视频制作GIF动态图片,不仅保留了视频的生动瞬间,还赋予了图像循环播放的魔力。这一技能不仅让创意表达更加丰富多彩,还极大地提升了视觉传播的效率和趣味性。在快节奏的数字时代,GIF动图以其小…...
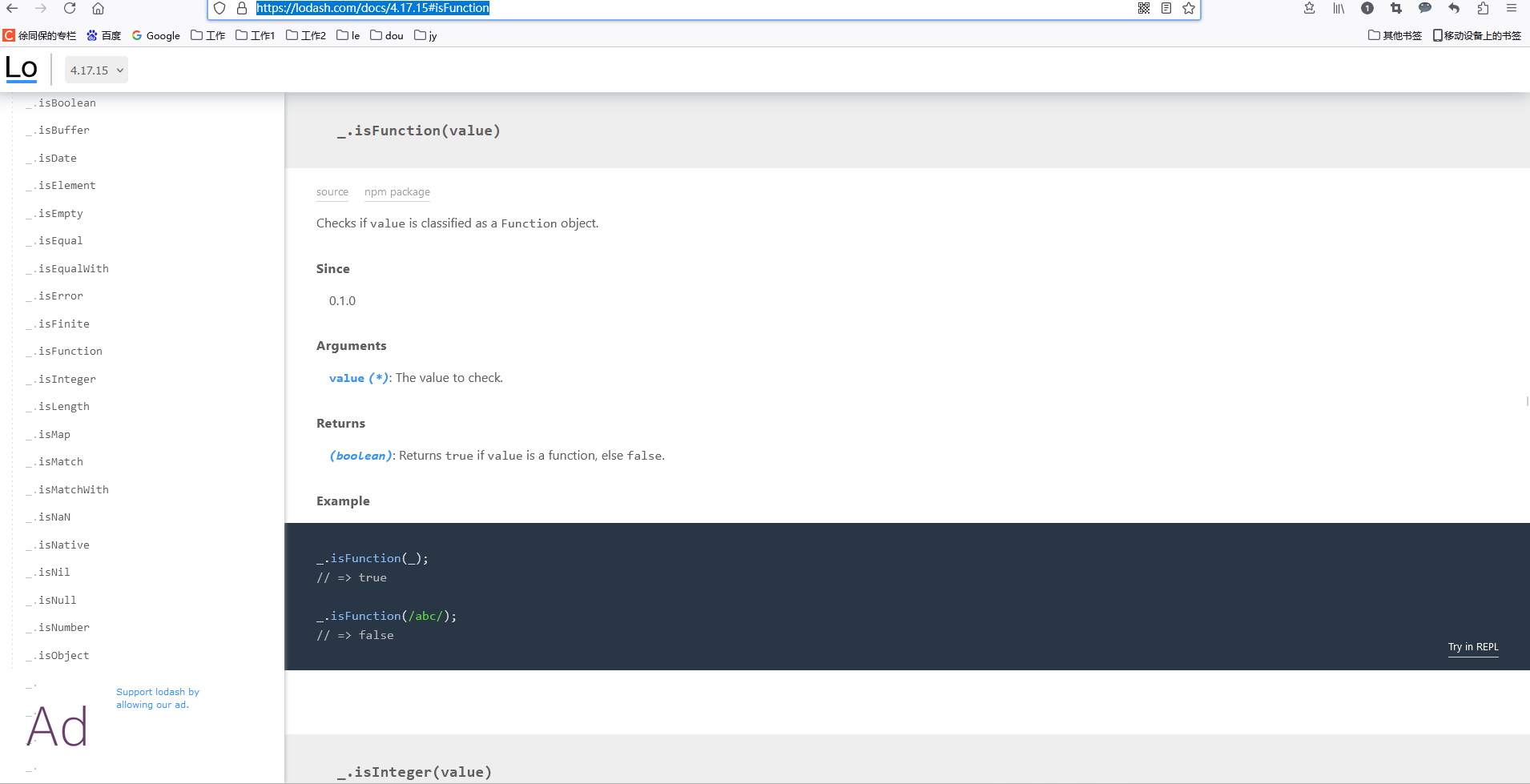
js 使用 lodash-es 检测某个值是否是函数
import { isFunction } from lodash-eslet isA isFunction(() > {}) console.log(isA) //true https://www.lodashjs.com/docs/lodash.isFunction#_isfunctionvalue https://lodash.com/docs/4.17.15#isFunction 人工智能学习网站 https://chat.xutongbao.top...

[go-zero] goctl 生成api和rpc
文章目录 1.goctl 概述2.go-zero 需要安装的组件3.生成 api4.生成 rpc 1.goctl 概述 goctl支持多种rpc,较为流行的是google开源的grpc,这里主要介绍goctl rpc protoc的代码生成与使用。protoc是grpc的命令,作用是将proto buffer文件转化为相…...
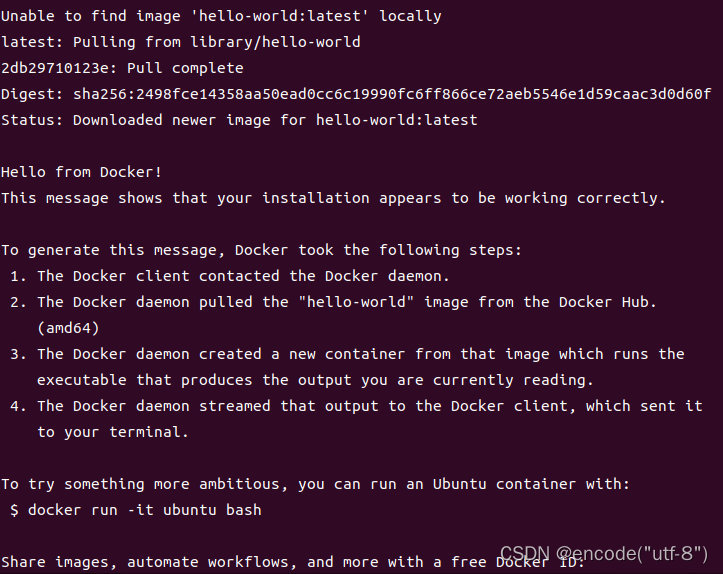
docker -run hello-world超时
主要原因就是尝试拉取库的时候没有从阿里云镜像里拉,所以设置一下就好了 这里使用的是ubuntu系统(命令行下逐行敲就行了) sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-EOF {"registry-mirrors": [&quo…...
黎曼度量曲面与高斯曲率)
拓扑学习系列(8)黎曼度量曲面与高斯曲率
黎曼度量 黎曼度量是黎曼几何中的一个重要概念,它用来描述流形上的切向量之间的长度和角度。黎曼度量赋予了流形一个内积结构,使得我们可以定义切向量的长度、夹角和内积,从而引入了度量空间的概念。让我更详细地解释一下黎曼度量࿱…...
:i.MX linux BSP)
汽车IVI中控开发入门及进阶(三十四):i.MX linux BSP
开发板: 汽车IVI中控开发入门及进阶(三十三):i.MX linux开发之开发板-CSDN博客 linux 开发项目: 汽车IVI中控开发入门及进阶(三十二):i.MX linux开发之Yocto-CSDN博客 前言: 有了开发板,linux BSP编译项目yocto,接下来就可以在i.MX平台上构建和安装i.MX Linux …...

【Python机器学习】算法链与管道——构建管道
目录 1、首先,我们构建一个由步骤列表组成的管道对象。 2、向任何其他scikit-learn估计器一样来拟合这个管道 3、调用pipe.score 我们来看下如何使用Pipeline类来表示在使用MinMaxScaler缩放数据后,再训练一个SVM的工作流程(暂时不用网格搜…...

Postman 高级用法学习
Postman 高级用法 Postman 是一款强大的 API 调试和开发工具,广泛应用于 API 开发、测试、调试和自动化流程中。除了基本的 API 请求发送和响应查看功能,Postman 还提供了许多高级功能。以下是详细的讲解,包括具体示例和操作步骤。 一、环境…...
)
从新手到高手:Scala函数式编程完全指南,Scala 访问修饰符(6)
1、Scala 访问修饰符 Scala 访问修饰符基本和Java的一样,分别有:private,protected,public。 如果没有指定访问修饰符,默认情况下,Scala 对象的访问级别都是 public。 Scala 中的 private 限定符ÿ…...
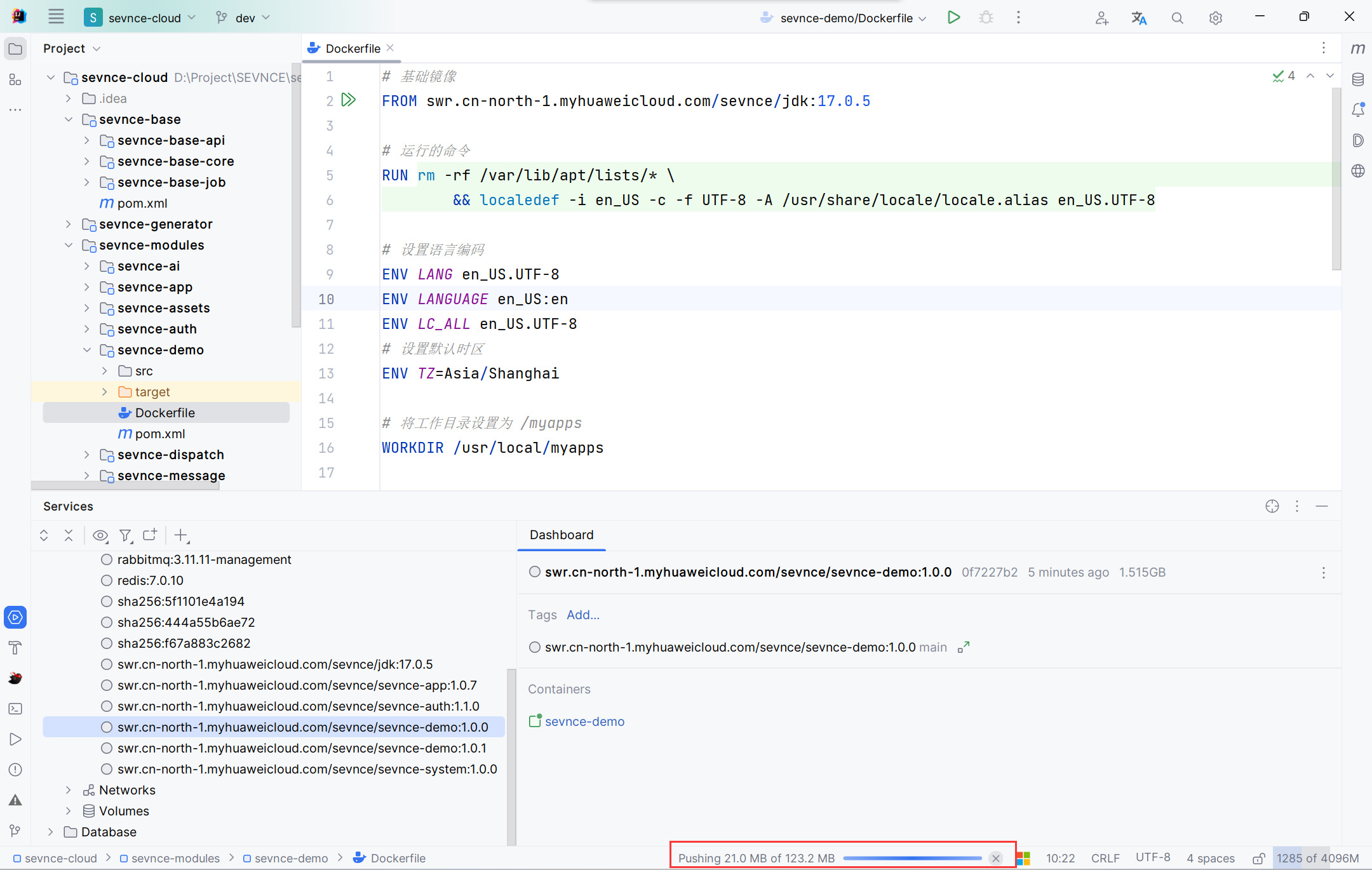
IDEA 一键部署Docker
以部署示例服务(sevnce-demo)为例。 配置服务器 地址、账号、密码根据实际情况填写 配置镜像仓库 地址、账号、密码根据实际情况填写 编写Dockerfile 在sevnce-demo根目录下右键,选择创建Dockerfile。 # 基础镜像 FROM sevnce-registry.c…...

linux centos tomcat 不安全的HTTP请求方法
1、页面查看 2、在linux主机可使用此命令查看 curl -v -X OPTIONS http://实际地址 3、进入tomcat conf目录vim web.xml,增加以下内容 <!-- close insecure http methods --> <security-constraint><web-resource-collection><web-resource…...

用STM32CubeMX和HAL库快速上手WS2812B:告别手动计算延时,一键生成驱动框架
基于STM32CubeMX的WS2812B智能灯光控制:从零构建现代化驱动方案在智能硬件和物联网设备快速发展的今天,WS2812B可编程LED灯带因其丰富的色彩表现和简单的单线控制方式,成为创客和工程师们最喜爱的显示组件之一。然而,传统的寄存器…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

JWT弱密钥爆破实战:从HS256签名原理到CTF权限提升
1. 这不是密码学考试,而是一场“密钥猜谜”实战JWT(JSON Web Token)在现代Web系统中早已不是可选项,而是默认配置。登录成功后返回一串形如eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsIm5hbWUiOiLnlKjliYkiLCJpYX…...

告别繁琐审核!实测AI Agent如何重塑复杂非结构化票据与合同处理流程?
摘要:在企业数字化转型步入深水区的2026年,处理复杂非结构化票据与合同已成为横亘在财务、法务部门面前的“最后一公里”难题。传统RPA因UI变动易崩溃、主流智能体因缺乏API适配而无法落地,导致大量业务仍依赖低效的人工操作。本文由「企服AI…...

SHAP原理与特征贡献解析
SHAP(SHapley Additive exPlanations)是一种基于博弈论中Shapley值的模型解释方法,它为机器学习模型的预测提供了一种统一、理论完备的特征归因框架。其核心思想是将模型的预测值视为所有特征协同合作的“总收益”,然后公平地分配…...

机器学习加速分子晶体偏振拉曼光谱模拟:非谐效应与准谐效应的分离
1. 项目概述:当机器学习遇见偏振拉曼光谱 偏振-取向拉曼光谱(PO-Raman)一直是我在材料光谱分析领域里觉得既迷人又头疼的技术。它就像给材料的“分子指纹”加上了方向滤镜,能揭示出振动模式在空间中的对称性和各向异性,…...

5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣
5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣 【免费下载链接】HandheldCompanion ControllerService 项目地址: https://gitcode.com/gh_mirrors/ha/HandheldCompanion 你是否正在寻找一款能够彻底改变Windows掌机游戏体验的控制软件…...