DPO算法推导
DPO
-
核心思想:直接使用偏好数据进行策略优化,省去
reward模型策略优化。 -
技术背景知识:
首先给定prompt x,生成两个答案 ( y 1 , y 2 ) Π S F T ( y ∣ x ) (y_1,y_2)~\Pi^{SFT}(y|x) (y1,y2) ΠSFT(y∣x) ,并通过人工标注对比 y 1 , y 2 y_1,y_2 y1,y2 ,获得偏好结果(preference) y w ≻ y l ∣ x y_w\succ y_l|x yw≻yl∣x,其中 w w w和 l l l表示
win和lose。引入奖励模型 r r r , y 1 > y 2 y_1 > y_2 y1>y2 的概率可以表示为
p ( y 1 > y 2 ) = r ∗ ( x , y 1 ) r ∗ ( x , y 1 ) + r ∗ ( x , y 2 ) p(y_1 > y_2) = \frac{r^*(x,y_1)}{r^*(x,y_1)+ r^*(x,y_2)} p(y1>y2)=r∗(x,y1)+r∗(x,y2)r∗(x,y1)
为使得奖励函数均为正数,引入Bradley-Terry模型。-
Bradley-Terry:
p ∗ ( y w ≻ y l ∣ x ) = e x p ( r ∗ ( x , y 1 ) ) e x p ( r ∗ ( x , y 1 ) ) + e x p ( r ∗ ( x , y 2 ) ) p^{*}(y_w\succ y_l|x) = \frac{exp(r^*(x,y_1))}{exp(r^*(x,y_1))+ exp(r^*(x,y_2))} p∗(yw≻yl∣x)=exp(r∗(x,y1))+exp(r∗(x,y2))exp(r∗(x,y1))
交叉熵:令 a x = e x p ( r ∗ ( x , y 1 ) ) a_x = exp(r^*(x,y_1)) ax=exp(r∗(x,y1)), a y = e x p ( r ∗ ( x , y 2 ) ) a_y = exp(r^*(x,y_2)) ay=exp(r∗(x,y2))
L o s s = − E ( a x , a y ) ∼ D [ l n a x a x + a y ] = − E ( x , y w , y l ) ∼ D [ l n e x p ( r ∗ ( x , y w ) ) e x p ( r ∗ ( x , y w ) ) + e x p ( r ∗ ( x , y l ) ) ] = − E ( x , y w , y l ) ∼ D [ l n 1 1 + e x p ( r ∗ ( x , y l ) − r ∗ ( x , y w ) ) ] = − E ( x , y w , y l ) ∼ D [ l n σ ( r ∗ ( x , y w ) − r ∗ ( x , y l ) ) ] Loss = -E_{(a_x,a_y)\sim D}[ln\frac{a_x}{a_x+a_y}] \\ = - E_{(x,y_w,y_l)\sim D}[ln\frac{exp(r^*(x,y_w))}{exp(r^*(x,y_w))+exp(r^*(x,y_l))}] \\ = - E_{(x,y_w,y_l)\sim D}[ln\frac{1}{1+exp(r^*(x,y_l)-r^*(x,y_w))}] \\ = - E_{(x,y_w,y_l)\sim D}[ln \sigma(r^*(x,y_w) -r^*(x,y_l))] \\ Loss=−E(ax,ay)∼D[lnax+ayax]=−E(x,yw,yl)∼D[lnexp(r∗(x,yw))+exp(r∗(x,yl))exp(r∗(x,yw))]=−E(x,yw,yl)∼D[ln1+exp(r∗(x,yl)−r∗(x,yw))1]=−E(x,yw,yl)∼D[lnσ(r∗(x,yw)−r∗(x,yl))] -
KL 散度:
K L ( P ∣ ∣ Q ) = ∑ x ∈ X P ( X ) l o g ( P ( X ) Q ( X ) ) KL(P||Q) = \sum_{x\in X}P(X)log(\frac{P(X)}{Q(X)}) KL(P∣∣Q)=x∈X∑P(X)log(Q(X)P(X))
P ( x ) , Q ( x ) P(x),Q(x) P(x),Q(x) 分别是数据真实分布和模型预测分布。
-
-
DPO目标函数:获取更多的奖励,并尽可能保证与基准模型一致。
m a x π E x ∈ X , y ∈ π [ r ( x , y ) ] − β ⋅ D K L [ π ( y ∣ x ) ∣ ∣ π r e f ( y ∣ x ) ] = m a x π E x ∈ X , y ∈ π [ r ( x , y ) ] − E x ∈ X , y ∈ π [ β ⋅ l o g π ( y ∣ x ) π r e f ( y ∣ x ) ] = m a x π E x ∈ X , y ∈ π [ r ( x , y ) − β ⋅ l o g π ( y ∣ x ) π r e f ( y ∣ x ) ] = m a x π E x ∈ X , y ∈ π [ l o g π ( y ∣ x ) π r e f ( y ∣ x ) − 1 β r ( x , y ) ) ] = m i n π E x ∈ X , y ∈ π [ l o g π ( y ∣ x ) π r e f ( y ∣ x ) − l o g e x p ( 1 β r ( x , y ) ) ] = m i n π E x ∈ X , y ∈ π [ l o g π ( y ∣ x ) π r e f ( y ∣ x ) ⋅ e x p ( 1 β r ( x , y ) ) ] = m i n π E x ∈ X , y ∈ π [ l o g π ( y ∣ x ) 1 Z ( x ) π r e f ( y ∣ x ) ⋅ e x p ( 1 β r ( x , y ) ) − l o g Z ( x ) ] \underset{\pi}{max} E_{x\in X, y \in \pi}[r(x,y)] - \beta·\mathbb{D}_{KL}[\pi(y|x) || \pi_{ref}(y|x)] \\ = \underset{\pi}{max} E_{x\in X, y \in \pi}[r(x,y)] - E_{x\in X, y \in \pi}[\beta·log \frac{\pi(y|x)}{\pi_{ref}(y|x)}] \\ = \underset{\pi}{max} E_{x\in X, y \in \pi}[r(x,y) - \beta·log \frac{\pi(y|x)}{\pi_{ref}(y|x)}] \\ = \underset{\pi}{max} E_{x\in X, y \in \pi}[log \frac{\pi(y|x)}{\pi_{ref}(y|x)}- \frac{1}{\beta}r(x,y))] \\ = \underset{\pi}{min} E_{x\in X, y \in \pi}[log \frac{\pi(y|x)}{\pi_{ref}(y|x)}- log \ \ exp(\frac{1}{\beta}r(x,y))] \\ = \underset{\pi}{min} E_{x\in X, y \in \pi}[log \frac{\pi(y|x)}{\pi_{ref}(y|x)·exp(\frac{1}{\beta}r(x,y))} ] \\ = \underset{\pi}{min} E_{x\in X, y \in \pi}[log \frac{\pi(y|x)}{\frac{1}{Z(x)}\pi_{ref}(y|x)·exp(\frac{1}{\beta}r(x,y))} - log \ \ Z(x) ] \\ πmaxEx∈X,y∈π[r(x,y)]−β⋅DKL[π(y∣x)∣∣πref(y∣x)]=πmaxEx∈X,y∈π[r(x,y)]−Ex∈X,y∈π[β⋅logπref(y∣x)π(y∣x)]=πmaxEx∈X,y∈π[r(x,y)−β⋅logπref(y∣x)π(y∣x)]=πmaxEx∈X,y∈π[logπref(y∣x)π(y∣x)−β1r(x,y))]=πminEx∈X,y∈π[logπref(y∣x)π(y∣x)−log exp(β1r(x,y))]=πminEx∈X,y∈π[logπref(y∣x)⋅exp(β1r(x,y))π(y∣x)]=πminEx∈X,y∈π[logZ(x)1πref(y∣x)⋅exp(β1r(x,y))π(y∣x)−log Z(x)]
令 Z ( x ) Z(x) Z(x) 表示如下:
Z ( x ) = ∑ y π r e f ( y ∣ x ) e x p ( 1 β r ( x , y ) ) Z(x) = \underset{y}{\sum} \pi_{ref}(y|x) exp(\frac{1}{\beta}r(x,y) ) Z(x)=y∑πref(y∣x)exp(β1r(x,y))
令:
1 Z ( x ) π r e f ( y ∣ x ) ⋅ e x p ( 1 β r ( x , y ) ) = π r e f ( y ∣ x ) ⋅ e x p ( 1 β r ( x , y ) ) ∑ y π r e f ( y ∣ x ) e x p ( 1 β r ( x , y ) ) = π ∗ ( y ∣ x ) \frac{1}{Z(x)}\pi_{ref}(y|x)·exp(\frac{1}{\beta}r(x,y)) = \frac{\pi_{ref}(y|x)·exp(\frac{1}{\beta}r(x,y))}{\underset{y}{\sum} \pi_{ref}(y|x) exp(\frac{1}{\beta}r(x,y) )} \\ = \pi^*(y|x) Z(x)1πref(y∣x)⋅exp(β1r(x,y))=y∑πref(y∣x)exp(β1r(x,y))πref(y∣x)⋅exp(β1r(x,y))=π∗(y∣x)
接下来继续对``dpo` 目标函数进行化简:
m i n π E x ∈ X , y ∈ π [ l o g π ( y ∣ x ) 1 Z ( x ) π r e f ( y ∣ x ) ⋅ e x p ( 1 β r ( x , y ) ) − l o g Z ( x ) ] = m i n π E x ∈ X , y ∈ π [ l o g π ( y ∣ x ) π ∗ ( y ∣ x ) − l o g Z ( x ) ] \underset{\pi}{min} E_{x\in X, y \in \pi}[log \frac{\pi(y|x)}{\frac{1}{Z(x)}\pi_{ref}(y|x)·exp(\frac{1}{\beta}r(x,y))} - log \ \ Z(x) ] \\ = \underset{\pi}{min} E_{x\in X, y \in \pi}[log \frac{\pi(y|x)}{\pi^*(y|x)} - log \ \ Z(x) ] \\ πminEx∈X,y∈π[logZ(x)1πref(y∣x)⋅exp(β1r(x,y))π(y∣x)−log Z(x)]=πminEx∈X,y∈π[logπ∗(y∣x)π(y∣x)−log Z(x)]
由于 Z ( x ) Z(x) Z(x) 表达式与 π \pi π 不相关,优化可以直接省去。
m i n π E x ∈ X , y ∈ π [ l o g π ( y ∣ x ) π ∗ ( y ∣ x ) − l o g Z ( x ) ] = m i n π E x ∈ X , y ∈ π [ l o g π ( y ∣ x ) π ∗ ( y ∣ x ) ] = m i n π E x ∼ D [ D K L ( π ( y ∣ x ) ∣ ∣ π ∗ ( y ∣ x ) ) ] \underset{\pi}{min} E_{x\in X, y \in \pi}[log \frac{\pi(y|x)}{\pi^*(y|x)} - log \ \ Z(x) ] \\ = \underset{\pi}{min} E_{x\in X, y \in \pi}[log \frac{\pi(y|x)}{\pi^*(y|x)} ] \\ = \underset{\pi}{min} E_{x \sim D}[\mathbb{D}_{KL}(\pi(y|x) || \pi^*(y|x))] \\ πminEx∈X,y∈π[logπ∗(y∣x)π(y∣x)−log Z(x)]=πminEx∈X,y∈π[logπ∗(y∣x)π(y∣x)]=πminEx∼D[DKL(π(y∣x)∣∣π∗(y∣x))]
当 目标函数最小化,也就是 D K L \mathbb{D}_{KL} DKL 最小化,所满足的条件为:
π ( y ∣ x ) = π ∗ ( y ∣ x ) = 1 Z ( x ) π r e f ( y ∣ x ) ⋅ e x p ( 1 β r ( x , y ) ) \pi(y|x) = \pi^*(y|x) = \frac{1}{Z(x)}\pi_{ref}(y|x)·exp(\frac{1}{\beta}r(x,y)) π(y∣x)=π∗(y∣x)=Z(x)1πref(y∣x)⋅exp(β1r(x,y))
反解奖励函数 r ( x , y ) r(x,y) r(x,y)
r ( x , y ) = β π ( y ∣ x ) π r e f ( y ∣ x ) + β ⋅ l n Z ( x ) r(x,y) = \beta \frac{\pi(y|x)}{\pi_{ref}(y|x)} + \beta · ln \Z(x) r(x,y)=βπref(y∣x)π(y∣x)+β⋅lnZ(x)
求解奖励函数隐式表达后,带入Bradley-Terry 交叉熵函数:
L o s s = − E ( x , y w , y l ) ∼ D [ l n σ ( r ∗ ( x , y w ) − r ∗ ( x , y l ) ) ] = − E ( x , y w , y l ) ∼ D [ l n σ ( β l o g π ( y w ∣ x ) π r e f ( y w ∣ x ) − β l o g π ( y l ∣ x ) π r e f ( y l ∣ x ) ) ] Loss = - E_{(x,y_w,y_l)\sim D}[ln \sigma(r^*(x,y_w) -r^*(x,y_l))] \\ =- E_{(x,y_w,y_l)\sim D}[ln \sigma(\beta log\frac{\pi(y_w|x)}{\pi_{ref}(y_w|x)} - \beta log \frac{\pi(y_l|x)}{\pi_{ref}(y_l|x)})] Loss=−E(x,yw,yl)∼D[lnσ(r∗(x,yw)−r∗(x,yl))]=−E(x,yw,yl)∼D[lnσ(βlogπref(yw∣x)π(yw∣x)−βlogπref(yl∣x)π(yl∣x))]
到此,整个数学部分已推导完毕,不得不说句牛逼plus。
-
梯度表征:
将上述损失进行梯度求导
∇ θ L o s s ( π θ ; π r e f ) = − E ( x , y w , y l ) ∼ D [ β σ ( β l o g π ( y w ∣ x ) π r e f ( y w ∣ x ) − β l o g π ( y l ∣ x ) π r e f ( y l ∣ x ) ) [ ∇ θ l o g π ( y w ∣ x ) − ∇ θ l o g π ( y l ∣ x ) ] ] \nabla_\theta Loss(\pi_{\theta};\pi_{ref}) = - E_{(x,y_w,y_l)\sim D}[\beta \sigma(\beta log\frac{\pi(y_w|x)}{\pi_{ref}(y_w|x)} - \beta log \frac{\pi(y_l|x)}{\pi_{ref}(y_l|x)}) [\nabla_{\theta}log \pi(y_w|x) - \nabla_{\theta}log \pi(y_l|x) ]] ∇θLoss(πθ;πref)=−E(x,yw,yl)∼D[βσ(βlogπref(yw∣x)π(yw∣x)−βlogπref(yl∣x)π(yl∣x))[∇θlogπ(yw∣x)−∇θlogπ(yl∣x)]]
再令:
r ^ ( x , y ) = β π θ ( y ∣ x ) π r e f ( y ∣ x ) \hat{r}(x,y) = \beta \frac{\pi_{\theta}(y|x)}{\pi_{ref}(y|x)} r^(x,y)=βπref(y∣x)πθ(y∣x)
最终形式:
∇ θ L o s s ( π θ ; π r e f ) = − β E ( x , y w , y l ) ∼ D [ σ ( r ^ ∗ ( x , y w ) − r ^ ∗ ( x , y l ) ) ⏟ h i g h e r w e i g h t w h e n r e w a r d e s t i m a t e i s w r o n g [ ∇ θ l o g π ( y w ∣ x ) ⏟ i n c r e a s e l i k e l i h o o d o f y w − ∇ θ l o g π ( y l ∣ x ) ⏟ d e c r e a s e l i k e l i h o o d o f y l ] ] \nabla_\theta Loss(\pi_{\theta};\pi_{ref}) = -\beta E_{(x,y_w,y_l)\sim D}[\underbrace{\sigma(\hat{r}^*(x,y_w) -\hat{r}^*(x,y_l))}_{higher\ weight\ when\ reward\ estimate\ is\ wrong} [\underbrace{\nabla_{\theta}log \pi(y_w|x)}_{\ \ \ \ \ \ \ \ \ increase \ likelihood\ of\ y_w} - \underbrace{\nabla_{\theta}log \pi(y_l|x)}_{decrease \ likelihood \ of \ y_l} ]] ∇θLoss(πθ;πref)=−βE(x,yw,yl)∼D[higher weight when reward estimate is wrong σ(r^∗(x,yw)−r^∗(x,yl))[ increase likelihood of yw ∇θlogπ(yw∣x)−decrease likelihood of yl ∇θlogπ(yl∣x)]] -
改进方法ODPO
dpo缺陷主要是:采用Bradley–Terry model只给出了一个response比另一个response好的概率,而没有告诉我们好的程度。
odpo 核心思想: 把这个好的程度的差距信息引入到偏好的建模里,应该能带来收益,及在dpo损失里添加margin , 这相当于要求偏好回应的评估分数要比非偏好回应的评估分数大,且要大offset值这么多。目的是:加大对靠得比较近的数据对的惩罚力度。
L o s s o d p o = − E ( x , y w , y l ) ∼ D [ l n σ ( r ∗ ( x , y w ) − r ∗ ( x , y l ) ) − δ r ] δ r = α l o g ( r ( y w ) − r ( y l ) ) Loss^{odpo}= - E_{(x,y_w,y_l)\sim D}[ln \sigma(r^*(x,y_w) -r^*(x,y_l)) - \delta_r] \\ \delta_r = \alpha \ log(r(y_w)- r(y_l)) Lossodpo=−E(x,yw,yl)∼D[lnσ(r∗(x,yw)−r∗(x,yl))−δr]δr=α log(r(yw)−r(yl))
-
相似改进方法:
IPOKTO都是不需要奖励模型的;
相关文章:

DPO算法推导
DPO 核心思想:直接使用偏好数据进行策略优化,省去 reward 模型策略优化。 技术背景知识: 首先给定prompt x,生成两个答案 ( y 1 , y 2 ) Π S F T ( y ∣ x ) (y_1,y_2)~\Pi^{SFT}(y|x) (y1,y2) ΠSFT(y∣x) ,并通…...
Qt源码分析:窗体绘制与响应
作为一套开源跨平台的UI代码库,窗体绘制与响应自然是最为基本的功能。在前面的博文中,已就Qt中的元对象系统(反射机制)、事件循环等基础内容进行了分析,并捎带阐述了窗体响应相关的内容。因此,本文着重分析Qt中窗体绘制相关的内容…...

docker 安装 禅道
docker pull hub.zentao.net/app/zentao:20.1.1 sudo docker network create --subnet172.172.172.0/24 zentaonet 使用 8087端口号访问 使用禅道mysql 映射到3307 sudo docker run \ --name zentao2 \ -p 8087:80 \ -p 3307:3306 \ --networkzentaonet \ --ip 172.172.172.…...

【简要说说】make 增量编译的原理
make 增量编译的原理 make是一个工具,它可以根据依赖关系和时间戳来自动执行编译命令。 当您修改了源代码文件后,make会检查它们的修改时间是否比目标文件(如可执行文件或目标文件)新,如果是,就会重新编译…...

DETRs Beat YOLOs on Real-time Object Detection论文翻译
cvpr 2024 论文名称 DETRs在实时目标检测上击败YOLO 地址 https://arxiv.longhoe.net/abs/2304.08069 代码 https://github.com/lyuwenyu/RT-DETR 目录 摘要 1介绍 2.相关工作 2.1实时目标探测器 2.2.端到端物体探测器 3.检测器的端到端速度 3.1.NMS分析 3.2.端到端速度…...
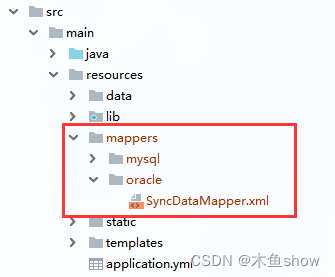
SpringBoot 多数据源配置
目录 一. 引入maven依赖包 二. 配置yml 三、创建 xml 分组文件 四、切换数据源 一. 引入maven依赖包 <dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.6.1&…...

RK3568驱动指南|第十六篇 SPI-第192章 mcp2515驱动编写:完善write和read函数
瑞芯微RK3568芯片是一款定位中高端的通用型SOC,采用22nm制程工艺,搭载一颗四核Cortex-A55处理器和Mali G52 2EE 图形处理器。RK3568 支持4K 解码和 1080P 编码,支持SATA/PCIE/USB3.0 外围接口。RK3568内置独立NPU,可用于轻量级人工…...

#BI建模与数仓建模有什么区别?指标体系由谁来搭建?
问题1: 指标体系是我们数仓来搭建还是分析师来做,如何去推动? 问题2:BI建模与数仓建模有什么区别? 指标体系要想做好,其实是分两块内容的,一块是顶层设计阶段,业务指标体系的搭建&am…...
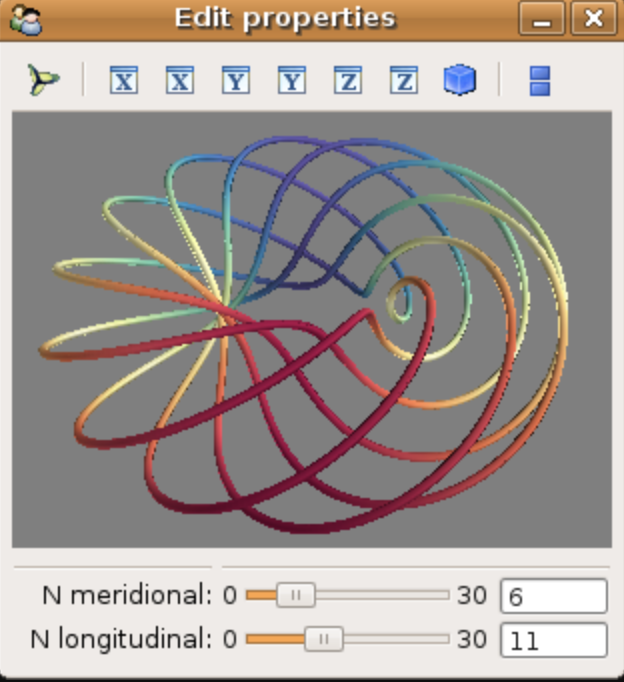
如何用Python实现三维可视化?
Python拥有很多优秀的三维图像可视化工具,主要基于图形处理库WebGL、OpenGL或者VTK。 这些工具主要用于大规模空间标量数据、向量场数据、张量场数据等等的可视化,实际运用场景主要在海洋大气建模、飞机模型设计、桥梁设计、电磁场分析等等。 本文简单…...
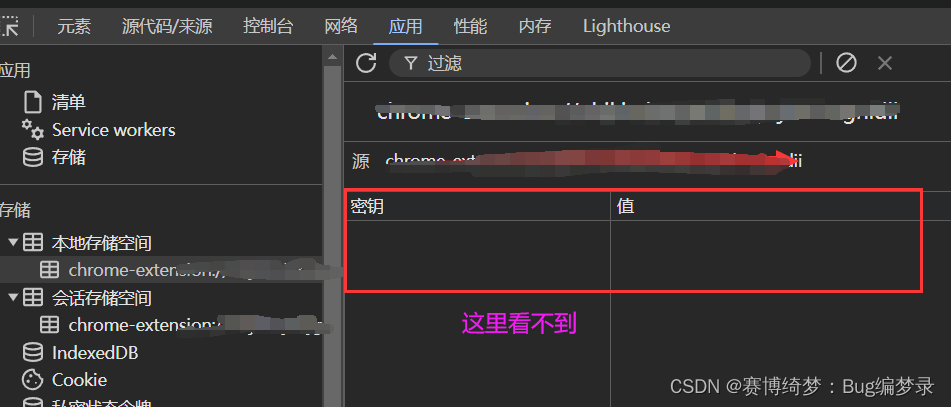
chrome.storage.local.set 未生效
之前chrome.storage.local.set 和 get 一直不起作用 使用以下代码运行成功。 chrome.storage.local.set({ pageState: "main" }).then(() > {console.log("Value is set");});chrome.storage.local.get(["pageState"]).then((result) > …...

泛微开发修炼之旅--30 linux-Ecology服务器运维脚本
文章链接:30 linux-ecology服务器运维脚本...

LeetCode 全排列
思路:这是一道暴力搜索问题,我们需要列出答案的所有可能组合。 题目给我们一个数组,我们很容易想到的做法是将数组中的元素进行排列,如何区分已选中和未选中的元素,容易想到的是建立一个标记数组,已经选中的…...

python实现支付宝异步回调验签
说明 python实现支付宝异步回调验签,示例中使用Django框架。 此方案使用了支付宝的pythonSDK,请一定装最新版本的,支付宝官网文档不知道多久没更新了,之前的版本pip安装会报一些c库不存在的错误; pip install alipay-…...
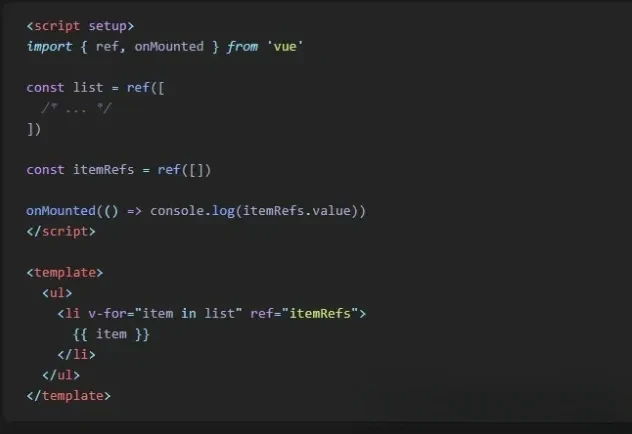
注意!Vue.js 或 Nuxt.js 中请停止使用.value
大家好,我是CodeQi! 一位热衷于技术分享的码仔。 当您在代码中使用.value时,必须每次都检查变量是否存在并且是引用。 这可能很麻烦,因为在运行时使用.value可能会导致错误。然而,有一个简单的解决方法,即使用unref()而不是.value。 unref()会检查变量是否是引用,并自…...

Java:JDK、JRE和JVM 三者关系
文章目录 一、JDK是什么二、JRE是什么三、JDK、JRE和JVM的关系 一、JDK是什么 JDK(Java Development Kit):Java开发工具包 JRE:Java运行时环境开发工具:javac(编译工具)、java(运行…...

Radio专业术语笔记
在收音机的 RDS (Radio Data System) 功能中,CT 代表 “Clock Time”。RDS 是一种数字广播标准,用于在调频广播中传输辅助数据,如电台名称、节目类型、交通信息等。CT 功能是其中的一部分,用于同步和显示广播电台发送的当前时间。…...

cocosCreator找出未用到的图片
最近整理项目的时候发现有些资源文件夹有点轮乱(一些历史原因导致的),而且有很多图片都是没用了的,但是没有被删除掉,还一直放在项目中,导致项目的资源文件夹比较大,而且还冗余。于是今天想着整理一下。 公开免费链接 找出未使用的图片 有好几种方法可以找出未使用的图片…...
一览 Anoma 上的有趣应用概念
撰文:Tia,Techub News 本文来源香港Web3媒体:Techub News Anoma 的目标是为应用提供通用的意图机器接口,这意味着使用 Anoma,开发人员可以根据意图和分布式意图机编写应用,而不是根据事务和特定状态机进行…...

Spring Boot集成fastjson2快速入门Demo
1.什么是fastjson2? fastjson2是阿里巴巴开发的一个高性能的Java JSON处理库,它支持将Java对象转换成JSON格式,同时也支持将JSON字符串解析成Java对象。本文将介绍fastjson2的常见用法,包括JSON对象、JSON数组的创建、取值、遍历…...

Three.js机器人与星系动态场景(二):强化三维空间认识
在上篇博客中介绍了如何快速利用react搭建three.js平台,并实现3D模型的可视化。本文将在上一篇的基础上强化坐标系的概念。引入AxesHelper辅助工具及文本绘制工具,带你快速理解camer、坐标系、position、可视区域。 Three.js机器人与星系动态场景&#x…...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

机器学习结合基因无关通路映射:从临床数据挖掘新药靶点
1. 项目概述:当机器学习遇见代谢通路,如何从数据中“挖”出新药靶点?在生物医学研究的前沿,我们正面临一个核心矛盾:一方面,我们拥有海量的临床数据,比如血糖、血压、BMI等指标;另一…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...
)
Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环)
更多请点击: https://kaifayun.com 第一章:Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环) Lovable 方法论的核心不是交付功能,而是培育“工具依赖感”——当一线工程师在凌晨三点调试线上问题时&am…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...