分子AI预测赛笔记
#AI夏令营 #Datawhale #夏令营
Taks1 跑通baseline
根据task1跑通baseline
注册账号
直接注册或登录百度账号,etc
fork 项目
零基础入门 Ai 数据挖掘竞赛-速通 Baseline - 飞桨AI Studio星河社区
启动项目
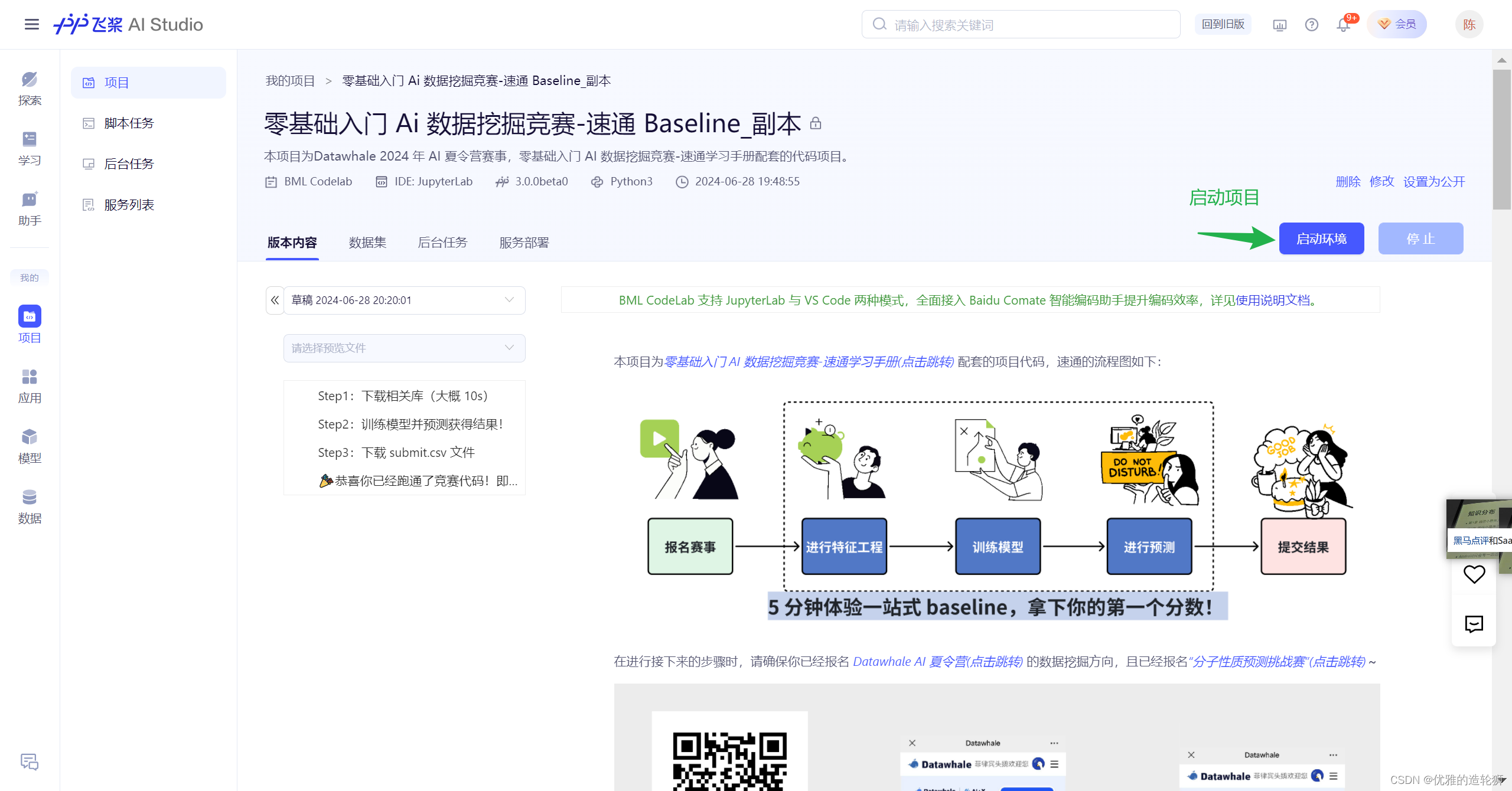
选择运行环境,并点击确定,没有特殊要求就默认的基础版就可以了
等待片刻,等待在线项目启动
 运行项目代码
运行项目代码
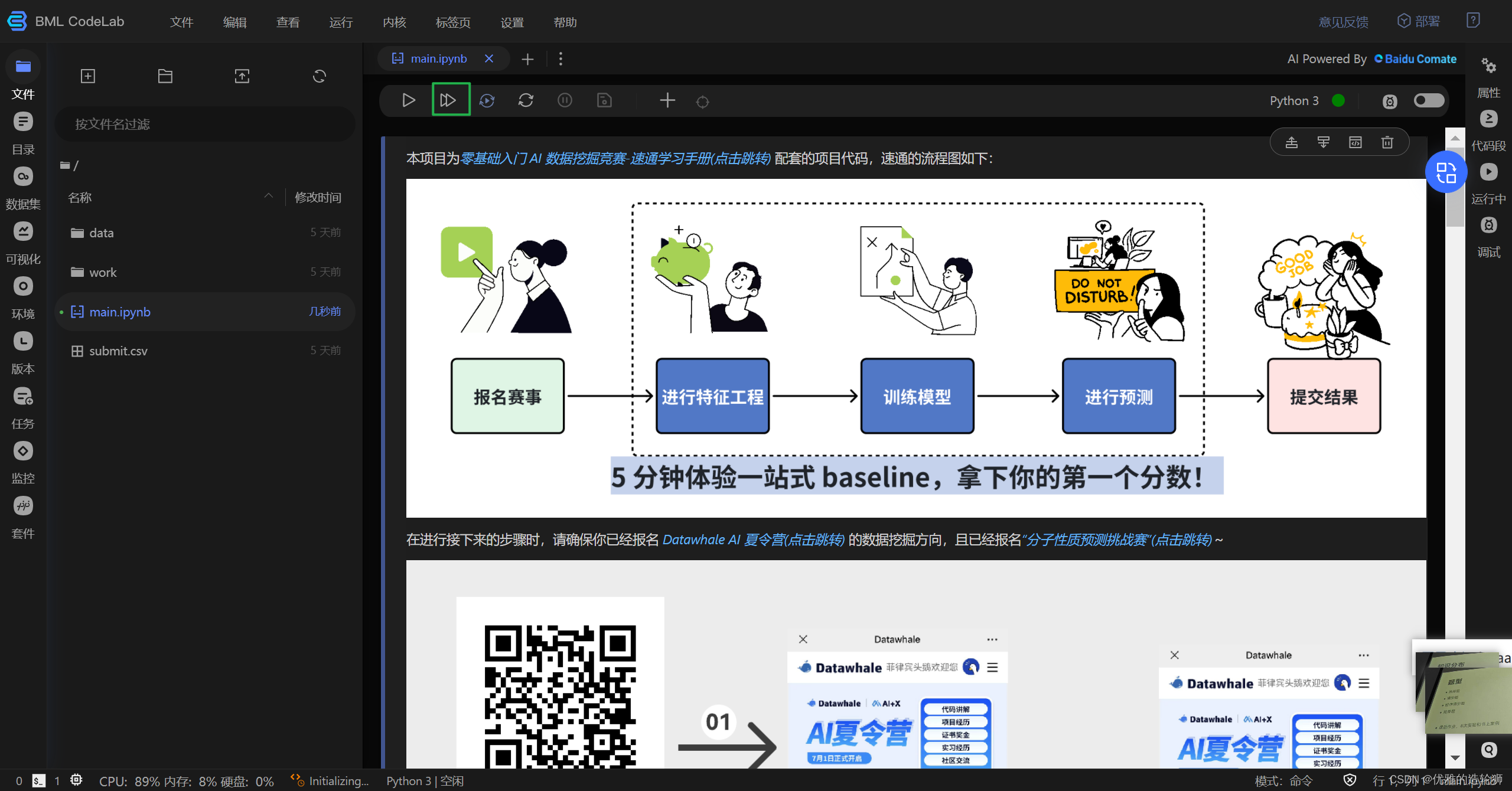
点击 运行全部Cell

程序运行完生成文件 submit.csv

这个文件就最终提交的文件。
Taks2 赛题深入解析
理解赛题,了解机器学习竞赛通用流程
数据字段理解
Docs
对 Smiles、Assay (DC50/Dmax)、Assay (Protac to Target, IC50)、Assay (Cellular activities, IC5、Article DOI、InChI字段学习分析
预测目标
选手需要预测PROTACs的降解能力,具体来说,就是预测Label字段的值。
根据DC50和Dmax的值来判断降解能力的好坏:如果DC50大于100nM且Dmax小于80%,则Label为0;如果DC50小于等于100nM或Dmax大于等于80%,则Label为1。
零基础入门AI(机器学习)竞赛 - 飞书云文档
https://datawhaler.feishu.cn/wiki/Ue7swBbiJiBhsdk5SupcqfL7nLX
Docs
Task3初步调试参数
学习9群助教 【温酒相随】原创, 九月助教编辑调整, 首发于B站~
https://www.bilibili.com/read/cv35897986/?jump_opus=1
导入库、训练集和测试集
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
# 从 lightgbm 模块中导入 LGBMClassifier 类
from lightgbm import LGBMClassifier# 2. 读取训练集和测试集
# 使用 read_excel() 函数从文件中读取训练集数据,文件名为 'traindata-new.xlsx'
train = pd.read_excel('./data/train.xlsx')
# 使用 read_excel() 函数从文件中读取测试集数据,文件名为 'testdata-new.xlsx'
test = pd.read_excel('./data/test.xlsx')
train
查看数据类型
data = train.info()data部分数据的数据项比较少。可以筛掉减少拟合
# 筛选
train = train.iloc[:,1:]
test = test.iloc[:,1:]
# 行保留 列从第一个下标1开始
# train['lan'].value_counts()# language查看object类型的列表
# 查看object类型的列表
train.select_dtypes(include = 'object').columns缺失值查看
# 缺失值查看temp = train.isnull().sum()temp[temp > 0]唯一值个数判断
# 唯一值个数判断
# fea = train.columns
fea = train.columns.tolist()
fea输出唯一值
# 输出唯一值for f in fea:print(f,train[f].nunique());# nunique() 统计列中的唯一值筛选
# 定义了一个空列表cols,用于存储在测试数据集中非空值小于10个的列名。
cols = []
for f in test.columns:if test[f].notnull().sum() < 10:cols.append(f)
cols# 使用drop方法从训练集和测试集中删除了这些列,以避免在后续的分析或建模中使用这些包含大量缺失值的列
train = train.drop(cols, axis=1)
test = test.drop(cols, axis=1)
# 使用pd.concat将清洗后的训练集和测试集合并成一个名为data的DataFrame,便于进行统一的特征工程处理
data = pd.concat([train, test], axis=0, ignore_index=True)
newData = data.columns[2:]将SMILES转换为分子对象列表,并转换为SMILES字符串列表
data['smiles_list'] = data['Smiles'].apply(lambda x:[Chem.MolToSmiles(mol, isomericSmiles=True) for mol in [Chem.MolFromSmiles(x)]])
data['smiles_list'] = data['smiles_list'].map(lambda x: ' '.join(x)) 用TfidfVectorizer计算TF-IDF
tfidf = TfidfVectorizer(max_df = 0.9, min_df = 1, sublinear_tf = True)res = tfidf.fit_transform(data['smiles_list'])转为dataframe格式
# 将结果转为dataframe格式
tfidf_df = pd.DataFrame(res.toarray())
tfidf_df.columns = [f'smiles_tfidf_{i}' for i in range(tfidf_df.shape[1])]
# 按列合并到data数据
data = pd.concat([data, tfidf_df], axis=1)自然数编码
# 自然数编码
def label_encode(series):unique = list(series.unique())return series.map(dict(zip(unique, range(series.nunique()))))
# 对每个类转换为其编码
for col in cols:if data[col].dtype == 'object':data[col] = label_encode(data[col])构建训练集和测试集
# 提取data中label行不为空的,将其作为train的数据并更新索引
train = data[data.Label.notnull()].reset_index(drop=True)
# 提取data中label行为空的,将其作为teat的数据并更新索引
test = data[data.Label.isnull()].reset_index(drop=True)
# 特征筛选
features = [f for f in train.columns if f not in ['uuid','Label','smiles_list']]
# 构建训练集和测试集
x_train = train[features]
x_test = test[features]
# 训练集标签
y_train = train['Label'].astype(int)使用采用5折交叉验证(
KFold(n_splits=5)
def cv_model(clf, train_x, train_y, test_x, clf_name, seed=2022):# 进行5折交叉验证kf = KFold(n_splits=5, shuffle=True, random_state=seed)train = np.zeros(train_x.shape[0])test = np.zeros(test_x.shape[0])cv_scores = []# 每一折数据采用训练索引和验证索引来分割训练集和验证集for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):print('************************************ {} {}************************************'.format(str(i+1), str(seed)))trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]# 配置CatBoost分类器的参数params = {'learning_rate': 0.05, 'depth': 8, 'l2_leaf_reg': 10, 'bootstrap_type':'Bernoulli','random_seed':seed,'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False, 'task_type':'CPU'}# 使用CatBoost分类器训练模型model = clf(iterations=20000, **params, eval_metric='AUC')model.fit(trn_x, trn_y, eval_set=(val_x, val_y),metric_period=100,cat_features=[],use_best_model=True,verbose=1)val_pred = model.predict_proba(val_x)[:,1]test_pred = model.predict_proba(test_x)[:,1]train[valid_index] = val_predtest += test_pred / kf.n_splitscv_scores.append(f1_score(val_y, np.where(val_pred>0.5, 1, 0)))print(cv_scores)print("%s_score_list:" % clf_name, cv_scores)print("%s_score_mean:" % clf_name, np.mean(cv_scores))print("%s_score_std:" % clf_name, np.std(cv_scores))return train, testcat_train, cat_test = cv_model(CatBoostClassifier, x_train, y_train, x_test, "cat")这段代码是一个交叉验证模型的函数,用于训练和评估分类器模型。具体来说,它使用了CatBoost分类器,在给定的训练数据集上进行了5折交叉验证,并返回了训练集和测试集的预测结果。
函数中的参数包括:
- clf: 分类器模型的类对象,这里是CatBoostClassifier。
- train_x, train_y: 训练数据的特征和标签。
- test_x: 测试数据的特征。
- clf_name: 分类器的名称,用于输出结果。
- seed: 随机种子,默认为2022。
函数的主要流程如下:
- 创建了一个5折交叉验证器(KFold)。
- 初始化了训练集和测试集的预测结果数组。
- 在每一折循环中,根据训练索引和验证索引分割训练集和验证集。
- 配置CatBoost分类器的参数,并使用训练集训练模型。
- 对验证集和测试集进行预测,并将预测结果加入到结果数组中。
- 计算并保存每一折验证集的F1分数。
- 输出每一折的F1分数列表、平均分数和标准差。
- 返回训练集和测试集的预测结果。
通过调用这个函数,可以得到CatBoost分类器在给定数据集上的交叉验证结果,评估模型的性能以及获取训练集和测试集的预测结果。
输出结果
from datetime import datetimecurrent_time = datetime.now() # 获取当前时间
formatted_time = current_time.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间# print("当前时间:", current_time)
# print("格式化时间:", formatted_time)
# 5. 保存结果文件到本地
pd.DataFrame({'uuid': test['uuid'],'Label': pred}
).to_csv(formatted_time+ '.csv', index=None)本地torch部分未用
这个夏令营不简单 #AI夏令营 #Datawhale #夏令营
相关文章:
分子AI预测赛笔记
#AI夏令营 #Datawhale #夏令营 Taks1 跑通baseline 根据task1跑通baseline 注册账号 直接注册或登录百度账号,etc fork 项目 零基础入门 Ai 数据挖掘竞赛-速通 Baseline - 飞桨AI Studio星河社区 启动项目 选择运行环境,并点击确定,没…...

003 线程的暂停和中断
文章目录 暂停中断**阻塞情况下中断,抛出异常后线程恢复非中断状态,即 interrupted false**调用Thread.interrupted() 方法后线程恢复非中断状态 暂停 Java中线程的暂停是调用 java.lang.Thread 类的 sleep 方法。该方法会使当前正在执行的线程暂停指定…...

mysql在部署时的问题
1.远程连接是否开放问题 DataGrip远程连接Ubuntu Linux MySQL服务器报错DBMS: MySQL (no ver.)-CSDN博客 【MySQL】DataGrip远程连接MySQL_datagrip连接远程mysql数据库-CSDN博客 一定要把对应端口规则打开 2.远程连接不适用3306作为默认运行端口 打开mysql的配置文件&…...

Flutter集成高德导航SDK(Android篇)(JAVA语法)
先上flutter doctor: flutter sdk版本为:3.19.4 引入依赖: 在app的build.gradle下,添加如下依赖: implementation com.amap.api:navi-3dmap:10.0.700_3dmap10.0.700navi-3dmap里面包含了定位功能,地图功能…...
)
代码随想录Day76(图论Part11)
97.小明逛公园(Floyd) 题目:97. 小明逛公园 (kamacoder.com) 思路: 答案 import java.util.*;public class Main {public static void main(String[] args) {Scanner scanner new Scanner(System.in);int n scanner.nextInt();…...
工程化:Commitlint / 规范化Git提交消息格式
一、理解Commitlint Commitlint是一个用于规范化Git提交消息格式的工具。它基于Node.js,通过一系列的规则来检查Git提交信息的格式,确保它们遵循预定义的标准。 1.1、Commitlint的核心功能 代码规则检查:Commitlint基于代码规则进行检查&a…...

电脑有线网卡和无线网卡的MAC地址
电脑上的无线网卡和有线网卡是两种不同类型的网络接口卡,它们各自有不同的功能和连接方式。 无线网卡: 功能:无线网卡允许计算机通过无线信号连接到网络,通常是Wi-Fi网络。连接方式:无需物理电缆,通过无线…...

代码随想录-DAY②-数组——leetcode 977 | 209
977 思路 使用两个指针分别指向位置 0 和 n−1,每次比较两个指针对应的数,选择较大的那个逆序放入答案并移动指针。这种方法无需处理某一指针移动至边界的情况。 时间复杂度:O(n) 空间复杂度:O(1) 代码 class Solution { pub…...

稀疏数组搜索
题目链接 稀疏数组搜索 题目描述 注意点 字符串数组中散布着一些空字符串words的长度在[1, 1000000]之间字符串数组是排好序的数组中的字符串不重复 解答思路 因为数组中的字符串是排好序的,所以首先想到的是二分查找,先将数组中长度与s相同的字符串…...

存储器类型介绍
存储器 ROM 我们一般把手机和电脑的硬盘当作ROM。ROM的全称是:Read Only Memery,只读存储器,就是只能读不能写的存储器。但是现在的ROM不仅可以读,还可以写数据,比如给手机下载APP,就是给手机上的ROM写数据…...

论文学习笔记1:Federated Graph Neural Networks: Overview, Techniques, and Challenges
文章目录 一、introduction二、FedGNN术语与分类2.1主要分类法2.2辅助分类法 三、GNN-ASSISTED FL3.1Centralized FedGNNs3.2Decentralized FedGNNs 四、FL-ASSISTED GNNS4.1horizontal FedGNNs4.1.1Clients Without Missing Edges4.1.1.1Non-i.i.d. problem4.1.1.2Graph embed…...

[数据集][目标检测]轮椅检测数据集VOC+YOLO格式13826张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):13826 标注数量(xml文件个数):13826 标注数量(txt文件个数):13826 标…...

视频剪辑音乐自动卡点Pr插件 BeatEdit v2.2 免费下载
Premiere Pro 视频剪辑音乐自动卡点鼓点节拍插件 BeatEdit v2.2.000 下载地址 https://prmuban.com/39091.html BeatEdit 检测音乐中的节拍并在 Premiere Pro 时间轴中为它们生成标记。 创建与音乐同步的自动编辑,或让 BeatEdit 协助您的手动编辑过程。 2.2.000&am…...
】为什么Nios® II构建流程报告无法在 Windows WSL 上确定程序大小?)
【INTEL(ALTERA)】为什么Nios® II构建流程报告无法在 Windows WSL 上确定程序大小?
目录 说明 解决方法 说明 由于英特尔 Quartus Prime 专业版软件 19.3 版中的 nios2-elf-stackreport 实用程序出现问题,nios2-elf-stackreport 实用程序确实如此 不报告程序大小或堆栈堆栈大小。 解决方法 要解决此问题,编辑 nios2-stackreport.pl …...

2024年第十四届APMCM亚太地区大学生数学建模竞赛
C 题 基于量子计算的物流配送问题 随着电子商务的迅猛发展,电商平台对物流配送的需求日益增长。为了确保货物能够按时、高效地送达消费者手中,电商平台与第三方物流公司建立了紧密的合作关系。然而,面对大量的货物和多样的目的地,…...

删除账户相关信息
功能需求 获取正确的待删除账户名杀死系统中正在运行的属于该账户的进程确认系统中属于该账户的所有文件删除该账户 1. 获取正确的待删除账户名 #让用户输入账户名 read -t 10 -p "please input account name: " accountif [ -z $account ] thenecho "account…...

JavaSE (Java基础):面向对象(下)
8.7 多态 什么是多态? 即同一方法可以根据发送对象的不同而采用多种不同的方式。 一个对象的实际类型是确定的,但可以指向对象的引用的类型有很多。在句话我是这样理解的: 在实例中使用方法都是根据他最开始将类实例化最左边的类型来定的&…...
Element中的日期时间选择器DateTimePicker和级联选择器Cascader
简述:在Element UI框架中,Cascader(级联选择器)和DateTimePicker(日期时间选择器)是两个非常实用且常用的组件,它们分别用于日期选择和多层级选择,提供了丰富的交互体验和便捷的数据…...

Construct公司 从 0 到 1 基于 Kitex+Istio 的微服务系统建设
本文根据 2024 年 5 月 25 日在上海举办的“云原生✖️AI 时代的微服务架构与技术实践”CloudWeGo 技术沙龙上海站活动中,Construct 服务端总监 Jason 的演讲《从 0 到 1 基于 Kitex Istio 的微服务系统建设》整理而来。 在微服务架构的浪潮中,企业面临…...

day04-组织架构
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1.组织架构-树组件应用树形组件-用层级结构展示信息,可展开或折叠。 2.组织架构-树组件自定义结构3.组织架构-获取组织架构数据4.组织架构-递归转化树形…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验?
Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验? 【免费下载链接】tsukimi A simple third-party Jellyfin client for Linux 项目地址: https://gitcode.com/gh_mirrors/ts/tsukimi 你是否厌倦了网页版Jellyfin的笨重体验&am…...
:openclaw agent 如何触发一次 Agent 运行?)
OpenClaw 源码解析(六):openclaw agent 如何触发一次 Agent 运行?
1. 本期要解决的问题 前几期我们已经从项目整体结构、CLI 命令体系、配置加载、Gateway 运行机制等角度理解了 OpenClaw 的基础框架。到了这一期,可以进一步进入 OpenClaw 最核心的使用动作:用户在终端中执行一条 openclaw agent --message "...&q…...
功能才是宝藏)
Unity Cinemachine相机系统深度使用:除了自动跟随,它的边界限制(Confiner)功能才是宝藏
Unity Cinemachine Confiner:解锁专业级镜头边界控制的实战指南在游戏开发中,镜头控制往往是被低估的艺术。许多开发者对Cinemachine的印象停留在"智能跟随相机"层面,却不知道它的Confiner功能能够彻底改变游戏镜头的专业度。想象一…...

免费岛屿设计工具终极指南:Happy Island Designer 完整教程 [特殊字符]️
免费岛屿设计工具终极指南:Happy Island Designer 完整教程 🏝️ 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友…...
的6个关键参数,选型不踩坑)
别光看手册!手把手教你读懂气体放电管(GDT)的6个关键参数,选型不踩坑
气体放电管实战选型指南:从参数表到电路设计的6个关键决策点 每次打开气体放电管(GDT)的英文数据手册,面对密密麻麻的参数表格和波形图,不少工程师都会陷入选择困难——这些数值到底如何影响实际电路保护效果…...

Python日志框架设计:从基础到高级配置
引言 日志是任何生产级应用不可或缺的组成部分。作为从Python转向Rust的开发者,我深刻理解良好的日志系统对于应用可观测性的重要性。本文将深入探讨Python日志框架的设计原理和最佳实践,帮助你构建高效、可扩展的日志系统。 一、logging模块基础 1.1…...