什么是数据挖掘(python)
文章目录
- 1.什么是数据挖掘
- 2.为什么要做数据挖掘?
- 3数据挖掘有什么用处?
- 3.1分类问题
- 3.2聚类问题
- 3.3回归问题
- 3.4关联问题
- 4.数据挖掘怎么做?
- 4.1业务理解(Business Understanding)
- 4.2数据理解(Data Understanding)
- 4.3数据准备(Data Preparation)
- 4.4 构建模型(Modeling)
- 4.5 评估模型(Evaluation)
- 4.6模型部署(Deployment)
我将借助5W1H 的思想来带你从整体上了解下数据挖掘,比如什么是数据挖掘、为什么要做数据挖掘、在哪些场景下用数据挖掘,以及怎么做数据挖掘。我会从这条主线上逐渐细化,为这个“骨架” 填充肌肉和血液,让它逐渐丰满起来。
1.什么是数据挖掘
这个问题看似很简单,但似乎也很难有一个明确的答案。
如果非要给数据挖掘一个定义的话,那么我认为数据挖掘就是寻找数据中隐含的知识并用于产生商业价值。也就是说,它是我们在数据中(尤其是在大量的数据中)找到一些有价值,甚至是非常有价值的东西的一种手段。
2.为什么要做数据挖掘?
技术与商业就像一对双生子,在互相促进中不断演进发展,随之而来的就是各大公司业务突飞猛进,很多新模式也涌现出来,使得数据量激增。
面对数以千万甚至上亿,以及不同形式的数据,很难再用纯人工,或者纯统计的方法从成千上万的变量中找到其隐含的价值。
我们需要一种规范的解决方案,能够利用并且充分利用这些数据里的每一个部分,通过一些自动化的机器学习算法,从数据中自动提取价值。而数据挖掘就提供了这样一系列的框架、工具和方法,可以处理不同类型的大量数据,并且使用复杂的算法部署,去探索数据中的模式。
总之,数据挖掘的产生动因主要有以下3 点。
- 海量数据。随着互联网技术的发展,数据的生产、收集和存储也越来越方便,海量数据因此产生。比如,我们常用的微信,每天要产生超过380 亿条数据;今日头条每天要发布上百万的新文章;淘宝每天有上千万的包裹要发出。
- 维度众多。在一个多维度的数据中,每增加一个维度都会增加数据分析的复杂程度。比如点外卖事件涉及的维度就有:浏览饭店的菜品(形式有文字、图片或语言、视频等)、浏览时间、下单价格、交易处理、分配配送员及GPS 信息、完成订单后的评价等。
- 问题复杂。通常用数据挖掘解决的问题都比较复杂,很难用一些规则或者简单的统计给出结果。如果让开发者写一个微波炉的智能控制逻辑,我想难度不是很大,即便是有十几个,甚至几十个按钮的控制中心也不过是多花费一点时间而已。但如果编写一段代码来区分某图片中是否有一只猫咪,那要考虑的问题就太多了,使用传统的方法很难解决,而这恰恰是数据挖掘所擅长的。
以上是我们进行数据挖掘的初衷,在后续的课程中你也会看到,随着这些问题的出现,它们在数据挖掘中是如何被解决的。
3数据挖掘有什么用处?
既然数据挖掘是一种方法,那就要用它去解决一些问题。下面我就来具体讲一下你最关心的,也是最实际的问题,数据挖掘到底有什么用处。
3.1分类问题
分类问题是最常见的问题。比如新闻网站,判断一条新闻是社会新闻还是时政新闻,是体育新闻还是娱乐新闻?这就是一个分类问题,也就是对已知类别的数据进行学习,为新的内容标注一个类别。
3.2聚类问题
聚类与分类不同,聚类的类别预先是不清楚的,我们的目标就是要去发现这些类别。聚类的算法比较适合一些不确定的类别场景。
比如我们出去玩,捡了一大堆不同的树叶回来,你不知道这些树叶是从什么树上掉落的,但是你可以根据它们的大小、形状、纹路、边缘等特征给树叶进行划分,最后得到了三个较小的树叶堆,每一堆树叶都属于同一个种类。
3.3回归问题
简单来说,回归问题可以看作高中学过的解线性方程组。它的最大特点是,生成的结果是连续的,而不像分类和聚类生成的是一种离散的结果。
比如,使用回归的方法预测北京某个房子的总价(y),假设总价只跟房子的面积(x)有关,那么我们构建的方程式就是ax+b=y。如何根据已知x 和y 的值解出a 和b 就是回归问题要解决的。回归方法是通过构建一个模型去拟合已知的数据(自变量),然后预测因变量结果。
3.4关联问题
关联问题最常见的一个场景就是推荐,比如,你在京东或者淘宝购物的时候,在选中一个商品之后,往往会给你推荐几种其他商品组合,这种功能就可以使用关联挖掘来实现。
4.数据挖掘怎么做?
数据挖掘,也是有方法论的。实际上,数据挖掘经过了数十年的发展和无数专家学者的研究,有很多人提出了完整的流程框架,这对于我们来说简直是福音。当然,如果你在使用的过程中觉得这些东西有问题,或者还有改进的空间,那也不要惧怕权威,尽信书则不如无书嘛。
在这里,我讲一个应用最多的CRISP-DM(Cross-industry Standard Process for Data Mining,跨行
业数据挖掘标准流程)方法论,不要被这么长的名字吓到,这里我们先简单地了解数据挖掘的操作步骤有哪些,后面我也会逐一详细讲解。
下面我们就来看一下,如何依照这6 个步骤进行数据挖掘。
4.1业务理解(Business Understanding)
想象你在一个外贸公司上班,有一天,你的老板突然给你说:“小明啊,你能不能训练一个模型来预测一下明年公司的利润呢?”这就是一个业务需求了,若要解决这个问题,首先要弄明白需求是什么,这就是业务理解,或者也可以叫作商业理解。比如,你要搞清楚什么是利润、利润的构成是什么样的、利润受什么影响,同时老板说的利润是净利润还是毛利润等问题。
业务理解,主旨是理解你的数据挖掘要解决什么业务问题。任何公司启动数据挖掘,都是想为业务赋能,因此我们必须从商业或者从业务的角度去了解项目的要求和最终的目的,去分析整个问题涉及的资源、局限、设想,甚至是风险、意外等情况。从业务出发,到业务中去。
4.2数据理解(Data Understanding)
明白了问题,还要明白解决问题需要什么数据。比如这个时候,你的老板又跟你说了:“小明啊,我想改改需求,能不能多做几个模型,把竞品公司明年的利润也都算算,我想对比一下。” 然而“巧妇难为无米之炊”,你根本就没有这个数据,这个需求也就无从完成了。数据理解阶段始于数据的收集工作,但我认为重点是在业务理解的基础上,对我们所掌握的数据要有一个清晰、明确的认识,了解有哪些数据、哪些数据可能对目标有影响、哪些可能是冗余数据、哪些数据存在不足或缺失,等等。需要注意的是,数据理解和业务理解是相辅相成的,因此你在制定数据挖掘计划的时候,不能只是单纯地谈需求,这也是大多数初入门的数据挖掘工程师容易忽略的。数据理解得不好,很可能会导致你对业务需求的错误评估,从而影响后续进度甚至是结果。
4.3数据准备(Data Preparation)
完成上面两个步骤后,我们就可以准备数据了。你需要找销售要销售数据,找采购要采购数据,找财务要各种收入、支出数据,然后整理所有需要用到的数据,想办法补全那些缺失的数据,计算各种统计值,等等。数据准备就是基于原始数据,去构建数据挖掘模型所需的数据集的所有工作,包括数据收集、数据清洗、数据补全、数据整合、数据转换、特征提取等一系列动作。
事实上,在大多数的数据挖掘项目中,数据准备是最困难、最艰巨的一步。如果你的数据足够干净和完整,那么在建模和评估阶段所付出的精力就越少,甚至都不必去使用什么复杂的模型就可以得到足够好的效果,所以这个阶段也是十分重要的。
4.4 构建模型(Modeling)
也可以叫作训练模型,在这一阶段,我们会把准备好的数据喂给算法,所以这个阶段重点解决的是技术方面的问题,会选用各种各样的算法模型来处理数据,让模型学习数据的规律,并产出模型用于后续的工作。
对于同一个数据挖掘的问题类型,可以有多种方法选择使用。如果有多重技术要使用,那么在这一任务中,对于每一个要使用的技术要分别对待。一些建模方法对数据的形式有具体的要求,比如SVM 算法只能输入数值型的数据,等等。因此,在这一阶段,重新回到数据准备阶段执行某些任务有时是非常必要的。
4.5 评估模型(Evaluation)
在模型评估阶段,我们已经建立了一个或多个高质量的模型。但是模型的效果如何,能否满足我们的业务需求,就需要使用各种评估手段、评估指标甚至是让业务人员一起参与进来,彻底地评估模型,回顾在构建模型过程中所执行的每一个步骤,以确保这些模型达到了目标。在评估之后会有两种情况,一种是评估通过,进入到上线部署阶段;另一种是评估不通过,那么就要反过来再进行迭代更新了。
4.6模型部署(Deployment)
整理了数据,研究了算法模型,并通过了多方评估,终于到了部署阶段。此时可能还要解决一些实际的问题,比如长期运行的模型是否有足够的机器来支撑,数据量以及并发程度会不会造成我们部署的服务出现问题,等等。但是,关于数据挖掘的生命周期可能还远未结束,关于一些特殊情况的出现可能仍然无法处理,以及在后续的进程中,随着新数据的生产以及变化,我们的模型仍然会发生一些变化。所以部署是一个挖掘项目的结束,也是一个数据挖掘项目的开始。
相关文章:
)
什么是数据挖掘(python)
文章目录 1.什么是数据挖掘2.为什么要做数据挖掘?3数据挖掘有什么用处?3.1分类问题3.2聚类问题3.3回归问题3.4关联问题 4.数据挖掘怎么做?4.1业务理解(Business Understanding)4.2数据理解(Data Understanding&#x…...

【Tomcat】Linux下安装帆软(fineReport)服务器 Tomcat
需求:帆软(fineReport)数据集上传至服务器 工具:XSHELL XFTP 帮助文档 一. 安装帆软服务器Tomcat 提供 Linux X86 和 Linux ARM 两种类型的部署包 ,所以在下载部署钱需要确认系统架构不支持在 32 位操作系统上安装 查…...

C++ | Leetcode C++题解之第213题打家劫舍II
题目: 题解: class Solution { public:int robRange(vector<int>& nums, int start, int end) {int first nums[start], second max(nums[start], nums[start 1]);for (int i start 2; i < end; i) {int temp second;second max(fi…...

windows系统中快速删除node_modules文件
npx命令方式 npx rimraf node_modules 项目中设置 "scripts": {# 安装依赖"i": "pnpm install",# 检测可更新依赖"npm:check": "npx npm-check-updates",# 删除 node_modules"clean": "npx rimraf node_m…...
返回值为void类型的页面跳转)
Spring MVC数据绑定和响应——页面跳转(一)返回值为void类型的页面跳转
一、返回值为void类型的页面跳转到默认页面 当Spring MVC方法的返回值为void类型,方法执行后会跳转到默认的页面。默认页面的路径由方法映射路径和视图解析器中的前缀、后缀拼接成,拼接格式为“前缀方法映射路径后缀”。如果Spring MVC的配置文件中没有配…...

CSS动画keyframes简单样例
一、代码部分 1.html <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><link rel"stylesheet" href…...
LabVIEW风机跑合监控系统
开发了一种基于LabVIEW的风机跑合监控系统,提高风机测试的效率和安全性。系统通过自动控制风机的启停、实时监控电流和功率数据,并具有过流保护功能,有效减少了人工操作和安全隐患,提升了工业设备测试的自动化和智能化水平。 项目…...

sql语句练习注意点
1、时间可以进行排序,也可以用聚合函数对时间求最大值max(时间) 例如下面的例子:取最晚入职的人,那就是将入职时间倒序排序,然后limit 1 表: 场景:查找最晚入职员工的所有信息 se…...

如视“VR+AI”实力闪耀2024世界人工智能大会
7月4日,2024世界人工智能大会暨人工智能全球治理高级别会议(以下简称为“WAIC 2024”)在上海盛大开幕,本届大会由外交部、国家发展和改革委员会、教育部等部门共同主办,围绕“以共商促共享 以善治促善智”主题…...

华为云交付模式和技术支持
华为云交付模式概览 用户由于自身或者企业属性的原因,对于使用云服务的要求也会有所不同。因此,华为云针对于不同用户的不同要求,提供了以下三种交付模式供用户选择。 公有云模式 公有云的核心属性是共享资源服务华为公有云为个人和企业用户…...

RK3568平台(opencv篇)ubuntu18.04上安装opencv环境
一.什么是 OpenCV-Python OpenCV-Python 是一个 Python 绑定库,旨在解决计算机视觉问题。 Python 是一种由 Guido van Rossum 开发的通用编程语言,它很快就变得非常流行,主要是 因为它的简单性和代码可读性。它使程序员能够用更少的代码行…...

R-CNN:深度学习在目标检测中的革命
R-CNN:深度学习在目标检测中的革命 目标检测是计算机视觉领域的一个核心问题,而R-CNN(Regions with Convolutional Neural Networks)算法是这一领域的一个重要里程碑。R-CNN及其后续的多种变体,如Fast R-CNN和Faster …...
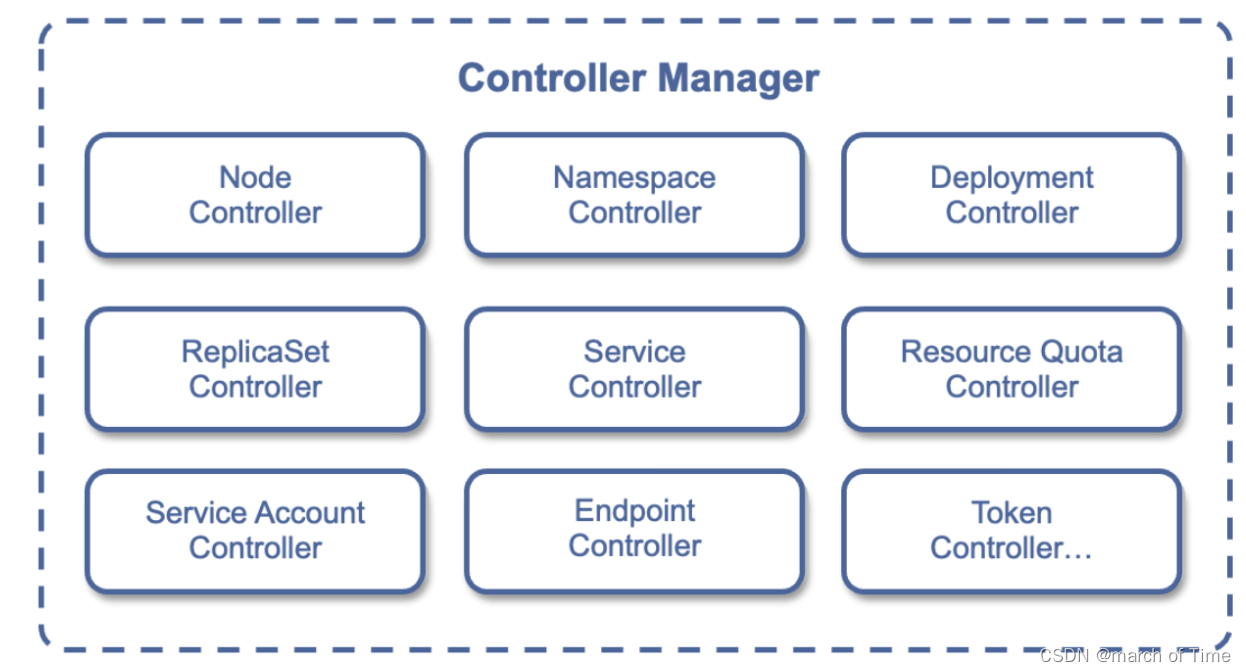
docker容器技术、k8s的原理和常见命令、用k8s部署应用步骤
容器技术 容器借鉴了集装箱的概念,集装箱解决了什么问题呢?无论形状各异的货物,都可以装入集装箱,集装箱与集装箱之间不会互相影响。由于集装箱是标准化的,就可以把集装箱整齐摆放起来,装在一艘大船把他们…...
ThinkPHP定时任务是怎样实现的?
接到一个需求:定时检查设备信息,2分钟没有心跳的机器,推送消息给相关人员,用thinkphp5框架,利用框架自带的任务功能与crontab配合来完成定时任务。 第一步:分析需求 先写获取设备信息,2分钟之…...

[C++][CMake][生成可执行文件][上]详细讲解
目录 0.准备工作1.添加CMakeLists.txt文件2.执行cmake命令3.变量定义4.指定使用的C标准5.指定输出路径 0.准备工作 add.c#include <stdio.h> #include "head.h"int add(int a, int b) {return ab; }sub.c#include <stdio.h> #include "head.h"…...

Asp.net Core 反射加载dll
定义一个类库,定义接口 namespace Plugin {public interface IPlugin{void EllisTest();} }定义另外一个类库,引用上面的类库,实现接口 using Plugin;namespace UserCustom {public class Custom : IPlugin{public void EllisTest(){Conso…...

利用coredump获取程序调用通路
一些前置知识 原文链接:https://blog.csdn.net/tenfyguo/article/details/8159176 一、什么是coredump 我们经常听到大家说到程序core掉了,需要定位解决,这里说的大部分是指对应程序由于各种异常或者bug导致在运行过程中异常退出或者中止&a…...
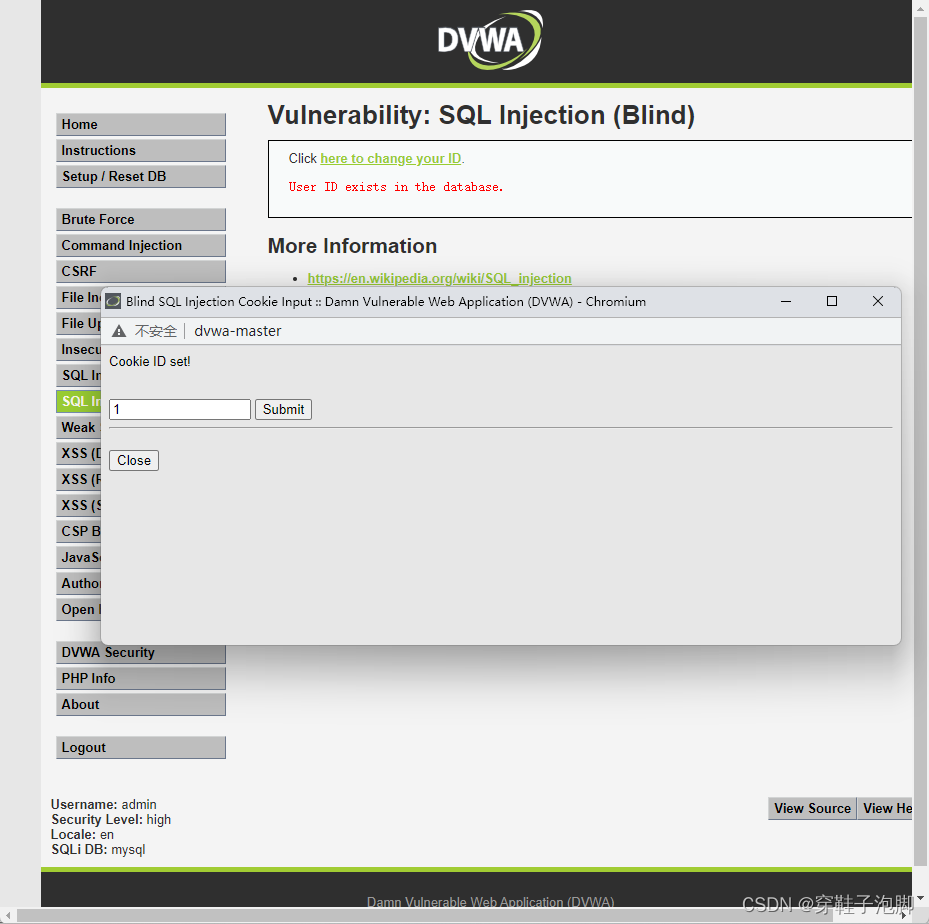
DVWA sql手注学习(巨详细不含sqlmap)
这篇文章主要记录学习sql注入的过程中遇到的问题已经一点学习感悟,过程图片会比较多,比较基础和详细,不存在看不懂哪一步的过程 文章目录 靶场介绍SQL注入 lowSQL注入 MediumSQL注入 HighSQL注入 Impossible 靶场介绍 DVWA(Damn…...
代码随想录算法训练营第70天图论9[1]
代码随想录算法训练营第70天:图论9 拓扑排序精讲 卡码网:117. 软件构建(opens new window) 题目描述: 某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的…...
浏览器设计为默认
...

【配置】Navicat连接sqlServer
安装 - SQL Server Native Client | Microsoft Learn 1.如果没有ODBC驱动则先下载驱动 SQLServerNativeClient10-sqlncli-10-驱动-SQLServer文档类资源-CSDN文库 SQLServerNativeClient11-sqlncli-11驱动资源-CSDN文库 Download Microsoft SQL Server 2012 SP4 Feature Pack …...

June安全防护手册:保护你的论坛免受常见Web攻击的10个技巧
June安全防护手册:保护你的论坛免受常见Web攻击的10个技巧 【免费下载链接】june June is a forum (Deprecated) 项目地址: https://gitcode.com/gh_mirrors/ju/june 在当今数字时代,论坛安全防护已成为每个网站管理员必须面对的重要课题。June作…...

SpringBoot+Vue汽车4S店销售管理系统源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

2026年AI论文工具实测排行,哪款真正适合顺利通关?
2026 年学术 AI 论文工具已形成全流程、理工 / 社科、英文 / 中文、免费 / 付费的清晰分化。综合实测排行与场景适配,千笔AI 是中文全能首选,DeepSeek 学术版是理工开源首选,毕业之家是国内毕业专属首选。 一、2026 年实测排行 TOP5ÿ…...

深度剖析Claude Code实操逻辑,解锁AI编程高效开发方式
文章目录前言一、我用Claude Code的翻车现场,能写一本《程序员血泪史》二、Claude Code的核心设计思想:你以为它是保姆,其实它是保安三、普通模式vs规划模式:一个是临时工,一个是项目经理四、两条核心指令,…...

自适应能量对齐:提升电子态密度机器学习预测精度的关键技术
1. 项目概述:为什么电子态密度的机器学习预测需要“自适应对齐”?在计算材料科学领域,电子态密度(DOS)是一个核心的物理量。它描绘了材料中电子能级随能量的分布情况,就像一张材料的“电子身份证”。通过这…...

论文初稿被批太水?青年教师力荐这几个AI论文写作软件
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

3步掌握Android虚拟定位:FakeLocation完全使用指南
3步掌握Android虚拟定位:FakeLocation完全使用指南 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation FakeLocation是一款基于Xposed框架的Android虚拟定位工具ÿ…...

【信息科学与工程学】计算机科学与自动化 ——第六十五篇 虚拟化/MIG 系列02
编号 类型 领域 虚拟化/MIG模式 算法名称 算法逐步推理思考的数学方程式及参数/常量/向量/常数/数字/数值列表 算法的时序数学方程式 关联知识 401 性能优化 GPU虚拟化+容器 MIG+容器 基于GPU内存带宽隔离的容器化AI训练任务调度算法 1. 带宽模型:每个MIG实例带宽…...

借脑之术:一根记忆枝条,嫁接到另一棵树上 —— Memory Grafting 深度解读
论文信息 标题 Memory Grafting: Scaling Language Model Pre-training via Offline Conditional Memory 作者 Runxi Cheng, Yuchen Guan, Yongxian Wei, Qianpu Sun, Qixiu Li, Sinan Du, Feng Xiong, Chun Yuan, Yan Lu, Yeyun Gong (10人) 机构 微软亚洲研究院 (Microsoft R…...