昇思MindSpore学习笔记2-01 LLM原理和实践 --基于 MindSpore 实现 BERT 对话情绪识别
摘要:
通过识别BERT对话情绪状态的实例,展现在昇思MindSpore AI框架中大语言模型的原理和实际使用方法、步骤。
一、环境配置
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
# 该案例在 mindnlp 0.3.1 版本完成适配,如果发现案例跑不通,可以指定mindnlp版本,执行`!pip install mindnlp==0.3.1`
!pip install mindnlp输出:
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting mindnlpDownloading https://pypi.tuna.tsinghua.edu.cn/packages/72/37/ef313c23fd587c3d1f46b0741c98235aecdfd93b4d6d446376f3db6a552c/mindnlp-0.3.1-py3-none-any.whl (5.7 MB)━━━━━━━━━━━━━━━━ 5.7/5.7 MB 14.2 MB/s eta 0:00:0000:0100:01
Requirement already satisfied: mindspore in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (2.2.14)
Requirement already satisfied: tqdm in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (4.66.4)
Requirement already satisfied: requests in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (2.32.3)
Collecting datasets (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/60/2d/963b266bb8f88492d5ab4232d74292af8beb5b6fdae97902df9e284d4c32/datasets-2.20.0-py3-none-any.whl (547 kB)━━━━━━━━━━━━━━━━ 547.8/547.8 kB 21.2 MB/s eta 0:00:00
Collecting evaluate (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/c2/d6/ff9baefc8fc679dcd9eb21b29da3ef10c81aa36be630a7ae78e4611588e1/evaluate-0.4.2-py3-none-any.whl (84 kB)━━━━━━━━━━━━━━━━ 84.1/84.1 kB 24.8 MB/s eta 0:00:00
Collecting tokenizers (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ba/26/139bd2371228a0e203da7b3e3eddcb02f45b2b7edd91df00e342e4b55e13/tokenizers-0.19.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (3.6 MB)━━━━━━━━━━━━━━━━ 3.6/3.6 MB 14.7 MB/s eta 0:00:00a 0:00:01
Collecting safetensors (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/c6/02/28e6280ed0f1bde89eed644b80f2ece4e5ae212dc9ee70d7f56fadc93602/safetensors-0.4.3-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (1.2 MB)━━━━━━━━━━━━━━━━ 1.2/1.2 MB 17.8 MB/s eta 0:00:00a 0:00:01
Collecting sentencepiece (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/a3/69/e96ef68261fa5b82379fdedb325ceaf1d353c6e839ec346d8244e0da5f2f/sentencepiece-0.2.0-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (1.3 MB)━━━━━━━━━━━━━━━━ 1.3/1.3 MB 14.4 MB/s eta 0:00:00a 0:00:01
Collecting regex (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/70/70/fea4865c89a841432497d1abbfd53878513b55c6543245fabe31cf8df0b8/regex-2024.5.15-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (774 kB)━━━━━━━━━━━━━━━━ 774.7/774.7 kB 15.3 MB/s eta 0:00:00a 0:00:01
Collecting addict (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/6a/00/b08f23b7d7e1e14ce01419a467b583edbb93c6cdb8654e54a9cc579cd61f/addict-2.4.0-py3-none-any.whl (3.8 kB)
Collecting ml-dtypes (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/50/96/13d7c3cc82d5ef597279216cf56ff461f8b57e7096a3ef10246a83ca80c0/ml_dtypes-0.4.0-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (2.2 MB)━━━━━━━━━━━━━━━━ 2.2/2.2 MB 11.9 MB/s eta 0:00:00a 0:00:01
Collecting pyctcdecode (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/a5/8a/93e2118411ae5e861d4f4ce65578c62e85d0f1d9cb389bd63bd57130604e/pyctcdecode-0.5.0-py2.py3-none-any.whl (39 kB)
Collecting jieba (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/c6/cb/18eeb235f833b726522d7ebed54f2278ce28ba9438e3135ab0278d9792a2/jieba-0.42.1.tar.gz (19.2 MB)━━━━━━━━━━━━━━━━ 19.2/19.2 MB 16.5 MB/s eta 0:00:0000:0100:01Preparing metadata (setup.py) ... done
Collecting pytest==7.2.0 (from mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/67/68/a5eb36c3a8540594b6035e6cdae40c1ef1b6a2bfacbecc3d1a544583c078/pytest-7.2.0-py3-none-any.whl (316 kB)━━━━━━━━━━━━━━━━ 316.8/316.8 kB 16.7 MB/s eta 0:00:00
Requirement already satisfied: attrs>=19.2.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (23.2.0)
Requirement already satisfied: iniconfig in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (2.0.0)
Requirement already satisfied: packaging in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (23.2)
Requirement already satisfied: pluggy<2.0,>=0.12 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (1.5.0)
Requirement already satisfied: exceptiongroup>=1.0.0rc8 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (1.2.0)
Requirement already satisfied: tomli>=1.0.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (2.0.1)
Requirement already satisfied: filelock in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (3.15.3)
Requirement already satisfied: numpy>=1.17 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (1.26.4)
Collecting pyarrow>=15.0.0 (from datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/87/60/cc0645eb4ef73f88847e40a7f9d238bae6b7409d6c1f6a5d200d8ade1f09/pyarrow-16.1.0-cp39-cp39-manylinux_2_28_aarch64.whl (38.1 MB)━━━━━━━━━━━━━━━━ 38.1/38.1 MB 14.2 MB/s eta 0:00:0000:0100:01
Collecting pyarrow-hotfix (from datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/e4/f4/9ec2222f5f5f8ea04f66f184caafd991a39c8782e31f5b0266f101cb68ca/pyarrow_hotfix-0.6-py3-none-any.whl (7.9 kB)
Requirement already satisfied: dill<0.3.9,>=0.3.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (0.3.8)
Requirement already satisfied: pandas in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (2.2.2)
Collecting xxhash (from datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/7c/b9/93f860969093d5d1c4fa60c75ca351b212560de68f33dc0da04c89b7dc1b/xxhash-3.4.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (220 kB)━━━━━━━━━━━━━━━━ 220.6/220.6 kB 15.6 MB/s eta 0:00:00
Collecting multiprocess (from datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/da/d9/f7f9379981e39b8c2511c9e0326d212accacb82f12fbfdc1aa2ce2a7b2b6/multiprocess-0.70.16-py39-none-any.whl (133 kB)━━━━━━━━━━━━━━━━ 133.4/133.4 kB 15.8 MB/s eta 0:00:00
Collecting fsspec<=2024.5.0,>=2023.1.0 (from fsspec[http]<=2024.5.0,>=2023.1.0->datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ba/a3/16e9fe32187e9c8bc7f9b7bcd9728529faa725231a0c96f2f98714ff2fc5/fsspec-2024.5.0-py3-none-any.whl (316 kB)━━━━━━━━━━━━━━━━ 316.1/316.1 kB 16.8 MB/s eta 0:00:00
Collecting aiohttp (from datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/eb/45/eebe8d2215328434f33ccb44a05d2741ff7ed4b96b56ca507e2ecf598b73/aiohttp-3.9.5-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (1.2 MB)━━━━━━━━━━━━━━━━ 1.2/1.2 MB 17.1 MB/s eta 0:00:0000:0100:01
Requirement already satisfied: huggingface-hub>=0.21.2 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (0.23.4)
Requirement already satisfied: pyyaml>=5.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (6.0.1)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from requests->mindnlp) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from requests->mindnlp) (3.7)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from requests->mindnlp) (2.2.2)
Requirement already satisfied: certifi>=2017.4.17 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from requests->mindnlp) (2024.6.2)
Requirement already satisfied: protobuf>=3.13.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (5.27.1)
Requirement already satisfied: asttokens>=2.0.4 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (2.0.5)
Requirement already satisfied: pillow>=6.2.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (10.3.0)
Requirement already satisfied: scipy>=1.5.4 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (1.13.1)
Requirement already satisfied: psutil>=5.6.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (5.9.0)
Requirement already satisfied: astunparse>=1.6.3 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (1.6.3)
Collecting pygtrie<3.0,>=2.1 (from pyctcdecode->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ec/cd/bd196b2cf014afb1009de8b0f05ecd54011d881944e62763f3c1b1e8ef37/pygtrie-2.5.0-py3-none-any.whl (25 kB)
Collecting hypothesis<7,>=6.14 (from pyctcdecode->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ae/ea/526a7a629fcf6c78a1a6d37f988ca7e02e5b5785ec4de8a194deb40529f4/hypothesis-6.104.2-py3-none-any.whl (462 kB)━━━━━━━━━━━━━━━━ 462.4/462.4 kB 14.4 MB/s eta 0:00:00
Requirement already satisfied: six in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from asttokens>=2.0.4->mindspore->mindnlp) (1.16.0)
Requirement already satisfied: wheel<1.0,>=0.23.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from astunparse>=1.6.3->mindspore->mindnlp) (0.43.0)
Collecting aiosignal>=1.1.2 (from aiohttp->datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/76/ac/a7305707cb852b7e16ff80eaf5692309bde30e2b1100a1fcacdc8f731d97/aiosignal-1.3.1-py3-none-any.whl (7.6 kB)
Collecting frozenlist>=1.1.1 (from aiohttp->datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/57/15/172af60c7e150a1d88ecc832f2590721166ae41eab582172fe1e9844eab4/frozenlist-1.4.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (239 kB)━━━━━━━━━━━━━━━━ 239.4/239.4 kB 17.1 MB/s eta 0:00:00
Collecting multidict<7.0,>=4.5 (from aiohttp->datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/d0/10/2ff646c471e84af25fe8111985ffb8ec85a3f6e1ade8643bfcfcc0f4d2b1/multidict-6.0.5-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (125 kB)━━━━━━━━━━━━━━━━ 125.9/125.9 kB 31.0 MB/s eta 0:00:00
Collecting yarl<2.0,>=1.0 (from aiohttp->datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/c6/d6/5b30ae1d8a13104ee2ceb649f28f2db5ad42afbd5697fd0fc61528bb112c/yarl-1.9.4-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (300 kB)━━━━━━━━━━━━━━━━ 300.9/300.9 kB 20.5 MB/s eta 0:00:00
Collecting async-timeout<5.0,>=4.0 (from aiohttp->datasets->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/a7/fa/e01228c2938de91d47b307831c62ab9e4001e747789d0b05baf779a6488c/async_timeout-4.0.3-py3-none-any.whl (5.7 kB)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from huggingface-hub>=0.21.2->datasets->mindnlp) (4.11.0)
Collecting sortedcontainers<3.0.0,>=2.1.0 (from hypothesis<7,>=6.14->pyctcdecode->mindnlp)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/32/46/9cb0e58b2deb7f82b84065f37f3bffeb12413f947f9388e4cac22c4621ce/sortedcontainers-2.4.0-py2.py3-none-any.whl (29 kB)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pandas->datasets->mindnlp) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pandas->datasets->mindnlp) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pandas->datasets->mindnlp) (2024.1)
Building wheels for collected packages: jiebaBuilding wheel for jieba (setup.py) ... doneCreated wheel for jieba: filename=jieba-0.42.1-py3-none-any.whl size=19314459 sha256=352f23b7dc8b4bade2f918165e055bc707601544400a4918136ba69f220ce9f6Stored in directory: /home/nginx/.cache/pip/wheels/1a/76/68/b6d79c4db704bb18d54f6a73ab551185f4711f9730c0c15d97
Successfully built jieba
Installing collected packages: sortedcontainers, sentencepiece, pygtrie, jieba, addict, xxhash, safetensors, regex, pytest, pyarrow-hotfix, pyarrow, multiprocess, multidict, ml-dtypes, hypothesis, fsspec, frozenlist, async-timeout, yarl, pyctcdecode, aiosignal, tokenizers, aiohttp, datasets, evaluate, mindnlpAttempting uninstall: pytestFound existing installation: pytest 8.0.0Uninstalling pytest-8.0.0:Successfully uninstalled pytest-8.0.0Attempting uninstall: fsspecFound existing installation: fsspec 2024.6.0Uninstalling fsspec-2024.6.0:Successfully uninstalled fsspec-2024.6.0
Successfully installed addict-2.4.0 aiohttp-3.9.5 aiosignal-1.3.1 async-timeout-4.0.3 datasets-2.20.0 evaluate-0.4.2 frozenlist-1.4.1 fsspec-2024.5.0 hypothesis-6.104.2 jieba-0.42.1 mindnlp-0.3.1 ml-dtypes-0.4.0 multidict-6.0.5 multiprocess-0.70.16 pyarrow-16.1.0 pyarrow-hotfix-0.6 pyctcdecode-0.5.0 pygtrie-2.5.0 pytest-7.2.0 regex-2024.5.15 safetensors-0.4.3 sentencepiece-0.2.0 sortedcontainers-2.4.0 tokenizers-0.19.1 xxhash-3.4.1 yarl-1.9.4[notice] A new release of pip is available: 24.1 -> 24.1.1
[notice] To update, run: python -m pip install --upgrade pip显示mindspore模块的基本信息
!pip show mindspore输出:
Name: mindspore
Version: 2.2.14
Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.
Home-page: https://www.mindspore.cn
Author: The MindSpore Authors
Author-email: contact@mindspore.cn
License: Apache 2.0
Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages
Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy
Required-by: mindnlp二、模型简介
BERT是一种新型语言模型
全称:Bidirectional Encoder Representations from Transformers
中文:双向表达的编码变换
Google发布于2018年
用于自然语言处理场景类似的预训练语言模型有:
问答
命名实体识别
自然语言推理
文本分类等
BERT模型涉及
Transformer的Encoder
双向结构
BERT模型的主要创新点
pre-train方法
用Masked Language Model捕捉词语
用Next Sentence Prediction捕捉句子
用Masked Language Model方法训练BERT对话时
随机把语料库中15%的单词做Mask操作。
Mask操作的三种情况:
80%的单词直接用[Mask]替换
10%的单词直接替换成另一个新的单词
10%的单词保持不变。
问答Question Answering (QA)
自然语言推断Natural Language Inference (NLI)
Next Sentence Prediction预训练任务
目的:
让模型理解两个句子之间的联系。
训练内容:
输入是句子A和B
B有一半的几率是A的下一句
预测B是不是A的下一句
训练结果:
Embedding table
12层Transformer权重(BERT-BASE)
或24层Transformer权重(BERT-LARGE)。
微调Fine-tuning下游任务:
文本分类
相似度判断
阅读理解等。
对话情绪识别Emotion Detection(简称EmoTect)
对话文本
判断文本情绪类别
积极
消极
中性
计算置信度。
示例:
导入mindspore dataset nn context mindnlp等模块
import os
import mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nn, context
from mindnlp._legacy.engine import Trainer, Evaluator
from mindnlp._legacy.engine.callbacks import CheckpointCallback, BestModelCallback
from mindnlp._legacy.metrics import Accuracy输出:
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 1.037 seconds.
Prefix dict has been built successfully.三、准备数据集
1. 数据集说明
实验数据集采用百度飞桨的机器人聊天数据
已标注
分词预处理
数据两列,制表符('\t')分隔:
情绪分类
0消极
1中性
2积极
中文文本
空格分词
utf8编码
数据示例:
label--text_a
0--谁骂人了?我从来不骂人,我骂的都不是人,你是人吗 ?
1--我有事等会儿就回来和你聊
2--我见到你很高兴谢谢你帮我2.下载数据集
# download dataset
!wget https://baidu-nlp.bj.bcebos.com/emotion_detection-dataset-1.0.0.tar.gz -O emotion_detection.tar.gz
!tar xvf emotion_detection.tar.gz输出:
--2024-07-01 13:38:50-- https://baidu-nlp.bj.bcebos.com/emotion_detection-dataset-1.0.0.tar.gz
Resolving baidu-nlp.bj.bcebos.com (baidu-nlp.bj.bcebos.com)... 119.249.103.5, 113.200.2.111, 2409:8c04:1001:1203:0:ff:b0bb:4f27
Connecting to baidu-nlp.bj.bcebos.com (baidu-nlp.bj.bcebos.com)|119.249.103.5|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1710581 (1.6M) [application/x-gzip]
Saving to: ‘emotion_detection.tar.gz’emotion_detection.t 100%[===================>] 1.63M 8.04MB/s in 0.2s 2024-07-01 13:38:50 (8.04 MB/s) - ‘emotion_detection.tar.gz’ saved [1710581/1710581]data/
data/test.tsv
data/infer.tsv
data/dev.tsv
data/train.tsv
data/vocab.txt3.定义数据集类
# prepare dataset
class SentimentDataset:"""Sentiment Dataset"""
def __init__(self, path):self.path = pathself._labels, self._text_a = [], []self._load()
def _load(self):with open(self.path, "r", encoding="utf-8") as f:dataset = f.read()lines = dataset.split("\n")for line in lines[1:-1]:label, text_a = line.split("\t")self._labels.append(int(label))self._text_a.append(text_a)
def __getitem__(self, index):return self._labels[index], self._text_a[index]
def __len__(self):return len(self._labels)四、数据加载和数据预处理
数据加载和预处理函数
process_dataset()
import numpy as np
def process_dataset(source, tokenizer, max_seq_len=64, batch_size=32, shuffle=True):is_ascend = mindspore.get_context('device_target') == 'Ascend'column_names = ["label", "text_a"]dataset = GeneratorDataset(source, column_names=column_names, shuffle=shuffle)# transformstype_cast_op = transforms.TypeCast(mindspore.int32)def tokenize_and_pad(text):if is_ascend:tokenized = tokenizer(text, padding='max_length',
truncation=True, max_length=max_seq_len)else:tokenized = tokenizer(text)return tokenized['input_ids'], tokenized['attention_mask']# map dataset
dataset = dataset.map(operations=tokenize_and_pad, input_columns="text_a",
output_columns=['input_ids', 'attention_mask'])
dataset = dataset.map(operations=[type_cast_op], input_columns="label",
output_columns='labels')# batch datasetif is_ascend:dataset = dataset.batch(batch_size)else:dataset = dataset.padded_batch(batch_size,
pad_info={'input_ids': (None, tokenizer.pad_token_id),
'attention_mask': (None, 0)})return dataset数据预处理部分采用静态Shape处理:
昇腾NPU环境下暂不支持动态Shape
from mindnlp.transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')输出:
100%━━━━━━━━━━━━━━━━━━━━━ 49.0/49.0 [00:00<00:00, 3.05kB/s]━107k/0.00 [00:05<00:00, 36.3kB/s]━263k/0.00 [00:15<00:00, 10.2kB/s]━━━━━━━━━━━━━━━━━━━━━ 624/? [00:00<00:00, 56.0kB/s]tokenizer.pad_token_id输出:
0取训练数据集的列名:
dataset_train = process_dataset(SentimentDataset("data/train.tsv"), tokenizer)
dataset_val = process_dataset(SentimentDataset("data/dev.tsv" ), tokenizer)
dataset_test = process_dataset(SentimentDataset("data/test.tsv" ), tokenizer, shuffle=False)
dataset_train.get_col_names()输出:
['input_ids', 'attention_mask', 'labels']遍历显示训练数据集
print(next(dataset_train.create_tuple_iterator()))输出:
[Tensor(shape=[32, 64], dtype=Int64, value=
[[ 101, 2769, 4638 ... 0, 0, 0],[ 101, 2769, 3221 ... 0, 0, 0],[ 101, 758, 1282 ... 0, 0, 0],...[ 101, 1217, 678 ... 0, 0, 0],[ 101, 872, 679 ... 0, 0, 0],[ 101, 872, 3766 ... 0, 0, 0]]),Tensor(shape=[32, 64], dtype=Int64, value=
[[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],...[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0]]),Tensor(shape=[32], dtype=Int32, value=[1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1])]五、模型构建
BERT 模型
BertForSequenceClassification模块构建
加载预训练权重
设置情感三分类
自动混合精度
实例化优化器
实例化评价指标
设置模型训练的权重保存策略
构建训练器
模型开始训练
from mindnlp.transformers import BertForSequenceClassification, BertModel
from mindnlp._legacy.amp import auto_mixed_precision
# set bert config and define parameters for training
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3)
model = auto_mixed_precision(model, 'O1')
optimizer = nn.Adam(model.trainable_params(), learning_rate=2e-5)(), learning_rate=2e-5)
输出:
100%━━━━━━━━━━━━━━━━━━ 392M/392M [00:53<00:00, 6.82MB/s]The following parameters in checkpoint files are not loaded:
['cls.predictions.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.dense.weight', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight']
The following parameters in models are missing parameter:
['classifier.weight', 'classifier.bias']
metric = Accuracy()
# define callbacks to save checkpoints
ckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='bert_emotect', epochs=1, keep_checkpoint_max=2)
best_model_cb = BestModelCallback(save_path='checkpoint', ckpt_name='bert_emotect_best', auto_load=True)
# 构建训练器
trainer = Trainer(network=model, train_dataset=dataset_train,eval_dataset=dataset_val, metrics=metric,epochs=5, optimizer=optimizer, callbacks=[ckpoint_cb, best_model_cb])%%time
# start training
trainer.run(tgt_columns="labels")输出:
The train will start from the checkpoint saved in 'checkpoint'.
Epoch 0: 100%━━━━━━━━━━━━━━ 302/302 [04:07<00:00, 2.25s/it, loss=0.3460012]
Checkpoint: 'bert_emotect_epoch_0.ckpt' has been saved in epoch: 0.
Evaluate: 100%━━━━━━━━━━━━━━ 34/34 [00:07<00:00, 1.07it/s]
Evaluate Score: {'Accuracy': 0.9351851851851852}
---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 0.---------------
Epoch 1: 100%━━━━━━━━━━━━━━ 302/302 [02:38<00:00, 1.95it/s, loss=0.19017023]
Checkpoint: 'bert_emotect_epoch_1.ckpt' has been saved in epoch: 1.
Evaluate: 100%━━━━━━━━━━━━━━ 34/34 [00:05<00:00, 7.48it/s]
Evaluate Score: {'Accuracy': 0.9564814814814815}
---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 1.---------------
Epoch 2: 100%━━━━━━━━━━━━━━ 302/302 [02:40<00:00, 1.92it/s, loss=0.12662967]
The maximum number of stored checkpoints has been reached.
Checkpoint: 'bert_emotect_epoch_2.ckpt' has been saved in epoch: 2.
Evaluate: 100%━━━━━━━━━━━━━━ 34/34 [00:04<00:00, 7.59it/s]
Evaluate Score: {'Accuracy': 0.9740740740740741}
---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 2.---------------
Epoch 3: 100%━━━━━━━━━━━━━━ 302/302 [02:40<00:00, 1.92it/s, loss=0.08593981]
The maximum number of stored checkpoints has been reached.
Checkpoint: 'bert_emotect_epoch_3.ckpt' has been saved in epoch: 3.
Evaluate: 100%━━━━━━━━━━━━━━ 34/34 [00:04<00:00, 7.51it/s]
Evaluate Score: {'Accuracy': 0.9833333333333333}
---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 3.---------------
Epoch 4: 100%━━━━━━━━━━━━━━ 302/302 [02:41<00:00, 1.92it/s, loss=0.05900709]
The maximum number of stored checkpoints has been reached.
Checkpoint: 'bert_emotect_epoch_4.ckpt' has been saved in epoch: 4.
Evaluate: 100%━━━━━━━━━━━━━━ 34/34 [00:04<00:00, 7.39it/s]
Evaluate Score: {'Accuracy': 0.9879629629629629}
---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 4.---------------
Loading best model from 'checkpoint' with '['Accuracy']': [0.9879629629629629]...
---------------The model is already load the best model from 'bert_emotect_best.ckpt'.---------------
CPU times: user 22min 58s, sys: 13min 25s, total: 36min 24s
Wall time: 15min 30s六、模型验证
验证评估
测试数据集
准确率
evaluator = Evaluator(network=model, eval_dataset=dataset_test, metrics=metric)
evaluator.run(tgt_columns="labels")输出:
Evaluate: 100%━━━━━━━━━━━━━━ 33/33 [00:08<00:00, 1.20s/it]Evaluate Score: {'Accuracy': 0.8822393822393823}
七、模型推理
遍历推理数据集,展示结果与标签。
dataset_infer = SentimentDataset("data/infer.tsv")
def predict(text, label=None):label_map = {0: "消极", 1: "中性", 2: "积极"}
text_tokenized = Tensor([tokenizer(text).input_ids])logits = model(text_tokenized)predict_label = logits[0].asnumpy().argmax()info = f"inputs: '{text}', predict: '{label_map[predict_label]}'"if label is not None:info += f" , label: '{label_map[label]}'"print(info)
from mindspore import Tensor
for label, text in dataset_infer:predict(text, label)输出:
inputs: '我 要 客观', predict: '中性' , label: '中性'
inputs: '靠 你 真是 说 废话 吗', predict: '消极' , label: '消极'
inputs: '口嗅 会', predict: '中性' , label: '中性'
inputs: '每次 是 表妹 带 窝 飞 因为 窝路痴', predict: '中性' , label: '中性'
inputs: '别说 废话 我 问 你 个 问题', predict: '消极' , label: '消极'
inputs: '4967 是 新加坡 那 家 银行', predict: '中性' , label: '中性'
inputs: '是 我 喜欢 兔子', predict: '积极' , label: '积极'
inputs: '你 写 过 黄山 奇石 吗', predict: '中性' , label: '中性'
inputs: '一个一个 慢慢来', predict: '中性' , label: '中性'
inputs: '我 玩 过 这个 一点 都 不 好玩', predict: '消极' , label: '消极'
inputs: '网上 开发 女孩 的 QQ', predict: '中性' , label: '中性'
inputs: '背 你 猜 对 了', predict: '中性' , label: '中性'
inputs: '我 讨厌 你 , 哼哼 哼 。 。', predict: '消极' , label: '消极'inputs: '我 讨厌 你 , 哼哼 哼 。 。', predict: '消极' , label: '消极'
八、自定义推理数据集
predict("家人们咱就是说一整个无语住了 绝绝子叠buff")输出:
inputs: '家人们咱就是说一整个无语住了 绝绝子叠buff', predict: '中性'相关文章:

昇思MindSpore学习笔记2-01 LLM原理和实践 --基于 MindSpore 实现 BERT 对话情绪识别
摘要: 通过识别BERT对话情绪状态的实例,展现在昇思MindSpore AI框架中大语言模型的原理和实际使用方法、步骤。 一、环境配置 %%capture captured_output # 实验环境已经预装了mindspore2.2.14,如需更换mindspore版本,可更改下…...

uniapp实现图片懒加载 封装组件
想要的效果就是窗口滑动到哪里,哪里的图片进行展示 主要原理使用IntersectionObserver <template><view><image error"HandlerError" :style"imgStyle" :src"imageSrc" :id"randomId" :mode"mode&quo…...

持续交付:自动化测试与发布流程的变革
目录 前言1. 持续交付的概念1.1 持续交付的定义1.2 持续交付的核心原则 2. 持续交付的优势2.1 提高交付速度2.2 提高软件质量2.3 降低发布风险2.4 提高团队协作 3. 实施持续交付的步骤3.1 构建自动化测试体系3.1.1 单元测试3.1.2 集成测试3.1.3 功能测试3.1.4 性能测试 3.2 构建…...

VBA常用的字符串内置函数
前言 在VBA程序中,常用的内置函数可以按照功能分为字符串函数、数字函数、转换函数等等,本节主要会介绍常用的字符串的内置函数,包括Len()、Left()、Mid()、Right()、Split()、String()、StrConV()等。 本节的练习数据表以下表为例ÿ…...
)
大数据面试题之Spark(7)
目录 Spark实现wordcount Spark Streaming怎么实现数据持久化保存? Spark SQL读取文件,内存不够使用,如何处理? Spark的lazy体现在哪里? Spark中的并行度等于什么 Spark运行时并行度的设署 Spark SQL的数据倾斜 Spark的exactly-once Spark的…...

AI绘画 Stable Diffusion图像的脸部细节控制——采样器全解析
大家好,我是画画的小强 我们在运用AI绘画 Stable Diffusion 这一功能强大的AI绘图工具时,我们往往会发现自己对提示词的使用还不够充分。在这种情形下,我们应当如何调整自己的策略,以便更加精确、全面地塑造出理想的人物形象呢&a…...

liunx离线安装Firefox
在Linux系统中离线安装Firefox浏览器,您需要先从Mozilla的官方网站下载Firefox的安装包,然后通过终端进行安装。以下是详细的步骤: 准备工作 下载Firefox安装包: 首先,在一台可以上网的电脑上访问Firefox官方下载页面…...
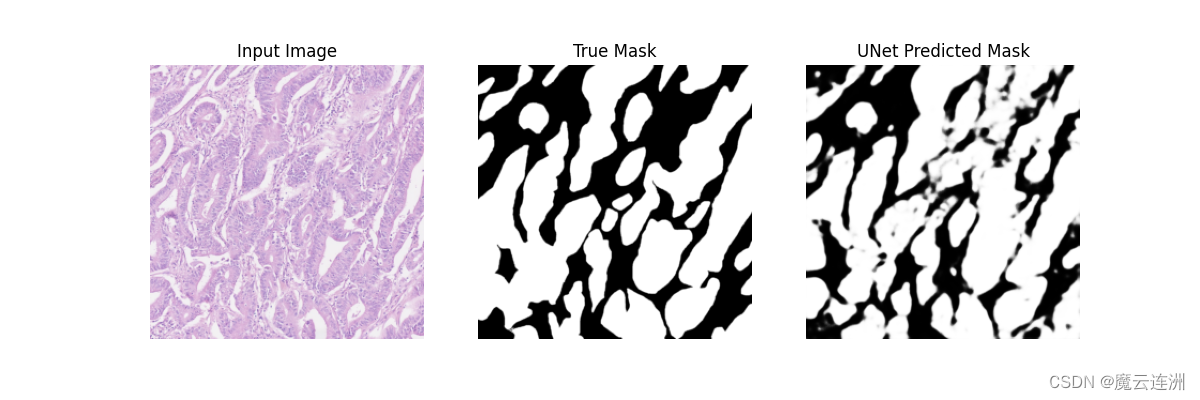
UNet进行病理图像分割
数据集链接:https://pan.baidu.com/s/1IBe_P0AyHgZC39NqzOxZhA?pwdnztc 提取码:nztc UNet模型 import torch import torch.nn as nnclass conv_block(nn.Module):def __init__(self, ch_in, ch_out):super(conv_block, self).__init__()self.conv nn…...

初二数学基础差从哪开始补?附深度解析!
有时候,当你推不开一扇门的时候,不要着急,试着反方向拉一下,或者横向拉一下。下面是小偏整理的初二数学基础差从哪开始补2021年,感谢您的每一次阅读。 初二数学基础差从哪开始补2021年 第一个问题是很多同学都…...

【C语言】return 关键字
在C语言中,return是一个关键字,用于从函数中返回值或者结束函数的执行。它是函数的重要组成部分,负责将函数的计算结果返回给调用者,并可以提前终止函数的执行。 主要用途和原理: 返回值给调用者: 当函数执…...

华为机试HJ13句子逆序
华为机试HJ13句子逆序 题目: 将一个英文语句以单词为单位逆序排放。例如“I am a boy”,逆序排放后为“boy a am I”所有单词之间用一个空格隔开,语句中除了英文字母外,不再包含其他字符 想法: 将输入的字符串通过…...
)
代码随想录day40 动态规划(5)
52. 携带研究材料(第七期模拟笔试) (kamacoder.com) 完全背包,可重复放入物品,需要用一维滚动数组从前往后遍历。 由于第0个物品和后面物品的转移方程没有区别,可以不额外初始化dp数组,直接用元素全0的d…...

FFmpeg 命令行 音视频格式转换
📚:FFmpeg 提供了丰富的命令行选项和功能,可以用来处理音视频文件、流媒体等,掌握命令行的使用,可以有效提高工作效率。 目录 一、视频转换和格式转换 🔵 将视频文件转换为另一种格式 🔵 指定…...

Jmeter使用JSON Extractor提取多个变量
1.当正则不好使时,用json extractor 2.提取多个值时,默认值必填,否则读不到变量...
c++ 设计模式 的课本范例(下)
(19) 桥接模式 Bridge,不是采用类继承,而是采用类组合,一个类的数据成员是类对象,来扩展类的功能。源码如下: class OS // 操作系统负责绘图 { public:virtual ~OS() {}virtual void draw(cha…...

结合数据索引结构看SQL的真实执行过程
引言 关于数据库设计与优化的前几篇文章中,我们提到了数据库设计优化应该遵守的指导原则、数据库底层的索引组织结构、数据库的核心功能组件以及SQL的解析、编译等。这些其实都是在为SQL的优化、执行的理解打基础。 今天这篇文章,我们以MySQL中InnoDB存…...
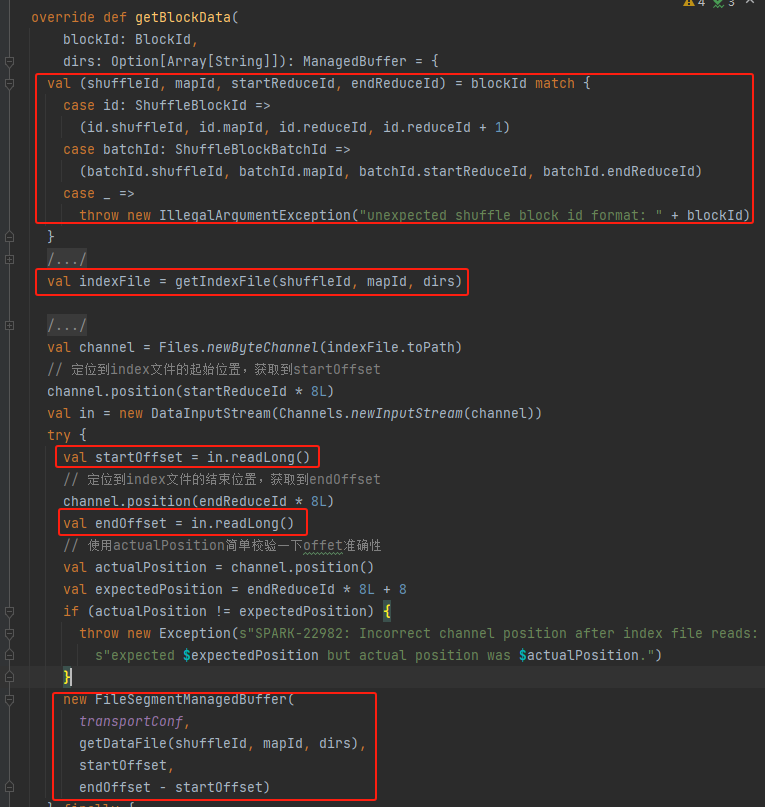
spark shuffle——shuffle管理
ShuffleManager shuffle系统的入口。ShuffleManager在driver和executor中的sparkEnv中创建。在driver中注册shuffle,在executor中读取和写入数据。 registerShuffle:注册shuffle,返回shuffleHandle unregisterShuffle:移除shuff…...

HTMLCSS(入门)
HTML <html> <head><title>第一个页面</title></head><body>键盘敲烂,工资过万</body> </html> <!DOCTYPE>文档类型声明,告诉浏览器使用哪种HTML版本显示网页 <!DOCTYPE html>当前页面采取…...

富格林:曝光可信策略制止亏损
富格林指出,相信大家都对黄金投资的价值空间有目共睹,现如今黄金市场波动频繁,因此不少投资者也开始加入该市场试图赢得额外的财富。但作为新手投资者贸贸然地进场操作,亏损的几率是很大的,因此要学会掌握正规平台曝光…...

Android --- Service
出自于此,写得很清楚。关于Android Service真正的完全详解,你需要知道的一切_android service-CSDN博客 出自【zejian的博客】 什么是Service? Service(服务)是一个一种可以在后台执行长时间运行操作而没有用户界面的应用组件。 服务可由其他应用组件…...

如何解决多语言语音识别乱码问题:Vosk API的字符编码终极指南
如何解决多语言语音识别乱码问题:Vosk API的字符编码终极指南 【免费下载链接】vosk-api Offline speech recognition API for Android, iOS, Raspberry Pi and servers with Python, Java, C# and Node 项目地址: https://gitcode.com/GitHub_Trending/vo/vosk-a…...

在多地域部署服务中体验Taotoken路由能力对API延迟的优化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多地域部署服务中体验Taotoken路由能力对API延迟的优化 1. 场景与挑战 在构建面向全球用户的服务时,一个常见的架构…...

Taotoken 的 API Key 分级管理与审计日志功能在安全合规中的实际价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的 API Key 分级管理与审计日志功能在安全合规中的实际价值 在企业级应用开发中,将大模型能力集成到业务系统…...

OpenAI破解80年数学猜想:AI首次完成原创性科学突破
2026年5月21日,一个普通的工作日,数学界却迎来了一场地震。OpenAI的内部通用推理模型,独立证明了离散几何领域一个悬置近80年的核心猜想——而且不是证明了它成立,而是直接推翻了它。 目录 引言:一个简单到小学生都能理解的问题 Erdős单位距离猜想:80年的数学悬案 AI突破…...

Warcraft Helper终极指南:让经典魔兽争霸3在现代Windows系统重获新生
Warcraft Helper终极指南:让经典魔兽争霸3在现代Windows系统重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在Wi…...

IPXWrapper完整教程:让经典游戏在Windows 10/11重获联机能力
IPXWrapper完整教程:让经典游戏在Windows 10/11重获联机能力 【免费下载链接】ipxwrapper 项目地址: https://gitcode.com/gh_mirrors/ip/ipxwrapper 还在为《星际争霸》《帝国时代》等经典游戏无法在现代Windows系统上联机而烦恼吗?IPXWrapper正…...

d2dx深度探索:经典游戏《暗黑破坏神2》现代化适配的技术架构与实现原理
d2dx深度探索:经典游戏《暗黑破坏神2》现代化适配的技术架构与实现原理 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2d…...

Nrfr完整指南:免Root修改SIM卡国家码,轻松突破区域限制
Nrfr完整指南:免Root修改SIM卡国家码,轻松突破区域限制 【免费下载链接】Nrfr 🌍 免 Root 的 SIM 卡国家码修改工具 | 解决国际漫游时的兼容性问题,帮助使用海外 SIM 卡获得更好的本地化体验,解锁运营商限制࿰…...

B站CC字幕下载与转换解决方案:实现视频学习资源本地化管理
B站CC字幕下载与转换解决方案:实现视频学习资源本地化管理 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 在视频学习日益普及的今天,B站作…...

AI Agent 在工具调用失败时,如何设计一个智能的降级策略?
这个问题挺关键的,工具调用失败在 AI Agent 系统里是常态,不是异常。核心思路是——先分类,再分级,最后兜底。 我之前做 Agent 编排系统的时候,工具调用成功率大概在 85% 左右,剩下 15% 都得靠降级策略兜住。如果没设计好,整个 Agent 就会频繁报错,用户体验很差。 第一步:错误…...