结合数据索引结构看SQL的真实执行过程
引言
关于数据库设计与优化的前几篇文章中,我们提到了数据库设计优化应该遵守的指导原则、数据库底层的索引组织结构、数据库的核心功能组件以及SQL的解析、编译等。这些其实都是在为SQL的优化、执行的理解打基础。
今天这篇文章,我们以MySQL中InnoDB存储引擎中的数据索引组织及一条SQL的物理执行过程,来更直观的理解数据库中我们提交一条SQL后,数据库默默帮我们做的事情。
准备工作
我们依然以前一篇文章中的t_customer表为例,建表语句如下:
create table t_customer(id int not null auto_increment comment '会员id',name varchar(32) comment '会员姓名',gender tinyint not null default 0 comment '会员性别:0未知,1男,2女',city varchar(32) comment '会员所在城市',primary key(`id`),key `idx_city` (`city`)
) comment '会员信息表';
然后我们编写一个Python脚本,利用Faker框架,来生成测试数据:
import random
from faker import Faker
from faker.providers import BaseProvider
import pymysql
import db_config as db_cfgprint(db_cfg.host)conn = pymysql.connect(host=db_cfg.host, port=db_cfg.port, user=db_cfg.user, password=db_cfg.password,database=db_cfg.database)
cursor = conn.cursor()
sql = "insert into t_customer(name, gender, city) values('{}', {}, '{}')"class GenderProvider(BaseProvider):def gender(self):return random.sample([1, 2, 0], counts=[100, 100, 1], k=1)[0]# 指定语言环境为中文环境,创建Faker生成器
fk = Faker('zh_CN')
fk.add_provider(GenderProvider)
for i in range(10000):cursor.execute(sql.format(fk.name(), fk.gender(), fk.city()))
conn.commit()
cursor.close()
conn.close()测试数据大概如下:

其实这里我们只是从数据组织结构上展开SQL的执行,没有测试数据也没啥影响。不过,还是强烈建议感兴趣的了解下Python,很好用,很好玩。这里不再展开,需要理解的可以看下笔者关于Python的相关系列文章。
B+树的索引组织结构
简单说下B+树索引
B+树索引,就是传统意义上的索引,也是目前关系型数据库系统中查找最为常用和最有效的索引。
需要注意的是,从使用的角度来看,B+树索引的构造类似于二叉树,根据键值(key value)能够快速找到相应的数据。但是,有几个细节需要提一下:
- B+树中的B不是表示二叉(binary),而是代表平衡(balance),因为B+树是从最早的平衡二叉树演化而来的,但是B+树不是一个二叉树
- 树结构的索引,只有是平衡树,才能降低树的高度,从而降低基于索引检索的磁盘IO的次数
- B+树索引,实际上并不能通过一个给定的键值查到具体的某一行数据,而是只能找到被查找符合键值的数据所在的页,这些数据按照键值顺序进行组织存储。然后数据库通过把页读入内存,然后在内存中执行进一步的查找操作,最终得到要查找的数据。后续我们简化一下操作,假设每个页都只存储一条数据,以便更好地进行表述、理解
- 关于数据以页为单位进行读取,前面的文章中已经提到,可以更好地利用程序的局部性原理,从而提高检索的效率
t_customer的索引结构
引言中已经提到,我们这里以MySQL的InnoDB存储引擎为例进行介绍,其他数据库中的底层原理也基本类似。
从前面的建表语句中,可以看出t_customer有两个索引:
- 主键索引 id,是聚簇索引(Clustered Index)
- idx_city,是辅助索引(Secondary Index)
索引的示意图大概如下:
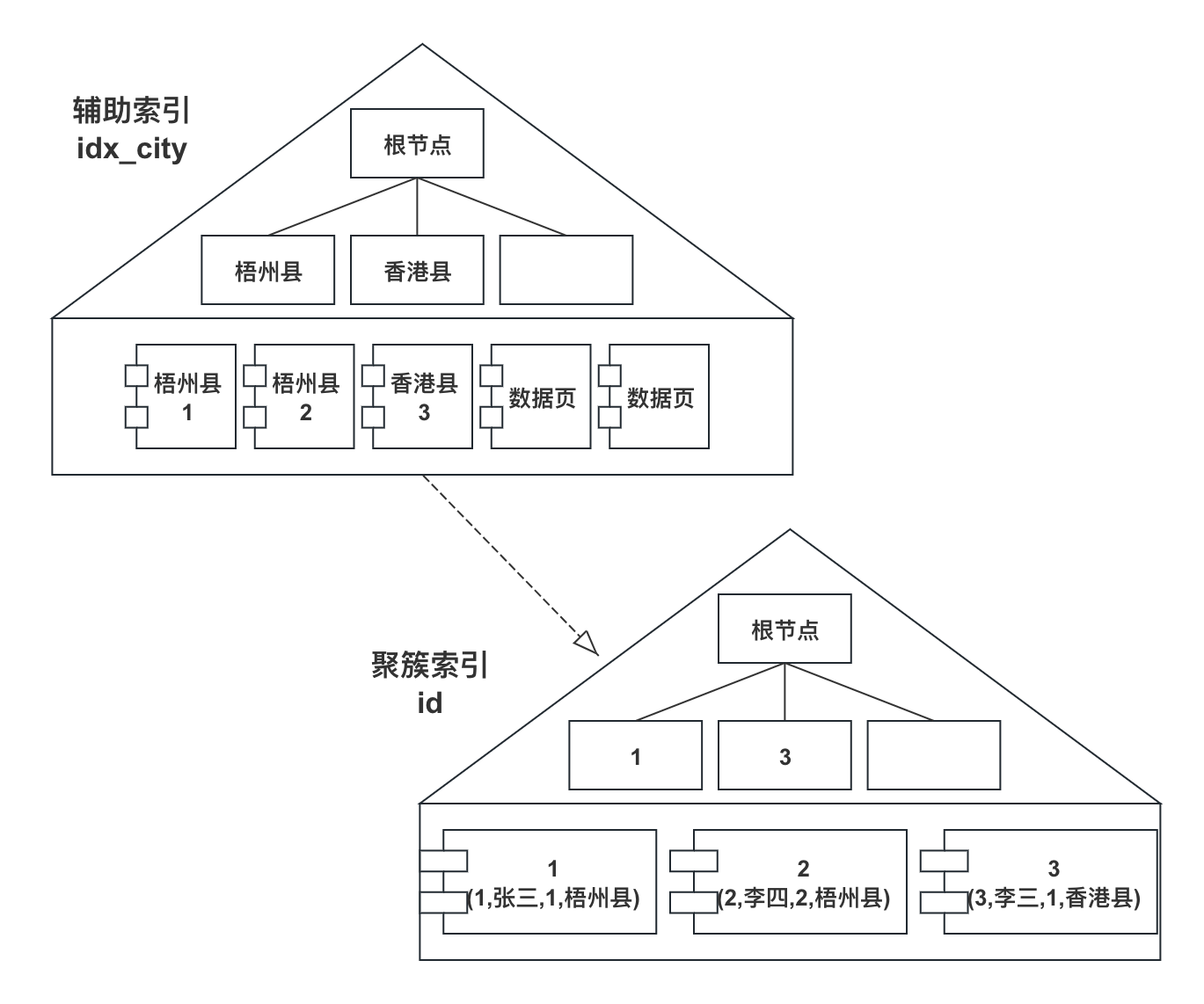
前面已经提到,我们简化一下,一个页只存储一条数据。
辅助索引的叶子结点,存储的都是该索引的键值及对应的主键的值;
聚簇索引的叶子节点,存储的都是一行行完整的数据。
SQL执行过程
接下来,我们将要执行的是这样一条SQL语句:
select id,name
from t_customer
where city = '合肥' and gender = 1
假设数据库的优化器最终决定要走idx_city这个索引,进行SQL的执行,主要的执行过程大概如下:
- 从索引idx_city中找到第一个满足city = '合肥'的主键id;
- 到主键id索引中取出整行,将id, name, gender取出,如果gender = 1 则将id, name的值放入内存缓冲区;
- 重复前两个步骤,直到在idx_city索引中找到的city值不满足查询条件为止
- 将内存缓冲区的数据返回给用户
上面的这条SQL,首先从idx_city索引中找到主键id,然后再到聚簇索引中找到整行记录,然后还要判断是否符合条件,再决定是否返回改行数据。这种查询场景,叫做”回表“。
回表的操作,会增加磁盘IO的次数,如果辅助索引结构中已经包含了用户需要的所有字段,则可以避免回表的操作,这时候的索引叫做”覆盖索引“。
下面,我们对这条SQL稍微修改一下:
select id,name
from t_customer
where city = '合肥' and gender = 1
order byname
limit 100现在这条要执行的SQL中,添加了排序及limit操作,执行的过程会发生相应的调整,假设优化器还是选择了要走idx_city这个索引:
- 从索引idx_city中找到第一个满足city = '合肥'的主键id;
- 到主键id索引中取出整行,将id, name, gender取出,如果gender = 1 则将id, name的值放入排序缓冲区sor_buffer中;
- 重复前两个步骤,直到在idx_city索引中找到的city值不满足查询条件为止
- 对sort_buffer中的数据按照字段name进行快速排序;
- 按照排序结果的数据取出前100条,返回给用户
其实,涉及到排序的话,问题会突然变得复杂起来,这里简单描述下,可能的情况:
1、符合条件的行数很多,sort_buffer中放不下,这时候就不能直接基于内存的排序算法进行了,就需要我们前面文章提到的TPMMS的算法了,进行基于磁盘的多路归并排序;
2、加入最终返回的字段比较多,执行引擎在执行的过程中,可能决定不将所有字段都放入sort_buffer,可能只放主键id和参与排序的字段,然后排序完成之后,需要再按序进行一次回表的操作,获取用户需要的所有字段,然后再返回给用户。基于是否将所有字段放入sort_buffer中,排序的操作符可以简单分为全字段排序和rowid排序。
实际上SQL的执行要考虑的真实场景比较复杂,本文为了便于描述与理解,做了相应的简化,感兴趣的可以自行研究。

相关文章:
结合数据索引结构看SQL的真实执行过程
引言 关于数据库设计与优化的前几篇文章中,我们提到了数据库设计优化应该遵守的指导原则、数据库底层的索引组织结构、数据库的核心功能组件以及SQL的解析、编译等。这些其实都是在为SQL的优化、执行的理解打基础。 今天这篇文章,我们以MySQL中InnoDB存…...
spark shuffle——shuffle管理
ShuffleManager shuffle系统的入口。ShuffleManager在driver和executor中的sparkEnv中创建。在driver中注册shuffle,在executor中读取和写入数据。 registerShuffle:注册shuffle,返回shuffleHandle unregisterShuffle:移除shuff…...

HTMLCSS(入门)
HTML <html> <head><title>第一个页面</title></head><body>键盘敲烂,工资过万</body> </html> <!DOCTYPE>文档类型声明,告诉浏览器使用哪种HTML版本显示网页 <!DOCTYPE html>当前页面采取…...

富格林:曝光可信策略制止亏损
富格林指出,相信大家都对黄金投资的价值空间有目共睹,现如今黄金市场波动频繁,因此不少投资者也开始加入该市场试图赢得额外的财富。但作为新手投资者贸贸然地进场操作,亏损的几率是很大的,因此要学会掌握正规平台曝光…...

Android --- Service
出自于此,写得很清楚。关于Android Service真正的完全详解,你需要知道的一切_android service-CSDN博客 出自【zejian的博客】 什么是Service? Service(服务)是一个一种可以在后台执行长时间运行操作而没有用户界面的应用组件。 服务可由其他应用组件…...

Vue3从入门到精通(三)
vue3插槽Slots 在 Vue3 中,插槽(Slots)的使用方式与 Vue2 中基本相同,但有一些细微的差异。以下是在 Vue3 中使用插槽的示例: // ChildComponent.vue <template><div><h2>Child Component</h2&…...

【FreeRTOS】同步与互斥通信-有缺陷的互斥案例
目录 同步与互斥通信同步与互斥的概念同步与互斥并不简单缺陷分析汇编指令优化过程 - 关闭中断时间轴分析 思考时刻 参考《FreeRTOS入门与工程实践(基于DshanMCU-103).pdf》 同步与互斥通信 同步与互斥的概念 一句话理解同步与互斥:我等你用完厕所,我再…...

Docker 安装 Python
Docker 安装 Python 在当今的软件开发领域,Docker 已成为一项关键技术,它允许开发人员将应用程序及其依赖环境打包到一个可移植的容器中。Python,作为一种广泛使用的高级编程语言,经常被部署在 Docker 容器中。本文将详细介绍如何在 Docker 中安装 Python,以及如何配置环…...
外泌体相关基因肝癌临床模型预测——2-3分纯生信文章复现——4.预后相关外泌体基因确定单因素cox回归(2)
内容如下: 1.外泌体和肝癌TCGA数据下载 2.数据格式整理 3.差异表达基因筛选 4.预后相关外泌体基因确定 5.拷贝数变异及突变图谱 6.外泌体基因功能注释 7.LASSO回归筛选外泌体预后模型 8.预后模型验证 9.预后模型鲁棒性分析 10.独立预后因素分析及与临床的…...

C++: Map数组的遍历
在C中,map是一个关联容器,它存储的元素是键值对(key-value pairs),其中每个键都是唯一的,并且自动根据键来排序。遍历map的方式有几种,但最常用的两种是使用迭代器(iterator…...

【Windows】Bootstrap Studio(网页设计)软件介绍及安装步骤
软件介绍 Bootstrap Studio 是一款专为前端开发者设计的强大工具,主要用于快速创建现代化的响应式网页和网站。以下是它的主要特点和功能: 直观的界面设计 Bootstrap Studio 提供了直观的用户界面,使用户能够轻松拖放元素来构建网页。界面…...

二维舵机颜色追踪,使用树莓派+opencv+usb摄像头+两个舵机实现颜色追踪,采用pid调控
效果演示 二维云台颜色追踪 使用树莓派opencvusb摄像头两个舵机实现颜色追踪,采用pid调控 import cv2 import time import numpy as np from threading import Thread from servo import Servo from pid import PID# 初始化伺服电机 pan Servo(pin19) tilt Serv…...

c进阶篇(四):内存函数
内存函数以字节为单位更改 1.memcpy memcpy 是 C/C 中的一个标准库函数,用于内存拷贝操作。它的原型通常定义在 <cstring> 头文件中,其作用是将一块内存中的数据复制到另一块内存中。 函数原型:void *memcpy(void *dest, const void…...

新手入门:无服务器函数和FaaS简介
无服务器(Serverless)架构的价值在于其成本效益、弹性和扩展性、简化的开发和部署流程、高可用性和可靠性以及使开发者能够专注于业务逻辑。通过自动化资源调配和按需计费,无服务器架构能够降低成本并适应流量变化,同时简化开发流…...

基于Transformer的端到端的目标检测 | 读论文
本文正在参加 人工智能创作者扶持计划 提及到计算机视觉的目标检测,我们一般会最先想到卷积神经网络(CNN),因为这算是目标检测领域的开山之作了,在很长的一段时间里人们都折服于卷积神经网络在图像处理领域的优势&…...
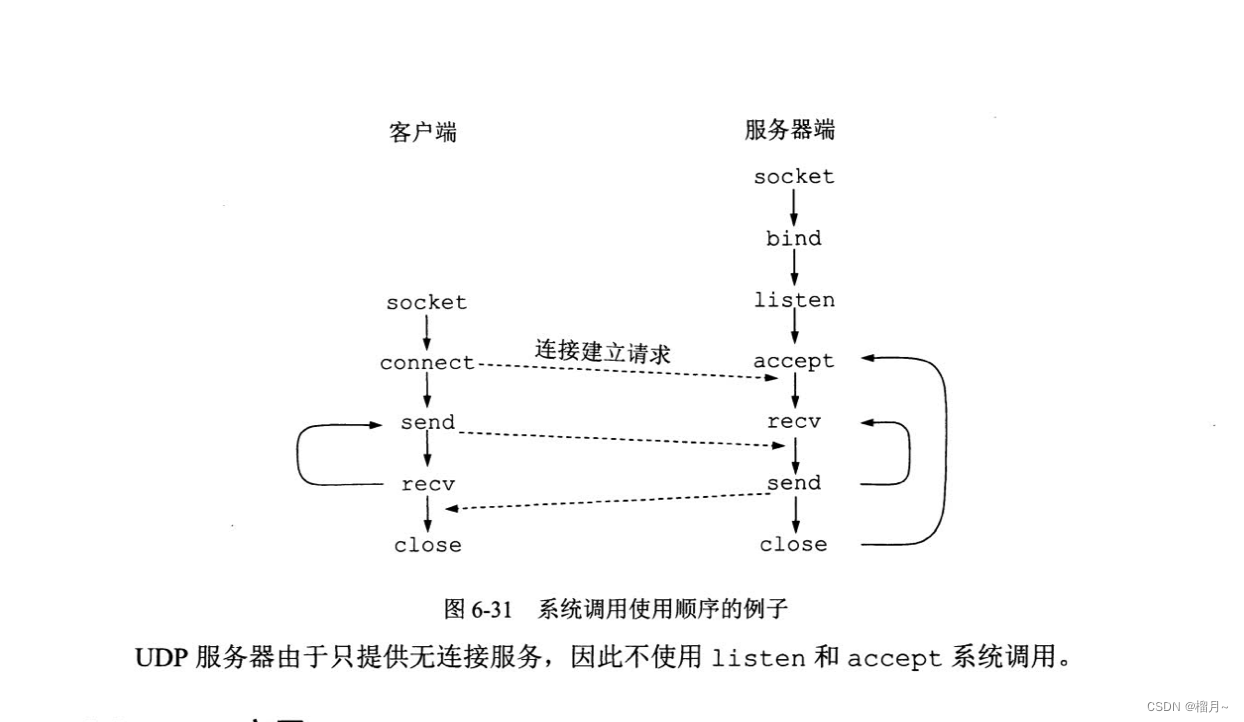
6.8应用进程跨网络通信
《计算机网络》第7版,谢希仁 理解socket通信...

redis布隆过滤器原理及应用场景
目录 原理 应用场景 优点 缺点 布隆过滤器(Bloom Filter)是一种空间效率很高的随机数据结构,它利用位数组和哈希函数来判断一个元素是否存在于集合中。 原理 数据结构: 位数组:一个由0和1组成的数组,初始…...
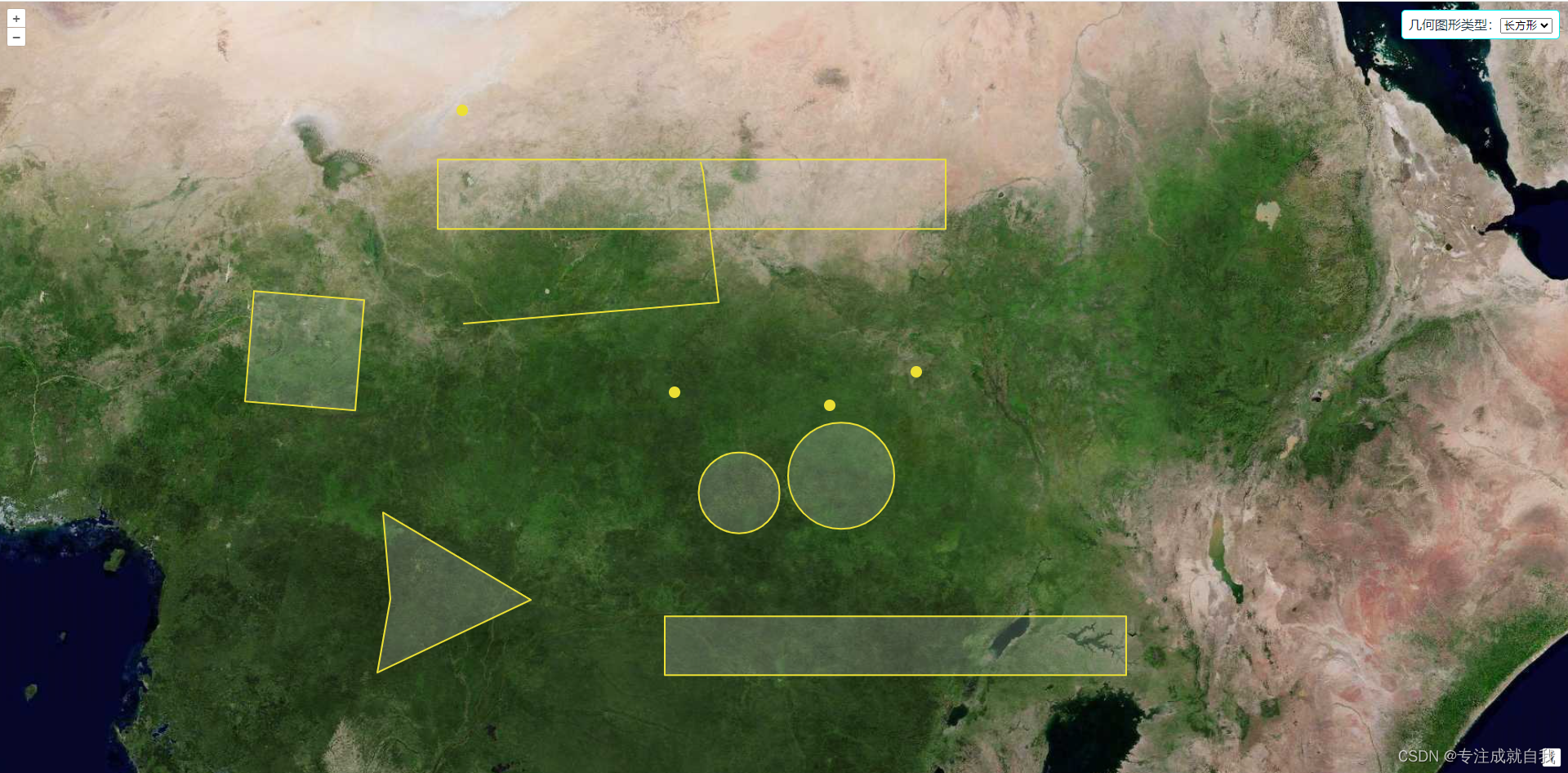
vue+openlayers之几何图形交互绘制基础与实践
文章目录 1.实现效果2.实现步骤3.示例页面代码3.基本几何图形绘制的关键代码 1.实现效果 绘制点、线、多边形、圆、正方形、长方形 2.实现步骤 引用openlayers开发库。加载天地图wmts瓦片地图。在页面上添加几何图形绘制的功能按钮,使用下拉列表(sel…...

「多模态大模型」解读 | 突破单一文本模态局限
编者按:理想状况下,世界上的万事万物都能以文字的形式呈现,如此一来,我们似乎仅凭大语言模型(LLMs)就能完成所有任务。然而,理想很丰满,现实很骨感——数据形态远不止文字一种&#…...

Redis深度解析:核心数据类型与键操作全攻略
文章目录 前言redis数据类型string1. 设置单个字符串数据2.设置多个字符串类型的数据3.字符串拼接值4.根据键获取字符串的值5.根据多个键获取多个值6.自增自减7.获取字符串的长度8.比特流操作key操作a.查找键b.设置键值的过期时间c.查看键的有效期d.设置key的有效期e.判断键是否…...

2026年在湖南选智能家居,有线和无线究竟该怎么选?
引言随着智能家居的普及,在湖南选择智能家居时,有线和无线方案的抉择成为许多消费者头疼的问题。华为鸿蒙智家株洲红星店凭借多年的行业经验和专业知识,为大家提供一些有价值的参考,帮助大家在2026年做出更合适的选择。有线智能家…...

TV Bro电视浏览器:让智能电视变身全能上网终端的终极指南
TV Bro电视浏览器:让智能电视变身全能上网终端的终极指南 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 你是否曾经尝试在智能电视上浏览网页,却…...

终极鸣潮自动化工具:5个技巧让你的游戏时间效率提升500%
终极鸣潮自动化工具:5个技巧让你的游戏时间效率提升500% 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves 你是否曾经为《…...

衰老生物学领域首个1站式标准化DNA甲基化数据库
摘要 准确量化生物年龄对于解析衰老机制、研发高效干预手段至关重要。分子衰老时钟(尤其是基于DNA甲基化数据的表观遗传时钟)已成为衰老研究领域的核心工具。然而,目前缺少覆盖多年龄、多组织且格式统一的公开DNA甲基化数据集,导致表观遗传时钟研究难以高效推进。研究者在…...

【仅剩72小时有效】ChatGPT最新指令缓存机制变更预警:所有未启用“strict_mode”配置的账号将于4月30日降权
更多请点击: https://kaifayun.com 第一章:ChatGPT自定义指令设置的底层逻辑与变更背景 ChatGPT 的自定义指令(Custom Instructions)并非简单的前端配置开关,而是深度集成于模型推理前处理(pre-inference …...
)
从云服务器到树莓派:不同场景下Linux IP地址类型的管理与查看技巧(ip/nmcli实战)
从云服务器到树莓派:Linux IP地址管理的场景化实战指南在混合计算环境中工作的开发者常常面临一个看似简单却充满陷阱的问题:如何快速确定当前Linux设备的IP地址类型?这个问题在公有云、本地虚拟机和嵌入式设备等不同场景下有着截然不同的答案…...

025、原理图库创建与管理
025 原理图库创建与管理:从一次电容封装错位说起 去年做一款工业控制板,BOM清单核对三遍,打样回来焊了十块板子,上电就炸了三块。排查到最后,发现是原理图库里一个0805电容的封装引脚间距画错了0.2mm。焊盘实际间距比标准大了一截,手工焊的时候电容歪着放,引脚搭到隔壁…...
)
DeepSeek日志异常检测实战:基于时序大模型的动态基线算法(已通过金融级等保三级日志审计验证)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek日志分析方案概述 DeepSeek系列大模型在推理与训练过程中会产生海量结构化与半结构化日志,涵盖请求元数据、token级耗时、KV缓存命中率、显存占用、错误堆栈等关键维度。本方案聚焦…...

【DeepSeek R1-VL流式优化白皮书】:基于127个真实生产案例的RTT压缩公式与chunk_size黄金阈值表
更多请点击: https://intelliparadigm.com 第一章:DeepSeek R1-VL流式响应优化的工程意义与挑战全景 DeepSeek R1-VL作为多模态大模型,其视觉-语言联合推理能力依赖于高吞吐、低延迟的流式响应机制。在实时图文理解、交互式AI助手、边缘端多…...

【Gemini重大Bug修复公告】:20年Google AI架构师亲述3个致命漏洞及72小时紧急修复全过程
更多请点击: https://intelliparadigm.com 第一章:Gemini重大Bug修复公告 近日,Google 工程团队紧急发布 Gemini API v0.5.3 补丁版本,修复了一个影响多模态推理一致性的高危竞态条件(Race Condition)Bug。…...