大力出奇迹:大语言模型的崛起与挑战
随着人工智能(AI)技术的迅猛发展,特别是在自然语言处理(NLP)领域,大语言模型(LLM)的出现与应用,彻底改变了我们与机器互动的方式。本文将探讨ChatGPT等大语言模型的定义、误解、潜在问题以及它们在未来的发展方向。

ChatGPT的定义与起源
ChatGPT是一款由OpenAI公司推出的产品,是该公司大语言模型(LLM)系列中的一员。ChatGPT的前身包括GPT-1、GPT-2和GPT-3,这些模型在语言理解和生成方面已经取得了令人瞩目的成就。ChatGPT特别是在指令增强方面表现突出,通过一个友好的web界面,用户可以与其进行自然语言的交互。然而,ChatGPT不仅仅是一个聊天工具,它代表了大语言模型技术的集大成者。
大语言模型(LLM)是NLP领域的重要发展方向,与传统的特定任务小模型不同,LLM是基于大量数据进行训练的通用模型。传统的小模型通常是为特定任务设计的,例如意图识别(intention detection)或实体识别(entity detection),它们通过组合来实现复杂的对话系统。而LLM则是通过大规模的预训练,能够处理多种任务,并且展示了广泛的语言理解和生成能力。
大模型与小模型的对比
大语言模型的出现彻底颠覆了传统的小模型组合方式。小模型是为特定任务而设计的,例如银行账户查询机器人只能回答与账户相关的问题,但对于其他领域的问题则无能为力。而大语言模型通过预训练,吸收了海量的文本数据,具备了广泛的知识储备和语言生成能力。
例如,OpenAI的GPT-3拥有1750亿个参数,能够处理多种语言任务,并展示出惊人的语言生成能力。而在未来,预计会出现参数更庞大的模型,如传说中的GPT-4,其参数量可能高达100万亿,展示出更强的语言处理能力。
预训练与微调
预训练和微调是大语言模型的重要训练步骤。预训练阶段,大模型通过吸收大量的文本数据,掌握了基本的语言知识和生成能力。微调阶段,模型根据特定任务进行调整和优化,以提高其在特定领域的表现。
举例来说,一个经过预训练的保洁机器人已经掌握了基础的清洁技能,而微调阶段则是让它适应特定家庭的清洁需求。这种预训练和微调的组合,大大降低了模型的训练成本,同时提高了其通用性和实用性。
生成式预训练变换器(GPT)的原理
GPT中的G代表生成式(Generative),即模型通过生成文本来完成任务;P代表预训练(Pre-training),即模型通过大规模数据训练,掌握了广泛的语言知识;T代表变换器(Transformer),即模型通过编码器和解码器结构,处理输入的文本并生成输出。
变换器(Transformer)是GPT模型的核心结构。输入的文本通过编码器转换为向量表示,然后通过解码器生成输出。这个过程类似于图像压缩与解压缩,通过提取和还原信息,实现文本的理解与生成。
大语言模型的挑战与幻觉
尽管大语言模型在语言生成方面表现出色,但它们也面临一些挑战。其中最显著的问题之一是所谓的"幻觉"(hallucination),即模型在生成文本时,会产生一些不真实或错误的信息。这种幻觉可能源于模型对数据的压缩和还原过程中的信息丢失和补充。
例如,当问及"苹果的平方根是多少"这样的问题时,模型可能会尝试生成一个看似合理但实际上错误的答案。这种现象提醒我们,大语言模型在处理特定知识和逻辑推理方面仍有局限。
为了减少幻觉,我们可以通过明确指令,告诉模型在不确定时给出"不知道"的回答。这种方法能够显著降低模型生成错误信息的概率。同时,结合外部工具和知识库,例如使用Python进行数学计算,可以提高模型在特定任务上的准确性。
涌现与思考链条
大语言模型展示出的一些高级能力,如涌现(emergence)和思考链条(Chain of Thought),让研究人员感到惊讶。涌现指的是模型在训练过程中,随着参数规模的增加,突然展示出一些新的能力。例如,模型能够理解复杂的问题,并通过分解问题和逐步推理来生成答案。
思考链条则是模型在回答复杂问题时,展示出类似于人类思维的推理过程。例如,当问及"刘强东的太太的年龄的平方根是多少"时,模型能够通过分解问题,逐步得出答案。这种能力展示了大语言模型在语言理解和逻辑推理方面的潜力。
未来发展与应用
大语言模型在未来的发展中,可能会朝着以下几个方向努力:
1. 提高知识准确性:通过结合外部知识库和实时数据,提高模型在特定领域的知识准确性。例如,通过与互联网连接,实时获取最新信息,减少模型生成错误信息的概率。
2. 增强逻辑推理能力:通过改进模型结构和训练方法,提高模型的逻辑推理能力,使其在处理复杂问题时更加准确和可靠。
3. 多语言支持:进一步提高模型对多种语言的支持能力,增强其在全球范围内的应用价值。
4. 个性化应用:通过微调和定制化训练,使模型能够适应不同用户的需求,提供更加个性化和精准的服务。
大语言模型的出现标志着NLP领域的一个重要里程碑。尽管它们在语言生成和理解方面展示了强大的能力,但仍然面临一些挑战。通过持续的研究和改进,我们可以期待大语言模型在未来发挥更大的作用,推动人工智能技术的发展和应用。无论是在商业应用、教育领域还是日常生活中,大语言模型都有潜力带来深远的影响。随着技术的不断进步,我们有理由相信,未来的大语言模型将会更加智能、可靠,为人类社会带来更多的便利和创新。
相关文章:
大力出奇迹:大语言模型的崛起与挑战
随着人工智能(AI)技术的迅猛发展,特别是在自然语言处理(NLP)领域,大语言模型(LLM)的出现与应用,彻底改变了我们与机器互动的方式。本文将探讨ChatGPT等大语言模型的定义、…...
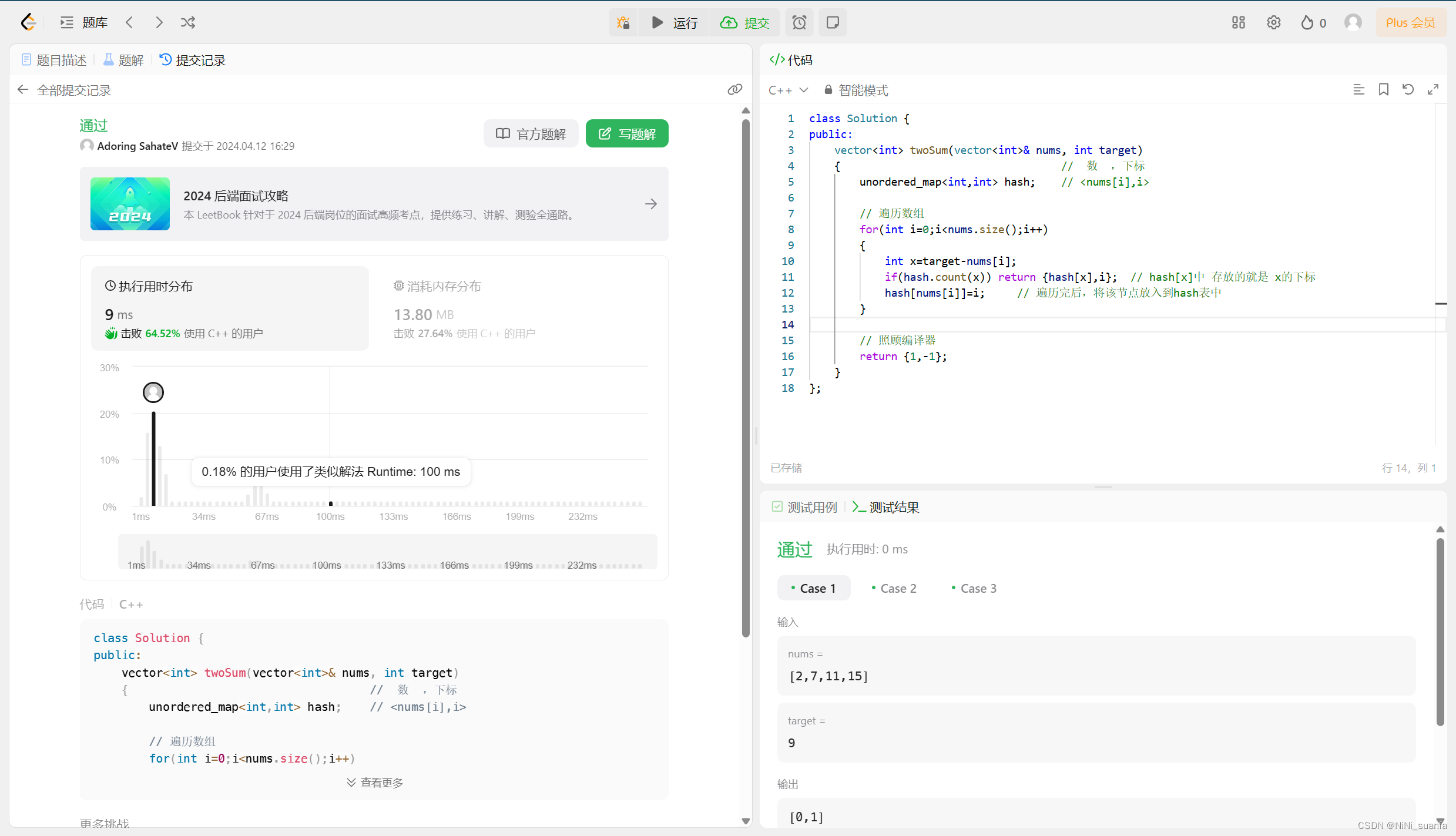
【算法 - 哈希表】两数之和
这里写自定义目录标题 两数之和题目解析思路解法一 :暴力枚举 依次遍历解法二 :使用哈希表来做优化 核心逻辑为什么之前的暴力枚举策略不太好用了?所以,这就是 这道题选择 固定一个数,再与其前面的数逐一对比完后&…...
:线性回归模型第一部分:认识线性回归模型)
【深度学习】图形模型基础(5):线性回归模型第一部分:认识线性回归模型
1. 回归模型定义 最简单的回归模型是具有单一预测变量的线性模型,其基本形式如下: y a b x ϵ y a bx \epsilon yabxϵ 其中, a a a 和 b b b 被称为模型的系数或更一般地,模型的参数。 ϵ \epsilon ϵ 代表误差项&#…...

2024 年第十四届 APMCM 亚太地区大学生数学建模竞赛B题超详细解题思路+数据预处理问题一代码分享
B题 洪水灾害的数据分析与预测 亚太中文赛事本次报名队伍约3000队,竞赛规模体量大致相当于2024年认证杯,1/3个妈杯,1/10个国赛。赛题难度大致相当于0.6个国赛,0.8个妈杯。该比例仅供大家参考。 本次竞赛赛题难度A:B:C3:1:4&…...

Yarn有哪些功能特点
Yarn是一个由Facebook团队开发,并联合Google、Exponent和Tilde等公司推出的JavaScript包管理工具,旨在提供更优的包管理体验,解决npm(Node Package Manager)的一些痛点。Yarn的功能特点主要包括以下几个方面࿱…...

深度学习算法bert
bert 属于自监督学习的一种(输入x的部分作为label) 1. bert是 transformer 中的 encoder ,不同的bert在encoder层数、注意力头数、隐藏单元数不同 2. 假设我们有一个模型 m ,首先我们为某种任务使用大规模的语料库预训练模型 m …...

PyTorch - 神经网络基础
神经网络的主要原理包括一组基本元素,即人工神经元或感知器。它包括几个基本输入,例如 x1、x2… xn ,如果总和大于激活电位,则会产生二进制输出。 样本神经元的示意图如下所述。 产生的输出可以被认为是具有激活电位或偏差的加权…...
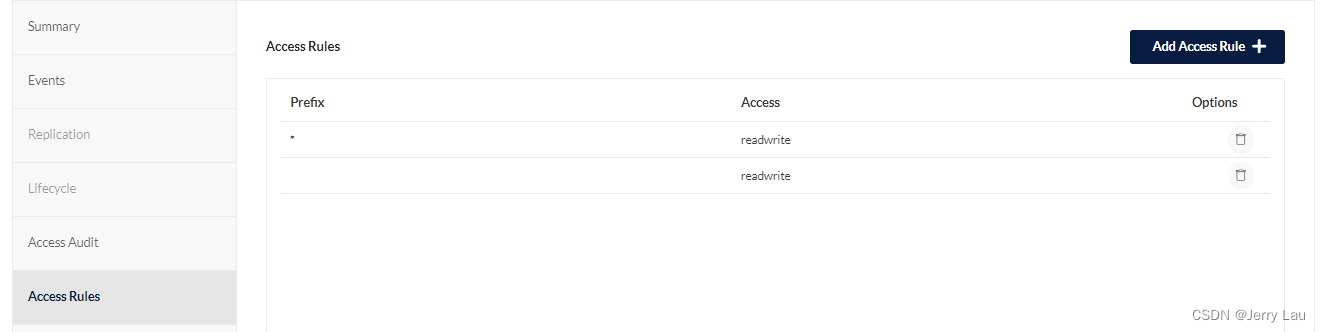
docker-compose搭建minio对象存储服务器
docker-compose搭建minio对象存储服务器 最近想使用oss对象存储进行用户图片上传的管理,了解了一下例如aliyun或者腾讯云的oss对象存储服务,但是呢涉及到对象存储以及经费有限的缘故,决定自己手动搭建一个oss对象存储服务器; 首先…...

vue3使用pinia中的actions,需要调用接口的话
actions,需要调用接口的话,假如页面想要调用actions中的方法获取数据, 必须使用try catch async await 进行包裹,详情看下面代码 import {defineStore} from pinia import {reqCode,reqUserLogin} from ../../api/hospital/i…...

Python酷库之旅-第三方库Pandas(003)
目录 一、用法精讲 4、pandas.read_csv函数 4-1、语法 4-2、参数 4-3、功能 4-4、返回值 4-5、说明 4-6、用法 4-6-1、创建csv文件 4-6-2、代码示例 4-6-3、结果输出 二、推荐阅读 1、Python筑基之旅 2、Python函数之旅 3、Python算法之旅 4、Python魔法之旅 …...

社交电商中的裂变营销利器,二级分销模式,美妆家具成功案例分享
二级分销返佣模式是一种帮助商家迅速扩大市场覆盖的有效营销策略,不仅能降低营销成本,还能提升品牌知名度。下面通过两个具体的案例来说明这种模式的好处和优势。 某知名美妆品牌在市场竞争日益激烈的情况下,决定采用二级分销返佣模式进行市场…...

【国产开源可视化引擎Meta2d.js】图层
独立图层 每个图元都有先后绘画顺序,即每个图元拥有一个独立图层,即meta2d.data().pens的数组索引。 可以通过meta2d.top/bottom/up/down等函数改变独立图层顺序。 分组图层 通过标签可以标识一个分组图层,通过meta2d.find(图层标签)获取…...

基于Redisson实现分布式锁
基于redisson实现分布式锁 之前背过分布式锁几种实现方案的八股文,但是并没有真正自己实操过。现在对AOP有了更深一点的理解,就自己来实现一遍。 1、分布式锁的基础知识 分布式锁是相对于普通的锁的。普通的锁在具体的方法层面去锁,单体应…...

Android Studio下载Gradle特别慢,甚至超时,失败。。。解决方法
使用Android studio下载或更新gradle时超级慢怎么办? 切换服务器,立马解决。打开gradle配置文件 修改服务器路径 distributionUrlhttps\://mirrors.cloud.tencent.com/gradle/gradle-7.3.3-bin.zip 最后,同步,下载,速…...
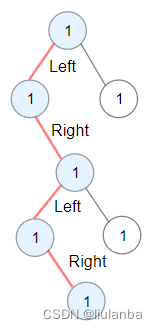
leetcode--二叉树中的最长交错路径
leetcode地址:二叉树中的最长交错路径 给你一棵以 root 为根的二叉树,二叉树中的交错路径定义如下: 选择二叉树中 任意 节点和一个方向(左或者右)。 如果前进方向为右,那么移动到当前节点的的右子节点&…...

c++ primer plus 第15章友,异常和其他:15.1.3 其他友元关系
c primer plus 第15章友,异常和其他:15.1.3 其他友元关系 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 15.1.3 其他友元关系 提示:写完文章后,目录可以自动生成,如何生成可…...

uniapp+vue3页面跳转和传参
页面跳转: uni.navigateTo({url: /pages/index}) 返回上一层: uni.navigateBack ({delta: 1 }) 页面跳转时传参: 跳转前的页面: uni.navigateTo({url: "/pages/index?id123"}) 跳转后的页面: onLoa…...

硬链接和软链接
在Linux系统中,链接(Link)是一种特殊的文件,它指向另一个文件或目录。链接分为两种类型:硬链接(Hard Link)和软链接(也称为符号链接,Symbolic Link)。 1. 硬…...
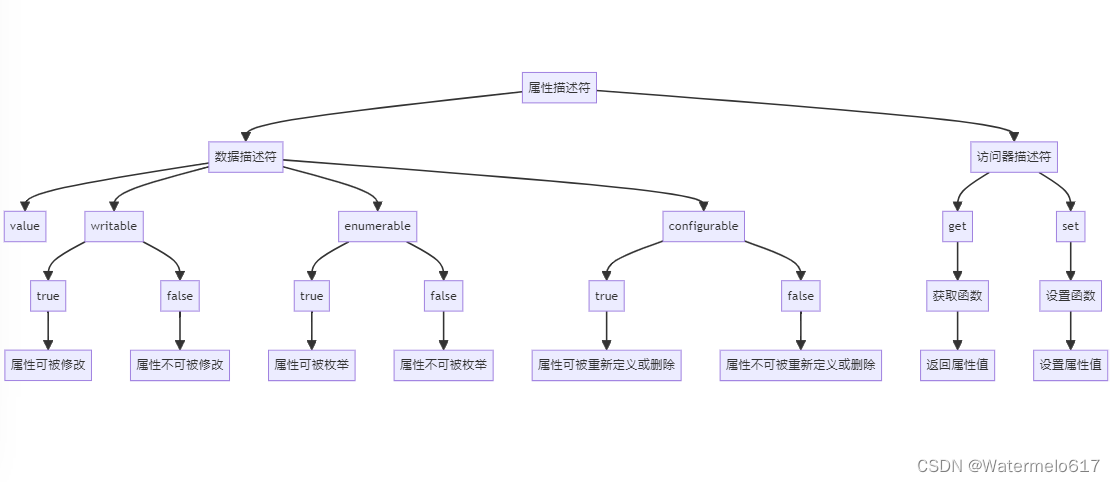
属性描述符初探——Vue实现数据劫持的基础
目录 属性描述符——Vue实现数据劫持的基础 一、属性描述符是什么? 编辑 1.1、属性描述符示例 1.2、用属性描述符定义属性及获取对象的属性描述符 1.3、带有读取器和设置器的属性描述符 二、使用属性描述符的情景 2.1、封装和数据隐藏 使用getter和setter…...

字节也没余粮了?天底下没有永远免费的GPT-4;AI产品用订阅制就不合理!让用户掏钱的N种定价技巧嘿嘿 | ShowMeAI日报
👀日报&周刊合集 | 🎡ShowMeAI官网 | 🧡 点赞关注评论拜托啦! 1. 当 Coze 也开始收费:天底下没有「永远」免费的 GPT-4 注:这里 Coze 指海外版。国内版 扣子 还是免费。 Coze (海外版) 官网链接 → htt…...

机器学习数学基础:线性代数、微积分与概率论的核心应用
1. 项目概述:为什么机器学习离不开数学?如果你刚开始接触机器学习,可能会被各种算法库和框架的易用性所迷惑,以为调调参数、跑跑模型就能解决一切问题。我刚开始也是这么想的,直到亲手实现一个简单的线性回归ÿ…...

终极Win11系统优化指南:Win11Debloat深度清理教程
终极Win11系统优化指南:Win11Debloat深度清理教程 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

NLP文本预处理全流程实战:从数据清洗到向量化的工程实践指南
1. 项目概述:从文本到智能的桥梁在人工智能的众多分支中,自然语言处理(NLP)一直是最具挑战性也最引人入胜的领域之一。它的核心目标直白而宏大:让机器能像人一样理解、运用和生成语言。这听起来像是科幻小说的情节&…...

AzurLaneAutoScript:碧蓝航线全自动脚本终极指南,解放双手的智能游戏管家
AzurLaneAutoScript:碧蓝航线全自动脚本终极指南,解放双手的智能游戏管家 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/Azur…...

图像做 DCT:揭秘那个让像素“开口说话“的数学魔法
一、一个让我"开窍"的乐谱解读故事 我有一个学钢琴的表妹,从小就有一种让我惊叹的能力——她听任何一段陌生的旋律,都能立刻在钢琴上准确弹出来。我一直觉得她有"绝对音感"这种天赋。有一次我好奇地问她:“你怎么做到的&…...

jvm垃圾回收器 - G1详解
G1垃圾收集器发展史与工作原理 G1(Garbage First,垃圾优先)收集器是JVM垃圾收集技术发展史上的里程碑之作,它开创了面向局部收集的设计思路和基于Region的内存布局形式,定位为CMS收集器的替代者和继承人。一、发展史 1…...

ncmdump终极指南:3分钟学会网易云音乐NCM格式免费解密
ncmdump终极指南:3分钟学会网易云音乐NCM格式免费解密 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经下载了网易云音乐的歌曲,却发现它们都是无法在其他播放器打开的NCM格式?别担心&am…...

TCME:用大模型与受控环境解锁非结构化隐私计算新范式
1. 项目概述:当隐私计算遇见大模型,TCME如何破局?在数据驱动的时代,我们每天都在与不信任的第三方打交道。无论是企业间的联合数据分析、个人与平台的服务交互,还是跨机构的合规审计,一个核心矛盾始终存在&…...

Godot中文离线文档本地构建全指南
1. 为什么你下载的“Godot中文文档”总在关键时刻打不开?我第一次在客户现场调试一个嵌入式Godot游戏时,笔记本突然断网——不是Wi-Fi掉线,是整个厂区网络策略限制,所有外网HTTP/HTTPS请求被拦截。当时我正卡在一个Node2D.set_glo…...

超新星遗迹光学辐射特征的主控因素:环境密度与磁场影响的统计诊断
1. 项目概述:当超新星遗迹的“指纹”遇上统计学的“放大镜”在宇宙这个宏大的实验室里,超新星遗迹(Supernova Remnant, SNR)扮演着能量“搅拌器”和物质“回收站”的双重角色。一颗大质量恒星走到生命尽头,…...