14-29 剑和诗人3 – 利用知识图谱增强 LLM 推理能力

知识图谱提供了一种结构化的方式来表示现实世界的事实及其关系。通过将知识图谱整合到大型语言模型中,我们可以增强它们的事实知识和推理能力。让我们探索如何实现这一点。
知识图谱构建
在利用知识图谱进行语言模型增强之前,我们需要从可靠的来源构建高质量的知识图谱。此过程通常涉及以下步骤:
- 数据提取:使用信息提取技术从知识库(例如 Wikidata、DBpedia)、网络表和文本语料库等来源提取结构化数据。
- 实体链接:将提取的实体链接到知识库中的唯一标识符,解决歧义并删除重复实体。
- 关系提取:使用基于模式、监督或无监督的关系提取方法识别实体之间的语义关系。
- 图形构建:通过将实体表示为节点、将关系表示为边来构建知识图谱,确保应用适当的数据清理、规范化和完整性约束。
- 知识库填充:用从提取的数据中的事实填充知识图谱,处理冲突并维护来源信息。
- 图形细化:通过约束执行、推理和人机验证等迭代过程细化知识图谱。
生成的知识图谱的质量至关重要,因为它将直接影响语言模型的事实知识和推理能力。
知识图谱整合策略
一旦我们有了高质量的知识图谱,我们就可以使用各种策略将其与大型语言模型相结合:
- 知识图谱嵌入:将知识图谱中的实体和关系表示为密集向量嵌入,可将其纳入语言模型的输入或输出表示中。这使得模型能够在训练或推理过程中捕获和利用关系知识。
- 知识图谱增强:使用知识图谱三元组增强语言模型的训练数据,有效地教导模型更好地表示和推理结构化知识。
- 知识图谱检索:在推理过程中,根据输入文本检索相关的知识图谱子图或事实,并将这些结构化知识作为附加上下文提供给语言模型。
- 基于知识的生成:开发语言生成模型,可以直接生成基于知识图谱事实的文本,确保生成的输出尊重并准确反映所提供的知识。
- 多任务学习:在传统语言任务(例如文本生成、问答)和知识图谱任务(例如链接预测、路径排名)的组合上训练语言模型,使其能够同时开发语言理解和结构化知识能力。
每种策略在复杂性、计算要求以及知识图谱与语言模型的集成程度方面都有各自的权衡。
知识图谱推理技术
简单地将知识图谱集成到语言模型中可能不足以完成复杂的推理任务。我们需要先进的技术来实现这些模型中有效的知识图谱推理:
- 路径排序和推理:训练语言模型对多跳知识图谱路径进行推理,使它们能够通过遍历和组合多个事实来回答复杂的查询。
- 符号推理:将符号推理能力融入语言模型,使其能够对结构化知识表示执行逻辑运算和推理。
- 神经符号推理:开发混合神经符号方法,结合神经网络(模式识别、泛化)和符号推理(可解释性、逻辑一致性)的优势。
- 知识图谱注意力:开发注意力机制,能够在语言模型推理过程中有效关注相关的知识图谱实体和关系,从而实现更有针对性和情境化的知识利用。
- 知识图谱约束:在语言模型训练或推理期间强制执行知识图谱约束(例如类型约束、基数约束),以确保生成的输出符合底层知识图谱结构和语义。
- 知识图谱细化:开发基于语言模型输出来细化和扩展知识图谱的技术,实现知识图谱增强语言模型的共生关系,而语言模型反过来又有助于细化和扩展知识图谱。
这些技术旨在弥合语言模型固有的模式匹配能力与知识图谱的结构化、符号化之间的差距,从而实现对结构化知识的更为稳健和可解释的推理。
使用知识图谱进行常识推理虽然知识图谱擅长表示事实知识,但常识推理仍然是语言模型面临的重大挑战。为了解决这个问题,我们可以利用捕获常识知识的知识图谱,例如 ConceptNet、ATOMIC 和 CommonsenseQA。
将常识知识图谱集成到语言模型中,可以使它们更好地理解和推理日常情况、事件和人类行为。这可以通过以下技术实现:
- 常识知识增强:利用常识知识图谱三元组增强语言模型训练数据,使模型能够学习和表示常识知识。
- 常识知识检索:在推理过程中,根据输入文本从知识图谱中检索相关的常识知识,并将其作为附加上下文提供给语言模型。
- 常识推理任务:通过以常识知识图谱为条件,训练常识推理任务的语言模型(例如,预测事件的可能原因或结果,理解社会规范和惯例)。
- 常识知识图谱补全:开发能够生成或补充现有知识图谱中缺失的常识知识的语言模型,从而实现常识知识的迭代扩展和细化。
利用常识知识增强语言模型可以提高其理解和生成自然、类似人类的语言的能力,以及以更有根据和一致的方式推理现实世界情况的能力。
多模态知识图谱
传统知识图谱侧重于以文本形式表示结构化知识,而多模态知识图谱则通过整合图像、视频和音频等其他模态来扩展这一概念。将多模态知识图谱集成到语言模型中可以使它们更好地理解和推理多模态数据。
多模态知识图谱集成的技术包括:
- 多模态知识图谱嵌入:学习代表文本和多模态数据中的实体和关系的联合嵌入,使语言模型能够捕获和推理多模态知识。
- 多模态知识图谱增强:使用多模态知识图谱三元组增强语言模型训练数据,教导模型将文本概念与其视觉或听觉表征联系起来。
- 多模态知识图谱检索:在推理过程中,根据输入的文本、图像或其他模态检索相关的多模态知识图谱实体或子图,并将这些结构化知识作为附加上下文提供给语言模型。
- 基于多模态知识的生成:开发语言生成模型,该模型可以基于文本和多模态知识图谱事实生成文本,从而能够生成准确反映所提供的多模态知识的描述、标题或叙述。
- 多模态多任务学习:在语言任务和多模态知识图谱任务(例如视觉关系预测、音频事件检测)的组合上训练语言模型,使它们能够开发语言和多模态理解能力。
通过整合多模态知识图谱,语言模型可以更好地理解和推理现实世界,其中的信息通常以多种模态(文本、图像、视频等)呈现。这可以提高图像字幕、视频描述和多模态问答等任务的性能。
知识图谱评估与分析
当我们将知识图谱集成到大型语言模型中时,评估和分析生成的模型以确保其有效性并了解其优势和局限性至关重要。以下是一些评估和分析技术:
- 事实知识评估:通过测试语言模型在开放领域问答、事实验证和知识库完成等知识密集型任务上的性能来评估语言模型的事实知识。
- 推理评估:通过测试语言模型在需要多跳推理、逻辑推理或常识理解的任务上的性能来评估语言模型的推理能力。
- 一致性分析:分析语言模型的输出与集成知识图谱的一致性,确保它尊重所提供的知识并且不会产生不一致或矛盾的陈述。
- 可解释性分析:开发技术来解释和说明语言模型的推理过程,特别是它如何利用集成知识图谱来得出其输出。
- 知识图谱探测:探测语言模型的内部表示,以了解它如何编码和利用知识图谱信息,从而可能为改进知识图谱集成策略提供见解。
- 人工评估:进行人工评估,以评估与知识图谱集成相结合时语言模型输出的质量、自然性和一致性。
- 错误分析:分析错误和失败案例,以识别语言模型知识图谱利用中的模式和弱点,为未来的改进和完善提供信息。
知识图谱的策划与演进
知识图谱不是静态实体;它们需要不断地管理和发展,以保持其相关性和质量。以下是一些知识图谱管理和发展的技术:
- 知识图谱细化:开发细化和清理知识图谱的技术,例如约束执行、重复数据删除和事实验证。这既涉及自动化方法,也涉及人为干预过程。
- 知识图谱补全:利用知识库补全、从文本中提取关系和众包等技术来识别并填充图中缺失的知识。
- 知识图谱维护:建立定期更新和维护知识图谱的流程,整合来自新兴来源的新信息并删除过时或不正确的事实。
- 知识图谱演变:开发方法随着时间的推移演变知识图谱模式和结构,允许随着领域和需求的变化而表示新类型的实体、关系和知识。
- 语言模型辅助知识图谱填充:利用知识图谱增强语言模型来协助知识图谱填充任务,例如实体提取、关系提取和事实生成,实现语言模型帮助扩展和细化知识图谱的共生关系。
- 人机交互知识图谱管理:通过众包、专家管理或交互式知识图谱创作工具融入人类专业知识,确保高质量的知识图谱开发和维护。
通过不断地整理和发展知识图谱,我们可以确保语言模型中集成的结构化知识保持最新、全面和准确,从而使模型能够提供可靠和相关的信息和推理。
高级技术:
高级知识图谱表示学习
- 知识图谱嵌入模型:通过探索更具表现力和更强大的嵌入模型来超越传统的知识图谱嵌入,这些模型可以更好地捕捉知识图谱中存在的丰富语义和复杂关系模式。示例包括:
- 张量分解模型(TuckER、m-CP)
- 双曲嵌入(MuRP、RotatE)
- 几何嵌入(RefE、BoxE)
- 语境化知识图谱嵌入:开发技术来学习知识图谱实体和关系的语境化嵌入,捕捉其含义和关系的动态和语境相关性质。
- 知识图谱元学习:探索元学习方法,可以有效地将知识图谱嵌入适应新任务、新领域或知识图谱模式,实现更灵活、快速适应的知识集成。
高级知识图谱推理
- 神经定理证明器:开发能够有效地对知识图谱进行逻辑推理和定理证明的神经架构,从而实现更稳健、更可解释的推理能力。
- 可区分推理:探索可区分推理框架,将符号推理操作(例如逻辑编程、约束求解)无缝集成到神经语言模型的端到端训练中,实现推理和语言理解更紧密的集成。
- 知识图谱强化学习:利用强化学习技术学习有效的推理策略和遍历、组合知识图谱事实的策略,实现更高效、目标驱动的知识图谱推理。
高级知识图谱增强
- 知识图谱对抗训练:采用对抗性训练技术,用对抗性构建的知识图谱示例来增强语言模型,提高其稳健性和处理知识图谱不一致或对抗性攻击的能力。
- 知识图谱数据增强:开发先进的数据增强技术,通过组合和重新组合现有事实来生成合成知识图谱数据,实现更加多样化和全面的知识图谱集成。
- 知识图谱引导的自我监督:探索利用知识图谱提供更具信息性和基于知识的自我监督信号的自我监督学习方法,实现更有效和知识感知的语言模型预训练。
高级知识图谱集成与融合
- 多模态知识图谱集成:开发技术将多模态知识图谱(例如文本、视觉、音频)有效地集成和融合到语言模型中,实现全面的多模态理解和推理。
- 知识图谱集成学习:探索可以结合多种知识图谱和集成策略的优势的集成学习方法,利用它们的互补知识和推理能力来提高性能和稳健性。
- 知识图谱迁移学习:研究能够有效地跨领域、任务或知识图谱模式迁移知识图谱推理能力的迁移学习技术,从而为新领域或应用提供更高效、更快速的知识集成。
这些先进的技术突破了知识图谱集成、表示学习、推理和增强的界限,实现了更强大、更稳健、更灵活的知识图谱增强语言模型。
知识图谱增强语言模型应用
知识图谱与大型语言模型 (LLM) 的集成将为各个领域带来大量令人兴奋的应用。以下是一些潜在的应用:
- 基于知识的问答:利用集成的知识图谱开发能够提供准确且合理答案的问答系统,从而提供更可靠、更易于解释的响应。
- 知识感知内容生成:通过调节相关知识图上的语言模型来生成高质量、事实一致的内容(例如文章、报告、故事),确保生成的文本符合提供的知识和约束。
- 知识图谱探索与查询:构建交互式系统,让用户通过自然语言交互来探索和查询知识图谱,其中语言模型作为知识图谱探索和查询的智能接口。
- 基于知识的任务导向对话:开发面向任务的对话系统,利用知识图谱提供信息丰富且知识丰富的响应,实现更自然和更具情境感知的对话。
- 基于知识图谱的推荐系统:通过整合知识图谱信息增强推荐系统,根据有关项目、用户及其关系的丰富背景知识提供更准确、更可解释的推荐。
- 多模式知识基础:开发能够将语言建立在文本和视觉/听觉知识基础上的多模式系统,实现多模式问答、图像/视频字幕和多媒体内容生成等应用。
- 知识感知的个人助理:构建智能个人助理,可以利用集成的知识图谱提供知识丰富且情境感知的帮助,实现更自然、更明智的互动。
- 知识图谱驱动的决策支持:开发能够对集成知识图谱进行推理的决策支持系统,根据事实知识和特定领域的推理提供明智且透明的决策建议。
这些应用凸显了知识图谱增强语言模型的潜力,它彻底改变了我们与知识交互和利用知识的方式,使各个领域的系统更加智能、知识渊博、值得信赖。
伦理考量与挑战
虽然将知识图谱集成到大型语言模型中具有巨大的潜力,但它也引发了必须解决的重要道德考虑和挑战:
- 知识图谱偏见与公平性:知识图谱可以继承并放大其底层数据源中存在的社会偏见,从而导致语言模型输出和决策出现偏差。识别和减轻知识图谱和语言模型中偏见的技术至关重要。
- 知识图谱隐私和安全:知识图谱可能包含有关个人、组织或系统的敏感或私人信息。必须实施适当的访问控制、匿名化和安全措施,以保护隐私并防止滥用。
- 知识图谱的出处和真实性:确保知识图谱事实的出处和真实性对于维护知识图谱增强语言模型的完整性和可信度至关重要。需要强大的事实核查和验证流程。
- 知识图谱滥用和恶意操纵:知识图谱可能会被操纵或滥用于恶意目的,例如传播错误信息或以有害方式影响语言模型输出。保障措施和监控系统是必要的。
- 透明度和可解释性:虽然知识图谱可以增强语言模型的可解释性,但确保推理过程的完全透明度和可解释性仍然是一个挑战,特别是对于复杂的多跳推理任务。
- 知识图谱的维护和发展:维护和发展大规模知识图谱是一项重大任务,需要大量资源和协调努力,对长期可持续性和可扩展性构成挑战。
- 知识图谱知识产权和许可:知识图谱可能包含受版权保护或专有的信息,从而引发需要谨慎处理的知识产权和许可问题。
- 知识图谱的可访问性和民主化:对高质量知识图谱的访问以及将其有效集成到语言模型中所需的专业知识可能受到限制,这可能会加剧知识和技术差距。
解决这些道德问题和挑战对于负责任和值得信赖地开发和部署知识图谱增强型语言模型至关重要。研究人员、从业人员、政策制定者和利益相关者之间的合作对于建立最佳实践、指导方针和治理框架至关重要,以确保安全且合乎道德地使用这些强大的技术。
未来方向和研究机会
知识图谱与 LLM 的整合是一个活跃且快速发展的研究领域,具有许多令人兴奋的未来方向和研究机会:
- 统一的知识表示和推理:开发统一的框架,可以无缝地表示和推理异构知识源,包括结构化知识图谱、非结构化文本和多模态数据,实现更全面、更整体的知识整合。
- 自适应和终身知识图谱学习:探索终身知识图谱学习技术,其中语言模型可以根据推理或交互过程中遇到的新信息不断调整和扩展其知识图谱。
- 知识图谱感知自监督:研究可以利用知识图谱为语言模型预训练提供更有效、基于知识的自监督信号的自监督学习方法。
- 知识图谱引导的语言模型生成:开发语言生成模型,能够在生成过程中有效利用知识图谱作为指导,确保事实的一致性、连贯性和对所提供知识约束的遵守。
- 神经符号知识表示和推理:探索结合神经网络和符号推理优势的混合神经符号方法,从而实现语言模型中更为稳健、更易于解释的知识表示和推理。
- 知识图谱推理基准:开发全面的基准和评估框架,专门用于评估语言模型的知识图谱推理能力,推动进步并实现公平的比较。
- 知识图谱压缩和高效推理:研究将大规模知识图谱压缩并高效集成到语言模型中的技术,实现在资源受限环境中的可扩展和实用部署。
- 知识图谱增强的多模态语言模型:探索将多模态知识图谱集成到语言模型中,从而增强多模态理解、推理和生成能力。
- 知识图谱辅助语言模型可解释性:开发可解释性技术,利用集成知识图谱为语言模型推理和决策过程提供更透明、更可解释的解释。
- 知识图谱驱动的人机协作:研究利用知识图谱增强语言模型的新型界面和交互范式,实现更有效、以知识为基础的人机协作和知识共享。
随着语言模型的规模和能力不断增长,知识图谱的集成将变得越来越重要,以赋予它们事实知识、推理能力和可解释性。通过解决这些未来的研究方向和挑战,我们可以充分发挥知识图谱增强语言模型的潜力,为更智能、知识渊博和值得信赖的人工智能系统铺平道路。
相关文章:
14-29 剑和诗人3 – 利用知识图谱增强 LLM 推理能力
知识图谱提供了一种结构化的方式来表示现实世界的事实及其关系。通过将知识图谱整合到大型语言模型中,我们可以增强它们的事实知识和推理能力。让我们探索如何实现这一点。 知识图谱构建 在利用知识图谱进行语言模型增强之前,我们需要从可靠的来源构建…...

【代码大全2 选读】看看骨灰级高手消灭 if-else 逻辑的瑞士军刀长啥样
文章目录 1 【写在前面】2 【心法】这把瑞士军刀长啥样3 【示例1】确定某个月份的天数(Days-in-Month Example)4 【示例2】确定保险费率(Insurance Rates Example)5 【示例3】灵活的消息格式(Flexible-Message-Format …...

深度学习 --- stanford cs231学习笔记八(训练神经网络之dropout)
6,dropout 6,1 线性分类器中的正则化 在线性分类器中,我们提到过正则化,其目的就是为了防止过度拟合。例如,当我们要用一条curve去拟合一些散点的数据时,常常是不希望训练出来的curve过所有的点,…...

【C++】 解决 C++ 语言报错:Undefined Reference
文章目录 引言 未定义引用(Undefined Reference)是 C 编程中常见的错误之一,通常在链接阶段出现。当编译器无法找到函数或变量的定义时,就会引发未定义引用错误。这种错误会阻止生成可执行文件,影响程序的正常构建。本…...
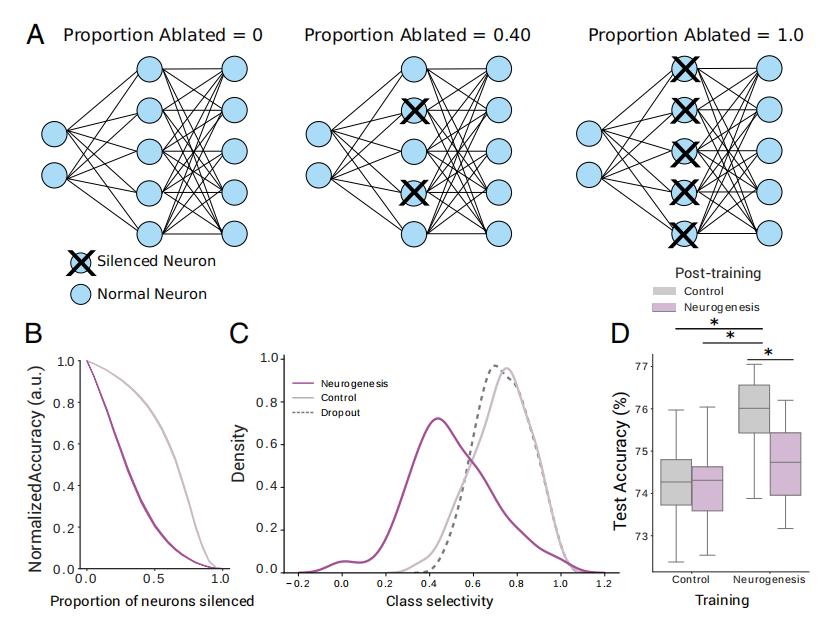
【博士每天一篇文献-算法】Adult neurogenesis acts as a neural regularizer
阅读时间:2023-12-20 1 介绍 年份:2022 作者:Lina M. Tran,Adam Santoro,谷歌DeepMind 期刊: Proceedings of the National Academy of Sciences 引用量:13 代码:https://github.c…...

在Spring Boot项目中引入本地JAR包的步骤和配置
在Spring Boot项目中,有时需要引入本地JAR包以便重用已有的代码库或者第三方库。本文将详细介绍如何在Spring Boot项目中引入本地JAR包的步骤和配置,并提供相应的代码示例。 1. 为什么需要本地JAR包 在开发过程中,可能会遇到以下情况需要使…...

Android Studio中使用命令行gradle查看签名信息
Android Studio中使用命令行gradle查看签名信息: 使用 Gradle 插件生成签名报告 打开 Android Studio 的 Terminal。 运行以下命令:./gradlew signingReport 将生成一个签名报告,其中包含 MD5、SHA1 和 SHA-256 的信息。 如果失败…...
昇思25天学习打卡营第5天 | 神经网络构建
1. 神经网络构建 神经网络模型是由神经网络层和Tensor操作构成的,mindspore.nn提供了常见神经网络层的实现,在MindSpore中,Cell类是构建所有网络的基类,也是网络的基本单元。一个神经网络模型表示为一个Cell,它由不同…...
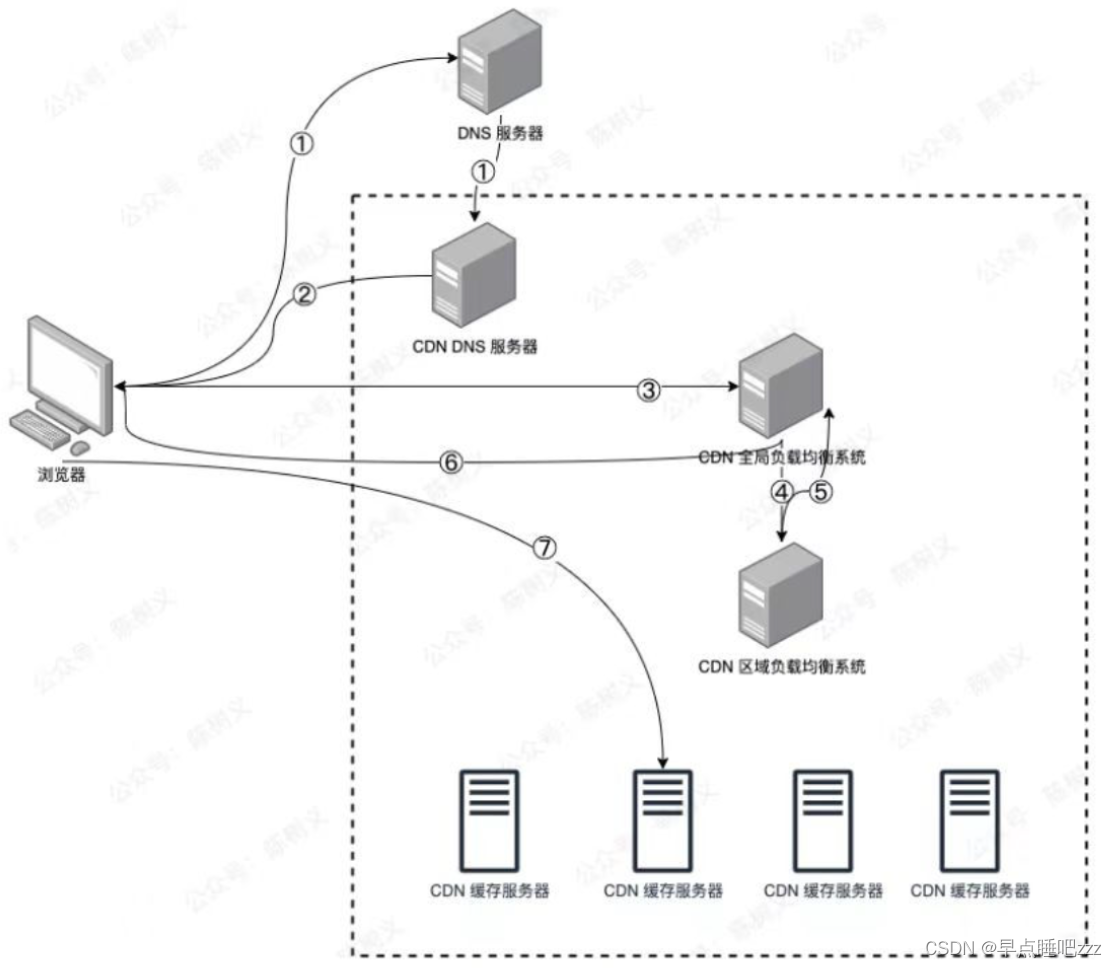
Web缓存—Nginx和CDN应用
目录 一、代理的工作机制 二、概念 三、作用 四、常用的代理服务器 二.Nginx缓存代理服务器部署 1.在三台服务器上部署nginx 此处yum安装 2.准备测试界面 三、CDN概念及作用 1.CDN的工作过程 一、代理的工作机制 (1)代替客户机向网站请求数据…...

Linux 端口
什么是虚拟端口 计算机程序之间的通讯,通过IP只能锁定计算机,但是无法锁定具体的程序。通过端口可以锁定计算机上具体的程序,确保程序之间进行沟通。 IP地址相当于小区地址,在小区内可以有许多用户(程序)&…...
)
菜鸡的原地踏步史02(◐‿◑)
每日一念 改掉自己想到哪写哪的坏习惯 二叉树 二叉树的中序遍历 class Solution {/**中序遍历左 - 中 - 右*/private List<Integer> res new ArrayList<>();public List<Integer> inorderTraversal(TreeNode root) {if(root null) {return res;}tranve…...

实现Java应用的数据加密与解密技术
实现Java应用的数据加密与解密技术 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 1. 数据加密与解密的重要性 数据安全是当今互联网应用开发中的重要问题之…...

赛博解压板
目录 开头程序程序的流程图程序的解压效果(暂无,但可以运行一下上面的代码)结尾 开头 大家好,我叫这是我58。今天,我们要看关于赛博解压板的一些东西。 程序 #define _CRT_SECURE_NO_WARNINGS 1 #define ROW 6//ROW表示行数,可…...

微信小程序常用的事件
1.点击事件 WXML 中绑定点击事件: <!-- index.wxml --> <button bindtap"handleTap">点击我</button> 对应的 JS 文件中编写点击事件处理函数: // index.js Page({handleTap: function() {console.log(按钮被点击了);} }…...

js时间转成xx前
// 时间戳转多少分钟之前 export default function getDateDiff(dateTimeStamp) {// console.log(dateTimeStamp,dateTimeStamp)// 时间字符串转时间戳var timestamp new Date(dateTimeStamp).getTime();var minute 1000 * 60;var hour minute * 60;var day hour * 24;var …...
)
iOS 锁总结(cc)
iOS中atomic和synchrosize锁的本质是什么? 在iOS中,atomic和@synchronized锁的本质涉及底层的多线程同步机制。以下是关于这两者本质的详细解释: atomic 定义与用途: atomic是Objective-C属性修饰符的一种,用于指示属性的存取方法是线程安全的。当一个属性被声明为ato…...

【CSAPP】-binarybomb实验
目录 实验目的与要求 实验原理与内容 实验设备与软件环境 实验过程与结果(可贴图) 操作异常问题与解决方案 实验总结 实验目的与要求 1. 增强学生对于程序的机器级表示、汇编语言、调试器和逆向工程等方面原理与技能的掌握。 2. 掌握使用gdb调试器…...
SpringBoot实战:轻松实现XSS攻击防御(注解和过滤器)
文章目录 引言一、XSS攻击概述1.1 XSS攻击的定义1.2 XSS攻击的类型1.3 XSS攻击的攻击原理及示例 二、Spring Boot中的XSS防御手段2.1 使用注解进行XSS防御2.1.1 引入相关依赖2.1.2 使用XSS注解进行参数校验2.1.3 实现自定义注解处理器2.1.4 使用注解 2.2 使用过滤器进行XSS防御…...

如何改善提示词,让 GPT-4 更高效准确地把视频内容整体转换成文章?
(注:本文为小报童精选文章。已订阅小报童或加入知识星球「玉树芝兰」用户请勿重复付费) 让我们来讨论一下大语言模型应用中的一个重要原则 ——「欲速则不达」。 作为一个自认为懒惰的人,我一直有一个愿望:完成视频制作…...

TensorBoard进阶
文章目录 TensorBoard进阶1.设置TensorBoard2.图像数据在TensorBoard中可视化3.模型结构在TensorBoard中可视化(重点✅)4.高维数据在TensorBoard中低维可视化5.利用TensorBoard跟踪模型的训练过程(重点✅)6.利用TensorBoard给每个…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

AWS DevOps Agent 完全指南
AWS DevOps Agent 是 AWS 推出的前沿 AI 运维代理,自主调查和解决事件、持续预防故障、提升系统可靠性。本文档覆盖从原理到实战的全生命周期管理。 一、定位与价值 一句话定义 AWS DevOps Agent = AI 驱动的 SRE 队友,724 自主调查告警、定位根因、生成修复方案、预防未来…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

大厂校招变了:AI 能力正在进入笔试和面试
最近不少同学投递校招时,应该已经发现一个变化: 以前 JD 里写的是“熟悉 Python / Java / SQL / Office 优先”。 现在越来越多岗位开始出现新的描述: “熟练使用 AI 工具者优先” “了解大模型应用者优先” “具备 AI 辅助编程经验优先” “…...